一种基于乳腺癌临床高维数据的分层重要特征选择方法与流程
本发明涉及了计算机技术,统计机器学习技术和特征工程技术等领域。
背景技术
乳腺癌是全球女性发病率最高的恶性肿瘤,严重威胁女性健康。乳腺癌患者通常会通过手术,以及化疗等治疗措施进行干预,在治疗过后随时可能面临着复发的风险。科学地评估预测乳腺癌患者生存状态可以辅助医生制定恰当的治疗计划,为降低患者复发风险和改善预后提供新的支撑。
实现评估预测乳腺癌患者生存状态,比如无复发生存率,可以基于乳腺癌临床数据建立机器学习预测模型。然而,临床数据质量很大程度上决定了预测模型的表现。真实世界下,乳腺癌患者的临床数据,一般包括患者基本信息、诊断病史、病理、手术、化疗、放疗、内分泌治疗和靶向治疗等信息。这些数据特征维度较高,而且通常存在数据的缺失、异常、重复和不一致的问题,所以需要对真实世界下的原始临床数据进行清洗,以确保数据质量。
数据清洗无法解决乳腺癌临床数据高维度的问题。而对高维特征数据进行特征工程、降维处理有很大的必要性,主要表现在以下两个方面:
(1)预测模型实用性。预测模型在嵌入乳腺癌患者预后评估系统后,需要医生或患者输入预测相关的必要信息。这些信息将作为模型输入特征取值进入预测模型,最后系统才能根据输入信息进行有效预测。输入特征过多,将耗费患者或医生精力及时间,这大大降低了预测模型的实用性。
(2)预测模型性能。事实上,特征工程被用来鉴定和移除不需要的,不相关的和冗余的属性,这些属性并不能提高预测模型的性能,或者可能事实上降低模型的性能。实际问题中,我们需要更少的特征,因为它能够降低模型的复杂度,而且一个更简单的模型能够被更简单的理解和解释。
因此,为构建实用且高性能的预测模型,重点在于对临床高维数据进行特征工程处理,以筛选出对乳腺癌无复发生存有重要影响的特征,从而达到辅助医生诊断,降低患者复发风险和改善预后的目的。
高维数据特征选择方法总体来可分为以下几种:
(1)单因素分析方法。对每个因素单独进行分析,通过统计检验的方法确定该因素是否对目标变量有显著影响。该方法只能简单地排除掉少量不相关的特征,忽略了特征之间的交互作用。
(2)特征重要性分析方法。使用某个基学习器(如cart或随机森林)拟合训练数据,得到每个特征的重要性评分,排除掉重要性评分为0的特征。该方法可以排除掉不相关的特征,但是往往最终选择的特征维度依旧较高,无法尽可能降低数据特征维度。
(3)递归特征消除方法。由guyon等人提出。该方法在特征重要性分析方法的基础上逐个地递归消除重要性较低的特征,逐次计算基学习器在新的特征集上的表现,并且重新计算每个特征的重要性评分,作为下一次特征消除的依据。最终选择表现最好的特征集。该方法在真实高维数据场景下,对计算资源和时间要求较高,而且基学习的选择以及特征重要性评分的不稳定性往往对结果有很大影响。
高维数据特征选择方法,要求在保证模型性能以及可接受时间复杂度的条件下,排除掉冗余或者不相关的特征,尽可能减少最终选择的特征数量。因此,如何在高维数据中选择重要特征,是国内外科研工作者需要重点思考的问题。
技术实现要素:
本发明目的是针对建立乳腺癌生存预测模型中临床数据维度过高的问题。利用统计特征选择和集成特征选择相结合的分层特征选择方法,解决重要特征提取和模型实用性的问题。
本发明的基于乳腺癌临床高维数据的分层重要特征选择方法,包括以下步骤:
统计特征选择处理:
对原始临床数据进行特征提取并进行清洗处理,得到原始特征集合fn;
计算原始特征集合fn中的每个维度的特征fi的显著性值;
由显著性值小于预设阈值的特征fi构成统计特征集合fm;
集成特征选择处理:
获取统计特征集合fm中的各特征fi的重要性评分均值
基于预设的重要性评分阈值,由统计特征集合fm中的重要性评分均值
进一步的,特征fi的显著性值的计算方式具体为:
基于特征fi的特征属性采用不同的度量方式计算特征fi的显著性值;
对于特征属性为分类变量的特征fi,首先判断特征fi是有序分类变量还是无序分类变量,若特征fi为有序分类变量,则采用mann-whitneyu检验计算特征fi的显著性值(p值);若特征fi是无序分类变量,则采用卡方检验计算特征fi的显著性值;
对于特征属性为连续变量的特征fi,首先采用ks检验(kolmogorov-smirnovtest)特征fi的分布是否服从正态分布,若服从正态分布,则采用独立样本的t检验(one-samplesttest)计算特征fi的显著性值;否则,使用mann-whitneyu检验计算特征fi的显著性值。
进一步的,重要性评分阈值的优选设置方式为:
初始阈值设置为0,采用向后特征选择法,逐步有选择地增加阈值,得到对应阈值下特征集合,并对每个阈值对应特征集合,建立梯度提升树模型,得到模型在测试集上的评估指标值,在满足与最大评估指标值之差在可接受范围内的所有对应特征集合中,选择特征数最少的特征集合对应阈值作为特征重要性评分阈值。
本发明方法充分运用分层特征选择,逐层筛选。在不影响乳腺癌模型性能的情况下,尽量选择包含较少特征的重要特征组合。该方法具有以下优势:
(1)使用统计特征选择找出对结局变量具有显著影响的单维特征,排除了显著不相关的单个特征对最终预测模型性能可能带来的影响;
(2)使用梯度提升树作为基学习器,能够很好地处理多维数据特征间的相互影响。从而充分学习数据特征的概率空间,确保了对重要特征评分的准确性;
(3)采用多次试验求取重要性评分均值,屏蔽了机器学习中偶然随机数选择事件的影响,从而确保了重要性评分的可靠性及稳定性;
(4)有选择地选取重要性评分阈值,而不是逐个消除特征,降低了特征选择的时间以及计算资源的消耗;
(5)在模型性能损失可接受范围内选择最简单的特征集,确保了构建预测模型的性能以及实用性。
因此,本发明有比较明显的优势和较广泛的适用场景。
附图说明
图1为本发明的基本处理流程图;
图2为本发明的统计特征选择流程图;
图3为本发明的集成特征选择流程图;
图4为集成特征选择的阈值设置示意图;
图5为本发明的应用的实现过程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
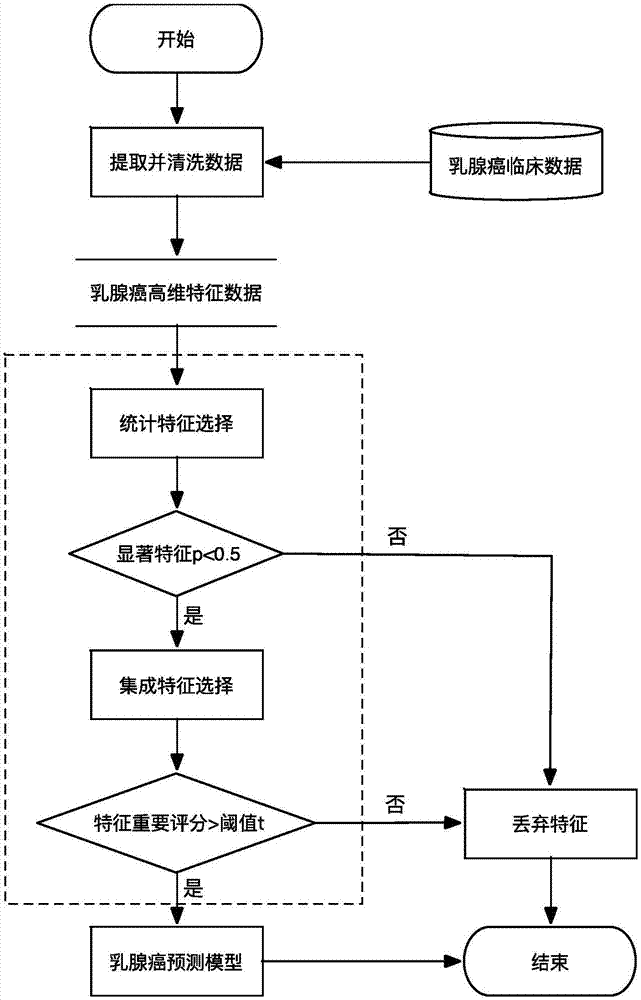
参见图1,本发明的面向乳腺癌临床高维数据的分层重要特征选择方法,包括了统计特征计算、集成特征计算以及集成特征计算中的所涉及的阈值设置方式。本发明利用统计特征选择和集成特征选择相结合的分层特征选择方法,可有效地解决重要特征提取和模型实用性等问题。其具体实现过程如下:
s1:统计特征选择。
对原始临床数据进行特征提取并进行清洗处理,得到原始特征集合fn;并计算原始特征集合fn中的每个维度的特征fi的显著性值,由显著性值小于预设阈值的特征fi(下标为维度标识符)构成统计特征集合fm。参见图2,其执行过程如下:
s101:对乳腺癌临床数据进行特征提取并进行清洗处理,得到原始特征集合fn,遍历fn中的每个维度的特征fi,判断该特征fi的特征属性,即判断特征fi是属于分类变量还是连续变量,若属于分类变量,则执行步骤s102;若属于连续变量,则执行步骤s104。
s102:若特征fi属于分类变量,则再判断其是属于有序分类变量还是无序分类变量。
s103:如果特征fi是有序分类变量,则对其使用mann-whitneyu检验计算p值;如果特征fi是无序分类变量,则对其使用卡方检验计算p值。再跳转到s106执行。
s104:如果特征fi是连续变量,则对其使用ks检验特征fi分布是否服从正态分布。
s105:若服从正态分布(例如p>0.05,则认为服从正态分布),则对其使用独立样本的t检验计算p值;否则,使用mann-whitneyu检验计算p值;
s106:如果特征fi统计检验p值小于0.05,则将特征fi加入已选择特征集合fm,即统计特征集合fm,其中fm的初始值为空集。
s2:集成特征选择。
对得到的统计特征集合fm,应用梯队提升树学习方法,进一步筛查重要特征,参见图3,执行过程如下:
s201:对统计特征集合fm进行重要性评分:
使用包含统计特征集合fm的训练数据,建立梯度提升树模型。经过模型参数调节及训练,输出统计特征集合fm中的各特征的重要性评分scorei。
s202:获取重要性评分均值
设置不同的随机数种子,重复步骤s201实验t次(本具体实施方式中,设置为100次),最终对t次实验结果取平均得到统计特征集合fm中的各特征的重要性评分均值
s203:设置特征重要性评分阈值:
统计特征集合fm中的各特征(元素)按重要性评分均值从小到大排序,构成初始候选特征集合fh;再对初始候选特征集合fh采用向后向特征选择法获取特征重要性评分阈值。参见图4,实现过程如下:
(1)设置初始阈值threshold为0。
(2)设置阈值增长的随机步长或固定步长step(观察重要性评分均值),得到每步阈值thresholdd下的候选特征集fhd,其中thresholdd=thresholdd-1+step,threshold0=0,步标识符j的初始值为1;候选特征集fhd为基于阈值thresholdj对初始候选特征集合fh筛选后的特征:若初始候选特征集合fh中的特征fi的重要性评分均值
(3)更新步标识符d=d+1,继续计算thresholdd,以及候选特征集fhd,直到达到预设的最大步数(本具体实施方式中设置为10)。此步骤的结束条件也可以是当前候选特征集fhd为空集;亦或是直到thresholdd等于或大于初始候选特征集合fh中最末端的特征的重要性评分均值。
(4)上述步骤得到的多个非空的候选特征集fh1,fh2,…,使用包含候选特征集fhj的训练数据,建立梯度提升树模型,其中下标j为非空集的候选特征集的标识符。
(5)对各梯度提升树模型的参数进行调节及训练,得到模型在独立测试集上的评估指标值vj,基于实际需求设置对应的评估指标。
(6)最终选择特征重要性评分阈值
其中δ表示预设的偏差阈值,依据实际情况选取,即在满足与最大评估指标值之差在可接受范围δ内的所有特征集合中,选择特征数|fhj|最小的特征集合对应的阈值
s204:选择重要特征。
由统计特征集合fm中的重要性评分均值大于等于阈值threshold的特征得到重要特征集合fe。
将本发明的特征选择方法应用到乳腺癌预测系统中,其具体应用实现过程示意图如图5所示,包括训练和预测两个阶段,其中训练过程具体为:在数据预处理模块中,基于乳腺癌患者的历史数据,经过抽取和整理后,将其分为人口学特征、诊断特征、病理特征和治疗特征。这些特征将整体输入到统计特征选择处理模块中,初步筛选出从统计学上来说不具有统计显著性的特征。然后,将筛选出的统计特征数据输入到集成特征选择处理模块中,基于反复试验、调参数和性能比较所设置的满足需求的阈值和特征评估分值,将小于阈值的特征剔除掉。由此,得到了具有较强统计学和模型辨别能力的最终特征(重要特征),达到了降维的目的。以降维后的特征为输入,构建乳腺癌预测机器学习模型。
在预测阶段,对某个患者(预测对象),基于训练阶段所筛选出的重要特征,从患者的乳腺癌临床数据中提取对应重要特征的那些特征数据,并输入到乳腺癌预测模型,基于预测结果输出患者的疾病状态。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
- 还没有人留言评论。精彩留言会获得点赞!