一种文本结构化方法及装置与流程
本公开涉及文本处理技术领域,尤其涉及一种文本结构化方法及装置。
背景技术:
电子病历系统的现代化是医疗信息建设的关键之一,电子病历中包含的信息对于建立起追随病人一生的健康画像起着至关重要的作用。同时,电子病历也是医疗科研的重要元数据。
目前,市面上大量的电子病历往往直接将诊疗诊断、医生查房等众多的文本信息直接存储为文本字段,舍弃了电子病历中应有的大量结构化信息,不利于信息的标准化存储、分享以及分析。
相关技术中,可以通过模板匹配、关键词匹配以及机器学习等方法对病历进行结构化处理。其中,模板匹配法和关键词匹配法的正确率较低,机器学习法则需要进行大量的数据标注,操作繁琐。
技术实现要素:
有鉴于此,本公开提出了一种文本结构化方法及装置,能够提高文本结构化的正确率和效率。
根据本公开的一方面,提供了一种文本结构化方法,所述方法包括:获取与上下文无关的文法规则集;通过基于所述与上下文无关的文法规则集生成的语法分析器对文本集合中各文本进行解析;针对所述文本集合中每个文本,在所述语法分析器成功解析该文本时,将所述语法分析器的输出确定为该文本对应的结构化文本。
根据本公开的另一方面,提供了一种文本结构化装置,所述装置包括:获取模块,用于获取与上下文无关的文法规则集;解析模块,用于通过基于所述与上下文无关的文法规则集生成的语法分析器对文本集合中各文本进行解析;确定模块,用于针对所述文本集合中每个文本,在所述语法分析器成功解析该文本时,将所述语法分析器的输出确定为该文本对应的结构化文本。
在本公开实施例中,利用与上下文无关的文法的算法将文本的结构提取出来,从而将文本转换为结构化文本,保留了层次化结构,提高文本结构化的正确率,也无需标注语料,提高了文本结构化的效率。
根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
附图说明
包含在说明书中并且构成说明书的一部分的附图与说明书一起示出了本公开的示例性实施例、特征和方面,并且用于解释本公开的原理。
图1示出根据本公开一实施例的文本结构化方法的流程图。
图2示出根据本公开一实施例的文本结构化装置的框图。
具体实施方式
以下将参考附图详细说明本公开的各种示例性实施例、特征和方面。附图中相同的附图标记表示功能相同或相似的元件。尽管在附图中示出了实施例的各种方面,但是除非特别指出,不必按比例绘制附图。
在这里专用的词“示例性”意为“用作例子、实施例或说明性”。这里作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。
另外,为了更好的说明本公开,在下文的具体实施方式中给出了众多的具体细节。本领域技术人员应当理解,没有某些具体细节,本公开同样可以实施。在一些实例中,对于本领域技术人员熟知的方法、手段、元件和电路未作详细描述,以便于凸显本公开的主旨。
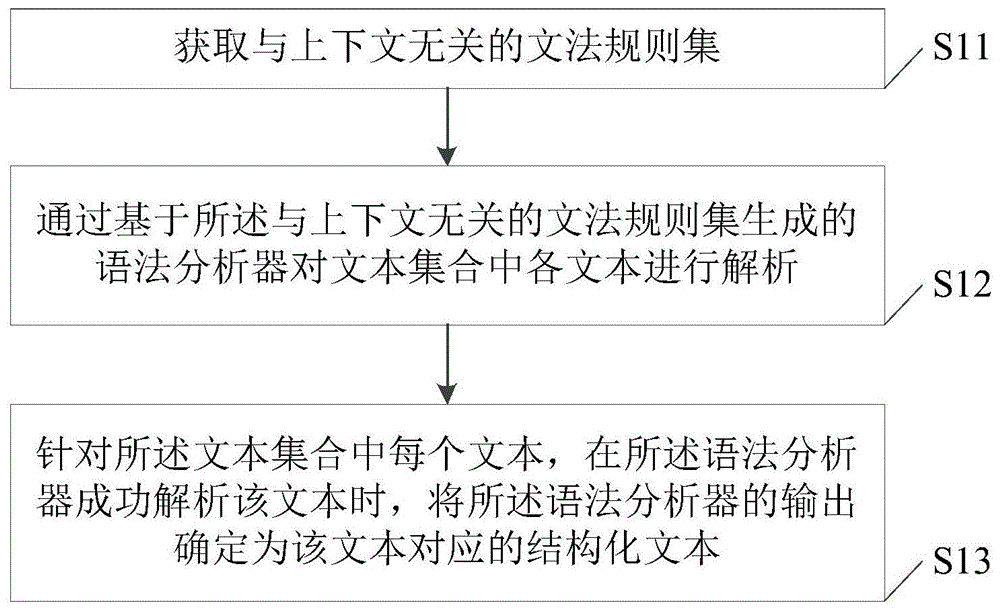
图1示出根据本公开一实施例的文本结构化方法的流程图。该方法可以应用于计算机等终端。在本公开实施例中以病历作为文本为例进行说明,本公开实施例的文本结构化方法还可以用于其他文本的处理。如图1所示,该方法可以包括:
步骤s11,获取与上下文无关的文法规则集。
步骤s12,通过基于所述与上下文无关的文法规则集生成的语法分析器对文本集合中各文本进行解析。
步骤s13,针对所述文本集合中每个文本,在所述语法分析器成功解析该文本时,将所述语法分析器的输出确定为该文本对应的结构化文本。
在本公开实施例中,利用与上下文无关的文法的算法将文本的结构提取出来,从而将文本转换为结构化文本,保留了层次化结构,提高文本结构化的正确率,也无需标注语料,提高了文本结构化的效率。
上下文无关文法(contextfreegrammar,cfg)是一种形式文法,其定义为:对某个形式文法g,如果规则集p中的每一条规则的形式为v→w,v∈vn,w∈{vn∪vt}*,则该形式文法g为上下文无关文法。按照上下文无关文法的定义,字符v总可以被字符串w自由替换,而无需考虑字符v出现的上下文。
在步骤s11中,与上下文无关的文法规则集(下文中简称为:规则集)中每一条规则的形式均符合上下文无关文法。
终端可以基于规则集生成语法分析器,例如,利用antlr识别规则集自动生成语法分析器。其中,antlr是指可以根据输入自动生成语法树并可视化显示出来的开源语法分析器。antlr允许定义用于解释token流的语法分析规则,然后根据语法分析规则自动生成相应的语法分析器。用户可以利用语法分析器将输入的文本进行编译,并转换成其他形式。在本公开实施例中,用户可以将非结构化的电子文本输入语法分析器进行编译,从而将非结构化的电子文本转换成结构化文本。
在本公开实施例中,语法分析器对输入的电子文本进行转换的过程可以包括:将规则集中每一条规则转换为一个有向的网络图,网络图中的每一个点代表一个状态,网络图中每一个箭头代表一个所引用的子规则或者一个终结串。然后,在所产生的网络图中搜索与电子文本中某个字符串匹配的路径,并生成用于结果路径的树结构,即解析树,解析树的每个叶子节点代表对于非结构化句子和相应的结构化结果。最后遍历解析树,将解析树叶子节点的结构化结果串起来生成结构化文本。
在本公开实施例中,规则集中的规则可以引用子规则,例如用于提取个人信息规则中可以包括用于提取姓名的规则、用于提取年龄的规则和用于提取身份证号的规则等。用于提取家族病史的规则中可以包括用于提取姓名的规则和用于提取疾病名称的规则等。其中,用户提取姓名的规则分别被用于提取个人信息规则和用于提取家族病史的规则引用,分别用于提取患者姓名和家属姓名。相较于相关技术中直接采用关键字进行匹配,根据本公开实施例的文本结构化方法可以确定提取的姓名具体属于哪一部分信息,可以保留层次化的结构。
在步骤s12中,文本集合可以表示包括多个文本的集合。终端可以通过语法分析器分别对文本集合中的每个文本进行解析。
在一种可能的实现方式中,文本集合包括的文本可以为电子文本。此时,针对文本集合中的每个文本,终端可以将该文本直接输入语法分析器,从而通过语法分析器对该文本进行解析。在一种可能的实现方式中,文本集合包括的文本可以为物理文本。此时,针对文本集合中的每个文本,可以先将该文本转化为电子文本,再将转化得到的电子文本输入语法分析器,从而通过语法分析器对该文本进行解析。其中,可以通过获取物理文本的图像,并对图像进行文字识别从而将物理文本转化为电子文本;也可以通过人工录入的方式将物理文本转化为电子文本。
语法分析器对文本进行解析后,可以输出解析结果。在解析成功的情况下,语法分析器可以输出解析成功的提示,并输出解析得到的结构化文本。在解析失败的情况下,语法分析器可以输出解析失败的提示,并输出解析失败的原因。
在本公开实施例中,通过语法解析器对文本进行解析后,如果语法解析器成功解析了该文本,则终端可以将直接将语法解析器的输出确定为该文本的结构化文本。
在一种可能的实现方式中,终端可以确定文本集合的解析成功率。若文本集合的解析成功率大于或者等于阈值,则在所述语法分析器成功解析该文本时,将所述语法分析器的输出确定为该文本对应的结构化文本。若文本集合的解析成功率小于阈值,则调整所述与上下文无关的文法规则集。
其中,文本集合的解析成功率可以为语法分析器成功解析的文本的数量与所述文本集合包括的文本的数量的比。阈值可以根据需要设置,例如可以设置为95%,对此本公开不做限制。
当文本集合的解析成功率大于或者等于阈值时,表明规则集能够较完整的覆盖文本集合中的文本的内容。因此,当文本集合的解析成功率大于或者等于阈值时,针对解析成功的文本,终端可以将语法分析器的输出确定为该文本对应的结构化文本。
当文本集合的解析成功率小于阈值时,表明规则集无法较完整的覆盖文本集合中的文本的内容。因此,当文本集合的解析成功率小于阈值时,终端可以调整规则集。
在一种可能的实现方式中,调整所述与上下文无关的文法规则集可包括:针对每个所述语法分析器未成功解析的文本,根据该文本调整所述与上下文无关的文法规则集。
终端可以依次根据每个未成功解析的文本调整规则集。根据不同未成功解析的文本调整规则集的方法相同。下面以根据任意一个未成功解析的文本调整规则集为例进行说明。
文本未被成功解析的原因至少包括两种,分别为:语法解析器未成功解析文本的关键词,以及语法解析器未成功解析文本的字段。举例来说,若语法解析器未成功解析文本中的姓名,则确定语法解析器未成功解析该文本的关键词。若语法解析器未成功解析文本中的姓名的具体内容(例如张某),则确定语法解析器未成功解析文本的字段。
针对语法解析器未成功解析文本的关键词的情况:
若所述语法解析器未成功解析该文本的关键词,则将第一描述词作为关键词添加至所述与上下文无关的文法规则集中,所述第一描述词可以包括该文本中与未成功解析的关键词匹配的词语。
以关键词“姓名”为例,假设规则集中定义了“患者姓名”、“‘姓’‘空格’‘名’”可以替代“姓名”,而文本中采用“名字”描述患者的姓名。由于语法解析器未在文本中查找到“姓名”、“患者姓名”,以及“‘姓’‘空格’‘名’”,因此可以确定关键词“姓名”解析失败。终端可以在文本中查找到“名字”与“姓名”匹配,因此,终端可以将“名字”确定为第一描述词,并将“名字”添加至规则集中,使得“名字”可以替代“姓名”。
针对语法解析器未成功解析文本的字段的情况:
当语法解析器未成功解析文本的字段时,可能存在两种原因:一种是语法解析器未成功解析该字段对应的关键词,另一种是语法解析器虽然成功解析了该字段对应的关键词,但是未获取到该关键词的取值。
文本的字段可以表示关键词的取值,例如“张某”、“李某”等患者的名字为关键词“姓名”的取值,“张某”、“李某”等患者的名字就是文本的字段。
在一种可能的实现方式中,若所述语法解析器未成功解析该文本的字段,则确定所述与上下文无关的文法规则集的关键词中是否存在第二描述词,所述第二描述词可以包括该文本中与未成功解析的字段对应的词语;若所述与上下文无关的文法规则集的关键词中不存在所述第二描述词,则将所述第二描述词作为关键词添加至所述与上下文无关的文法规则集中。
在一种可能的实现方式中,若所述与上下文无关的文法规则集的关键词中存在所述第二描述词,则根据该文本向所述与上下文无关的文法规则集中添加与该文本中未成功解析的字段对应的与上下文无关的文法规则。
当规则集的关键词中不存在第二描述词,表明规则集可能未较完整的覆盖文本的内容,此时,终端可以根据该文本向所述与上下文无关的文法规则集中添加与该文本中未成功解析的字段对应的与上下文无关的文法规则。
例如,当终端确定未获取到患者的名字“张某”时,可以获取文本中与“张某”对应的词语作为第二描述词。假设第二描述词为“名字”,则终端可以在规则集查找“名字”。当规则集中不存在“名字”时,则可以将“名字”添加至规则集中。当规则集中存在“名字”时,可能规则集未覆盖文本中的个人信息,需要向规则集中添加与个人信息相关的与上下文无关的文法规则。
在一种可能的实现方式中,终端可以基于调整后的规则集生成新的语法分析器,将文本集合中各文本输入新的语法分析器进行分析,并重新确定文本集合的解析成功率,直至文本集合解析成功率大于或者等于阈值。
在一种可能的实现方式中,步骤s11可以包括:根据所述文本集合包括的文本的类型获取与上下文无关的文法规则集。
不同类型的文本的结构不同、层次不同、包括的关键字也不同,相应制定的规则集也就不同。因此,终端需要根据文本集合包括的文本的类型获取与上下文无关的文法规则集,以使规则集更符合文本的结构,从而提升文本结构化的正确率。
举例来说,电子病历按照类型可以分为入院记录、首次病程、其他查房记录、手术记录、主任首次查房记录、出院记录、日常病程、死亡记录、术前小结,以及术后首次病程记录等。
在一个示例中,文本集合中包括的电子病历的类型相同,终端可以按照电子病历的类型将原始电子病历分到不同的文本集合中,针对各文本集合分别获取与上下文无关的文法规则集。
在一个示例中,文本集合中包括的电子病历的类型不同,终端可以分别获取各类型电子病历对应的与上下文无关的文法规则集,将获取的各类型电子病历对应的与上下文无关的文法规则集组合在一起,得到针对文本集合的与上下文无关的文法规则集。
图2示出根据本公开一实施例的文本结构化装置的框图。该装置可以应用于终端。如图2所示,该装置30可以包括:
获取模块31,用于获取与上下文无关的文法规则集;
解析模块32,用于通过基于所述与上下文无关的文法规则集生成的语法分析器对文本集合中各文本进行解析;
确定模块33,用于针对所述文本集合中每个文本,在所述语法分析器成功解析该文本时,将所述语法分析器的输出确定为该文本对应的结构化文本。
在本公开实施例中,利用与上下文无关的文法的算法将文本的结构提取出来,从而将文本转换为结构化文本,保留了层次化结构,提高文本结构化的正确率,也无需标注语料,提高了文本结构化的效率。
在一种可能的实现方式中,所述装置30还包括:
调整模块,用于若所述文本集合的解析成功率小于阈值,则调整所述与上下文无关的文法规则集,其中,所述文本集合的解析成功率为所述语法分析器成功解析的文本的数量与所述文本集合包括的文本的数量的比。
在一种可能的实现方式中,所述调整模块还用于:
针对每个所述语法分析器未成功解析的文本,根据该文本调整所述与上下文无关的文法规则集。
在一种可能的实现方式中,所述调整模块还用于:
若所述语法解析器未成功解析该文本的关键词,则将第一描述词作为关键词添加至所述与上下文无关的文法规则集中,所述第一描述词包括该文本中与未成功解析的关键词匹配的词语。
在一种可能的实现方式中,所述调整模块还用于:
若所述语法解析器未成功解析该文本的字段,则确定所述与上下文无关的文法规则集的关键词中是否存在第二描述词,所述第二描述词包括该文本中与未成功解析的字段对应的词语;
若所述与上下文无关的文法规则集的关键词中不存在所述第二描述词,则将所述第二描述词作为关键词添加至所述与上下文无关的文法规则集中。
在一种可能的实现方式中,所述调整模块还用于:
若所述与上下文无关的文法规则集的关键词中存在所述第二描述词,则根据该文本向所述与上下文无关的文法规则集中添加与该文本中未成功解析的字段对应的与上下文无关的文法规则。
在一种可能的实现方式中,所述获取模块31还用于:
根据所述文本集合包括的文本的类型获取与上下文无关的文法规则集。
本领域内的技术人员应明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本公开是参照根据本公开实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flashram)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitorymedia),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!