一种基于医保大数据测算罕见病发病率的分析方法与流程
本发明涉及医保数据处理与分析技术,具体涉及一种基于医保大数据测算罕见病发病率(incidence)的分析方法。
背景技术:
罕见病(rarediseases)是指患病率、发病率很低的一类少见的疾病,目前我国缺乏对这类疾病的基本流行特征的信息,包括发病率、患病率等。医疗保险数据(claimsdata)一般是在医保行政管理系统中,通过支付信息整合而形成的数据,包括参保人基本特征、诊断、治疗等信息,数据量巨大,不仅全面性、时效性好,成本低,可操作性高,更是来自于真实世界的纵向数据,有利于快速高效的开展流行病学研究,特别是可以利用全国医保数据为解决我国罕见病流行病学数据缺乏这一问题提供新思路。
与其他流行病学研究不同的是,计算发病率需要明确一定时间内的新发病例数量和一定时期内的已患病人口数量。目前国外针对罕见病发病率的分析方法中,raghug等学者利用美国medicare医保数据,计算2001-2011年期间特发性肺纤维化发病率等,但这些发病率研究的计算是基于医保数据中的个体原始数据,对于我国的海量医保数据,无论数据存储的期别、格式和体量,还是数据指标的跨度、缺失和个体脱保等均与国外医保数据不同,故无法直接将上述方法用于我国医保数据库的流行病学研究中;而纵观国内利用医保数据的研究发现,目前大多集中于通过挖掘医保数据发现欺诈行为,改善疾病治疗效果以及辅助政策的修改制定等方面,少见利用医保数据进行流行病学,特别是罕见病发病率、患病率的研究,使得目前难以充分利用医保大数据,开展罕见病的相关流行病学特征进行分析。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于医保大数据测算疾病发病率的新方法,基于优化数据中间存储格式,通过汇总每月医保数据的多个关键参数,包括:每月参保个体总数、每月新增参保个体数、每月就诊记录总数、每月就诊记录诊断缺失总数,一定时期内的新发病例数、一定时期内已患病人数(一定时期根据研究需要确定,可为一个月、两个月、一年等),获得发病率计算所需的分子与分母信息,进而计算得到发病率。本发明方法涉及汇总数据格式下高效计数发病率对应分子、分母的统计运算,是一种符合我国医保数据特征的计算罕见病发病率的方法,可用于罕见病流行病学分析。
本发明可测算的疾病要求不能彻底治愈,一旦诊断,终生罹患。
本发明的原理是:基于人月的概念,计数每月参保个体总数、每月新增参保个体数、每月就诊记录总数、每月就诊记录诊断缺失总数,结合目标疾病定义抽提目标患者,并推导诊断随机缺失情境下的“隐形患者”,结合公式推导计算发病率。本发明方法可测算的疾病包括多发性骨髓瘤、浆细胞白血病、浆细胞病、特发性肺间质纤维化、poems综合征等所有符合不能彻底治愈,一旦诊断,终生罹患特征的罕见病。通过本发明方法能够获得罕见病的发病率资料,为合理制定临床指南提供数据和技术支持,进一步促进医保大数据的转化应用。
本发明提供的技术方案是:
一种基于医保大数据测算罕见病发病率的方法,测算的疾病要求为不能彻底治愈;基于医保数据库,通过汇总每月医保数据的多个关键参数(包括:每月参保个体总数、每月新增参保个体数、每月就诊记录总数、每月就诊记录诊断缺失总数、一定时期内的新发病例数、一定时期内已患病人数),获得发病率计算所需的分子与分母信息,进而计算得到发病率;发病率计算的分子指特定时间内,一定范围的人群中目标疾病的新发生病例数,分母即特定时间内的暴露人口数,即可能发生目标疾病的人,需排除已患病在特定时间内不可能再成为新发病例的人;
包括如下步骤:
a1.确定医保数据库范围(如时间跨度、地域分布、门诊/住院);
a2.数据库的基本清洗和目标疾病的定义;
数据库的基本清洗包括以下基本步骤:(1)数据库中变量的完整性和逻辑性核查;(2)数据库中文本内容的编码标准化和自然语言处理;(3)数据库中国际疾病分类(internationalclassificationofdiseases,icd)的版本确定和统一。
本发明中,目标疾病的定义以医保数据库中出现对应疾病的名称或icd编码为准,具体需要充分考虑文本和icd编码的多种表达形式,并通过分词技术构建尽量全面的包含目标疾病诊断名称表达方式的字典库。
本发明构建字典库的过程为:
首先从医保数据库中提取包含目标诊断疾病名称(比如多发性骨髓瘤)的文本信息,这部分文本信息可能包含错误的疾病名称表达方式,也有可能包含其他诊断名称,无法直接利用;
需要采用分词技术,把提取得到的文本信息里,涉及到目标诊断疾病名称(多发性骨髓瘤)的字段提取出来;
然后通过人工逐条判断这些疾病名称表达是否正确,将正确的文本表达确定为初步的字典库;
根据初步的字典库再次从医保数据库中提取包含目标诊断的所有信息,再利用分词技术进行识别;
如此反复多次,直至目标诊断疾病名称的文本表达准确率达95%以上,确定为最终的字典库。目的是尽可能得到包含所有目标诊断疾病名称的表达方式,以便后续确定患者时不会漏掉。
a3.分母信息的汇总;
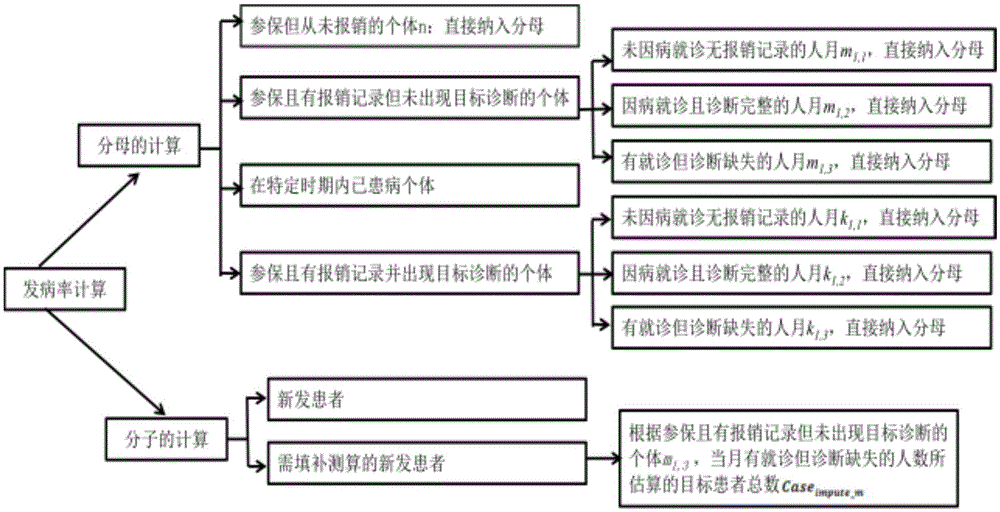
具体分为四组:参保但从未报销的个体、参保且有报销记录但未出现目标疾病诊断的个体、参保有报销记录且出现目标疾病诊断的个体、一定时间内已患目标疾病的个体。根据每位个体在每个月的参保状态,纳入参保人次,剔除未参保人次。
具体地,根据参保状态,若有参保记录则纳入此时的人次,如果没有参保记录则删除。
分母的第一组:参保但从未报销的个体,按人月总和对应计算公式如式1:
其中,t表示第t个月份;insurancet,n为第n个该组个体在第t个月份的参保状态;n代表第一组分母的人月总和。
第二组:参保且有报销记录但未出现目标诊断的个体,包括三种情况;
第一种情况:未因病就诊无报销记录的人月直接纳入分母,对每月而言,即未因病就诊无报销记录的当月人数m1,1;
第二种情况:因病就诊且诊断完整的人月应纳入分母计算,对每月而言,即因病就诊且诊断完整的当月人数m1,2;
第三种情况:有就诊但诊断缺失的人月应考虑后续填补,提取因病就诊但诊断缺失的当月人数m1,3。
以每个月为例,第二组分母的人月总和对应计算公式如式2:
其中,t表示第t个月份;insurancet,m为第m个该组个体在第t个月份的参保状态;m代表第二组分母的人月总和。
第三组:参保有报销记录且出现目标诊断的个体,包括三种情况;
第一种情况:未因病就诊无报销记录的人月直接纳入分母,对每月而言,即未因病就诊无报销记录的当月人数k1,1;
第二种情况:因病就诊且诊断完整的人月应纳入分母计算,对每月而言,即因病就诊且诊断完整的当月人数k1,2;
第三种情况:有就诊但诊断缺失的人月应考虑后续填补,对每月而言,即因病就诊但诊断缺失的当月人数k1,3。
以每个月为例,第三组分母的人月总和对应计算公式如式3:
其中,t表示第t个月份;insurancet,k为第k个该组个体在第t个月份的参保状态;k代表示第三组分母的人月总和。
第四组:已患病的个体;
第四组的总和对应计算公式如式4:
其中,t1表示一定时期;p代表该时期内的已患病人数总和。
a4.分子信息的汇总,包括两组;
针对目标疾病,进行对应的分子信息抽提,具体分为两组:新发患者和需填补测算的新发患者。新发患者指一定期间内,一定范围人群中目标疾病的新发生病例数;后者(需填补测算的新发患者)测算基于就诊信息的诊断缺失与是否罹患某种罕见病的关联不存在统计学意义。
分子第一组:新发患者
纳入一定时期内(例如,可按月或可按年)的全部新发患者,记为
分子第二组:需填补测算的新发患者
a5.分子新发患者的基本特征核查与统一,如年龄、性别、民族、户籍等
医保数据分为“参保人员信息表”、“普通门(急)诊费用及结算信息表”和“门诊大病、门诊统筹、住院、家庭病床费用及结算信息表”3张表单,各表单之间通过关联变量,对年龄、性别、民族、户籍等需要进行多部核查和统一,以达到每个关联变量对应唯一的身份识别id(如身份证),同时每个唯一的身份识别id对应的年龄、性别、民族和户籍等信息内部一致。
a6.发病率的计算,将上述汇总的分子信息与分母信息求商,计算发病率。
发病率incidence的计算公式(以计算一年的发病率为例)
其中,newcase表示该观察年内的新发患者总数,包括数据库中观察到的新发患者和填补测算的新发患者之和,用∑newcase表示;personyear表示同时期的暴露人口数,即指该观察年内该观察地区内可能发生该病的人群,用∑personmonth表示;∑tcase为每个月需填补测算的新发患者之和,
每个月的分母总数∑tpersonmonth通过下式计算得到:
∑tpersonmonth=∑tpersonmonth1+∑tpersonmonth2+∑tpersonmonth3
其中,t表示第t个月份。∑tpersonmonth1对应参保但从未报销的个体所贡献的人月,∑tpersonmonth2代表参保且有报销记录但未出现目标诊断的个体所贡献的人月,∑tpersonmonth3代表参保有报销记录且出现目标诊断的个体所贡献的人月,
本发明的有益效果是:
通过本发明所提供的以医保大数据为基础的罕见病发病率测算方法,涉及汇总数据格式下高效计数发病率对应分子、分母的统计运算,一方面可以获得我国罕见病的发病率和疾病负担数据(包括疾病(disease)、伤残(disability)和过早死亡(prematuredeath)对整个社会经济及健康的压力),为合理制定临床指南提供数据和技术支持;另一方面,本发明提供了利用医保数据解决疾病发病率计算的新方法,能够促进医保大数据的转化应用,切实填补我国罕见病的发病率资料空白。本发明方法是一种符合我国医保数据特征的计算罕见病发病率的方法,可用于罕见病流行病学分析。
附图说明
图1是本发明提供的计算发病率的方法的流程框图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于医保大数据测算疾病发病率的新方法,基于优化数据中间存储格式,通过汇总每月医保数据的多个关键参数,获得发病率计算所需的分子与分母信息,进而计算得到发病率;发病率计算的分子指特定时间内,一定范围的人群中目标疾病的新发生病例数,分母即特定时间内的暴露人口数,即可能发生目标疾病的人,需排除已患病在特定时间内不可能再成为新发病例的人。
图1所示是本发明提供的计算发病率方法的流程,本发明的具体实施方式如下:
a1.确定数据库范围(如时间跨度、地域分布、门诊/住院);
a2.数据库的基本清洗和目标疾病的定义;
数据库的基本清洗包括以下基本步骤:(1)数据库中变量的完整性和逻辑性核查;(2)数据库中文本内容的编码标准化和自然语言处理;(3)数据库中国际疾病分类(internationalclassificationofdiseases,icd)的版本确定和统一。
本发明中,目标疾病的定义以医保数据库中出现对应疾病的名称或icd编码为准,具体需要充分考虑文本和icd编码的多种表达形式,构建尽量全面的字典库。
a3.发病率对应分母信息的汇总;
发病率的分母具体分为四组
第一组:参保但从未报销的个体
该部分患者从未因病就诊,只有参保记录,无报销记录,在发病率计算时仅用作分母。具体需要统计观察时间内,每个观察对象在每个月的参保状态(1=参保,0=未参保),然后把未参保的人月剔除,把参保的人月合计放入分母。以每个月为例,分母的第一组按人月总和对应计算公式如式1:
其中,t表示第t个月份;insurancet,n为第n个该组个体在第t个月份的参保状态;n代表分母的第一组的人月总和。
第二组:参保且有报销记录但未出现目标诊断的个体
该部分患者曾因病就诊,但未出现目标诊断,同时拥有参保记录、报销记录,同样在发病率计算时仅用作分母。具体需要统计观察时间内,每个观察对象在每个月的参保状态(1=参保,0=未参保),然后同样把未参保的人月剔除,但参保的人月不能直接放入分母,而是根据诊断状态分为三种情况:
第一种情况:未因病就诊无报销记录的人月直接纳入分母(如附图1),对每月而言,即未因病就诊无报销记录的当月人数m1,1;
第二种情况:因病就诊且诊断完整的人月应纳入分母计算(如附图1),对每月而言,即因病就诊且诊断完整的当月人数m1,2;
第三种情况:有就诊但诊断缺失的人月应考虑后续填补(如附图1),提取因病就诊但诊断缺失的当月人数m1,3。
以每个月为例,第二组分母的人月总和对应计算公式如式2:
其中,t表示第t个月份;insurancet,m为第m个该组个体在第t个月份的参保状态;m代表第二组分母的人月总和。
第三组:参保有报销记录且出现目标诊断的个体
该部分患者有因病就诊,且出现过目标诊断,同时拥有参保记录、报销记录,在患病率、发病率计算时用作分子和分母。就分母而言,具体需要统计观察时间内,每个观察对象在每个月的参保状态(1=参保,0=未参保),然后同样把未参保的人月剔除(如附图1),但参保的人月仍不能直接放入分母,而是根据诊断状态分为三种情况:
第一种情况:未因病就诊无报销记录的人月直接纳入分母(如附图1),对每月而言,即未因病就诊无报销记录的当月人数k1,1;
第二种情况:因病就诊且诊断完整的人月应纳入分母计算(如附图1),对每月而言,即因病就诊且诊断完整的当月人数k1,2;;
第三种情况:有就诊但诊断缺失的人月应考虑后续填补(如附图1),对每月而言,即因病就诊但诊断缺失的当月人数k1,3。
以每个月为例,第三组分母的人月总和对应计算公式如式3:
其中,t表示第t个月份;insurancet,k为第k个该组个体在第t个月份的参保状态;k代表示第三组分母的人月总和。
第四组:已患病的个体
由于本发明可测算的疾病一旦诊断,终身罹患,故分母应为可能发生目标疾病的人群,即暴露人口数,故在计算分母时需要去掉一定时期内已患病的个体,第四组的总和对应计算公式如式4:
其中,t1表示一定时期;p代表该时期内的已患病人数总和。
a4.分子信息的汇总;
根据目标疾病的定义后,进行对应的分子信息抽提,具体分为两组:
分子第一组:新发患者
纳入一定时期内的全部新发患者,记为∑tcase_new,其中,t表示特定时期内;case_new表示一定时期内新诊断为目标疾病的人数。新发患者的判断方法是:在研究计算发病率的特定时间之前没有出现目标诊断的患者,根据研究疾病的不同选用不同的洗脱期。例如计算某罕见病某一年的发病率,则在数据库范围内这一年之前的年份内没有出现目标诊断即判断为新发患者。
分子第二组:需填补测算的新发患者
部分就诊记录存在诊断缺失,包括参保且就诊但诊断缺失的非目标疾病患者和参保且就诊但诊断缺失的目标疾病患者,即m1,3和k1,3。由于计算发病率要求患者是新发,也即第一次出现目标诊断,所以对于k1,3的患者虽然当月诊断缺失,但因已在之前被诊断为目标患者,不算做新发患者,故不纳入分子。因此,这里需要填补测算的部分为m1,3,该部分记录不宜直接剔除,如表1所示,
表1发病率计算时分子填补示意图
理想状态下的发病率incidence的计算公式为式5:
其中,a代表参保且有就诊且就诊记录诊断不缺失的个体中可以抓取到的目标疾病患者人数,b代表参保且有就诊且就诊记录诊断不缺失的个体中可以抓取到的非目标疾病患者人数,c代表参保且有就诊且就诊记录诊断缺失的个体中理论上可抓取到的目标疾病患者人数,d代表参保且有就诊且就诊记录诊断缺失的个体中可以抓取到的非目标疾病患者人数,e代表参保但从未就诊的个体人数。
而直接剔除后的发病率计算公式表示为式6:
理想状态下的发病率与直接剔除后的发病率两者显然不等。因此,需要对诊断缺失部分,基于一定假设,进行适当估算,以获取c和d的数值。本发明采用的初始假设是就诊信息的诊断缺失与是否罹患某种罕见病的关联不存在统计学意义,即
其中,c+d为诊断缺失的总记录数,可直接计数得到。
根据式7计算得到分子中需要填补的人数。注意,需要填补测算的新发患者诊断缺失部分为:参保且有报销记录但未出现目标诊断的个体中当月有就诊但诊断缺失的人数m1,3,按照上述假设进行填补,caseimpute_m=c,填补后的目标疾病新发患者人数总数为
a5.分子患者的基本特征核查与统一
医保数据分为“参保人员信息表”、“普通门(急)诊费用及结算信息表”和“门诊大病、门诊统筹、住院、家庭病床费用及结算信息表”3张表单,各表单之间通过关联变量,对年龄、性别、民族、户籍等需要进行多部核查和统一,以达到每个关联变量对应唯一的身份识别id(如身份证),同时每个唯一的身份识别id对应的年龄、性别、民族和户籍等信息内部一致。
a6.发病率的计算
发病率计算公式(以人年为单位)
其中,∑newcase表示该观察年内的新发患者总数,包括数据库中观察到的新发患者和填补测算的新发患者之和;personyear表示同时期的暴露人口数,即指该观察年内该观察地区内可能发生该病的人群;∑tcase为每个月需填补测算的新发患者之和,
每个月的分母总数∑tpersonmonth通过下式计算得到:
∑tpersonmoth=∑tpersonmonth1+∑tpersonmonth2+∑tpersonmonth3
其中,t表示第t个月份。∑tpersonmonth1对应参保但从未报销的个体所贡献的人月,∑tpersonmonth2代表参保且有报销记录但未出现目标诊断的个体所贡献的人月,∑tpersonmonth3代表参保有报销记录且出现目标诊断的个体所贡献的人月,
下面通过实例来对本发明做进一步说明。
本实例选取2012-2016年的某省城镇职工参保库和城镇居民参保库,选取四年为洗脱期,则计算基于该省2016年的医保数据库计算多发性骨髓瘤的患病率,数据库包括2016年的城镇职工参保人员(217,342,112人)、城镇居民参保人员(145,714,765人)。
完成基本的数据清洗后(如报销日期、就诊日期变量缺失、异常等),多发性骨髓瘤的临床诊断方式结合文本、icd编码表述如表2:
表2多发性骨髓瘤的诊断描述和icd编码列举
数据库中包含诊断信息的字段名称共有6个,分别是主要诊断名称、主要诊断编码、第一次要诊断名称、第一次要诊断编码、第二次要诊断名称和第二次要诊断编码,则实际定义按照数据库内字段结构定义如下:
上述各字段必须包含字段取值(字段之间为“或者”关系):骨髓瘤,卡勒,骨髓癌/骨髓ca,骨髓病,c90,m9732,203.0;
上述各字段必须排除字段取值(字段之间为“或者”关系):浆细胞,孤立性,c90.1,c90.2
具体分子抓取时,针对主要诊断、第一次要诊断、第二次要诊断、主要诊断编码、第一次要诊断编码和第二次要诊断编码共六个字段展开,要求全部六个字段中,必须具备至少一个“必须包含字段”,但必须不含有“必须排除字段”。
然后进行分母信息的汇总,其中每月参保个体总数、每月就诊记录总数和每月就诊记录诊断缺失总数在每个月的分布如表3所示:
表3分子分母计算需要用到的医保数据参数汇总表
需要说明的是,每月参保个体总数=参保但从未报销的个体+参保且有报销记录单位出现目标诊断的个体+参保有报销记录且出现目标诊断的个体,故这里仅列出了医保数据中的关键参数每月参保个体总数。
一、分母的计算
分母的计算分为两部分:2016年年均参保人数和2016年之前已患病的个体数。
第一部分2016年年均参保人数采用采用12个月平均的方法,得:(30152092+28539556+30571984+30615202+28779370+30912654+31344596+28196530+30464440+30734528+32040068
+30705856)/12=30254740
第二部分2016年前的已患病个体数通过以下方法得到:将该省2012-2016年的数据库分为2012-2015年和2016年两部分,每一部分都保证每一个个体仅有一条诊断记录,将两个数据库用软件进行横向合并,匹配的部分即为在2016年有就诊记录且在2016年前已被诊断为多发性骨髓瘤的患者数,通过此法得到该省2016年前已患病的个体数为3821人。
二、分子的计算
分子的计算分为两部分:新发患者数和需填补测算的患者
第一部分新发患者数,采用与已患病个体数同样的方法得到,即:将该省2012-2016年的数据库分为2012-2015年和2016年两部分,每一部分都保证每一个个体仅有一条诊断记录,将两个数据库用软件进行横向合并,匹配结果中仅在2016年的数据库中出现的部分即为在2016多发性骨髓瘤的新发患者数,通过此法得到该省2016年新发患者个体数为417人。
第二部分需填补的患者数计算如下(本例以年为单位计算需填补患者数),先计算出2016年年均就诊记录数为:
(5266439+4685125+5446965+4767414+5356961+4962207+5627907+4545582+4700331+5365805+5684190+5739000)/12=5178994
2016年年均就诊记录诊断缺失数为:
(331479+314970+333140+315726+300708+271454+274475+282899+273228+284421+277799+280500)/12=295067
然后根据2016年中的新发患者417人,计算需填补的患者数为:(417*295067)/(5178994-295067)=25
则发病率计算如下:
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!