一种医学诊断人工智能系统、装置及其自我学习方法与流程
本发明涉及一种人工智能平台及其运行方法,具体地,涉及一种可自我学习的医学诊断人工智能系统、装置及其自我学习方法。
背景技术:
目前的网上医学诊断平台,大多停留在医生驻留在网站上,患者通过网络通讯技术与医生进行沟通,将自己的病症描述给医生以让医生作出诊断的方式。这种方式有以下缺点:(1)医生不能实际接触到患者,更不能进行望闻问切,患者如果不能把症状描述清楚,则很可能会误导医生做出错误判断;(2)由于获取的信息极为有限,即使网上医学诊断平台上的医生做出了诊断,患者还是要亲自去医院检查以最终确诊,这使得该网上医学诊断平台实际上成为了鸡肋,且对患者和医生都造成了时间的浪费;(3)医生在诊断时,没有任何可参考数据,极易误判,产生不可逆的后果;(4)由于医生夜晚要休息,网上医学诊断平台在晚上时,是处于瘫痪状态的,不能全天候服务病患。
因此,市场上急需一种可以自行收集数据、诊断病症、诊断准确、不知疲倦的人工智能疾病诊断系统。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种医学诊断人工智能系统、装置及自我学习方法,其可以自行收集使用者数据、诊断病症,且诊断准确,不易出现诊断错误,能够根据新病症及时生成新数据指标算法,以适应更加庞大的受众群体。
根据本发明的第一方面,提供一种医学诊断人工智能系统的自我学习方法,包括:
采集医学诊断原始数据;
将采集到的所述原始数据进行分类处理,得到分类后数据;
将所述分类后数据代入数据指标算法中,进行数据转换,形成直观数据;以及,不断进行所述数据指标算法的验证;
使用所述直观数据构建用户画像;
根据所述用户画像判断是否能找到匹配的医学模型,若是,则对用户进行风险提醒;否则,告知用户未找到匹配的医学模型,根据用户样本特征通过机器学习算法构建新的医学模型;
根据所述新医学模型自行构建新数据指标算法,将所述新数据指标算法替换原数据指标算法。
可选地,所述得到分类后数据后还包括:将所述分类后数据存储至大数据平台数据池。
可选地,根据所述新医学模型自行构建新数据指标算法,包括:
从所述大数据平台数据池中提取所述分类后数据;
根据所述新医学模型结合所述分类后数据自行构建新数据指标算法。
可选地,所述原始数据采集后还包括:去除所述原始数据中的明显偏差数据。
可选地,所述原始数据采集,通过智能终端不间断采集原始数据。
根据本发明的第二方面,提供一种可自我学习的医学诊断人工智能系统,包括:
原始数据采集模块,用于进行医学诊断原始数据采集;
数据分类模块,用于将所述原始数据采集模块采集到的所述原始数据进行分类处理,得到分类后数据;
数据转换模块,用于将所述数据分类模块生成的所述分类后数据代入数据指标算法中,进行数据转换,形成直观数据;所述数据转换模块还用于不断进行所述数据指标算法的验证;
用户画像构建模块,用于使用所述数据转换模块形成的所述直观数据构建用户画像;
医学模型匹配判断模块,用于根据所述用户画像构建模块构建的所述用户画像判断是否能找到匹配的医学模型;
风险提醒模块,用于在所述医学模型匹配判断模块找到匹配的医学模型时,进行风险提醒;
新医学模型生成模块,用于在所述医学模型匹配判断模块没有找到匹配的医学模型时,告知用户未找到匹配的医学模型,并根据用户样本特征通过机器学习算法构建新的医学模型;
新数据指标算法构建模块,用于根据所述新医学模型生成模块生成的所述新医学模型自行构建新数据指标算法;
数据指标算法替换模块,用于将所述数据转换模块中的所述数据指标算法替换为所述新数据指标算法构建模块构建出的所述新数据指标算法。
可选地,所述可自我学习的医学诊断人工智能系统还包括:大数据平台数据池,用于存储所述所述数据分类模块产生的分类后数据。
可选地,所述新数据指标算法构建模块包括:
分类后数据提取单元,用于在所述新数据指标算法构建模块前,从所述大数据平台数据池中提出所述分类后数据;
新数据指标算法构建单元,用于根据所述新医学模型生成模块生成的所述新医学模型结合所述分类后数据提取单元提取到的所述分类后数据自行构建新数据指标算法。
可选地,所述可自我学习的医学诊断人工智能系统还包括:清洗模块,用于去除所述原始数据采集模块采集的所述原始数据中的明显偏差数据。
可选地,所述原始数据采集模块,不间断采集原始数据。
根据本发明的第三方面,提供一种可自我学习的医学诊断人工智能装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时可用于执行所述的医学诊断人工智能系统的自我学习方法。
与现有技术相比,本发明具有如下的有益效果:
本发明上述的可自我学习方法,可以进行自我学习,自行完善数据指标算法,用于医学诊断人工智能系统、装置,能提高诊断结果的准确性,对应的健康类型越来越多。
本发明上述的可自我学习的医学诊断人工智能系统、装置,可以24小时收集处理患者的数据,无需用户主动要求诊断,不影响用户的正常生活,在检测到用户可能存在健康问题时,即刻想用户发送警报,告知用户有健康风险。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明一实施例方法的流程图;
图2为本发明的另一实施例的流程图;
图3为本发明的另一实施例的流程图;
图4为本发明的另一实施例的流程图;
图5为本发明的一实施例全天分析之心率密度占比序列图;
图6a、图6b为本发明一实施例中平均心率与耗氧量、能量代谢率之间的关系图;
图7a、图7b分别是运动中心率与耗氧量、能量代谢率的关系图;
图8~图10为本发明一实施例中中医学诊断人工智能系统监控显示图;
图11为本发明一实施例中新医学模型训练原理框图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
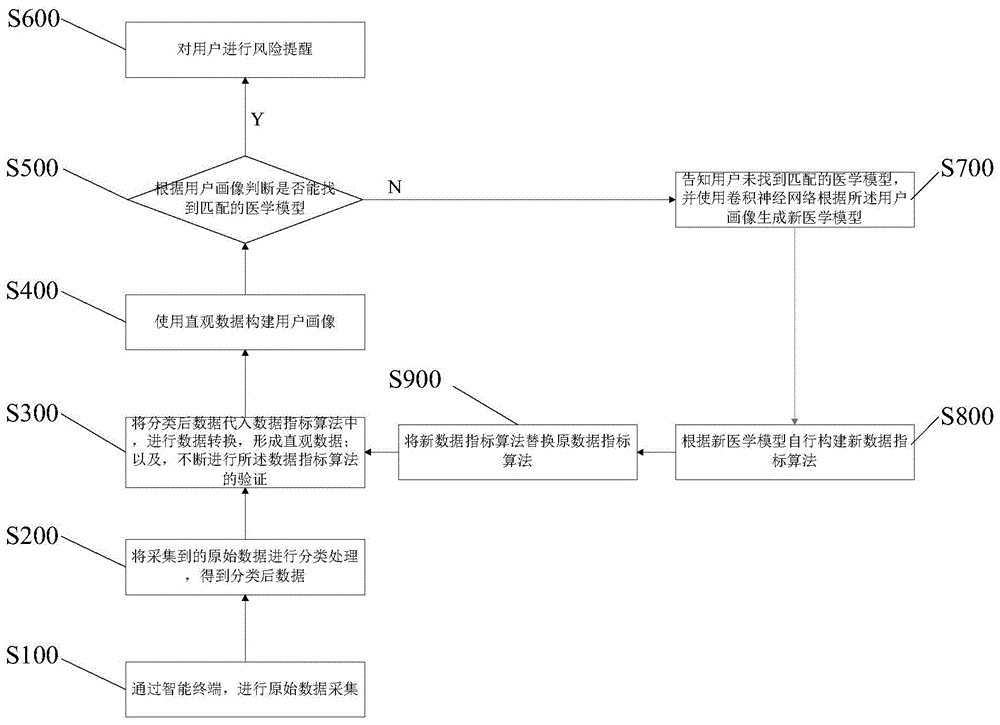
参照图1所示,本发明一实施例中医学诊断人工智能系统的自我学习方法的流程图,包括如下步骤:
s100,通过智能终端,进行原始数据采集,智能终端可以是手机、手环或智能手表等设备,在采集原始数据时,是呈时间段连续采集的,如整个白天的原始数据、整个夜间的原始数据、全天的原始数据、亦或是静息时的原始数据,原始数据可以是ppg传感器检测到的连续变化的血液容积,也可以是六轴传感器检测出的行走数等;
s200,将采集到的原始数据进行分类处理,得到分类后数据,分类处理,是指:根据每个人的时间周期进行心率采集,时间周期分睡眠(深度睡眠和浅度睡眠)、清晨(早上清醒未起床)、静息、运动,并根据二十四小时时间进行时间单点与各个区间段的归类;
s300,将分类后数据代入数据指标算法中,进行数据转换,形成直观数据;以及,不断进行数据指标算法的验证;数据指标算法是对不同类型的的心率值进行对比与重构,得到同一个时间同一个类型的心率在不同周期的计算比值变化、分布状态,以及一个人同多数人的各系列心率值的对比与偏差度计算。
具体的,如时间阵列指标分析:
其中全天分析之心率密度占比序列图,可以观看出一个人整体心率密度分布涵盖区间及心率密度好坏与否。如图5所示。
s400,使用直观数据构建用户画像,所谓用户画像包括:用户年龄、性别、身高(动态)、体重(动态)、腰围(动态)等信息;
s500,根据用户画像判断是否能找到匹配的医学模型,若是,则执行步骤s600;否则,执行步骤s700;
其中,医学模型是指:不同疾病在不同状态下对应的心率状态的线性回归分析与数学统计分析,即在不同的病症中,病人与正常人的心率变化规律的数学模型。
如下表两组心率变异值比较:
在有人群标签条件下,正常人与某些类型疾病病人心率【脉率】变动情况是有线性相关性。例如55岁以上老年人凌晨1点到4点之间心率均值与上午9点到12点心率均值会出现下行10%-20%,未出现则说明心血管异常。
根据用户画像寻找匹配的医学模型,是指:不同的用户特征在疾病中线性回归分析的对应情况是不同的,如图6a、图6b所示,为本发明一实施例中平均心率与耗氧量、能量代谢率之间的关系图。如55岁以上年龄高血压人群的晨息心率增快程度与心脑血管发病率呈线性关系,55岁以内年龄段人群却非线性关系,这样,通过s400用户画像的信息来寻找对应的医学模型。
s600,如找到匹配的医学模型,根据匹配的医学模型对用户进行风险提醒;
s700,如没有找到匹配的医学模型,则根据用户样本特征通过机器学习算法构建新医学模型;
在部分实施例中,通过机器学习算法构建新医学模型,可以按照以下步骤来进行:
s701、原始数据采集与清洗:当发现用户有身心方面特定未定义问题或疾病时,先以此构建共性标签。然后收集全这些用户的所有体征信息数据,年龄、性别、心率、血压、血氧、体质指数、腰臀比、心率变异性、心率减速力等参数信息,并将这些数据进行去重、标准化和错误修正。
s702、数据初步分析与筛选:找出上述s701每类数据的最大(小)值、平均值、方差、中位数、某些特定值(比如零值)所占比例或者分布规律等,以便对这些数据有一个初步的分析与了解;另一方面是确定自变量(x1,x2,x3,...,xn;特征向量,即输入向量)和因变量y(目标向量,即输出向量),找出这些自变量和因变量的相关性,确定相关系数;最后将确定的自变量根据重要程度进行筛选,筛选可以手工选择或模型选择,选择好合适的特征后,对这些自变量进行命名以便更好的标记。
s703、数据转化:
这一步是为了将上述特征数据转化成机器学习算法可以简单识别的数据,比如中心化、归一化、向量化等,也是对特征筛选结果的再加工,以增强特征的表示能力,防止模型过于复杂和学习困难。
s704、拆分数据集:
将s703中转化好的数据随机地分为两个部分——训练集和验证集,训练集用于新医学模型训练,验证集将用于评估新医学模型训练后的表现情况。在具体实施例中,训练集和验证集所占比例一般为8:2或者7:3,当然,也可以根据实际情况选用其他比例。
s705、模型训练:
新医学模型训练之前,需要确定合适的算法。通过交叉验证对逻辑回归、决策树、随机森林、神经网络、梯度提升和svm这些算法一个个地进行测试和比较,并调参确保每个算法达到最优解,然后选择最好的一个。确定好算法后,结合s704中的训练集数据对新医学模型进行训练优化。
s706、模型评估:
完成训练之后,将s705中的验证集数据用来评估训练好的模型。模型评估常见的方法有混淆矩阵、提升图、洛伦兹图、基尼系数、roc曲线。完成评估后,如果模型需要优化,则可以通过调参来实现,不断重复s705训练和s706评估的过程,直至模型符合预期要求。完成新医学模型的构建。
在上述新医学模型构建后,还可以进一步进行封装接口和模型上线,即:新医学模型达标后,可以封装服务接口以实现模型调用,以便返回预测结果。这样新医学模型就可以上线使用了。
s800,根据新医学模型自行构建新数据指标算法,具体的,对于疾病模型中的心率变化数学规律模型,在心率变化计算分类中如未发现与已经构建的指标类型与标准形成对应关系,则需要重新建立新的阵列对应与指标标准;
对于不同画像的人群以及在不同时间点的心率统计分析归类上,目前已研究的类型是无法涵盖所有,以及现在用户画像的细分还不足够,例如老年人分类,55岁-65岁为一个老年类型,但是随着数据量的增加,55-65年级区间是可以做更加精细化分类与画像信息的重组。例如在研究人群心率变化及器官耗氧量趋势变化中,将原有人群细分为男和女之后,原系统内找不到对应细分模型,但是卷积神经网络人工智能可以自学习型将相应人群标签细分后做数据归类和计算。
如以下表格中所示的男女被试者在不同负荷下的各参数统计值:
从而得出更加细分的人群画像及线性分析结果,然后确定新的指标。
如图7a、图7b所示,分别表示运动中心率与耗氧量、能量代谢率的关系,数据指标算法可以模拟增加运动分析新的大类指标等,如下表所示:
当然,以上仅仅是一个实施例中可能出现的情况,本发明并不局限于上述情况,在一些新的情况出现时,均可以根据实际需要进行数据指标算法的设计或改进,形成一种新的数据指标算法。
s900,将新数据指标算法替换原数据指标算法。
参照图2所示,在上述实施例的基础上,步骤s200后还包括s210:用于将分类后数据存储至大数据平台数据池。
参照图3所示,在上述任一实施例的基础上,步骤s800包括:s801从大数据平台数据池中提取分类后数据;s802根据新医学模型结合分类后数据自行构建新数据指标算法。
参照图4所示,在上述任一实施例的基础上,步骤s100后还包括以下步骤:s110去除原始数据中的明显偏差数据。步骤s100中,原始数据的采集为昼夜不间断采集原始数据。
对应于上述的方法,本发明还提供一种可自我学习的医学诊断人工智能系统的实施例,该系统包括:原始数据采集模块,用于进行原始数据采集;数据分类模块,用于将原始数据采集模块采集到的原始数据进行分类处理,得到分类后数据;数据转换模块,用于将数据分类模块生成的分类后数据代入数据指标算法中,进行数据转换,形成直观数据;数据转换模块,还用于不断进行数据指标算法的验证;用户画像构建模块,用于使用数据转换模块形成的直观数据构建用户画像;医学模型匹配判断模块,用于根据用户画像构建模块构建的用户画像判断是否能找到匹配的医学模型;风险提醒模块,用于在医学模型匹配判断模块找到匹配的医学模型时,对用户进行风险提醒;新医学模型生成模块,用于在医学模型匹配判断模块没有找到匹配的医学模型时,告知用户未找到匹配的医学模型,并根据用户样本特征通过机器学习算法构建新的医学模型;新数据指标算法构建模块,用于根据新医学模型生成模块生成的新医学模型自行构建新数据指标算法;数据指标算法替换模块,用于将数据转换模块中的数据指标算法替换为新数据指标算法构建模块构建出的新数据指标算法。
在一实施例中,上述的可自我学习的医学诊断人工智能系统还包括:大数据平台数据池,用于存储数据分类模块产生的分类后数据。
在一实施例中,上述的新数据指标算法构建模块包括:分类后数据提取单元,用于在新数据指标算法构建模块前,从大数据平台数据池中提出分类后数据;新数据指标算法构建单元,用于根据新医学模型生成模块生成的新医学模型结合分类后数据提取单元提取到的分类后数据自行构建新数据指标算法。
在一实施例中,上述的可自我学习的医学诊断人工智能系统还包括:清洗模块,用于去除原始数据采集模块采集的原始数据中的明显偏差数据。原始数据采集模块昼夜不间断采集原始数据。
上述可自我学习的医学诊断人工智能系统实施例中的各模块和单元,具体实现技术可以采用可自我学习的医学诊断人工智能方法对应的步骤中的技术,在此不再赘述。
结合上述的可自我学习的医学诊断人工智能系统和方法,本发明实施例还提供一种可自我学习的医学诊断人工智能装置,该装置包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时可用于执行的医学诊断人工智能系统的自我学习方法。
本发明上述实施例,可以24小时收集处理患者的数据,且不影响用户的正常生活,且本发明的医学诊断人工智能平台可以进行自我学习,使得诊断越来越准确,可诊断疾病范围越来越多。上述的医学诊断人工智能平台根据收集的数据进行智能诊断和学习,可以对使用者的监控状态进行监控,并根据监控的健康数据给出参考或建议,如图8、9、10所示。
如图11所示,在部分优选实施例中,上述s705的模型训练或新医学模型生成模块,可以选择神经网络算法来对模型进行训练,训练和预测识别的过程可以参照以下步骤进行:
①确定训练集:训练集中的数据(traindata)需同时包含特征值(input)和对应标签值(label),标签值(label)也称为目标值(target)。
②设计网络结构:确定网络层数,每一隐藏层的节点数和激活函数,以及输出层的激活函数和损失函数。图11用的是两层隐藏层,隐藏层所用激活函数a()是relu函数,输出层的函数是线性linear函数(也可以看成是没有激活函数)。损失函数l()用于比较距离mse:mean((output-target)2),mse越小表示预测效果越好,训练过程就是不断减小mse的过程。
③权重初始化:图11中的wh1、wh2、w0在训练前不能为空,要初始化才能够计算loss,wh1、wh1、w0初始化决定loss在损失函数中从哪个点开始作为起点来训练网络。
④训练网络:训练过程就是用训练集数据的特征值(input)经过网络计算出输出值(output),再用输出值(output)和目标值(target)计算出loss,再计算出梯度(gradients)来更新权重(weights)的过程:
a、正向传递:计算当前网络的预测值,
output=linear(w0*relu(wh2*relu(wh1*input+bh1)+bh2)+b0)
b、计算loss:
loss=mean((output-target)2)
c、计算梯度:从loss开始反向传播计算每个参数对应的梯度,图11应用stochasticgradientdescent(sgd)来计算梯度,即每次更新所计算的梯度都是从一个样本计算出来的。
d、更新权重:所有参数的梯度都将更新:
w=w-learningrate*gradient
e、预测新值:训练过所有样本后,再打乱样本顺序训练若干次。训练完毕后,当再来新的数据input,就可以运用训练完成的网络来进行预测了,这时的output就是效果很好的预测值了。预测流程如图11右侧预测识别端所示。
需要说明的是,本发明提供的方法中的步骤,可以利用系统中对应的模块、装置、单元等予以实现,本领域技术人员可以参照系统的技术方案实现方法的步骤流程,即,系统中的实施例可理解为实现方法的优选例,在此不予赘述。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!