家庭用户识别方法及模块与流程
【技术领域】
本发明涉及移动通信技术领域,尤其涉及一种家庭用户识别方法及模块。
背景技术:
家庭成员识别模型,是基于家庭业务、用户位置、通话行为等用户特征数据,通过识别潜在家庭关系,进而聚合形成家庭群组的方法,通常通过家庭成员识别技术和距离计算技术来实现。
在家庭成员识别技术中,现有家庭成员的识别主要基于短号网业务、位置重合度等关系来实现。在短号网业务技术中,短号是中国移动推出的短号集群网的简称,群内成员互通电话电话不限通话时间,适合大家庭在一个城市使用。在一个短号网内的成员,很大概率上存在家庭关系。因此,现有家庭成员的识别方式,常将位于同个短号网内的成员,当成一个家庭输出。在位置重合度技术中,利用通信运营商的网络,可获取移动终端用户的位置信息(经纬度坐标)。利用家庭成员多数情况下聚集在同地的特性,通过判断用户间位置信息是否相同,来识别家庭成员。在当前的多数家庭成员识别方案中,常通过用户间的lac、ci是否相同,来进行判定。
在距离计算技术中,在涉及到距离计算时,通常基于相似度算法进行计算。一般情况下,有以下多种方法:
第一,欧氏距离(euclideandistance)
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的欧氏距离:
也可以用表示成向量运算的形式:
第二,曼哈顿距离(manhattandistance)
二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离
d12=|x1-x2|+|y1-y2|
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的曼哈顿距离
第三,切比雪夫距离(chebyshevdistance)
二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离
d12=max(|x1-x2|,|y1-y2|)
两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的切比雪夫距离
这个公式的另一种等价形式是
第四,闵可夫斯基距离(minkowskidistance)
闵氏距离不是一种距离,而是一组距离的定义。两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
由上文的描述可知,家庭关系识别是为了满足家庭类业务营销的需要,而现有技术公开的家庭成员的识别方法仅从家庭类业务或者位置信息相等进行建模,未充分区分业务特点。
技术实现要素:
有鉴于此,本发明实施例提供了一种家庭用户识别方法及系统,用以解决现有技术公开的家庭成员的识别方法仅从家庭类业务或者位置信息相等进行建模,未充分区分业务特点问题。
第一方面,本发明实施例提供了一种家庭用户识别方法,所述方法包括:分组,根据所办业务的等级由高到低将家庭用户依次分为第一家庭用户、第二家庭用户和第三家庭用户;结对,将身份信息相匹配的两个家庭用户结成第一家庭关系对,基于第一家庭用户和多对第一家庭关系对组成第一群组;当两个所述第二家庭用户的位置信息之间的距离满足预设阈值或通话信息满足预设条件时结成第二家庭关系对,基于第二家庭用户和多对第二家庭关系对组成第二群组;当两个所述第三家庭用户的通话信息满足预设条件相匹配或身份信息相匹配,且位置信息之间的距离满足预设阈值时结成第三家庭关系对,基于第三家庭用户和多对所述第三家庭关系对组成第三群组;聚合,在所述第一群组中将第一家庭关系对与第一家庭用户进行聚合运算以组成多个第一家庭户,在所述第二群组中将第二家庭关系对与第二家庭用户进行聚合运算以组成多个第二家庭户,在所述第三群组中将第三家庭关系对与第三家庭用户进行聚合运算以组成多个第三家庭户;融合,基于所述第一群组,依次将第一家庭户与所述第二群组的第二家庭户和所述第三群组的第三家庭户进行融合运算,输出家庭群组。
通过本实施例提供的方案,利用多业务因素识别家庭关系对,综合考虑多类能预示家庭关系的业务,并根据业务与家庭关系联系的重要程度对业务进行分类,以此为出发点进行建模,使得家庭关系的识别更加深入;利用位置距离识别家庭关系对,提高了关系识别的准确性。
在一种优选的实施方案中,所述聚合运算是指当第一家庭用户与第一家庭关系对中的家庭用户均能结成家庭关系对时进行聚合以组成第一家庭户,当第二家庭用户与第二家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第二家庭户,当第三家庭用户与第三家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第三家庭户;和/或,所述融合运算是指若所述第二家庭户或所述第三家庭户中的第二家庭用户或第三家庭用户与所述第一家庭户中的第一家庭用户相匹配时,将所述第二家庭用户或所述第三家庭用户融入该第一家庭户中。
通过本实施例提供的方案,以家庭关系对为基础,将家庭用户逐个纳入,形成链状的家庭户。将办理业务等级较低的第二家庭用户、第三家庭用户逐次与第一家庭用户相融合,最终形成目标用户精准、业务定位准确的家庭群组,有利于后续业务的推广。
在一种优选的实施方案中,所述结对还包括,先识别第二家庭用户的通话信息,找出通讯记录相匹配的第二家庭用户,并以此输出初级家庭关系对;再基于位置信息在初级家庭关系对中找出位置信息之间的距离在预设阈值内的两个第二家庭用户,以此输出第二家庭关系对;和/或,所述通话信息包括家庭用户的通话时间和通话频率,所述通话时间相匹配是指家庭用户在工作日午间和夜间存在通话,所述通话频率相匹配是指家庭用户在三个月内任一月通话天数≥2;和/或,所述身份信息匹配是指匹配家庭用户的身份证号和身份证地址;和/或,所述位置信息的距离计算包括:设定家庭用户的常驻地;定位所述常驻地对应的基站;根据基站所在的经纬度定位家庭用户的球面位置;基于家庭用户的球面位置来计算家庭用户之间的曲线距离,从而得到家庭用户的位置信息之间的距离;和/或,所述预设阈值为夜间距离600米。
通过本实施例提供的方案,先通过通话关系识别用户之间关系,再从识别结果中通过位置距离来进一步精确识别家庭关系对,提高了家庭关系对的识别精确性。能够准确识别通话双方的关系亲密度,从而准确识别出家庭关系对。利用身份证号和身份证地址的唯一性,精准识别家庭关系对。基于家庭用户经纬度,基于球面位置来计算位置距离,将位置距离满足预设阈值的家庭用户对视为在同地,考虑了球面曲度带来的距离伸展性,提高了家庭关对系识别的准确性。由于城区内的用户密集,手机所属基站容易产生偏移,城区内基站的覆盖半径一般在150-300米,用户可能接收300米内的基站,所以相距600米内的基站可能接收到同一位置手机发出来的信号,设定预设阈值为600米,提高了通过位置距离计算所输出的家庭关系对的精确性。
在一种优选的实施方案中,对未聚合入第一家庭户、第二家庭户和第三家庭户的第一家庭用户、第二家庭用户和第三家庭用户,分别移除出第一群组、第二群组和第三群组,并以单人家庭户输出;和/或,当第一家庭户、第二家庭户或第三家庭户中的家庭用户数量大于7时,停止所述聚合或所述融合;和/或,所述业务还包括非家庭业务,办理所述非家庭业务为其他家庭用户,当两个其他家庭用户的位置信息之间的距离满足预设阈值、通话信息满足预设条件且身份信息相匹配时结成其他家庭关系对,基于多对其他家庭关系对组成其他群组,基于第一群组,与其他群组进行所述融合。
通过本实施例提供的方案,进一步提高家庭群组中家庭成员的相关性,将没有家庭群组关系的用户,以单人家庭群组输出,拓展了业务的多样性和家庭群组类型。能够满足大部分家庭组成的需求,避免多余计算浪费资源。针对那些办理了非家庭业务的用户群体进行分类、匹配和识别,使得本方法所能识别的家庭用户的覆盖面更广,不会遗漏那些办理家庭业务不活跃的家庭用户。
在一种优选的实施方案中,在输出家庭群组后,采集所述家庭群组中家庭成员的背景信息,根据所述背景信息识别家庭成员中主关键人,若被识别为所述主关键人的家庭成员的数量为复数,则根据该复数个家庭成员所办理的所述业务的等级,将办理所述业务的等级最高的家庭用户设置为主关键人,所述背景信息包括业务办理频率、网龄和每用户平均收入信息;和/或,在输出家庭群组后,采集所述家庭群组中家庭成员的终端使用信息,根据所述终端使用信息及所述身份信息,将所述家庭成员进行角色识别并按照辈分分成三个类别,分别为老人类别、父母类别和子女类别,所述终端使用信息包括触点接触频率、终端机型和应用软件使用信息;和/或,当所述类别中存在多个家庭成员时,对该多个家庭成员进行年龄识别,对年长的家庭成员对应变更为老人类别或父母类别。
通过本实施例提供的方案,能够进一步分析家庭结构,方便用户进一步办理符合其家庭需求的业务。进一步识别家庭结构中主要负责办理业务的家庭用户,提高识别精确性,方便家庭用户进一步定制运营商的业务。可以判断家庭用户的业务办理、业务使用和业务负担能力,进一步精确识别家庭群组中的主关键人。精确识别家庭群组中的家庭成员角色,便于家庭用户定制符合自身需求的业务。分析家庭用户的触点接触频率以识别其终端使用频率,分析家庭用户的终端机型以识别其年龄,分析家庭用户的应用软件使用信息以识别其兴趣,从而精准识别家庭用户的年龄、性别和角色,实现精准分类。避免家庭群组中角色识别错误,提高分类的精确性。
第二方面,本发明实施例提供了一种家庭用户识别系统,包括:分组模块,用于根据所办业务的等级由高到低将家庭用户依次分为第一家庭用户、第二家庭用户和第三家庭用户;计算识别模块,用于身份信息匹配、通话信息识别、位置距离计算、聚合运算和融合运算;结对模块,用于基于所述计算识别模块将身份信息相匹配的两个家庭用户结成第一家庭关系对,基于第一家庭用户和多对第一家庭关系对组成第一群组;当两个所述第二家庭用户通过所述通话信息识别得出通话信息满足预设条件,或通过所述位置距离计算得出位置信息之间的距离满足预设阈值时结成第二家庭关系对,基于第二家庭用户和多对第二家庭关系对组成第二群组;当两个所述第三家庭用户通过所述通话信息识别得出通话信息满足预设条件相匹配或通过所述身份信息匹配得出身份信息相匹配,且通过所述位置距离计算得出位置信息之间的距离满足预设阈值时结成第三家庭关系对,基于第三家庭用户和多对所述第三家庭关系对组成第三群组;聚合模块,用于在所述第一群组中将第一家庭关系对与第一家庭用户进行聚合运算以组成多个第一家庭户,在所述第二群组中将第二家庭关系对与第二家庭用户进行聚合运算以组成多个第二家庭户,在所述第三群组中将第三家庭关系对与第三家庭用户进行聚合运算以组成多个第三家庭户;融合模块,用于基于所述第一群组,依次将第一家庭户与所述第二群组的第二家庭户和所述第三群组的第三家庭户进行融合运算;输出模块,用于基于所述融合模块输出家庭群组。
通过本实施例提供的方案,该家庭用户识别系统能够利用多业务因素识别家庭关系对,综合考虑多类能预示家庭关系的业务,并根据业务与家庭关系联系的重要程度对业务进行分类,以此为出发点进行建模,使得家庭关系的识别更加深入;利用位置距离识别家庭关系对,提高了关系识别的准确性。
在一种优选的实施方案中,所述聚合运算是指当第一家庭用户与第一家庭关系对中的家庭用户均能结成家庭关系对时进行聚合以组成第一家庭户,当第二家庭用户与第二家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第二家庭户,当第三家庭用户与第三家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第三家庭户;和/或,所述融合运算是指若所述第二家庭户或所述第三家庭户中的第二家庭用户或第三家庭用户与所述第一家庭户中的第一家庭用户相匹配时,将所述第二家庭用户或所述第三家庭用户融入该第一家庭户中。
通过本实施例提供的方案,以家庭关系对为基础,将家庭用户逐个纳入,形成链状的家庭户。将办理业务等级较低的第二家庭用户、第三家庭用户逐次与第一家庭用户相融合,最终形成目标用户精准、业务定位准确的家庭群组,有利于后续业务的推广。
在一种优选的实施方案中,所述输出模块还用于对未聚合入第一家庭户、第二家庭户和第三家庭户的第一家庭用户、第二家庭用户和第三家庭用户,分别移除出第一群组、第二群组和第三群组,并以单人家庭户输出;和/或,当第一家庭户、第二家庭户或第三家庭户中的家庭用户数量大于7时,所述聚合模块或所述融合模块停止聚合或融合。
通过本实施例提供的方案,进一步提高家庭群组中家庭成员的相关性,将没有家庭群组关系的用户,以单人家庭群组输出,拓展了业务的多样性和家庭群组类型。能够满足大部分家庭组成的需求,避免多余计算浪费资源。
在一种优选的实施方案中,所述家庭用户识别系统还包括主关键人识别模块,用于在所述家庭群组获取模块输出家庭群组后,采集所述家庭群组中家庭成员的背景信息,根据所述背景信息识别家庭成员中主关键人;所述背景信息包括业务办理频率、网龄和每用户平均收入信息。
通过本实施例提供的方案,该家庭用户识别系统能够进一步分析家庭结构,方便用户进一步办理符合其家庭需求的业务。该家庭用户识别系统可以判断家庭用户的业务办理、业务使用和业务负担能力,进一步精确识别家庭群组中的主关键人。
在一种优选的实施方案中,所述家庭用户识别系统还包括角色分类模块,用于在所述家庭群组获取模块输出家庭群组后,采集所述家庭群组中家庭成员的终端使用信息,根据所述终端使用信息及所述身份信息,将所述家庭成员进行角色识别并按照辈分分成三个类别,分别为老人类别、父母类别和子女类别,所述终端使用信息包括触点接触频率、终端机型和应用软件使用信息;和/或,当所述类别中存在多个家庭成员时,对该多个家庭成员进行年龄识别,对年长的家庭成员对应变更为老人类别或父母类别。
通过本实施例提供的方案,该家庭用户识别系统能够精确识别家庭群组中的家庭成员角色,便于家庭用户定制符合自身需求的业务。该家庭用户识别系统分析家庭用户的触点接触频率以识别其终端使用频率,分析家庭用户的终端机型以识别其年龄,分析家庭用户的应用软件使用信息以识别其兴趣,从而精准识别家庭用户的年龄、性别和角色,实现精准分类。该家庭用户识别系统能够避免家庭群组中角色识别错误,提高分类的精确性。
与现有技术相比,本技术方案至少具有如下有益效果:
1、本实施例提供的家庭用户识别方法及系统能够从业务等级最高的核心业务出发,拓展构建家庭群组的家庭用户识别模型,通过业务关键性判定,以此为依据形成群组,融合家庭用户的通话行为、位置进而完成家庭群组的输出;
2、本实施例提供的家庭用户识别方法及系统能够利用了球面位置上的两点通过经纬度计算其曲面距离的算法,基于位置距离识别家庭用户之间的位置关系;
3、本实施例提供的家庭用户识别方法及系统能够对家庭群组的内部结构进行判定,识别家庭主关键人,对家庭用户进行角色分类。
【附图说明】
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
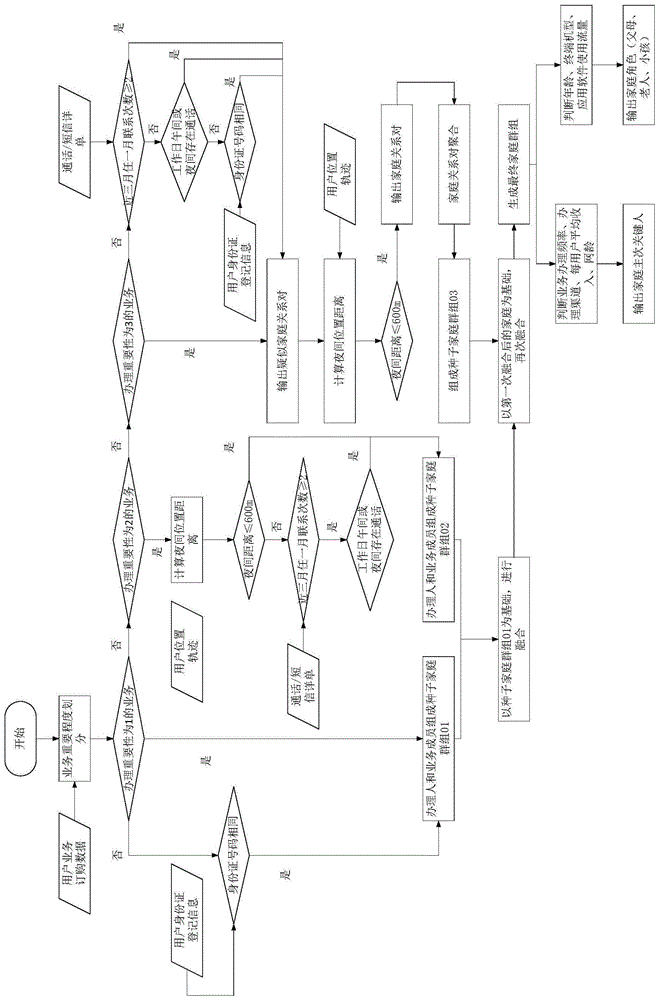
图1是本发明实施例1所提供的家庭用户识别方法的流程图;
图2是本发明实施例1所提供的家庭用户识别方法的家庭群组融合示意图;
图3是本发明实施例2所提供的家庭用户识别系统的模块示意图。
【具体实施方式】
为了更好的理解本发明的技术方案,下面结合附图对本发明实施例进行详细描述。
如图1至图3所示,其中,图1是本发明实施例1所提供的家庭用户识别方法的流程图;图2是本发明实施例1所提供的家庭用户识别方法的家庭群组融合示意图;图3是本发明实施例2所提供的家庭用户识别系统的模块示意图。
实施例1
如图1所示,本发明实施例1提供了一种家庭用户识别方法,方法包括:分组,根据所办业务的等级由高到低将家庭用户依次分为第一家庭用户、第二家庭用户和第三家庭用户;结对,将身份信息相匹配的两个家庭用户结成第一家庭关系对,基于第一家庭用户和多对第一家庭关系对组成第一群组;当两个第二家庭用户的位置信息之间的距离满足预设阈值或通话信息满足预设条件时结成第二家庭关系对,基于第二家庭用户和多对第二家庭关系对组成第二群组;当两个第三家庭用户的通话信息满足预设条件相匹配或身份信息相匹配,且位置信息之间的距离满足预设阈值时结成第三家庭关系对,基于第三家庭用户和多对第三家庭关系对组成第三群组;聚合,在第一群组中将第一家庭关系对与第一家庭用户进行聚合运算以组成多个第一家庭户,在第二群组中将第二家庭关系对与第二家庭用户进行聚合运算以组成多个第二家庭户,在第三群组中将第三家庭关系对与第三家庭用户进行聚合运算以组成多个第三家庭户;融合,基于第一群组,依次将第一家庭户与第二群组的第二家庭户和第三群组的第三家庭户进行融合运算,输出家庭群组。
现有技术基于是同一时间维度下的基站位置数据是否相同,来判断用户间的位置关系,进而确定家庭关系。然而,在某些情况下,基站位置存在漂移,同一位置下的用户可能有不同的基站lac和ci,仅从重合度来判断家庭关系,并不准确。本实施例1的家庭用户识别方法,在对业务进行分级后,仍然会出现使用同一身份证办理多个等级的业务的情况,因此在根据业务的等级将家庭用户分成多个群组后,对使用同一身份证办理其他等级业务而非第一等级业务的家庭用户融入第一群组,减少计算、避免遗漏。针对较低等级的业务办理用户的范围广、人员杂、提取家庭关系对难度相对较高的问题,使用多种算法进行组合,提高家庭关系对识别的精准性。故,本实施例1的家庭用户识别方法利用多业务因素识别家庭关系对,综合考虑多类能预示家庭关系的业务,并根据业务与家庭关系联系的重要程度对业务进行分类,以此为出发点进行建模,使得家庭关系的识别更加深入;利用位置距离识别家庭关系对,提高了关系识别的准确性。
在本实施例1的家庭用户识别方法中,所述聚合运算是指当第一家庭用户与第一家庭关系对中的家庭用户均能结成家庭关系对时进行聚合以组成第一家庭户,当第二家庭用户与第二家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第二家庭户,当第三家庭用户与第三家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第三家庭户。聚合运算以家庭关系对为基础,将家庭用户逐个纳入,形成链状的家庭户。
在本实施例1的家庭用户识别方法中,所述融合运算是指若所述第二家庭户或所述第三家庭户中的第二家庭用户或第三家庭用户与所述第一家庭户中的第一家庭用户相匹配时,将所述第二家庭用户或所述第三家庭用户融入该第一家庭户中。将办理业务等级较低的第二家庭用户、第三家庭用户逐次与第一家庭用户相融合,最终形成目标用户精准、业务定位准确的家庭群组,有利于后续业务的推广。
在本实施例1的家庭用户识别方法中,所述结对还包括,先识别第二家庭用户的通话信息,找出通讯记录相匹配的第二家庭用户,并以此输出初级家庭关系对;再基于位置信息在初级家庭关系对中找出位置信息之间的距离在预设阈值内的两个第二家庭用户,以此输出第二家庭关系对。
在第二群组进行用户匹配计算时,为了更精确、更有序地识别家庭关系对,先通过通话关系识别用户之间关系,再从识别结果中通过位置距离来进一步精确识别家庭关系对,提高了第二家庭关系对的识别精确性。
在本实施例1的家庭用户识别方法中,通讯记录识别包括识别家庭用户的通话时间和通话频率,通话时间相匹配是指家庭用户在工作日午间和夜间存在通话,通话频率相匹配是指家庭用户在三个月内任一月通话天数≥2。
根据人们日常工作生活的规律,家人之间往往会因为一些家事、急事在工作日午间和夜间发生通话,且不管工作多忙,家人之间每个月都会有固定的通话次数。因此,对家庭用户之间的通话时间和通话频次进行识别分析,就能够准确识别通话双方的关系亲密度,从而准确识别出家庭关系对。
在本实施例1的家庭用户识别方法中,身份信息匹配包括匹配家庭用户的身份证号和身份证地址,利用身份证号和身份证地址的唯一性,精准识别家庭关系对。
在本实施例1的家庭用户识别方法中,位置距离计算包括:设定家庭用户的常驻地;定位常驻地对应的基站;根据基站所在的经纬度定位家庭用户的球面位置;基于家庭用户的球面位置来计算家庭用户之间的曲线距离,从而得到位置距离。
由于地球是圆的,在地球上的两点之间的实际距离是球面距离,因此采用一般的位置距离算法并不精确。本实施例1的方法基于家庭用户经纬度,基于球面位置来计算位置距离,将位置距离满足预设阈值的家庭用户对视为在同地,考虑了球面曲度带来的距离伸展性,提高了家庭关对系识别的准确性。
在本实施例1的家庭用户识别方法中,预设阈值为夜间距离600米。由于城区内的用户密集,手机所属基站容易产生偏移,城区内基站的覆盖半径一般在150-300米,用户可能接收300米内的基站,所以相距600米内的基站可能接收到同一位置手机发出来的信号,设定预设阈值为600米,提高了通过位置距离计算所输出的家庭关系对的精确性。
在本实施例1的家庭用户识别方法中,对未聚合入第一家庭户、第二家庭户和第三家庭户的第一家庭用户、第二家庭用户和第三家庭用户,分别移除出第一群组、第二群组和第三群组,并以单人家庭户输出。
在对办理最高等级的业务的第一群组中的第一家庭用户进行分组时,总有一些家庭用户是单独的、不与其他家庭用户产生联系的,故将哪些办理了单人业务的家庭用户设置为没有家庭群组关系的用户,以单人家庭群组输出,从而拓展可办理业务的家庭群组类型。进一步提高家庭群组中家庭成员的相关性,将没有家庭群组关系的用户,以单人家庭群组输出,拓展了业务的多样性和家庭群组类型。
在本实施例1的家庭用户识别方法中,当第一家庭户、第二家庭户或第三家庭户中的家庭用户数量大于7时,停止聚合或融合。将输出的家庭群组的最大人数设定为7人,就能够满足大部分家庭组成的需求,避免多余计算浪费资源。
在本实施例1的家庭用户识别方法中,业务还包括非家庭业务,办理非家庭业务为其他家庭用户,当两个其他家庭用户的位置信息之间的距离满足预设阈值、通话信息满足预设条件且身份信息相匹配时结成其他家庭关系对,基于多对其他家庭关系对组成其他群组;基于第一群组,与其他群组进行融合。针对那些办理了非家庭业务的用户群体进行分类、匹配和识别,使得本方法所能识别的家庭用户的覆盖面更广,不会遗漏那些办理家庭业务不活跃的家庭用户。
在本实施例1的家庭用户识别方法中,在输出家庭群组后,采集家庭群组中家庭成员的背景信息,根据背景信息识别家庭成员中主关键人。
在输出家庭群组后,本实施例1的家庭用户识别方法还能够进一步分析家庭结构,方便用户进一步办理符合其家庭需求的业务。
在本实施例1的家庭用户识别方法,若被识别为主关键人的家庭成员的数量为复数,则根据该复数个家庭成员所办理的业务的等级,将办理业务的等级最高的家庭用户设置为主关键人。
本实施例1的家庭用户识别方法可进一步识别家庭结构中主要负责办理业务的家庭用户,提高识别精确性,方便家庭用户进一步定制运营商的业务。
在本实施例1的家庭用户识别方法中,背景信息包括业务办理频率、网龄和每用户平均收入信息。
基于运营商的业务办理、业务营销需要,主关键人的背景信息应能反应其消费能力和消费趣向,因此本实施例1的家庭用户识别方法能够判断家庭用户的业务办理、业务使用和业务负担能力,进一步精确识别家庭群组中的主关键人。
在本实施例1的家庭用户识别方法中,在输出家庭群组后,采集家庭群组中家庭成员的终端使用信息,根据终端使用信息及身份信息,将家庭成员进行角色识别并按照辈分分成三个类别,分别为老人类别、父母类别和子女类别。
为了更精确地给家庭群组的家庭用户推广、定制业务,需要对家庭用户的年龄、性别、身份、职业、生活习惯等信息有尽可能精确的把握。本实施例1的家庭用户识别方法通过对家庭成员的终端使用信息和身份信息进行采集和分析,能够精确识别家庭群组中的家庭成员角色,便于家庭用户定制符合自身需求的业务。
在本实施例1的家庭用户识别方法中,终端使用信息包括触点接触频率、终端机型和应用软件使用信息。通过分析家庭用户的触点接触频率以识别其终端使用频率,分析家庭用户的终端机型以识别其年龄,分析家庭用户的应用软件使用信息以识别其兴趣,从而精准识别家庭用户的年龄、性别和角色,实现精准分类。
在本实施例1的家庭用户识别方法中,当类别中存在多个家庭成员时,对该多个家庭成员进行年龄识别,对年长的家庭成员对应变更为老人类别或父母类别。从而避免家庭群组中角色识别错误,提高分类的精确性。
采用本实施例1所提供的家庭用户识别方法进行建模、识别、计算、输出家庭群组的具体流程如下。
随着宽带、电视、智能家居等的迅速发展对用户间家庭关系识别有了迫切需求。因此,对家庭成员的识别必不可少。构建家庭关系识别模型,识别客户所属家庭及其家庭成员,以及家庭户中的主、次关键人,以便构建完整的家庭单元,支撑家庭产品营销体系的构建。
整体的建模思路,是根据家庭业务相关性权重,将家庭群组识别分为三类,在此基础上,融合识别最终家庭成员,即基于第一部分确定的种子家庭群组01(即对应办理最高等级业务的家庭用户所组成的第一群组),融合第二部分确定的种子家庭群组02(即对应办理第二等级业务的家庭用户所组成的第二群组),再融合确定的第三部分种子家庭群组03(即对应办理第三等级业务的家庭用户所组成的第三群组),最终完成家庭群组成员的识别。此处将家庭群组根据业务等级分为三类,一方面是为了方便叙述本实施例1的方法,不至于语言繁琐,另一方面则是因为在应用过程中,三级分类已经能够满足大部分的家庭用户识别应用场景。但这并不代表本方法只能应用于三级业务等级的场景,可以推知的是,本方法可以拓展应用至n级业务等级的场景。
其中,种子家庭群组01(即第一群组)基于关键业务输出,是家庭拓展的基本单元;种子家庭群组02(即第二群组)考虑了次关键业务,并综合用户身份信息、位置距离、通话行为,输出家庭关系对;种子家庭群组03(即第三群组)则分析了家庭用户行为场景,设计聚合算法,利用用户行为关系特征,不断迭代聚合计算,输出潜在家庭群组。
在此基础上,本实施例1的家庭用户识别方法还综合考虑了用户业务办理频率、触点接触频率、网龄、消费能力、应用软件使用信息等特征,进一步识别了家庭结构,输出家庭主次关键人,以及判断家庭成员角色,为家庭产品营销提供了更精准化的指引。
通过梳理家庭用户的交往场景,并分析家庭用户行为及家庭用户关系特征,从以下多个建模分析维度,提取相应数据,构建出本实施例1的家庭用户识别方法所输出的家庭群组中的家庭成员关系模型。如下表1所示
表1
如图1所示的是采用本实施例1的家庭用户识别方法的流程图,以业务重要性及家庭用户联系场景等为分析依据,构建种子家庭群组(即第一群组、第二群组和第三群组),并进行有序拓展,逐步形成完整的家庭关系对;在此基础上,辅以家庭用户的特征,完善家庭群组。
第一,根据业务重要性划分
家庭用户办理的业务,由于不同业务与家庭关系的联系紧密程度不同,有些业务能够较为有力地说明用户间的家庭关系,有些却不能。因此,在分析之前,需对业务重要性进行划分,以便提高分析准确性。以下表2为例,根据业务的重要程度可分为三个业务等级,表2仅举出了众多业务等级划分方式中的一种,根据实际用户分布、地域的不同,可以对业务等级进行调整。
表2
第二,生成种子家庭群组(即第一群组、第二群组和第三群组)
其一,生成种子家庭群组01(即第一群组)
由“家庭用户办理的业务重要程度为1的业务”和“身份信息”共同确定种子家庭群组01。即:
(1)办理了家庭业务且在同个群组的家庭用户,形成一个家庭,组成种子家庭群组01;
(2)使用同一身份证办理号卡的用户,形成一个家庭,组成种子家庭群组01;
(3)对于已办理宽带/和目/hitv/iptv的用户,则认为该用户独立形成单人家庭,组成种子家庭群组01。
其二,生成种子家庭群组02(即第二群组)
满足以下任一情况,办理人和业务成员组成种子家庭群组02:
(1)由家庭业务重要程度为2的业务且满足位置信息情况,确定种子家庭群组02。位置关系需满足,用户间夜间常驻地距离<=600m。
(2)由家庭业务重要程度为2的业务且满足通话交往情况,确定种子家庭群组02。通话条件需满足,用户间近3个月中任意一月通话天数>=2,且工作日午间(11:00-14:00)、夜间(17:00-20:30)期间产生通话。
此步骤中,引入夜间常住地距离算法,基于用户经纬度位置数据,计算得到用户间的位置距离。与常用的距离计算方法包括,例如欧氏距离、曼哈顿距离不同,本提案通过考虑球面特性,将球面距离引入到计算过程,从而能更为准确地判断用户位置距离。即输入两个用户的经纬度位置,算法则可自动输出用户距离。该算法简要描述如下:
设定夜间常驻地定义为晚上0点-7点所处时间最长且天数最多的基站。根据“基站-经纬度”对应关系表,由常驻地基站lac、ci可确定用户所在的经纬度(longitude,latitude),实现用户唯一定位。在地球上的用户,其位置是在球体上,因此模拟用户在球面上的位置差异,任意两点之间的距离,基于haversine公式完成输出:
其中,
haversin(θ)=sin2(θ/2)=(1-cos(θ))/2
·r为地球半径,可取平均值6371km;
·
·δλ表示两点经度的差值。
此外,这里取用户距离阈值为600米,是出于由于城区内的用户密集,手机所属基站容易产生偏移,城区内基站的覆盖半径一般在150-300米,用户可能接收300米内的基站,所以相距600米内的基站可能接收到同一位置手机发出来的信号。在实际开展模型应用时,可根据当地基站距离分布调整该阈值,提高模型应用精准性。
其三,生成种子家庭群组03(即第三群组)
根据用户信息、交往圈通话、业务办理、地理位置等业务场景(如下4个),确定家庭关系对。通过聚合算法进行迭代聚合计算,聚合家庭关系对,形成基础家庭组。通过迭代补齐算法,不断完善家庭群组的家庭成员的构成。形成种子家庭群组03。
(1)生成家庭关系对
通过分析家庭用户之间的关系,确定以下4个家庭行为场景:
1)家庭用户通话周期及频率较为固定;
2)家庭用户存在利用同一身份证为另一成员办卡的现象;
3)同一家庭用户可能办理家庭业务重要程度为3的业务;
4)家庭用户间在某些特殊时段可能产生通话。
对应的家庭关系对识别规则为:
1)近3个月中任意一月联系天数>=2的多个家庭用户;
2)绑定同一身份证地址的多个家庭用户;
3)已办理家庭业务重要程度为3的业务的家庭用户;
4)工作日午间(11:00-14:00)、夜间(17:00-20:30)期间产生通话。
此外,由于最终家庭群组中的家庭成员具有地理位置上的相似性,故夜间位置是判断家庭成员关系的必要条件,即只有满足夜间位置距离小于600米的用户对,才是潜在的家庭成员。
上述1)、4)的通话时间、天数、次数阈值可通过对比家庭群组和非家庭群组在近3月的联系天数,以及午间、夜间的通话时间确定。
(2)家庭关系对通过迭代聚合计算形成种子家庭群组03
在输出家庭关系对后,还需进一步聚合已有家庭关系对,才能形成种子家庭群组。在这个过程,设计了家庭关系对的聚合算法,完成家庭关系对的聚合。
主要包括两大步骤:
第一步:家庭关系对聚合
将已匹配的家庭关系对,通过聚合算法,组合成基础家庭组。3人家庭户是基于2人家庭户,通过聚合算法得出。当且仅当3人家庭户中两两家庭用户满足家庭关系,则可聚合形成新的家庭组。在判断新成员是否要融入原家庭组时,由于原家庭组的家庭成员间已满足家庭条件,故只需判断新成员是否与家庭用户间两两存在家庭关系即可。
同理,4人家庭户也是基于3人家庭户聚合而成,以此类推,(n+1)人家庭户均包含不多于n个人的家庭户的组合关系,因此,最终确定n人家庭户时,需要剔除所有多余n+1人的家庭户的组合。
第二步:新用户迭代补齐
基于第一步聚合输出的基础家庭组,通过迭代补齐计算的方式,不断完善家庭群组成员的构成,以提高家庭群组识别的准确性。迭代补齐计算的具体原理如下:
所有家庭关系对,匹配剔除属于基础家庭组范围内的家庭关系对,而在剩余家庭关系对中的家庭用户,将会添加到基础家庭组中人数最少的家庭关系对(前提:该家庭用户与基础家庭组中的某个家庭用户能够匹配成家庭关系对),最后重新计算新的家庭群组的成员,若增加补位的家庭群组人数大于7人,则保留原有家庭群组。
提取所有的家庭用户,将没有家庭群组关系的用户,以一人家庭户输出。
第三,有序融合三类种子家庭群组
基于种子家庭群组01,融合种子家庭群组02,再融合种子家庭群组03,最终完成家庭群组的家庭成员的识别。融合算法原理如下:
如图2所示,以种子家庭群组01为基础,若种子家庭群组02中家庭户的某个成员(例如c)同时也出现在种子家庭群组01的家庭户中,则将种子家庭群组02的家庭户成员c全部纳入到种子家庭群组01家庭户中,以此完善种子家庭群组01的家庭户成员,当家庭户成员超过7人时,则不做融合处理,保留原有家庭户结构。若种子家庭群组02中家庭户的全部家庭成员未出现在种子家庭群组01的家庭户中,则保留种子家庭群组02中家庭户的原有家庭结构。同理,基于第一次融合的家庭群组,将种子家庭群组03中的家庭户d融合进来,最终完成家庭群组成员a~f的识别。
第四,识别家庭结构
其一,识别家庭主次关键人
基于是否办理家庭业务的情况,分别结合家庭成员的业务办理频率、网龄和每用户平均收入信息,根据其优先级,综合识别出家庭户的主次关键人。
若家庭户办理了家庭业务的情况,则匹配家庭业务的主号,即为主关键人。
若同时出现2人及以上主关键人,或家庭户未办理家庭业务,则根据用户业务办理频率、网龄、每用户平均收入按优先级确认主关键人。
其二,识别家庭角色
基于家庭用户的基本信息、终端使用情况,结合年龄用户数分布所确定的家庭角色划分的年龄阈值,从而完成家庭成员角色的精准识别。角色识别规则如下:
1)子女类别:用户终端机型为儿童机;或介于5岁与30岁之间。结合性别信息,可识别出儿子、女儿等角色类别。
2)老人类别:用户终端机型为老人机,结合性别信息,可识别出爷爷、奶奶等角色类别;或满足男性年龄60岁以上的用户视为爷爷类别,女性年龄55岁以上的用户视为奶奶类别。
3)父母类别:女性介于30岁与55岁之间的用户视为母亲类别,女性介于30岁与60岁之间的用户视为父亲类别
4)最后,考虑到30~55/60的年龄区间过大,故采用进一步识别机制,当该区间同时家庭户同时存在两个母亲标签,且用户不同,则需将年龄大的一方视为奶奶类别,年龄小的的一方保持不变。
对于是否儿童家庭判别,家庭中只要有一个家庭成员满足年龄18岁以下或者使用母婴类应用软件的条件,即可视为儿童家庭;而对于是否老人家庭判别,家庭中只要有一个家庭成员满足男性年龄60岁以上或者女性年龄55岁以上或者使用老人类应用软件的条件,即可视为老人家庭。
实施例2
如图3所示,本发明实施例2提供了一种家庭用户识别系统,该装置主要采用实施例1所提供的家庭用户识别方法进行家庭用户识别。
该装置包括分组模块、计算识别模块、结对模块、聚合模块、融合模块、输出模块、主关键人识别模块和角色分类模块。
其中,分组模块,用于根据所办业务的等级由高到低将家庭用户依次分为第一家庭用户、第二家庭用户和第三家庭用户;计算识别模块,用于身份信息匹配、通话信息识别、位置距离计算、聚合运算和融合运算;结对模块,用于基于计算识别模块将身份信息相匹配的两个家庭用户结成第一家庭关系对,基于第一家庭用户和多对第一家庭关系对组成第一群组;当两个第二家庭用户通过通话信息识别得出通话信息满足预设条件,或通过位置距离计算得出位置信息之间的距离满足预设阈值时结成第二家庭关系对,基于第二家庭用户和多对第二家庭关系对组成第二群组;当两个第三家庭用户通过通话信息识别得出通话信息满足预设条件相匹配或通过身份信息匹配得出身份信息相匹配,且通过位置距离计算得出位置信息之间的距离满足预设阈值时结成第三家庭关系对,基于第三家庭用户和多对第三家庭关系对组成第三群组;聚合模块,用于在第一群组中将第一家庭关系对与第一家庭用户进行聚合运算以组成多个第一家庭户,在第二群组中将第二家庭关系对与第二家庭用户进行聚合运算以组成多个第二家庭户,在第三群组中将第三家庭关系对与第三家庭用户进行聚合运算以组成多个第三家庭户;融合模块,用于基于第一群组,依次将第一家庭户与第二群组的第二家庭户和第三群组的第三家庭户进行融合运算;输出模块,用于基于融合模块输出家庭群组。
该家庭用户识别系统针对较低等级的业务办理用户的范围广、人员杂、提取家庭关系对难度相对较高的问题,该家庭用户识别系统使用多种算法进行组合,提高家庭关系对识别的精准性。故能够利用多业务因素识别家庭关系对,综合考虑多类能预示家庭关系的业务,并根据业务与家庭关系联系的重要程度对业务进行分类,以此为出发点进行建模,使得家庭关系的识别更加深入;利用位置距离识别家庭关系对,提高了关系识别的准确性。
在本实施例2的家庭用户识别系统中,聚合运算是指当第一家庭用户与第一家庭关系对中的家庭用户均能结成家庭关系对时进行聚合以组成第一家庭户,当第二家庭用户与第二家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第二家庭户,当第三家庭用户与第三家庭关系对中的家庭用户均能结成另一家庭关系对时进行聚合以组成第三家庭户。以家庭关系对为基础,将家庭用户逐个纳入,形成链状的家庭户。
在本实施例2的家庭用户识别系统中,融合运算是指若第二家庭户或第三家庭户中的第二家庭用户或第三家庭用户与第一家庭户中的第一家庭用户相匹配时,将第二家庭用户或第三家庭用户融入该第一家庭户中。将办理业务等级较低的第二家庭用户、第三家庭用户逐次与第一家庭用户相融合,最终形成目标用户精准、业务定位准确的家庭群组,有利于后续业务的推广。
在本实施例2的家庭用户识别系统中,输出模块还用于对未聚合入第一家庭户、第二家庭户和第三家庭户的第一家庭用户、第二家庭用户和第三家庭用户,分别移除出第一群组、第二群组和第三群组,并以单人家庭户输出。
在对办理最高等级的业务的第一群组中的第一家庭用户进行分组时,总有一些家庭用户是单独的、不与其他家庭用户产生联系的,故将哪些办理了单人业务的家庭用户设置为没有家庭群组关系的用户,以单人家庭群组输出,从而拓展可办理业务的家庭群组类型。进一步提高家庭群组中家庭成员的相关性,将没有家庭群组关系的用户,以单人家庭群组输出,拓展了业务的多样性和家庭群组类型。
在本实施例2的家庭用户识别系统中,当第一家庭户、第二家庭户或第三家庭户中的家庭用户数量大于7时,聚合模块或融合模块停止聚合或融合。将输出的家庭群组的最大人数设定为7人,就能够满足大部分家庭组成的需求,避免多余计算浪费资源。
在本实施例2的家庭用户识别系统中,家庭用户识别系统还包括主关键人识别模块,用于在家庭群组获取模块输出家庭群组后,采集家庭群组中家庭成员的背景信息,根据背景信息识别家庭成员中主关键人。
在输出家庭群组后,本实施例2的家庭用户识别系统还能够进一步分析家庭结构,方便用户进一步办理符合其家庭需求的业务。
在本实施例2的家庭用户识别系统中,背景信息包括业务办理频率、网龄和每用户平均收入信息。
基于运营商的业务办理、业务营销需要,主关键人的背景信息应能反应其消费能力和消费趣向,因此本实施例2的家庭用户识别系统能够判断家庭用户的业务办理、业务使用和业务负担能力,进一步精确识别家庭群组中的主关键人。
在本实施例2的家庭用户识别系统中,家庭用户识别系统还包括角色分类模块,用于在家庭群组获取模块输出家庭群组后,采集家庭群组中家庭成员的终端使用信息,根据终端使用信息及身份信息,将家庭成员进行角色识别并按照辈分分成三个类别,分别为老人类别、父母类别和子女类别。
为了更精确地给家庭群组的家庭用户推广、定制业务,需要对家庭用户的年龄、性别、身份、职业、生活习惯等信息有尽可能精确的把握。本实施例2的家庭用户识别系统通过对家庭成员的终端使用信息和身份信息进行采集和分析,能够精确识别家庭群组中的家庭成员角色,便于家庭用户定制符合自身需求的业务。
在本实施例2的家庭用户识别系统中,终端使用信息包括触点接触频率、终端机型和应用软件使用信息。通过分析家庭用户的触点接触频率以识别其终端使用频率,分析家庭用户的终端机型以识别其年龄,分析家庭用户的应用软件使用信息以识别其兴趣,从而精准识别家庭用户的年龄、性别和角色,实现精准分类。
在本实施例2的家庭用户识别系统中,当类别中存在多个家庭成员时,对该多个家庭成员进行年龄识别,对年长的家庭成员对应变更为老人类别或父母类别。从而避免家庭群组中角色识别错误,提高分类的精确性。
与现有技术相比,本技术方案至少具有如下有益效果:
1、本实施例提供的家庭用户识别方法及系统能够从业务等级最高的核心业务出发,拓展构建家庭群组的家庭用户识别模型,通过业务关键性判定,以此为依据形成群组,融合家庭用户的通话行为、位置进而完成家庭群组的输出;
2、本实施例提供的家庭用户识别方法及系统能够利用了球面位置上的两点通过经纬度计算其曲面距离的算法,基于位置距离识别家庭用户之间的位置关系;
3、本实施例提供的家庭用户识别方法及系统能够对家庭群组的内部结构进行判定,识别家庭主关键人,对家庭用户进行角色分类。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!