基于BiLSTM的电子健康记录表示学习方法及系统与流程
本公开涉及电子健康记录(electronichealthrecords,ehr)的数据表示学习方法的研究技术领域,尤其涉及基于bilstm的电子健康记录表示学习方法及系统。
背景技术:
本部分的陈述仅仅是提到了与本公开相关的背景技术,并不必然构成现有技术。
ehr系统中存储的是与患者住院有关的大量医疗数据,包括诊断、检查结果、药物、放射影像和临床记录等。近年来,ehr的爆炸性增长为数据挖掘技术、机器学习技术和其他数据科学研究等的发展提供了许多的机会,同时也吸引了许多研究者的关注和参与。另外,ehr系统所带来的大量的有价值的医疗研究数据对探究患者病情、预测患者未来发病率等发挥着重要的作用。目前,利用现有的医疗大数据为患者提供最佳和最个性化的医疗服务正在成为医疗行业变革成功的主要趋势之一。
在实现本公开的过程中,发明人发现现有技术中存在以下技术问题:
ehr数据具有高维性、时序性、稀疏性和复杂性等特性,这为ehr数据的研究带来了许多挑战,进一步来说将ehr用于精准的、个性化的医学研究是一项具有挑战性且复杂性的工作。因此,在进行分类、回归等任务或应用之前,从ehr数据中提取出有效的医疗特征是至关重要的一步。表示学习技术的出现便为ehr数据的处理提供了很好的机会。表示学习旨在通过机器学习方法将研究对象的语义信息表示为稠密的低维实值向量,它在医学领域的作用是将医疗事件或患者特征转化为更高级的抽象表示,从而为医学领域的研究任务提供更有效且更具有鲁棒性的医疗特征。尽管表示学习技术在某些领域(例如文本数据的处理)已经取得了很大的成就,但该技术尚未广泛地应用于医疗领域。
技术实现要素:
本公开的目的就是为了解决上述问题,提供基于bilstm的电子健康记录表示学习方法及系统,不仅考虑了就诊内发生的各医疗诊断代码之间的潜在关联信息以及它们的权值比重,同时利用了患者就诊序列的时序性和差异性,综合地学习了医疗特征的向量表示。
为了实现上述目的,本公开采用如下技术方案:
第一方面,本公开提供了基于bilstm的电子健康记录表示学习方法;
基于bilstm的电子健康记录表示学习方法,包括:
构建基于bilstm的深度学习模型;
构建训练集,所述训练集为a疾病患者的电子健康记录中若干次历史就诊的诊断结果和当前就诊的诊断结果;
利用训练集对基于bilstm的深度学习模型进行训练,将某疾病患者的若干次历史就诊的诊断结果作为模型的输入值,将患者当前就诊的诊断结果作为模型的输出值;得到训练好的基于bilstm的深度学习模型;
获取同样患a疾病的待表示学习患者的电子健康记录,将待表示学习患者电子健康记录的若干次历史诊断结果输入到训练好的基于bilstm的深度学习模型中,输出待表示学习患者的最终表示学习向量。
第二方面,本公开提供了基于bilstm的电子健康记录表示学习系统;
基于bilstm的电子健康记录表示学习系统,包括:
模型构建模块,其被配置为:构建基于bilstm的深度学习模型;
训练集构建模块,其被配置为:构建训练集,所述训练集为a疾病患者的电子健康记录中若干次历史就诊的诊断结果和当前就诊的诊断结果;
模型训练模块,其被配置为:利用训练集对基于bilstm的深度学习模型进行训练,将某疾病患者的若干次历史就诊的诊断结果作为模型的输入值,将患者当前就诊的诊断结果作为模型的输出值;得到训练好的基于bilstm的深度学习模型;
学习表示向量输出模块,其被配置为:获取同样患a疾病的待表示学习患者的电子健康记录,将待表示学习患者电子健康记录的若干次历史诊断结果输入到训练好的基于bilstm的深度学习模型中,输出待表示学习患者的最终表示学习向量。
第三方面,本公开提供了基于bilstm的疾病预测系统;
基于bilstm的疾病预测系统,包括:
模型构建模块,其被配置为:构建基于bilstm的深度学习模型;
训练集构建模块,其被配置为:构建训练集,所述训练集为a疾病患者的电子健康记录中若干次历史就诊的诊断结果和当前就诊的诊断结果;
模型训练模块,其被配置为:利用训练集对基于bilstm的深度学习模型进行训练,将某疾病患者的若干次历史就诊的诊断结果作为模型的输入值,将患者当前就诊的诊断结果作为模型的输出值;得到训练好的基于bilstm的深度学习模型;
输出模块,其被配置为:获取同样患a疾病的待预测患者的电子健康记录,将待预测患者电子健康记录的若干次历史诊断结果输入到训练好的基于bilstm的深度学习模型中,输出待预测患者的疾病预测结果。
第四方面,本公开还提供了一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成第一方面所述方法的步骤。
第五方面,本公开还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述方法的步骤。
本公开的有益效果:
通过我们的训练好的基于bilstm的深度学习模型,学习得到的数据表示的性能要优于原始数据的性能。面向患者电子健康记录的表示学习方法需要综合地考虑患者的就诊治疗过程,探索隐含的重要关联信息,从而学习更加有效且更具有鲁棒性的医疗特征。所学习的数据表示能够从数据中捕获到隐含的数据规则和模式,这对于科学研究的发展是非常有帮助的。
附图说明
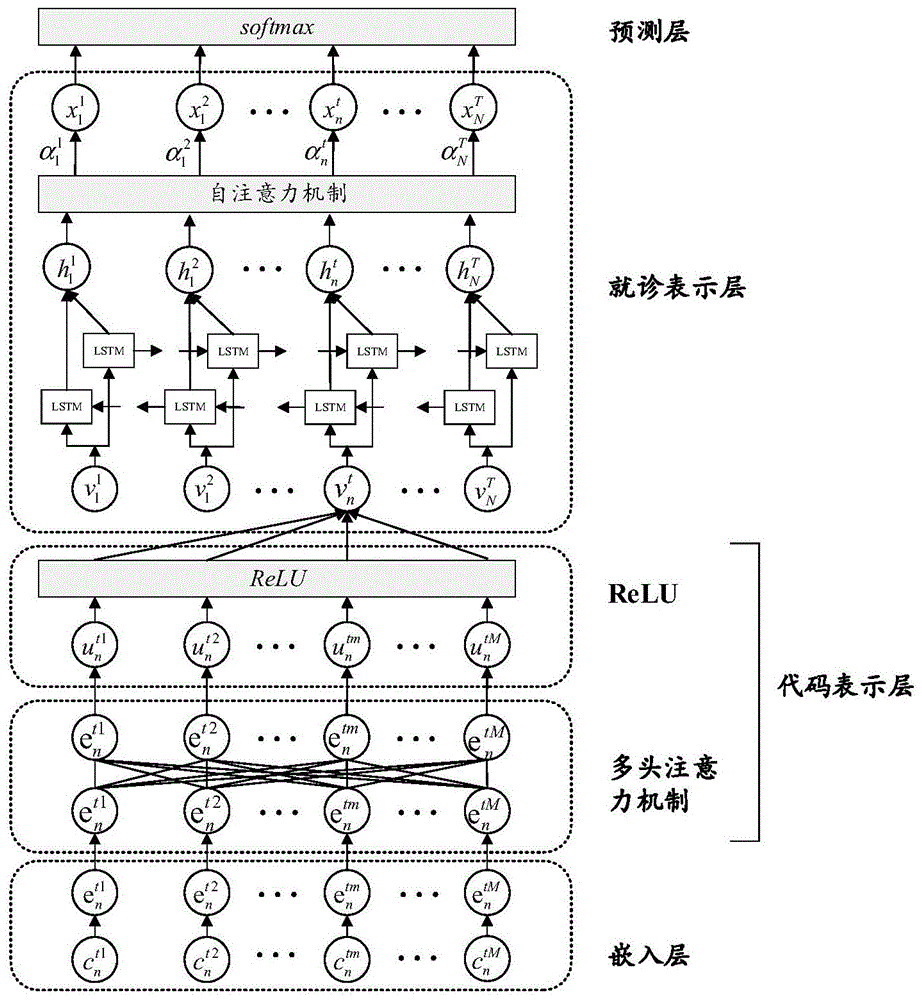
图1为本公开实施例一的基于bilstm和注意力机制的表示学习方法框架图;
图2为本公开实施例一的数据结构图;
图3为本公开实施例一的多头注意力机制结构图。
具体实施方式
下面结合附图与实施例对本公开作进一步说明。
中英文介绍:
双向长短期记忆神经网络(bidirectionallongshort-termmemory,bilstm);
电子健康记录(electronichealthrecords,ehr);
实施例一,本实施例提供了基于bilstm的电子健康记录表示学习方法;
如图1所示,基于bilstm的电子健康记录表示学习方法,包括:
s1:构建基于bilstm的深度学习模型;
s2:构建训练集,所述训练集为a疾病患者的电子健康记录中若干次历史就诊的诊断结果和当前就诊的诊断结果;
s3:利用训练集对基于bilstm的深度学习模型进行训练,将某疾病患者的若干次历史就诊的诊断结果作为模型的输入值,将患者当前就诊的诊断结果作为模型的输出值;得到训练好的基于bilstm的深度学习模型;
s4:获取同样患a疾病的待表示学习患者的电子健康记录,将待表示学习患者电子健康记录的若干次历史诊断结果输入到训练好的基于bilstm的深度学习模型中,输出待表示学习患者的最终表示学习向量。
作为一个或多个实施例,所述s1中,构建基于bilstm的深度学习模型;其中,基于bilstm的深度学习模型,包括:
依次连接的嵌入层、多头注意力机制模型、激活函数层、bilstm神经网络、自注意力机制模型、全连接层和softmax层;
所述嵌入层,用于获取电子健康记录;所述电子健康记录,包括:若干个患者就诊序列,每个患者就诊序列均包含若干个诊断代码;对每个诊断代码进行向量映射;
所述多头注意力机制模型,用于探索患者就诊序列中各个诊断代码的权重,以及各个诊断代码的之间存在的潜在关联关系,从而得到每个诊断代码的向量表示;
所述激活函数层,用于对每个诊断代码的向量表示添加非负性约束;对患者就诊序列中的添加非负性约束的诊断代码向量进行累加,得到患者就诊序列的初步向量表示;
所述bilstm神经网络,用于将初步向量表示输入到bilstm神经网络中,得到患者就诊序列的隐含向量;
所述自注意力机制模型,用于将隐含向量输入到自注意力机制中,学习每个隐含向量的权重,将学习到的每个隐含向量的权重和隐含向量相乘,即对隐含向量进行加权,得到最后的就诊向量表示;
所述全连接层,用于对输出患者当前就诊的诊断结果。
应理解的,患者就诊序列,是指:患者在本次就诊期间内发生的所有诊断代码的序列集合。如图2所示,图2中表示的是一位患者的所有就诊序列。
应理解的,诊断代码,是指:icd-9疾病编码,表示不同的疾病。
进一步地,对每个诊断代码进行向量映射,是通过嵌入矩阵对每个诊断代码进行向量映射。
应理解的,假设共有n位患者,每位患者进行了t次就诊(每位患者的就诊次数t是不同的),每个就诊序列包含m个诊断代码。其中一位患者的就诊序列数据结构如图2所示。给定第n位患者在他的第t次就诊序列中被诊断出的编号为m的诊断代码
其中
应理解的,患者每次就诊期间被诊断出的疾病与疾病之间存在着引起、被引起等关联性和共现性信息。我们采用多头注意力机制来探索这些隐含关联信息,学习各诊断代码在本次就诊内的权重,从而得到代码的向量表示。
多头注意力机制与单一注意力机制不同。首先介绍放缩点积注意力(scaleddot-productattention),该注意力函数是给定一组查询序列q={q1,q2,...,qs-1,qs}和一组键-值序列k={k1,k2,...,ks-1,ks},v={v1,v2,...,vs-1,vs},s表示的是样本数目。然后通过q和k计算得到v中每个值的权重来得到v中所有值的加权和,该注意力函数被定义如下:
其中,dk为q的维度,
多头注意力机制(如图3所示)是将q、k和v进行h次不同的参数映射,分别生成h个的不同的q、k和v序列,然后利用这些序列来并行的执行上面描述的注意力函数,生成多个不同的输出值。其中h可以理解为并行执行的注意力函数的个数或者是多头注意力机制中头的数目。最后将注意力函数的输出值连接起来再次进行线性变换得到最终的输出向量,这便是多头注意力机制最后的输出值。基于上一步通过嵌入矩阵得到的诊断代码的初始向量表示
其中,wiq,wik,wiv和wio为权重参数矩阵,h是多头注意力机制中头的数目,
例如,一位被诊断患有糖尿病(诊断代码为250)的患者,在就诊过程中被诊断出来的疾病极有可能还有糖尿病的并发症,比如肾脏方面的疾病、视网膜病变、心脏微血管病变等等。这些并发症会和糖尿病同时出现在这位患者的多次就诊当中,它们之间存在一定的关联关系和共现信息。其次,并发症与糖尿病相比,它们对患者病情的影响和发挥的作用相对较小,所以重点还要是放在糖尿病的治疗上面,也就是说糖尿病在患者就诊中的权值所占比重要更大一些。因此我们需要综合地考虑患者的就诊治疗过程来更好的进行特征学习。
应理解的,通过relu激活函数对代码表示添加非负性约束,增加代码表示的可解释性,最终将每个离散的诊断代码映射成一个非负实值向量。
应理解的,为了增加代码表示的可解释性,我们通过relu激活函数对代码表示添加非负性约束,最终将离散的诊断代码映射成非负实值向量。
应理解的,将每次就诊序列中出现的所有诊断代码的向量表示进行累加求和,形成初始就诊表示
其中,
得到一个包含所有患者初始就诊向量的集和
应理解的,bilstm神经网络擅长挖掘数据的长期依赖性和时序性,我们利用bilstm神经网络来处理患者的就诊序列,并获得bilstm神经网络的隐含向量来作为下一步的输入。
应理解的,为了学习到更加有效且有意义的就诊表示,我们利用bilstm神经网络来捕获就诊序列中存在的时序性信息,并且联合自注意力机制来学习序列间的差异性,综合的来学习患者的就诊表示。
先来介绍lstm模型,该模型擅长处理时间序列,它的每个单元都可以通过内部组件来保存以前输入的信息,具体来说它的上一个神经单元的某些输出可以作为下一个单元的输入来进行传输,因此可以重用以前的信息来更好的捕获数据的前后关联性。另外,lstm能够有效地保持数据之间的长期依赖关系,这对于克服神经网络中出现的梯度消失问题是非常有用的。lstm由四个门组成,分别是遗忘门、输入门、更新门和输出门。
首先是遗忘门,遗忘门ft决定从单元状态中丢弃的信息内容。遗忘门的数学公式如下,
ft=σ(wfxt+ufht-1+bf)(7)
其中,σ,xt,ht-1和bf分别为遗忘门中的sigmoid激活函数、当前输入、上一个细胞单元的输出、偏置,wf和uf是权重参数矩阵。
其次是输入门,输入门it决定需要存储在单元状态中的新信息,
it=σ(wixt+uiht-1+bi)(8)
其中,σ,xt,ht-1和bi分别为输入门中的sigmoid激活函数、当前输入、上一个细胞单元的输出、偏置,wi和ui是权重参数矩阵。
然后是候选细胞单元
其中,tanh,xt,ht-1和bc分别为输入门中的tanh激活函数、当前输入、上一个细胞单元的输出、偏置,wc和uc都是权重参数矩阵。
通过上述可以计算出更新的细胞单元状态ct,
其中,ct-1表示上一个单元的细胞状态。
最后,输出门ot决定最终要生成的信息,ht是当前细胞单元的输出值,
ot=σ(woxt+uoht-1+bo)(11)
ht=ot*tanh(ct)(12)
其中,σ,xt,ht-1和bo分别为遗忘门中的sigmoid激活函数、当前输入、上一个细胞单元的输出、偏置,wo和uo是权重参数矩阵,用到的激活函数为tanh。
bilstm是汇总来自数据两个方向的信息来更好的获得隐含表示。
基于上述得到的初始就诊表示v,我们使用bilstm对向量进行编码,从两个方向将序列信息进行汇总来得到模型的隐含向量。
其中
应理解的,将隐含向量作为自注意力机制的输入,学习每个向量的权重,并利用学习的权重α与隐含向量h来构成最后的就诊表示
α=softmax(w2tanh(w1ht))(16)
x=αh(17)
其中,w1和w2是权重参数矩阵。
作为一个或多个实施例,所述s2:构建训练集,所述训练集为a疾病患者的电子健康记录中若干次历史就诊的诊断结果和当前就诊的诊断结果;其中,a疾病,例如:高血压、糖尿病、高血脂、肺炎等。
若干次历史就诊的诊断结果,例如:
一位患者在第一次就诊中被诊断为有关消化系统方面的症状(787)、原发性高血压(401)、呼吸系统和其他胸部方面的症状(786);
第二次就诊结果为原发性高血压(401);
第三次就诊为高血压性心脏及慢性肾脏疾病(404)和血脂代谢紊乱(272);
第四次就诊为糖尿病(250)。
当前就诊(第五次就诊)的诊断结果为糖尿病(250)和原发性高血压(401)。其中,括号中的数字代表该疾病的icd-9疾病编码。
作为一个或多个实施例,所述s4获取同样患a疾病的待表示学习患者的电子健康记录,将待表示学习患者电子健康记录的若干次历史诊断结果输入到训练好的基于bilstm的深度学习模型中,输出待表示学习患者的最终表示学习向量;其中,输出的待表示学习患者的最终表示学习向量是由训练好的基于bilstm的深度学习模型的自注意力机制模型输出的。
在ehr系统中,每个患者的ehr数据可以看作是一个有序的就诊序列集合,每个就诊序列又包括一系列用于描述患者病情的无序的医疗诊断代码。基于ehr的数据结构,一方面患者就诊期间发生的诊断代码之间会存在着潜在的关联信息和共现信息。另一方面患者的就诊序列具有时序性和差异性,涉及不同患者病情的就诊信息会对患者的预测时间点就诊的诊断结果产生或大或小的影响。所以面向患者ehr的表示学习方法需要综合地考虑患者的就诊治疗过程,探索隐含的重要关联信息,从而学习更加有效且更具有鲁棒性的医疗特征。所学习的数据表示能够从数据中捕获到隐含的数据规则和模式,这对于科学研究的发展是非常有帮助的。
实施例二,本实施例提供了基于bilstm的电子健康记录表示学习系统;
基于bilstm的电子健康记录表示学习系统,包括:
模型构建模块,其被配置为:构建基于bilstm的深度学习模型;
训练集构建模块,其被配置为:构建训练集,所述训练集为a疾病患者的电子健康记录中若干次历史就诊的诊断结果和当前就诊的诊断结果;
模型训练模块,其被配置为:利用训练集对基于bilstm的深度学习模型进行训练,将某疾病患者的若干次历史就诊的诊断结果作为模型的输入值,将患者当前就诊的诊断结果作为模型的输出值;得到训练好的基于bilstm的深度学习模型;
学习表示向量输出模块,其被配置为:获取同样患a疾病的待表示学习患者的电子健康记录,将待表示学习患者电子健康记录的若干次历史诊断结果输入到训练好的基于bilstm的深度学习模型中,输出待表示学习患者的最终表示学习向量。
作为一个或多个实施例,所述基于bilstm的深度学习模型,包括:
依次连接的嵌入层、多头注意力机制模型、激活函数层、bilstm神经网络、自注意力机制模型、全连接层和softmax层;
所述嵌入层,用于获取电子健康记录;所述电子健康记录,包括:若干个患者就诊序列,每个患者就诊序列均包含若干个诊断代码;对每个诊断代码进行向量映射;
所述多头注意力机制模型,用于探索患者就诊序列中各个诊断代码的权重,以及各个诊断代码的之间存在的潜在关联关系,从而得到每个诊断代码的向量表示;
所述激活函数层,用于对每个诊断代码的向量表示添加非负性约束;对患者就诊序列中的添加非负性约束的诊断代码向量进行累加,得到患者就诊序列的初步向量表示;
所述bilstm神经网络,用于将初步向量表示输入到bilstm神经网络中,得到患者就诊序列的隐含向量;
所述自注意力机制模型,用于将隐含向量输入到自注意力机制中,学习每个隐含向量的权重,将学习到的每个隐含向量的权重和隐含向量相乘,即对隐含向量进行加权,得到最后的就诊向量表示;
所述全连接层,用于对输出患者当前就诊的诊断结果。
将上述得到的患者就诊信息的高级抽象表示作为预测患者当前就诊诊断结果的特征,输入到与softmax分类器连接的全连接层当中进行预测。
pre=softmax(wprex+bpre)(18)
其中,pre表示的是预测结果,wpre是权重参数矩阵,bpre为偏置。
我们使用交叉熵作为损失函数,
其中s是总的样本数(即所有患者的所有就诊数目),yj表示的是真实结果,prej表示预测结果。
本公开提供基于bilstm和注意力机制的表示学习方法。该方法由四部分组成:嵌入层、代码表示层、就诊表示层和预测层。首先是嵌入层,该层是通过嵌入矩阵将离散的诊断代码进行向量初始化;然后是代码表示层,这一层包括多头注意力机制和relu线性层。我们利用多头注意力机制来探索诊断代码之间存在的隐含关联信息,并学习各诊断代码在本次就诊内的权重,从而得到代码的中间向量表示。然后是通过relu激活函数给中间向量表示添加非负性约束。最终将每个离散的诊断代码表示成一个非负实值向量并通过这些向量来构成就诊的初步向量表示;就诊表示层是由bilstm模型和自注意力机制构成,这部分充分利用了就诊序列的时序性和差异性信息,通过bilstm模型和自注意力机制综合的学习患者的就诊向量表示;最后是预测层,该层是一个与全连接层相连接的softmax分类器,利用学习得到就诊表示对患者未来某个时间节点的就诊诊断结果进行预测。
实施例三,本实施例还提供了基于bilstm的疾病预测系统;
基于bilstm的疾病预测系统,包括:
模型构建模块,其被配置为:构建基于bilstm的深度学习模型;
训练集构建模块,其被配置为:构建训练集,所述训练集为a疾病患者的电子健康记录中若干次历史就诊的诊断结果和当前就诊的诊断结果;
模型训练模块,其被配置为:利用训练集对基于bilstm的深度学习模型进行训练,将某疾病患者的若干次历史就诊的诊断结果作为模型的输入值,将患者当前就诊的诊断结果作为模型的输出值;得到训练好的基于bilstm的深度学习模型;
输出模块,其被配置为:获取同样患a疾病的待预测患者的电子健康记录,将待预测患者电子健康记录的若干次历史诊断结果输入到训练好的基于bilstm的深度学习模型中,输出待预测患者的疾病预测结果。
作为一个或多个实施例,所述基于bilstm的深度学习模型,包括:
依次连接的嵌入层、多头注意力机制模型、激活函数层、bilstm神经网络、自注意力机制模型、全连接层和softmax层;
所述嵌入层,用于获取电子健康记录;所述电子健康记录,包括:若干个患者就诊序列,每个患者就诊序列均包含若干个诊断代码;对每个诊断代码进行向量映射;
所述多头注意力机制模型,用于探索患者就诊序列中各个诊断代码的权重,以及各个诊断代码的之间存在的潜在关联关系,从而得到每个诊断代码的向量表示;
所述激活函数层,用于对每个诊断代码的向量表示添加非负性约束;对患者就诊序列中的添加非负性约束的诊断代码向量进行累加,得到患者就诊序列的初步向量表示;
所述bilstm神经网络,用于将初步向量表示输入到bilstm神经网络中,得到患者就诊序列的隐含向量;
所述自注意力机制模型,用于将隐含向量输入到自注意力机制中,学习每个隐含向量的权重,将学习到的每个隐含向量的权重和隐含向量相乘,即对隐含向量进行加权,得到最后的就诊向量表示;
所述全连接层,用于对输出患者当前就诊的诊断结果。
实施例四,本实施例还提供了一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成实施例一所述方法的步骤。
实施例五,本实施例还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成实施例一所述方法的步骤。
上述虽然结合附图对本公开的具体实施方式进行了描述,但并非对本公开保护范围的限制,所属领域技术人员应该明白,在本公开的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本公开的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!