下行接收数据的处理方法及装置、存储介质、终端与流程
1.本发明涉及通信技术领域,尤其涉及一种下行接收数据的处理方法及装置、存储介质、终端。
背景技术:
2.在通信系统中,1个传输块(transport block,简称tb)可以划分为c个码块(code block,简称cb),如新空口(new radio,简称nr)系统中1个tb最多可以划分为152个cb。在用户设备(user equipment,简称ue)端,若tb内的所有cb解码正确,则上报发送确认ack;若有任意一个cb解错,则上报发送失败nack。在基站端,若基站接收到的是ack信息,该混合自动重传请求(hybrid automatic repeat request,简称harq)进程发送新的数据;若基站接收到的是nack信息,该harq进程重传。因此ue端若有任意一个cb解码错误,基站都需要重传。
3.传统传输中,终端顺序接收处理一个tb内的各个cb,在部分场景,比如一些衰落信道下,终端接收的信号质量较差,多个cb都出现译码器多次迭代都无法解码正确的现象,浪费终端功耗。
4.由此,亟需一种下行接收数据的处理方法,使得终端能够根据接收的信号节省解码资源,以节省终端功耗。
技术实现要素:
5.本发明解决的技术问题是如何提供一种下行接收数据的处理方法,使得终端能够根据接收的信号节省解码资源,以节省终端功耗。
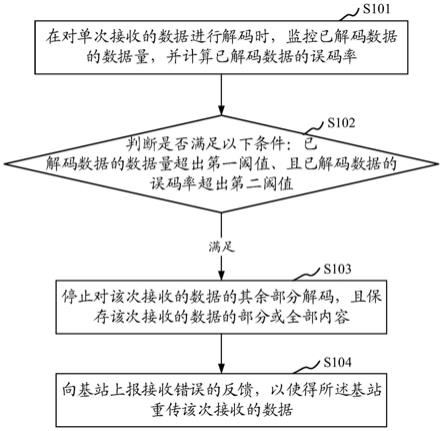
6.为解决上述问题,本发明实施例提供了一种下行接收数据的处理方法,所述方法包括:在对单次接收的数据进行解码时,监控已解码数据的数据量,并计算已解码数据的误码率;判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的误码率超出第二阈值;如果判断结果为满足,则停止对该次接收的数据的其余部分解码,且保存该次接收的数据的部分或全部内容;向基站上报接收错误的反馈,以使得所述基站重传该次接收的数据。
7.可选的,所述数据量包括若干个码块和/或码块组。
8.可选的,所述保存该次接收的数据的部分或全部内容,包括:保存该次接收的数据中未解码的码块/码块组。
9.可选的,所述保存该次接收的数据的部分或全部内容,包括:将该次接收的数据的部分或全部内容存入harq缓存区。
10.可选的,所述停止对该次接收的数据的其余部分解码,包括:将该次接收的数据的其余部分绕过译码器或译码模块。
11.可选的,所述向基站上报接收错误的反馈之后,还包括:接收所述基站重传的数据,根据重传的数据和保存的内容进行再次解码。
12.可选的,所述判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解
码数据的误码率超出第二阈值之后,还包括:如果判断结果为不满足,继续解码该次接收的数据的其余部分。
13.本发明实施例还提供一种下行接收数据的处理装置,所述装置包括:误码率计算模块,用于在对单次接收的数据进行解码时,监控已解码数据的数据量,并计算已解码数据的误码率;判断模块,用于判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的误码率超出第二阈值;保存模块,用于在判断模块的判断结果为满足时,停止对该次接收的数据的其余部分解码,且保存该次接收的数据的部分或全部内容;上报模块,用于向基站上报接收错误的反馈,以使得所述基站重传该次接收的数据。
14.本发明实施例还提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行任一项所述方法的步骤。
15.本发明实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行任一项所述方法的步骤。
16.与现有技术相比,本发明实施例的技术方案具有以下有益效果:
17.本发明实施例提供一种下行接收数据的处理方法,所述方法包括:在对单次接收的数据进行解码时,监控已解码数据的数据量,并计算已解码数据的误码率;判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的误码率超出第二阈值;如果判断结果为满足,则停止对该次接收的数据的其余部分解码,且保存该次接收的数据的部分或全部内容;向基站上报接收错误的反馈,以使得所述基站重传该次接收的数据。较之现有技术,本发明实施例提供的方法,使得ue在监控到当前接收到的数据的误码率过高、且已解码的数据量能够代表当前接收到的数据的实际情况时,放弃对未解码的部分的继续解码,以节省系统功耗。
18.进一步地,基站按照传输协议等的规定进行harq重传,再次向ue发送反馈为nack的tb或cbg,ue接收重传的tb或cbg,结合保存的内容对重传的tb或cbg再次进行解码。以提高重传时解码成功的概率。
附图说明
19.图1为本发明实施例的一种下行接收数据的处理方法的流程示意图;
20.图2为本发明实施例的另一种下行接收数据的处理方法的流程示意图;
21.图3为本发明实施例的一种下行接收数据的处理装置的结构示意图;
22.图4为本发明实施例的一种下行接收数据的硬件实现示意图。
具体实施方式
23.具体地,在nr或者长期演进(long term evolution,简称lte)等通信系统中,基站与ue之间的通信的harq重传模式支持tb模式或者码块组(code block group,简称cbg)模式。其中,tb模式指的是若tb中的cb解码失败,则基站重传该tb。另外,1个tb可以划分为n个cbg,其中,n的取值可以为2、4、6、8等,每个cbg中又包含若干个cb,以nr系统为例,1个tb最多可以划分为152个cb,1个cbg最多有76个cb。在ue端,若对一个cbg内的所有cb解码正确,则该cbg上报ack;若cbg内有任意一个cb解码错误,则该cbg上报nack。此时基站以cbg为重
传的单元,即,若基站接收到某一cbg对应的nack,则基站生成针对这一cbg的cbg传输信息(cbg transmission information,简称cbgti)信息映射到下行控制信息(downlink control information,简称dci)中,重传这一cbg。
24.依据r15 38.214协议,假设一个tb最大可以划分为n个cbg,这个tb的cb总数为c,则这个tb的cbg个数可以表示:m=min(n,c);其中,min(n,c)表示取n和c之中的最小值。
25.如果cbg的个数m等于cb的个数c,那么一个cbg就包含一个cb;如果m不等于c,则需要根据以下过程来确认cbg中cb的个数:
26.首先,定义m1=mod(c,m),其中,表示对向下取整,表示为对向上取整,mod()表示对括号内数值取余。
27.对于第m个cbg(其中,m=0,1,
…
,m1‑
1)的情况,包含编号为mk1+k的cb,其中,k=0,1,
…
,k1‑
1;
28.对于第m个cbg(其中,m=m1,m1+1,
…
m)的情况,包含编号为m1k1+(m
‑
m1)k2+的cb,其中,k=0,1,
…
,k2‑
1;
29.用户根据以上方式确认cbg的数量,以及每个cbg中包含哪些cb。
30.例如最大cbg个数n=2,一个tb的cb个数c=13,则该tb的cbg划分方式如下表1:
31.表1
[0032][0033]
如背景技术所言,现有技术中在终端接收的信号质量较差的场景下,可能造成译码器多次迭代也无法解码,继而发生终端功耗浪费的问题。
[0034]
为解决该问题,本发明实施例提供一种下行接收数据的处理方法,包括:在对单次接收的数据进行解码时,监控已解码数据的数据量,并计算已解码数据的误码率;判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的误码率超出第二阈值;如果判断结果为满足,则停止对该次接收的数据的其余部分解码,且保存该次接收的数据的部分或全部内容;向基站上报接收错误的反馈,以使得所述基站重传该次接收的数据。
[0035]
由此,能够使得终端能够根据接收的信号节省解码资源,以节省终端功耗。
[0036]
为使本发明的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
[0037]
请参见图1,图1为本发明实施例的一种下行接收数据的处理方法的流程示意图,图1所述的下行接收数据的处理方法由ue侧执行,该方法可以包括:
[0038]
步骤s101,在对单次接收的数据进行解码时,监控已解码数据的数据量,并计算已解码数据的误码率;
[0039]
可选的,单次接收的数据可以是以tb或者cbg为单位的下行数据。
[0040]
基站向ue发送编码后的下行数据,ue通过译码器或者译码模块对接收到的下行数据进行解码。在解码过程中,译码器或者译码模块可监控已经完成解码数据(即已解码数据)的数据量,并计算已解码数据的误码率。
[0041]
具体地,已解码数据的误码率=已解码数据中误码数据的数据量
÷
已解码数据的数据量。
[0042]
可选的,数据量包括若干个cb和/或cbg。
[0043]
对应地,此时的误码数据的数据量可以为误码cb和/或cbg的数量,已解码数据的数据量可以为已解码的cb和/或cbg的数量。
[0044]
此时,所述误码率可以包括码块误码率(block error ratio,简称bler),码块误码率=误码cb的数量
÷
已解码cb的数量。
[0045]
也即,在ue统计已解码数据的数据量时,可以以cb或者cbg为单位进行统计。
[0046]
例如,若以tb模式进行数据传输,则可统计正在解码的tb中已解码的cb的数量或者已解码的cbg的数量,以表示已解码数据的数据量。若以cbg模式进行传输时,可统计正在解码的cbg中已解码的cb的数量,以表示已解码数据的数据量。可选的,可通过cb的标识(identification,简称id)来统计已解码的cb的数量。
[0047]
步骤s102,判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的误码率超出第二阈值;
[0048]
其中,第一阈值为预设的数据量,第一阈值用于判定已解码数据是否能够代表单次接收数据的解码情况。
[0049]
可选的,以cb为单位统计已解码数据的数据量时,第一阈值可以为预设数量个cb。进一步,第一阈值可以为预设的cb的id值,记作cbnumthr,也即,若已解码的cb的id值大于等于cbnumthr时,则已解码数据的数据量超出第一阈值。
[0050]
以cbg为单位统计已解码数据的数据量时,第一阈值可以为预设数量个cbg。可选的,第一阈值也可以为已解码数据占单次接收的数据的一个预设比例。
[0051]
第二阈值为预设的误码率,第二阈值用于判定已解码数据的误码率是否过高、且是否需要对该次接收的数据继续解码,第二阈值的实际数值可根据实验或需要设定。可选的,码块误码率对应的第二阈值可以记作cbblerthr,此时,已解码数据的码块误码率(记作cbbler)超出第二阈值可以表示为cbbler≥cbblerthr。
[0052]
如果判断结果为满足,则继续执行步骤s103,停止对该次接收的数据的其余部分解码,且保存该次接收的数据的部分或全部内容;
[0053]
若步骤s102的判断结果为是,则可说明已解码的数据量能够代表该次接收数据的解码情况、且该次接收的数据的误码率过高,则ue放弃对该次接收的数据的其余部分的继续译码,以节省ue端的系统功耗。此时ue将该次接收的数据的全部或者部分进行保存,以作为后续解码的参考信息。
[0054]
可选的,若对该次传输的数据全部解码成功,则可删除保存的该次接收的数据的部分或全部内容。
[0055]
可选的,步骤s103所述停止对该次接收的数据的其余部分解码,包括:将该次接收的数据的其余部分绕过译码器或译码模块。
[0056]
ue控制将该次接收的数据中未解码的部分绕过译码器或者译码模块。
[0057]
可选的,步骤s103所述保存该次接收的数据的部分或全部内容,包括:保存该次接收的数据中未解码的码块/码块组。
[0058]
由于在图1所述的方法中,已判定已解码数据的误码率过高,则可不对已解码数据
进行存储,仅保存该次接收的数据中未解码的码块/码块组。
[0059]
可选的,在以cb为单位统计已解码数据的数据量时,且第一阈值为cbnumthr,则保存该次数据传输中cb的id值≥cbnumthr的cb。可选的,步骤s103所述保存该次接收的数据的部分或全部内容,可以包括:将该次接收的数据的部分或全部内容存入harq缓存区。
[0060]
步骤s104,向基站上报接收错误的反馈,以使得所述基站重传该次接收的数据。
[0061]
其中,接收错误的反馈即为针对单次传输的tb或cbg对应的nack,基站接收到该nack之后,可对该单次传输的tb或cbg进行harq重传。
[0062]
本实施例中,提供了一种下行接收数据的处理方法,使得ue在监控到当前接收到的数据的误码率过高、且已解码的数据量能够代表当前接收到的数据的实际情况时,放弃对未解码的部分的继续解码,以节省系统功耗。
[0063]
在一个实施例中,请参见图2,图1中步骤s102的判断结果若为不满足,则执行步骤s201,继续解码该次接收的数据的其余部分。
[0064]
可在解码该次接收的数据的其余cb和/或cbg中,跳转至步骤s102。此时,解码数据的数据量超出第一阈值,可以仅执行步骤s102中判断误码率是否超出第二阈值。
[0065]
在一个实施例中,请继续参见图2,步骤s104所述向基站上报接收错误的反馈之后,还可以包括:步骤s105,接收所述基站重传的数据,根据重传的数据和保存的内容进行再次解码。
[0066]
基站按照传输协议等的规定进行harq重传,再次向ue发送反馈为nack的tb或cbg,ue接收重传的tb或cbg,结合保存的内容对重传的tb或cbg再次进行解码。
[0067]
本实施例中,ue在基站进行harq重传时,可将之前保存的内容作为解码的参考数据,以提高重传时解码成功的概率。
[0068]
在一个具体实施例中,以cbg模式或者tb模式以进行传输时,若以cb的数量对已解码的数据量计数,则当前解码的cb的id记作cbidx(表2中x=0,1,
…
,5)。已解码数据的码块误码率记作cbbler,则已解码cb的错误个数记作cberrcnt,三者的关系可以参见表2:
[0069]
表2
[0070][0071]
请参见图3,图3为本发明实施例的一种下行接收数据的处理装置的结构示意图,所述下行接收数据的处理装置30可以包括:
[0072]
误码率计算模块301,用于在对单次接收的数据进行解码时,监控已解码数据的数据量,并计算已解码数据的误码率;
[0073]
判断模块302,用于判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的误码率超出第二阈值;
[0074]
保存模块303,用于在判断模块的判断结果为满足时,停止对该次接收的数据的其
余部分解码,且保存该次接收的数据的部分或全部内容;
[0075]
上报模块304,用于向基站上报接收错误的反馈,以使得所述基站重传该次接收的数据。
[0076]
可选的,所述数据量包括若干个码块和/或码块组。
[0077]
在一个实施例中,所述保存模块303,还可以用于保存该次接收的数据中未解码的码块/码块组。
[0078]
在一个实施例中,所述保存模块303,还可以用于将该次接收的数据的部分或全部内容存入harq缓存区。
[0079]
在一个实施例中,所述保存模块303,还可以用于将该次接收的数据的其余部分绕过译码器或译码模块。
[0080]
在一个实施例中,在上报模块304向基站上报接收错误的反馈之后,所述下行接收数据的处理装置30还可以包括:
[0081]
再次解码模块,用于接收所述基站重传的数据,根据重传的数据和保存的内容进行再次解码。
[0082]
在一个实施例中,所述判断模块302判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的误码率超出第二阈值之后,所述下行接收数据的处理装置30还可以包括:
[0083]
继续解码模块,用于如果判断结果为不满足,继续解码该次接收的数据的其余部分。
[0084]
关于所述下行接收数据的处理装置30的工作原理、工作方式的更多内容,可以参照上述图1至图2中所述方法的相关描述,这里不再赘述。
[0085]
现有技术中,ue对tb内的各个cb逐个完成对数似然比(loglikelihood ratio,简称llr)的量化、解扰、解交织解重复合并、harq合并、解打孔、低密度奇偶校验码(low density parity check code,简称ldpc)译码、cb循环冗余校验(cyclic redundancy check,简称crc),最终输出cb crc的校验结果。
[0086]
对应地,请参见图4,图4为本发明实施例的一种下行接收数据的硬件实现示意图,将下行接收数据的llr进行llr量化,通过解交织/解扰处理单元对下行接收数据进行解扰、解交织、解重复等处理,通过harq合并处理单元,继续对处理后的数据进行harq合并处理。将harq合并处理单元的输出数据作为图1和图2中的单次接收的数据,经由码块误码率(cbbler)计算单元401计算输出数据的码块误码率、并经过绕过(bypass)译码器判决单元402判断该单次接收的数据是否应绕过译码器。此时,码块误码率(cbbler)计算单元401执行计算已解码数据的码块误码率,bypass译码器判决单元402执行图1中步骤s102判断是否满足以下条件:已解码数据的数据量超出第一阈值、且已解码数据的码块误码率超出第二阈值。当bypass译码器判决单元402的判断结果为满足,则判定对该次接收的数据解码失败,使得harq缓存(buffer)写入(write back)控制单元403将该次接收的数据的部分或全部内容写入harq缓存(harq buffer)404。harq buffer 404中写入的内容,待与harq合并处理单元输出的harq重传的该次接收的数据进行再次解码。当bypass译码器判决单元402的判断结果为不满足,则不绕过译码器,也即继续对该次接收的数据进行继续解码,并经cb crc得到输出结果,作为下行接收数据的译码结果。
[0087]
在一个具体的硬件实现中,码块误块率(cbbler)计算单元401支持识别4比特(bit)位宽的cbbler门限记作cberrthr。
[0088]
可将若cbidx≥cbnumthr且cberrcnt
×
16≥(cbidx+1)
×
cberrthr,其中cbnumthr为第一阈值,cberrcnt为(cbidx+1)个cb内译码错误的cb个数,cberrthr为4bit表示的码块误块率对应的第二阈值。cberrthr与cbblerthr之间的关系为cbblerthr=cberrthr
÷
16。
[0089]
本发明实施例还提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行图1至图2所述方法的步骤。所述存储介质可以是计算机可读存储介质,例如可以包括非挥发性存储器(non
‑
volatile)或者非瞬态(non
‑
transitory)存储器,还可以包括光盘、机械硬盘、固态硬盘等。
[0090]
本发明实施例还提供一种终端,该终端可以为ue。所述终端可以包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行图1至图2所述方法的步骤。
[0091]
具体地,在本发明实施例中,所述处理器可以为中央处理单元(central processing unit,简称cpu),该处理器还可以是其他通用处理器、数字信号处理器(digital signal processor,简称dsp)、专用集成电路(application specific integrated circuit,简称asic)、现成可编程门阵列(field programmable gate array,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
[0092]
还应理解,本申请实施例中的存储器可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read
‑
only memory,简称rom)、可编程只读存储器(programmable rom,简称prom)、可擦除可编程只读存储器(erasable prom,简称eprom)、电可擦除可编程只读存储器(electrically eprom,简称eeprom)或闪存。易失性存储器可以是随机存取存储器(random access memory,简称ram),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的随机存取存储器(random access memory,简称ram)可用,例如静态随机存取存储器(static ram,简称sram)、动态随机存取存储器(dram)、同步动态随机存取存储器(synchronous dram,简称sdram)、双倍数据速率同步动态随机存取存储器(double data rate sdram,简称ddr sdram)、增强型同步动态随机存取存储器(enhanced sdram,简称esdram)、同步连接动态随机存取存储器(synchlink dram,简称sldram)和直接内存总线随机存取存储器(direct rambus ram,简称dr ram)。
[0093]
应理解,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,表示前后关联对象是一种“或”的关系。
[0094]
本申请实施例中出现的“多个”是指两个或两个以上。
[0095]
本申请实施例中出现的第一、第二等描述,仅作示意与区分描述对象之用,没有次序之分,也不表示本申请实施例中对设备个数的特别限定,不能构成对本申请实施例的任何限制。
[0096]
本申请实施例中出现的“连接”是指直接连接或者间接连接等各种连接方式,以实现设备间的通信,本申请实施例对此不做任何限定。
[0097]
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1