数据处理装置及数据处理方法与流程
本发明涉及数据处理装置及数据处理方法。
背景技术:
下述,在专利文献1中公开了一种影像声音信号处理装置,其根据由影像解码器解码出的图像数据,对影像场景的特征进行判定,与该影像场景的特征相应地生成声场控制信息。
专利文献1:日本特开2009-296274号公报
在上述专利文献1的结构中,不使用声音数据,而是使用图像数据对内容的场景进行判定,与该场景的判定结果相应地生成声场控制信息,因此存在下述课题,即,该声场控制不一定是适当的。
技术实现要素:
在本发明中,目的在于实现一种数据处理装置,其使用声音数据对内容的场景进行判定,根据该场景的判定结果,选择对声音数据执行的处理。
本发明所涉及的数据处理装置,其包含:第1判定部,其使用声音数据,输出与内容的场景相关的第1判定结果;处理选择部,其与所述第1判定结果相应地,通过第1选择方法选择针对所述声音数据的处理;声音数据处理部,其针对所述声音数据而执行由所述处理选择部选择出的所述处理;以及第2判定部,其从多个属性候选中,对所述内容的属性进行判定,所述处理选择部与所述属性的判定结果相应地,通过与所述第1选择方法不同的第2选择方法对所述处理进行选择。
本发明所涉及的数据处理方法,使用声音数据,输出与内容的场景相关的第1判定结果,与所述第1判定结果相应地,通过第1选择方法选择针对所述声音数据的处理,针对所述声音数据而执行选择出的所述处理,从多个属性候选中,对所述内容的属性进行判定,与所述属性的判定结果相应地,通过与所述第1选择方法不同的第2选择方法对所述处理进行选择。
附图说明
图1是表示第1实施方式中的控制部及声音数据处理部的功能性结构的框图。
图2是包含第1实施方式中的数据处理装置的听取环境的示意图。
图3是表示第1实施方式中的数据处理装置的结构的示意性的框图。
图4是第1实施方式中的数据处理方法的流程图。
图5是在第1实施方式中使用的场景判定模型的概念图。
标号的说明
1数据处理装置,11输入部,12解码器,13声道扩展部,14声音数据处理部,15d/a转换器,16放大器,17控制部,18rom,19ram,31第1判定部,32处理选择部,33第2判定部,21l前-左扬声器,21r前-右扬声器,21c中央扬声器,21sl环绕-左扬声器,21sr环绕-右扬声器。
具体实施方式
[第1实施方式]
以下,使用附图对本发明的第1实施方式进行说明。
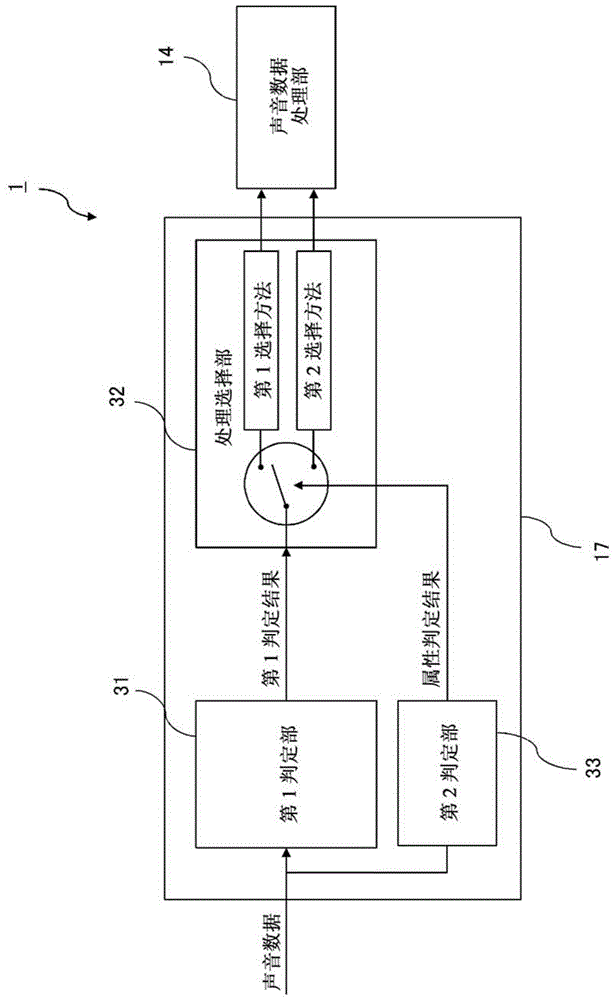
本实施方式中的数据处理装置1包含控制部17和声音数据处理部14。控制部17包含第1判定部31、处理选择部32及第2判定部33。
第1判定部31使用声音数据,输出与内容的场景相关的第1判定结果。第2判定部33从多个属性候选中对内容的属性进行判定。
处理选择部32基本来说,与第1判定结果相应地,通过第1选择方法对处理(例如,声场)进行选择。但是,处理选择部32与通过第2判定部33得到的属性的判定结果相应地,通过与第1选择方法不同的第2选择方法对所述处理进行选择。
声音数据处理部14针对声音数据而执行由处理选择部32选择出的处理。例如,声音数据处理部14将由处理选择部32选择出的声场的效果赋予给所述声音数据。
通过如上所述的结构,本发明的数据处理装置1能够使用声音数据对内容的场景进行判定,根据该场景的判定结果,进行针对声音数据的处理(例如,声场控制)。因此,能够进行更适当的处理。作为例子,关于内容是包含描述车辆的行驶场景的影像数据的音乐视频的情况进行说明。在使用影像数据对内容的场景进行判定的情况下,由于在影像数据中包含有车辆的行驶场景,因此有可能进行对与车辆的行驶声音相关的频率进行强调的声场控制。但是,在本实施方式的结构中,即使在影像数据中包含有车辆的行驶场景,数据处理装置1仍会使用音乐视频所包含的声音数据而进行场景的判定。因此,能够进行更适当的声场控制。
另外,通过设为处理选择部32与由第2判定部33得到的属性的判定结果相应地,通过与第1选择方法不同的第2选择方法对所述声场进行选择的结构,由此能够设为可进行与多个属性相对应的声场控制。
下面,对更具体的结构进行说明。
图2是包含本实施方式中的数据处理装置1的听取环境的示意图。如图1所示,在本实施方式中,在听取位置u的周围设置有前-左扬声器21l、前-右扬声器21r、中央扬声器21c、环绕-左扬声器21sl、及环绕-右扬声器21sr。前-左扬声器21l设置于听取位置u的前方左侧,前-右扬声器21r设置于听取位置u的前方右侧,中央扬声器21c设置于听取位置u的前方中央,环绕-左扬声器21sl设置于听取位置u的后方左侧,环绕-右扬声器21sr设置于听取位置u的后方右侧。前-左扬声器21l、前-右扬声器21r、中央扬声器21c、环绕-左扬声器21sl、及环绕-右扬声器21sr各自通过无线或有线而与数据处理装置1连接。此外,在本实施方式中,举出5ch的环绕系统的例子进行说明,但本发明除此以外也能够在2.0ch、5.1ch、7.1ch、11.2ch等各种声道数的环绕系统中使用。
图3是表示本实施方式中的数据处理装置1的结构的示意性的框图。数据处理装置1能够使用例如av放大器、个人计算机、电视接收机所包含的声音处理部、一体式的扬声器等而实现。如图3所示,本实施方式中的数据处理装置1具有:输入部11、解码器12、声道扩展部13、声音数据处理部14、d/a转换器15、放大器(amplifier)16、控制部17、rom(read-onlymemory)18及ram(randomaccessmemory)19。
控制部17将在rom18中存储的动作用程序(固件)读出至ram19,对数据处理装置1集中地进行控制。该动作用程序可以与光学、磁性等的种类无关地从各种记录介质进行安装,也可以经由互联网下载。
输入部11经由hdmi(注册商标)、网络而取得音频信号。作为音频信号的方式,例如包含pcm(pulsecodemodulation)、dolby(注册商标)、dolbytruehd、dolbydigitalplus、dolbyatmos(注册商标)、aac(advancedaudiocoding)(注册商标)、dts(注册商标)、dts-hd(注册商标)masteraudio、dts:x(注册商标)、dsd(directstreamdigital)(注册商标)等,其种类并不特别受到限定。输入部11将声音数据输出至解码器12。
在本实施方式中,网络包含无线lan(localareanetwork)、有线lan、wan(wideareanetwork)等,作为数据处理装置1和光盘播放器等声源装置之间的信号传递路径起作用。
解码器12例如由dsp(digitalsignalprocessor)构成,对音频信号进行解码,提取声音数据。此外,在本实施方式中,声音数据只要没有特别记载,则全部作为数字数据而进行说明。
声道扩展部13例如由dsp构成,将与上述的前-左扬声器21l、前-右扬声器21r、中央扬声器21c、环绕-左扬声器21sl、环绕-右扬声器21sr各自相对应的、多个声道的声音数据通过声道扩展处理而生成。此外,关于声道扩展处理,能够应用公知技术(例如美国专利第7003467号公报等)。生成的各声道的声音数据输出至声音数据处理部14。
此外,声道扩展部13可以构成为,仅在原始内容中没有包含用户所要求的声道数的声音数据的情况下,进行上述的声道扩展处理。即,可以构成为,在原始内容中包含有用户所要求的声道数的声音数据的情况下,声道扩展部13将从解码器12输出的声音数据以原状态直接输出至声音数据处理部14。或者,也可以设为数据处理装置1不具有声道扩展部13的结构。
声音数据处理部14例如由dsp构成,与控制部17的设定相应地,进行对输入的各声道的声音数据赋予规定的声场效果数据的处理。
声场效果数据例如由根据输入的声音数据而生成的模拟反射音数据构成。生成的模拟反射音数据与原来的声音数据相加而输出。
d/a转换器15将各声道的声音数据变换为模拟信号。
放大器16对从d/a转换器15输出的模拟信号进行放大,分别输出至前-左扬声器21l、前-右扬声器21r、中央扬声器21c、环绕-左扬声器21sl、环绕-右扬声器21sr。通过如上所述的结构,将对音频内容的直接音赋予了模拟反射音而得到的声音从各扬声器输出,在听取位置u的周围形成模拟出规定的音响空间的声场。
图1是表示本实施方式中的控制部17及声音数据处理部14的功能性结构的框图。控制部17可以由单个cpu(centralprocessingunit)构成,也可以由多个cpu构成。
在本发明的数据处理装置1中,控制部17如上所述包含第1判定部31、处理选择部32及第2判定部33。
图4是本实施方式中的数据处理方法的流程图。第1判定部31使用从解码器12取得的声音数据,输出与内容场景相关的第1判定结果(s001)。第2判定部33从多个属性候选中,对内容的属性进行判定(s002)。此外,第1判定部31输出第1判定结果的步骤s001和第2判定部33对内容的属性进行判定的步骤s002的前后关系可以是任意的。
在这里,第2判定部33进行判定的内容的属性并不特别受到限定,例如,第2判定部33可以判定在电影、音乐、新闻等的属性候选之中,内容包含于何种属性。另外,作为不同的例子,第2判定部33判定在动作电影、喜剧电影、sf电影等的属性候选之中,内容包含于何种属性。作为进一步不同的例子,第2判定部33判定在男歌手、女歌手的属性候选之中,内容包含于何种属性。
在本实施方式中,说明下述例子,属性候选为“电影”、“音乐”这两个,第2判定部33判定在这两个属性候选之中,内容包含于何种属性。
在本实施方式中,第1判定部31具有通过仅与由第2判定部33进行判定的属性候选(电影-音乐)中的一部分的属性候选即“电影”相关的机械学习而生成的场景判定模型。作为机械学习,例如能够使用深度学习、支持向量机等各种方法。在本实施方式中,关于场景判定模型使用深度学习而进行机械学习的例子进行说明。
图5是在本实施方式中使用的场景判定模型的概念图。场景判定模型关于与电影内容相关的许多练习用内容进行了机械学习。作为机械学习过程,例如通过手动作业,对练习用内容中的各画面帧(frame)赋予场景类别,将赋予的场景类别和此时的各声道的音量等级、频率特性等作为教师数据而输入。在本实施方式中,第1至第4场景候选和各声道的音量等级、频率特性的特征作为教师数据进行输入。
在本实施方式中,第1判定部31进行判定的第1至第4场景候选的例子如下面所述。第1场景候选是如战斗场景这样的要求雄壮的宏大感的演出的场景。第2场景候选是例如sfx这样的要求将细微的声音鲜明地表现的场景。第3场景候选是要求适于角色扮演游戏、冒险游戏的演出的场景。第4场景候选是电视剧等要求对台词进行强调的场景。按照从第1场景候选至第4场景候选的顺序,在声音数据处理部14中的声场控制中,大幅地附加使声音鸣响的效果。此外,在本实施方式中,将以上这4个场景候选为例而进行说明,但作为其他场景候选,也可以包含例如“重视bgm的场景”、“重视效果音的场景”、“重视低音的场景”等,场景候选的内容并不限定于上述的例子。
如果向第1判定部31输入声音数据,则使用上述的场景判定模型,进行与场景相关的判定。而且,第1判定部31作为第1判定结果,输出与上述第1至第4场景候选各自相关的得分(s001)。作为具体例,第1判定部31从输入的声音数据进行特征提取,基于预先准备的场景判定模型而进行分类,由此输出与上述第1至第4场景候选各自相关的得分(s001)。此外,在本实施方式中,第1判定部31最终输出的第1判定结果,以4个得分的合计成为1的方式被进行了标准化。
第1判定部31作为与场景相关的第1判定结果,将与上述第1至第4场景候选各自相关的得分传递至处理选择部32。
第2判定部33如上所述,从多个属性候选中,对所述内容的属性进行判定。在本实施方式中,属性候选为“电影”、“音乐”这两个,第2判定部33判定在该两个属性候选中,内容包含于何种属性(s002)。
通过第2判定部33进行的内容的属性的判定方法并不特别受到限定。作为内容属性的判定方法的具体例,存在针对声音数据的频率解析、内容所包含的影像数据的解析、及使用内容所包含的标题信息等的元数据的解析等。
作为进行针对声音数据的频率解析的一个例子,是通过对内容所包含的lfe(lowfrequencyeffect)信号进行解析而进行的。在电影内容和音乐内容中,在lfe信号中使用的频带不同。因此,对声音数据所包含的lfe信号进行分析,能够根据在该lfe信号中使用的频带,对输入的内容是电影内容还是音乐内容进行判定。
关于进行针对声音数据的频率解析的第二个例子进行说明。时间轴上的、电影内容的lfe信号的变化,通常大于音乐内容的lfe信号的变化。因此,通过对声音数据中的多个帧的lfe信号的振幅的变化的大小进行分析,从而能够对输入的内容是电影内容还是音乐内容进行判定。
第2判定部33将内容的属性的判定结果传递至处理选择部32。
处理选择部32基于从第1判定部31传递的与场景相关的第1判定结果和从第2判定部33传递的与属性相关的判定结果,对一个声场进行选择(s003、s004)。
在本实施方式中,在内容的属性包含于第1判定部31所具有的场景判定模型已机械学习的属性候选的情况下(在本实施方式中,在属性的判定结果为“电影”的情况下),处理选择部32采用第1选择方法(s003)。反之,在内容的属性不包含于上述属性候选的情况下(在本实施方式中,在属性的判定结果为“音乐”的情况下),处理选择部32采用第2选择方法(s004)。
首先,关于通过第2判定部33进行的内容的属性的判定为“电影”的情况进行说明。基于第2判定部33的判定结果,处理选择部32作为“第1选择方法”而选择与具有最高的得分的场景候选相对应的声场(s003)。例如,在从第1判定部31输出的各场景候选的得分中,第1场景候选具有最高的得分的情况下,选择适于战斗场景这样的要求雄壮的宏大感的演出的场景的声场。
接下来,关于通过第2判定部33进行的内容的属性的判定为“音乐”的情况进行说明。如上所述,在本实施方式中,第1判定部31具有通过仅与由第2判定部33进行判定的属性候选(电影-音乐)中的一部分的属性候选即“电影”相关的机械学习而生成的场景判定模型。因此,在内容的属性为“音乐”的情况下,与在第1判定部31中输出的各场景的得分的值最大的场景候选相应地选择声场并不一定是适当的。例如,音乐内容通常持续地包含有大的音量。因此,在根据通过与电影内容相关的机械学习而生成的场景判定模型,对音乐内容进行了参数处理的情况下,上述的第1场景候选的得分有可能变得最高。在处理选择部32与该第1场景候选相应地对声场进行了选择的情况下,在声音数据处理部14中,作为音乐内容会附加不必要地使声音过于鸣响的声场。因此,在通过第2判定部33得到的内容的属性的判定为“音乐”的情况下,处理选择部32通过与上述的第1选择方法不同的第2选择方法,选择声场(s004)。
作为第2选择方法的第一个例子,说明处理选择部32在除了规定的场景候选以外的多个场景候选中,选择与具有最高的得分的场景候选相对应的所述声场的例子。例如,设为第1判定结果中的第1场景候选的得分为0.5,第2场景候选的得分为0.3,第3场景候选的得分为0.1、第4场景候选的得分为0.1。根据上述的理由,第1场景候选不适于音乐内容。因此,处理选择部32作为第2选择方法而对除了该第1场景候选以外的第2至第4场景候选中,选择与具有最高的得分的场景候选相对应的声场。即,在上述例子中,处理选择部32选择与第2场景候选相对应的声场。
作为第2选择方法的第二个例子,说明处理选择部32与属性的判定结果相应地对与多个场景候选相关的得分乘以系数的例子。例如,处理选择部32可以对与不适合于音乐内容的第1场景候选相关的得分乘以比1小的值的系数(例如,0.8或0等),由此调整为第1场景候选的得分降低。另外,由处理选择部32乘以系数的对象并不限于一个场景候选,也可以对4个场景候选全部乘以系数。此外,处理选择部32可以以相乘得到的最终的得分的合计成为1的方式,再次进行标准化。
作为第2选择方法的第三个例子,说明处理选择部32对规定的声场进行选择的例子。例如,可以构成为在由第1判定部31输出的第1判定结果中,第1场景候选的得分最高的情况下,处理选择部32对第2场景候选进行选择。或者,可以构成为在通过第2判定部33得到的属性的判定结果为“音乐”的情况下,处理选择部32选择与对应于第1至第4场景候选的声场不同的第5声场。
此外,在上述的例子中,说明了第1判定部31的场景判定模型作为机械学习而使用深度学习的例子,但也可以构成为第1判定部31的场景判定模型作为机械学习而使用多类分类用的支持向量机。例如,为了将声音数据分类为n个场景候选,将(n-1)个支持向量机进行组合,进行类别分类。在上述的例子中,进行与4个场景候选相关的分类,因此场景判定模型成为包含3个支持向量机的结构。例如,首先,在第1支持向量机中,对输入的声音数据是否是第1场景候选进行判定。在声音数据不是第1场景候选的情况下,在第2支持向量机中,对声音数据是否是第2场景候选进行判定。在声音数据不是第2场景候选的情况下,在第3支持向量机中,对声音数据是否是第3场景候选进行判定。在声音数据不是第3场景候选的情况下,声音数据决定为是第4场景候选。
如上所述的,在使用了通过使用多类分类用的支持向量机的机械学习得到的场景判定模型的情况下,图1所示的第1判定部31作为第1判定结果而输出第1至第4场景候选中的一个场景候选。
而且,在与通过第2判定部33得到的属性的判定结果相应地,处理选择部32通过第1选择方法对声场进行选择的情况下,处理选择部32基于由第1判定部31输出的第1判定结果即一个场景候选,对声场进行选择。此外,在本实施方式中,作为处理选择部32选择针对声音数据的处理的例子,举出对赋予给声音数据的声场效果进行选择的例子而进行说明,但本发明并不限定于此。作为通过处理选择部32进行的针对声音数据的处理的选择例,除此以外,包含均衡器的设定的选择、各声道的增益比率、延时时间等参数的选择等。
另一方面,说明与通过第2判定部33得到的属性的判定结果相应地,处理选择部32通过第2选择方法,对规定的声场进行选择的情况。例如,可以构成为在第1判定部31作为第1判定结果而输出“第1场景候选”的情况下,处理选择部32例如对第2场景候选进行选择。或者,可以构成为在通过第2判定部33得到的属性的判定结果为“音乐”的情况下,处理选择部32选择与对应于第1至第4场景候选的声场不同的第5声场。
处理选择部32将基于声场选择结果的命令信号输出至声音数据处理部14。在该命令信号中,包含有与声音数据处理部14在运算处理中使用的各种声场参数的设定相关的指示。在声场参数中例如包含各声道的增益比率、滤波器系数及延时时间等。声音数据处理部14基于该命令信号,进行声场参数的变更,由此进行对输入的各声道的声音数据赋予规定的声场效果数据的处理(s005)。
通过如上所述的结构,能够将通过第1判定部31得到的与场景相关的第1判定结果用于具有多个内容属性的多个声音数据。换言之,根据上述结构,具有下述优点,即,第1判定部31无需进行网罗了全部内容的属性的场景判定。因此,作为第1判定部31所具有的场景判定模型,能够使用通过仅与多个属性候选中的一部分的属性候选相关的机械学习而生成的模型。因此,能够减少针对场景判定模型进行的机械学习的量。并且,能够实现作为第1判定部31所输出的第1判定结果而只要输出与有限的场景候选相关的得分就可以的结构。
- 还没有人留言评论。精彩留言会获得点赞!