一种智能电话应答方法和系统与流程
本发明涉及智能语音应答领域,尤其是一种智能电话应答方法和系统。
背景技术:
在现代社会中,广告推销或骚扰电话越来越多,人们既不想浪费时间接听陌生的推销和骚扰电话,又担心错过重要信息,例如客户电话、银行通知、快递通知和面试邀约等,而且有时因为忙碌无法接听电话时可能会错过重要电话。
针对此情况,目前存在着智能应答类软件来帮助被叫用户接听电话,现有的智能应答类软件中音库作为合成语音应答时的声音来源,音库一般为采用tts合成音库(texttospeech,tts技术能够自动将任意文字实时转换为连续的自然语音)或事先录制的主播音库,来合成智能应答电话助理声音,在为被叫用户代接电话后,使用合成音库或主播音库内的音源合成电话助理的声音与主叫用户进行语音问答交流。
然而,一方面,这两种音库一般都是由智能应答类软件的厂家负责采集和制作而成的标准音库,对于被叫用户而言只能被动从标准音库中选择一种或几种来使用,无法自制音库或对音库进行自定义编辑,交互性和娱乐性差。另一方面,对于普通的tts合成音库而言,声音自然度和流畅度不够高,语气上也生硬,主叫用户能够明显知道是智能应答类软件代接的电话,降低了沟通交流的积极性,影响来电交互体验;由于语音交流体验差,主叫用户可能会质疑该软件的智能程度,导致主叫用户选择结束交流,最终被叫用户并没有得到有效的通话信息,例如目前在各种运营商领域、银行中使用的部分智能语音应答系统一般采用tts合成音库(包括智能电话客服、智能前台等),机器化程度非常明显,语气、声音都略显僵硬;语意的识别精确度不高,不能完整识别语义意图,导致大部分客户无法第一时间呈现需求,容易直接跳过智能客服找人工客服;对于主播音库而言,可以对主播进行多种声音风格的录制,虽然能够保证声音的流畅度、语气表达等,但是对于一些认识被叫被叫用户的主叫用户,有重要的信息通知到对方时,他们希望在电话中直接与被叫用户本人沟通并及时得到回应,而不是通过别人转达的方式。这类产品在代接电话时虽然有较好的听觉体验,但在听到主播声音时,能够轻易分辨出不是被叫被叫用户本人接听电话,从而降低交流沟通意愿,也导致被叫用户无法及时了解主叫用户的重要信息。
技术实现要素:
本发明目的在于针对上述背景技术中存在的问题,提供一种智能电话应答方法和系统,被叫用户可方便地自定义和训练属于本人的用于合成智能应答语音的音库,增强语音应答中被叫用户与系统的交互性和合成音的自然性,可以让主叫用户认为是在与被叫用户本人进行交流,增加通电话的好感度从而顺利告知来电的目的等,防止被叫用户错过重要电话中的信息。
为了达到上述目的,本发明的技术方案有:
一种智能电话应答方法,基于智能应答平台和声音复刻平台,包括如下步骤:
采集被叫用户的声音数据;
将所述声音数据经由所述智能应答平台上传至声音复刻平台,所述声音复刻平台对所述声音信息进行解析和声学模型训练并制成私人音库,被叫用户对所述私人音库具有编辑权限;
所述智能应答平台接收主叫用户的电话呼叫转移信号后,调用所述私人音库形成音频文件,以供与所述主叫用户进行电话语音交互;
所述智能应答平台获取并记录通话过程中的通话信息,以供被叫用户接收。
在本方法中,不同于现有技术中音库都是开发商预设的标准音库,通过私人音库制作步骤,可以由被叫用户本人随时录制属于自己的私人音库,而且录制的声音并非直接用于合成音频文件,而是先利用声音复刻平台对其做解析和声学模型训练,使其在用于合成音频文件的时候更加自然流畅,且贴近真人说话的声音,可以让主叫用户有更好的电话交互体验。在音库的声音数据是被叫用户本人的基础上,被叫用户本人对私人音库还具有编辑的权限,因此被叫用户可以随时对私人音库进行编辑,例如被叫用户还可以根据自己的需要或兴趣爱好,录制多个本人的私人音库,以供选择,适用于不同场合下使用不同的音库;若是被叫用户对录制的私人音库不满意也可以随时将其删除,还可以对其进行命名、做标记等。通过上述操作,作为合成接听电话时音频文件的音库实现方便地由被叫用户自定义,自发进行,音库的种类和数量不再是由开发者来决定,被叫用户与执行的系统之间的交互性更高,增强了整个方法的趣味性和娱乐性。
在此基础上,智能应答平台进行电话语音交互的过程中,通过调用上一步被叫用户自定义的私人音库可以合成十分近似被叫用户本人说话的自然流畅的音频文件,在向主叫用户播放音频文件时,很容易让主叫用户以为是在和被叫用户本人交流,交流意愿较强从而顺利告知来电目的。告知来电目的之后再将来电过程中的通话信息(包括主叫用户身份、来电时间、来电目的、是否需要回电等信息)经过提取之后记录下来供被叫用户在方便的时候查看,这样,就算被叫用户无法或因为任何理由不愿意接电话时,只要采用本发明中的方法来智能接听电话,就不会错过电话中的重要信息。
进一步地,获取并记录通话信息后将所述通话信息以文本信息形式发送至被叫用户的通讯设备上。通过与互联网短信网关或短信中心相连接,可以将信息记录步骤中提取记录下来的通话信息直接以短信的形式发送到被叫用户的通讯设备上,避免被叫用户错过查看通话信息。
进一步地,所述智能应答步骤在被叫用户无法接听电话或主动拒绝接听电话时启动。保证了既不会影响被叫用户正常的电话接听,又可以避免错过电话,尤其是被叫用户主动拒绝接听电话时避免客户直面不想接的电话,更加人性化。
进一步地,所述电话语音交互的过程具体包括:电话通讯线路接通后,先播放采用所述私人音库合成的初始引导音频文件,根据主叫用户的回复实时制定回复内容,根据回复内容调用所述私人音库合成用户电话语音交互的音频文件。接听电话后先播放初始引导音频文件相当于播放开场白,而非让打电话的人先说话,可以掌握对话的主动权,能快速得知主叫用户的来电目的和来电身份,再结合内容后可以帮助迅速判断来电意图,减小自动判断的难度,提高判断准确度。
进一步地,所述私人音库包括两个以上,选择其中一个私人音库合成音频文件。多个私人音库可以为被叫用户提供更多的自定义空间,每次选择一个私人音库可以保证在电话接听时语音风格统一,使得主叫用户在接听电话时听到的语音更加自然和贴近真人。
进一步地,所述私人音库包括默认音库和一个以上备选音库,所述初始引导音频文件调用所述默认音库合成;播放所述初始引导音频文件后,根据主叫用户的回复优先获取主叫用户的个人身份和来电目的,根据所述个人身份和来电目的切换为备选音库调用或继续调用默认音库。在播放初始引导音频文件时,还不清楚主叫用户的身份,因此可以先用默认音库对其进行引导询问,在得知主叫用户的个人身份和来电目的后,根据实际情况来切换备选音库可以达到对语气的修正,灵活性和适应性更强,而且可以使得通话更加自然,与真人接电话的场景近似程度更高。例如,当判断为亲密朋友邀约时,可以调用语气亲昵的备选音库来进行接下来的对话;当判断为客户来电询问公事时,可以切换为严肃正经的备选音库来继续对话。
进一步地,标记每个所述备选音库,所述标记信息包括本备选音库适合使用的主叫用户个人身份和来电目的;获取主叫用户的个人身份和来电目的,分别与每个所述备选音库的标记进行比对,判断存在备选音库标记中的个人身份与来电目的与主叫用户一致时,将当前调用的默认音库切换至该备选音库;否则继续调用当前默认音库。备选音库被标记之后,在调用时更加方便,减小系统自动调用到不合适的音库。而且被叫用户也可以根据自己的喜好来设置采用何种音库去面对不同身份的主叫用户,个性化强烈。
进一步地,还包括电话号码识别和标记步骤:所述智能应答平台在电话通讯线路接通之前,先识别来电号码,若来电号码为被叫用户的通讯录中已存号码,判断主叫用户的个人身份后选择调用与之匹配的备选音库;若为陌生号码则调用默认音库。事先通过号码就可以初步判断来电者的个人身份,避免播放引导音频文件时的生疏,一接通电话就可以给来电者熟悉感,从而顺利告知来电目的,不会错过来电信息。
进一步地,所述个人身份包括:亲友、工作领导和同事、无标记陌生人、广告推销者、标记骚扰电话和其它身份;所述来电目的包括:私人问题、工作问题、广告推销、骚扰和其它问题。这些个人身份可以预设入系统中,便于被叫用户在设置备选音库的标记时直接选用即可,避免出现完全自定义时词语过多,智能应答平台无法判断的情况。
进一步地,所述私人音库包括语气语调不同的下述音库中的一种或任意组合:亲友私事应答音库、领导同事公事应答音库、无标记陌生来电音库和推销骚扰应对音库。每种音库的语气语调不相同便于以不同的声音形象来面对主叫用户,例如亲友私事应答音库可以是亲昵轻松的,领导同事公事应答音库是严肃认真的、无标记陌生来电音库是平淡无明显感情的、推销骚扰应对音库是不耐烦的等等,这几种音库足以应对日常生活来电的绝大部分场合。
本发明还提供一种智能电话应答系统,包括:
被叫用户前端:所述被叫用户前端用于录制采集被叫用户的声音数据,并将录制的声音上传至智能应答平台;
声音复刻平台:所述声音复刻平台用于将被叫用户前端上传的声音通过声音复刻技术进行解析和声学模型训练制成并储存为可编辑的私人音库;
智能应答平台:所述智能应答平台用于在接收主叫用户的呼叫转移信号后,根据主叫用户的意图实时制定回复文本,调用所述私人音库合成回复文本的音频文件后向主叫用户播放,与主叫用户进行电话语音交互;还用于获取和记录通话过程中的通话信息供被叫用户查看;
通信运营系统:所述通信系统用于为所述被叫用户前端和智能应答平台提供电话和短信通信服务。
本系统在被叫用户前端就可以由被叫用户自由地自己录制本人的声音作为音库,相较于现有技术中开发商在后台提供的音库而言,被叫用户在前端即可参与和实现相当于原本后台功能的操作。再结合智能应答平台对被叫用户前端的功能支持,实现了私人音库的可编辑,自定义化的程度更高,使得本发明中的智能应答平台比现有的类似平台被叫用户交互性更高,娱乐性更高,更加对被叫用户友好。此外,在使用的音库方面,本发明中的音库是声音复刻平台在被叫用户录制的音库的基础上进行解析和声学模型训练后形成的私人音库,对音库进行了首次加工处理,因此后期在合成音频文件的时候,可以比直接采用原始采集声音合成的音频文件自然度和流畅度更高,使得合成的话语更加贴近真人说话,达到使主叫用户以为是被叫用户真人接电话的效果。通信运营系统负责通信服务,保证系统可以接进现有的通信网络内,实现包括打电话和发短信等一般的电信服务。
进一步地,所述智能应答平台包括:
语义识别模块:所述语义识别模块用于识别主叫用户语音中的语义,并将语义实时转写为文本内容;
应答模块:所述应答模块用于根据语义识别模块识别出的语义来实时制定回复内容,所述回复内容为文本形式;
语音合成模块:所述语音合成模块用于将所述实时回复内容通过调用所述私人音库合成向主叫用户播放的音频文件。
在智能应答平台中经过这几个模块的协同作用,可以实现本人私人音库的制作、主叫用户语义的正确识别、根据主叫用户的语义进行实时回复应答、回复内容的语音合成功能。
进一步地,所述被叫用户前端为可通话的移动智能终端,通过所述智能终端上的app、小程序、公众号或h5页面录制本人说话的声音。可通话的移动智能终端与被叫用户的关系紧密,一般被被叫用户随身携带,因此适合被叫用户随时进行声音的录制,便捷程度高,无需使用计算机和专用的设备来进行录音,对硬件要求较低,对于被叫用户而言触手可及,更加愿意使用整套系统。
附图说明
图1为本发明的一种智能电话应答方法的流程框图;
图2为本发明的一种智能电话应答系统的结构框图;
图3为本发明的一种应用所述智能电话应答系统的方法的示意图;
图4为本发明的一种智能电话应答系统中nlp服务的结构图;
图5为为本发明的一种智能电话应答系统的产品结构图。
具体实施方式
结合附图说明对本发明的一种智能电话应答方法和系统进行详细的描述,以对本发明的保护范围进行解释和说明。
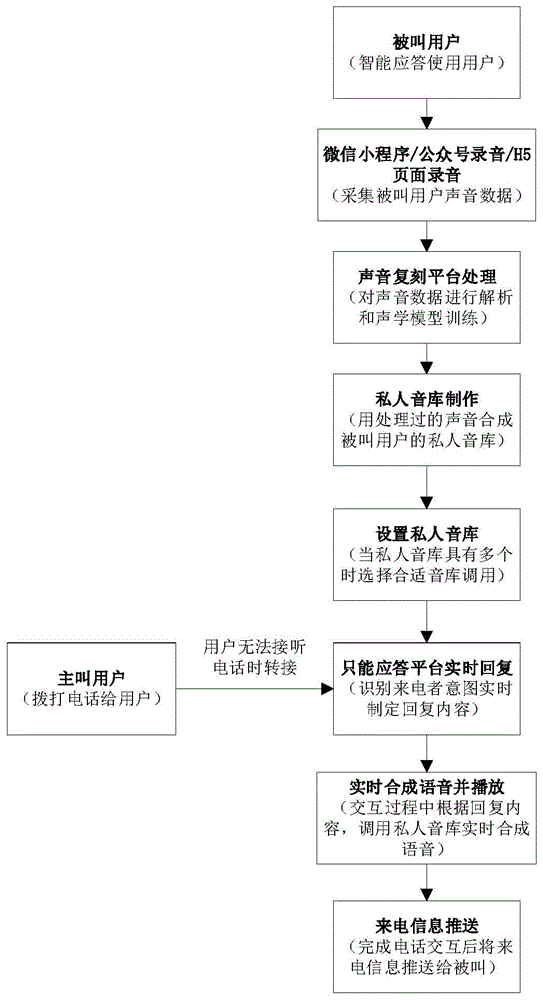
如图1所示为本发明的一种智能电话应答方法,其基于智能应答平台和声音复刻平台,包括如下步骤:
采集被叫用户的声音数据;将所述声音数据经由所述智能应答平台上传至声音复刻平台,所述声音复刻平台对所述声音信息进行解析和声学模型训练并制成私人音库,被叫用户对所述私人音库具有编辑权限。
不同于现有技术中音库都是开发商预设的标准音库,通过私人音库制作步骤,可以由被叫用户本人随时录制属于自己的私人音库,而且录制的声音并非直接用于合成音频文件,而是先对其做解析和声学模型训练,使其在用于合成音频文件的时候更加自然流畅,而且在解析训练的过程中还可以对其进行降噪处理,使采集到的被叫用户声音样本中含有的环境杂音等去除,合成后的语音质量更高,且贴近真人说话的声音,可以让主叫用户有更好的电话交互体验。在音库的声音数据是被叫用户本人的基础上,被叫用户本人对私人音库还具有编辑的权限,因此被叫用户可以随时对私人音库进行编辑,例如被叫用户还可以根据自己的需要或兴趣爱好,录制多个本人的私人音库,以供选择,适用于不同场合下使用不同的音库;若是被叫用户对录制的私人音库不满意也可以随时将其删除,还可以对其进行命名、做标记等。通过上述操作,作为合成接听电话时音频文件的音库实现方便地由被叫用户自定义,自发进行,音库的种类和数量不再是由开发者来决定,被叫用户与执行的系统之间的交互性更高,增强了整个方法的趣味性和娱乐性。作为私人音库的优选实施方案,所述私人音库包括两个以上,选择其中一个私人音库合成音频文件。多个私人音库可以为被叫用户提供更多的自定义空间,每次选择一个私人音库可以保证在电话接听时语音风格统一,使得主叫用户在接听电话时听到的语音更加自然和贴近真人。
作为私人音库制作步骤的优选实施方式,被叫用户在可通话的移动智能终端,通过所述智能终端上的app、小程序、公众号或h5页面录制本人说话的声音,根据要求录制小篇文章或语句,录制完成后再通过声音复刻技术进行解析和声学训练模型。
所述智能应答平台接收主叫用户的电话呼叫转移信号后,调用所述私人音库形成音频文件,以供与所述主叫用户进行电话语音交互;在私人音库制作步骤的基础上,本步骤通过调用上一步被叫用户自定义的私人音库可以合成十分近似被叫用户本人说话的自然流畅的音频文件,在向主叫用户播放音频文件时,很容易让主叫用户以为是在和被叫用户本人交流,交流意愿较强从而顺利告知来电目的。
具体地,所述电话语音交互的过程具体包括:电话通讯线路接通后,先播放采用所述私人音库合成的初始引导音频文件,根据主叫用户的回复实时制定回复内容,根据回复内容调用所述私人音库合成用户电话语音交互的音频文件。接听电话后先播放初始引导音频文件相当于播放开场白,而非让打电话的人先说话,可以掌握对话的主动权,能快速得知主叫用户的来电目的和来电身份,再结合内容后可以帮助迅速判断来电意图,减小自动判断的难度,提高判断准确度。
上述方案还具有一个优选实施方式,所述私人音库包括默认音库和一个以上备选音库,所述初始引导音频文件调用所述默认音库合成;播放所述初始引导音频文件后,根据主叫用户的回复优先获取主叫用户的个人身份和来电目的,根据所述个人身份和来电目的切换为备选音库调用或继续调用默认音库。在播放初始引导音频文件时,还不清楚主叫用户的身份,因此可以先用默认音库对其进行引导询问,在得知主叫用户的个人身份和来电目的后,根据实际情况来切换备选音库可以达到对语气的修正,灵活性和适应性更强,而且可以使得通话更加自然,与真人接电话的场景近似程度更高。例如,当判断为亲密朋友邀约时,可以调用语气亲昵的备选音库来进行接下来的对话;当判断为客户来电询问公事时,可以切换为严肃正经的备选音库来继续对话。
更加优选地,标记每个所述备选音库,所述标记信息包括本备选音库适合使用的主叫用户个人身份和来电目的;获取主叫用户的个人身份和来电目的,分别与每个所述备选音库的标记进行比对,判断存在备选音库标记中的个人身份与来电目的与主叫用户一致时,将当前调用的默认音库切换至该备选音库;否则继续调用当前默认音库。备选音库被标记之后,在调用时更加方便,减小系统自动调用到不合适的音库。而且被叫用户也可以根据自己的喜好来设置采用何种音库去面对不同身份的主叫用户,个性化强烈。
在智能选择私人音库方面,为了更好地增强接听时的真人类似度,本实施例还提供一种实施方式:所述智能应答平台在电话通讯线路接通之前,先识别来电号码,若来电号码为被叫用户的通讯录中已存号码,判断主叫用户的个人身份后选择调用与之匹配的备选音库;若为陌生号码则调用默认音库。事先通过号码就可以初步判断来电者的个人身份,避免播放引导音频文件时的生疏,一接通电话就可以给来电者熟悉感,从而顺利告知来电目的,不会错过来电信息。
在以上实施方式中提到的个人身份包括:亲友、工作领导和同事、无标记陌生人、广告推销者、标记骚扰电话和其它身份;所述来电目的包括:私人问题、工作问题、广告推销、骚扰和其它问题。这些个人身份可以预设入系统中,便于被叫用户在设置备选音库的标记时直接选用即可,避免出现完全自定义时词语过多,智能应答平台无法判断的情况。
与个人身份和来电目的匹配地,所述私人音库包括语气语调不同的下述音库中的一种或任意组合:亲友私事应答音库、领导同事公事应答音库、无标记陌生来电音库和推销骚扰应对音库。每种音库的语气语调不相同便于以不同的声音形象来面对主叫用户,例如亲友私事应答音库可以是亲昵轻松的,领导同事公事应答音库是严肃认真的、无标记陌生来电音库是平淡无明显感情的、推销骚扰应对音库是不耐烦的等等,这几种音库足以应对日常生活来电的绝大部分场合。
在通话完成或通话过程中,所述智能应答平台获取并记录通话过程中的通话信息,以供被叫用户接收。告知来电目的之后再将来电过程中的通话信息(包括主叫用户身份、来电时间、来电目的、是否需要回电等信息)经过提取之后记录下来供被叫用户在方便的时候查看,通过这种方式,就算被叫用户无法或因为任何理由不愿意接电话时,只要采用本发明中的方法来智能接听电话,就不会错过电话中的重要信息。在本实施例中,优选智能应答步骤在被叫用户无法接听电话或主动拒绝接听电话时启动。保证了既不会影响被叫用户正常的电话接听,又可以避免错过电话,尤其是被叫用户主动拒绝接听电话时避免客户直面不想接的电话,更加人性化。
在信息记录步骤的基础上,为了更好地避免被叫用户错过通话信息,在所述信息记录步骤后还包括短信推送步骤,所述短信推送步骤包括:以长连接的方式与移动短信平台的互联网短信网关或短信中心相连接,遵循运营商的cmpp协议,将所述通话信息以短信的形式发送至被叫用户的通讯设备上。通过与互联网短信网关或短信中心相连接,可以将信息记录步骤中提取记录下来的通话信息直接以短信的形式发送到被叫用户的通讯设备上,避免被叫用户错过查看通话信息。
本发明还提供一种智能电话应答系统,如附图2所示为本系统的结构框图,如图3所示为本系统应用上述只能电话应答方法的示意图。
本实施例中的智能电话应答系统包括:
被叫用户前端:所述被叫用户前端用于录制采集被叫用户的声音数据,并将录制的声音上传至智能应答平台;所述被叫用户前端优选为可通话的移动智能终端(例如智能手机),通过所述智能终端上的app、小程序(现在各大平台提供的小程序,例如微信、支付宝等)、公众号或h5页面录制本人说话的声音。可通话的移动智能终端与被叫用户的关系紧密,一般被被叫用户随身携带,因此适合被叫用户随时进行声音的录制,便捷程度高,无需使用计算机和专用的设备来进行录音,对硬件要求较低,对于被叫用户而言触手可及,更加愿意使用整套系统。
声音复刻平台:所述声音复刻平台用于将被叫用户前端上传的声音通过声音复刻技术进行解析和声学模型训练制成并储存为可编辑的私人音库;声音复刻平台采用现有的声音复刻技术(也称个性化声音合成技术),对采集的原始声音数据进行解析和声学模型训练,通过此技术形成的私人音库,用于合成音频时声音语气语调等更加自然、逼真,更加贴近真人。此外,还可包括对声音进行降噪处理,识别并去除环境声处理,将单个词语分解出来的语音语气自然化处理等等功能,可以采用现有技术中的人工智能技术来实现。在这一步对被叫用户录制的声音做处理主要考虑到被叫用户没有开发商在录制标准音库时的专业条件,例如专业的录音棚、麦克风,经过专业训练的主播,在生活场景下录制时很容易受到环境影响,使得录制的原始声音中带有环境音较为嘈杂,或语气语调不连贯等,经过声音复刻平台处理后的声音可以达到较高的水准,便于后期合成音频文件。此外在实际使用中,声音复刻平台的音库编辑功能是呈现在被叫用户的移动智能终端的操作页面中的,方便被叫用户对其进行编辑。
智能应答平台:所述智能应答平台用于在接收主叫用户的呼叫转移信号后,根据主叫用户的意图实时制定回复文本,调用所述私人音库合成回复文本的音频文件后向主叫用户播放,与主叫用户进行电话语音交互;还用于获取和记录通话过程中的通话信息供被叫用户查看;在现有技术中已经有了智能应答平台技术存在,用于自动接听电话等功能,可以采用现有的智能应答平台,在其基础上与声音复刻平台的接口相连,实现数据的调用。
通信运营系统:所述通信系统用于为所述被叫用户前端和智能应答平台提供电话和短信通信服务。
本系统在被叫用户前端就可以由被叫用户自由地自己录制本人的声音作为音库,相较于现有技术中开发商在后台提供的音库而言,被叫用户在前端即可参与和实现相当于原本后台功能的操作。再结合智能应答平台对被叫用户前端的功能支持,实现了私人音库的可编辑,自定义化的程度更高,使得本发明中的智能应答平台比现有的类似平台被叫用户交互性更高,娱乐性更高,更加对被叫用户友好。此外,在使用的音库方面,本发明中的音库是在被叫用户录制的音库的基础上进行解析和声学模型训练后形成的私人音库,对音库进行了首次加工处理,因此后期在合成音频文件的时候,可以比直接采用原始采集声音合成的音频文件自然度和流畅度更高,使得合成的话语更加贴近真人说话,达到使主叫用户以为是被叫用户真人接电话的效果。通信运营系统负责通信服务,保证系统可以接进现有的通信网络内,实现包括打电话和发短信等一般的电信服务。
作为智能应答平台的优选方案,本方案中的所述智能应答平台包括以下模块,在智能应答平台中经过这几个模块的协同作用,可以实现本人私人音库的制作、主叫用户语义的正确识别、根据主叫用户的语义进行实时回复应答、回复内容的语音合成功能。
语义识别模块:所述语义识别模块用于识别主叫用户语音中的语义,并将语义实时转写为文本内容;在本方案中,优选采用asr技术来作为语义识别模块,asr(automaticspeechrecognition)语音识别技术:就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。asr技术的引擎包含语音识别和语音转写两个部分;语音识别提供关键字语音识别和连续语音识别,具备前端语音处理和后端识别处理,支持端点检测、噪音消除、智能打断、后端语音识别等功能,即在电话交互的过程中,可以识别被叫用户开始说话、话语间的停顿、说话结束等,以及在平台播音的过程中,被叫用户可以打断平台播音等。语音转写能够把被叫用户说的任意语音转换成对应的文字信息,在电话交互过程中,将被叫用户的语音进行实时转写成文本内容。
应答模块:所述应答模块用于根据语义识别模块识别出的语义来实时制定回复内容,所述回复内容为文本形式;在本方案中,优选采用nlp服务来实现应答模块的功能,如图4所示为nlp服务的结构图,nlp(naturallanguageprocessing)是人工智能(ai)的一个子领域。智能nlp服务提供轻量级、方便易用http协议开发接口,基于该接口可以便捷调用相关资源,快速完成各种智能语音交互的开发工作以实现智能来电助手业务。
其中,nlp应用的技术及算法包括:文本分类,语义相似度,实体识别,词槽提取;实体消歧,词义消歧;句法分析,词性标注,角色标注;智能nlp特点:引入语义理解平台进行语料前置解析,再到业务语料处理平台进行二次解析;拥有大量通用实体和辅助词资源,帮助机器进行分词、词法、语法分析,可快速扩展多种应用场景,同时支持运营自建技能和实体。智能应答平台中使用的智能nlp模块,能够预先配置场景、意图的相关语料,根据主叫用户的对话文本,进行语义理解,识别被叫用户对话的意图,并将意图提交给平台业务软件进行处理。
语音合成模块:所述语音合成模块用于将实时回复内容从所述私人音库中选取对应的声音文件合成向主叫用户播放的音频文件(tts)。在本方案中,优选采用tts技术来实现语音合成模块的功能,tts(texttospeech)技术能够自动将任意文字实时转换为连续的自然语音,是一种能够在任何时间、任何地点,向任何人提供语音信息服务的高效便捷手段,非常符合信息时代海量数据、动态更新和个性化查询的需求。在智能应答系统中,平台通过调用私人音库,再使用tts引擎进行音频合成,在合成的过程中,可对私人音库进行调优,比如:被叫用户声音风格调优,可以对被叫用户声音风格进行调整,比如严肃的、幽默的、轻快的、低沉的等等;说话语调调优,根据文本语句特点调整说话的语调,如陈述语句、疑问句等;语速调优,根据话术文本的长度,调整语速。
此外,在智能电话应答系统与通信运营系统之间的功能接口有以下几类:智能应答业务被叫用户开户、智能应答业务销户、智能应答业务套餐更改、智能应答被叫用户在网状态等数据更改。智能应答业务通过一级boss系统进行开户、退订和更改套餐等业务操作,被叫用户数据和业务数据以boss系统为基准;智能应答业务平台与一级boss系统采用基于tcp的boss接口协议进行业务数据的传送和交互。
智能电话应答系统的短信网关接口的实现,是短信网关以长连接的方式与移动短信平台的ismg(互联网短信网关)或smsc(短信中心)相连接,遵循运营商的cmpp协议,完成向被叫用户推送下行短信,或接收被叫用户发送的上行短信业务需求。智能应答业务系统的短信网关与ismg或smsc连接后就可以做短信提交、查询短信发送状态、删除短信等的操作,并可以接受ismg发送来的短信。上行短信功能包括被叫用户开户、密码修改、业务查询指令等;下行短信功能包括:业务通知发送,留言通知,查询结果功能等。
除上述的模块之外,本系统还有一些其它模块为功能的实现做辅助,例如前置机和语音播报资源。前置机是被叫用户ivr接入方式的智能ip-pbx设备,采用ip方式的话路接入。前置机话路与信令接入采用ip方式与移动核心网络cs域的ce设备链接。前置机的后端话路控制、录放音等网络汇聚接入系统的骨干核心网络。在智能电话应答系统代接电话过程中,语音播报资源将平台合成的音频文件进行播放,实现对话交互过程。
如图5所示为本智能电话应答系统的产品结构,其中:
能力层:主要是智能应答平台所使用到的底层技术能力,主要包括语音识别、语义理解、音频录制、声音采集、声学模型训练、tts合成等;
应用层:主要是根据底层核心技术能力封装形成的应用模块,主要有来电场景识别,对话交互、录音、语音合成、语速语调设置、语句停顿设置等;
功能层:主要是产品展示给被叫用户的每个使用功能,包括智能代接、来电意图、个性化私人音库、语音转文字、号码标记等。
根据上述说明书的揭示和教导,本发明所属领域的技术人员还可以对上述实施方式进行变更和修改。因此,本发明并不局限于上面揭示和描述的具体实施方式,对本发明的一些修改和变更也应当落入本发明的权利要求的保护范围内。此外,尽管本说明书中使用了一些特定的术语,但这些术语只是为了方便说明,并不对本发明构成任何限制。
- 还没有人留言评论。精彩留言会获得点赞!