基于生物反馈的精神状态干预与调节系统及其工作方法与流程
本发明涉及精神状态干预与调节技术领域,更具体地说,涉及一种基于生物反馈的精神状态干预与调节系统及其工作方法。
背景技术:
生物反馈技术是利用现代生理科学仪器,通过人体内生理或病理信息的自身反馈,使被试者经过特殊训练后,进行有意识的“意念”控制和心理训练。随着生物反馈技术的发展,针对情绪调控的训练成为可能。近两年已经有研究利用实时的功能磁共振成像fmri反馈技术进行情绪调控的训练,被试者通过直观的观测到自身的大脑活动情况,来完成调控过程,有效证实了系统的可行性。但是,基于fmri的反馈实验代价高;同时作为一个动态过程,情绪调控的时变特性是毫秒级的,采用fmri进行的反馈系统,实时性不高,影响了调控效率。
此外,现有的生物反馈技术多采用与显示屏交互的方法,比如将游戏或者视频与生物反馈技术相结合,来调整人的生理及心理状态,这种与显示屏的交互是非常生硬的,人不能很好地沉浸在刺激氛围,因此干预与调节效果一般。
现有的精神状态评估大多通过采集人体的生理信号,如脑电、皮电、肌电、心率等信号来对人的情绪进行分析,从而实现对精神状态的评估。但是现有的基于脑电的精神状态评估系统是通过电极采集脑电信号,然后用短时傅里叶变换、主成分分析等算法进行数据处理,提取数据特征,在不同频段对情绪进行识别,但是该算法提取的特征应用于情绪识别时效果并不好。
技术实现要素:
为克服现有技术中的缺点与不足,本发明的一个目的在于提供一种基于生物反馈的精神状态干预与调节系统。该系统在被试者接受刺激状态下监测分析被试者精神状态,并根据精神状态调节刺激内容和强度,从而对被试者的情绪进行影响,进而对精神状态进行干预和调节,实现简便,具有良好实时性,效率高。本发明的另一个目的在于提供一种上述精神状态干预与调节系统的工作方法,该工作方法实现简便,精神状态调节具有良好实时性。
为了达到上述目的,本发明通过下述技术方案予以实现:一种基于生物反馈的精神状态干预与调节系统,其特征在于:包括:
用于将场景源文件投影成影像的投影模块;
用于将与投影影像相对应的音频源文件进行播放的音频播放模块;
用于采集被试者生理信号的生理信号采集模块;
用于对生理信号采集模块采集到的生理信号进行情绪识别和精神状态评估,得到精神状态评估结果的精神状态评估模块;
以及用于根据精神状态评估模块得到的精神状态评估结果来调整场景源文件和音频源文件,并反馈到投影模块和音频播放模块的精神状态干预调节模块。
优选地,还包括用于储存和管理精神状态评估结果和生理信号的云平台,云平台与精神状态评估模块信号连接。
一种上述精神状态干预与调节系统的工作方法,其特征在于:包括如下步骤:
s1步,投影模块将场景源文件投影成影像供被试者观看,对被试者进行视觉刺激;同时音频播放模块将与投影影像相对应的音频源文件进行播放,对被试者进行听觉刺激;
s2步,生理信号采集模块采集被试者的生理信号;生理信号包括脑电信号、心率信号、肌电信号、皮电信号、面部表情信号和语音信号中的任一项或两项以上;
s3步,精神状态评估模块对生理信号进行预处理、特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果;
s4步,精神状态干预调节模块根据精神状态评估结果调整场景源文件,并反馈到投影模块,以调整投影模块的投影影像;同时调整音频源文件,并反馈到音频播放模块,以播放与投影影像相对应的音乐。
优选地,所述s1步中,投影模块将场景源文件投影成影像供被试者观看,对被试者进行视觉刺激,是指:投影模块为全息投影模块,全息投影模块将场景源文件投影成影像供被试者观看,对被试者进行视觉刺激。
优选地,所述s1步中,音频播放模块将与投影影像相对应的音频源文件进行播放,对被试者进行听觉刺激,是指:音频播放模块为扬声器或入耳式耳机或骨传导耳机;扬声器或入耳式耳机或骨传导耳机将与投影影像相对应的音频源文件进行播放,对被试者进行听觉刺激。
优选地,所述s2步中,生理信号采集模块采集被试者的生理信号,是指:生理信号采集模块采集被试者的脑电信号;
s3步,精神状态评估模块对生理信号进行预处理、特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果,是指:精神状态评估模块对脑电信号进行预处理,并采用动态图卷积神经网络算法结合宽度学习系统进行特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果。
优选地,所述的精神状态评估模块对脑电信号进行预处理,并采用动态图卷积神经网络算法结合宽度学习系统进行特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果,是指:采用独立成分分析算法和主成分分析算法去除脑电信号中的眼电、心电、电磁干扰伪迹以实现预处理;采用动态图卷积神经网络算法来提取脑电信号的特征,将脑电信号映射到特征空间,然后在特征空间中采用宽度学习系统作为分类器,将脑电信号进行情绪分类识别,得到各个情绪类别的强度值;根据各个情绪类别的强度值评估被试者的精神状态。
优选地,所述情绪类别包括疲劳、抑郁、沮丧和无聊;根据各个情绪类别的强度值评估被试者的精神状态,是指:设定疲劳正常值、抑郁正常值、沮丧正常值和无聊正常值,分别判断疲劳强度值与疲劳正常值的比值、抑郁强度值与抑郁正常值的比值、沮丧强度值与沮丧正常值的比值和无聊强度值与无聊正常值来评估被试者的精神状态。
优选地,所述s4步中,精神状态干预调节模块根据精神状态评估结果调整场景源文件,并反馈到投影模块,以调整投影模块的投影影像;同时调整音频源文件,并反馈到音频播放模块,以播放与投影影像相对应的音乐,是指:采用如下两种方案之一:
一、精神状态干预调节模块根据精神状态评估结果从精神状态干预调节模块中的投影场景库调出相应的场景源文件,并把场景源文件发送至投影模块,投影模块对接收到的场景源文件进行投影以调整投影影像;同时精神状态干预调节模块从精神状态干预调节模块中的播放音频库调出与投影影像相对应的音频源文件,并把音频源文件发送至音频播放模块,音频播放模块对接收到的音频源文件进行播放以使音频播放模块播放与投影影像相对应的音乐;
二、精神状态干预调节模块根据精神状态评估结果生成相对应的投影信号指令,并发送至投影模块;投影模块根据投影信号指令从投影模块中的投影场景库调出相对应的场景源文件进行投影以调整投影影像;同时精神状态干预调节模块生成与投影信号指令相对应的音频信号指令,并发送至音频播放模块;音频播放模块根据音频信号指令从音频播放模块中的播放音频库调出相对应的音频源文件进行播放以使音频播放模块播放与投影影像相对应的音乐。
与现有技术相比,本发明具有如下优点与有益效果:
1、本发明在对被试者进行视觉刺激和听觉刺激状态下采集被试者的生理信号评估被试者的精神状态,并实时调整投影影像和音乐来调节刺激内容和强度,从而实时对被试者的情绪进行影响,进而对精神状态进行干预和调节;实现简便,对被试者情绪调控进行实时监测和训练,集精神状态评估和干预调节于一体,具有良好的实时性,效率高;
2、传统的情绪刺激多是采用图片或者视频,被试者不容易快速进入状态,而且可能会出现走神的情况,使得采集的脑电信号不准确;本发明设计与情绪相关联的全息投影场景,利用全息投影技术的干涉和衍射原理记录并再现物体真实的三维图像,而且从人眼对物体深度感在生理上的心理暗示加以考虑,生成更加逼真的立体三维图像,让人有更加沉浸式的体验,对情绪的刺激也更加准确和强烈;
3、本发明在精神状态评估模块中,采用动态图卷积神经网络算法(dynamicalgraphconvolutionalneuralnetworks,dgcnn)和宽度学习系统(broadlearningsystem,bls),即dgcnn+bls的算法来实现精神状态的评估;动态图卷积神经网络算法是卷积神经网络算法(cnn)在图上的一个扩展;传统cnn的研究对象主要针对于规则空间结构的数据,而dgcnn采用图谱的思想,实现对不规则空间结构的数据进行深度学习的方法;动态图卷积神经网络算法可以实现端到端的学习,从原始的脑电信号中自动学习出复杂的特征;宽度学习系统是一种不需要深度结构的增量学习系统,它可以作为一个分类器来进行情绪的分类与识别,效果好且速度非常快;因此这种深度学习+宽度学习的算法对精神状态的评估更加准确;
4、本发明不仅可以采用扬声器和入耳式耳机播放音频,还可以用骨传导耳机来播放音频;骨传导耳机将声音转化为不同频率的机械振动信号,通过人的颅骨、肌体和神经组织来传递;相对于传统通过振膜来产生声波的声音传导方式,骨传导省去了许多声波传递的步骤;并且能在嘈杂的环境中实现清晰的声音还原,相比传统的入耳式耳机以及扬声器具有更出色的音频播放效果,而且声波也不会因为在空气中扩散而影响到他人;
5、本发明中精神状态评估模块将采集到的生理信号以及得到的精神状态评估结果发送至云平台,方便实现云平台的数据存储、处理和数据分析操作,便于进行模型校正。
附图说明
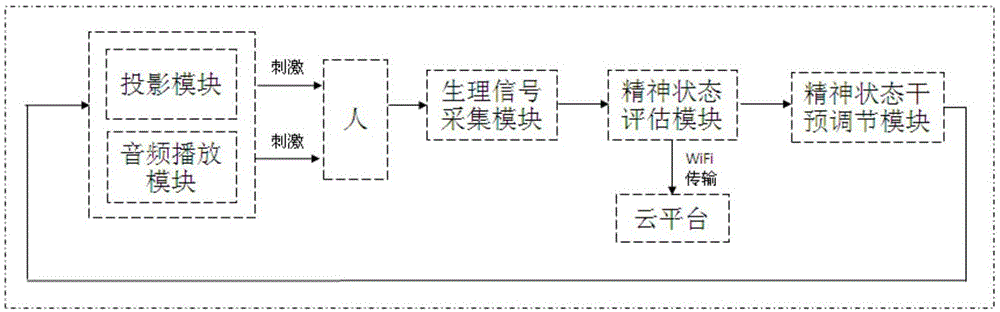
图1是本发明系统的框图;
图2是本发明系统中全息投影模块的框图;
图3是本发明系统中音频播放模块的框图;
图4是本发明系统中生理信号采集模块的框图;
图5是本发明系统中精神状态评估模块的框图;
图6是本发明系统中精神状态干预调节模块的框图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细的描述。
实施例
本实施例基于生物反馈的精神状态干预与调节系统,其结构如图1所示,包括:
用于将场景源文件投影成影像的投影模块;
用于将与投影影像相对应的音频源文件进行播放的音频播放模块;
用于采集被试者生理信号的生理信号采集模块;
用于对生理信号采集模块采集到的生理信号进行情绪识别和精神状态评估,得到精神状态评估结果的精神状态评估模块;
以及用于根据精神状态评估模块得到的精神状态评估结果来调整场景源文件和音频源文件,并反馈到投影模块和音频播放模块的精神状态干预调节模块。
优选还包括用于储存和管理精神状态评估结果和生理信号的云平台,云平台与精神状态评估模块信号连接。
精神状态干预与调节系统的工作方法包括如下步骤:
s1步,投影模块将场景源文件投影成影像供被试者观看,对被试者进行视觉刺激;同时音频播放模块将与投影影像相对应的音频源文件进行播放,对被试者进行听觉刺激;
s2步,生理信号采集模块采集被试者的生理信号;生理信号包括脑电信号、心率信号、肌电信号、皮电信号、面部表情信号和语音信号中的任一项或两项以上;
s3步,精神状态评估模块对生理信号进行预处理、特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果;
s4步,精神状态干预调节模块根据精神状态评估结果调整场景源文件,并反馈到投影模块,以调整投影模块的投影影像;同时调整音频源文件,并反馈到音频播放模块,以播放与投影影像相对应的音乐。
本发明在对被试者进行视觉刺激和听觉刺激状态下采集被试者的生理信号评估被试者的精神状态,调整投影影像和音乐来调节刺激内容和强度,从而对被试者的情绪进行影响,进而对被试者的精神状态进行干预和调节;实现简便,对被试者情绪调控进行实时监测和训练,具有良好的实时性,效率高。
以被试者克服恐高为例,首先精神状态干预调节模块从投影场景库中选择10层楼高的场景源文件,发送给投影模块,并且选择一些轻松的音乐发送给音频播放模块,投影模块投影出10层楼高的影像,对被试者的情绪进行刺激,生理信号采集模块采集人的生理信号,如脑电、肌电、心率等,通过精神状态评估模块进行情绪分析和精神状态评估。一段时间后,当被试者逐渐习惯了10层楼的高度,精神状态评估模块会检测到被试者不再那么恐惧,精神状态干预调节模块接收到此精神状态评估结果后,智能调整投影影像,例如选择20层楼高的场景源文件,发送给投影模块,从而对被试者的精神状态进行干预和调节,帮助被试者逐渐克服恐高。
优选的方案是:s1步中,投影模块将场景源文件投影成影像供被试者观看,对被试者进行视觉刺激,是指:投影模块为全息投影模块,全息投影模块将场景源文件投影成影像供被试者观看,对被试者进行视觉刺激。
全息投影模块主要是对全息场景库中的源文件进行投影,生成三维立体全息投影影像。如图2所示,首先将场景源文件通过显示屏播放,显示屏的播放内容通过塔形玻璃进行反射之后,形成立体的三维全息投影影像。全息投影的场景源文件的选择是由精神状态干预调节模块完成。
音频播放模块将与投影影像相对应的音频源文件进行播放,对被试者进行听觉刺激,是指:音频播放模块为扬声器或入耳式耳机或骨传导耳机;扬声器或入耳式耳机或骨传导耳机将与投影影像相对应的音频源文件进行播放,对被试者进行听觉刺激,如图3所示。
骨传导耳机是将声音转化为不同频率的机械振动信号,通过人的颅骨、肌体和神经组织来传递。相对于传统通过振膜来产生声波的声音传导方式,骨传导耳机省去了许多声波传递的步骤,并且能在嘈杂的环境中实现清晰的声音还原,而且声波也不会因为在空气中扩散而影响到他人。在使用时,被试者可以根据具体的情况自由选择播放音频的方式,从而有更好的体验效果。
s2步中,生理信号采集模块采集被试者的生理信号,是指:生理信号优选为脑电信号,生理信号采集模块采集被试者的脑电信号。生理信号采集模块如图4所示,优选采用智能头带、智能头盔等可穿戴设备,可采用stm32芯片进行控制和处理,首先将可穿戴设备戴在被试者头部,使电极稳定接触前额皮肤,然后进行导联选择,采集一导联至多导联的脑电信号,将采集到的脑电信号进行前置放大,以得到比较强烈的信号,之后进行后置放大和滤波操作,最后输出脑电信号。
s3步,精神状态评估模块对生理信号进行预处理、特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果,是指:精神状态评估模块对脑电信号进行预处理,并采用动态图卷积神经网络算法结合宽度学习系统进行特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果,如图5所示。
进一步地说,所述的精神状态评估模块对脑电信号进行预处理,并采用动态图卷积神经网络算法结合宽度学习系统进行特征提取和情绪识别,对被试者的精神状态进行评估,得到精神状态评估结果,是指:采用独立成分分析算法和主成分分析算法去除脑电信号中的眼电、心电、电磁干扰伪迹以实现预处理;采用动态图卷积神经网络算法来提取脑电信号的特征,将脑电信号映射到特征空间,然后在特征空间中采用宽度学习系统作为分类器,将脑电信号进行情绪分类识别,得到各个情绪类别的强度值;根据各个情绪类别的强度值评估被试者的精神状态。
情绪类别包括疲劳、抑郁、沮丧和无聊;根据各个情绪类别的强度值评估被试者的精神状态,是指:设定疲劳正常值、抑郁正常值、沮丧正常值和无聊正常值,分别判断疲劳强度值与疲劳正常值的比值、抑郁强度值与抑郁正常值的比值、沮丧强度值与沮丧正常值的比值和无聊强度值与无聊正常值来评估被试者的精神状态。
s4步中,精神状态干预调节模块根据精神状态评估结果调整场景源文件,并反馈到投影模块,以调整投影模块的投影影像;同时调整音频源文件,并反馈到音频播放模块,以播放与投影影像相对应的音乐,是指:采用如下两种方案之一:
一、精神状态干预调节模块根据精神状态评估结果从精神状态干预调节模块中的投影场景库调出相应的场景源文件,并把场景源文件发送至投影模块,投影模块对接收到的场景源文件进行投影以调整投影影像;同时精神状态干预调节模块从精神状态干预调节模块中的播放音频库调出与投影影像相对应的音频源文件,并把音频源文件发送至音频播放模块,音频播放模块对接收到的音频源文件进行播放以使音频播放模块播放与投影影像相对应的音乐,如图6所示;
二、精神状态干预调节模块根据精神状态评估结果生成相对应的投影信号指令,并发送至投影模块;投影模块根据投影信号指令从投影模块中的投影场景库调出相对应的场景源文件进行投影以调整投影影像;同时精神状态干预调节模块生成与投影信号指令相对应的音频信号指令,并发送至音频播放模块;音频播放模块根据音频信号指令从音频播放模块中的播放音频库调出相对应的音频源文件进行播放以使音频播放模块播放与投影影像相对应的音乐。
精神状态评估模块通过wifi无线通信模块与云平台实现信号连接。wifi无线通信模块设置可用串口wifi模块tln13ua06,m02spi转wifi模块等等。精神状态评估模块将采集到的生理信号以及得到的精神状态评估结果通过wifi无线通信模块发送至云平台,方便实现云平台的数据存储、处理和数据分析操作。
本发明的优点是:
1、本发明在对被试者进行视觉刺激和听觉刺激状态下采集被试者的生理信号评估被试者的精神状态,调整投影影像和音乐来调节刺激内容和强度,从而对被试者的精神状态进行干预和调节;实现简便,对被试者情绪调控进行实时监测和训练,具有良好的实时性,效率高;
2、传统的情绪刺激多是采用图片或者视频,被试者不容易快速进入状态,而且可能会出现走神的情况,使得采集的脑电信号不准确;本发明设计与情绪相关联的全息投影场景,利用全息投影技术的干涉和衍射原理记录并再现物体真实的三维图像,而且从人眼对物体深度感在生理上的心理暗示加以考虑,生成更加逼真的立体三维图像,让人有更加沉浸式的体验,对情绪的刺激也更加准确和强烈;
3、本发明在精神状态评估模块中,采用动态图卷积神经网络算法(dynamicalgraphconvolutionalneuralnetworks,dgcnn)和宽度学习系统(broadlearningsystem,bls),即dgcnn+bls的算法来实现精神状态的评估;动态图卷积神经网络算法是卷积神经网络算法(cnn)在图上的一个扩展;传统cnn的研究对象主要针对于规则空间结构的数据,而dgcnn采用图谱的思想,实现对不规则空间结构的数据进行深度学习的方法;动态图卷积神经网络算法可以实现端到端的学习,从原始的脑电信号中自动学习出复杂的特征;宽度学习系统是一种不需要深度结构的增量学习系统,它可以作为一个分类器来进行情绪的分类与识别,效果好且速度非常快;因此这种深度学习+宽度学习的算法对精神状态的评估更加准确;
4、本发明不仅可以采用扬声器和入耳式耳机播放音频,还可以用骨传导耳机来播放音频;骨传导耳机将声音转化为不同频率的机械振动信号,通过人的颅骨、肌体和神经组织来传递;相对于传统通过振膜来产生声波的声音传导方式,骨传导省去了许多声波传递的步骤;并且能在嘈杂的环境中实现清晰的声音还原,相比传统的入耳式耳机以及扬声器具有更出色的音频播放效果,而且声波也不会因为在空气中扩散而影响到他人;
5、本发明中精神状态评估模块将采集到的生理信号以及得到的精神状态评估结果发送至云平台,方便实现云平台的数据存储、处理和数据分析操作,便于进行模型校正。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!