基于情感诱发的脑电信号识别方法与流程
本发明设计一种神经科学、信号处理和模式识别,尤其是脑电数据分析方法的一种基于构造超完备字典的脑电信号识别方法。
背景技术:
情感是人与人交流过程中不可或缺的信息载体。虽然目前基于情感识别的算法有很多,例如隐马尔科夫模型和支持向量机等,但是不论人们对这些算法如何改进,使这些算法如何的智能化,它们都很难与人脑的运行机制相媲美,因此,研究人脑对情感的感知过程,是实现人机交互的有效方法之一。近年来,随着脑电研究的深入,基于情感的脑电研究也受到越来越多的关注。人脑对情感的正确识别有利于人们的社会交往和环境适应。同时,对正常人的研究也可为临床诊断和治疗提供参考。
诱发脑电信号的刺激不同,所产生的脑电波形也是有所区别的,如何根据这些波形来推出被试所处于的认知状态,是信号识别领域的研究热点。对于传统的识别器而言,都要求用于识别的信号特征必须具有有效性,因此信号的特征提取对于信号的识别就显得尤为重要,例如专利申请号为201210199052.7,名称为 “基于脑电特征的情绪状态识别方法”中提出了一种共空间的模式算法用于去除背景信号,增强脑电信号来进行特征提取和识别;在专利申请号为201110344311.6,名称为 “基于有效时间序列和电极重组的脑电信号分类系统和方法”,提出了一种基于有效时间序列和电极重组的脑电信号识别方法,该发明将重组的脑电信号作为特征,采用传统识别方法进行脑电识别,在专利申请号为201210308790.0,名称为 “一种脑电特征提取方法”中需要提取信号的时频特征和形态特征,并将两种特征结合来识别脑电信号的状态;在专利申请号为201110127576.0,名称为 “一种基于脑电信号的疲劳状态识别方法”中采用模糊模式识别的方法评估人脑的疲劳程度,该方法的实现也需要提取每个通道信号的特征信息。
上述发明均需要基于不同方法对信号进行特征提取,再使用不同的识别模型进行识别,运算量大,且识别结果依赖于特征和识别模型的有效性。而且对于类似脑电信号这样的维数较高的信号,若先对其进行降采样再提取特征,那么降采样后的信号可能会损失原始信号中的部分特征,那么所获得的信号特征结果是不可靠的。
技术实现要素:
本发明的目的是提供一种基于情感诱发的脑电信号识别方法,用于情感脑电信号的压缩识别方法,以解决现有信号识别方法需要提取特征的限制。
本发明所采用的数据信号是基于事件相关的脑电信号,具体技术方案如下。
一种基于情感诱发的脑电信号识别方法,所述脑电信号识别方法是按下列步骤进行的:
(1)脑电信号采集:所述脑电信号采集是在情感诱发条件下,提取被试在不同情感诱发条件下的脑电数据;
(2)脑电信号预处理:所述脑电信号预处理是对脑电信号进行去除伪迹、眼电以及带通滤波的处理;
(3)脑电信号识别:所述脑电信号识别是选择合适的观测矩阵,将原始信号进行压缩,通过构造及训练适用于压缩后脑电信号的超完备字典方法对脑电信号进行识别,以便识别出不同情感状态下的脑电信号。
在上述技术方案中,所述脑电信号的采集是按下列步骤进行的:
(1)实验设计:选择音频、视频或图片的某一种素材作为情感刺激材料,在实验过程中需要被试者认真观看或倾听是实验材料,并采集有效的情感脑电数据;
(2)实验材料筛选与预处理:对实验的音频材料经过有效性筛选,再对所选的情感刺激进行必要的端点预处理,准确确定情感的起始点。
在上述技术方案中,所述脑电信号的采集方法是:使用E-prime软件设计实验程序,使用64导的Neuroscan设备采集脑电数据,其中脑电信号的实时采样率设定为1000Hz,且每个导连的电极阻抗都小于5KΩ。
在上述技术方案中,所述脑电信号的预处理是离线滤波通带为0.5 Hz - 30 Hz,去除伪迹、眼电使用Neuroscan仪器自带的curry软件进行。
在上述技术方案中,所述脑电信号的识别方法按下列步骤进行的:
(1)数据归一化处理;
(2)选择有效导联,本发明选择FC1、FC2、FC3、FC4、C1、C2、C3、C4、CP1、CP2、CP3及CP4位置处的电极,共12导的脑电数据进行识别;
(3)选择合适的观测矩阵,将原始信号进行压缩即为压缩后的信号;
(4)构造及训练样本字典,按下列步骤进行:
1)构造初始字典:设对悲伤、生气、高兴、惊奇和中性于五种情感诱发的脑电数据,其中每种情感脑电数据的训练样本为为情感的类别,第类训练样本构成矩阵,五种训练样本组成的矩阵为训练样本的维数,每类训练样本的采样点数,;对于任一测试样本的重构过程通过矩阵表示成为第类样本的稀疏系数;
2)训练字典:假设算法对初始字典进行训练,得到新的超完备稀疏字典为训练符合第类情感样本表达的超完备稀疏字典,K-SVD算法步骤如下:
Ⅰ、稀疏编码阶段:根据,利用现有的追踪算法计算出每个样本的稀疏表示向量;
Ⅱ、字典更新阶段:根据上一步稀疏编码阶段已知,已知,设训练字典未知,求解字典的过程为字典进行更新,并逐个更新字典第列的原子,其目标逼近函数为:
其中为误差矩阵,表示原子稀疏系数;
Ⅲ、用表示所用到的原子位置索引集合,即非零值的位置集合,将设置成只保留中所提到的那些原子的集合,记为;
Ⅳ、对进行SVD分解,的第一列,用替换字典中的第,完成字典D的更新;
(5)根据,找到用完备字典表示测试样本的稀疏解,然后再对;
(6)计算残差,,找出最小残差所对应字典的所属类别;
(7)输出识别结果,最小残差所对应的类别,即为所求的识别结果。
上述一种基于情感诱发的脑电信号识别方法的技术方案,与现有技术相比,在识别过程中,首先要选取合适的观测矩阵对已知训练样本和待识别的样本进行压缩,然后再根据压缩后的脑电信号构造适合它的超完备字典,并提取该字典下的稀疏系数,采用K-SVD方法训练最优的稀疏字典,得到不同情感类别的训练字典,最后对压缩后的数据分别采用已经训练好的不同类别的字典进行稀疏重构,计算在不同类别的训练字典下的重构样本和测试样本之间的残差,残差最小的信号对应的字典所属类别即为最后的识别结果。该算法可以在降低原始数据采样率的同时对数据进行有效识别,并且避免了传统识别方法需要提取信号特征的过程,节省了运算时间。
附图说明
图1是本发明关于情感脑电信号识别的流程图。
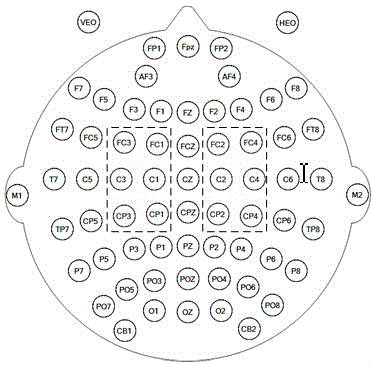
图2是本发明2 64导联的电极信号分布图。
具体实施方式
下面结合实施例和附图对本发明的基于情感诱发的脑电信号识别方法做出详细说明。
本发明提出的基于情感诱发的脑电信号识别方法,对多类情感声音诱发的脑电通过构造超完备字典的方法进行识别,有效避免了传统识别方法需要提取信号特征的过程,节约了运算成本。
如附图1所示,本发明是基于情感诱发的脑电信号识别方法。主要涉及脑电数据的采集、预处理及脑电数据的识别三个方面。下面对本发明的三个方面进行具体说明:
(1)脑电信号的采集。所述的脑电信号的采集是在情感诱发条件下,提取被试在不同情感诱发条件下的64导脑电数据。
选择音频、视频或图片等某一种素材作为情感刺激材料。在实验过程中需要被试认真观看或倾听是实验材料,以便采集有效的情感脑电数据。实验中的所有音频材料都要经过有效性筛选(正确率95%以上),这样筛选的目的是为了保证情感刺激的有效性,并对所选的情感刺激进行必要的端点预处理(比如音频和视频等),以准确确定情感的起始点。并对所选的情感刺激进行必要的端点预处理(比如音频和视频等),以准确确定情感的起始点。
使用E-prime软件设计实验程序,美国Neuroscan公司的64导Ag/Agcl电极记录脑电(EEG),其中,脑电信号实时采集的采样率为1000 Hz,每个导联的电极阻抗均小于5KΩ。
实验被试所选择的是太原理工大学在校研究生,年龄23-35岁。所有的被试都是在校大学生和研究生,且无精神障碍。听力正常,视力或校正视力正常。每位被试都是自愿参加实验,并签署实验的知情同意书。实验过程是按照世界卫生组织Helsinki宣言中的道德原则进行的,同时也是经过中国科学院心里研究所伦理委员会批准的(审核号:H16012)。
(2)脑电信号的预处理。对脑电信号进行去除伪迹、眼电以及带通滤波等处理。
由于脑电信号十分微弱,因此在采集过程中很容易受到其他噪声信号的干扰。脑电信号的预处理主要是指去除采集到的脑电信号中所掺杂的伪迹。在基于情感诱发的脑电信号识别方法中,所要去除的伪迹主要包括眼电、肌电、心电、工频干扰、电磁干扰和任务不相关的脑电等。
在本发明的实验过程中记录双眼外侧的水平眼电(HEOG)及左眼上下垂直眼电(VEOG)并用来达到去除眼电伪迹的目的。采用70 Hz的直流DC带通滤波。参考电极为鼻尖,离线后转换参考电极为全头平均,脑电信号的离线滤波通带为0.5 Hz - 30 Hz。去除伪迹、眼电使用仪器自带的curry软件进行。
(3)脑电信号的识别。通过构造及训练适合脑电信号的超完备字典方法对脑电信号进行识别,以便识别出不同情感状态下的脑电信号。具体的识别方法如下:
1)数据归一化处理。为了避免数据处理的复杂性,需要将训练数据和测试数据都进行归一化处理。
2)选择有效导联。本发明选择FC1、FC2、FC3、FC4、C1、C2、C3、C4、CP1、CP2、CP3、CP4位置处的电极,共12导的脑电数据进行识别。如附图2所示,虚线框内的电极即为实验所选择的电极。
3)选择合适的观测矩阵,即为压缩后的信号。
4)构造及训练样本字典。由于每一导的脑电数据处理过程都相同,因此本步骤中所描述的方法只是其中一个导联的脑电信号的处理过程。
a)构造初始字典。假设对于五种情感(悲伤、生气、高兴、惊奇和中性)诱发的脑电数据,其中每种情感脑电数据的训练样本为为情感的类别,那么第类训练样本就构成矩阵,那么五种训练样本组成的矩阵为训练样本的维数,也就是每类训练样本的采样点数,的重构过程都可以通过矩阵类样本的稀疏系数。
b)训练字典。假设,利用K-SVD算法对初始字典进行训练,得到新的超完备稀疏字典即为训练好的符合第类情感样本表达的超完备稀疏字典,K-SVD算法步骤如下:
Ⅰ、稀疏编码阶段:根据,利用现有的追踪算法可计算出每个样本的稀疏表示向量。
Ⅱ、字典更新阶段:字典更新阶段的目的是逐个更新字典原子。根据上一步稀疏编码阶段可的过程为字典更新阶段,它的方法是假设稀疏系数个原子是固定的,逐个更新字典第个原子已知其余原子未知的情况下,求解。其目标逼近函数为如下:
Ⅲ、用表示所用到的这些原子的位置索引集合,即非零值的位置集合,将。
Ⅳ、对的第一列,用其替换字典中的第,进而完成了字典D的更新。
5)根据,求解最小化范数问题。
6)计算残差,,找出最小残差所对应的类别。
7)输出识别结果,最小残差所对应的类别,即为所求的识别结果。
上述实施例在识别过程中,首先要选取合适的观测矩阵对已知训练样本和待识别的样本进行压缩,然后再根据压缩后的脑电信号构造适合它的超完备字典,并提取该字典下的稀疏系数,采用K-SVD方法训练最优的稀疏字典,得到不同情感类别的训练字典,最后对压缩后的数据分别采用已经训练好的不同类别的字典进行稀疏重构,计算在不同类别的训练字典下的重构样本和测试样本之间的残差,残差最小的信号对应的字典所属类别即为最后的识别结果。该算法可以在降低原始数据采样率的同时对数据进行有效识别,并且避免了传统识别方法需要提取信号特征的过程,节省了运算时间,提高了效率。
- 还没有人留言评论。精彩留言会获得点赞!