基于从局部到全局的视频时序片段提取方法与流程
技术领域:
本发明属于计算机科学人工智能领域,具体涉及一种基于从局部到全局的视频时序片段提取方法,用于从短视频中提取精彩行为时序片段。
背景技术:
:
时序片段提名生成是视频分析的一个重要的组成部分,其目的是在未经剪辑的视频中精确的定位行为动作发生的时间片段,生成的时序片段的好坏对下一步基于提名的动作检测有很大影响。如何生成具有精确时序边界的片段是时序片段提名生成的一个关键问题。
时序片段提名生成方法大致分为以下三种:第一种是基于滑动窗口的方法,具体来说,首先预定义大量不同尺度的候选框,然后根据候选框中是否有行为发生来给候选框打分并根据得分排序。但这种方法存在的缺陷是候选框全都是预先设定好的尺度,框中可能包含大量冗余的噪声,导致时序边界不够精确。第二种是基于行为得分的方法,具体来说,这类方法首先给每一个时间点上的视频打一个行为性得分(即是否有行为发生),然后用设定阈值的方法将得分大于阈值的聚合起来,形成提名片段。但这种方法的不足是提名片段的质量严重依赖于聚合的策略。第三种是基于边界点检测的方法,具体来说,这种方法首先预测时间点上每一帧视频的行为性概率,开始概率以及结束概率,然后用概率大的开始点,结束点来构成提名片段。但这种方法的不足是仅关注局部而缺少了全局的时序信息。
技术实现要素:
:
为了解决现有方法中没有充分利用全局信息,仅仅关注局部信息来进行建模的不足以及行为片段包含大量冗余背景的不足,本发明提出一种基于从局部到全局的视频时序片段提取方法,其技术方案如下:
一种基于从局部到全局的视频时序片段提取方法,包括如下具体步骤:
1)特征提取:按如下方法从给定的视频帧中提取特征向量f,该方法包括:
首先用tvl1法提取给定视频帧的光流,再采用双流网络按视频帧的时序来分别对每一对图片和光流进行建模,聚合形成特征向量f’,然后将所有聚合形成特征向量f’沿着时序维度堆叠形成特征向量f;
2)编码:对特征向量f,依次使用时序卷积网络、双向循环神经网络以及注意力机制进行编码,其具体步骤如下:
2.1)使用时序卷积网络对特征向量f进行局部信息建模:
首先将步骤1)提取的特征向量f作为输入,使用时序卷积来捕获局部信息,即将特征向量f输入到2层步长为1,卷积核大小为3的一维卷积,该过程可按如下公式表示:
femb1=(wemb1*f+bemb1)
femb2=(wemb2*femb1+bemb2)
式中,femb1表示特征向量f经过第一层时序卷积生成的特征向量;femb2表示经过第二层时序卷积生成的特征向量;wemb1表示第一层卷积核的权重参数;bemb1表示第一层卷积核的偏置参数;wemb2表示第二层卷积核的权重参数;bemb2表示第二层卷积核的偏置参数;*表示卷积运算;
然后通过加和操作来融合femb1和femb2,得到融合后的特征向量fcomp:
fcomp=femb1+femb2;
2.2)使用双向循环神经网络对融合后的特征向量fcomp进行全局信息建模,所述双向循环神经网络为bilstm神经网络,其中,bilstm神经网络由两个lstm神经网络组成,单个lstm神经网络的全局特征的编码过程如下:
it=σ(wxixt+whiht-1+bi)
ft=σ(wxfxt+whfht-1+bf)
ot=σ(wxoxt+whoht-1+bo)
gt=tanh(wxgxt+whght-1+bg)
ct=ft⊙ct-1+it⊙gt
ht=ot⊙tanh(ct)
式中,t表示时间点,it,ft,ot分别表示t时间点的单个lstm的输入门、遗忘门和输出门;ct表示t时间点的新的细胞信息;ct-1表示t-1时间点的旧的细胞信息;xt表示在t时间点的输入特征向量;ht表示t时间点的隐状态,⊙表示点乘运算;wxi和bi分别表示输入门的权重矩阵与偏置矩阵;wxf和bf分别表示遗忘门的权重矩阵与偏置矩阵;wxo和bo分别表示输出门的权重矩阵与偏置矩阵;wxg和bg分别表示候选细胞信息的权重矩阵与偏置矩阵;
2.3)使用注意力机制来引导模型的学习过程,使其更关注行为而非背景噪声,即采用多层感知机以及非线性映射,使在增加时序上运动行为的权重的同时抑制嘈杂背景的权重,该过程可按如下公式表示:
st=tanh(wqs(h'twhq+bq)+bs)
式中,st表示多层感知机的输出,st,i表示多层感知机的输出st的第i维,i的取值范围为[1,d],d表示多层感知机的输出st的维度数;wqs和bq分别表示模型中第一层线性层的权重矩阵与偏置矩阵;whq和bs分别表示模型中第二层线性层的权重矩阵与偏置矩阵;αt,i表示st中第i维度上的权重;
再通过给每个时间点分配权重来形成编码后的特征向量s't,该过程可按如下公式表示:
s't=∑iαt,ist,i;
3)提名特征预测:基于编码后的特征向量s't,采用卷积网络的方法生成表示s't每个时间点包含行为的概率、行为开始的概率和行为结束的概率,并用设定阈值的方法将概率值大的时间点聚合形成提名片段,并基于形成的提名片段生成提名特征;
4)评估:对步骤3)中的提名特征用全连接网络进行置信度得分预测,再采用非极大值抑制方法筛除冗余片段,得到时序片段组。
优选地,步骤2.2)中所述bilstm循环神经网络通过前向与后向的方法来使网络学习到整个时间点上从过去到未来的全局的特征向量,该过程可按如下公式表示:
其中,h't表示前向与后向lstm生成的特征向量特征向量的聚合;
优选地,步骤2.3)中所述注意力机制采用attn注意力机制。
本发明相比于现有技术具有如下有益效果
本发明的基于从局部到全局的视频时序片段提取方法,使模型能够在学习的过程中既关注到视频的局部信息,又关注到视频的全局信息,同时能够更关注到行为本身而非背景,从而准确的提取出视频中行为发生的片段。
附图说明:
图1为本方法的流程图;
图2为双向循环神经网络的结构图;
图3为注意力机制结构图;
图4为在行为检测数据集thumos14上本发明方法的可视化结果图。
具体实施方式:
下面结合具体实施例及对应附图对本发明作进一步说明。
实施例一:
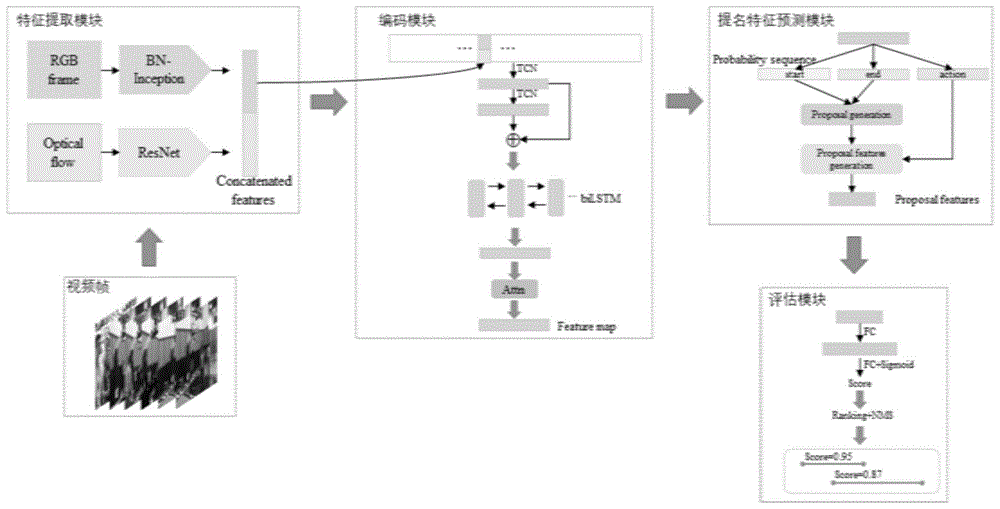
本实施例采用本发明提出的基于从局部到全局的视频时序片段提取方法,本发明所采用的基于局部到全局的视频时序片段提取系统,包括特征提取模块、编码模块、提名特征预测模块和评估模块组成。
如图1所示,本发明方法包括如下具体步骤:
1)首先使用特征提取模块提取给定视频帧中时间点上每一个时间点的视觉语义时空特征。特征提取模块主要采用视频领域广泛使用的双流网络,即用两个分支来分别建模静态的表观信息与动态的运动信息,两个分支的输入分别为图片和光流。具体过程为:首先用tvl1法提取给定的视频帧的光流,再采用双流网络按视频帧的时序来分别对每一对图片和光流进行建模,聚合形成特征向量f’,然后将所有聚合形成特征向量f’沿着时序维度堆叠形成特征向量f;
2)特征向量f经过编码模块生成更加关注全局信息以及行为运动本身的特征向量,即对提取的特征向量f,依次使用时序卷积网络、双向循环神经网络以及注意力机制进行编码,其具体步骤如下:
2.1)首先使用时序卷积网络(tcn)来捕获局部细节,在本方法的实现中,时序卷积网络主要采用2次时序上的一维卷积,步长为1,卷积核大小为3,此处我们不做时序上的下采样因为时序信息对于行为运动的定位非常重要,过早地下采样容易丢失时序上行为运动的发生关系,该过程可按如下公式表示:
femb1=(wemb1*f+bemb1)
femb2=(wemb2*femb1+bemb2)
式中,femb1表示特征向量f经过第一层时序卷积生成的特征向量;femb2表示经过第二层时序卷积生成的特征向量;wemb1表示第一层卷积核的权重参数;bemb1表示第一层卷积核的偏置参数;wemb2表示第二层卷积核的权重参数;bemb2表示第二层卷积核的偏置参数;*表示卷积运算;
然后通过加和操作来融合femb1和femb2,得到融合后的特征向量fcomp:
fcomp=femb1+femb2;
2.2)接下来使用双向循环神经网络来捕获全局信息,即使用双向循环神经网络对融合后的特征向量fcomp进行全局信息建模,所述双向循环神经网络为bilstm神经网络,具体的结构图如图2所示,该神经网络主要采用2个循环神经网络(lstm神经网络),通过前向与后向的方法来使我们的网络学习到整个时间点上从过去到未来,全局的特征描述,该过程可按如下公式表示:
其中,单个lstm神经网络的全局特征的编码过程如下:
it=σ(wxixt+whiht-1+bi)
ft=σ(wxfxt+whfht-1+bf)
ot=σ(wxoxt+whoht-1+bo)
gt=tanh(wxgxt+whght-1+bg)
ct=ft⊙ct-1+it⊙gt
ht=ot⊙tanh(ct)
式中,t表示时间点,it,ft,ot分别表示t时间点单个lstm的输入门、遗忘门和输出门;ct表示t时间点的新的细胞信息;ct-1表示t-1时间点的旧的细胞信息;xt表示在t时间点的输入特征向量;ht表示t时间点的隐状态,⊙表示点乘运算;wxi和bi分别表示输入门的权重矩阵与偏置矩阵;wxf和bf分别表示遗忘门的权重矩阵与偏置矩阵;wxo和bo分别表示输出门的权重矩阵与偏置矩阵;wxg和bg分别表示候选细胞信息的权重矩阵与偏置矩阵;
2.3)最后,为了使特征学习更加关注运动信息本身而不是冗余嘈杂的背景,使用注意力机制来引导模型的学习过程,本实施例注意力机制采用attn注意力机制,该注意力模型的结构图如图3所示,图3表示注意力机制所做的非线性特征变换。在本方法的实现中主要采用非线性映射,使增加时序上运动行为的权重的同时抑制嘈杂背景的权重,该过程可按如下公式表示:
st=tanh(wqs(h'twhq+bq)+bs)
式中,st表示多层感知机的输出,st,i表示多层感知机的输出st的第i维,i的取值范围为[1,d],d表示多层感知机的输出st的维度数;wqs和bq分别表示模型中第一层线性层的权重矩阵与偏置矩阵;whq和bs分别表示模型中第二层线性层的权重矩阵与偏置矩阵;αt,i表示st中第i维度上的权重;
再通过给每个时间点分配权重来形成编码后的特征向量s't,该特征向量s't更关注行为本身,该过程可按如下公式表示:
s't=∑iαt,ist,i;
3)编码后的特征向量s't经过提名特征预测模块生成预测的行为片段特征描述。具体来说,首先使用卷积网络分别生成时序上每个时间点包含行为的概率p(a)、行为开始的概率p(s)和行为结束的概率p(e)。然后通过设定阈值的方法筛选出概率大的时间点,组成提名片段,即候选时序片段,并在此基础上用插值的方法提取出提名特征。
4)候选时序片段的提名特征经过评估模块生成候选时序片段的置信度得分。具体来说,主要使用全连接神经网络以及sigmoid激活函数,sigmoid输出的得分越高,表示真实标签与预测的时序片段重叠的越好。然后使用目标检测中常用的非极大值抑制方法筛除冗余的片段,得到最终的时序片段组。
应用实施例一:
本应用实施例采用实施例一中的基于从局部到全局的视频时序片段提取方法,将其应用到时序片段生成领域著名的数据集thumos14和activitynet-1.3上验证其有效性。实验结果如表1,表2所示,thumos14上结果可视化如图4所示。
如下表1所示,结合评价指标ar@an的含义可知,本方法在时序片段生成数据集thumos14上效果显著,尤其是ar@50,ar@100,ar@200,和最开始的方法,使用双流网络提取特征能取得最好的结果,分别从13.56,23.83,33.96提升到39.96,48,66,54.73,充分验证了本发明的方法能够在建模局部细节的同时更关注到全局信息,能够在面对冗余嘈杂背景的情境下自动关注行为运动本身。
表1时序片段提取在thumos14数据集上的结果表
如下表2所示,结合评价指标ar@an和auc的含义可知,本方法不仅在小数据集thumos14上效果显著,将其应用到大规模数据集activitynet-1.3上依然有不错的性能提升,与最近的方法相比,ar@an从74.16提升到75.80,auc从66.17提升到67.48。activitynet-1.3中的视频不仅长短不一,场景变换也十分复杂,对于精确定位行为片段十分具有挑战性,性能上的提升,充分验证了本方法在复杂场景下的有效性。
如图4所示,图4中groundtruth表示视频中行为片段的真实发生以及结束持续时间,proposals表示本方法预测的行为片段的发生以及结束持续时间,从图4中可以发现,尽管行为发生的时间段有长有短,我们的预测和groundtruth相比误差仍然在1s以内,充分验证了本发明方法的有效性,即生成的时序片段几乎能完全覆盖真实标签。
表2时序片段提取在activitynet-1.3数据集上的结果表
提供以上实施方式仅仅为了描述本发明的目的,而非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理做出的何种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!