一种婴幼儿视力自动检测方法与流程
本发明涉及图像处理领域,更具体地,涉及一种婴幼儿视力自动检测方法。
背景技术:
和年龄稍大的儿童相较,3岁以下的婴幼儿没有表达语言或者肢体能力,智力水平及识别力水平较低,注意力不能较长时间保持集中,很难配合常规视力检查工作。因此在1985年mcdonald等人设计完成teller视力卡,teller视力卡主要是由17张条栅卡和1张空白卡组成,主要应用于3岁以下无语言表达能力的婴幼儿和神经系统发育异常有认识障碍或语言障碍的儿童。teller视力卡检测婴幼儿视力的具体原理过程如下:向婴幼儿出示不同的条栅卡,若婴幼儿的眼睛移动,则表示其能看到相应条栅卡的条栅,通过条栅卡对应的条栅级别即可确定其视力水平。但是,上述操作过程中主要是通过人工方式来判断婴幼儿的眼睛是否发生移动,人为的误判率较高,检测的精度不理想。
技术实现要素:
本发明为解决以上婴幼儿视力检测方法误判率高、检测精度不理想的缺陷,提供了一种应用图像处理技术来对婴幼儿视力进行检测的方法,该方法的误判率低、检测的精度与现有技术相比得到了提高。
为实现以上发明目的,采用的技术方案是:
一种婴幼儿视力自动检测方法,包括以下步骤:
s1.同步记录出示teller视力卡的视频图像及被检测者的视频图像;
s2.通过出示teller视力卡的视频图像确定视力卡展示窗口位置及相应的视力卡展示时段,并从被检测者的视频图像中提取与视力卡展示时段相应的片段进行步骤s3~s8的操作;
s3.使用adaboost算法训练出对人脸识别效果最优的强分类器;
s4.将强分类器进行级联,得到筛选式级联分类器;
s5.对步骤s2提取的片段进行分解,得到视频帧的集合,然后对集合中的每一帧视频帧进行步骤s6~s7的操作:
s6.使用筛选式级联分类器对视频帧进行检测,确定其人脸区域;
s7.通过surf算法确定人脸区域中的兴趣点位置,然后根据兴趣点邻域的haar小波响应来确定surf描述子;
s8.对视频帧集合中任意相邻的两帧图像的surf描述子计算其相似度,若计算的相似度大于所设定的阈值,则匹配成功,婴幼儿的眼睛发生了移动;此时通过视力卡对应的条栅级别即可确定婴幼儿的视力水平。
优选地,所述步骤s3训练强分类器的具体过程如下:
s11.给定的训练样本集共包括n个样本,其中n个样本中包括x个人脸样本和y个非人脸样本;设定训练的最大循环次数t;
s12.初始化各个训练样本的权重为1/n;
s13.第一轮迭代训练n个样本,得到第一个最优弱分类器;
s14.提高上一轮训练中被误判的样本的权重;
s15.将新的样本与上一轮训练中被误判的样本放在一起进行新一轮的训练;
s16.循环执行步骤s14、s15,t轮后得到t个最优弱分类器;
s17.以加权求和的方式组合t个最优弱分类器得到强分类器。
优选地,所述人脸样本和非人脸样本使用haar-like特征来表征,并利用计算积分图的方法来加快特征数值的计算。
与现有技术相比,本发明的有益效果是:
(1)通过图像处理技术来对婴幼儿视力进行检测,其误判率低、检测的精度与现有技术相比得到了提高。
(2)通过视力卡展示时段来确定检测时段,达到缩减处理视频的时间、减少计算机处理数据、提高视频检测的实时性的技术效果。
(3)本发明提供的方法首先对人脸脸部进行检测,然后再在检测到的人脸区域中确定眼睛的具体位置,提高了检测的效率。
附图说明
图1为方法的的流程示意图。
图2为筛选式级联分类器的示意图。
图3为hessian矩阵行列式近似值图像与与图像的对比图。
图4为积分图简化的示意图。
图5为surf算法的金字塔图像示意图。
图6为surf算法主方向确定过程的示意图。
图7为haar小波特征的计算示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
如图1所示,本发明提供的方法主要是包括以下步骤:
s1.同步记录出示teller视力卡的视频图像及被检测者的视频图像;
s2.通过出示teller视力卡的视频图像确定视力卡展示窗口位置及相应的视力卡展示时段,并从被检测者的视频图像中提取与视力卡展示时段相应的片段进行步骤s3~s8的操作;
s3.使用adaboost算法训练出对人脸识别效果最优的强分类器;
s4.将强分类器进行级联,得到筛选式级联分类器;
s5.对步骤s2提取的片段进行分解,得到视频帧的集合,然后对集合中的每一帧视频帧进行步骤s6~s7的操作:
s6.使用筛选式级联分类器对视频帧进行检测,确定其人脸区域;
s7.通过surf算法确定人脸区域中的兴趣点位置,然后根据兴趣点邻域的haar小波响应来确定surf描述子;
s8.对视频帧集合中任意相邻的两帧图像的surf描述子进行对比,判断其是否一致,若存在着surf描述子不一致的相邻两帧图像,则判断婴幼儿的眼睛发生了移动;此时通过视力卡对应的条栅级别即可确定婴幼儿的视力水平。
其中,步骤s2中,确定视力卡展示窗口及相应的视力卡展示时段的具体原理如下:
1)确定展示窗口位置并标定
视力卡展示窗口有着自己独特的图像特征,在任意检测视频中,展示窗口的外部上下部分在y轴方向上都是有规律的,即在y轴正方向上展示窗口外的二值图像的像素值由白变为黑,而在y轴反方向上展示窗口外的二值图像的像素值由白变为黑。因此,可以通过图像预处理将原视频帧的右半部分图像变为二值图像,然后假设某一条y轴方向的检测线,只要检测线满足上述条件,便认定此检测线是穿过展示窗口的,为了便于观察,可用白色圆形图案进行标定。
2)确定视力卡展示时段
在窗口位置定位并标定完成后,高效准确地确定teller视力卡展示时段就是当务之急。因为teller视力卡的条栅间隔不同,故在二值图像上效果就不一样,假设此前选取的检测线位置刚好处在teller视力卡黑色条栅处,那么就会出现漏检的情况,为了解决这个问题,选取合适的三条检测线,这样无论teller视力卡的条栅怎样变化,三条检测线中至少有一条是满足条件的。此外,在没有视力卡和展示视力卡两种情况下,展示窗口位置的检测线上的像素差别还是很大的,由此判断视力卡的展示时间。
在具体的实施过程中,所述步骤s3训练强分类器的具体过程如下:
s11.给定的训练样本集共包括n个样本,其中n个样本中包括x个人脸样本和y个非人脸样本;设定训练的最大循环次数t;
s12.初始化各个训练样本的权重为1/n;
s13.第一轮迭代训练n个样本,得到第一个最优弱分类器;
s14.提高上一轮训练中被误判的样本的权重;
s15.将新的样本与上一轮训练中被误判的样本放在一起进行新一轮的训练;
s16.循环执行步骤s14、s15,t轮后得到t个最优弱分类器;
s17.以加权求和的方式组合t个最优弱分类器得到强分类器。
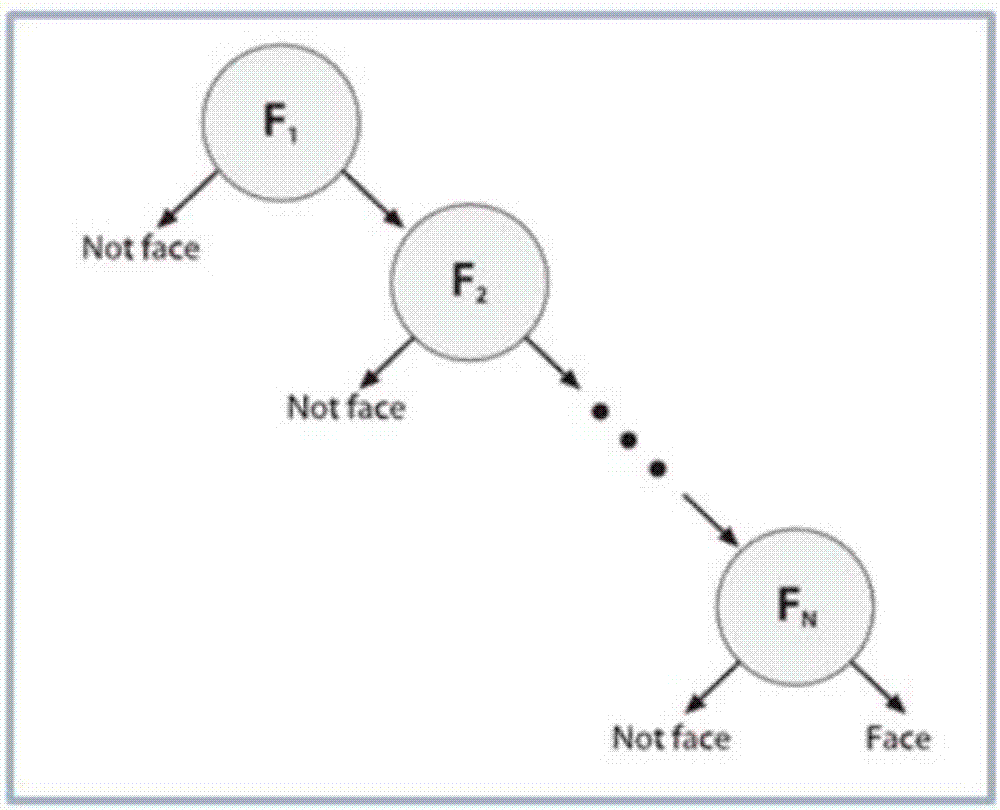
步骤s4中通过瀑布(cascade)算法将分类器的连接方式变为筛选式的级联分类器,级联的每个节点是adaboost训练得到的强分类器,在级联的每个节点设置阈值,其中阈值能使得几乎所有人脸样本都能通过,而绝大部分非人脸样本不能通过。通过分类器级联的方式能够保证高检测率和低拒绝率。一般情况下,高检测率必然会导致高误识率,这是强分类阈值划分引起的,也是强分类阈值划分的局限性所在。检测率和误识率这两者是不可能兼得的事情。但是想要提高强分类器检测率的同时又想要降低误识率可以通过增加分类器个数来实现,即级联强分类器,其示意图如图2所示。
surf算法是herbertbay等人在sift算法的基础上优化而来的,相比sift算法,surf算法具有更快的计算速度,实现了实时处理,其快速的基础就是引入积分图像。surf算法的过程是先通过hessian矩阵的行列式来确定兴趣点位置,再根据兴趣点邻域的haar小波响应来确定描述子。
因为surf算法采用的是hessian矩阵行列式近似值图像,假设图像中某像素点的hessian矩阵如下所示:
为了保证特征点的尺度无关性,需要进行高斯滤波,则滤波后的hessian矩阵如下:
其中lxx(x,σ)表示高斯滤波后图像在x方向上的二阶导数,lxy(x,σ)和
lyy(x,σ)都是图像的二阶导数。一般情况下,为了求取图像的二阶导数,利用公式:
其中h(x)表示图像的灰度值,而f(x)则表示将h(x)进行高斯滤波处理得到的结果。
如图3所示,左边两幅图分别为9x9灰度图像在中心点(黑色点)处的二阶导数d2f(x)/dx2和d2f(x)/dxdy的模板对应的值,近似后变成右边的两幅图,图中灰色部分像素值为0。为了减少计算量,使用积分图进行简化,如图4所示。
其中,灰色部分代表当前像素点,深色部分代表积分区域。
这样计算任意矩形区域的灰度之和sx就可以简化如下:
sx=s(x1,y1)+s(x4,y4)-s(x2,y2)-s(x3,y3)
图像中每个像素点的hessian矩阵行列式的近似值公式为:
det(happrox)=dxxdyy-(0.9dxy)2
其中0.9是一个经验值。如此便可得到一张近似hessian行列式图,而高斯金字塔的每一层octave都有若干张尺度不同的图片。在surf算法中,图片的大小是一直不变的,不同的octave层得到的待检测图片是改变高斯模糊尺寸大小得到的。surf算法采用这种方法节省了降采样过程,处理速度加快,其金字塔图像如下图5所示:
在兴趣点主方向上,surf算法和sift算法也大有不同。sift选取兴趣点附近
在sift算法中,是在特征点周围取16*16的邻域,并分为4*4个的小区域,每个小区域统计8个方向梯度,最后得到4*4*8=128维的向量,并把该向量作为该点的sift描述子。而在surf算法中,在特征点周围取边长为20s(s是所检测到该特征点所在的尺度)的一个正方形框,其方向就是主方向,然后把该框分为16个子区域,每个子区域统计25个像素的水平方向和垂直方向(水平和垂直方向都是相对主方向而言的)的haar小波特征。该过程的示意图如图6所示。在surf算法中每个小区域就有4个值,故每个特征点就是16*4=64维的向量,相比sift算法,特征匹配速度大大加快。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!