一种利用颈部振动的人工智能发声系统及其发声方法与流程
本发明涉及医学仪器领域,具体涉及一种利用颈部振动的人工智能发声系统及其发声方法。
背景技术
全喉切除术后的患者在肿瘤被切除的同时,平时发音的声带也被切除,导致正常的语言交流功能丧失,生活质量大大下降。目前主要的解决方法是让患者使用电子喉,将电子喉的振动头端放置于喉部下方进行发声。这种方式有两个缺点。一是电子喉的声音属于金属音,听起来不自然;二是患者使用时需要用手握住电子喉,同时抵住喉部,使用起来不方便。
技术实现要素:
针对上述不足,本发明提供了一种利用颈部振动的人工智能发声系统及其发声方法,采集特定患者的颈部振动信号,利用人工智能技术进行信号的判别,并通过电子发声器发声;同时采用无线模块发射和接收振动信号,将传感器和电子发声器分离,减少医疗装置对喉部的压力。本发明的技术方案为:
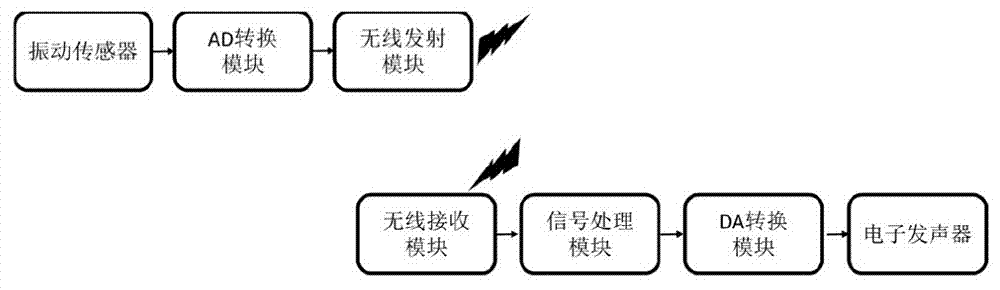
一种利用颈部振动的人工智能发声系统,包括:振动传感器、ad转换模块、无线发射模块、无线接收模块、信号处理模块、da转换模块和电子发声器;
振动传感器,用于采集特定患者的颈部振动信号;
ad转换模块,用于将采集到的振动模拟信号转换成数字信号;
无线发射模块,用于将数字信号转换成无线电波进行发射;
无线接收模块,用于接收无线电波,并将电波信号转换成数字信号;
信号处理模块,利用人工智能技术分析每次振动信号所代表的语音信息,并输出分析结果信号;
da转换模块,用于将分析结果信号转换成模拟信号;
电子发声器,用于将模拟信号转换成声音;
所述的振动传感器包括:电感式振动传感器、电容式振动传感器、压电式振动传感器、电阻应变式振动传感器。
所述的无线发射模块和无线接收模块包括:蓝牙模块、zigbee模块、wifi模块。
一种利用颈部振动的人工智能发声方法,包括以下步骤:
s1.网络模型训练:
s11.采集颈部振动信号;
s12.对振动信号进行语音信息标记,形成语音标签;
s13.对振动信号进行数据预处理,形成输入数据;
s14.重复上述步骤k次,采集k组信号
s15.将输入数据和语音标签输入深度神经网络进行训练,生成网络模型;
s2.语音信息预测
s21.采集颈部振动信号;
s22.对振动信号进行数据预处理,形成输入数据;
s23.利用训练好网络模型对输入数据进行语音类别的预测,输出分析结果;
s24.将分析结果信号转换成模拟信号,输入电子发声器进行发声。
本发明与现有技术相比具有以下优点:
1、与现有技术相比,本发明利用人工智能技术进行神经网络训练,这种定制化方法训练出来的网络模型可以大大地提高预测语音信息的准确率;而且使用电子发声器发声,让声音听起来更自然。
2、与现有技术相比,本发明采用无线模块发射和接收振动信号,将传感器和电子发声器分离,减少了医疗器械给患者带来的不便,具有更高的便携性和实用性。
附图说明
图1是本发明的系统框图。
图2是本发明实施例采集到的振动信号示例。
图3是本发明实施例时域频谱图转换结果。
图4是本发明提出的深度网络架构图。
具体实施方式
下面结合附图并通过实施例对本发明作进一步的详细说明,以下实施例是对本发明的解释,而本发明并不局限于以下实施例。
如图1所示,本实施例提供了一种利用颈部振动的人工智能发声系统,包括:振动传感器、ad转换模块、无线发射模块、无线接收模块、信号处理模块、da转换模块和电子发声器;
振动传感器,用于采集特定患者的颈部振动信号;本实施例采用微型振动传感器csx-sen-180a。它是一款可全方位振动感知、倾斜感应或运动检测的多功能微型振动传感器,以其高灵敏度来感知外界环境的变化。静止时,传感器一般处于接通状态,当发生震动或位移时,传感器会产生连续的脉冲信号来唤醒单片机,可通过软件设置调节灵敏度。
ad转换模块,用于将采集到的振动模拟信号转换成数字信号;本实施例采用ad7705ad转换模块。ad7705适用于低频测量,它能将从传感器接收到的很弱的输入直接转换成串行数字信号输出,而无需外部仪表放大器。采用σ-δ的adc,实现16位无误码的良好性能,片内可编程放大器可设置输入信号增益。通过片内控制寄存器调整内部数字滤波器的关闭时间和更新速率,可设置数字滤波器的第一个凹口。
无线发射模块,用于将数字信号转换成无线电波进行发射;无线接收模块,用于接收无线电波,并将电波信号转换成数字信号;信号处理模块,利用人工智能技术分析每次振动信号所代表的语音信息,并输出分析结果信号;
本实施例采用集信号处理器和蓝牙无线模块为一体的hy-40r204p。hy-40r204p提供蓝牙低功耗特性:无线电,蓝牙协议栈,配置文件和客户应用程序所需的空间,还提供灵活的硬件接口,用于连接ad模块。hy-40r204p拥有可编程arm-cortex-m3处理器。本实施例采用基于c语言的深度网络框架,在单片机上实现神经网络计算功能。
da转换模块,用于将分析结果信号转换成模拟信号;本实施例采用ad420转换模块。ad420采用σ-δ(sd)dac技术,以非常低的成本实现了16位单调性。满量程0.1%建立时间不超过3ms。
电子发声器,用于将模拟信号转换成声音;本实施例电子发声器采用ask-515。
本实施例采用的人工智能发声方法包括以下步骤:
s1.网络模型训练:
s11.采集颈部振动信号;
采集患者发声时喉部的振动信号,采样2000个数据点;并将每组信号均分成40组,每组50个数据点;
s12.对振动信号进行语音信息标记,形成语音标签;
用y={y1,y2,...,ym,...,yi}来记录每个语音标签样本,其中ym是一个i维的one-hot编码向量,本例中i=1000;
s13.对振动信号进行数据预处理,形成输入数据;
数据预处理方法采用短时傅里叶变换法,将40组一维的振动信号转换成二维的时域频谱图,其所用的公式如下:
其中,z(t)是信号源,g(t)是窗函数,stft是时域频谱转换结果。转换结果如图3所示。时域频谱图的大小是100x100x3。
s14.重复上述步骤k次,采集k组信号
s15.将输入数据和语音标签输入深度神经网络进行训练,生成网络模型;网络模型架构如图4所示。将步骤s13的40个时频图作为网络输入,然后经过cnn卷积模块和lstm长短时记忆模块进行特征提取。训练时每个batch个数是20,cnn模块包含2个卷积层和池化层,长短时记忆模块包含2个lstm层。
s2.语音信息预测
s21.采集颈部振动信号;
s22.对振动信号进行数据预处理,形成输入数据;
s23.利用训练好网络模型对输入数据进行语音类别的预测,输出分析结果;
s24.将分析结果信号转换成模拟信号,输入电子发声器进行发声。
本说明书中所描述的以上内容仅仅是对本发明所作的举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离本发明说明书的内容或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!