基因组测序数据的Leon-RC压缩方法与流程
本发明涉及生物信息领域,更具体地,涉及一种基因组测序数据的leon-rc压缩方法。
背景技术:
现有的二代测序数据压缩方法主要有两种:一种是基于参考基因组的压缩算法,如quip、cram、pathenc和fastqz等,压缩后的文件存储的是短读与参考基因组之间的映射信息。同源物种基因组之间具有高度相似性,以人类为例,任何两个人的基因组相同部分的内容高达99%,因此,在获得参考基因组的情况下,如果能够存储这1%的额外信息,就能够存储目标基因组。
基于参考基因组的二代测序数据压缩流程如下:
(1)选取合适的参考基因组,同源物种序列由于具有高度相似性作为参考基因组具有优势;
(2)将原始短读映射(mapping)到参考基因组,并记录原始数据的匹配位置、差异位置、差异内容和差异类型;
(3)对步骤(2)记录的差异结果进行高效编码压缩。
另一种是无参考基因组的压缩算法,如:scalce、dsrc、orcom、beetl、mince等,它利用了短读之间的相似性对数据进行压缩,通常而言,基于拼接的无参考基因组的压缩方法分为以下两个步骤:
(1)将一部分短读使用拼接算法拼成一个临时参考基因组;
(2)使用基于参考基因组的压缩方法,将原始短读映射到临时参考基因组,并将映射结果进行编码。
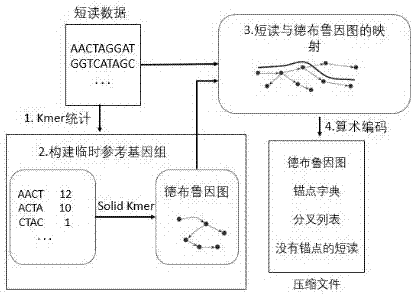
leon是目前比较高效的无参考基因组压缩算法,它能够同时兼顾压缩率和压缩速率,图1为leon算法压缩的过程的总体流程。其主要分为以下几个步骤:
(1)读取fasta文件或fastq文件中的短读,并统计短读中的kmer在整个文件中出现的次数,设置一个阈值,出现次数大于该阈值的kmer为solidkmer;
(2)用所得的solidkmer构建一个锚点字典并拼接成一个德布鲁因图,并存储在布隆过滤器中,以便后续快速匹配;
(3)将原始文件中的每一条短读映射至德布鲁因图,映射的结果存储在映射表中;
(4)用算术编码对德布鲁因图、锚点字典以及映射表进行压缩,压缩后合并的结果即为压缩后的文件。
不同于传统的非参考基因组压缩算法,leon定义了自己的一套映射规则。在它的映射表中包含了以下三项:锚点下标、左路径(leftpath)、右路径(rightpath)。锚点下标指的是初始kmer的位置,左路径包含了从锚点开始短读左边的kmer与参考基因组的映射关系,右路径则包含了从锚点开始短读右边的kmer与参考基因组的映射关系。
绝大部分基于参考基因组的压缩算法和无参考基因组的压缩算法其压缩速率很低,原因在于原始数据和参考基因组比对/映射的过程耗时过长。即便leon使用了布隆过滤器和德布鲁因图拼接算法,能够高效以o(1)的时间复杂度进行原始文件与临时参考基因组的比对映射,但其在实现的过程中对二代测序数据的相似性特点运用不充分,只考虑到了直接重复和互补回文这两种情况。如果在kmer与德布鲁因图匹配的过程中,只考虑了直接重复和互补回文,而没有考虑可能出现的镜像重复、反转重复这两种情况,可能会导致某些短读无法找到锚点,从而无法映射到临时参考基因组,也可能存在锚点,但是寻找锚点的时间过长。
技术实现要素:
本发明提供了一种基因组测序数据的leon-rc压缩方法,其主要对leon算法的锚点字典构造方法进行改进,一方面是减少了锚点字典的大小,另一方面使得压缩过程中能够更快地寻找到序列的锚点kmer。
为实现以上发明目的,采用的技术方案是:
一种基因组测序数据的leon-rc压缩方法,对leon算法构造锚点字典的步骤进行改进,包括以下步骤:
(1)将短读划分为多个kmer;
(2)选择一个kmer,计算其直接重复、镜像重复、反转重复、互补回文的kmer值,比较这四个值,获得最小的kmer值;
(3)将最小的kmer值放入布隆过滤器中进行匹配查找,布隆过滤器中存放有solidkmer,判断solidkmer中是否存在最小的kmer值;若存在,则向锚点字典中添加该最小的kmer值,并结束查找;若不存在,则获取下一个kmer,重复步骤(2)、(3);
(4)若所有kmer的最小的kmer值都不存在于solidkmer中,则说明该短读不存在锚点;
(5)通过步骤(1)~(4)构造锚点字典。
优选地,所述方法构造得到锚点字典后,对短读进行压缩,其具体过程如下:
s1.在短读开始编码的位置寻找锚点;在锚点字典中检索kmer,计算他们的最小值kmer,当其中一个最小值kmer出现在锚点字典中,则停止检索,记录下标至映射表的anchor中;映射表中的anchor记录位置为该kmer在锚点字典中的下标为1,并且用一个变量readanchorrevcompmodel来记录锚点类型;如果锚点不存在的话,则将第一个kmer加入到锚点字典中;
s2.记录锚点左右两边剩下的路径长;
s3.记录有差异的碱基位置,从锚点开始向右查找,判断短读的下一个kmer是否存在于布隆过滤器中,若不存在,则记录该kmer和相对于锚点的位置,若存在,则判断是否在布隆过滤器中唯一,若唯一,则不做操作,若不唯一,则记录选择;
s4.经过以上三个步骤完成了对短读的压缩。
与现有技术相比,本发明的有益效果是:
本发明提供的方法优化了锚点字典的构造过程,考虑了kmer的四种相似性特点,能够减少锚点字典的大小,并更快地寻找到每条序列的锚点kmer。在寻找一条序列的锚点kmer时,leon对每个kmer只进行了一次直接互补回文的变换,再判断当前kmer和互补回文kmer的最小值是否属于德布鲁因图,如果属于则加入到锚点字典中。然而二代测序数据的四种相似性特点都有可能出现,因此,本发明提供的leon-rc方法对每个kmer进行了额外的三种相似性变换,它能够减小锚点字典的大小,并且能够更快地寻找到当前序列的锚点kmer。
附图说明
图1为leon算法压缩的总体流程图。
图2为leon-rc算法的短读映射过程图。
图3为压缩速率测试对比图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
本发明提供了一种基因组测序数据的leon-rc压缩方法,其主要对leon算法构造锚点字典的步骤进行改进,包括以下步骤:
(1)将短读划分为多个kmer;
(2)选择一个kmer,计算其直接重复、镜像重复、反转重复、互补回文的kmer值,比较这四个值,获得最小的kmer值;
(3)将最小的kmer值放入布隆过滤器中进行匹配查找,布隆过滤器中存放有solidkmer,判断solidkmer中是否存在最小的kmer值;若存在,则向锚点字典中添加该最小的kmer值,并结束查找;若不存在,则获取下一个kmer,重复步骤(2)、(3);
(4)若所有kmer的最小的kmer值都不存在于solidkmer中,则说明该短读不存在锚点;
(5)通过步骤(1)~(4)构造锚点字典。
获得锚点字典后,就可以对短读进行压缩,其压缩过程实际上是构建短读的映射表,其包含了短读与德布鲁因图和锚点字典的映射关系。图2为leon-rc算法短读映射的过程。
以第一条短读“gctagatga”为例,其具体步骤如下:
(1)首先寻找锚点,也就是短读开始编码的位置。在锚点字典中检索短读“gctagatga”中大小为4的kmer,也就是“gcta”、“ctag”、“taga”等等,计算它们的最小值kmer,当其中一个出现在锚点字典中,则停止检索,记录下标至映射表的anchor中,由图可知,第一个kmer“gcta”的最小值kmer“atcg”就存在于锚点字典中,因此,映射表中的anchor记录位置为该kmer在锚点字典中的下标为1,并且用一个变量readanchorrevcompmodel(大小为两个bit)来记录锚点类型(00表示直接重复,01表示镜像重复,10反转重复,11表示互补重复,此处为镜像重复,故为01)。如果锚点不存在的话,则将第一个kmer加入到锚点字典中;
(2)记录锚点左右两边剩下的路径长。由于示例短读中第一个kmer就是锚点,因此左边不需要记录,路径长为0,右边还剩短读长度-k个kmer需要记录,也就是5,路径长也就是5;
(3)记录有差异的碱基位置,从锚点开始向右查找。短读的下一个kmer为“ctag”,首先判断是否存在于布隆过滤器中,若不存在,则记录该kmer和相对于锚点的位置,若存在,则判断是否在布隆过滤器中唯一,若唯一,则不做操作,解码的时候可以直接通过布隆过滤器找到,若不唯一,则记录选择,解码的时候根据记录选择下一个kmer。如锚点右边第二个kmer——“taga”,由于布隆过滤器中存在两种情况“taga”和“tagg”,解压的时候无法确定选哪个,因此,在压缩的过程中,就需要记录选择“a”。这就起到了为布隆过滤器提供了一个白名单的作用。
压缩后就得到了布隆过滤器、锚点字典和映射表这三个部分,通过这三个部分,就能够将压缩后的序列解压出来。
还是以第一条短读“gctagatga”为例。解码过程如下:
(1)根据映射表中anchor的值1找到锚点字典中下标为1的锚点kmer——“atcg”,readanchorrevcompmodel的值为01,表示这个锚点kmer是镜像重复得到的,因此,再通过镜像重复就能得到原始的锚点“gcta”;
(2)leftpath为0,所以只需要从右边开始解压,rightpath的第一个值为5,表示右边还有5个碱基,第二个值为“a”,表示遇到多种情况时选“a”;
(3)由于锚点kmer是“gcta”,右边的下一个kmer就有四种可能——“ctaa”、“ctac”、“ctag”、“ctat”。本文通过布隆过滤器去查询这四种情况,结果发现只有“ctag”存在布隆过滤器中,所以毫无疑问下一个碱基就是a了;
(4)重复步骤3继续查找,当在找第二个碱基的时候,布隆过滤器中存在了两种可能——“taga”和“tagg”,这个时候就可以用到rightpath的第二个值“a”,表明在这种多个kmer存在的情况下应该选“a”,也就是“taga”;
(5)继续向右查找,当找到了rightpath中第一个值——5个碱基后停止,此时可以得到短读——“cgctagatga”。
向左查找的过程与向右查找类似,除了下一个碱基应该放在kmer的左边以外,没有任何区别。
实施例2
本实施例对不同的大小的二代测序数据进行压缩测试,压缩测试的结果如图3所示,相较于leon,leon-rc在保持压缩率不变的情况下,显著提高压缩速率。其中srr934718_1文件的压缩速率提升幅度最大,由56.16mb/s提升到了64.95mb/s。提升幅度高达15.6%。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!