一种互联网大数据弹幕处理系统及方法与流程
本发明涉及一种大数据弹幕处理系统,特别是涉及一种用于流媒体上同步显示的大数据弹幕处理系统。
背景技术:
弹幕是目前被广泛应用于互联网上的新兴词汇,其代表了一条评论在视频上划过而与视频同步出现在画面内,使用户无需翻看评论即可了解此时其他用户的想法。
目前越来越多的人愿意用弹幕评论,但是流媒体视频上能够显示弹幕的面积有限,因此,各大网站均采用了很多不同的方式筛选弹幕,诸如按照用户等级、按照词汇等方式,而这样会使一部分用户的评论无法被其他用户浏览,导致失去了价值。
但是被限制了面积的画面如何显示更多的弹幕数据和弹幕信息,是本领域技术人员一直在思考的问题。
因此,目前亟需一种能够在相同显示面积下显示更多弹幕信息的大数据弹幕处理系统。
技术实现要素:
本发明要解决的技术问题是提供一种能够在相同显示面积下显示更多弹幕信息的大数据弹幕处理系统。
本发明一种互联网大数据弹幕处理系统,包括
弹幕获取模块,其用于输入第一弹幕;
近义词数据库,其用于存储多组近义词数据并标记每组近义词数据中的的常用词数据;
控制模块,其用于在每个预设时间内,将每个第一弹幕根据所述近义词数据而转化为所述常用词数据,将所述常用词数据转化为第二弹幕;并根据所述常用数据的数量而调整第二弹幕的字体大小;
弹幕服务器,其用于将所述第二弹幕与流媒体合并并输出至用户终端。
本发明一种互联网大数据弹幕处理系统,其中包括
弹幕获取模块,其用于输入第一弹幕;
近义词数据库,其用于存储多组近义词数据并标记每组近义词数据中的的常用词数据;
控制模块,其用于在每个预设时间内,将每个第一弹幕根据所述近义词数据而转化为所述常用词数据,将所述常用词数据转化为第二弹幕;并根据所述常用数据的数量而调整第二弹幕的字体颜色;
弹幕服务器,其用于将所述第二弹幕与流媒体合并并输出至用户终端。
本发明一种互联网大数据弹幕处理系统,其中所述控制模块获取所述流媒体的当前播放帧后的预设帧数,当所述预设帧数内出现连续变化小于预设阈值的连续固定帧数据时,则将所述连续固定帧数据的第一帧的时间作为之前一个预设时间的结束时间。
本发明一种互联网大数据弹幕处理系统,其中所述控制模块获取所述流媒体的当前播放帧后的预设帧数,当所述预设帧数内出现连续变化小于预设阈值的连续固定帧数据时,则将所述连续固定帧数据的最后一帧的时间作为所述最后一帧所处的预设时间的结束时间。
本发明一种互联网大数据弹幕处理系统,其中当所述流媒体为点播视频时,控制模块将合并后的第二弹幕配置在所述预设时间的中间而发出,并与所述流媒体数据合成。
本发明一种互联网大数据弹幕处理系统,其中当所述流媒体为直播视频时,控制模块将合并后的第二弹幕配置在所述预设时间的之后的延迟时间内而发出,并与所述流媒体数据合成。
本发明一种互联网大数据弹幕处理系统,其中当所述流媒体为点播视频时,控制模块比较在预设时间内的每个分时段内的获取的合成了第二弹幕的第一弹幕的数量,并将其中数量最多的分时段的结束时间作为所述第二弹幕的发送时间。
本发明一种互联网大数据弹幕处理系统的处理方法,包括如下步骤:
step1、存储多组近义词数据并标记每组近义词数据中的的常用词数据;
step2、输入第一弹幕
step3、在每个预设时间内,将每个第一弹幕根据所述近义词数据而转化为所述常用词数据,将所述常用词数据转化为第二弹幕;并根据所述常用数据的数量而调整第二弹幕的字体大小;
step4、将所述第二弹幕与流媒体合并并输出至用户终端。
本发明一种互联网大数据弹幕处理系统与现有技术不同之处在于本发明一种互联网大数据弹幕处理系统通过上述方式可大数据弹幕通过找出其相同的近义词的形式来将其合并,再根据输入过上述近义词的第一弹幕的数量而调整输出的第二弹幕的字体大小,从而避免由于弹幕过多带来的弹幕互相遮盖而使用户无法看清弹幕的问题,又避免了删除、筛选过多弹幕而使用户无法分清更多用户的弹幕内容的问题。
本发明一种互联网大数据弹幕处理系统与现有技术不同之处在于本发明一种互联网大数据弹幕处理系统通过上述方式可大数据弹幕通过找出其相同的近义词的形式来将其合并,再根据输入过上述近义词的第一弹幕的数量而调整输出的第二弹幕的字体颜色,从而避免由于弹幕过多带来的弹幕互相遮盖而使用户无法看清弹幕的问题,又避免了删除、筛选过多弹幕而使用户无法分清更多用户的弹幕内容的问题。
下面结合附图对本发明的一种互联网大数据弹幕处理系统作进一步说明。
附图说明
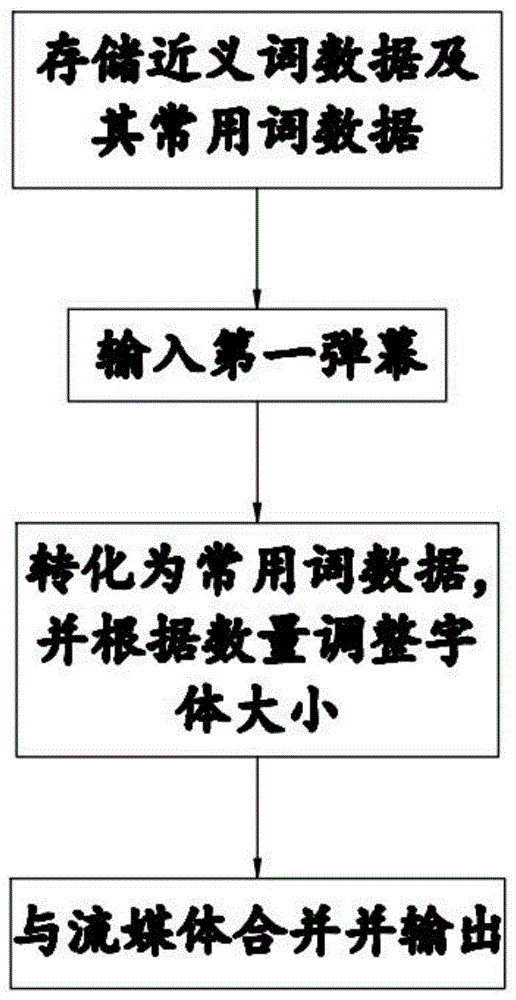
图1是一种互联网大数据弹幕处理系统的流程图。
具体实施方式
如图1所示,本发明一种互联网大数据弹幕处理系统包括
弹幕获取模块,其用于输入第一弹幕;
近义词数据库,其用于存储多组近义词数据并标记每组近义词数据中的的常用词数据;
控制模块,其用于在每个预设时间内,将每个第一弹幕根据所述近义词数据而转化为所述常用词数据,将所述常用词数据转化为第二弹幕;并根据所述常用数据的数量而调整第二弹幕的字体大小;
弹幕服务器,其用于将所述第二弹幕与流媒体合并并输出至用户终端。
本发明通过上述方式可大数据弹幕通过找出其相同的近义词的形式来将其合并,再根据输入过上述近义词的第一弹幕的数量而调整输出的第二弹幕的字体大小,从而避免由于弹幕过多带来的弹幕互相遮盖而使用户无法看清弹幕的问题,又避免了删除、筛选过多弹幕而使用户无法分清更多用户的弹幕内容的问题。
例如,预设时间为15秒,多个用户在此时间内分别输入“中国队威武”、“中国队666”、“中国队厉害”、“中国队真棒”、“中国队好强”这样的第一弹幕,其中,与其一组的近义词数据中“中国队霸气”为常用词数据,那么在这15秒内,上述几个第一弹幕均会合成一个“中国队霸气”的第二弹幕,并且,由于是5个第一弹幕合并来的第二弹幕,因此,如果普通的字体的等级为1的话,那么这个“中国队霸气”的第二弹幕的字体等级应为5,也就是说“中国队霸气”的第二弹幕的字体应该比普通的未被合成的弹幕的字体等级大4个等级。
当然,本发明的一种变形还可为:
本发明一种互联网大数据弹幕处理系统,其中包括
弹幕获取模块,其用于输入第一弹幕;
近义词数据库,其用于存储多组近义词数据并标记每组近义词数据中的的常用词数据;
控制模块,其用于在每个预设时间内,将每个第一弹幕根据所述近义词数据而转化为所述常用词数据,将所述常用词数据转化为第二弹幕;并根据所述常用数据的数量而调整第二弹幕的字体颜色;
弹幕服务器,其用于将所述第二弹幕与流媒体合并并输出至用户终端。
本发明通过上述方式可大数据弹幕通过找出其相同的近义词的形式来将其合并,再根据输入过上述近义词的第一弹幕的数量而调整输出的第二弹幕的字体颜色,从而避免由于弹幕过多带来的弹幕互相遮盖而使用户无法看清弹幕的问题,又避免了删除、筛选过多弹幕而使用户无法分清更多用户的弹幕内容的问题。
例如,预设时间为15秒,多个用户在此时间内分别输入“中国队威武”、“中国队666”、“中国队厉害”、“中国队真棒”、“中国队好强”这样的第一弹幕,其中,与其一组的近义词数据中“中国队霸气”为常用词数据,那么在这15秒内,上述几个第一弹幕均会合成一个“中国队霸气”的第二弹幕,并且,由于是5个第一弹幕合并来的第二弹幕,因此,如果普通的字体的颜色为白色的话,那么这个“中国队霸气”的第二弹幕的字体颜色应为与白色反差更大的颜色,诸如深黑红色,也就是说“中国队霸气”的第二弹幕的字体应该比普通的未被合成的弹幕的字体颜色差别大4个等级。
其中,所述预设时间可为(1s,60s)优选为15s,也就是说,每15秒内合并所有的近义词的第一弹幕,并根据上述近义词的第一弹幕的数量而输出不同字体大小或字体颜色的第二弹幕。这个预设时间可代表一个固定值,也可代表一个最大值。
优选地,所述控制模块获取所述流媒体的当前播放帧后的预设帧数,当所述预设帧数内出现连续变化小于预设阈值的连续固定帧数据时,则将所述连续固定帧数据的第一帧的时间作为之前一个预设时间的结束时间。
本发明通过上述方式可将预设时间更加灵活化处理,也就是说,上述预设时间仅仅规定了其最大时间,在当前播放帧之后的预设帧数内出现连续固定帧数据,改变之前预设时间的结束时间,从而保证了每个时间段尽可能体现流媒体内的不同的内容数据,并且,弹幕与之匹配,对于弹幕的合并、弹幕的大小、弹幕的颜色也能根据此时的内容而进行对应的调整,而不会发生混乱的场景。
因为,在不同的场景下,用户观看在这一场景后所发的弹幕是不同的,而在此情况下,如果这一场景和下一场景各合并了一半近义词弹幕,则无法体现所述近义词弹幕实际占用这一场景的权重,而本发明就是为了每个场景会针对性的合并近义词的弹幕,并将其发送频率、发送速度、发送数量用不同的文字大小、文字颜色发送出,从而体现其权重,方便流媒体视频作者、观众、管理员等人的观看。
其中,本发明以预设帧数内出现连续变化小于预设阈值的连续固定帧数据,作为一个场景数据,一个场景数据中可出现一个或多个预设时间,第一个预设时间的开头与所述一个场景数据的开头时间相同,最后一个预设时间的结尾与所述一个场景数据的结束时间相同。
其中,所述预设帧数可为:(30,3600),优选为3600帧,其中流媒体的图像可为30帧每秒或60帧每秒。
其中,所述预设阈值可为(10%,90%),优选为60%,也就是说,若预设帧数内出现连续变化小于60%时,则判定其为连续固定帧数据。换句话说,连续预设帧数的相同位置的图像能够达到60%相同,则判定其为连续固定帧数据。
优选地,所述控制模块获取所述流媒体的当前播放帧后的预设帧数,当所述预设帧数内出现连续变化小于预设阈值的连续固定帧数据时,则将所述连续固定帧数据的最后一帧的时间作为所述最后一帧所处的预设时间的结束时间。
本发明通过上述方式可将预设时间更加灵活化处理,也就是说,上述预设时间仅仅规定了其最大时间,在当前播放帧之后的预设帧数内出现连续固定帧数据,改变当前预设时间的结束时间,从而保证了每个时间段尽可能体现流媒体内的不同的内容数据,并且,弹幕与之匹配,对于弹幕的合并、弹幕的大小、弹幕的颜色也能根据此时的内容而进行对应的调整,而不会发生混乱的场景。
因为,在不同的场景下,用户观看在这一场景后所发的弹幕是不同的,而在此情况下,如果这一场景和下一场景各合并了一半近义词弹幕,则无法体现所述近义词弹幕实际占用这一场景的权重,而本发明就是为了每个场景会针对性的合并近义词的弹幕,并将其发送频率、发送速度、发送数量用不同的文字大小、文字颜色发送出,从而体现其权重,方便流媒体视频作者、观众、管理员等人的观看。
其中,本发明以预设帧数内出现连续变化小于预设阈值的连续固定帧数据,作为一个场景数据,一个场景数据中可出现一个或多个预设时间,第一个预设时间的开头与所述一个场景数据的开头时间相同,最后一个预设时间的结尾与所述一个场景数据的结束时间相同。
其中,所述预设帧数可为:(30,3600),优选为3600帧,其中流媒体的图像可为30帧每秒或60帧每秒。
其中,所述预设阈值可为(10%,90%),优选为60%,也就是说,若预设帧数内出现连续变化小于60%时,则判定其为连续固定帧数据。换句话说,连续预设帧数的相同位置的图像能够达到60%相同,则判定其为连续固定帧数据。
优选地,当所述流媒体为点播视频时,控制模块将合并后的第二弹幕配置在所述预设时间的中间而发出,并与所述流媒体数据合成。
本发明通过将合并后的第二弹幕在所述预设时间的中间的点而作为发出第二弹幕的时间点,从而可在最适合预设时间内的内容而发出第二弹幕。
优选地,当所述流媒体为直播视频时,控制模块将合并后的第二弹幕配置在所述预设时间的之后的延迟时间内而发出,并与所述流媒体数据合成。
本发明通过将合并后的第二弹幕在所述预设时间的接触的延迟时间内的点而作为发出第二弹幕的时间点,从而可在最接近预设时间内的内容而发出第二弹幕。
其中,所述延迟时间可为(0.1s,10s),优选为3秒内,从而更加贴合预设时间的内容。
优选地,当所述流媒体为点播视频时,控制模块比较在预设时间内的每个分时段内的获取的合成了第二弹幕的第一弹幕的数量,并将其中数量最多的分时段的结束时间作为所述第二弹幕的发送时间。
本发明在流媒体中连续的多个预设时间内具有多个连续的分时段,以此获取的第一弹幕最多的分时段的结束时间作为第二弹幕的发送时间,可代表在将合成的第二弹幕在第一弹幕发送速度最大时发出,从而更贴合多数用户的发送意愿。
其中,所述分时段可为(预设时间/1000,预设时间/10),优选为预设时间/20。
本发明一种互联网大数据弹幕处理系统的处理方法,包括如下步骤:
step1、存储多组近义词数据并标记每组近义词数据中的的常用词数据;
step2、输入第一弹幕
step3、在每个预设时间内,将每个第一弹幕根据所述近义词数据而转化为所述常用词数据,将所述常用词数据转化为第二弹幕;并根据所述常用数据的数量而调整第二弹幕的字体大小;
step4、将所述第二弹幕与流媒体合并并输出至用户终端。
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!