一种基于深度学习的人脑MRI海马体检测与分割方法与流程
本发明属于人工智能的辅助分析技术领域,涉及一种mri影像海马体检测与分割技术领域,特别涉及一种基于深度学习的人脑mri海马体检测与分割方法。
背景技术
阿尔茨海默病,又称老年性痴呆,是一种发病隐匿、发展缓慢、并随时间不断恶化的神经系统退行性疾病。常无确切起病时间和起病症状,早期往往不易被发现,一旦发生,即呈不可逆的缓慢进展。研究表明,老年性痴呆是继肿瘤、心脏病、脑血管病之后引起老年人死亡的第四大病因,其治疗花费在所有疾病中排第三位。随着我国人口的老龄化加剧,阿尔茨海默病患者持续增加。目前,我国患者数量居全球之首,而且每年平均有30万新发病例,也是全球增速最快的国家之一。
阿尔茨海默病早期临床表现为海马体萎缩。医生可通过核磁共振技术,对患者脑部进行三维造影,进而通过影像分析进行诊断以及相关治疗方案的设计。在判断海马体是否萎缩时,医生通常需要对海马体结构进行分割,并进行形状和体积分析。然而海马体尺寸小、形状不规则并因人而异,且在常规核磁共振影像下海马体与周边组织结构对比度低,边界不清晰甚至不连续,非具备多年临床经验的影像科医生难以进行精准分割。而我国医患比例极为悬殊,稀缺的医生资源远远无法满足庞大患者群体的需求。且基层医院医疗力量薄弱,医生水平参差不齐,造成大量患者涌向大型三甲医院,进一步加剧医患比例失衡。因此,基于人工智能的辅助分析技术已成为医学界乃至全社会重点关注的问题。
技术实现要素:
为了解决上述技术问题,本发明提供了一种基于深度学习的人脑mri海马体检测与分割方法,解决了现有技术中非具备多年临床经验的影像科医生难以进行精准分割问题。
本发明所采用的技术方案是:一种基于深度学习的人脑mri海马体检测与分割方法,其特征在于,包括以下步骤:
步骤1:mri数据预处理;
步骤2:建立模型结构;
步骤3:初始划分数据集为训练集、验证集和测试集,并确定模型超参数;
步骤4:利用训练集训练模型;
步骤5:判断验证集表现是否达到要求;
若是,则执行步骤6;
若否,则调整超参数后回到步骤4重新训练;
步骤6:重新划分数据集并训练模型。
本申请实施例中提供的基于深度学习的海马体自动检测与分割方法,相比传统人工分割的方法,本发明充分利用历史人工分割结果图像信息,不仅能自动高效检测与分割,更加有利于解决影像科医生稀缺、基层医疗能力薄弱、医患比例悬殊等问题。模型过拟合时,本发明创造性的增加了l2正则项,并加上了正则项超参数,使模型的方差减小,效果有了明显的提高。经过多次实验,我们将网络深度增加至5层,也提升了模型效果。
附图说明
图1为本发明实施例的模型结构图;
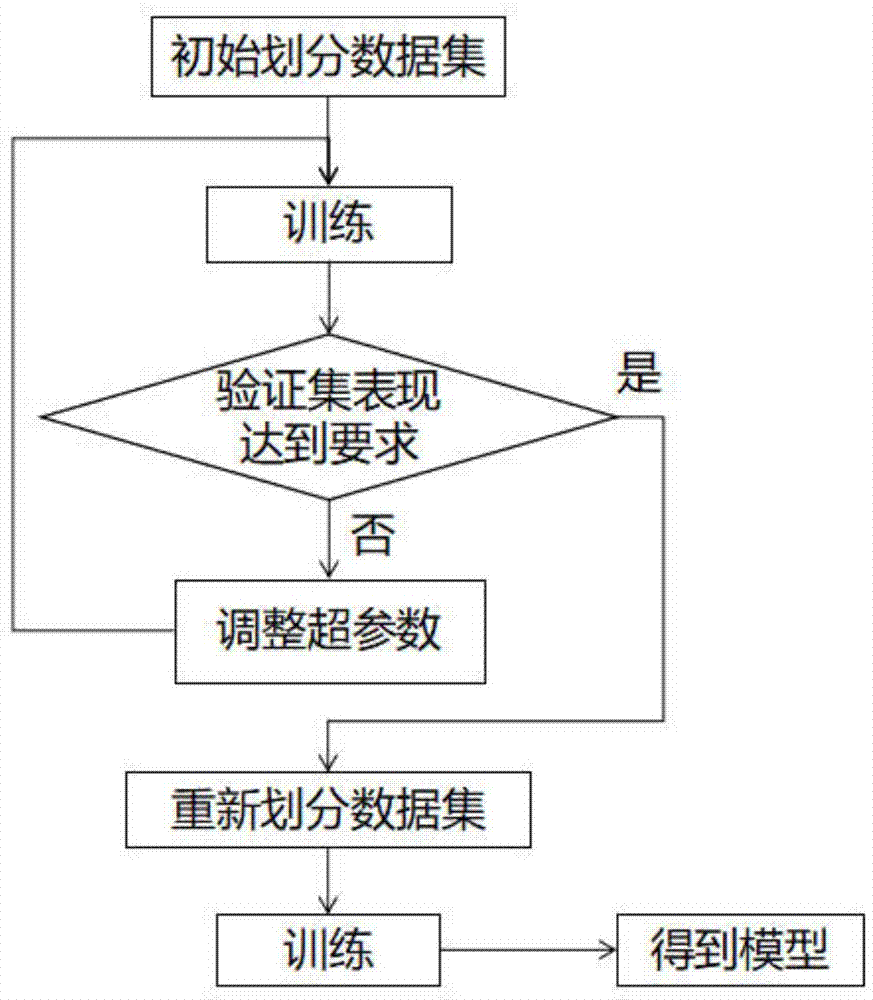
图2为本发明实施例的初始划分数据集流程图;
图3为本发明实施例的重新划分数据集流程图;
图4为本发明实施例的模型结构图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
请见图1,本发明提供的一种基于深度学习的人脑mri海马体检测与分割方法,包括以下步骤:
步骤1:mri数据预处理;
具体实现包括以下子步骤:
步骤1.1:统计mri中大脑海马体与大脑边缘的相对位置关系,得出其中最大海马体包围框;
步骤1.2:数据预处理;
步骤1.2.1:裁掉3个维度上的空白的部分,获得大脑所在位置;
步骤1.2.2:根据步骤1.1的统计结果进行裁剪,裁剪时在最大包围框基础上加δdx、δdy、δdz,其中δd根据所裁剪的图片实际大小确定,保证加上δd以后,图片3个维度上边长为n的倍数,n=2深度-1;加上δd后的最大包围框为该mri的“潜在海马体区”;每张图片包含左、右两个海马体,能裁剪出两个“潜在海马体区”;本实施例n取5;
步骤1.2.3:对上一步得到的数据进行边缘填充,使用0数据填充,并将其尺寸统一为m1×m2×m3,其中m1、m2、m3均为任何不小于预处理后mr图像尺寸的,且为n的倍数的数;本实施例m1×m2×m3取64×80×32;
步骤2:建立模型结构,使用3du-net作为最终模型;请见图4,是步骤2建立模型结构的结果。
步骤3:划分数据集并确定模型超参数;
请见图2,将步骤1中预处理后的数据划分为三部分,50%的数据作为训练集,20%的数据作为验证集,30%的数据作为测试集。
使用3du-net作为最终模型,其超参数包括深度、核基数、l2正则参数、初始学习率、下采样层。具体请见表1;
表1确定的超参数
步骤4:利用训练集训练模型;
步骤5:判断验证集表现是否达到要求;
若是,则执行步骤6;
若否,则调整超参数后回到步骤4重新训练;
使用步骤3中的测试集进行模型评估,并对评估结果dice系数进行统计分析,统计最大值、最小值、平均值、中位数、方差;dice系数最低为0,最高为1;在单个样本上,dice越高说明模型效果越好;多个样本需要统计总体效果,平均值大好、方差小好;如果测试集表现达不到用户要求,则根据经验调整超参数后回到步骤4。
对模型的评估函数使用dice系数(dicecoefficient):
d为dice系数,y为真实值,y'为模型预测值。
dice系数最低为0,最高为1。越高说明模型效果越好。
训练成本函数(costfunction)使用dice成本(diceloss):
是为了方便成本函数收敛而加入的。
步骤6:重新划分数据集并训练模型。
请见图3,具体实现包括以下子步骤:
步骤6.1:重新划分数据集,分为训练集和测试集两部分,90%的数据作为训练集,10%的数据作为测试集;
步骤6.2:部署至配有gpu的计算机进行首次训练,得到模型参数。
本发明还可以使用更多数据进行模型训练,或者使用数据增强的方法来进行数据增强,从而提升模型效果。
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!