一种基于参数预测的深度迁移室内定位方法
1.本发明属于室内定位技术领域,具体是涉及一种基于参数预测的深度迁移室内定位方法。
背景技术:
2.移动设备的普及和无线通讯技术的发展推动了一系列基于移动终端的业务的发展,其中基于位置的服务极大地改变了人们的生活方式,它通过获得用户的地理位置进而在相关平台上为用户提供服务,目前已经被广泛地应用于行人导航、广告推送、资产安全管理等场景中。定位技术作为基于位置的服务的基础,受到了研究者的广泛关注。
3.在众多室内定位技术中,基于wifi的定位技术得益于其低成本、高实时性、使用便捷等优势,成为了最具前景的定位技术之一。该定位方法主要分为两大类:几何测距法和位置指纹法。前者容易受到多径效应和非视距传播的影响导致定位效果不稳定,后者只依赖于离线建立的指纹库,能有效避免由测量带来的误差,具有更强的稳定性。然而传统的基于位置指纹的定位方法的基本假设是:在线定位阶段的样本与离线建库阶段的指纹服从相同的数据分布。但在真实的室内环境下,rss信号会随着时间的变化波动并出现数据分布偏移的现象,此外由于设备的硬件差异,不同设备对同一信号的测量值也会存在偏差,这两种因素都会导致传统指纹定位方法的假设不成立。因此,在实际定位场景中传统指纹定位方法并不适用,而迁移学习中的领域适应技术被证明能够解决这类问题。
4.文献“m.long,y.cao,j.wang,and m.jordan,“learning transferable features with deep adaptation networks,”in international conference on machine learning,2015,pp.97
–
105”和文献“b.sun and k.saenko,“deep coral:correlation alignment for deep domain adaptation,”in european conference on computer vision,2016,pp.443
–
450”是最常见的领域适应方法,它们分别使用最大均值差异准则(maximum mean discrepancy,mmd)和深度协方差对齐(deep correlation alignment,deep coral)来缩小不同领域数据的分布差异。但这两种方法都采用了同一网络来提取不同领域的数据特征,这样的特征提取方式的弊端是过度专注于两个领域的共性而忽略了各自领域的独有特性。此外,由于相同的网络提取的特征为两个领域的公共部分,因此只能有效地约束共有特征的相似程度,按照这种方式缩小领域差异显然是不够充分的,并且当某一领域数据量较小或领域差异较大时还会导致模型的定位性能剧烈下降。基于上述原因,此类方法在复杂的室内定位环境中难以实现准确的定位。
技术实现要素:
5.本发明的目的是,为克服上述技术的不足,提供一种新的基于参数预测的深度迁移室内定位方法。如图1所示,本发明方法涉及两个结构相同但参数不同的深度神经网络,主要包含三个阶段,分别为:预训练阶段、参数预测阶段和测试阶段。图中的虚线框表示在此阶段内参数正在被更新,实线框表示参数固定不变。在预训练阶段,仅利用有标签的源域
数据训练一个源网络,使其能在源域数据上取得良好的分类效果;在参数预测阶段,将目标域网络参数初始化为预训练的源网络参数,利用目标域数据和源域数据训练参数转换矩阵并更新分类层参数,通过转换矩阵对目标网络参数进行预测;在测试阶段,将在线样本输入目标网络中实现对位置的估计。
6.本发明的技术方案是:一种基于参数预测的深度迁移室内定位方法,包括以下步骤:
7.s1、将待定位室内环境划分为c个格点,依次记录每个格点的位置并设置唯一标签,格点标签可以表示为:
8.y
s
={y
k
|k=1,2,
…
,c}
9.s2、在第1个月份内,使用移动设备依次在每个格点中进行多次采样并记录每条rss样本值用于构建指纹库,其中第i条rss样本值可以表示为:
[0010][0011]
其中,m表示待定位区域中所有接入点的数量,表示第i条样本中接收到第m个接入点的信号强度值。假设整个待定位区域中一共采集了n
s
条rss样本,则所有样本可以表示为:
[0012]
x
s
={x
it
|i=1,2,
…
,n
s
}
[0013]
将所有样本和其对应的位置标签进行拼接,得到源域数据
[0014][0015]
s3、从第n个月(n≥2)开始,接收来自用户或待定位设备的rss值作为目标域数据
[0016][0017]
其中,x
t
表示总数量为n
t
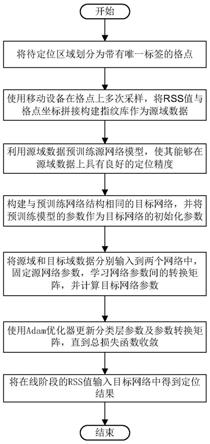
的所有在线样本集合,可进一步详细地表示为:
[0018]
x
t
={x
jt
|j=1,2,
…
,n
t
}
[0019]
s4、构建包含l层的源网络进行预训练,其中网络前(l
‑
1)层为特征提取部分,对应参数记为θ
s
,最后一层为分类层,对应参数记为θ
s
。将有标签的源域数据输入源网络中,采用如公式(1)所示的交叉熵损失函数计算网络的分类损失,并基于该分类损失利用梯度下降法更新参数θ
s
和θ
s
;
[0020][0021]
s5、构建与源网络结构相同的目标网络,其特征提取部分的参数记为θ
t
,分类层对应参数记为θ
t
,初始化目标网络的参数为预训练好的源网络参数;
[0022]
s6、基于源网络参数和转换矩阵对目标网络参数进行预测,预测部分为网络前(l
‑
1)层的参数θ
t
,分类层参数在源网络分类层参数的基础上随训练过程进行更新。神经网络的每一层都包含权重矩阵和偏置向量两部分,一个具有l层的神经网络的参数θ,具体可以表示为:
[0023]
[0024]
其中,θ
(i)
表示第i层的网络参数,w
(i)
和b
(i)
分别表示该层的权重矩阵和偏置向量。转换矩阵中包含对权重矩阵进行放缩的矩阵a及对偏置向量进行平移的向量d。
[0025]
s7、将源域数据和目标域数据分别输入源网络和目标网络中,固定源网络参数θ
s
,更新每一层的放缩矩阵a和平移向量d,以及最后一层分类层的参数θ
t
。
[0026]
s8、将第(n+1)个月的在线rss样本输入目标网络中进行定位,得到定位结果。
[0027]
进一步地,步骤s6中对目标网络参数进行预测的具体步骤为:
[0028]
s61、将放缩矩阵a中的元素全部初始化为1,将平移向量d中的元素全部初始化为0;
[0029]
s62、基于源网络参数θ
s
对目标网络的参数进行预测,即每一层权重矩阵中的元素与放缩矩阵中的对应元素相乘,偏置向量中的元素与平移向量中的元素对应相加。目标域网络第i层的参数可按照公式(3)进行计算:
[0030][0031]
进一步地,步骤s7的具体训练步骤为:
[0032]
s71、将有标签的源域数据输入源网络,经过参数为θ
s
的特征提取部分后得到源域数据特征r
s
。特征通过参数为θ
t
的分类层后,利用交叉熵损失函数衡量预测结果:
[0033][0034]
s72、将无标签目标域数据通过参数为θ
t
的特征提取部分得到目标域数据特征r
t
;
[0035]
s73、在希尔伯特空间内利用mmd准则最小化源域特征r
s
和目标域特征r
t
之间的距离,即最小化损失函数
[0036][0037]
其中,φ为核映射,核函数k(r
s
,r
t
)=<φ(r
s
),φ(r
t
)>;
[0038]
s74、使用梯度下降法更新放缩矩阵a和平移向量d及最后一层分类层的参数θ
t
,最小化总损失函数直到收敛:
[0039][0040]
本发明的有益效果是:本发明在源域网络参数的基础上学习一种转换矩阵对目标域网络的参数进行预测,该转换矩阵会使目标域的特征分布尽可能接近源域特征的最终分布,从而有效克服传统领域适应方法只能提取领域公共特征的弊端。此外,分类层参数随转换矩阵一起更新,能够不断适应对目标域样本进行分类的任务,使目标域网络在适应新的
环境的同时保留了源域网络的处理能力。
附图说明
[0041]
图1为基于参数预测的深度迁移室内定位模型的结构示意图;
[0042]
图2为基于参数预测的深度迁移室内定位方法流程图;
[0043]
图3为背景技术方法和本发明方法在不同月份的平均定位误差对比图;
[0044]
图4为背景技术方法和本发明方法在同种设备和不同设备下的定位误差对比图。
具体实施方式
[0045]
下面结合附图及实施例,详细描述本发明的技术方案:
[0046]
如图2所示,本发明主要包括以下步骤:
[0047]
步骤1.将待定位室内环境划分为c个格点,依次记录每个格点的位置并设置唯一标签,格点标签可以表示为:
[0048]
y
s
={y
k
|k=1,2,
…
,c}
[0049]
步骤2.在第1个月份内,使用移动设备依次在每个格点中进行多次采样并记录每条rss样本值用于构建指纹库,其中第i条rss样本值可以表示为:
[0050][0051]
其中,m表示待定位区域中所有接入点的数量,表示第i条样本中接收到第m个接入点的信号强度值。假设整个待定位区域中一共采集了n
s
条rss样本,则所有样本可以表示为:
[0052]
x
s
={x
it
|i=1,2,
…
,n
s
}
[0053]
将所有样本和其对应的格点编号进行拼接,得到源域数据
[0054][0055]
步骤3.从第n个月(n≥2)开始,接收来自用户或待定位设备的rss作为目标域数据
[0056][0057]
其中,x
t
表示总数量为n
t
的所有在线样本集合,可进一步详细地表示为:
[0058]
x
t
={x
jt
|j=1,2,
…
,n
t
}
[0059]
步骤4.构建包含l层的源网络进行预训练,其中网络前(l
‑
1)层为特征提取部分,对应参数记为θ
s
,最后一层为分类层,对应参数记为θ
s
。在实施例中使用的是5层全连接神经网络,前4层为特征提取部分。将有标签的源域数据输入源网络中,采用如公式(1)所示的交叉熵损失函数计算网络的分类损失,并基于该分类损失利用梯度下降法更新参数θ
s
和θ
s
;
[0060][0061]
步骤5.构建与源网络结构相同的目标网络,其特征提取部分的参数记为θ
t
,分类层对应参数记为θ
t
,初始化目标网络的参数为预训练好的源网络参数;
[0062]
步骤6.基于源网络参数和转换矩阵对目标网络参数进行预测,预测部分为网络前4层的参数θ
t
,分类层参数在源网络分类层参数的基础上随训练过程进行更新。神经网络的每一层都包含权重矩阵和偏置向量两部分,一个具有l层的神经网络的参数θ,具体可以表示为:
[0063][0064]
其中,θ
(i)
表示第i层的网络参数,w
(i)
和b
(i)
分别表示该层的权重矩阵和偏置向量。转换矩阵包含对权重矩阵进行放缩的矩阵a及对偏置向量进行平移的向量d。
[0065]
进一步地,步骤6中对目标网络参数进行预测的具体步骤为:
[0066]
步骤61、将放缩矩阵a中的元素全部初始化为1,将平移向量d设置为零向量;
[0067]
步骤62、基于源网络参数θ
s
对目标网络的参数进行预测,即每一层权重矩阵中的元素与放缩矩阵中的对应元素相乘,偏置向量中的元素与平移向量中的元素对应相加,目标域网络第i层的参数可按照公式(3)进行计算:
[0068][0069]
步骤7.将步骤2和步骤3得到的源域数据和目标域数据分别输入源网络和目标网络中,固定源网络参数θ
s
,更新每一层的放缩矩阵a和平移向量d,以及最后一层分类层的参数θ
t
。
[0070]
进一步地,步骤7的具体训练步骤为:
[0071]
步骤71、将有标签的源域数据输入源网络,经过前4层参数为θ
s
的特征提取部分后得到源域数据特征r
s
。特征通过参数为θ
t
的分类层后,利用交叉熵损失函数衡量预测结果:
[0072][0073]
步骤72、将无标签目标域数据通过前4层参数为θ
t
的特征提取部分得到目标域数据特征r
t
;
[0074]
步骤73、为了使目标域数据特征充分接近源域数据特征,在希尔伯特空间内利用mmd准则最小化源域特征r
s
和目标域特征r
t
之间的距离,即最小化损失函数
[0075][0076]
其中,φ为核映射,核函数k(r
s
,r
t
)=<φ(r
s
),φ(r
t
)>;
[0077]
步骤74、使用梯度下降法更新每一层网络参数的放缩矩阵a和平移向量d及最后一
层分类层的参数θ
t
,最小化总损失函数直到收敛:
[0078][0079]
步骤8、将第(n+1)个月的在线rss样本输入由步骤7训练完毕得到的目标网络中输出预测标签并将其转换为二维坐标得到定位结果。
[0080]
实施例
[0081]
使用在西班牙jaume i大学图书馆采集的wifi rss公开数据集进行实验,数据采集区域总覆盖面积为308.4平方米,共有620个接入点,整个区域被划分为48个网格格点。使用第1个月采集的8640条有标签样本作为源域数据,第n个月(n≥2)的3120条样本作为无标签目标域数据,对本发明的方法进行效果验证。
[0082]
算法中涉及到的深度神经网络模型均包含5个全连接层,每一层的神经元个数依次为256,128,128,128和48。预训练的源网络中对参数进行随机初始化,参数预测阶段中的目标网络参数初始化为预训练好的源网络参数。
[0083]
本发明从环境变化和异构设备两个角度分别验证提出算法的优越性。第一组实验是对比背景技术方法和本发明方法在环境变化下的定位误差,图3中绘制了从2月至25月的误差变化情况,从图中可以看出本发明方法对环境变化的适应性明显优于背景技术方法,且本发明的方法在2至25月实现了2.44m的平均定位误差,而其他两种背景技术的平均定位误差分别为2.61m和2.65m;第二组实验对比了背景技术方法和本发明方法在设备差异的影响下的定位误差情况,如图4所示本发明方法的定位误差在同种设备(设备1)和不同设备(设备2)测量值下均明显低于两种背景技术方法。两组实验的结果证明,本发明提出的基于参数预测的深度迁移室内定位方法能够克服常用领域适应技术中过度专注于领域共性而忽略领域特异性的弊端,在充分利用源域数据训练出的模型参数的基础上使用无标签目标域数据加以辅佐,从而实现对目标域网络参数的预测,该网络结构能够在挖掘领域共性的同时对领域差异进行自适应。综上所述,本发明是一种能够良好适应复杂环境的高精度室内定位方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1