一种基于HEVC标准的帧内预测的64x64CU预处理方法
一种基于hevc标准的帧内预测的64x64 cu预处理方法
技术领域
1.本发明属于视频编码解码技术领域,涉及一种基于hevc标准的帧内预测的64x64 cu预处理方法。
背景技术:
2.视频编码,顾名思义,就是指将视频数据在保证一定视频质量的前提下通过一定手段进行编码压缩,以减少视频的存储和收发所需要的数据量。在这个信息技术飞速发展的数字时代,视频数据呈爆发式的增长,如视频分辨率从常用的720p发展到了现在最大的8k,帧率由曾经的十几帧到现在常用的60帧乃至更高。在视频质量的高速发展下,视频编码技术也经历了很多代国际标准,其中新一代高效视频编码(high efficiency video coding,hevc),具有很高的压缩率,相比于其前一代h.264,其性能提升了40%左右。虽然性能提升了,但其编码复杂度有很大的升高。
3.在hevc编码中,一帧视频会分成若干个树形编码单元(coding tree unit,ctu),ctu的尺寸最小为16x16最大为64x64。然后在ctu中会以四叉树的方式划分成若干个编码单元(coding unit,cu),cu有8x8~64x64尺寸。在帧内预测时,会对所有尺寸的cu进行计算,这会占用很大的时间。
4.帧内预测是hevc中非常重要且复杂的部分,整个过程会占用很大的时间。帧内预测有35种预测模式,分为dc模式、planar模式和33种角度预测模式,每一种预测模式有不同的计算公式。在预测时,每一个预测单元(prediction unit,pu)均需要将35个预测模式全部计算一遍,与原始像素相减得到残差,然后计算其对应的编码代价,最后选择出代价最小的一个预测模式作为该pu的最佳预测模式。
5.现有的hevc帧内预测技术的目的都是提高帧内预测的速度,而提高帧内预测的速度,一个是增加计算的并行度,一个就是发明一种估计算法来减少帧内预测的运算量来提高速度。而当前绝大多数都是以减少运算量来提高速度,即舍弃一些预测模式的计算,这样虽然能够提高速度,但是精度又有很大的降低。
6.现有的技术方案《一种快速hevc帧内预测模式选择方法》,该方案在帧内预测过程中,利用视频纹理方向与预测模式角度的相关性,以及粗选过程中的基于哈达玛变换的代价的统计特性,在不同尺寸的情况下,设定对应不同的阈值,同时又通过粗选之后的帧内预测模式的连续性来反应预测单元的纹理方向,来减少粗选得到的帧内预测模式,以此减少帧内预测的计算量,提高帧内预测的速度。
7.可见,现有技术方案的目的都是通过减少帧内预测的计算量来减少帧内预测在选择最佳预测模式上所花费的时间,但是却增加了其图像纹理方向特征等数据的计算量,而且在进行预测时,由于有些预测模式没有计算,对最终编码后的视频质量难免会有一定的损失。
8.本提案同样是以减少帧内预测的计算量为目的来提高hevc帧内预测的速度,提出一种基于hevc标准的帧内预测的64x64 cu预处理方案,本发明不是以减少帧内预测模式的
计算为代价,而是通过4个32x32的cu的预测值来代替64x64 cu的预测值,以此可以省去64x64 cu的帧内预测的像素预测过程,达到提高帧内预测速度的目的。
技术实现要素:
9.本发明的目的在于减少帧内预测的计算量,提供一种基于hevc标准的帧内预测的64x64cu预处理方法,通过将一个ctu中的4个32x32 cu的残差直接代替64x64 cu的残差,可以完全取消64x64 cu的预测过程;且由于变换单元(trasition unit,tu)的最大尺寸为32x32,因此可直接将4个32x32 cu的变换结果的所有绝对值之和进行相加来代替64x64cu的变换结果的绝对值之和。该方案对于预测单元较小的流水线硬件电路而言,仅需添加一个缓存累加模块,就能够节省很大的时钟数。如4x4块为一个预测单元,在单路预测模式的情况下,完成一个4x4块需要35个时钟才能完成,而完成整个64x64 cu的预测,则需要35x256=8960个时钟,这在对时间要求紧迫的场合下是一个很可行的方案。
10.为实现上述目的,本发明的技术方案是:一种基于hevc标准的帧内预测的64x64 cu预处理方法,在进行64x64 cu的率失真代价计算时,跳过残差计算过程,直接使用4个32x32 cu的残差,来代替64x64 cu的残差,以减少残差计算需要的时间,达到加速帧内率失真优化的目的。
11.在本发明一实施例中,在进行64x64 cu的率失真代价计算时,跳过残差计算过程,直接使用4个32x32 cu的残差,来代替64x64 cu的残差具体实现方式为:
12.在进行64x64 cu的率失真代价计算时,64x64 cu直接省去satd计算过程,直接使用4个32x32cu的satd之和来代替,由此得到各模式的率失真代价:
[0013][0014]
其中,floor()为向下取整函数,λ的计算公式如下:
[0015][0016]
其中qp为量化步长,r的值与当前的预测模式是否在mpm(most probable mode)表(mpm表是用当前pu(prediction unit)上方和左侧的最佳模式生成的最可能的模式列表,mpm列表共有3个模式)有关,若在mpm表中则r=1,否则r=7。
[0017]
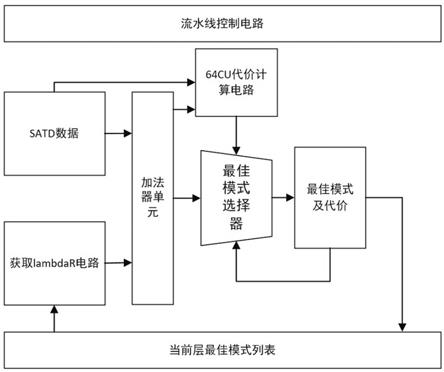
在本发明一实施例中,该方法还提供有对应的硬件框架结构,包括获取lambdar电路、加法器单元、64cu代价计算电路、最佳模式选择器,当前层最佳模式列表输出经获取lambdar电路、加法器单元分别与64cu代价计算电路、最佳模式选择器连接,4个32x32 cu的satd值输入至加法器单元,第1个32x32 cu的satd值经率失真代价计算后输入至64cu代价计算电路,第2至4个32x32 cu的satd值输入至64cu代价计算电路,64cu代价计算电路输出与最佳模式选择器连接,最佳模式选择器输出与当前层最佳模式列表输入连接。
[0018]
在本发明一实施例中,该方法具体实现方式如下:
[0019]
1)输入第一个32x32 cu的satd值,计算出各模式下的率失真代价,发送到最佳模式选择器中得出当前32x32 cu的最佳预测模式,同时将各模式下的率失真代价值发送到64cu代价计算电路中进行缓存;
[0020]
2)输入第二个32x32cu的satd值,直接发送到64cu代价计算电路中与缓存的值进
行累加,继续缓存起来;同时计算出当前32x32 cu各模式下的率失真代价,发送到最佳模式选择器中得出当前32x32 cu的最佳预测模式;
[0021]
3)重复步骤2),将第三个、第四个32x32 cu的satd值累加到64cu代价计算电路中,最终得到64x64 cu各模式下的率失真代价,之后将数据发送到最佳模式选择器中,得出64x64 cu的最佳预测模式;
[0022]
在率失真代价计算上,64x64 cu与第一个32x32 cu使用的是同一个lambdar,因此步骤1)输入到64cu代价计算电路中的数据是第一个32x32 cu各模式的率失真代价而不是satd值。
[0023]
在本发明一实施例中,lambdar即获取lambdar电路输出的值
[0024]
相较于现有技术,本发明具有以下有益效果:本发明相比于现有的hevc帧内预测技术,一方面克服现有技术通过减少帧内预测需要计算的模式数,而不能将全部模式计算一遍,而本发明可以将所有的模式全部计算一遍;另一方面现有技术不适合在硬件设计中实现,而本发明有提供一种硬件实现方案,对于其他的硬件实现非常有可借鉴的地方。
附图说明
[0025]
图1为本发明64x64 cu预处理示例。
具体实施方式
[0026]
下面结合附图,对本发明的技术方案进行具体说明。
[0027]
本发明一种基于hevc标准的帧内预测的64x64 cu预处理方法,通过将一个ctu中的4个32x32 cu的残差直接代替64x64 cu的残差,可以完全取消64x64 cu的预测过程。且由于变换单元(trasition unit,tu)的最大尺寸为32x32,因此可直接将4个32x32 cu的变换结果的所有绝对值之和进行相加来代替64x64cu的变换结果的绝对值之和。该方案对于预测单元较小的流水线硬件电路而言,仅需添加一个缓存累加模块,就能够节省很大的时钟数。如4x4块为一个预测单元,在单路预测模式的情况下,完成一个4x4块需要35个时钟才能完成,而完成整个64x64 cu的预测,则需要35x256=8960个时钟,这在对时间要求紧迫的场合下是一个很可行的方案。
[0028]
本发明以一个硬件电路架构为例,来辅助说明实施方法。如图1所示,为一个cu最佳模式选择电路框架。由于在本发明的方案下,64x64 cu可直接省去satd计算过程,直接使用4个32x32cu的satd之和来代替。
[0029]
模式通过如下公式得到对应模式的率失真代价:
[0030][0031]
其中,floor()为向下取整函数,λ的计算公式如下:
[0032][0033]
其中qp为量化步长,r的值与当前的预测模式是否在mpm表有关,若在mpm表中则r=1,否则r=7。
[0034]
在图1电路中,lambdar就是上面率失真代价计算公式中的加号右侧部分。预处理
步骤如下:
[0035]
第一步、输入第一个32x32 cu的satd值,计算出各模式下的代价,分别发送到模式选择模块中得出当前32x32 cu的最佳预测模式和64cu代价计算电路中进行缓存。
[0036]
第二步、输入第二个32x32cu的satd值,直接发送到64cu代价计算电路中与缓存的值进行累加,继续缓存起来。同时计算出当前32x32 cu各模式下的代价,发送到模式选择模块中得出当前32x32 cu的最佳预测模式。
[0037]
第三步、重复第二步,将第三个第四个32x32 cu的satd值累加到64cu代价计算电路,最终得到64x64 cu的各模式的代价,之后将数据发送到模式选择电路中,得出64x64 cu的最佳预测模式。
[0038]
在代价计算上,64x64 cu与第一个32x32 cu使用的是同一个lambdar,因此第一步输入到64cu代价计算电路中的数据是第一个32x32 cu的各模式的代价而不是satd值。
[0039]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1