基于逻辑Petri网的循环并发结构的过程模型修正方法与流程
本发明涉及循环并发结构的过程模型修正领域,具体涉及一种基于逻辑petri网的循环并发结构的过程模型修正方法。
背景技术:
过程挖掘是从事件日志中提取与过程相关的信息,去发现、监控和改进实际过程。现有的过程挖掘技术有过程发现、一致性检测和过程改进。过程发现是根据事件日志生成过程模型;一致性检测是将过程模型与其对应的事件日志进行对比,将事件日志在过程模型上重演从而检查其合规性;过程改进是利用实际过程产生的日志去扩展或改进已有过程模型。目前,已存在很多过程发现算法,α算法是利用活动的顺序关系发现过程模型,其前提是日志的次序关系必须是完备的。现有文献针对α算法进行了很多改进,其中一个文献解决了α算法不能有效挖掘不可见变迁,另外一个文献解决了非自由选择结构问题。启发式挖掘算法针对因果网描述的过程模型,考虑了事件和序列的频次。基于状态的区域发现算法通过寻找并发结构,发现对应的库所区域,使用变迁系统作为输入;基于语言的区域的过程发现寻找同样的库所,但使用“语言”作为输入。
评估过程模型质量时,主要考虑4个维度:拟合度、简洁度、精确度和泛化度。拟合度是指事件日志在过程模型上的重演能力,如果模型可以重演日志中所有迹,那么其拟合度是理想的,现实中理想情况微乎其微,不论是过程发现还是模型修正都在尽力提高模型拟合度,拟合度是评价模型质量最重要的指标;简洁度是指模型结构的简洁与否;精确度是模型不允许生成除给定事件日志记录之外的迹,只能重演事件日志中的迹;泛化度是预测未来迹的发生情况。
常见的一致性检测有托肯重演、足迹对比和校准等。通过一致性检测可以发现事件日志与过程模型之间存在的偏差,从而对过程模型进行扩展或修正,使模型更符合现实。通过对事件日志和过程模型进行校准,根据校准序列的日志动作、模型动作和同步动作可以精确定位偏差。fahland模型修正方法在校准基础上,将存在偏差的不拟合子日志进行收集,并将可以描述不拟合子日志的自环插入原模型。fahland修正方法,提高了模型拟合度,但是修正模型允许子过程可以多次重复出现,导致模型精度降低,复杂性提高。目前,已存在很多提高模型精确度的修正方法,针对某一特定结构,对模型进行高精确度修正。基于petri网的修正方法,通过包含循环结构的事件日志,对模型进行修正,不能很好地修正活动之间的逻辑关系。而逻辑petri网可以很好的解决这类问题。
逻辑petri网是高级petri网和抑制弧petri网的抽象与扩展,其变迁的输入、输出受逻辑表达式限制。逻辑petri网可以提高模型简洁度,描述活动之间的逻辑关系,并能很好地描述实时协同工作系统模型的网结构。
技术实现要素:
本发明的目的是针对模型中的循环并发结构,提出一种基于逻辑petri网的循环并发结构的过程模型修正方法。根据过程树,提出并发变迁集概念,通过连续日志动作的标识库所集与相应变迁前集之间的关系,进行偏差定位,根据逻辑petri网,对模型进行动态修正。
本发明采用以下的技术方案:
一种基于逻辑petri网的循环并发结构的过程模型修正方法,包括以下步骤:
定义校准
设a∈λ,σ∈a*是a上的一条迹,且pn=(p,t;f,m)。(a,t)∈(a∪{>>})×(t∪{>>})是一个动作,校准γ=(a1,t1)(a2,t2)…(a|γ|,t|γ|)是迹σ和模型pn之间的动作队列,且满足:
①π1(γ)=σ,即迹中的动作序列产生迹σ;
②mi[π2(γ)>mf,即模型中的动作序列产生一个完整的引发序列;
其中,若a∈a且t=>>,则为日志动作;若a=>>且t∈t,则为模型动作;若a∈a且t∈t,则为同步动作;否则为非法动作;
γσ,pn是迹σ和模型pn之间所有校准的集合;
定义最优校准
设a∈λ,σ∈a*是a上的一条迹,且pn=(p,t;f,m),称γ∈γσ,pn为迹σ和模型pn之间的最优校准,当且仅当对
γσ,pn,lc是迹σ、模型pn与可能性代价函数lc之间的最优校准集合,最优校准存在一个或者多个;
定义过程树
设a∈λ,pn=(p,t;f,m)是一个petri网,
①a∈a∪{τ}是一个过程树;
②设pt1,…,ptn(n>0)是过程树,则
操作符集
步骤1:对普通扩展校准、普通最优扩展校准、逻辑扩展校准和逻辑最优扩展校准进行定义;
定义普通扩展校准
设a∈λ,σ∈a*是a上的一条迹,且pn=(p,t;f,m);
(a,t,p|set)∈(a∪{>>})×(t∪{>>})×{m|pset}是一个动作,普通扩展校准β=(a1,t1,p1|set)(a2,t2,p2|set)…(a|β|,t|β|,p|β||set)是动作队列,且满足:
①γ是迹σ和模型pn之间的校准;
②m0是初始标志,存在m0[σ′>mi,σ′为从π2(γ)模型活动的第1个变迁开始到第i个变迁之间的一条迹,0<i≤|γ|;
③mi|pset为mi状态下所有存在托肯的库所集,称为标识库所集;
γσ,pn,m|pset是迹σ、模型pn与标识库所集m|pset之间所有普通扩展校准的集合;
定义普通最优扩展校准
设a∈λ,且pn=(p,t;f,m),称β∈γσ,pn,m|pset为迹σ、模型pn与标识库所集m|pset之间的普通最优扩展校准,当且仅当对于
γσ,pn,m|pset,lc是迹σ、模型pn、标识库所集m|pset与可能性代价函数lc之间的普通最优扩展校准的集合,最优扩展校准存在一个或者多个;
定义逻辑扩展校准
设a∈λ,σ∈a*是a上的一条迹,lpn=(p,t;f,m)是a上的一个逻辑petri网,(a,t,p|set)∈(a∪{>>})×(t∪{>>})×{m|pset}是一个动作,逻辑扩展校准βl=(a1,t1,p1|set)(a2,t2,p2|set)…(a|βl|,t|βl|,p|βl||set)是动作队列,且满足:
①γσ,lpn是迹σ和模型lpn之间的校准;
②mi|pset为mi状态下所有存在托肯的库所集,称为标识库所集;
γσ,lpn,m|pset是迹σ、模型lpn与标识库所集m|pset之间所有逻辑扩展校准的集合;
定义逻辑最优扩展校准
设a∈λ,lpn=(p,t;f,m)是a上的一个逻辑petri网,称βl∈γσ,lpn,m|pset为迹σ、模型lpn与标识库所集m|pset之间的逻辑最优扩展校准,当且仅当对于
γσ,lpn,m|pset,lc是迹σ、模型lpn、标识库所集m|pset与可能性代价函数lc之间的逻辑最优扩展校准的集合;
步骤2:进行循环并发结构的静态模型修正;
当过程模型描述的行为与事件日志记录的行为之间存在偏差时,为了使模型能重演日志中记录的行为,需要对现有模型进行修正;通过计算连续日志动作集合,遍历普通最优扩展校准定位偏差,对模型进行静态修正;
下面给出计算连续日志动作集合算法,通过算法1,得到最优扩展校准中的连续日志动作;
算法1计算连续日志动作集合算法
输入:petri网pn=(p,t;f,m),普通最优扩展校准γσ,pn,m|pset,lc;
输出:连续日志动作集合cl;
步骤(1):初始化连续日志动作集合cl;
步骤(2):遍历γσ,pn,m|pset,lc,若存在连续的日志动作{(ai,>>,pi|set),…,(aj,>>,pj|set)},且ai和aj分别为网模型并发块的首尾活动;
步骤(3):将符合条件的连续日志动作的添加到变迁{ai,…,aj}添加到cl集合中;
步骤(4):输出连续日志动作集合cl。
计算连续日志动作集合之后,需要通过定位偏差来确定偏差位置,给出算法2,能静态定位日志和模型之间的偏差;
算法2静态偏差定位算法
输入:连续日志动作集合cl,普通最优扩展校准γσ,pn,m|pset,lc;
输出:偏差位置d(pn|set,tn);
步骤(1):初始化偏差位置d(pn|set,tn);
步骤(2):遍历γσ,pn,m|pset,lc,若连续日志动作集合cl在普通最优扩展校准中已完整出现且发生,则pn|set为连续日志动作的首变迁ai的标志库所集,tn为首变迁ai;
步骤(3):将得到的(pn|set,tn)并到d(pn|set,tn)集合中;
步骤(4):输出偏差位置d(pn|set,tn)。
根据偏差位置,及逻辑petri网,给出静态模型修正算法;
算法3静态模型修正算法
输入:静态偏差定位d(pn|set,tn),petri网pn=(p,t;f,m);
输出:修正后的逻辑petri网lpn′=(p′,t′;f′,i′,o′,m′);
步骤(1):初始化修正模型lpn′为原模型;
步骤(2):调用算法1和算法2得到偏差位置d(pn|set,tn);
步骤(3):在模型中添加pn|set到tn的弧;
步骤(4):根据lpn挖掘算法挖掘变迁的触发条件,得到新的逻辑变迁ai′,并将ai′添加到模型中;
步骤(5):输出修正后的逻辑petri网lpn′。
步骤3:进行循环并发结构的动态模型修正;
当连续日志动作在普通扩展校准中并未完整出现时,根据逻辑petri网,动态的确定偏差位置并对模型进行修正,相对于静态模型修正,动态模型修正较复杂,在偏差定位之前,需获得模型的并发变迁集,以便于准确定位偏差,根据过程树概念,引入并发变迁集概念;
操作符:→代表顺序关系,∧代表并行关系,在过程树中,叶子结点为petri网模型的变迁,非叶子结点为操作符;
遍历过程树,若存在操作符∧的左(右)子树为叶子结点,则n.lchild.child=null(n.rchild.child=null)。若右(左)子树不为叶子结点,则n.rchild.child≠null(n.lchild.child≠null),每一个右(左)子树的后续叶子结点n.rchild.p(n.lchild.p)都与该操作符∧的叶子结点n.lchild(n.rchild)为并发变迁对(ta,tb);
定义模型中并发变迁集
设a∈λ,且pn=(p,t;f,m),pt是petri网的过程树,并行变迁对(ta,tb)满足:
①
②若n∈pt且n=“∧”,n的左子树n.lchild不为叶子结点,n的右子树n.rchild为叶子结点,n.lchild.p为子树n.lchild的后续叶子结点,则ta=n.lchild.p且tb=n.rchild;
③若n∈pt且n=“∧”,n的左子树n.lchild为叶子结点,n的右子树n.rchild不为叶子结点,n.rchild.p为子树n.rchild的后续叶子结点,则ta=n.rchild.p且tb=n.lchild。
根据并发变迁集的概念,下面算法4给出寻找并发变迁集方法,输入pn对应的过程树pt,输出并发变迁集cts,模型中的并发变迁集cts为所有并发变迁对(ta,tb)的集合,cts用于寻找偏差位置;
算法4寻找并发变迁集算法
输入:过程树pt;
输出:并发变迁集cts;
步骤(1):初始化并发变迁集cts;
步骤(2):当过程树pt中的结点n不为空时进行步骤(3)~(5);
步骤(3):若n为操作符∧,且左子树n.lchild不为叶子结点,右子树n.rchild为叶子结点,则左子树的后续叶子结点和右子树为一组并发变迁对(n.lchild.p,n.rchild),并添加到并发变迁集cts中;
步骤(4):若n为操作符∧,且右子树n.rchild不为叶子结点,左子树n.lchild为叶子结点,则右子树的后续叶子结点和左子树为一组并发变迁对(n.rchild.p,n.lchild),并添加到并发变迁集cts中;
步骤(5):寻找下一个结点;
步骤(6):输出并发变迁集cts。
在模型中不存在自环结构时,动态定位偏差并修正模型的算法为:
算法5动态的偏差定位与模型修正算法
输入:连续日志动作集合cl,普通最优扩展校准γσ,pn,m|pset,lc,petri网pn=(p,t;f,m),并发变迁集cts;
输出:修正后的逻辑petri网lpn′=(p′,t′;f′,i′,o′,m′);
步骤(1):初始化偏差位置d(pn|set,tn);
步骤(2):初始化修正模型lpn′为原模型;
步骤(3):将收集的连续日志动作cl遍历普通最优扩展校准β,若未完整出现且发生,则到步骤(4),否则退出;
步骤(4):若连续日志动作首变迁first(cl)的前集属于first(cl)的标志库所集,则first(cl)使能,到步骤(10),否则到步骤(5);
步骤(5):若first(cl)和模型pn的任一变迁不属于cts中任一变迁对,则pn|set为first(cl)的标志库所集,tn为first(cl),pm|set是需要同pn|set比较的库所集,pm|set为tn前集;
步骤(6):若first(cl)存在并发变迁s,且连续日志动作中不包含s,则pn|set为first(cl)的标志库所集,tn为first(cl),pm|set为tn前集;
步骤(7):若first(cl)存在并发变迁s,且连续日志动作中包含s,则pn|set为first(cl)的标志库所集,去掉包含于first(cl)前集的库所,去掉含于并发变迁s前集的元素,tn为first(cl),pm|set为first(cl)前集和s前集的交集,去掉含于first(cl)标志库所集的元素;
步骤(8):将pn|set到tn的弧添加到模型中;
步骤(9):根据lpn挖掘算法挖掘变迁的触发条件比较pm|set和pn|set之间逻辑关系,得到逻辑变迁first(cl)′,并将first(cl)′添加到模型中;
步骤(10):更新first(cl)的标志库所集,将其赋值给cl第二个变迁的标志库所集,并在cl中去掉首元素;
步骤(11):输出修正后的逻辑petri网lpn′。
本发明具有的有益效果是:
本发明针对循环并发结构,提出了基于逻辑petri网的循环并发结构的过程模型修正方法,首先,通过添加标识库所集,给出普通/逻辑最优扩展校准,之后,根据连续日志动作在最优扩展校准中是否完整出现,分为静态或动态模型修正。静态模型修正是直接根据连续日志动作的标识库所集与相应变迁前集之间的关系,进行偏差定位,并根据逻辑petri网进行静态模型修正。动态模型修正相对复杂,根据过程树,提出并发变迁集,通过连续日志动作的标识库所集与相应变迁前集之间的关系,进行偏差定位,并根据逻辑petri网进行动态模型修正。基于逻辑petri网动态修正模型简洁度更高,可以更好的描述活动之间的逻辑关系,在保持高拟合度的同时,提高了精确度。
附图说明
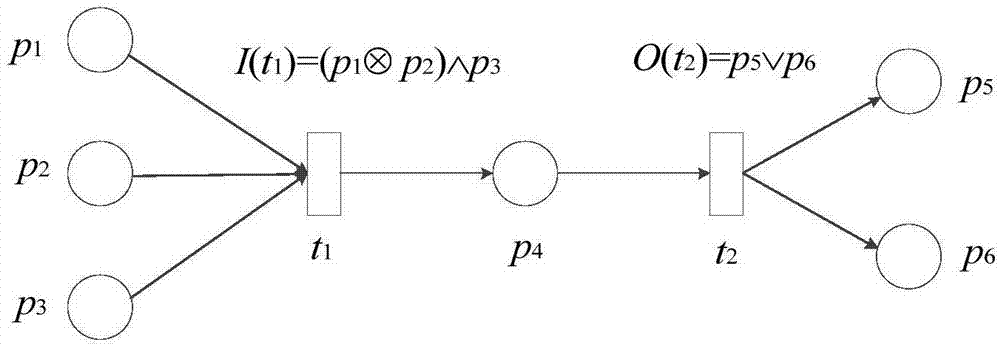
图1为逻辑petri网模型图。
图2为ɑ算法挖掘出的petri网模型pn1图。
图3为迹σ6的普通最优扩展校准β1。
图4为静态方法修正的模型。
图5为pn1对应的过程树pt1。
图6为迹σ7的普通最优扩展校准β2。
图7为动态方法修正的模型。
图8为医院肿瘤科业务流程。
图9为基于fahland方法修正的就诊模型。
图10为基于goldratt方法修正的部分就诊模型(1)。
图11为基于goldratt方法修正的部分就诊模型(2)。
图12为基于knapsack方法修正的部分就诊模型(1)。
图13为基于knapsack方法修正的部分就诊模型(2)。
图14为基于逻辑petri网动态模型修正的就诊模型。
图15为拟合度变化图。
图16为精确度变化图。
具体实施方式
下面结合附图和具体实施例对本发明的具体实施方式做进一步说明:
定义迹,事件日志
令λ为所有活动名称的集合,a∈λ为活动集,迹σ是一个活动序列,即σ∈a*。事件日志l是a上迹的一个多重集,即l∈b(a*)。
定义petri网
四元组pn=(p,t;f,m)称为一个petri网,当且仅当:
①n=(p,t;f)为一个网,其中p是有限库所集,t是有限变迁集,
②
③pn具有下面的变迁发生规则:
a.对t∈t,若
b.若m[t>,则在m下,t可以发生,从m引发t得到一个新的标识m′,记作m[t>m′,且对
其中·t表示变迁t的前集,t·表示变迁t的后集。
定义逻辑petri网
六元组lpn=(p,t;f,i,o,m)称为一个逻辑petri网,当且仅当:
①p是一个有限库所集;
②t=td∪ti∪to是一个有限变迁集,
a.td表示petri网中的变迁集;
b.ti表示逻辑输入变迁集,对于
c.to表示逻辑输出变迁集,对于
③
④i是逻辑输入变迁的逻辑输入函数,
⑤o是逻辑输出变迁的逻辑输出函数,
⑥
⑦变迁引发规则:
a.若
b.若
c.若
图1给出一个简单的逻辑petri网例子,该模型中有两个逻辑变迁:t1和t2。其中t1是逻辑输入变迁,逻辑输入函数
定义校准
设a∈λ,σ∈a*是a上的一条迹,且pn=(p,t;f,m)。(a,t)∈(a∪{>>})×(t∪{>>})是一个动作,校准γ=(a1,t1)(a2,t2)…(a|γ|,t|γ|)是迹σ和模型pn之间的动作队列,且满足:
①π1(γ)=σ,即迹中的动作序列产生迹σ;
②mi[π2(γ)>mf,即模型中的动作序列产生一个完整的引发序列;
其中,若a∈a且t=>>,则为日志动作;若a=>>且t∈t,则为模型动作;若a∈a且t∈t,则为同步动作;否则为非法动作。
γσ,pn是迹σ和模型pn之间所有校准的集合。
定义最优校准
设a∈λ,σ∈a*是a上的一条迹,且pn=(p,t;f,m)。称γ∈γσ,pn为迹σ和模型pn之间的最优校准,当且仅当对
γσ,pn,lc是迹σ、模型pn与可能性代价函数lc之间的最优校准集合,最优校准可能存在一个或者多个。
定义过程树
设a∈λ,pn=(p,t;f,m)是一个petri网。
①a∈a∪{τ}是一个过程树;
②设pt1,…,ptn(n>0)是过程树,则
操作符集
一种基于逻辑petri网的循环并发结构的过程模型修正方法,包括以下步骤:
步骤1:对普通扩展校准、普通最优扩展校准、逻辑扩展校准和逻辑最优扩展校准进行定义;
通过校准中的日志动作、模型动作可以识别日志记录行为和模型描述行为之间的偏差。在校准序列中添加可达标识库可以精确定位偏差。为了确定偏差出现的位置,对校准进行扩展,即添加标识库所集。扩展校准不仅适用于petri网,还能确定逻辑petri网的偏差位置,下面给出普通/逻辑扩展校准和普通/逻辑最优扩展校准定义:
定义普通扩展校准
设a∈λ,σ∈a*是a上的一条迹,且pn=(p,t;f,m)。
(a,t,p|set)∈(a∪{>>})×(t∪{>>})×{m|pset}是一个动作,普通扩展校准β=(a1,t1,p1|set)(a2,t2,p2|set)…(a|β|,t|β|,p|β||set)是动作队列,且满足:
①γ是迹σ和模型pn之间的校准;
②m0是初始标志,存在m0[σ′>mi,σ′为从π2(γ)模型活动的第1个变迁开始到第i个变迁之间的一条迹,0<i≤|γ|;
③mi|pset为mi状态下所有存在托肯的库所集,称为标识库所集。
γσ,pn,m|pset是迹σ、模型pn与标识库所集m|pset之间所有普通扩展校准的集合。
定义普通最优扩展校准
设a∈λ,且pn=(p,t;f,m)。称β∈γσ,pn,m|pset为迹σ、模型pn与标识库所集m|pset之间的普通最优扩展校准,当且仅当对于
γσ,pn,m|pset,lc是迹σ、模型pn、标识库所集m|pset与可能性代价函数lc之间的普通最优扩展校准的集合,最优扩展校准可能存在一个或者多个。
例1.若存在日志l1={σ1=<t1,t2,t3,t5,t6>,σ2=<t1,t2,t3,t4,t5,t6>,σ3=<t1,t4,t2,t3,t5,t6>,σ4=<t1,t2,t4,t3,t5,t6>,σ5=<t1,t3,t5,t6>},图2是通过α算法得到模型pn1。
迹σ6=<t1,t2,t3,t4,t5,t1,t2,t3,t4,t5,t6>,迹σ6与pn1普通最优扩展校准β1如图3所示。
最优校准β1标识库所集m|pset如下:m1|p={p2,p3,p4},m2|p={p2,p4,p5},m3|p={p4,p6},m4|p={p6,p7},m5|p=m6|p=m7|p=m8|p=m9|p=m10|p={p8},m11|p={p9}。
由于逻辑扩展校准和普通逻辑校准只是基于不同的网模型,其他概念相似,所以下面只给出逻辑扩展校准和逻辑最优校准的定义。
定义逻辑扩展校准
设a∈λ,σ∈a*是a上的一条迹,lpn=(p,t;f,m)是a上的一个逻辑petri网。(a,t,p|set)∈(a∪{>>})×(t∪{>>})×{m|pset}是一个动作,逻辑扩展校准βl=(a1,t1,p1|set)(a2,t2,p2|set)…(a|βl|,t|βl|,p|βl||set)是动作队列,且满足:
①γσ,lpn是迹σ和模型lpn之间的校准;
②mi|pset为mi状态下所有存在托肯的库所集,称为标识库所集。
γσ,lpn,m|pset是迹σ、模型lpn与标识库所集m|pset之间所有逻辑扩展校准的集合。
定义逻辑最优扩展校准
设a∈λ,lpn=(p,t;f,m)是a上的一个逻辑petri网。称βl∈γσ,lpn,m|pset为迹σ、模型lpn与标识库所集m|pset之间的逻辑最优扩展校准,当且仅当对于
γσ,lpn,m|pset,lc是迹σ、模型lpn、标识库所集m|pset与可能性代价函数lc之间的逻辑最优扩展校准的集合。
步骤2:进行循环并发结构的静态模型修正;
当过程模型描述的行为与事件日志记录的行为之间存在偏差时,为了使模型可以重演日志中记录的行为,需要对现有模型进行修正。对于存在循环并发结构的模型,现有修正方法得到的模型结构比较复杂,且不能正确地描述活动之间的关系,导致模型精确度比较低。因此提出一种静态模型修正方法,计算连续日志动作集合,遍历普通最优扩展校准定位偏差,对模型进行静态修正。
在网模型中,如果两个变迁之间存在多个并发变迁,则称这两个变迁为并发块的首尾活动。如图2,
算法1计算连续日志动作集合算法
输入:petri网pn=(p,t;f,m),普通最优扩展校准γσ,pn,m|pset,lc;
输出:连续日志动作集合cl;
步骤(1):初始化连续日志动作集合cl;
步骤(2):遍历γσ,pn,m|pset,lc,若存在连续的日志动作{(ai,>>,pi|set),…,(aj,>>,pj|set)},且ai和aj分别为网模型并发块的首尾活动;
步骤(3):将符合条件的连续日志动作的添加到变迁{ai,…,aj}添加到cl集合中;
步骤(4):输出连续日志动作集合cl。
计算连续日志动作集合之后,需要通过定位偏差来确定偏差位置,下面给出算法2,可以静态定位日志和模型之间的偏差。
算法2静态偏差定位算法
输入:连续日志动作集合cl,普通最优扩展校准γσ,pn,m|pset,lc;
输出:偏差位置d(pn|set,tn);
步骤(1):初始化偏差位置d(pn|set,tn);
步骤(2):遍历γσ,pn,m|pset,lc,若连续日志动作集合cl在普通最优扩展校准中已完整出现且发生,则pn|set为连续日志动作的首变迁ai的标志库所集,tn为首变迁ai;
步骤(3):将得到的(pn|set,tn)并到d(pn|set,tn)集合中;
步骤(4):输出偏差位置d(pn|set,tn)。
根据偏差位置,及逻辑petri网,给出静态模型修正算法。
算法3静态模型修正算法
输入:静态偏差定位d(pn|set,tn),petri网pn=(p,t;f,m);
输出:修正后的逻辑petri网lpn′=(p′,t′;f′,i′,o′,m′);
步骤(1):初始化修正模型lpn′为原模型;
步骤(2):调用算法1和算法2得到偏差位置d(pn|set,tn);
步骤(3):在模型中添加pn|set到tn的弧;
步骤(4):根据lpn挖掘算法挖掘变迁的触发条件,得到新的逻辑变迁ai′,并将ai′添加到模型中;
步骤(5):输出修正后的逻辑petri网lpn′。
例2.以pn1和β1为例,根据算法1,遍历普通最优扩展校准β1,输出连续日志动作集合cl1={t1,t2,t3,t4,t5}。根据算法2,得到pn|set=m(t1)|pset=m6|p={p8},tn={t1},偏差位置d1=(p8,t1)。根据算法3,对模型进行修正,添加一条从pn|set到tn(p8到t1)的弧,且将t1变为逻辑输入变迁。根据lpn挖掘算法挖掘变迁的触发条件,库所p8和p1之间不能同时存在托肯,即
步骤3:进行循环并发结构的动态模型修正;
在连续日志动作在普通扩展校准中已出现且发生时,可以用静态修正方法对模型进行修正。下面给出当连续日志动作在普通扩展校准中并未完整出现时,根据逻辑petri网,动态的确定偏差位置并对模型进行修正的方法。相对于静态模型修正,动态模型修正比较复杂。在偏差定位之前,需获得模型的并发变迁集,以便于准确定位偏差。根据过程树概念,引入并发变迁集概念。
以pn1为例,过程树表示petri网。用到过程树两种操作符:→(顺序关系)和∧(并行关系)。在过程树中,叶子结点为petri网模型的变迁,非叶子结点为操作符。图5是模型pn1的过程树pt1,即
遍历过程树,若存在操作符∧的左(右)子树为叶子结点,则n.lchild.child=null(n.rchild.child=null)。若右(左)子树不为叶子结点,则n.rchild.child≠null(n.lchild.child≠null)。每一个右(左)子树的后续叶子结点n.rchild.p(n.lchild.p)都与该操作符∧的叶子结点n.lchild(n.rchild)为并发变迁对(ta,tb)。
定理1若n=“∧”为过程树pt的结点,n的左(右)子树n.lchild(n.rchild)为叶子结点,则n.lchild(n.rchild)与n的其他子树的所有叶子结点n.rchild.p(n.lchild.p)并发。
证明过程树pt的叶子结点均为变迁,操作符均为非叶子结点。若n∈pt且n=“∧”,在petri网中,n=“∧”对应于mn[tn>mn′。假设n的左子树n.lchild为叶子结点,n的右子树n.rchild不为叶子结点,操作符n=“∧”之后,即mn[tn>mn′。在mn′状态下,
定理1表明在过程树pt中,操作符∧的叶子结点对应的变迁与非叶子结点的后续叶子结点对应的变迁并发。下面给出模型中并发变迁集的定义。
定义模型中并发变迁集
设a∈λ,且pn=(p,t;f,m),pt是petri网的过程树,并行变迁对(ta,tb)满足:
①
②若n∈pt且n=“∧”,n的左子树n.lchild不为叶子结点,n的右子树n.rchild为叶子结点,n.lchild.p为子树n.lchild的后续叶子结点,则ta=n.lchild.p且tb=n.rchild;
③若n∈pt且n=“∧”,n的左子树n.lchild为叶子结点,n的右子树n.rchild不为叶子结点,n.rchild.p为子树n.rchild的后续叶子结点,则ta=n.rchild.p且tb=n.lchild。
根据并发变迁集的概念,下面算法4给出寻找并发变迁集方法。输入pn对应的过程树pt,输出并发变迁集cts。模型中的并发变迁集cts为所有并发变迁对(ta,tb)的集合,cts可以用于寻找偏差位置。
算法4寻找并发变迁集算法
输入:过程树pt;
输出:并发变迁集cts;
步骤(1):初始化并发变迁集cts;
步骤(2):当过程树pt中的结点n不为空时进行步骤(3)~(5);
步骤(3):若n为操作符∧,且左子树n.lchild不为叶子结点,右子树n.rchild为叶子结点,则左子树的后续叶子结点和右子树为一组并发变迁对(n.lchild.p,n.rchild),并添加到并发变迁集cts中;
步骤(4):若n为操作符∧,且右子树n.rchild不为叶子结点,左子树n.lchild为叶子结点,则右子树的后续叶子结点和左子树为一组并发变迁对(n.rchild.p,n.lchild),并添加到并发变迁集cts中;
步骤(5):寻找下一个结点;
步骤(6):输出并发变迁集cts。
下面给出仅
定理2设仅
(a)存在自环结构当且仅当:
(b)不存在自环结构当且仅当:
证明(a)充分性:当f(·first(cl))=·t·,f(p)=·t·,则p∈·first(cl)。因为p∈m(first(cl))|pset,则
(b)充分性:当f(·first(cl))=·t·,f(p)=·f·,则
定理2表明,通过库所p是否存在标记可以判断模型是否存在自环结构。根据定理2,下面给出在模型中不存在自环结构时,动态定位偏差并修正模型的方法。
算法5动态的偏差定位与模型修正算法
输入:连续日志动作集合cl,普通最优扩展校准γσ,pn,m|pset,lc,petri网pn=(p,t;f,m),并发变迁集cts;
输出:修正后的逻辑petri网lpn′=(p′,t′;f′,i′,o′,m′);
步骤(1):初始化偏差位置d(pn|set,tn);
步骤(2):初始化修正模型lpn′为原模型;
步骤(3):将收集的连续日志动作cl遍历普通最优扩展校准β,若未完整出现且发生,则到步骤(4),否则退出;
步骤(4):若连续日志动作首变迁first(cl)的前集属于first(cl)的标志库所集,则first(cl)使能,到步骤(10),否则到步骤(5);
步骤(5):若first(cl)和模型pn的任一变迁不属于cts中任一变迁对,则pn|set为first(cl)的标志库所集,tn为first(cl),pm|set是需要同pn|set比较的库所集,pm|set为tn前集;
步骤(6):若first(cl)存在并发变迁s,且连续日志动作中不包含s,则pn|set为first(cl)的标志库所集,tn为first(cl),pm|set为tn前集;
步骤(7):若first(cl)存在并发变迁s,且连续日志动作中包含s,则pn|set为first(cl)的标志库所集,去掉包含于first(cl)前集的库所,去掉含于并发变迁s前集的元素,tn为first(cl),pm|set为first(cl)前集和s前集的交集,去掉含于first(cl)标志库所集的元素;
步骤(8):将pn|set到tn的弧添加到模型中;
步骤(9):根据lpn挖掘算法挖掘变迁的触发条件比较pm|set和pn|set之间逻辑关系,得到逻辑变迁first(cl)′,并将first(cl)′添加到模型中;
步骤(10):更新first(cl)的标志库所集,将其赋值给cl第二个变迁的标志库所集,并在cl中去掉首元素;
步骤(11):输出修正后的逻辑petri网lpn′。
下面以迹σ7和β2为例,给出动态模型修正的例子。
例3.迹σ7=<t1,t2,t3,t4,t5,t1,t3,t4,t5,t6>,图6是迹σ7的普通最优扩展校准β2。
其中,标识库所集m|pset如下:m1|p={p2,p3,p4},m2|p={p2,p4,p5},m3|p={p4,p6},m4|p={p6,p7},m5|p=m6|p=m7|p=m8|p=m9|p={p8},m10|p={p9}。
根据算法1,遍历β2,得到连续日志动作集合cl2={t1,t3,t4,t5}。
根据算法4,可以得到pn1的并发变迁对为(t2,t4)和(t3,t4),cts={(t2,t4),(t3,t4)}。
根据算法5,t1没有并发变迁对,且
此时需增添一条pn|set到tn的弧,且将t1变为逻辑输入变迁。库所p8和p1之间不能同时存在托肯,因此将t1变为逻辑输入变迁,即
在修正模型过程中,一旦找到了偏差位置就立刻修正模型,并更新原有模型和最优扩展校准中的标识库所集,直至达到终止状态。此时需要更新修正后的模型和最优扩展校准β2的库所标识集。
cl2中m6|p={p2,p3,p4},此时·t3={p2,p5},
更新修正后的模型和β2的库所标识集,cl2中m7|p={p4,p6},
动态的偏差定位和模型修正得到的逻辑petri网如图7所示。
实施例1
利用某医院肿瘤科的数据进行了仿真实验,基于逻辑petri网动态模型修正方法,与fahland修正方法、goldratt修正方法和knapsack修正方法]进行了实验比较分析。fahland修正方法、goldratt修正方法和knapsack修正方法是通过过程挖掘工具prom6.6实现。基于逻辑petri网的修正方法,还没有相应的实验工具,因此采用手工模拟。由于静态模型修正比较简单,因此下面只给出动态模型修正的实验。
以医院肿瘤科业务流程为例,根据其事件日志用α算法得到的模型如图8所示。首先患者进行挂号(registered),拿号(acquisitionnumber),按顺序叫号(callnumberbyorder),问诊(inquiry)。进行问诊时可以做以下几种检查:血液检查(bloodtest),磁共振成像检查(magneticresonanceimaging),之后进行超声检查(ultrasoundexamination);也可以超声检查之后进行血液检查和磁共振成像检查;也可以是血液检查和超声检查之后磁共振成像检查;也可以只进行磁共振成像检查。接下问诊(diagnosis),如果是健康人员,可以直接离开医院(leavehealthily);如果是非良性肿瘤患者,直接进行手术(surgery),进行住院治疗(hospitalization);如果是良性肿瘤,先进行问诊等待(outpatientwaiting),注射药物(injectingdrugs),进行相应咨询服务(consultationservice),再进行定期观察(regularobservation),与此同时进行取药(takemedicine)。
在实际就诊中,可能存在重复情况。比如:在进行诊断之后,问诊,继续磁共振成像检查和超声检查,再进行诊断;或者良性肿瘤的人员在定期观察之后,问诊等待,继续取药和咨询服务,再定期观察。在以上部分就诊流程情况中,存在这一种特殊结构,即在循环中存在并发结构。针对循环并发结构,petri网模型无法正确且准确表达活动之间的逻辑关系,需要利用逻辑petri网进行模型修正。
在获得的事件日志中,首先过滤明确偏离过程的日志和明显不完整的日志。表1给出了三组事件日志的信息,包括迹的总数,迹的长度,事件数,活动数以及偏差数。
表1三组事件日志
fahland方法通过添加不可见变迁跳过模型动作,收集循环活动作为子日志,在原模型中添加自环。goldratt方法和knapsack方法根据不同的约束条件添加单个活动自环的方式进行修正。这三种修正方法不能很好地描述活动之间的逻辑关系,且修正后的模型存在部分相同行为,增加了模型复杂度。添加自环和不可见变迁虽然提高了模型拟合度,但大大降低了精确度。对图8的模型和表1的事件日志进行模型修复,图9为fahland方法修正后的模型。由于篇幅有限,只给出了关键部分的goldratt方法的修正模型,见图10和图11,及knapsack方法的修正模型,见图12和图13。
可以看出,fahland修正方法、goldratt修正方法和knapsack修正方法并不能很好的修正循环结构。fahland方法修正得到的模型与原模型相比增加了8个库所、8个变迁、7个不可见变迁、26条流关系,子过程中存在多个重复活动且添加了多条流关系,增加了模型复杂度,修正后的模型存在多个不可见变迁和环,降低了模型精确度。goldratt方法修正得到的模型与原模型相比增加了17个变迁、29条弧。knapsack方法修正得到的模型增加了15个变迁、30条流关系。这两种方法修正后的模型存在大量自环,不能很好描述活动之间的逻辑关系,且降低了模型精确度。这三种方法修正模型较大的改变了原模型结构,且相对复杂。
图14是基于逻辑petri网动态模型修正方法得到的模型。修正后的模型基本保留了原模型结构,与原模型相比只增加了4条流关系,将4个普通变迁修改成逻辑输入变迁,得到逻辑输入函数
表2四种修正模型的简洁度比较
表2是利用三组事件日志,根据上述四种方法修正的模型,各元素的比较,其中包括修正模型的库所数、变迁数、不可见变迁数和流关系的比较。可以看出,基于逻辑petri网的动态模型方法修正模型的库所数、变迁数和流关系均最少,简洁度更高。
采用100-1000不同数量级的事件日志,利用上述四种方法进行模型修正。下面给出四种修正模型在不同迹条数下拟合度和精确度的比较。拟合度是评价模型质量最重要的指标,拟合度越高,则模型重演日志中的迹越多,模型质量越高。基于四种方法修正模型,在迹条数不同情况下拟合度的变化情况如图15所示。
如图15所示,基于逻辑petri网动态修正模型和fahland方法修正模型和日志的拟合度较高,明显高于goldratt方法和knapsack方法修正模型(这两种方法拟合度相同)。
模型精确度越高,则模型生成除给定事件日志记录之外的迹越少,模型质量越高。四种方法修正模型在迹条数不同情况下精确度的变化情况如图16所示。
如图16所示,随着迹数量的增加,基于逻辑petri网动态修正模型的精确度最高,其次是fahland方法修正模型,goldratt方法和knapsack方法修正模型精确度较低,效果较明显。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!