一种基于Transformer深度学习模型的加密流量识别方法
一种基于transformer深度学习模型的加密流量识别方法
技术领域
1.本发明涉及一种基于transformer深度学习模型的加密流量识别方法,属于计算机网络安全技术领域。
技术背景
2.加密流量识别,是指将加密后的网络流量按照一定的识别目标,划分为不同的集合。随着网络时代的发展,加密网络流量呈现爆炸式增长。虽然加密可以起到保护隐私的作用,但是,经过加密的流量也可能是攻击者隐藏破坏性活动的手段。因此,准确的加密流量识别,对维护网络空间安全具有重要意义。
3.流量识别技术的发展可以分为以下四类:基于端口号、基于深度包检测、基于机器学习和基于深度学习。
4.基于端口号的方法,假设大多数应用程序使用默认的端口号来推断应用程序的类型。然而,现在的许多应用程序使用动态端口。另外,一些恶意软件使用端口伪装、端口随机等技术来隐藏流量,所以该方法很快失效。
5.基于深度包检测的方法,准确率极高且简单有效,但需要匹配数据包内容,无法处理加密流量。
6.为了解决上述的问题,进一步出现了基于机器学习的方法,通常依赖于统计特征或时间序列特征,然后使用传统的机器学习算法,如支持向量机、决策树、随机森林等算法进行建模与识别。然而,此方法仍存在两个问题:(1)数据流量的特征需要人工提取,而且这往往依赖于专家经验,十分耗时耗力;(2)传统机器学习方法有很大的局限性,例如对复杂函数难以表示、容易陷入局部最优解等。
7.与大多数传统机器学习方法不同,在没有人工干预的情况下,基于深度学习的方法可以实现特征的自动提取,并在此基础上直接进行流量识别,是一种端到端的流量识别模型。基于深度学习方法的研究重点,主要集中在使用哪种深度学习模型,以及如何构造符合输入要求的数据。
8.目前,常用的深度学习模型有卷积神经网络、循环神经网络、自编码器等。在使用卷积神经网络时,输入通常是一维向量或二维图片,再利用一维卷积或二维卷积提取特征。在使用循环神经网络时,输入通常是序列化的数据,如流中多个数据包的统计特征或网络流量字节经过词嵌入技术后产生的向量。
9.还有一些方法,混合使用了多种深度学习模型,多个模型的组合方式大致分为两种:(1)多个模型分别从不同的角度提取特征后,将多个特征进行融合;(2)多个模型顺序提取特征,即一个模型的输入是另一个模型的输出。
10.基于深度学习的方法主要使用三种形式的输入特征:(1)时间序列特征,如每个数据包的长度和到达时间间隔等;(2)整条流的统计特征,如数据包平均长度和每秒发送的平均字节等;(3)数据包字节,如报头字节和有效负载字节等。
11.虽然现有的深度学习方法已经在加密流量识别领域取得了一定效果,但仍然存在
一些不足和缺陷:(1)大部分模型采用的输入形式较为单一;(2)卷积神经网络无法考虑输入之间的相互关系,循环神经网络采用递归的方式,训练时间较长。
技术实现要素:
12.本发明的目的是为了解决现有的基于深度学习的加密流量识别方法存在识别率低、训练周期长等技术问题,创造性地提出一种基于transformer深度学习模型的加密流量识别方法。
13.本发明的创新点在于:首次使用transformer模型进行网络加密流量识别,并给出了具体实现方法。该模型是一个依赖于自注意力机制对输入的全局依赖关系进行特征提取的模型,能够充分考虑输入之间的相互关系,能够并行化操作,大大提高了训练速度和预测准确度。
14.本发明采用以下技术方案实现。
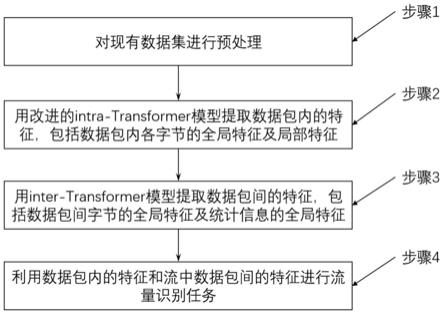
15.一种基于transformer深度学习模型的加密流量识别方法,包括以下步骤:
16.步骤1:对现有数据集进行预处理。
17.具体地,步骤1包括以下步骤:
18.步骤1.1:使用splitcap工具,将pcap文件(一种常用的数据报存储格式,文件中的数据按照特定格式存储)按照五元组信息,以流为单位进行划分。其中,五元组信息包括源ip地址、目的ip地址、源端口号、目的端口号和传输层协议。
19.步骤1.2:取流中所有数据包网络层部分,并对数据包头进行匿名化处理。将源ip地址和目的ip地址全部设置0.0.0.0,将源端口号和目的端口号全部设置为0。然后,取匿名化后的网络层数据包的前n个字节,如不够则用0补充,以达到神经网络输入数据尺寸固定要求为准。
20.步骤1.3:取流中的任意m个相邻的数据包,组成子流。从而实现利用流的少数数据包就可以进行流量识别的目的,体现了流量识别的实时性。
21.步骤2:用改进的intra-transformer模型提取数据包内的特征,包括数据包内各字节的全局特征和局部特征。
22.具体地,步骤2包括以下步骤:
23.步骤2.1:对处理后的数据包的n个字节进行词嵌入,将字节特征映射到d维向量空间,获得数据包的词嵌入特征f1,f1∈rn×d,其中r表示矩阵中的实数。
24.步骤2.2:由于transformer模型对位置信息是一无所知的。因此,需要使用额外的位置表示来对字节的顺序进行建模。
25.将输入序列中的各字节的位置信息pos,通过式1和式2编码为一个d维的位置特征f2,f2∈rn×d,具体如下:
26.f2(pos,2i)=sin(pos/10000
2i/d
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
27.f2(pos,2i+1)=cos(pos/10000
2i/d
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
28.其中,2i表示偶数,2i+1表示奇数。
29.步骤2.3:将词嵌入特征和位置编码特征进行合并,获得transformer模型的输入特征f3,f3∈rn×d,其计算方式如式3所示:
30.f3=f1+f2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
31.步骤2.4:采用多头自注意力方式,从不同角度获得数据包字节的全局依赖关系。具体如下:
32.首先,对f3进行三次线性变换,分别获得查询向量q、键向量k和值向量v,其中,q∈rn×d、k∈rn×d、v∈rn×d,n表示字节数。三次线性变换分别为:
33.q=f3wqꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
34.k=f3wkꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
35.v=f3wvꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
36.其中,w为一个d
×
d大小的矩阵。f3乘w表示做了一次线性变换。
37.然后,计算各字节之间的关联矩阵score,score∈rn×n。该矩阵决定了在某个位置的字节,对数据包其他位置字节的关注程度,如式7所示:
[0038][0039]
其中,为缩放因子,用于缓解由于softmax激活函数引入的梯度消失问题;t为矩阵转置。
[0040]
之后,将关联矩阵与值向量v做矩阵乘法操作,得到一个角度的全局依赖关系,即,多头自注意力机制中的一个头head1,head1∈rn×d,计算公式如下:
[0041][0042]
为了从多个角度充分提取数据包内各字节的全局依赖关系,重复公式(4)至(8)的操作,获得h个不同的头,即head1,head2,
…
,headh。为更好的融合多角度的信息,对h个头进行拼接操作。
[0043]
最后,为了保证输入输出维度的一致性,对拼接后的特征进行线性变换,得到特征f4∈rn×d,计算公式如下:
[0044]
f4=concat(head1,head2,
…
,headh)w
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0045]
其中,concat表示矩阵拼接操作。f4即为从多个角度提取到的一个数据包内字节的全局依赖关系。
[0046]
步骤2.5:为了解决深度学习模型中出现的梯度消失问题,对f3和f4采用残差连接。同时,利用层归一化操作,使训练能够使用更大的学习率,加快训练速度,还可以起到抗过拟合作用。
[0047]
具体地,通过残差和层归一化,得到特征f5,f5∈rn×d,计算公式为:
[0048]
f5=layernorm(f3+f4)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0049]
其中,layernorm表示层归一化。
[0050]
步骤2.6:由于原始的transformer模型只能提取数据包字节的全局依赖关系,为了获得数据包字节的局部特征,对步骤2.5中的特征f5,利用两个不同尺度的一维卷积,同时为保证特征维度的一致,两种一维卷积核的数量均为d个,最终分别得到网络获取的浅层局部特征f6和深层局部特征f7,f6∈rn×d,f7∈rn×d。
[0051]
然后,利用relu激活函数对其进行激活,计算公式为:
[0052]
f6=relu(1dconv(f5))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0053]
f7=relu(1dconv(f6))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0054]
其中,1dconv表示一维卷积。
[0055]
步骤2.7:将f7与f5进行残差连接后,进行层归一化操作,获得特征f8,f8∈rn×d:
[0056]
f8=layernorm(f5+f7)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0057]
步骤2.8:为了更好地提取数据包内的特征,将步骤2.4至步骤2.7重复k1次,利用更深的网络,提取更深层次的特征f9,f9∈rn×d:
[0058][0059]
其中,代表第k1次重复执行步骤2.4至步骤2.7。
[0060]
步骤2.9:将基于改进的intra-transformer提取的数据包内的特征f9输入给一个全连接层,全连接层的输出神经元个数等于向量空间维度d,得到特征f
10
,f
10
∈r1×d,如式15所示:
[0061]f10
=fc(flatten(f9))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0062]
其中,flatten代表将二维特征平铺成一个一维向量。fc代表全连接。
[0063]
步骤3:用inter-transformer模型提取数据包间的特征。包括数据包间字节的全局特征和数据包间统计信息的全局特征。
[0064]
具体地,步骤3包括以下步骤:
[0065]
步骤3.1:对于有m个数据包的子流,首先通过步骤2中的改进的intra-transformer模型提取m个数据包的包内特征,即,对于所有的包执行步骤2.1至步骤2.9操作,最终得到m个特征:
[0066]
将这m个特征进行拼接,得到inter-transformer的输入特征f
11
,
[0067][0068]
步骤3.2:为充分利用流量数据的特征,除利用包的字节特征外,还要利用包的统计特征,即流中m个连续数据包的长度。
[0069]
将包的长度信息通过词嵌入方式,映射到d维向量空间,获得包长度的长度嵌入特征f
12
,f
12
∈rm×d。
[0070]
步骤3.3:对于包间的相对位置信息,同样使用同步骤2.2中的位置编码,最终得到位置编码特征f
13
,f
13
∈rm×
2d
。
[0071]
步骤3.4:将特征f
11
、f
12
和f
13
进行融合,得到特征f
14
,f
14
∈rm×
2d
:
[0072]f14
=concat(f
11
,f
12
)+f
13
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0073]
步骤3.5:利用多头自注意力机制(如步骤2.4所述方法),在流量层面从不同角度获得流中各个数据包间的全局依赖关系,最终得到特征f
15
,f
15
∈rm×
2d
。
[0074]
步骤3.6:对f
14
和f
15
进行残差和层归一化操作(如步骤2.5所述方法),最终得到特征f
16
,f
16
∈rm×
2d
。
[0075]
步骤3.7:将特征f
16
输入给两层全连接层,并用非线性激活函数激活。
[0076]
第一个全连接层的输出神经元个数为4d,输出特征f
17
,f
17
∈rm×
4d
。
[0077]
第二个全连接层的输出神经元个数为2d,输出特征为f
18
,f
18
∈rm×
2d
。
[0078]f17
=relu(fc(f
16
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19)
[0079]f18
=fc(f
17
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0080]
其中,fc表示全连接。
[0081]
步骤3.8:对f
17
和f
18
进行残差和层归一化操作(如步骤2.5所述方法),最终得到特征f
19
,f
19
∈rm×
2d
。
[0082]
步骤3.9:为了更好的提取流中数据包间的特征,将步骤3.5至步骤3.8重复执行k2次,提取出更深层次的特征f
20
,f
20
∈rm×
2d
:
[0083][0084]
其中,代表重复执行k2次步骤3.5至步骤3.8操作。
[0085]
步骤4:利用步骤2提取的数据包内的特征和步骤3提取的流中数据包间的特征,进行流量识别任务。
[0086]
具体地,方法如下:
[0087]
将步骤3的输出特征f
20
输入给两个全连接层,两个全连接层的输出神经元个数分别为d(等于向量空间维度d)和分类任务的类别数c,得到特征f
21
和最终的分类结果res,f
21
∈r1×d、res∈r1×c。
[0088]f21
=fc(flatten(f
20
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0089]
res=fc(f
21
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23)
[0090]
其中,flatten代表将二维特征平铺成一个一维向量。
[0091]
有益效果
[0092]
本发明方法,对比现有技术,具有以下优点:
[0093]
1.本方法利用改进的intra-transformer模型,提取出数据包内各字节的全局特征和局部特征,利用inter-transformer模型提取流中数据包间字节的全局特征和统计信息的全局特征。相较于卷积神经网络,考虑了输入的全局特征,使模型性能有较大的提升;相较于循环神经网络,能够并行化处理,加速收敛,减少训练时间。
[0094]
2.本方法仅利用流中部分相邻数据包便可对流进行分类,无需利用流中的大部分包,即可实现快速识别流量类型的目标。
[0095]
3.本方法在满足实时性的前提下,性能领先于现有的加密流量识别方法,在实时性与精度之间实现了更好的平衡。
附图说明
[0096]
图1为本发明的流程图。
[0097]
图2为数据预处理流程图。
[0098]
图3为本发明中改进的intra-transformer模块的结构。
[0099]
图4为本发明中inter-transformer模块的结构。
[0100]
图5为本发明中特征提取和分类的整体模型结构。
具体实施方式
[0101]
下面结合附图和实施例,对本发明方法做进一步详细说明。
[0102]
实施例
[0103]
如图1所示,一种基于transformer深度学习模型的加密流量识别方法,包括以下步骤:
[0104]
步骤1:对现有数据集进行预处理。具体的数据集处理流程如图2所示。
[0105]
在本实施例中,首先使用splitcap工具将数据集中原始pcap文件按照五元组信息(源ip地址,目的ip地址,源端口号,目的端口号,传输层协议)以流为单位进行划分,划分后的流量数据以pcap格式存储。
[0106]
然后,利用python的dkpt库中来提取流中所有数据包网络层部分,并对数据包头进行匿名化处理,具体地是将源ip地址和目的ip地址全部设置0.0.0.0,将源端口号和目的端口号全部设置为0。然后取匿名化后的网络层数据包的前50个字节,不够则用0补充,以达到神经网络输入数据尺寸固定的要求。最终将一个包的前50个字节保存在一个列表中。
[0107]
最后,取流中的任意3个相邻的数据包组成子流,以实现利用流的少数数据包就可以进行流量识别的目的,体现了流量识别的实时性。最终处理后的数据集以列表的形式储存,其中每一个元素对应一个子流,每一个子流又是由三个相邻的数据包列表组成。最终数据集被保存在一个pkl文件中。
[0108]
步骤2:用改进的intra-transformer模型提取数据包内的特征,包括数据包内各字节的全局特征及局部特征,图3是改进的intra-transformer的结构,主要是利用了transformer的编码器部分,并对原始的transformer编码器结构进行了改进,利用两个一维卷积来替换两个全连接层:
[0109]
(1)对处理后的数据包的前50个字节进行词嵌入,将字节特征映射到256维的向量空间,获得数据包的词嵌入向量f1∈r
50
×
256
。
[0110]
(2)由于transformer模型对位置信息是一无所知的。因此,需要额外的位置表示来对字节的顺序进行建模,所以需要将输入序列中的各字节的位置信息编码为一个256维的位置向量f2∈r
50
×
256
。位置编码使用了三角函数,其中对于偶数位置,使用正弦编码,对于奇数位置,使用余弦编码。
[0111]
(3)然后将词嵌入向量和位置编码向量进行合并,直接使用矩阵加法操作,获得intra-transformer模型的输入f3∈r
50
×
256
。
[0112]
(4)采用多头自注意力方式,从不同角度获得数据包字节的全局依赖关系。对于其中一个头,通过对特征f3进行三次线性变换获得查询向量q∈r
50
×
256
、键向量k∈r
50
×
256
、值向量v∈r
50
×
256
。然后计算各字节之间的关联矩阵score∈r
50
×
50
,该矩阵表示一个包中50个字节之间的关注程度。然后将关联矩阵与值向量v做矩阵乘法操作,就可以得到多头自注意力机制中的一个头。为了充分提取数据包内各字节的全局依赖关系,重复上述操作获取4个头,并将4种全局依赖关系进行拼接,更好的融合多角度的信息,最后为了保证输入输出维度的一致性,对拼接后的特征进行线性变换得到特征f4∈r
50
×
256
,该特征即是从多个角度提取到的一个数据包内字节的全局依赖关系。
[0113]
(5)为了解决深度学习模型中出现的梯度消失问题,对特征f4采用了残差连接。同时还利用了层归一化操作,使训练可以使用更大的学习率,加快训练速度,还可以起到抗过
拟合作用。通过残差和层归一化得到f5∈r
50
×
256
。
[0114]
(6)原始的transformer模型只能提取数据包字节的全局依赖关系,为了获得数据包字节的局部特征,利用3
×
256和5
×
256两个不同尺度的一维卷积,同时为了保证特征维度的一致,两种一维卷积核的数量均为256个,最终分别得到特征f6∈r
50
×
256
和f7∈r
50
×
256
。f6表示网络获取的浅层局部特征,f7表示网络获取的深层局部特征,然后利用relu激活函数进行激活。
[0115]
(7)对于一维卷积的输出特征,同样使用了残差结构和层归一化操作,获得特征f8∈r
50
×
256
:
[0116]
(8):将(4)至(7)的步骤重复进行2次,构建更深的网络结构,从而更好地提取数据包内的特征。
[0117]
(9):将经过(8)提取的数据包内的特征输入给一个全连接层,全连接层的输出神经元个数为256,f
10
∈r1×
256
。
[0118]
步骤3:用inter-transformer模型提取数据包间的特征,包括数据包间字节的全局特征及数据包间统计信息的全局特征,图4是inter-transformer模型的结构,就是利用原始的transformer模型的编码器,具体流程如下:
[0119]
(1)对于有3个数据包的子流,首先通过步骤2中的改进的intra-transformer模型提取3个数据包的包内特征,即对于所有的包进行步骤2,最终得到3个特征,将这3个特征拼接起来,得到inter-transformer的输入特征f
11
∈r3×
256
:
[0120]
(2)为了充分利用流量数据的特征,除了利用包的字节特征外,还利用了包的统计特征,即流中3个连续数据包的长度。现有的方法中还会利用包的方向信息,但因为本发明使用的是单向流,所以只用了包的长度信息,将包的长度信息利用词嵌入技术映射到256维向量空间,获得包长度的长度嵌入向量f
12
∈r3×
256
。
[0121]
(3)给inter-transformer模型提供数据包间的相对位置信息,对包的位置信息进行位置编码,最终得到位置编码向量f
13
∈r3×
512
。
[0122]
(4)将上述3步的向量进行融合,对特征f
11
和特征f
12
进行矩阵拼接后,与特征f
13
进行矩阵加法操作,得到特征f
14
∈r3×
512
:
[0123]f14
=concat(f
11
,f
12
)+f
13
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0124]
(5)利用多头自注意力机制,在流量层面从8个不同的角度获得流中各个数据包间的全局依赖关系,最终得到特征f
15
∈r3×
512
。
[0125]
(6)对于特征f
15
利用残差和层归一化操作,可以解决梯度消失问题,还能提高训练速度并防止过拟合,最终得到特征f
16
∈r3×
512
。
[0126]
(7)将特征f
16
输入给两层全连接层并用非线性激活函数激活,第一个全连接层的输出神经元个数为1024,输出特征为f
17
∈r3×
1024
。第二个全连接层的输出神经元个数为512,输出特征为f
18
∈r3×
512
。
[0127]
(8)对于全连接层的输出同样利用残差和层归一化操作,最终得到特征f
19
∈r3×
512
。
[0128]
(9)将步骤(5)~(9)的操作,视同为一个编码器块,为了更好的提取流中数据包间的特征,将编码器块重复2次,提取更深层次的特征f
20
∈r3×
512
。
[0129]
步骤4:利用步骤2提取的数据包内的特征和步骤3提取的流中数据包间的特征进行流量识别任务,在本实施例中将流量分为6类。整体流程见图5。
[0130]
把步骤3的输出特征f
20
输入给两个全连接层,两个全连接层的输出神经元个数分别为256和分类任务的类别数6,得到的特征和最终的分类结果分别为f
22
∈r1×
256
和res∈r1×6。对于res,取其数值最大的列即为最终的分类结果。
[0131]
实例验证
[0132]
使用的数据集为iscx vpn-nonvpn与iscx tor-nontor数据集。这两个数据集都包含6种非加密流量和6种加密后的流量,在本发明中分别对6种非加密流量,6种vpn加密流量,6种tor加密流量进行分类。iscx vpn-nonvpn数据集包含28g,共150条原始流量,经过五元组分流后包含195095条单向流,经过子流划分后包含717829条流量。iscx tor-nontor数据集包含20g,共41条原始流量,经过五元组分流后包含138条单向流,经过子流划分后包含186883条流量。对两个数据集,均利用10折交叉验证法,取90%的数据作为训练集,10%的数据作为测试集。
[0133]
在实现上,所有的实验均使用pytorch深度学习框架完成,对于intra-transformer模型的训练周期设置为20,每次迭代的批量大小设置为128,inter-transformer模型的训练周期设置为5,每次迭代的批量大小设置为128。在1块3090ti显卡上进行训练。所有的性能测试也均在3090ti上进行。在训练方式上,两个模型均采用adam(adaptive moment estimation)优化器对参数进行学习,其中初始学习率设置为0.0001和0.001,betas设置为0.9与0.999,eps设置为1e-8
,weight_decay设置为0。在trasformer1模型的训练中,采用每隔5个周期,就将学习率递减为原始的90%的策略。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1