高密度AP分布场景GCN-DDPG无线局域网络参数调优方法和系统
本发明涉及种针对高密度ap分布场景gcn-ddpg无线局域网络参数调优方法和系统,属于无线通信、数学建模、强化学习领域。
背景技术:
最近几年,随着ieee802.11协议标准的不断完善,无线局域网络的性能不断提高,因此无线局域网已经成为了中大型企业实现网络办公、大型公共场所热点等大规模场景部署通信网络的首选方法。
无线局域网络使用的公共的无线信道资源,在无线局域网络工作的2.4ghz这个频谱带上,分布着很多的其他无线设备例如蓝牙设备、电磁炉等,会极大地干扰无线局域网络信号的传输。即使不计算外界设备的干扰,无线局域网络将2.4ghz的频谱资源划分为13个信道,其中完全不产生相互干扰的只有1、6、11信道,这对于高密度ap分布的场景来说,还是很紧迫的资源。另外无线局域网络的工作模式是时分通信,虽然ieee802.11协议规定了一系列策略减少碰撞,但是多用户并发的碰撞依旧是不可避免的,这也会给系统性能也会带来很严重的影响。因此如何在高密度ap分布的场景下,降低干扰和提高无线局域网络的性能是产业发展和技术研究的主要方向之一。
就传统的调优方案而言,对无线局域网络整体进行建模,然后利用一系列公式算法对模型简化、优化,最终达到想要的效果,整体过程是一种静态的确定性的方案。但高密度ap分布下的无线局域网络是极为复杂的,想依靠传统的基于模型和规则的方式设计降低同频干扰、提高无线局域网络性能的方案,需要耗费大量的人力物理,但效果往往并不理想。
本发明中引入了当前热门的深度强化学习算法ddpg(deepdeterministicpolicygradient,确定性深度策略梯度)。而对于强化学习,一切都是动态的过程。强化学习是通过与环境的交互,在不断试错的情况下优化决策模型本身的。强化学习本身的决策不一定是当前环境下最优的决策,它将未来的收益也纳入考虑,而传统算法优化的结果就是当前情况下的最优解,无法顾及一段时间后环境的变化。而在深度学习以及gcn技术加入之后,深度强化学习算法拥有了更为准确的特征输入,对环境的理解也更加深刻,因此算法的收敛速度更快也更为稳定。
技术实现要素:
发明目的:本发明涉及一种针对高密度ap分布场景gcn-ddpg无线局域网络参数调优方法和系统。本发明主要是为了解决无线局域网络参数调优困难的问题。
上述目的通过以下技术方案来实现:
一种针对高密度ap分布场景gcn-ddpg无线局域网络参数调优方法,包括如下步骤:
(1)通过数学建模的方式构建出无线局域网络的参数方案评估模型,参数方案评估模型的输入是所有ap(无线接入点)的信号发射功率p和空闲信道评估阈值c;输出是所有ap的信号发射功率p、空闲信道评估阈值c以及对无线局域网络的饱和吞吐量的估计值r;
(2)通过gcn图卷积神经网络将参数方案评估模型的输出作为输入,进行特征的提取,处理成特征向量;
(3)构建深度强化学习ddpg算法模型,使其与构建的无线局域网络的参数方案评估模型交互,通过试错的方式提高算法性能使其收敛,深度强化学习ddpg算法模型收敛后的无线局域网络参数配置就是最优的无线局网络参数配置方案;深度强化学习ddpg算法模型的输入是gcn图卷积神经网络的输出特征向量,输出是所有ap的信号发射功率p和空闲信道评估阈值c,也就是参数配置方案。
优选地,步骤(1)的具体步骤包括:
(1.1)收集要仿真的真实的无线局域网络的参数信息,包括每个ap的信号发射功率、空闲信道评估阈值、所处信道以及整个无线局域网络的固有参数信息,固有参数信息包括网络中最大包长l,mac(媒介访问控制层)帧头长度、phy(物理层)帧头长度、ack(确认帧)、rts(readytosend,请求发送帧)、cts(cleartosend,准许发送帧)、短帧间隔(shortinter-framespace,sifs)、dcf帧间隔(dcfinter-framespace,difs)长度,最大随机退避窗口cwmax和最小随机退避窗口cwmin;将要仿真区域的三维坐标系,标出每个ap的位置,另外随机生成ap数量10倍的ue(用户)的位置信息;
(1.2)假设api与apj的距离是n米,使用2.4ghz频段传输信号,利用无线信号自由空间路径损耗公式(通信领域经验公式,路损=32.4+20log(n/1000)+20log(2400))计算出api发射的信号到apj位置时的信号强度,计算出每一对ap强度,构成ap到ap信号强度矩阵;用同样的方法,计算出ap到ue的信号强度矩阵;
(1.3)利用上述两个信号强度矩阵,计算ap对于ue的信噪比以及信干噪比,根据信噪比选择连接的ap,根据信干噪比选择信号传输速率,然后计算ap对ue的一阶二阶干扰;
(1.4)利用数学模型,根据输入的ap的信号发射功率和空闲评估阈值,计算出无线局域网络的饱和吞吐量估计结果r,然后将ap的信号发射功率p和空闲评估阈值c和r,作为环境状态一起输出。
优选地,步骤(2)的具体步骤包括:
(2.1)将ap到ap的信号强度矩阵中,假设其中一行为api,空闲信道评估阈值为ci,将该行每一个值与ci做比较,大于ci该位置被赋值为1,小于为0,矩阵对角线元素置0;便可得到ap的邻接矩阵a,为1表示该位置的两个ap相互干扰;
(2.2)利用邻接矩阵a,计算度矩阵d;度矩阵只有对角线有值,且为邻接矩阵a相应行的所有值的累加;假设参数矩阵为x,然后利用公式
优选地,步骤(3)的具体步骤包括:
(3.1)利用策略网络随机生成一个参数配置方案,即每一个ap的信号发射功率和空闲信道评估阈值,然后向配置中加入一定的随机数后,送入环境交互模块,获得这个配置的饱和吞吐量;将配置和饱和吞吐量一起存到记忆库中,重复n次(比如10000次)这个操作;
(3.2)重复n次后,继续利用策略网络成参数配置,加入的噪声值,要随训练次数增多,逐渐减小;并且要从记忆库随机提取一批数据,利用策略梯度算法,更新策略网络和价值网络;
(3.3)不断重复训练的过程,直到策略网络收敛,交互环境给与的饱和吞吐量值趋于稳定。
优选地,步骤(3.1)的具体步骤包括:
(3.1.1)将所有的ap的信号发射功率以及空闲信道评估阈值进行归一化
(3.1.2)利用ap路损信息表计算ap之间的干扰关系;建立ap到ap信号强度矩阵,建立ap到ue的信号强度矩阵;
(3.1.3)因此根据上面两步计算出的信号强度矩阵,计算出每一个ap,在ue所处的位置的信噪比;ue根据信噪比排序,选择信噪比最大的ap进行连接;然后利用两个信号强度矩阵计算出该ap在当前位置的信干噪比,并根据信干噪比选择信号传输速率;
(3.1.4)根据ap与ap之间的信号强度矩阵,假设ap1的空闲信道评估阈值是c1,那么将其他ap对ap1的干扰与这个值比较,如果大于c1,则认为是该ap是ap1的一阶干扰;用同样的方法计算出其他ap的一阶干扰ap;从ap组中删除ap1的一阶干扰ap,然后将剩下的ap两两组合,将它们的信号强度相加如果大于c1,则认为改组是ap1的二阶干扰ap。用同样的方法计算其他ap的二阶干扰ap;
(3.1.5)根据以上计算出来的参数,通过模型公式,计算出无线局域网在该参数下的饱和吞吐量估计值。
一种针对高密度ap分布场景gcn-ddpg无线局域网络参数调优系统,包括:
环境交互模块:将ddpg模块生成的无线局域网络参数配置送入环境交互模块,模块输出该参数配置下,无线局域网络的饱和吞吐量估计值;
gcn模块:将交互环境模块输出的,无线局域网络的参数信息和结构信息,通过矩阵的拉普拉斯变换,将二者结合在一起,生成特征矩阵送入ddpg模块;
ddpg模块:策略网络评估当前无线局域网络参数状态下,应该配置的ap参数,价值网络评估该参数的好坏;然后利用策略梯度算法,更新两个网络的参数。
本发明对比现有技术的有益性在于:本发明可以针对大多数情况下的无线局域网络环境,可以在有限的人手的训练资源的情况下,自动生成无线局域网络的参数配置,免去人工计算的困难。
附图说明
图1为本发明实施例gcn-ddpg无线局域网络参数调优方法估计架构图;
图2为本发明实施例交互环境模块的细节流程图;
图3为本发明实施例使用的无线局域络参数图;
图4为本发明实施例ap信号传输速率参数图;
图5为本发明实施例gcn模块的细节流程图;
图6为本发明实施例深度强化学习细节流程图;
图7为策略网络用策略梯度算法的细节流程图;
图8为环境反馈的无线局域网络饱和吞吐量值曲线。
具体实施方式
下面结合附图和实施例对本发明的技术方案作进一步的说明。
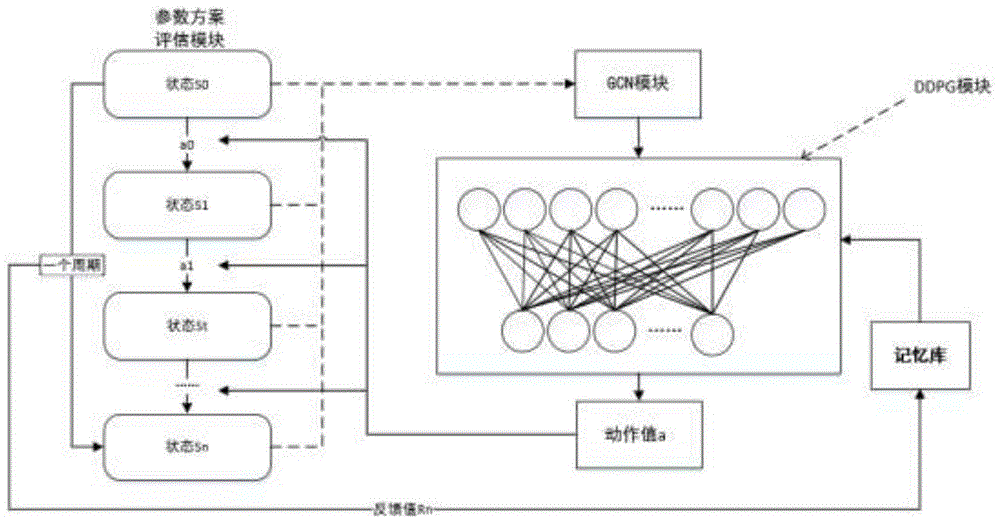
本实施例提供了一种针对高密度ap分布场景gcn-ddpg无线局域网络参数调优方法,解决了传统方法难以对高密度ap分布下无线局网络参数调优的难题。图1展示了本发明gcn-ddpg无线局域网络参数调优方法估计架构图,包括:
深度强化学习模块:
交互环境模块:将ddpg模块生成的无线局域网络参数配置(ap的信号发射强度和空闲信道侦听阈值)送入环境交互模块,模块输出该参数配置下,无线局域网络的饱和吞吐量估计值。
gcn图卷积神经网络模块:将交互环境模块输出的,无线局域网络的参数信息(ap当前的发射信号强度和空闲信道评估阈值)和结构信息(ap之间的邻接矩阵),通过矩阵的拉普拉斯变换,将二者结合在一起,生成特征矩阵送入ddpg模块。
ddpg模块:策略网络评估当前无线局域网络参数状态下,应该配置的ap参数,价值网络评估该参数的好坏。然后利用策略梯度算法,更新两个网络的参数。
图2展示了交互环境模块的细节流程图,包括:
步骤s101、将所有的ap的信号发射功率以及空闲信道评估阈值进行归一化
步骤s102、无线信号自由空间路径损耗公式计算ap之间的干扰关系。因为ap1与ap2的干扰关系是相互的,因此ap1到ap2和ap2到ap1的路损是一致的。因此用ap1的信号发射功率减去二者之间的路损,便可以得到ap1在ap2的信号强度是多少,也就是干扰强度的大小,建立成一个ap到ap信号强度矩阵,同理建立ap到ue的信号强度矩阵。
步骤s103、根据上面计算出的信号强度矩阵,很容易计算出每一个ap,在ur所处的位置的信噪比。ue根据信噪比排序,选择信噪比最大的ap进行连接。但因为在ue的位置,所有ap经受的噪声强度是一致的,因此在实际操作中,只需要选择信号强度最大的ap连接即可。
然后利用两个信号强度矩阵计算出该ap在当前位置的信干噪比,并根据信干噪比选择信号传输速率,具体参数如图5所示。信干噪比的计算方式,假设ue连接的ap是ap1,它的信号强度为p。可以求出剩余ap的信号强度psum,而则信干燥比=log(p/psum)具体参数如图4所示。
步骤s104、根据ap与ue之间的信号强度矩阵,假设ue1的空闲信道评估阈值是c1,那么将其他ap对ue1的干扰与这个值比较,如果大于c1,则认为是该ap是ue1的一阶干扰。用同样的方法计算出其他ue的一阶干扰ap。从ap组中删除ue1的一阶干扰ap,然后将剩下的ap两两组合,将它们的信号强度相加如果大于c1,则认为该组是ue1二阶干扰ap。用同样的方法计算其他ue的二阶干扰ap。
步骤s105、根据以上计算出来的参数,通过模型公式,计算出无线局域网在该参数下的饱和吞吐量估计值,然后将ap的信号发射功率p和空闲评估阈值c和r,作为环境状态一起输出。
1)利用模型中的计算公式,参数带入,计算出数据包顺利传输时所用平均时间ts、数据包传输失败所用平均时间tc,以及数据发送概率τ和冲突概率p计算公式如下:
其中h为mac帧头长度、phy帧头长度的总和,各个符号代表传输该帧需要的时间长度
其中
2)利用模型公式可以计算出一个ue和ap链路当前时刻信号传输的概率ptr和信号传输
成功的概率ps。公式如下:
其中n1和n2表示该ap的一个干扰ap数量个二阶ap干扰数量
3)然后可以用上述两个概率计算出ap节点状态,分别是ap处于空闲状态pidle、传输状态pdata以及冲突状态pcoll公式,计算公式如下:
4)最后利用改进模型的计算公式,计算出单个ap和ue链路的饱和吞吐量,计算公式如下:
δ是传播时延,为1us,rate是ue的传输速度。最后对所有ue链路的饱和吞吐量估计值求和,就可得到无线局域网络总的饱和吞吐量估计值r。
图5展示了gcn模块的细节流程图,包括:
步骤s201、将ap到ap的信号强度矩阵中,假设其中一行为api,空闲信道评估阈值为ci,将改行每一个值与ci做比较,大于ci该位置被赋值为1,小于为0,矩阵对角线元素置0。便可以得到ap的邻接矩阵a,为1表示该位置的两个ap相互干扰。
步骤s202、利用邻接矩阵a,计算度矩阵d。度矩阵只有对角线有值,且为邻接矩阵a相应行的所有值的累加。假设参数矩阵为x,然后利用gcn公式
图6展示了深度强化学习细节流程图,包括
步骤s301、利用策略网络随机生成一个参数配置(每一个ap的信号发射功率和空闲信道评估阈值),在加入配置中加入一定的随机数后,送入交互环境模块,获得这个配置的饱和吞吐量。将配置个饱和吞吐量一起存到记忆库中,重复n(比如10000)次这个操作。
步骤s302、随着训练次数的增加后,减小加入参数配置的噪声n。每完成一次算法与环境的交互,将交互的数据送入记忆库,然后从记忆库抽取一批数据,用于策略网络和价值网络的参数更新。如图7所示,策略网络用策略梯度算法更新,价值网络用tderror更新,td-error是样本在使用td算法更新时目标值函数与当前状态值函数的差值,其中目标值函数是立即奖励与下一个状态值函数之和。
策略梯度算法是强化学习的目标是为智能体找到一个最优的行为策略从而获取最大的回报。策略梯度方法主要特点在于直接对策略进行建模并优化。策略通常被建模为由θ参数化的函数πθ(a|s)。回报(目标)函数的值受到该策略的直接影响,因而可以采用很多算法来对θ进行优化来最大化回报(目标)函数。回报(目标)函数定义如下:
其中dπ(s)代表有πθ引出的马尔科夫链的平稳分布(π下的在线策略状态分布)。使用梯度上升方法,我们可以将参数θ往梯度
策略性能的梯度
步骤s303、查看每次环境反馈的无线局域网络的饱和吞吐量值是否趋于稳定,进入平滑状态。如果是,则训练完成,没有则继续训练,直到收敛。
采用上述算法对实施例的其中一次训练的结果进行展示,训练算法时,环境反馈的无线局域网络饱和吞吐量值曲线如图8所示。从图中可以看出,本模型确实可以有效的无线局域网络参数进行调整,使得无线局域网络的饱和吞吐量性能不断地提高至一个稳定状态。
本发明实现了针对高密度ap分布下,利用gcn-ddpg结合的深度强化学习算法对无线局域网络进行参数的优化。和传统的参数优化方法相比,本发明提出的方法可以使用少量的人力资源和计算资源的情况下快速对无线局域网络的参数进行调整。而且随着ap数量的增多,传统的参数优化方法的复杂度是呈指数倍增长。而对于本发明,ap的增多只是让输入的拉普拉斯特征矩阵的维度增加1,整体算法的复杂性并未增长。而且强化学习技术应用于通信领域的样例还是很少,本发明具有一定的借鉴意义。
本发明已以较佳实施例揭示如上,但并非用以限定相关领域技术方案。本领域的技术人员可以对本发明的技术方案进行修改或者完善,而不脱离本发明技术方案的精神和范围,均涵盖在本发明的权力要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!