使用无细胞DNA片段大小检测肿瘤相关变体的制作方法
相关申请的引用
本申请根据35u.s.c.§119(e)要求题目为“使用无细胞dna片段大小检测肿瘤相关变体”的于2017年4月21日递交的美国临时专利申请62/488,549号的权益,通过引入将其整体并入本文,用于所有目的。
发明背景
能在相对较短时间内对整个基因组进行测序的技术出现以及循环无细胞dna(cfdna)的发现,为在没有与侵入性采样方法相关风险的情况下分析遗传物质提供了机会。
在癌症患者血液的cfdna中可以发现少量源自肿瘤,特别是恶性肿瘤(或癌症)的循环肿瘤dna(ctdna)。可以通过对cfdna进行测序来检测已知与各种类型的肿瘤特异性相关的序列变体,从而对ctdna进行鉴定。为了诊断或分层疾病而测定血液中ctdna的检测方法也称为液体活检。液体活检中用于诊断癌症的现有方法的局限性包括由于ctdna水平有限而导致灵敏性不足,以及由于基因组信息的固有性质而导致的技术上测序偏倚。这些局限性导致了对提高特异性、灵敏性和适用性的方法的持续需求,以在各种临床环境中可靠地分析与癌症相关的变体。
发明概述
ctdna片段的平均长度比未受癌症影响的细胞中的cfdna片段短。本文公开的一些实施方案利用未受影响的cfdna和ctdna之间的这种差异来检测癌症相关变体的存在(或判定所述变体)。本申请提供了用于液体活检的方法和系统,其将cfdna的大小信息与序列信息有效地结合,从而实现了判定与肿瘤相关的变体并确定癌症的高的分析灵敏性和特异性。因为本文提供的各种方法和系统实现了协同结合大小和序列信息的算法和过程,所以这些实施方案达到了与仅使用序列或大小信息的常规方法相比,分析灵敏性和特异性得到了提高,并克服了用于诊断癌症的液体活检中的某些限制。
本申请的一个方面涉及用于通过分析从测试样品获得的cfdna片段的大小和序列来确定测试样品中与肿瘤相关的基因序列变体的存在或拷贝数的方法。在一些实施方案中,测试样品可以是外周血、唾液、尿液和其他生物流体,如下所述。
在一些实施方案中,所述方法在包括一个或多个处理器和系统存储器的计算机系统上实施,以确定测试样品中与肿瘤相关的基因序列变体的存在或拷贝数,测试样品包括源于肿瘤细胞的无细胞核酸片段。
一些实施方案提供了用于在包含无细胞核酸片段的测试样品中检测与肿瘤相关的简单核苷酸变体的方法。所述方法包括:(a)富集具有对应于一个或多个选择的基因组区域的序列的cfdna片段,与肿瘤相关的简单核苷酸变体位于所述基因组区域中;(b)用从样品中提取的cfdna片段制备文库,其中该文库保留了cfdna片段的片段长度;(c)对cfdna片段进行测序以获得cfdna片段的序列和大小;以及(d)使用所述cfdna片段的序列和大小,产生所述cfdna片段中存在肿瘤变体的判定。
在一些实施方案中,该方法包括:(a)通过一个或多个处理器检索从测试样品获得的cfdna片段的序列读取和片段大小;(b)通过一个或多个处理器将cfdna片段分配到代表不同片段大小的多个箱中;以及(c)使用所述序列读取并通过所述一个或多个处理器,确定从所述多个箱中选择的优先箱集合中的所述感兴趣变体的等位基因频率,其中所述优先箱集合被选择为:(i)限制所述优先箱集合中的感兴趣变体数量低于检测限的概率,并且(ii)增加所述优先箱集合中的感兴趣变体数量高于在所述多个箱中的所有箱的概率。
在一些实施方案中,测试样品是血浆样品。在一些实施方案中,所述感兴趣变体已知或怀疑与癌症有关。在一些实施方案中,所述感兴趣变体已知或怀疑与遗传疾病有关。
在一些实施方案中,所述方法还包括将优先箱集合中的感兴趣变体的等位基因频率与标准进行比较,并且基于该比较,对测试样品中的感兴趣变体进行判定。在一些实施方案中,所述方法的检测限为约0.05%-0.2%。
在一些实施方案中,通过以下过程选择优先箱集合:提供多个候选集合,每个候选集合包括来自多个箱的非一致箱;对于每个候选集合,计算在建模样品中所述候选集合的箱中感兴趣变体的等位基因频率低于检测限的第一概率,其中所述建模样品包括源自具有感兴趣变体的细胞的cfdna和源自不具有感兴趣变体的细胞的cfdna;对于每个候选集合,计算在建模样品中所述候选集合的箱中感兴趣变体的等位基因频率高于在建模样品中所述多个箱中的感兴趣变体的等位基因频率的第二概率;以及基于所述第一概率和所述第二概率,选择候选集合作为优先集合。包括来自多个箱的非一致箱的每个候选集合意味着每个候选集合具有与其他候选集合的箱不同的箱。
在一些实施方案中,所述优先集合在第一概率的值不超过标准的候选集合中具有第二概率的最大值。
在一些实施方案中,通过渴望方法(greedyprocess)获得所述多个候选集合。在一些实施方案中,所述渴望方法包括:获得从一个或多个已知未受感兴趣病症影响的未受影响训练样品和一个或多个已知受感兴趣病症影响的受影响训练样品中获得的cfdna片段的序列读取和片段大小;基于大小将从一个或多个未受影响训练样品中获得的cfdna片段分配到多个箱中;基于大小将从一个或多个受影响训练样品中获得的cfdna片段分配到多个箱中;基于所述一个或多个受影响训练样品的片段的频率与所述一个或多个未受影响训练样品的片段的频率的比率,对所述多个箱的每个箱进行评级;选择具有最高评级的箱作为候选集合;将具有下一个最高评级的箱添加到最后候选集合以提供下一候选集合;以及重复最后一步,直到添加所述多个箱中的所有箱,每次重复提供一个候选集合。
在一些实施方案中,所述感兴趣病症包括一种或多种癌症。在一些实施方案中,所述感兴趣病症包括与感兴趣变体有关的癌症。在一些实施方案中,所述受影响训练样品包括癌组织,未受影响训练样品包括非癌组织。
在一些实施方案中,将所述建模样品中候选集合的箱中的感兴趣变体的等位基因频率估计为:
其中af(lb1,b2...bk)是箱lb1,lb2...lbk的等位基因频率,nmut(lb1,b2...bk)是箱lb1,lb2...lbk中感兴趣变体的计数,dp是测序深度,f肿瘤是来自具有感兴趣变体的细胞的cfdna分数,α(lbi)是箱lbi中一个或多个已知受感兴趣病症影响的受影响样品的片段长度分布中片段的密度,并且β(lbi)是箱lbi中一个或多个已知未受感兴趣病症影响的未受影响样品的片段长度分布中片段的密度。
在一些实施方案中,具有感兴趣变体的细胞是癌细胞,并且所述建模样品包括血浆样品,所述血浆样品包括来自癌细胞的cfdna和来自非癌细胞的cfdna。
在某些实施方案中,将箱lb1,lb2...lbk中感兴趣变体的计数建模为二项分布:
其中af肿瘤是在具有感兴趣变体的组织中感兴趣变体的等位基因频率。
在某些实施方案中,af肿瘤计算为:
af肿瘤=af血浆/f肿瘤
其中af血浆是建模样品中感兴趣变体的等位基因频率。
在一些实施方案中,所述方法还包括在将候选集合选为优先集合之后,从所述优先集合中去除一个或多个不包含感兴趣变体序列的箱。
在一些实施方案中,所述感兴趣变体包括简单核苷酸变体(snv)。在一些实施方案中,所述snv是单核苷酸变体、定相顺序变体(phasedsequentialvariant)或小插入缺失(smallindel)。
在一些实施方案中,所述序列读取是双端读取,并且所述cfdna片段的大小是从读取对获得的。
在一些实施方案中,从所述样品获得的cfdna片段已经被富集。
在一些实施方案中,所述方法还包括,在(a)之前,从所述测试样品中提取cfdna片段。
在一些实施方案中,所述cfdna片段包括循环肿瘤dna(ctdna)片段。
本申请的另一方面提供了分析无细胞dna(cfdna)以确定感兴趣变体的方法,所述方法包括:(a)获得从测试样品获得的cfdna片段的序列读取和片段大小;(b)将cfdna片段基于其大小分配到代表不同片段大小的多个箱中;以及(c)使用所述序列读取,确定在选自多个箱的优先箱集合中的感兴趣变体的等位基因频率,其中通过以下过程选择优先箱集合:(i)提供多个候选集合,每个候选集合包括来自多个箱的非一致箱;(ii)对于每个候选集合,计算在建模样品中所述候选集合的箱中感兴趣变体的等位基因频率高于在建模样品中所述多个箱中的感兴趣变体的等位基因频率的第二概率,其中建模样品包括具有感兴趣变体的组织和具有感兴趣变体的野生型序列的组织;以及(iii)选择具有第二概率的最大值的候选集合。
在一些实施方案中,该方法还包括,在(iii)之前并且对于每个候选集合,计算在建模样品中所述候选集合的箱中感兴趣变体的等位基因频率不超过检测限的第一概率,其中(iii)包括在第一概率的值不超过标准的候选集合中选择具有第二概率的最大值的候选集合。
本申请的实施方案还提供一种计算机程序产品,所述计算机程序产品包括非易失性计算机可读介质,在其上提供了用于执行本文所述的操作和其他计算操作的程序指令。
一些实施方案提供了用于评估测试样品中感兴趣核酸序列的拷贝数的系统。所述系统包括:测序仪,用于从所述测试样品接收核酸并提供来自所述样品的核酸序列信息;处理器;以及一个或多个计算机可读存储介质,其上存储有用于在处理器上执行以使用本文所述方法评估所述测试样品中拷贝数的指令。
尽管本文的实例涉及人类,并且语言主要针对人类,但是本文所述的构思适用于来自任何植物或动物的基因组。根据以下描述和所附权利要求书,本申请的这些和其他目的以及特征将变得更加完全清晰,或者可以通过以下所述本申请的实践来获知。
援引加入
本文所引用的所有专利、专利申请和其他出版物,包括这些参考文献中公开的所有序列,均以引用的方式明确地并入本文,其程度就像每个单独的出版物、专利或专利申请均被明确地和单独地指出要通过引用并入本文一样。为了在此引用文献的上下文所指示的目的,所有引用的文献在相关部分均通过引用整体并入本文。然而,任何文献的引用均不应被解释为承认其是相对于本申请的现有技术。
附图简述
图1a从主题上说明了如何使用双端测序来确定片段大小和序列。
图1b显示了来自支持肿瘤变体的读取(深灰色)和支持非肿瘤变体或参考序列的读取(浅灰色)的片段大小的经验数据的密度图。
图1c显示了较短的cfdna片段(短于或等于150bp,深灰色条)和较长的cfdna片段(长于150bp,浅灰色条)的等位基因频率。
图2示出的流程图说明了制备样品并分析从所述样品中提取的cfdna片段,使用片段的大小和序列信息两者来判定感兴趣变体的过程。
图3a示出的流程图说明了使用cfdna片段的序列信息和大小信息来确定感兴趣变体的过程。
图3b示出的流程图说明了用于获得多个候选箱集合的渴望方法。
图3c说明了如何将正常cfdna和肿瘤来源的dna的数据结合起来以对样品进行建模,样品例如为包括正常和与肿瘤相关的cfdna的血浆样品。
图3d示出的流程图说明了从多个候选集合中选择优先箱集合的过程。
图3e示出正常样品的频率长度分布和肿瘤样品的频率长度分布,以及如何从所述分布获得概率数据。
图3f示出了多个候选集合的概率数据。
图4示出了根据某些实施方案的典型计算机系统。
图5是用于处理测试样品并进行诊断的分散系统的框图。
图6示意性地说明了如何将处理测试样品中的不同操作分组,以由系统的不同元件来处理。
图7a-图7d示出了使用不同的片段大小箱集合的感兴趣变体的等位基因频率,四种情形中每一种一幅图。
图8显示了来自肿瘤细胞和正常细胞的cfdna的片段长度分布。
图9显示了将cfdna片段分配到各自跨越5个核苷酸的箱中的片段长度的直方图。
图10显示了对于32个真实阳性突变,具有不同水平的原始等位基因频率的组的倍数变化数据。
发明详述
定义
除非另有说明,本文所公开的方法和系统的实践涉及分子生物学、微生物学、蛋白质纯化、蛋白质工程、蛋白质和dna测序以及重组dna领域中常用的常规技术和设备,这在本领域技术范围内。这样的技术和设备是本领域技术人员已知的,并且在许多教科书和参考著作中进行了描述(参见,例如,sambrooketal.,“molecularcloning:alaboratorymanual,”thirdedition(coldspringharbor),[2001]);以及ausubeletal.,“currentprotocolsinmolecularbiology”[1987])。
数字范围包括定义范围的数字。贯穿本说明书给出的每个最大数值限制旨在包括每个较低的数值限制,如同这些较低的数值限制在本文中明确写出一样。贯穿本说明书给出的每个最小数值限制将包括每个更高的数值限制,如同这些更高的数值限制在本文中明确地写出一样。贯穿本说明书给出的每个数值范围将包括落入该较宽数值范围内的每个较窄数值范围,如同这些较窄数值范围均在本文中明确写出。
本文提供的标题无意限制本申请。
除非本文另有定义,本文使用的所有技术和科学术语具有与本领域普通技术人员通常理解的相同含义。包含本文包括的术语的各种科学词典是本领域技术人员众所周知并可得到的。尽管与本文描述的那些方法或材料相似或等同的任何方法和材料都可用于本文公开的实施例的实践或测试中,但描述了一些方法和材料。
下文直接定义的术语将通过整体参考本说明书更全面地描述。应当理解,本申请不限于所描述的特定方法、方案和试剂,因为这些可以变化,这取决于本领域技术人员使用方法、方案和试剂的背景。如本文所用,单数术语“一(a)”、“一(an)”和“所述(the)”包括复数引用,除非上下文另有明确指示。
除非另有说明,核酸以5'至3'的方向从左至右书写,氨基酸序列则以氨基至羧基的方向从左至右书写。
如本文所用,感兴趣序列表示生物体(例如人)的基因组中的核酸序列。在一些实施方案中,感兴趣序列是基因、snp、外显子、基因的调控序列等。在一些实施方案中,感兴趣序列是染色体或亚染色体区域。
感兴趣变体是需要测量、定性、定量或检测的基因序列的具体变体。在一些实施方案中,感兴趣变体是已知或怀疑与病症(如癌症、肿瘤或遗传疾病)相关的变体。
基因是dna的位点(或区域),由核苷酸组成,是遗传的分子学单位。
基因可以在其序列中获得突变,从而导致群体中的不同变体,即等位基因。这些等位基因编码的蛋白质略有不同,导致不同的表型性状。
等位基因频率或基因频率是基因(或基因变体)的一个等位基因相对于该基因的其他等位基因的频率,可以表示为分数或百分比。等位基因频率通常与具体基因座相关,因为基因通常位于一个或多个座位。但是,本文使用的等位基因频率也可以与dna片段的基于大小的箱关联。在这种意义上,将包含等位基因的dna片段(如cfdna)分配给不同的基于大小的箱。相对于其他等位基因的频率,基于大小的箱中等位基因的频率是等位基因频率。在一些实施方案中,等位基因或变体的频率是多个箱(如优先箱集合)中的所有读取中支持变体判定的读取的比例。
本文中术语“参数”是指表征诸如物理特征之类的系统特性的数值,该物理特征的值或其他特征会影响相关条件,如具有简单核苷酸变体或拷贝数变体的样品或dna片段。在某些情况下,术语参数是参考影响数学关系或模型输出的变量而言,该变量可以是自变量(即模型的输入)或基于一个或多个自变量的中间变量。根据模型的范围,一个模型的输出可能成为另一模型的输入,从而成为另一模型的参数。
术语“片段大小参数”是指与片段或片段集合(如核酸片段;例如,从体液获得的cfdna片段)的大小或长度有关的参数。当基因组产生相对于来自另一基因组或同一基因组另一部分的核酸片段而言具有更高浓度的大小或大小范围的核酸片段时,片段大小或大小范围可能是异常基因组或其部分的特征。本文公开的各种实施方案提供了将大小信息与序列信息结合以确定简单核苷酸变体的方法。另外,序列的丰度也可以与大小信息结合以确定结构变异或拷贝数变异。各种实施方案以创新方式组合了片段大小信息和序列信息,比两种信息的简单累加或替代选择更有效,从而提供了优于用于检测具有低变体频率的癌症变体的常规检测方法的改进性能。
“简单核苷酸变体”或“snv”是在相对短的基因序列中与参考序列相差一个或多个核苷酸的遗传变体。snv包括单核苷酸变体、定相顺序变体以及小插入缺失(indels)。snv与结构变体和拷贝数变体的不同之处在于,结构变体包括染色体结构重排,如大插入缺失、重复、倒位和颠倒,拷贝数变体包括基因组正常二倍体区域的异常拷贝数。已知或怀疑与肿瘤相关的某些snv(也称为肿瘤snv)在各种实施方案中为分析靶标。
本文中术语“可能包含变体的片段”用于指这样的片段,其被鉴定为怀疑具有对应于癌症变体的序列突变的cfdna片段。在各种实施方案中,如果确定cfdna片段提供的序列读取包含已知癌症变体的序列并且该序列读取的基因组坐标与癌症变体匹配,则将所述cfdna片段鉴定为可能包含变体的片段。由于测序和其他处理有时会引入错误,因此不确定显示出癌症突变的片段序列真实地对应于源自癌细胞的片段。其实从片段的包含癌症变体的序列读取有可能是由于测序错误而不是真实的体细胞突变。
本文中术语“拷贝数变化”或“cnv”是指与参考样品中存在的核酸序列的拷贝数相比,测试样品中存在的核酸序列的拷贝数变化。在某些实施方案中,核酸序列为1kb或更大。在某些情况下,核酸序列是整个染色体或其显著部分。“拷贝数变体”是指通过比较测试样品中的感兴趣核酸序列与该感兴趣核酸序列的预期水平而发现存在拷贝数差异的核酸序列。例如,将测试样品中感兴趣核酸序列的水平与合格样品中的感兴趣核酸序列水平进行比较。拷贝数变体/变化包括缺失(包括微缺失)、插入(包括微插入)、重复、倍增和易位。cnv涵盖染色体非整倍性和部分非整倍性。
本文中术语“非整倍性”是指由整个染色体或部分染色体的丢失或增加引起的遗传物质的失衡。
术语“多个”是指多于一个要素。例如,本文使用该术语可以指使用本文公开的方法足以鉴定测试样品和合格样品中snv或cnv的显著差异的若干核酸分子或序列标签。在一些实施方案中,对于每个测试样品,获得至少约3×106个约20至40bp的序列标签。在一些实施方案中,每个测试样品提供至少约5×106、8×106、10×106、15×106、20×106、30×106、40×106或50×106个序列标签的数据,每个序列标签包含约20至40bp。
术语“双端读取”是指来自双端测序的读取,双端测序从核酸片段的每个末端获得一个读取。双端测序可涉及将多核苷酸链片段化为称为插入物的短序列。对于较短的多核苷酸(如无细胞dna分子),片段化是可选的或不必要的。
术语“多核苷酸”、“核酸”和“核酸分子”可互换使用,是指核苷酸(即,rna的核糖核苷酸和dna的脱氧核糖核苷酸)的共价连接序列,其中一个核苷酸的戊糖3'位置通过磷酸二酯基连接至下一核苷酸的戊糖5'位置。核苷酸包括任何形式的核酸序列,包括但不限于rna和dna分子,如cfdna分子。术语“多核苷酸”包括但不限于单链和双链多核苷酸。
本文中术语“测试样品”是指通常来源于生物流体、细胞、组织、器官或生物体的样品,其包含含有待进行snv或cnv筛选的至少一种核酸序列的核酸或核酸混合物。在某些实施方案中,所述样品包含至少一种拷贝数疑似已经发生变异的核酸序列。此类样品包括但不限于痰液/口腔液、羊水、血液、血液成分或细针穿刺活检样品(例如,外科活检、细针穿刺活检等)、尿液、腹膜液、胸膜液等。尽管所述样品通常取自人类个体(例如患者),但该测定法可用于任何哺乳动物的样品中的snv或cnv,包括但不限于狗、猫、马、山羊、绵羊、牛、猪等。所述样品可以直接从生物来源获得,也可以在进行预处理以改变样品特性后使用。例如,这样的预处理可以包括从血液制备血浆,稀释粘性流体等。预处理方法还可包括但不限于:过滤、沉淀、稀释、蒸馏、混合、离心、冷冻、冻干、浓缩、扩增、核酸片段化、干扰组分的失活、试剂的添加、裂解等。如果对所述样品采用此类预处理方法,则此类预处理方法通常应使感兴趣核酸保留在测试样品中,有时其浓度与未处理的测试样品(例如,即,没有经过任何此类预处理方法的样品)中的浓度成比例。相对于本文所述的方法,这种“处理的”或“加工的”样品仍被认为是生物学“测试”样品。
术语“训练集合”在本文中是指一组训练样品,其可以包括受影响和/或未受影响的样品,并用以建立用于分析测试样品的模型。在一些实施方案中,所述训练集合包括未受影响的样品。在这些实施方案中,使用对于感兴趣snv或cnv未受影响的样品训练集合来建立用于检测snv或cnv的阈值。训练集合中的未受影响样品可用作合格样品,以鉴别归一化序列(例如归一化染色体),未受影响样品的染色体量则用于设置每个感兴趣序列(例如染色体)的阈值。在一些实施方案中,所述训练集合包括受影响的样品。训练集合中的受影响样品可用于验证可以容易地将受影响的测试样品与未受影响的样品区分开。
训练集合也是感兴趣群体中的统计样品,所述统计样品不应与生物学样品混淆。统计样品通常包含多个个体,使用这些个体的数据来确定一个或多个可推广到所述群体的感兴趣定量值。所述统计样品是感兴趣群体中个体的子集合。个体可以是人、动物、组织、细胞、其他生物样品(即,统计样品可以包括多个生物样品),以及提供用于统计分析的数据点的其他个体实体。
通常,将训练集合与验证集合结合使用。术语“验证集合”用于指统计样品中的一组个体,这些个体的数据用于验证或评估使用训练集合确定的感兴趣定量值。在一些实施方案中,例如,训练集合提供用于计算参考序列的掩码的数据,而验证集合提供用于评估掩码的有效性或效力的数据。
本文中的术语“感兴趣序列”或“感兴趣核酸序列”是指与健康个体和患病个体之间序列表示的差异有关的核酸序列。感兴趣序列可以是在疾病或遗传病症中被错误表示(即被过度或不足地表示)的染色体上的序列。感兴趣序列可以是染色体一部分,即染色体片段,或整个染色体。例如,感兴趣序列可以是在非整倍性条件下过量表示的染色体,或者是在癌症中表示不足的编码肿瘤抑制子的基因。感兴趣序列包括在个体细胞的总群体或亚群中被过高或不足地表示的序列。“合格的感兴趣序列”是合格样品中的感兴趣序列。“测试感兴趣序列”是测试样品中的感兴趣序列。
术语“覆盖率”是指映射到限定序列的序列标签的丰度。覆盖率可以通过序列标签密度(或序列标签计数)、序列标签密度比率、归一化覆盖量、调整后的覆盖率值等定量表示。
本文中术语“二代测序(ngs)”是指允许对克隆扩增的分子和单个核酸分子进行大规模平行测序的测序方法。ngs的非限制性实例包括使用可逆染料终止子的合成测序和连接测序。
本文中术语“阈值”和“合格阈值”是指用作截断值以表征样品(如包含来自怀疑患有医学病症的生物体的核酸的测试样品)的任何数值。可以将阈值与参数值进行比较,以确定产生该参数值的样品是否表明该生物体具有医学病症。在某些实施方案中,使用合格数据集计算合格阈值,并将其用作snv或cnv的诊断限。如果从本文公开的方法获得的结果超过阈值,则可以诊断个体具有snv或cnv。可以通过分析针对样品的训练集合计算的归一化值(例如染色体量、ncv或nsv)来确定本文所述方法的适当阈值。阈值可以使用训练集合中的合格(即未受影响)样品来确定,训练集合中包括合格(即未受影响)样品和受影响的样品。训练集中已知具有染色体非整倍性的样品(即受影响的样品)可用于确定所选阈值可用于区分测试集合中受影响的和未受影响的样品(请参见本文的实施例)。阈值的选择取决于用户希望进行分类的置信度。在一些实施方案中,用于确定适当阈值的训练集合包括至少10、至少20、至少30、至少40、至少50、至少60、至少70、至少80、至少90、至少100、至少200、至少300、至少400、至少500、至少600、至少700、至少800、至少900、至少1000、至少2000、至少3000、至少4000个或更多合格样品。使用较大的合格样品集合来提高阈值的诊断效用可能是有利的。
术语“读取”是指从核酸样品一部分获得的序列。通常,虽然不是必须的,但读取代表样品中连续碱基对的短序列。读取可以由样品部分的碱基对序列以符号形式表示(以a、t、c或g)。可以将读取存储在存储设备中,并进行适当的处理以确定读取是否与参考序列匹配或满足其他标准。可以直接从测序设备获得读取,或从与样品有关的存储序列信息间接获得读取。在某些情况下,读取是具有足够用于鉴定更大的序列或区域的长度(例如,至少约25bp)的dna序列,例如可比对并具体指定到染色体或基因组区域或基因。
术语“基因组读取”用于指个体整个基因组中任何区段的读取。
本文中术语“序列标签”与术语“映射的序列标签”可互换使用,是指已经通过比对而被具体指定(即映射)到更大序列(例如参考基因组)的序列读取。映射的序列标签被唯一地映射到参考基因组,即它们被指定到参考基因组的单个位置。除非另有说明,映射到参考序列上相同序列的标签将被计数一次。标签可以作为数据结构或其他数据组合提供。在某些实施方案中,标签包含读取序列和该读取的相关信息,如序列在基因组中的位置,例如在染色体上的位置。在某些实施方案中,该位置被指定为正链取向。可以定义标签以允许与参考基因组比对中有限量的错配。在一些实施方案中,可以映射到参考基因组上多个位置的标签(即,不是唯一地映射的标签)可以不包括在分析中。
如本文所用,术语“比对的”、“比对”或“进行比对”,是指将读取或标签与参考序列进行比较,从而确定参考序列是否包含读取序列的过程。如果参考序列包含读取,则该读取可以被映射到参考序列,或者在某些实施方案中,被映射到参考序列中的具体位置。在某些情况下,比对只是表明读取是否为具体参考序列的成员(即,读取在参考序列中存在还是不存在)。例如,读取与人类13号染色体参考序列的比对,将表明该读取是否存在于13号染色体的参考序列中。提供此信息的工具可以称为集合成员资格测试器。在某些情况下,比对还指示读取或标签所映射的参考序列上的位置。例如,如果参考序列是整个人类基因组序列,则比对可以指示在13号染色体上存在读取,并且可以进一步指示该读取在13号染色体的具体链和/或位点上。
比对的读取或标签是根据核酸分子与参考基因组中已知序列的顺序被鉴定为匹配的一个或多个序列。尽管可以手动进行比对,但是通常通过计算机算法来实施比对,因为手动进行比对不可能在合理的时间段内对读取进行比对以实现本文公开的方法。来自比对序列的算法的一个实例是作为illumina基因组学分析流程(pipeline)的一部分分发的高效核苷酸数据本地比对(eland)计算机程序。可选地,可以使用布隆(bloom)过滤器或类似的集合成员资格测试器来使读取与参考基因组比对。参见2011年10月27日提交的美国专利申请61/552,374号,将其通过引用整体并入本文。比对中序列读取的匹配可以是100%序列匹配,或小于100%(非完美匹配)。
如本文所用,术语“映射”是指通过比对将序列读取特异性地指定到更大的序列,例如参考基因组。
如本文所用,术语“参考基因组”或“参考序列”是指可用于参考来自个体的鉴定序列的任何生物体或病毒的任何具体的已知基因组序列,无论是部分的还是完整的。例如,在美国国家生物技术信息中心(ncbi,ncbi.nlm.nih.gov)上可以找到用于人类个体以及许多其他生物的参考基因组。“基因组”是指以核酸序列表达的生物体或病毒的完整遗传信息。
在各种实施方案中,参考序列显著大于与之比对的读取。例如,参考序列可以为至少约100倍大,或至少约1000倍大,或至少约10,000倍大,或至少约105倍大,或至少约106倍大,或至少约107倍大。
在一个实例中,参考序列是全长人类基因组的参考序列。这样的序列可以被称为基因组参考序列。在另一个实例中,参考序列限于具体人类染色体,如染色体13。在一些实施方案中,参考y染色体是来自人类基因组版本hg19的y染色体序列。这样的序列可以被称为染色体参考序列。参考序列的其他实例包括其他物种的基因组,以及任何物种的染色体、亚染色体区域(如链)等。
在各种实施方案中,参考序列是共有序列或衍生自多个个体的其他组合。但是,在某些应用中,参考序列可以取自特定个体。
本文中术语“临床相关序列”是指已知或怀疑与遗传或疾病病症相关或涉及的核酸序列。确定不存在或不存在临床相关序列,可用于确定诊断或确认医学病症的诊断,或提供疾病发展的预后。
当在核酸或核酸混合物的上下文中使用时,本文中术语“衍生的”是指从其来源获得核酸的方式。例如,在一个实施方案中,源自两个不同基因组的核酸的混合物是指核酸如cfdna,是由细胞通过自然发生的过程(如坏死或凋亡)自然释放的。在另一个实施方案中,源自两个不同基因组的核酸的混合物是指所述核酸是从个体的两种不同类型的细胞中提取的。
当在获得特定定量值的上下文中使用时,本文中术语“基于”是指使用另一数量作为输入,以计算特定定量值作为输出。
本文中术语“生物流体”是指取自生物来源的液体,并且包括例如血液、血清、血浆、痰、灌洗液、脑脊液、尿液、精液、汗液、眼泪、唾液等。如本文所用,术语“血液”、“血浆”和“血清”明确涵盖其级分或加工部分。类似地,当从活检、拭子、涂片等中获取样品时,“样品”明确涵盖了从活检、拭子、涂片等中得到的处理过的级分或部分。
如本文所用,术语“对应于”有时是指存在于不同个体的基因组中并且不一定在所有基因组中都具有相同序列的核酸序列(如基因或染色体),但用于提供感兴趣序列(如基因或染色体)的同一性而非遗传信息。
如本文所用,术语“染色体”是指活细胞的具有遗传的基因载体,其衍生自包含dna和蛋白质组分(特别是组蛋白)的染色质链。本文采用了常规的国际公认的个人人类基因组染色体编号系统。
如本文所用,术语“多核苷酸长度”是指参考基因组的序列或区域中的核苷酸的绝对数量。术语“染色体长度”是指以碱基对给出的已知染色体长度,例如,在万维网上|genome|.|ucsc|.|edu/cgi-bin/hgtracks?hgsid=167155613&chrominfopage=发现的人类染色体的ncbi36/hg18组件中提供的染色体。
本文中术语“个体”是指人类个体以及非人类个体,如哺乳动物、无脊椎动物、脊椎动物、真菌、酵母、细菌和病毒。尽管本文的实例涉及人类,并且该语言主要针对人类,但是本文公开的概念适用于来自任何植物或动物的基因组,并且可用于兽医、动物科学、研究实验室等领域。
术语“病症”在广义上是指“医学病症”,包括所有疾病和失调,但可包括受伤和正常健康状况如怀孕,其可能会影响人的健康,从医疗救助中受益,或涉及针对医疗处理的影响。
如本文所用,术语“灵敏性”是指当存在感兴趣病症时测试结果为阳性的概率。可以将其计算为真阳性数除以真阳性和假阴性之和。
如本文所用,术语“特异性”是指当缺乏感兴趣病症时测试结果为阴性的概率。可以将其计算为真阴性的数量除以真阴性和假阳性的总和。
本文中术语“富集”是指扩增母体样品一部分中包含的多态性靶核酸,并将扩增的产物与母体样品中去除了该部分的其余部分组合的过程。例如,母体样品的其余部分可以是原始母体样品。
如本文所用,术语“引物”是指分离的寡核苷酸,当置于诱导延伸产物合成的条件下(例如,条件包括核苷酸、诱导剂如dna聚合酶,以及合适的温度和ph)时,其能够充当合成的起始点。为了最大的扩增效率,引物优选是单链的,但是也可以是双链的。如果是双链的,则在用于制备延伸产物之前,首先对引物进行处理以分离其链。优选地,引物是寡脱氧核糖核苷酸。引物必须足够长以在诱导剂存在下引发延伸产物的合成。引物的确切长度将取决于许多因素,包括温度、引物来源、方法的使用以及用于引物设计的参数。
介绍
癌症基因组测序研究共同确定了各种可使人类肿瘤生长和发展的遗传突变。由于他们的发现,科学家们发现大多数癌症都具有体细胞dna突变。与从父母传给孩子的遗传或种系突变不同,体细胞突变是人的一生中在单个细胞的dna中形成的,而不是从父母传给孩子的。因此,归因于与癌症相关的体细胞dna突变的序列变体,提供了检测癌症和测量癌症发展的生物标记。
肿瘤组织本身包括大量的dna材料,可以对其进行分析以检测癌症变体或已知或怀疑与各种癌症相关的序列变体。这可以通过对肿瘤组织进行活检来进行。然而,由于癌症的位置和形式的不断变化,通常难以连续地在各个位置获得活检样品以获取癌症组织和癌症起源的dna。科学家发现,垂死的肿瘤细胞会将其dna的小片段释放到血液和其他体液中。这些片段称为无细胞循环肿瘤dna(ctdna),与非癌细胞的无细胞dna(cfdna)共存。正在开发用于筛选与体细胞突变相关的ctdna的方法,以检测和跟踪患者肿瘤的进展。这些方法也称为液体活检。
当前的各种液体活检方法利用高通量测序来分析从患者收集的cfdna。但是,检测肿瘤特异性变体的能力受到数个因素的限制。利用高通量测序的液体活检方法受到测序错误率和测序深度的限制。在某些癌症患者中,对于某些肿瘤变体,肿瘤负荷可能非常大。例如,在某些样品中,ctdna可能少于0.1%或0.01%。因此,源自肿瘤的cfdna的分数可以低于测序流程的误差范围。低肿瘤负担患者所称的肿瘤特异性变体可能会因假阳性率高而困扰,因为在假定的读取中与肿瘤变体匹配的序列实际上是由于测序错误而不是真实突变的可能性很小但存在。希望增加真阳性以改善灵敏性,而减少假阳性以改善选择性。
最近的研究发现,ctdna片段通常比非肿瘤细胞的cfdna片段短。已经观察到,ctdna片段平均比背景cfdna短约20bp(例如,约145bp相对于165bp)。ctdna和cfdna的分布广泛且重叠。但是,仅这些观察结果并不能提供改善液体活检分析性能的手段。下面介绍的方法可表征支持变体的读取的插入大小分布。这些方法通过应用特定的过程和算法来利用片段大小的差异,这些过程和算法协同有效地组合了片段大小和片段丰度信息,从而提高了使用高通量测序进行变体判定的性能。与单独使用序列或大小信息或在替代方案中相比,一些实施方案提供了改进的灵敏性和/或选择性。
在各种应用中,ctdna分析需要以非常低的频率检测突变片段,对于筛选应用其突变率为0.1-0.01%甚至更低。鉴于文库制备、聚类和测序中存在的错误,将真阳性与假阳性(特异性)区分开来具有挑战性。通过建立利用cfdna片段大小的检测方法,我们可以增加癌症变体判定正确的可能性。例如,如果在片段中判定了可能的体细胞突变而该片段很短,则与片段较长的情况相比,它更可能是真正的肿瘤片段。这种类型的加权可用于改善测定的特异性。利用片段大小差异的另一种方法是,仅使用或更大地加权较短片段。相对于非肿瘤cfdna,这有效地丰富了ctdna信息。
使用大小信息的其他潜在好处包括:1)减少测序要求,2)估计总肿瘤负担,以及3)将生殖细胞变体与真正的体细胞变体体区分开,其中生殖细胞变体具有正常的片段长度,而体细胞变体具有较短的片段。
还可以使用ctdna测量来解决分析转移性癌症患者的肿瘤异质性的问题。转移性癌症患者带有多个有时具有不同驱动突变的肿瘤。由于这些驱动突变通常是药物的靶标,因此非常需要鉴定和表征患者中的驱动突变。而且,了解哪些驱动突变来自同一肿瘤以及哪些驱动突变来自不同肿瘤将是有价值的。此外,有证据表明,当在肿瘤内的显性克隆中存在以药物靶向的驱动突变时,与驱动突变来自较小克隆的情况相比,治疗反应更好。常规方法对于确定这些异质性度量无效。多次对患者进行活检以确定这些度量是不切实际或不安全的。此外,活检仅取样一个肿瘤的一小部分。血液中的ctdna是人体所有肿瘤中ctdna的叠加。
在下面的实例中,使用靶向测序的初步数据显示,ctdna数据中的相对等位基因频率可能代表不同的克隆或肿瘤。本文提供的一些实施方案可以确定肿瘤异质性、来自相同克隆的突变,以及哪个克隆可能是主要克隆。
在某些实施方案中,全基因组测序有助于确定肿瘤异质性。绝大多数实体瘤的体细胞拷贝数变化大于10mb。这些可以使用全基因组测序进行检测,从而提供ctdna分数的正交度量。区域特异性的不同拷贝数水平可用于确定肿瘤异质性。此外,可以将这种全基因组范围拷贝数变化的度量和肿瘤异质性的度量与上述更深层的靶向测序进行比较。将使用靶向方法测得的局灶性体细胞变化与拷贝数变化进行比较时,可能会提高区分多个克隆的能力。
本申请提供了液体活检中的分析方法,用于从例如双端读取中获得片段大小信息,并在分析流程中使用该信息。更高的分析灵敏性提供了以更高的选择性应用液体活检方法的能力。并且通过调整决策标准,与仅使用序列信息的常规方法相比,灵敏性也可以得到提高。
cfdna的片段大小
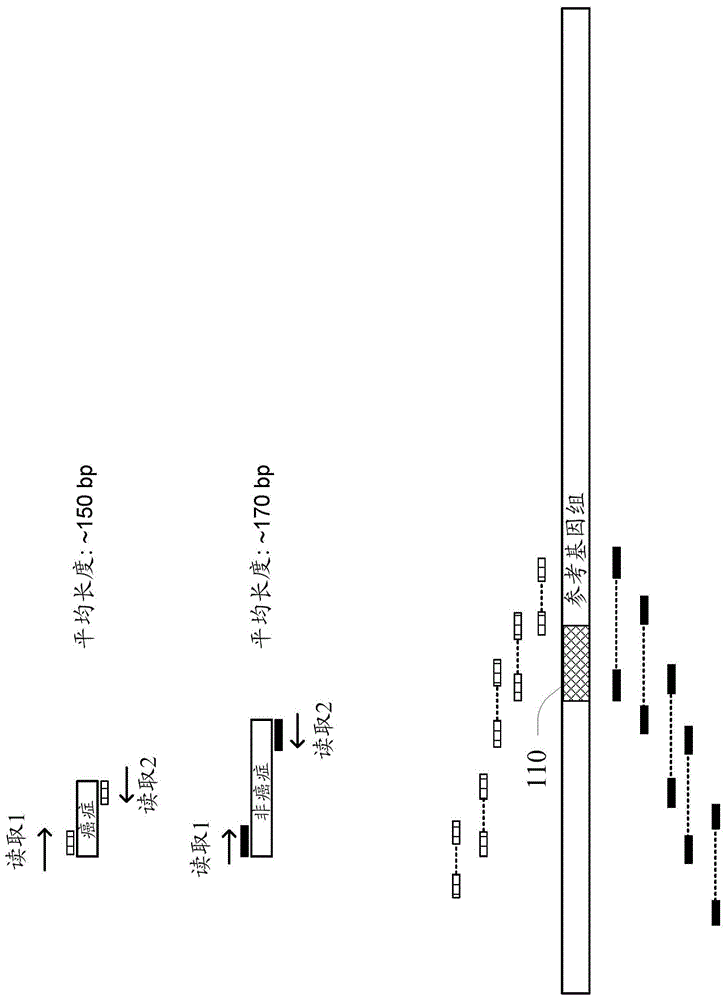
如上所述,片段大小参数以及cfdna中的序列和丰度可用于评估肿瘤变体。cfdna片段的片段大小可通过双端测序、电泳(例如,基于微芯片的毛细管电泳)和本领域已知的其他方法获得。图1a的主题说明了双端测序可如何用于确定片段大小、片段序列和序列覆盖率。
图1a上半部分显示了ctdna片段和非癌症cfdna片段的示意图,所述片段为双端测序过程提供了模板。通常,将长的核酸序列片段化为较短的序列,以在双端测序过程中读取。这样的片段也称为插入物。在一些实施方案中,无细胞dna不需要片段化,因为它们已经存在于大多数短于300个碱基对的片段中。如图1a上部所示,ctdna片段比背景cfdna短。一些观察已经看到大约20bp的差异,例如ctdna大约145bp,而非癌cfdna大约165bp。图1b显示了来自癌症或肿瘤变体(深灰色)的读取和非癌症变体或参考序列(浅灰色)的读取的片段大小的经验数据的密度图。在这里,癌症变体显示出较小片段大小的富集。
在本文公开的实施方案的应用中,两种dna来源的精确和绝对大小,不如两者之间的相对差异那么重要。在一种假设中,dna片段的大小与癌细胞相对于正常细胞相关的不同细胞类型有关。血浆中的非癌cfdna可能起源于血细胞,而血浆中的癌症cfdna可能起源于上皮细胞。血细胞的核小体结构可以不同于上皮细胞的核小体结构。这样的结构差异可能导致dna被切割成不同的大小。在另一个假设中,片段大小的差异可能是癌细胞与核小体之间相互作用的结果。
核小体是真核生物中dna包装的基本单位,包括一段顺序缠绕在组蛋白八聚体周围的dna片段,该八聚体由2个拷贝的核心组蛋白h2a、h2b、h3和h4组成。核小体核心颗粒由大约147个碱基对的dna组成,包裹在组蛋白八聚体周围的1.67个左手超螺旋匝中。核心颗粒通过最多约80bp的接头dna连接。从技术上讲,核小体定义为核心颗粒加上这些连接区之一;然而,该词有时也用于指核小体核心。癌细胞和非癌细胞中的凋亡或其他细胞机制,有可能差异性破坏核小体的结构。本领域技术人员理解,这种大小差异的潜在机制不影响本申请的实用性。
在某些平台上的双端测序中,例如下文中进一步描述的illumina的合成平台测序,将衔接子序列、索引序列和/或引物序列连接至片段的两端。首先从一个方向读取片段,从片段的一端提供读取1。然后从片段的另一端开始进行第二读取,提供读取2的序列。读取1和读取2之间的对应关系可以通过它们在流通池中的坐标来识别。然后,将读取1和读取2映射到参考序列,作为一对彼此靠近的标签,如图1a下半部分所示。在一些实施方案中,如果读取足够长,则两个读取可在插入物的中间部分重叠。在该对与参考序列比对之后,可以从两个读取的位置确定两个读取之间的相对距离和从其得到读取的片段的长度。因为双端读取提供的碱基对是相同长度的单末端读取的两倍,所以它们有助于提高比对质量,尤其是对于具有许多重复序列或非唯一序列的序列。在将双端读取与参考序列比对后,可以确定与箱进行对比的读取数。插入物(例如,cfdna片段)的数目以及长度,也可以针对一个箱来确定。在一些实施方案中,如果插入物跨过两个箱,则插入物的一半可归因于每个箱。在各种实施方案中,插入物的序列信息和比对位置均用于确定插入物是否包括感兴趣变体,例如参考基因组中感兴趣序列110的癌症相关变体。例如,在某些实施方案中,如果cfdna片段的读取包含肿瘤变体的序列,并且该序列与癌症变体的基因组坐标相匹配,则将该cfdna确定为可能含有变体的片段。在下游过程中,使用可能包含变体的片段的序列和大小来分析cfdna片段,以确定样品中癌症变体的存在或丰度。
在一些研究中已经观察到,具有癌症相关变体(ctdna)的cfdna倾向于具有比正常cfdna更短的片段大小(或更短的片段)。如图1b所示,ctdna具有其峰向低端移动的片段长度分布(fld)。同样,图1c显示,相比较长的cfdna片段(长于150bp,浅灰色条),较短的cfdna片段(短于或等于150bp,深灰色条)倾向于具有更高的等位基因频率。图中的每对条形图显示了与癌症相关的变体的数据,纵轴表示变体等位基因频率。
使用cfdna片段的大小确定感兴趣变体
各种实施方案提供了用于从cfdna测序数据中判定感兴趣变体(如肿瘤变体或癌症特异性体细胞变体)的方法。这些变体可分为三大类:简单核苷酸变体(snv)、结构变体(sv)和拷贝数变体(cnv)。snv包括简单核苷酸变体、定相顺序变体,以及小的插入和缺失(indels)。结构变体包括染色体结构重排,包括大插入缺失、重复、倒置和颠换。cnv包括基因组正常二倍体区域的异常拷贝数。在这三个变体类别中,可以通过合并ctdna片段大小信息来改进snv和cnv判定。
图2示出了说明过程200的流程图,该过程200用于制备样品并使用片段的大小和序列信息来分析从样品中提取的cfdna片段,以判定样品中的感兴趣变体(例如,肿瘤变体)。在一些实施方案中,肿瘤变体是简单核苷酸变体(snv)。在一些实施方案中,snv是简单核苷酸变体,如snp、定相顺序变体或小插入缺失。在一些实施方案中,肿瘤是恶性的(癌的)或潜在恶性的(癌前的)。该过程开始于从个体获得包括无细胞dna的样品。样品可以从外周血、唾液和其他体液中获得,如在下文的样品处理部分中进一步描述。该过程涉及从样品中提取无细胞dna片段。参见框202。在一些实施方案中,可能需要相对大量的cfdna,因为一些样品的ctdna浓度可能相对较低。
为了增加检测肿瘤感兴趣变体的可能性,一些实施方案涉及富集已知具有肿瘤变体的序列区域。在一些实施方案中,富集涉及cfdna片段的全基因组扩增。在一些实施方案中,富集涉及cfdna片段的靶向扩增。参见操作204。富集可以在测序文库制备之前或之后进行。实际上,除非另有说明,本文描述或说明的所有操作可以不按所示顺序执行。如图2所示的过程200,富集了具有对应于与肿瘤相关的变体所位于的一个或多个所选基因组区域的序列的cfdna片段。操作204有助于靶向位于可能具有已知或怀疑与肿瘤(特别是恶性或癌变前肿瘤)相关的变体的区域中的序列扩增。通过扩增这些靶区域中的片段,增加了检测癌症相关变体的可能性。在一些应用中,靶向区域可以包括染色体、亚染色体或单个基因区域。在其他应用中,可以在相对窄的序列范围内靶向简单核苷酸变体,序列范围如500bp、1000bp、2000bp、3000bp、4000bp、5000bp、10000bp或20000bp。在一些实施方案中,可以执行全基因组测序。这样的实施方案对于检测长序列的cnv特别有用。在各种实施方案中,由于ctdna的浓度低,因此进行深度测序过程,例如深度至少约10,000x。通过靶向的和整个基因组的扩增可促进此类深度测序。
只要不存在破坏肿瘤或健康组织片段大小分布差异的实验程序,可以在有或没有样品扩增的情况下应用各种实施方案。
过程200涉及由从样品中提取的cfdna片段来制备测序文库。参见框206。在许多于高通量测序平台上使用测序文库的应用中,dna分子被片段化和末端修复。然而,在涉及cfdna的应用中,dna分子以数十至数百个碱基对范围的片段存在。在本文中使用片段大小的信息的实施方案中,文库制备应基本上保留片段的大小。因此,在样品制备中应避免可能破坏体液中存在的碎片的恶劣条件。当然,单独的制剂可能涉及某些延长片段长度的引物和衔接子。然而,只要制备物在不同片段上均一致地影响大小,就可以回收片段的大小信息,如在上述的双端测序技术中。
在一些实施方案中,制备文库涉及将衔接子应用于所提取的cfdna片段的两端。在一些实施方案中,衔接子包括可用于识别样品中单个片段的物理唯一分子标识符。在一些实施方案中,物理唯一分子标识符小于约12个核苷酸。在美国专利申请第15/130,668号中提供了应用唯一分子标识符的方法和系统,该专利申请通过引用整体并入本文。
过程200还涉及对cfdna片段进行测序以获得包含关于cfdna片段序列的信息的读取。参见框208。在各种实施方案中,将双端测序用于对来自两端的片段进行测序。当读取比所述片段短时该方法可能很有用,在各种高通量测序平台上可能就是这种情况。在替代的实施方案中,可以使用具有足够长以覆盖dna片段完整片段的读取的单端测序。
将从测序获得的序列读取与参考基因组或其部分比对以提供序列标签,其包括序列和比对位置(例如,基因组坐标)。参见框210。序列标签的比对信息可以确定一对双端读取中两个读取的相对位置。过程200还涉及使用序列标签中的信息确定样品中存在的cfdna片段的大小。参见框212。在一些实施方案中,序列标签足够长以覆盖cfdna片段的整个大小。在这些实施方案中,片段大小可以通过在测序过程中简单计数片段中碱基的数目来获得。在其他实施方案中,一对的两个读取的相对比对位置,可用于确定从中获得读取的片段的大小。可以将读取的比对位置与读取的序列结合,以确定该读取所源自的片段是否可能包括源自癌症相关突变的癌症变体。如果读取包括癌症变体的序列,并且任选地匹配癌症变体的基因组坐标,则该读取所源自的片段也被称为可能含变体的片段。该片段可能包含源自癌症突变的序列,因为由于测序流程中出现的错误,所述读取具有较小但有效的机会来匹配癌症变体的序列和位置。
然后,过程200产生判定,以使用cfdna片段的序列和大小来确定cfdna片段中是否存在肿瘤变体。参见框214。在图3a-图3f的过程的各种实施方案,可以使用cfdna片段的序列和大小信息产生肿瘤变体或与该变体有关的病症的判定。
转到图3a,流程图示出了用于使用cfdna片段的序列信息和大小信息来确定感兴趣变体的过程300。该方法可以在包括一个或多个处理器和以下将进一步描述的系统存储器的计算机系统上实现。感兴趣变体可以是与感兴趣病症相关的等位基因。在一些实施方案中,怀疑感兴趣变体与癌症或肿瘤有关。例如,感兴趣变体可以是已知与乳腺癌相关的brca突变。在一些实施方案中,已知或怀疑感兴趣变体与遗传疾病有关。在一些实施方案中,感兴趣变体包括简单核苷酸变体(snv)。在一些实施方案中,snv是简单核苷酸变体、定相顺序变体或插入缺失。
过程300开始于获得源自测试样品的cfdna片段的序列读取。该过程还获得了源自测试样品的cfdna片段的大小。参见框302。cfdna片段的大小也称为片段大小、片段长度或分子大小。在一些实施方案中,通过诸如图2中描绘的过程200之类的过程,获得cfdna的大小信息和序列信息。在一些实施方案中,序列读取是双端读取,并且将读取对用于确定如上所述的cfdna片段大小。在一些实施方案中,当感兴趣变体与肿瘤或癌症相关时,cfdna片段包括循环肿瘤dna(ctdna)片段。在一些实施方案中,测试样品是血浆样品。在一些实施方案中,测试样品是孕妇的血浆样品,并且cfdna包括源自孕妇的cfdna和源自孕妇怀有的胎儿的cfdna。
过程300还包括将cfdna片段分配给代表不同片段大小的多个箱。参见框304。在一些实施方案中,多个箱中的每个箱具有相同的箱大小。换句话说,每个箱覆盖固定范围的片段大小。在一些实施方案中,所述箱覆盖不重叠的连续大小范围。例如,第一个箱包含1至5个核苷酸的片段,第二个箱包含6至10个核苷酸的片段,第三箱包含11至16个核苷酸的片段,第四箱包含16至20个核苷酸的片段,依此类推。在各种实施方案中,可以使用不同的箱大小,例如2、3、4、5、6、7、8、9、10、20、30、40、50和100。在一些实施方案中,多个箱共同涵盖1-1000个核苷酸,1-500个核苷酸,或1-380个核苷酸的总范围。在不同条件下的不同实施方案中,可以使用不同的箱大小和总范围。例如,图9显示的分析将cfdna片段分配到每个跨5个核苷酸的箱中,多个箱共同覆盖了1-380个核苷酸的大小范围。如图9所示,将cfdna片段分配给箱时,非一致箱中cfdna片段的频率会形成直方图,该直方图对应于片段长度分布,类似于图3c中的分布330、332和334。
过程300还包括使用在操作302中获得的序列读取来确定从多个箱中选择的优先箱集合中的感兴趣变体的数量。选择所述优先箱集合以:(1)限制在所述优先箱集合中的感兴趣变体数量低于所述优先箱集合中的检测限(lod)的概率,并且(2)增加在所述优先箱集合中的感兴趣变体数量高于在所述多个箱中的所有箱的概率。例如,为了检测与癌症有关的变体,选择优先箱集合以增加与癌症相关的信号,同时确保在所述优先箱集合中的信号超过检测限。在一些实施方案中,感兴趣变体的数量是感兴趣变体的等位基因频率。在一些实施方案中,所述数量是优先箱集合中感兴趣变体的计数。在一些实施方案中,可以相对于参考或基线将数量归一化。
在一些实施方案中,通过提供多个候选集合并从多个候选集合中选择一个集合作为优先集合,来获得优先箱集合。在一些实施方案中,不包含感兴趣变体(例如,肿瘤相关变体)的箱被从优先集合中排除。在一些实施方案中,与使用选定的箱来测试样品分开地执行选择或识别优先集合的过程。换言之,识别箱的过程可以执行一次,并且所选箱被多次使用以测试样品。在一些实施方案中,多个候选集合可以由如图3b所示并且在图3c中说明的过程310提供。在一些实施方案中,使用诸如图3d中所示并且在图3e-图3f中说明的过程350之类的过程,从多个候选集合中选择优先箱集合。
在一些实施方案中,过程300还包括将感兴趣变体的数量与判定标准进行比较,以确定测试样品中感兴趣变体的存在或丰度。在一些实施方案中,在优先箱集合中的感兴趣变体的数量是等位基因频率,并且判定标准是0.05%。其他数量和判定标准可以在其他实施方案中用于各种条件。例如,可以相对于参考量(例如,归一化序列的等位基因频率)对所述数量进行归一化,并且可以凭经验确定合适的标准。在一些实施方案中,可以基于感兴趣变体的数量来确定与感兴趣变体相关联的身体状况。
图3b是示出用于获得多个候选箱集合的渴望的方法的流程图。过程310开始于获得来自一个或多个已知未受感兴趣病症影响的未受影响训练样品的cfdna片段的序列读取和大小。参见框302。在一些实施方案中,已知感兴趣病症与感兴趣变体相关联。例如,感兴趣变体可能是乳腺癌,感兴趣变体可能是brca1或brca2基因的突变。在一些实施方案中,感兴趣病症是包括与感兴趣变体相关联的病症种类的一般病症。例如,感兴趣变体可以是brca突变,而感兴趣病症可以是一般的癌症,包括乳腺癌、肺癌、胃癌和/或其他形式的癌症。在前一个实例中,优先箱集合可能更具体地适合于检测与感兴趣变体相关的癌症类型。在前述实例中,通过渴望的方法310获得的候选箱集合和从候选箱集合中选择的优先箱集合可以更广泛地推广到各种类型的癌症。
在一些实施方案中,感兴趣病症包括一种或多种癌症。在一些实施方案中,感兴趣病症包括与感兴趣变体有关的癌症。在一些实施方案中,受影响训练样品包括癌细胞,而未受影响训练样品包括健康细胞。
处理过程310还涉及获得来自一种或多种已知受感兴趣病症影响的受影响训练样品中的cfdna片段的序列读取和大小。参见框314。
过程310还包括基于其大小将源自一个或多个未受影响训练样品的cfdna片段分配到多个箱中。参见框316。基于其大小将源自一个或多个未受影响训练样品的cfdna片段分配到多个箱中,从而得到对应于图3c的片段长度分布330的直方图。
图3c说明了如何将正常cfdna和肿瘤来源的dna的数据结合起来以对样品进行建模,所述样品如包含正常和与肿瘤相关的cfdna的血浆样品。图3c示出了未受影响样品的片段长度分布330,肿瘤来源片段的片段长度分布332,以及包括正常和肿瘤cfdna片段的建模样品的片段长度分布334,其是通过组合来自分布330和分布332的片段而获得的。例如,受肿瘤影响的患者的血浆样品(因此包含正常的cfdna和肿瘤来源的ctdna)可具有类似于分布334的片段长度分布。
过程310还涉及基于大小将来自一个或多个受影响训练样品的cfdna片段分配到多个箱中。参见框318。当感兴趣病症是肿瘤时,将来自未受影响训练样品的cfdna片段分配到多个箱,从而得到对应于图3c中片段长度分布332的直方图。
过程310还包括基于分配给所述箱的一个或多个受影响训练样品的片段数量与分配给所述箱的一个或多个未受影响训练样品的片段数量的比率来对每个箱进行排名。参见框320。还参见图3c的342。在一些实施方案中,片段的数量是片段的频率。在一些实施方案中,可以相对于基线或参考水平将数量归一化。
多个箱中的每个箱可包含来自未受影响训练样品和受影响训练样品的片段。例如,图3c中的箱336覆盖大小在约100个核苷酸范围内的片段,并且包含来自正常(未受影响)样品的片段和来自癌症(或受影响的)样品的片段。在图3c的图示中,箱336包括来自正常样品的三个片段和来自肿瘤样品的三个片段。因此,箱336提供了正常片段与肿瘤片段的比率1。箱340还包括来自正常样品的三个片段和来自肿瘤样品的三个片段。因此,箱340还提供了来自肿瘤的片段与正常片段的比率为1。箱338包括来自正常样品的13个片段和来自肿瘤样品的9个片段。箱338提供了癌症与正常比率9/13。这样,在操作320中,箱336和340的评级高于箱338。
在图3c中,包括野生型变体的片段被表示为空心圆,并且包括肿瘤变体的片段被表示为实心圆。在一些实施方案中,当为优先箱集合选择箱时,在下游过程中排除不包含肿瘤变体的箱,如箱336。
过程310还包括选择具有最高评级的箱作为候选集合。参见框322。在图3c所示的实例中,在一些实施方案中,箱336或箱340可以被选择为候选集合。在其他实施方案中,当两个或更多个候选集合具有并列评级时,可以考虑其他因素,例如箱336和340。例如,可以考虑包括肿瘤变体的片段数目以解决并列情况。因此,在图3c的实例中,在箱336之前选择箱340,因为箱340包括含有两个具有肿瘤变体的片段。可以被考虑用来解决并列情况的其他因素,包括但不限于:箱中的片段总数,源自癌症样品的片段数目,实验考虑因素和生物学考虑因素。
过程310将具有下一个最高评级的箱添加到最后的候选集合,以提供下一个候选集合。参见框324。图3b中的操作324对应于将箱336添加到包括箱340的最后候选集合,以提供下一个候选集合。下一个候选集合包括箱340和箱336。
过程310确定是否还有更多箱要考虑。参见框326。如果要考虑更多的箱,则该过程通过将具有下一个最高评级的另一个箱添加到最后的候选集合来重复该最后步骤,以提供下一个候选集合。参见决策326的“是”分支,循环回到框324。如果不再考虑更多的箱,则过程310提供所获得的候选集合。参见框328。还参见图3c中的操作344。从候选集合中,将选择一个集合以提供优先集合的箱。在一些实施方案中,使用图3d所示的过程350来选择优先集合,该过程也参考图3e进行了说明。
图3d所示的流程图示出了用于从多个候选集合中选择优先箱集合的过程350。过程350开始于提供多个候选集合。在一些实施方案中,可以通过诸如图3b的过程310之类的过程来获得多个候选集合。每个候选集合包括来自多个箱的非一致箱。参见框352。
过程350还涉及针对每个候选集合计算,建模样品的候选集合的箱中感兴趣变体的等位基因频率低于检测限的第一概率(p1)。参见框354。在一些实施方案中,检测限为约0.05%-0.2%。在一些实施方案中,检测限为约0.2%或0.05%。可以通过结合与片段分布330相关的正常样品和与片段长度分布332相关的肿瘤样品来获得建模样品。建模样品包括来自未受感兴趣病症影响的细胞的cfdna片段和来自受感兴趣病症影响的细胞的cfdna。
过程350还涉及针对每个候选集合计算,候选集合的箱中建模样品的感兴趣变体的等位基因频率高于多个箱的所有箱中感兴趣变体的等位基因频率的第二概率(p2)。参见框356。在多个箱的所有箱中建模样品的感兴趣变体的等位基因频率,也称为血浆等位基因频率(af血浆)。
过程350还涉及在其第一概率的值不超过阈值的候选集合中,选择具有第二概率最大值的候选集合的箱作为优先集合。参见框358。在一些实施方案中,不包含来自受影响(或肿瘤)样品的片段的箱被从优先集合中排除。
图3e示出了正常样品的频率长度分布(360)和肿瘤样品的频率长度分布362,以及如何为建模样品获得第一概率(p1)和第二概率(p2)。对于给定的箱(箱l),可以获得肿瘤样品的等位基因频率α(l)和正常样品的等位基因频率β(l)。等位基因频率α(l)和β(l)可用于计算建模样品的箱的等位基因频率,如下所示:
其中
af(lb1,b2...bk)是箱lb1,lb2...lbk的等位基因频率,
nmut(lb1,b2...bk)是箱lb1,lb2...lbk中感兴趣变体的计数,
dp是测序深度,
f肿瘤是来自具有感兴趣变体的细胞的cfdna分数,,
α(lbi)是箱lbi中一个或多个已知受感兴趣病症影响的受影响样品的片段长度分布中片段的密度,并且
β(lbi)是箱lbi中一个或多个已知未受感兴趣病症影响的未受影响样品的片段长度分布中片段的密度。
在某些实施方案中,可以将箱lb1,lb2...lbk中感兴趣变体的计数建模为二项分布:
其中af肿瘤是在具有感兴趣变体的组织中感兴趣变体的等位基因频率。
在某些实施方案中,af肿瘤的计算公式为:
af肿瘤=af血浆/f肿瘤
其中af血浆是在多个箱的所有箱中建模样品中的感兴趣变体的等位基因频率。
对候选集合的箱中的建模样品使用感兴趣变体的等位基因频率(及其概率分布),以及在多个箱的所有箱中使用感兴趣变体的等位基因频率(及其概率分布),可以获得p1和p2。在获得p1和p2之后,可以使用多个候选集合的两个概率的数据来选择候选集合,从而所选择的候选集合在其第一概率(p1)的值不超过阈值的候选集合中,具有第二概率(p2)中的最大值。参见框358。在一些实施方案中,阈值约为0.002。
图3f绘制了多个候选集合的两个概率的曲线图。数据点370在所有数据点中具有最大可能的p2(这也是在p1值低于阈值的所有数据点中最大的)。数据点370的可能p1低于阈值(例如,对数标度为200)。因此,选择与数据点370相对应的候选集合作为优先集合。优先箱集合在图3f的插入图中标示为箱集合372。在一些实施方案中,不包含感兴趣变体(例如肿瘤变体)的片段的箱被从优先箱集合中排除。
在一些实施方案中,当选择优先箱集合时,考虑第二概率(p2),而可选地考虑第一概率(p1)。在一些实施方案中,用于分析无细胞dna的方法包括:(a)通过计算机系统获得来源于测试样品的cfdna片段的序列读取和大小;(b)通过一个或多个处理器将cfdna片段分配到代表不同片段大小的多个箱中;(c)使用所述序列读取并由所述一个或多个处理器确定从所述多个箱中选择的优先箱中的感兴趣变体的数量,其中所述优先箱集合是通过以下过程选择的:(i)提供多个候选集合,每个候选集合包括来自多个箱的非一致箱;(ii)对于每个候选集合,计算在建模样品中候选集合的箱中的感兴趣变体的等位基因频率高于所述建模样品中多个箱的所有箱中的感兴趣变体的等位基因频率的第二概率;(iii)从多个候选集合中选择具有第二概率的最大值的候选集合的箱作为优先集合。每个候选集合包括不同的箱,意味着每个候选集合具有与其他候选集合的箱不同的箱。
在一些实施方案中,该方法还包括,在(iii)之前并且对于每个候选集合,计算在所述建模样品中候选集合的箱中的感兴趣变体的等位基因频率低于检测限的第一概率,其中(iii)包括在其第一概率的值不超过阈值的候选集合中选择具有第二概率的最大值的候选集合的箱作为优先集合。
片段长度也可以提高cnv判定的性能。在美国专利申请第15/382,508号中,提供了使用片段大小、片段序列和序列覆盖率来确定cnv的方法和系统,该专利申请通过引用整体并入本文。简言之,cnv判定通常是通过将基因组区域的箱内的覆盖率与基线进行比较来执行的。基线可以是一组对照,也可以是样品中预期没有拷贝数变化的对照区域。如果将箱-覆盖率与一组对照进行比较,则片段大小可用作支持cnv的独立特性。
样品和样品处理
样品
用于判定变体或确定cnv的样品包含“无细胞”核酸(例如cfdna)。可以通过本领域已知的各种方法从生物样品中获得无细胞核酸,包括无细胞dna,所述生物样品包括但不限于血浆、血清和尿液(参见例如fanetal.,procnatlacadsci105:16266-16271[2008];koideetal.,prenataldiagnosis25:604-607[2005];chenetal.,naturemed.2:1033-1035[1996];loetal.,lancet350:485-487[1997];botezatuetal.,clinchem.46:1078-1084,2000;和suetal.,jmol.diagn.6:101-107[2004])。为了从样品中的细胞中分离无细胞dna,可以使用各种方法,包括但不限于:分级分离、离心(例如密度梯度离心)、dna特异性沉淀、或高通量细胞分选和/或其他分离方法。可获得用于手动和自动分离cfdna的市售试剂盒(rochediagnostics,indianapolis,in,qiagen,valencia,ca,macherey-nagel,duren,de)。包含cfdna的生物样品已用于通过可检测染色体非整倍性和/或多种多态性的测序测定,以确定是否存在染色体异常,例如21三体。
在各种实施方案中,可以在使用前(例如,在制备测序文库之前),特异性或非特异性地富集样品中存在的cfdna。样品dna的非特异性富集是指样品基因组dna片段的全基因组扩增,可用于在准备cfdna测序文库之前增加样品dna的水平。非特异性富集可以是包含一个以上基因组的样品中存在的两个基因组之一的选择性富集。例如,非特异性富集可以是血浆样品中癌症基因组的选择性,其可以通过已知方法获得,以增加样品中癌症与正常dna的相对比例。或者,非特异性富集可以是样品中存在的两个基因组的非选择性扩增。例如,非特异性扩增可以是样品中癌症和正常dna的扩增,所述样品包含来自癌症和正常基因组的dna的混合物。全基因组扩增的方法是本领域已知的。简并寡核苷酸引物pcr(dop)、引物延伸pcr技术(pep)和多置换扩增(mda)是全基因组扩增方法的实例。在一些实施方案中,包含来自不同基因组的cfdna混合物的样品,未富集混合物中存在的基因组的cfdna。在其他实施方案中,包含来自不同基因组的cfdna的混合物的样品,针对样品中存在的任何一个基因组非特异性地富集。
如上所述,包含对其施用本文所述方法的核酸的样品,通常包括例如,如上所述的生物样品(“测试样品”)。在一些实施方案中,要针对一种或多种snv或cnv进行筛选的一种或多种核酸,是通过许多众所周知的方法中的任一种来纯化或分离的。
因此,在某些实施方案中,样品包含纯化的或分离的多核苷酸或由其组成,或者它可以包含这样的样品,如组织样品、生物流体样品、细胞样品等。合适的生物流体样品,包括但不限于:血液、血浆、血清、汗液、眼泪、痰、尿液、痰、耳流出物、淋巴液、唾液、脑脊液、残余物、骨髓悬浮液、阴道流出物、经宫颈灌洗液、脑液、腹水、乳汁、呼吸道、肠道和泌尿生殖道的分泌物、羊水、乳汁和白细胞样品。在一些实施方案中,样品是易于通过非侵入性程序获得的样品,例如血液、血浆、血清、汗液、眼泪、痰、尿液、痰、耳流出物、唾液或粪便。在某些实施方案中,样品是外周血样品、或外周血样品的血浆和/或血清级分。在其他实施方案中,生物样品是拭子或涂片、活检标本或细胞培养物。在另一个实施方案中,样品是两种或更多种生物样品的混合物,例如,生物样品可以包含两种或更多种生物流体样品、组织样品和细胞培养样品。如本文所用,术语“血液”、“血浆”和“血清”明确涵盖其级分或加工的部分。类似地,在从活检、拭子、涂片等中获取样品的地方,“样品”明确涵盖了从活检、拭子、涂片等中得到的处理过的级分或部分。
在某些实施方案中,样品可以从来源获得,包括但不限于:来自不同个体的样品,来自相同或不同个体的不同发育阶段的样品,来自不同患病个体(例如,患有癌症或怀疑患有遗传性疾病的个体)、正常个体的样品,在个体的疾病不同阶段获得的样品,从对疾病进行不同治疗的个体获得的样品,受到不同环境因素影响的个体的样品,对疾病易感的个体的样品,对暴露于传染病媒介(例如hiv)等的个体进行抽样。
在一个示例性但非限制性的实施方案中,样品是获自怀孕女性例如孕妇的母体样品。在这种情况下,可以使用本文所述的方法分析样品,以提供胎儿中潜在染色体异常的产前诊断。母体样品可以是组织样品、生物流体样品或细胞样品。作为非限制性实例,生物流体包括:血液、血浆、血清、汗液、眼泪、痰、尿液、痰、耳流出物、淋巴液、唾液、脑脊液、残余物、骨髓悬浮液、阴道流出物、经宫颈灌洗液、脑液、腹水、乳汁、呼吸道、肠道和泌尿生殖道的分泌物以及白血球样品。
在另一个示例性但非限制性的实施方案中,母体样品是两种或更多种生物样品的混合物,例如,所述生物样品可包含两种或更多种生物流体样品、组织样品和细胞培养样品。在一些实施方案中,样品是易于通过非侵入性程序获得的样品,例如血液、血浆、血清、汗液、眼泪、痰、尿液、乳汁、痰液、耳流出物、唾液和粪便。在一些实施方案中,生物样品是外周血样品,和/或其血浆和血清级分。在其他实施方案中,生物学样品是拭子或涂片、活检样品或细胞培养物的样品。如上所述,术语“血液”、“血浆”和“血清”明确涵盖其级分或加工的部分。类似地,在从活检、拭子、涂片等中获取样品的地方,“样品”明确涵盖了从活检、拭子、涂片等中得到的处理过的级分或部分。
在某些实施方案中,样品也可以获自体外培养的组织、细胞或其他含多核苷酸的来源。培养的样品可以取自包括但不限于以下来源:在不同培养基和条件(例如,ph、压力或温度)下保存的培养物(例如,组织或细胞),保存不同时间长度的培养物(例如,组织或细胞),用不同因子或试剂(例如候选药物或调节剂)处理的培养物(例如组织或细胞),或不同类型的组织和/或细胞的培养物。
从生物来源分离核酸的方法是众所周知的,并且将取决于来源的性质而不同。如本文所述的方法所需要,本领域技术人员可以容易地从来源分离核酸。在某些情况下,将核酸样品中的核酸分子片段化可能是有利的。片段化可以是随机的,也可以是特异性的,例如,使用限制性核酸内切酶进行消化所实现的。随机片段化的方法是本领域众所周知的,并且包括例如,有限的dna酶消化、碱处理和物理剪切。在一个实施方案中,样品核酸以cfdna的形式获得,而不进行片段化。
测序文库制备
在一个实施方案中,本文所述的方法可以利用二代测序技术(ngs),其允许将多个样品作为基因组分子(即,单重测序)或作为包含索引基因组分子的合并样品(例如,多重测序)来通过一次测序运行分别地测序。这些方法可产生多达数亿个dna序列的读取。在各种实施方案中,可以使用例如本文所述的二代测序技术(ngs)来确定基因组核酸和/或索引基因组核酸的序列。在各种实施例中,可以使用如本文所述的一个或多个处理器来对使用ngs获得的大量序列数据进行分析。
在各种实施方案中,此类测序技术的使用不涉及测序文库的制备。
但是,在某些实施方案中,本文考虑的测序方法涉及测序文库的制备。在一种示例性方法中,测序文库的制备涉及制备准备被测序的衔接子修饰的dna片段(例如,多核苷酸)的随机集合。可以通过逆转录酶的作用,从dna或rna包括dna或cdna的等同物、类似物,例如dna或互补cdna或从rna模板产生的复制dna,制备多核苷酸的测序文库。多核苷酸可以以双链形式起源(例如,dsdna,如基因组dna片段、cdna、pcr扩增产物等),或者在某些实施方案中,多核苷酸可以以单链形式起源(例如,ssdna、rna等),并已转换为dsdna形式。举例说明,在某些实施方案中,单链mrna分子可被复制成适用于制备测序文库的双链cdna。初级多核苷酸分子的精确序列通常对文库制备方法并不重要,并且可以是已知的或未知的。在一个实施方案中,多核苷酸分子是dna分子。更特别地,在某些实施方案中,多核苷酸分子代表生物体的整个遗传互补或基本上生物体的整个遗传互补,并且是基因组dna分子(例如,细胞dna、无细胞dna(cfdna)等),通常包括内含子序列和外显子序列(编码序列),以及非编码调控序列,如启动子和增强子序列。在某些实施方案中,初级多核苷酸分子包含人基因组dna分子,例如存在于怀孕个体的外周血中的cfdna分子。
通过使用包含特定范围片段大小的多核苷酸,可以简化某些ngs测序平台的测序文库的制备。此类文库的制备通常涉及大的多核苷酸(例如细胞基因组dna)的片段化,以获得所需大小范围的多核苷酸。
可以通过本领域技术人员已知的多种方法中的任何一种来实现片段化。例如,可以通过机械手段实现分裂,包括但不限于雾化、超声处理和水力剪切。然而,机械手段片段化通常会在c-o、p-o和c-c键处切割dna骨架,导致平末端和3'-和5'-悬突端与断裂的c-o、p-o和/c-c键的异质混合(参见例如,alnemri和liwack,jbiol.chem265:17323-17333[1990];richards和boyer,jmolbiol11:327-240[1965]),由于它们可能缺乏用于后续酶促反应所需的5'-磷酸酯,可能需要对其进行修复,例如测序衔接子的连接,这是制备用于测序的dna所必需的。
相反,cfdna通常以少于约300个碱基对的片段形式存在,因此,使用cfdna样品生成测序文库通常不需要片段化。
通常,无论多核苷酸是被强制片段化(例如,体外片段化),还是天然作为片段存在,它们都将被转化为具有5'-磷酸和3'-羟基的平末端dna。标准协议,例如,使用本文其他地方所述的illumina平台进行测序的协议,指示用户对样品dna进行末端修复,在加da尾部之前纯化末端修复的产品,以及在文库制备的衔接子连接步骤之前纯化加da尾部的产品。
本文描述的序列文库制备方法的各种实施方案,避免了通常由标准方案强制执行的一个或多个步骤以获得可被ngs测序的修饰的dna产物的需要。缩简法(abb法),1-步法和2-步法是用于制备测序文库的方法实例,其可参见2012年7月20日提交的专利申请第13/555,037号,其通过引用整体并入本文。
测序方法
如上所述,将所制备的样品(例如,测序文库)进行测序,作为鉴定snv或cnv的过程的一部分。可以使用多种测序技术中的任何一种。
一些测序技术在市场上可以买到,如来自affymetrixinc.(sunnyval,ca)的杂交测序平台,来自454lifesciences(bradford,ct)、illumina/solexa(hayward,ca)和helicosbiosciences(cambridge,ma)的合成测序平台,以及来自appliedbiosystems(fostercity,ca)的连接测序平台,如下所述。除了使用helicosbiosciences的合成测序进行单分子测序外,其他单分子测序技术包括但不限于:pacificbiosciences的smrttm技术、iontorrenttm技术,以及例如,由oxfordnanoporetechnologies开发的纳米孔测序。
虽然自动sanger方法被认为是“第一代”技术,但sanger测序(包括自动sanger测序)也可以用于本文所述的方法中。其他合适的测序方法包括但不限于核酸成像技术,例如原子力显微镜(afm)或透射电子显微镜(tem)。示例性测序技术在下面更详细地描述。
在一个示例性但非限制性的实施方案中,本文所述的方法包括使用illumina的合成测序和基于可逆终止子的测序化学(例如,描述于bentleyetal.,nature6:53-59[2009]),获得测试样品中核酸的序列信息,例如母体样品中的cfdna,正在筛查癌症等的个体中的cfdna或细胞dna。模板dna可以是基因组dna,例如细胞dna或cfdna。在一些实施方案中,将来自分离的细胞的基因组dna用作模板,并将其片段化为数百个碱基对的长度。在其他实施方案中,将cfdna用作模板,并且不需要片段化,因为cfdna作为短片段存在。例如,胎儿cfdna以约170个碱基对(bp)长度的片段在血液中循环(fanetal.,clinchem56:1279-1286[2010]),并且在测序之前不需要dna的片段化。循环肿瘤dna也存在于短片段中,其大小分布在约150-170bp处达到峰值。illumina的测序技术依赖于将片段化的基因组dna连接到一个平面的光学透明表面,该表面结合了寡核苷酸锚。对模板dna进行末端修复以生成5'-磷酸化的平末端,并将klenow片段的聚合酶活性用于在钝的磷酸化dna片段的3'末端添加一个a碱基。这种添加为连接至寡核苷酸衔接子的dna片段做好了准备,寡核苷酸衔接子的3'末端具有单个t碱基的悬突以提高连接效率。衔接子寡核苷酸与流通池锚定寡核苷酸互补(在重复扩增分析中不要与锚定/锚定的读取混淆)。在有限稀释条件下,将衔接子修饰的单链模板dna添加到流通池中,并通过与锚定寡核苷酸的杂交来固定。延伸连接的dna片段并进行桥扩增,以创建具有数亿个簇的超高密度测序流通池,每个簇包含约1,000个相同模板的拷贝。在一个实施方案中,进行簇扩增之前,使用pcr对随机片段化的基因组dna进行扩增。或者,使用无扩增(例如,无pcr)的基因组文库制备物,并且仅使用簇扩增来富集随机片段化的基因组dna(kozarewaetal.,naturemethods6:291-295[2009])。使用强大的四色dna合成测序技术对模板进行测序,该技术采用可逆的终止子和可移动的荧光染料。使用激光激发和全内反射光学器件可以实现高灵敏性的荧光检测。将约数十至数百个碱基对的短序列读取与参考基因组比对,并使用专门开发的数据分析流程软件来识别短序列读取至参考基因组的独特映射。第一次读取完成后,可以在原位再生模板,以从所述片段的另一端进行第二次读取。因此,可以使用dna片段的单末端或双端测序。
本申请的各种实施例可以使用允许双端测序的合成测序。在一些实施方案中,illumina的通过合成平台的测序涉及聚簇的片段。聚簇是每个片段分子被等温扩增的过程。在一些实施方案中,如本文所述的实例,所述片段具有连接至所述片段两端的两个不同的衔接子,所述衔接子允许所述片段与流通池泳道表面上两个不同的寡核苷酸杂交。所述片段进一步在片段的两端包括或连接到两个索引序列,该索引序列提供标记以识别多重测序中的不同样品。在某些测序平台中,待测序的片段也称为插入片段。
在一些实施方案中,用于在illumina平台中聚簇的流通池是具有通道的载玻片。每个通道是一个玻璃槽,上面覆盖着两种类型的寡核苷酸“草坪”。所述表面上两种类型寡核苷酸中的第一种使杂交成为可能。该寡核苷酸与所述片段一端上的第一衔接子互补。聚合酶产生杂交片段的互补链。双链分子被变性,而原始模板链被洗掉。剩余的链与许多其他剩余的链平行,通过桥式应用进行克隆扩增。
在桥式扩增中,链进行折叠,并且该链第二端上的第二衔接子区域与流通池表面上的第二种寡核苷酸杂交。聚合酶产生互补链,形成双链桥分子。该双链分子被变性,从而导致两个单链分子通过两个不同的寡核苷酸被连接至所述流通池。然后,该过程一遍又一遍地重复,并且对于数百万个簇同时发生,从而导致所有片段的克隆扩增。桥式扩增后,将反向链裂解并洗掉,仅留下正链。3'端被阻止以防止意外启动。
聚簇后,测序从延伸第一个测序引物开始以产生第一个读取。在每个循环中,荧光标记的核苷酸竞争添加到生长链中。基于模板的序列仅添加一个。加入每个核苷酸后,该簇被光源激发,并发射出特征性的荧光信号。循环数决定了读取的长度。发射波长和信号强度决定了所述碱基判定。对于给定的簇,同时读取所有相同的链。成千上万个簇以大规模并行的方式测序。第一次读取完成后,将读取的产物冲洗掉。
在涉及两个索引引物的方案的下一步中,引入索引1引物,并将其与模板上的索引1区域杂交。索引区提供了片段的识别,这对于在多重测序过程中对样品进行多路分离很有用。索引1读取的生成类似于第一次读取。在完成索引1读取后,将读取的产物洗去,并将该链的3'末端去保护。然后,模板链折叠并与流通池上的第二个寡核苷酸结合。以与索引1相同的方式读取索引2序列。然后在该步骤完成时洗出索引2读取产物。
读取两个索引后,通过使用聚合酶延伸第二个流通池寡核苷酸来启动读取2,从而形成双链桥。将该双链dna变性,3'末端被封闭。最初的正链被切割并洗掉,留下了反向链。读取2首先是引入读取2测序引物。与读取1一样,重复测序步骤,直到达到所需的长度。读取的2产物被洗去。整个过程会产生数百万个代表所有片段的读取。来自合并样品文库的序列是根据样品制备过程中引入的唯一索引进行分离的。对于每个样品,将对碱基判定的相似延伸的读取进行局部聚簇。将正向和反向读取配对以创建连续序列。将这些连续序列与参考基因组比对,以进行识别变体。
上述通过合成实例进行的测序涉及双端读取,其在公开的方法的许多实施方案中使用。双端测序涉及片段两端的两次读取。当一对读取被映射到参考序列时,可以确定两个读取之间的碱基对距离,然后可以使用该距离来确定从中获得读取的片段的长度。在某些情况下,跨过两个箱的片段的一对末端读取之一将与一个箱对齐,而另一个读取与相邻箱对齐。随着箱变长或读取次数变短,这种情况变得越来越少。可以使用各种方法来解释这些片段的箱成员身份。例如,可以在确定箱的片段大小频率时将其省略;可以针对两个相邻箱计数它们;可以将它们分配给包含两个箱中有更大碱基对的箱;或者可以将它们分配给其权重与每个箱中碱基对的一部分有关的两个箱。
双端读取可使用不同长度的插入物(即要测序的不同片段大小)。作为本申请中的默认含义,双端读取用于指从各种插入物长度获得的读取。在某些情况下,为了区分短插入物双端读取和长插入物双端读取,后者也称为匹配的双端读取。在涉及匹配的双端读取的一些实施方案中,首先将两个生物素连接的衔接子连接到相对长的插入物(例如,几kb)的两端。然后,生物素连接的衔接子将插入物的两个末端连接起来,以形成一个环状分子。然后可以通过进一步破碎环化的分子来获得包含生物素连接的衔接子的子片段。然后可以通过与上述短插入物双端测序相同的方法,对包含原始片段两端相反顺序的子片段进行测序。使用illumina平台进行配对双端测序的更多详细信息显示在以下url的在线出版物中,该出版物通过引用整体并入本文:res.illumina.com/documents/products/technotes/technote_nextera_matepair_data_processing。关于双端测序的其他信息可参见:美国专利第7601499号和美国专利公开第2012/0,053,063号,关于双端测序方法和设备的材料,其通过引用并入本文。
在对dna片段测序之后,将预定长度例如100bp的序列读取映射到已知的参考基因组或与之比对。映射或比对的读取及其在参考序列上的相应位置也称为标签。在一个实施方案中,参考基因组序列是ncbi36/hg18序列,其可获自万维网:genome.ucsc.edu/cgi-bin/hggateway?org=human&db=hg18&hgsid=166260105。或者,参考基因组序列是grch37/hg19,其可获自万维网:genome.ucsc.edu/cgi-bin/hggateway。其他公共序列信息来源包括genbank、dbest、dbsts、embl(欧洲分子生物学实验室)和ddbj(日本dna数据库)。有许多计算机算法可用于比对序列,包括但不限于:blast(altschuletal.,1990)、blitz(mpsrch)(sturrock&collins,1993)、fasta(person&lipman,1988)、bowtie(langmeadetal.,genomebiology10:r25.1-r25.10[2009])或eland(illumina,inc.,sandiego,ca,usa)。在一个实施方案中,对血浆cfdna分子的克隆扩展拷贝的一端进行测序,并通过illumina基因组分析仪的生物信息学比对分析进行处理,该分析仪使用核苷酸数据库的高效大规模比对(eland)软件。
在一个示例性但非限制性的实施方案中,本文所述的方法包括使用helicos公司的真正单分子测序(tsms)技术的单分子测序技术,获得测试样品中的核酸的序列信息,例如母体样品中的cfdna,正在筛查癌症等的个体的cfdna或细胞dna(例如,其描述于harrist.d.etal.,science320:106-109[2008])。在tsms技术中,将dna样品切割成约100至200个核苷酸的链,然后将polya序列添加到每条dna链的3'末端。每条链通过添加荧光标记的腺苷核苷酸进行标记。然后将dna链杂交到流通池,该流通池包含数百万个固定在流通池表面的寡聚-t捕获位点。在某些实施方案中,模板的密度可以为约1亿个模板/cm2。然后将流通池加载到仪器(例如heliscopetm测序仪)中,并用激光照射流通池的表面,以显示每个模板的位置。ccd摄像机可以在流通池表面上确定模板的位置。然后切割模板荧光标记并洗掉。测序反应通过引入dna聚合酶和荧光标记的核苷酸开始。寡聚-t核酸用作引物。聚合酶以模板指导的方式将标记的核苷酸掺入引物。除去聚合酶和未掺入的核苷酸。通过对流通池表面进行成像,可以识别出已定向掺入荧光标记核苷酸的模板。成像后,切割步骤将去除荧光标记,然后使用其他荧光标记的核苷酸重复该过程,直到获得所需的读取长度。在每个核苷酸添加步骤中收集序列信息。通过单分子测序技术进行的全基因组测序,在测序文库的制备中排除或通常避免了基于pcr的扩增,并且该方法允许直接测量样品,而不是测量该样品的拷贝。
在另一个示例性但非限制性的实施方案中,本文所述的方法包括使用454测序(roche),获得测试样品中核酸,例如母体测试样品中的cfdna、正在筛查癌症等的个体的cfdna或细胞dna的序列信息(例如,其描述于margulies,m.etal.nature437:376-380[2005])。454测序通常涉及两个步骤。第一步,将dna剪切成约300-800个碱基对的片段,然后将片段平端化。然后将寡核苷酸衔接子连接至片段的末端。衔接子用作片段的扩增和测序的引物。可以使用例如,含有5'-生物素标签的衔接子b,将片段连接到dna捕获珠,例如链霉亲和素包被的珠。在油水乳状液的液滴内,pcr扩增与所述珠相连的片段。结果是每个珠上克隆扩增的dna片段有多个拷贝。在第二步骤中,将所述珠捕获在孔(例如皮升大小的孔)中。对每个dna片段并行进行焦磷酸测序。一个或多个核苷酸的添加产生光信号,该光信号由在测序仪中的ccd相机记录。信号强度与掺入的核苷酸数成正比。焦磷酸测序利用焦磷酸(ppi),其在添加核苷酸后释放。在存在腺苷5'磷酰硫酸酯的情况下,ppi通过atp硫化酶转化为atp。萤光素酶使用atp将萤光素转化为氧化萤光素,该反应产生的光可以进行测量和分析。
在另一个示例性但非限制性的实施方案中,本文所述的方法包括使用solidtm技术(appliedbiosystems),获得测试样品中核酸,例如母体测试样品中的cfdna、正在筛查癌症等的个体的cfdna或细胞dna的序列信息。在solidtm通过连接的测序中,将基因组dna剪切成片段,并将衔接子连接到片段的5'和3'末端以生成片段文库。或者,可以通过将衔接子连接至片段的5'和3'末端、环化片段、消化所述环化的片段来生成内部衔接子,并将衔接子连接至所得片段的5'和3'末端以生成配对的双端文库,从而引入内部衔接子片段。接下来,在含有珠、引物、模板和pcr组分的微反应器中制备克隆的珠群体。pcr之后,使模板变性,并富集珠以分离具有扩展模板的珠。所选珠上的模板经过3'修饰,可以与玻璃载片结合。可以通过将部分随机的寡核苷酸与由特定荧光团识别的中心确定的碱基(或碱基对)进行顺序杂交和连接来确定序列。记录颜色后,将连接的寡核苷酸切割并去除,然后重复该过程。
在另一个示例性但非限制性的实施方案中,本文所述的方法包括使用pacificbiosciences的单分子实时(smrttm)测序技术,获得测试样品中核酸,例如母体测试样品中的cfdna、正在筛查癌症等的个体的cfdna或细胞dna的序列信息。在smrt测序中,在dna合成过程中对染料标记核苷酸的连续掺入成像。单个dna聚合的序列信息酶分子连接到各个零模式波长检测器(zmw检测器)的底表面,该检测器在将磷酸化的核苷酸掺入正在生长的引物链中时获得序列信息。zmw检测器包括限制结构,该限制结构使得能够针对荧光核苷酸的背景观察通过dna聚合酶掺入单个核苷酸,所述荧光核苷酸迅速扩散进出zmw(例如,以微秒为单位)。通常需要数毫秒的时间才能将核苷酸掺入正在生长的链中。在此期间,荧光标记被激发并产生荧光信号,并且荧光标记被切割掉。染料相应荧光的测量显示掺入了哪种碱基。重复该过程以提供序列。
在另一个示例性但非限制性的实施方案中,本文所述的方法包括使用纳米孔测序,获得测试样品中核酸,例如母体测试样品中的cfdna,正在筛查癌症等的个体的cfdna或细胞dna的序列信息(例如,其描述于sonigv和mellera.clinchem53:1996-2001[2007])。纳米孔测序dna分析技术是由许多公司开发的,包括例如,牛津纳米孔技术公司(oxford,unitedkingdom)、sequenom、nabsys等。纳米孔测序是一种单分子测序技术,通过该技术单分子dna在通过纳米孔时即可直接测序。纳米孔是一个小孔,通常直径约为1纳米。纳米孔浸入导电流体中并在其上施加电势(电压),会由于离子通过纳米孔的传导而产生少量电流。流过的电流量对纳米孔的大小和形状敏感。当dna分子穿过纳米孔时,dna分子上的每个核苷酸都会以不同程度阻塞纳米孔,从而以不同程度地改变通过纳米孔的电流大小。因此,当dna分子通过纳米孔时电流的这种变化提供了dna序列的读取。
在另一个示例性但非限制性的实施方案中,本文所述的方法包括使用化学敏感的场效应晶体管(chemfet)阵列,获得测试样品中核酸,例如母体测试样品中的cfdna、正在筛查癌症等的个体的cfdna或细胞dna的序列信息(例如,其描述于美国专利申请公开第2009/0026082号)。在该技术一个实例中,可以将dna分子放入反应室中,并且可以将模板分子与结合到聚合酶的测序引物杂交。通过chemfet,可将一种或多种三磷酸酯掺入测序引物3'端的新核酸链中,识别为电流变化。一个阵列可以具有多个chemfet传感器。在另一个实例中,可以将单个核酸附着到珠上,并且可以在所述珠上扩增核酸,并且可以将各个珠转移到chemfet阵列上的各个反应室中,每个室都有chemfet传感器,并且所述核酸可以测序。
在另一个实施方案中,本方法包括使用透射电子显微镜(tem),获得测试样品中的核酸,例如母体测试样品中的cfdna的序列信息。该方法被称为单分子放置快速纳米转移(imprnt),包括利用单原子分辨率透射电子显微镜对高分子量(150kb或更大)dna进行选择性重原子标记的dna成像,并将这些分子以具有一致的碱基与碱基间距的超密集(3nm链与链)平行阵列排列在超薄膜上。电子显微镜用于对胶片上的分子成像,以确定重原子标记的位置,并从dna中提取碱基序列信息。该方法进一步描述于pct专利公开第wo2009/046445号。该方法允许在不到10分钟的时间内对完整的人类基因组进行测序。
在另一个实施方案中,dna测序技术是iontorrent单分子测序,其将半导体技术与简单的测序化学方法相结合,以在半导体芯片上将化学编码的信息(a、c、g、t)直接翻译成数字信息(0、1)。实际上,当核苷酸通过聚合酶掺入dna链时,氢离子作为副产物释放出来。iontorrent使用微机械加工孔的高密度阵列,以大规模并行方式执行此生化过程。每个孔中都容纳有一个不同的dna分子。孔下面是离子敏感层,在离子敏感层下方是离子传感器。当将核苷酸(例如c)添加到dna模板中,然后整合到dna链中时,氢离子将被释放。该离子产生的电荷会改变溶液的ph值,可通过iontorrent的离子传感器检测到。测序仪-实质上是世界上最小的固态ph计-判定碱基,直接从化学信息转变为数字信息。然后,ionpersonalgenomemachine(pgmtm)测序仪依次将一个又一个的核苷酸注入该芯片。如果注入该芯片的下一个核苷酸不匹配。不会记录任何电压变化,也不会判定任何碱基。如果dna链上有两个相同的碱基,则电压将加倍,并且芯片将记录判定的两个相同碱基。直接检测可以在数秒钟内记录核苷酸掺入。
在另一个实施方案中,本方法包括使用杂交测序获得测试样品中的核酸,例如母体测试样品中的cfdna的序列信息。杂交测序包括使多个多核苷酸序列与多个多核苷酸探针接触,其中多个多核苷酸探针中的每一个可以任选地连接至基质。基质可以是包含已知核苷酸序列阵列的平坦表面。与阵列的杂交模式可用于确定样品中存在的多核苷酸序列。在其他实施方案中,每个探针被连接到珠,例如磁珠等。可以确定与珠的杂交,并用于鉴定样品中的多个多核苷酸序列。
在本文描述的方法的一些实施方案中,映射的序列标签包含约20bp、约25bp、约30bp、约35bp、约40bp、约45bp、约50bp、约55bp、约60bp、约65bp、约70bp、约75bp、约80bp、约85bp、约90bp、约95bp、约100bp、约110bp、约120bp、约130、约140bp、约150bp、约200bp、约250bp、约300bp、约350bp、约400bp、约450bp、或约500bp的序列读取。可以预期,技术上的进步将使大于500bp的单端读取成为可能,从而在生成双端读取时允许大于1000bp的读取。在一个实施方案中,所映射的序列标签包含36bp的序列读取。通过将标签的序列与参考序列进行比较以确定测序的核酸(例如cfdna)分子的染色体来源,可以实现序列标签的定位,并且不需要特定的基因序列信息。可以允许很小程度的不匹配(每个序列标签0-2个不匹配),以解释参考基因组和混合样品中的基因组之间可能存在的微小多态性。
每个样品通常获得多个序列标签。在一些实施方案中,将读取映射到每个样品的参考基因组,获得了至少约3×106个序列标签、至少约5×106个序列标签、至少约8×106个序列标签、至少约10×106个序列标签、至少约15×106个序列标签、至少约20×106个序列标签、至少约30×106个序列标签、至少约40×106个序列标签、或至少约50×106个序列标签,其包含20-40bp(例如36bp)的读取。在一个实施方案中,所有序列读取均映射到参考基因组的所有区域。在一个实施方案中,分析已经映射到参考基因组的所有区域(例如所有染色体)的标签,并且确定cfdna样品中的snv或cnv。
正确确定样品中是否存在snv或cnv所需的准确度,取决于测序过程中样品中映射至参考基因组的序列标签数量的变化(染色体间可变性),以及在不同测序运行中映射到参考基因组的序列标签数量的变化(序列间可变性)。例如,对于映射到富含gc或缺乏gc的参考序列的标签,变化可能特别明显。使用不同的方案提取和纯化核酸,制备测序文库,以及使用不同的测序平台,可能会导致其他变化。本方法基于归一化序列(归一化染色体序列或归一化片段序列)的知识,使用序列剂量(染色体剂量或片段剂量),从实质上考虑了源自染色体之间(运行中)和测序之间(运行之间)的累积可变性以及平台相关的可变性。染色体剂量是基于归一化染色体序列的知识,归一化染色体序列可以由单个染色体组成,也可以由选自染色体1-22、x和y的两个或多个染色体组成。或者,归一化染色体序列可以由一个染色体片段,或由一个染色体或两个或多个染色体的两个或多个片段组成。片段剂量是基于归一化片段序列的知识,归一化片段序列可以由任何一个染色体的单个片段,或由染色体1-22、x和y的任意两个或多个染色体的两个或多个片段组成。
测定感兴趣变体的设备和系统
通常使用各种计算机执行的算法和程序来进行测序数据的分析并从中得出诊断。因此,某些实施例采用涉及存储在一个或多个计算机系统或其他处理系统中或通过其传输的数据的处理。本文公开的实施方案还涉及用于执行这些操作的设备。该设备可以被特殊构造用于所需目的,或者它可以是由计算机中存储的计算机程序和/或数据结构选择性地激活或重新配置的通用计算机(或一组计算机)。在一些实施方案中,一组处理器协作地(例如,经由网络或云计算)和/或并行地执行所列举的分析操作中的一些或全部。用于执行本文描述的方法的处理器或一组处理器可以是各种类型的,包括微控制器和微处理器,如可编程装置(例如,cpld和fpga),以及非可编程装置,例如门阵列asic或通用微处理器。
另外,某些实施方案涉及有形的和/或非易失性计算机可读介质或计算机程序产品,其包括用于执行各种计算机实现的操作的程序指令和/或数据(包括数据结构)。计算机可读介质的实例包括但不限于:半导体存储装置,磁性介质如磁盘驱动器、磁带,光学介质如cd,磁光介质,以及专门配置用于存储和执行程序指令的硬件装置如只读存储设备(rom)和随机存取存储器(ram)。所述计算机可读介质可以由终端用户直接控制,或者所述介质可以由终端用户间接控制。直接控制的介质实例包括位于用户设施处的介质和/或未与其他实体共享的介质。间接控制的介质实例包括用户可以通过外部网络和/或通过提供共享资源(例如“云”)服务间接访问的介质。程序指令的实例包括机器代码如由编译器生成的机器代码,以及包含更高级别代码的文件,这些文件可以由计算机使用解释器执行。
在各种实施方案中,以电子格式提供在所公开方法和设备中采用的数据或信息。这样的数据或信息可以包括衍生自核酸样品的读取和标签,与参考序列的特定区域比对(例如,与染色体或染色体区段比对)的此类标签的计数或密度,参考序列(包括仅提供或主要提供多态性的参考序列),染色体和片段剂量,诸如snv或非整倍性的判定,归一化的染色体和片段值,成对的染色体或片段以及相应的归一化染色体或片段,咨询建议,诊断等。如本文所用,以电子格式提供的数据或其他信息可用于存储在机器上以及在机器之间的传输。常规上,以数字形式提供电子格式的数据,并且可以将其作为位和/或字节存储在各种数据结构、列表、数据库等中。该数据可以以电子、光学等方式体现。
一个实施方案提供了一种计算机程序产品,该计算机程序产品用于生成指示测试样品中是否存在与癌症相关的snv或非整倍性的输出。该计算机产品可以包含用于执行上述任何一种或多种确定染色体异常的方法的指令。如所解释,所述计算机产品可以包括其上记录有计算机可执行或可编译逻辑(例如,指令)的非易失性和/或有形计算机可读介质,以使处理器能够确定是否应进行snv判定或cnv判定。在一个实例中,所述计算机产品包括计算机可读介质,该计算机可读介质具有记录在其上的用于使处理器能够诊断snv或cnv的计算机可执行或可编译逻辑(例如,指令)。
来自所考虑的样品的序列信息可以被映射到染色体参考序列,以识别用于任何一个或多个感兴趣染色体中的每一个的多个序列标签,以及识别用于归一化所述任何一个或多个感兴趣染色体中的每一个的片段序列的多个序列标签。在各种实施方案中,所述参考序列被存储在诸如关系数据库或对象数据库的数据库中。
应当理解,对于没有帮助的人来执行本文公开的方法的计算操作是不切实际的,甚至在大多数情况下是不可能的。例如,不借助计算设备,要将来自样品的一个30bp读取的映射到人类染色体中的任何一条,可能需要多年的努力。当然,由于可靠的snv和cnv判定通常需要将数千个(例如,至少约10,000个)或甚至数百万个读取映射到一个或多个染色体上,因此问题变得更加复杂。
可以使用用于评估测试样品中感兴趣基因序列拷贝数的系统来执行本文公开的方法。该系统包括:(a)测序仪,用于从测试样品中接收核酸,并提供来自所述样品的核酸序列信息;(b)处理器;以及(c)一种或多种计算机可读存储介质,其上存储有用于在所述处理器上执行以实施用于识别任何snv或cnv的方法的指令。
在一些实施方案中,该方法由其上存储有用于实施用以识别任何snv或cnv的方法的计算机可读指令的计算机可读介质来指示。因此,一个实施方案提供了一种计算机程序产品,该计算机程序产品包括其上存储有计算机可执行指令的一个或多个计算机可读非易失性存储介质,当该计算机可执行指令由计算机系统的一个或多个处理器执行时,使该计算机系统实现用于评估包含正常核酸和肿瘤无细胞核酸的测试样品中感兴趣序列的拷贝数的方法。该方法包括:(a)通过一个或多个处理器检索从测试样品获得的cfdna片段的序列读取和片段大小;(b)通过一个或多个处理器将所述cfdna片段分配到代表不同片段大小的多个箱中;(c)使用所述序列读取并由所述一个或多个处理器确定从所述多个箱中选择的优先箱集合中的所述感兴趣变体的等位基因频率,其中所述优先箱集合被选择为:(i)限制所述优先箱集合中的感兴趣变体数量低于检测限的概率;(ii)增加所述优先箱集合中的感兴趣变体数量高于所述多个箱中所有箱的概率。
在一些实施方案中,所述指令可进一步包括针对提供所述母体测试样品的人类个体自动记录与所述方法有关的信息,如染色体剂量以及在患者病历中是否存在snv或cnv。患者病历可以由例如实验室、医师办公室、医院、健康维护组织、保险公司或个人病历网站维护。此外,基于处理器实施的分析的结果,该方法可以进一步包括对从其获取了母体测试样品的人类个体进行开处方、开始和/或改变治疗。这可能涉及对从个体身上采集的其他样品进行一项或多项其它测试或分析。
还可以使用计算机处理系统来执行所公开的方法,该计算机处理系统适于或配置为实施用于识别任何snv或cnv的方法。一个实施方案提供了一种计算机处理系统,该计算机处理系统适于或配置为实施本文所述的方法。在一个实施方案中,所述设备包括测序装置,该测序装置适于或配置用于对样品中的至少一部分核酸分子进行测序,以获得本文其他各处所述的序列信息的类型。该设备还可包括用于处理样品的组件。这样的组件在本文其他地方有描述。
序列或其他数据可以直接或间接输入计算机或存储在计算机可读介质中。在一个实施方案中,计算机系统直接连接至测序装置,该测序装置读取和/或分析来自样品的核酸序列。来自此类工具的序列或其他信息是通过计算机系统中的接口提供的。或者,从序列存储源(如数据库或其他存储库)提供给系统处理的序列。一旦可用于处理设备,存储装置或大容量存储装置至少临时地缓冲或存储核酸序列。另外,存储装置可以存储各种染色体或基因组等的标签计数。存储器还可以存储用于分析呈现序列或映射数据的各种例程和/或程序。这样的程序/例程可以包括用于执行统计分析的程序等。
在一个实例中,用户将样品提供到测序设备中。数据由连接到计算机的测序设备收集和/或分析。计算机上的软件允许数据收集和/或分析。数据可以存储、显示(通过监视器或其他类似装置)和/或发送到其他位置。该计算机可以连接到互联网,该互联网用于将数据传输到远程用户(例如,医师、科学家或分析人员)使用的手持设备。应当理解,可以在发送之前存储和/或分析数据。在一些实施方案中,原始数据被收集并发送到将分析和/或存储数据的远程用户或设备。传输可以通过互联网进行,也可以通过卫星或其他连接进行。或者,可以将数据存储在计算机可读介质上,并且可以将该介质运送给最终用户(例如,通过邮件)。远程用户可以在相同或不同的地理位置,包括但不限于建筑物、城市、州、国家或大洲。
在一些实施方案中,所述方法还包括收集关于多个多核苷酸序列(例如,读取、标签和/或参考染色体序列)的数据,并将该数据发送至计算机或其他计算系统。例如,计算机可以连接到实验室器材,例如样品收集设备、核苷酸扩增设备、核苷酸测序设备或杂交设备。然后,计算机可以收集实验室装置收集的适用数据。可以在任何步骤将数据存储在计算机上,例如,在发送之前、发送期间或者发送期间或发送之后实时收集实时信息。数据可以存储在可以从计算机提取的计算机可读介质上。所收集或存储的数据可以例如经由局域网或诸如互联网之类的广域网从计算机传输到远程位置。如下所述,在远程位置可以对发送的数据执行各种操作。
在本文公开的系统、设备和方法中可以存储、传输、分析和/或操控的电子格式化数据类型如下:
通过对测试样品中的核酸进行测序获得的读取
通过将读取与参考基因组或其他参考序列进行比对获得的标签
参考基因组或序列
序列标签密度-参考基因组或其他参考序列的两个或多个区域(通常是染色体或染色体片段)中每个区域的标签计数或数量
对特定感兴趣染色体或染色体段进行归一化的染色体或染色体片段的身份
从感兴趣染色体或片段以及相应的归一化染色体或片段获得的染色体或染色体片段(或其他区域)的剂量
将用于判定染色体剂量的阈值作为受影响的、未受影响的或无判定的
染色体剂量的实际判定
诊断(与判定相关的临床病症)
从判定和/或诊断得出的进一步测试建议
从判定和/或诊断得出的治疗和/或监测计划
可以使用不同的设备在一个或多个位置获得、存储、传输、分析和/或操控这些各种类型的数据。处理选项涵盖范围很广。在范围的一端,所有或许多此种信息都存储在处理测试样品的位置,例如医生办公室或其它临床场所,并在其中使用。在另一种极端情况下,样品是在一个位置获得的,可以在不同的位置进行处理并可选择地进行测序,在一个或多个不同的位置进行读取比对和判定,并在另一个位置准备诊断、建议和/或计划(可能是获取样品的位置)。
在各种实施方案中,用测序设备产生读取,然后将其传输到远程位点,在那儿对其进行处理以产生判定。例如,在这个远程位置,将读取与参考序列进行比对以产生标签,将其计数并分配给感兴趣染色体或片段。同样在远程位置,使用相关的归一化染色体或片段将计数转换为剂量。更进一步,在远程位置,所述剂量被用于产生判定。
在不同位置可能采用的处理操作包括:
样品采集
在测序之前进行样品处理
测序
分析序列数据,并导出snv或cnv判定
诊断
向患者或医疗保健提供者报告诊断和/或判定
制定进一步治疗、测试和/或监测的计划
执行计划
心理咨询
如本文其他地方所述,这些操作中的任何一个或多个可以是自动化的。通常,将对测序和序列数据的分析以及产生snv或cnv判定进行计算机处理。其他操作可以手动或自动执行。
可以进行样品收集的地点实例,包括卫生从业人员的办公室、诊所、患者家(提供样品收集工具或试剂盒的地方)以及移动医疗车。可以在测序之前进行样品处理的位置的实例,包括医疗从业人员的办公室、诊所、患者家(提供样品处理设备或试剂盒的地方)、移动医疗车以及snv或cnv分析提供者的设施。可以执行测序的位置的实例,包括医疗从业者办公室、诊所、医疗从业者办公室、诊所、患者家(提供样品测序设备和/或试剂盒的地方)、移动医疗车以及snv或cnv分析提供者的设施。可以在进行测序的位置提供专用的网络连接,用于以电子格式传输序列数据(通常为读取)。这样的连接可以是有线的或无线的,并具有且可以被配置为将数据发送到可以在传输到处理站点之前处理和/或聚合数据的站点。数据聚合器可以由健康组织(例如,健康维护组织(hmo))维护。
分析和/或推导操作可以在前述位置中的任何一个处执行,或者可在专用于计算和/或分析核酸序列数据的服务的另一远程站点处执行。这样的位置包括,例如,诸如通用服务器场之类的集群、snv或cnv分析服务业务的设施等。在一些实施方案中,用于执行分析的计算设备是租借的或租赁的。计算资源可以是处理器的互联网可访问集合的一部分,该处理器诸如俗称云的处理资源。在某些情况下,所述计算是由一组相互关联或不关联的处理器并行或大规模并行执行的。可以使用诸如集群计算、网格计算等的分布式处理来完成该处理。在这样的实施方案中,计算资源的集群或网格共同形成由多个处理器或计算机共同组成的超级虚拟计算机,所述多个处理器或计算机共同作用以执行本文所述的分析和/或推导。如本文所述,这些技术以及更常规的超级计算机可以用于处理序列数据。每种都是依赖处理器或计算机的并行计算形式。在网格计算的情况下,这些处理器(通常是整个计算机)通过网络(私人的、公用的或互联网)通过常规网络协议(例如以太网)连接。相比之下,超级计算机具有许多通过本地高速计算机总线连接的处理器。
在某些实施方案中,诊断是在与分析操作相同的位置处产生的。在其他实施方案中,它在不同的位置执行。在某些实例中,报告诊断是在取样的位置进行的,尽管并非必须如此。可以生成或报告诊断和/或执行计划的位置的实例,包括医疗从业人员的办公室、诊所、计算机可访问的互联网站点,以及与网络的有线或无线连接的手持装置如手机、平板电脑、智能手机等。进行咨询的地点的实例,包括健康医生的办公室、诊所、可通过计算机访问的互联网站点、手持装置等。
在一些实施方案中,样品收集、样品处理和测序操作在第一位置进行,而分析和推导操作在第二位置进行。但是,在某些情况下,样品采集是在一个位置(例如,从业人员的办公室或诊所)采集的,而样品处理和测序是在不同的位置进行的,该位置可选地是进行分析和推导的相同位置。
在各种实施方案中,可以通过由于用户或实体启动样品收集、样品处理和/或测序来启动上面列出的操作的序列。在一个或多个这些操作开始执行之后,其他操作自然会随之而来。例如,测序操作可以导致读取被自动收集并发送到处理设备,该处理设备通常自动地并且可能在没有进一步用户干预的情况下进行snv或cnv操作的序列分析和推导。在一些实施方案中,然后将该处理操作的结果自动地传递给系统组件或实体,该过程可能以重新格式化作为诊断来传递给处理向卫生专业人员和/或患者报告信息的系统组件或实体。如所解释,这样的信息还可以被自动处理以产生治疗、测试和/或监视计划,可能连同咨询信息。因此,开始早期操作可以启动端到端的顺序,在该顺序中,向健康专业人员、患者或其他有关方面提供对身体状况有用的诊断、计划、咨询和/或其他信息。即使整个系统的各部分在物理上是分开的,并且可能远离例如样品和测序设备的位置,也可以做到这一点。
图4以简单的框形式示出了典型的计算机系统,当适当地配置或设计该计算机系统时,其可以用作根据某些实施方案的计算设备。计算机系统2000包括连接到存储设备的任何数量的处理器2002(也称为中央处理单元或cpu),该存储设备包括主存储器2006(通常是随机存取存储器或ram)、主存储器2004(通常是只读存储器或rom)。cpu2002可以是各种类型,包括诸如可编程装置(例如,cpld和fpga)的微控制器和微处理器,以及诸如门阵列asic或通用微处理器的非可编程装置。在所描述的实施方案中,主存储器2004用于向cpu单向传送数据和指令,而主存储器2006通常用于双向地传送数据和指令。这两个主存储装置都可以包括任何合适的计算机可读介质,如上述介质。大容量存储装置2008还双向连接到主存储2006,并且提供附加的数据存储容量,并且可以包括上述任何计算机可读介质。大容量存储装置2008可以用于存储程序、数据等,并且通常是诸如硬盘的辅助存储介质。通常,这样的程序、数据等被临时复制到主存储器2006以在cpu2002上执行。应理解的是,保留在大容量存储装置2008中的信息,在适当的情况下可以以标准方式被结合为主存储器2004的一部分。诸如cd-rom2014的特定大容量存储装置,也可以单向地将数据传递给cpu或主存储器。
cpu2002还连接到接口2010,该接口2010连接到一个或多个输入/输出装置,如核酸测序仪(2020)、视频监视器、轨迹球、鼠标、键盘、麦克风、触敏显示器、换能器卡读取器、磁带或纸带读取器、平板电脑、手写笔、语音或手写识别外围设备、usb端口或其他众所周知的输入装置如其他计算机。最后,cpu2002可以选择使用外部连接(如在2012总体所示)来连接到外部设备如数据库、计算机或电信网络。通过这种连接,可以预期cpu可以从网络接收信息,或可能会在执行本文所述方法步骤的过程中向网络输出信息。在一些实施方案中,代替或除经由接口2010以外,核酸测序仪(2020)可以经由网络连接2012可通信地连接至cpu2002。
在一个实施方案中,诸如计算机系统2000的系统被用作能够执行本文所述的一些或全部任务的数据导入、数据关联和查询系统。可以经由网络连接2012提供包括数据文件在内的信息和程序,以供研究者访问或下载。或者,可以在存储装置上将此类信息、程序和文件提供给研究人员。
在特定实施方案中,计算机系统2000直接连接至数据采集系统,如微阵列、高通量筛选系统或从样品捕获数据的核酸测序仪(2020)。来自这样的系统的数据通过接口2010提供,以供系统2000进行分析。或者,由系统2000处理的数据是从诸如数据库或相关数据的其他存储库的数据存储源提供的。一旦进入设备2000,诸如主存储器2006或大容量存储器2008的存储装置,至少临时地缓冲或存储相关数据。存储器还可存储用于导入、分析和呈现所述数据的各种例程和/或程序,所述数据包括序列读取、umi、用于确定序列读取、折叠序列读取和纠正读取中的错误等的代码。
在某些实施方案中,本文使用的计算机可以包括用户终端,该用户终端可以是任何类型的计算机(例如,台式计算机、膝上型计算机、平板电脑等)、媒体计算平台(例如,电缆、卫星机顶盒、数字录像机等)、手持式计算装置(例如pda、电子邮件客户端等)、手机或任何其他类型的计算或通信平台。
在某些实施方案中,本文使用的计算机还可以包括与用户终端通信的服务器系统,该服务器系统可以包括服务器装置或分散式服务器装置,并且可以包括大型计算机、小型计算机、超级计算机、个人计算机或其组合。在不脱离本发明的范围的情况下,也可以使用多个服务器系统。用户终端和服务器系统可以通过网络彼此通信。网络可以包括例如有线网络如lan(局域网)、wan(广域网)、man(城域网)、isdn(集成服务数字网络)等,以及无线网络如无线lan、cdma、蓝牙和卫星通信网络等,而不限制本发明的范围。
图5示出了用于从测试样品产生判定或诊断的分散系统的一种实施方案。样品收集位置01用于从诸如孕妇或推定的癌症患者的患者获得测试样品。然后将样品提供到处理和测序位置03,在该位置03可以如上所述对测试样品进行处理和测序。位置03包括用于处理样品的设备以及用于对处理后的样品进行测序的设备。如本文其他地方所述,测序的结果是读取的集合,其通常以电子格式提供,并提供给诸如互联网的网络,其在图5中由附图标记05表示。
序列数据被提供给远程位置07,在该位置执行分析和判定生成。此位置可能包括一个或多个功能强大的计算装置如计算机或处理器。在位置07处的计算资源完成分析并根据接收到的序列信息生成判定后,该判定将传递回到网络05。在某些实施方案中,不仅在位置07处生成了判定,而且还产生了相关的诊断。所述判定和/或诊断然后通过网络传输并返回到样品收集位置01,如图5所示。正如所解释的,这只是针对如何在各个位置之间分开与生成判定或诊断相关的各种操作的多种变型之一。一种常见的变型涉及在单个位置提供样品收集、处理和测序。另一个变型涉及在与分析和判定生成相同的位置提供处理和测序。
图6详细说明了在不同位置执行各种操作的选项。在图6所示的最细微的意义上,以下每个操作均在各自位置执行:样品收集、样品处理、测序、读取比对、判定、诊断以及报告和/或计划制定。
在汇集这些操作中一些操作的一个实施方案中,在一个位置执行样品处理和测序,并且在不同的位置执行读取比对、判定和诊断。参见图6中由参考字符a标识的部分。在另一实施方案中,其在图6中由字符b标识,样品收集、样品处理和测序均在同一位置进行。在此实施方案中,读取比对和判定在第二位置执行。最后,在第三位置进行诊断以及报告和/或计划制定。在图6中用字符c表示的实施方案中,样品收集是在第一位置执行的,样品处理、测序、读取比对、判定和诊断都在第二位置一起执行,而报告和/或计划制定是在第三位置执行。最终,在图6中标为d的实施方案中,样品收集在第一位置执行,样品处理、测序、读取比对和判定均在第二位置执行,而诊断以及报告和/或计划管理在第三位置执行。
一个实施方案提供了用于分析无细胞dna(cfdna)中与肿瘤相关的简单核苷酸变体的系统,该系统包括用于接收核酸样品并提供来自核酸样品的核酸序列信息的测序仪;处理器;包括用于在所述处理器上执行的代码的机器可读存储介质,所述代码包括:(a)用于检索从测试样品获得的cfdna片段的序列读取和片段大小的代码;(b)用于将cfdna片段分配到代表不同片段大小的多个箱中的代码;(c)用于使用序列读取确定在从多个箱中选择的优先箱集合中的感兴趣变体的等位基因频率的代码,其中优先箱集合被选择为:(i)限制优先箱集合中的感兴趣变体的数量低于检测限的概率,以及(ii)增加优先箱集合中的感兴趣变体的数量高于多个箱中所有箱的概率。
在本文提供的任何系统的一些实施方案中,测序仪被配置为执行下一代定序(ngs)。在一些实施方案中,测序仪被配置为使用通过可逆染料终止子的合成测序进行大规模平行测序。在其他实施方案中,测序仪被配置为通过连接进行测序。在其他实施方案中,测序仪被配置为进行单分子测序。
实施例
实施例1
该实施例使用模拟数据来说明,由使用优先箱集合来分析无细胞dna片段以确定感兴趣变体的方法所提供的优点。该实施例示出了一些实施方案可以提供改进的信号水平以用于检测感兴趣变体(例如,与肿瘤相关的变体)。
针对四种不同情形生成了模拟数据,每种情形均具有不同的肿瘤分数、肿瘤细胞中的等位基因频率,以及血浆样品中的等位基因频率。血浆样品包括源自肿瘤细胞和健康细胞的cfdna片段。这些情形还具有不同的测序深度。
表1显示了四种不同情形的参数值。提供了情形a以模拟一个样品,该样品的肿瘤分数(f肿瘤)为0.01,肿瘤细胞中等位基因频率(af肿瘤)为0.5,血浆中等位基因频率(af血浆)为0.005,并经过测序深度(dp)为5000×的处理。提供了情形a以模拟癌症处于早期且肿瘤分数非常低的临床病症。
情形b的肿瘤分数为0.2,肿瘤细胞等位基因频率为0.5,血浆等位基因频率为0.1。情形b的测序深度为1000。情形b用于模拟当肿瘤负荷高且肿瘤变化可能对监测肿瘤发展有利的肿瘤晚期阶段的临床病症。
情形c的肿瘤分数为0.2,肿瘤细胞等位基因频率为0.02,血浆等位基因频率为0.004。测序深度为5000。提供情形c以模拟转移中的治疗耐药突变,其中肿瘤分数高,但肿瘤细胞中等位基因频率低。
情形d的肿瘤分数为0.1,肿瘤细胞等位基因频率为0.05,血浆等位基因频率为0.005。该情形的测序深度为5000。情形d设计为模拟原发癌中的亚克隆突变,其中肿瘤分数处于中等水平,且肿瘤细胞等位基因频率相对较低。
图7a至图7d示出了使用不同的片段大小的箱集合的感兴趣变体的等位基因频率,一个图对应情景a至d中每一种。图7a显示了情形a的数据。四组箱集合的等位基因频率显示为m1-m4须盒图。框m1显示了使用一组优先箱集合获得的等位基因频率数据。选择优先集合以增加优先集合中感兴趣变体具有比多个箱的所有箱中更高的等位基因频率的概率(或上述af血浆),并限制感兴趣变体具有等位基因频率低于优先箱集合中的检测限的概率。排除不包含任何具有感兴趣变体的片段的箱。即,对用于获得等位基因频率的箱进行优先评级并包含变体。
框m2中的数据以与m1相似的方式获得,不同的是,优先箱集合包括候选集合中的所有箱,即,包括包含具有感兴趣变体的片段的箱和不包含具有感兴趣变体的任何片段的箱。即,优先获得用于获得等位基因频率的箱。
框m3显示了包含短于150个碱基对的片段的箱的等位基因频率数据。
框m4显示了所有箱位的等位基因频率数据,没有优先级。该等位基因频率也称为血浆等位基因频率或原始等位基因频率。
如图7a所示,m1的等位基因频率(优先的且含有变体)高于m3和m4。同样,m2的等位基因频率(优先的)也高于m3和m4。差异具有统计学意义。图7a说明,在癌症处于早期且肿瘤分数非常低的情形a中,使用包含感兴趣变体的优先箱有助于提高用于检测感兴趣变体的信号水平。
上面在图7a中观察到的数据模式也出现在图7b-图7d中。因此,使用通过本文描述的方法获得的优先箱,可以提高在各种临床病症下检测肿瘤变体的信号水平,如在情形b中当肿瘤负荷高时,在具有治疗抗性突变的肿瘤转移状态中肿瘤等位基因频率低时(情形c),以及当肿瘤与具有相对较低的肿瘤等位基因频率和中等肿瘤分数的亚克隆突变相关时(情形d)。
使用两组优先箱集合不仅可以增加检测感兴趣变体的灵敏性,而且还可以潜在地增加或保持检测感兴趣变体的选择性。表2显示了用于分析四行cfdna数据的四种不同类型的箱的选择性值。选择性=真阴性/(真阴性+假阴性)。该表在三列(0.01、0.00.1和0.2)中显示了三种不同肿瘤分数的数据。跨越不同肿瘤分数,出现了四个非一致箱之间的一致数据模式。具体而言,使用所有分箱进行的分析具有99.7%的高选择性。当仅使用包含短于150bp片段的箱时,选择性水平降低至94.6%。使用优先箱以及优先且突变的箱进行分析的选择性仍为99.7%。对于更高的肿瘤分数(0.1和0.2),在四个不同的箱集合中相同的选择性模式保持不变。因此,从表2中的数据可以明显看出,使用优先箱可以保持变体检测的选择性。
实施例2
该实施例提供了从实际生物样品获得的经验数据,以说明使用上述公开的优先箱的方法可以增加用于检测感兴趣变体的信号水平。
图8显示了来自肿瘤细胞和正常细胞的cfdna的片段长度分布。暗灰色线条表示肿瘤细胞衍生的cfdna分布。中灰色线条显示了正常细胞衍生的包括基因fgfr3和letm1的cfdna分布。浅灰色线条显示了正常细胞衍生的含有其他基因的cfdna分布。肿瘤来源的cfdna片段分布也用灰色阴影填充。从图8中的三个分布可以明显看出,肿瘤来源的cfdna分布具有一个向较低端移动的主峰。
图9显示了分配给肿瘤来源的cfdna和正常来源的cfdna的具有5nt箱大小的箱的cfdna片段的频率。肿瘤来源的cfdna频率以深灰色条显示,而正常cfdna数据以浅灰色条显示。这两个分布是双峰的。癌症来源的分布在约150-175bp处有一个主要峰,在约315bp处有一个次要峰。正常细胞的分布在170bp处有一个主要峰,在约320bp处有一个次要峰。图9中的数据还表明,肿瘤来源的cfdna片段可以比正常cfdna片段短。
表3显示了三种类型的箱集合的肿瘤等位基因数量的倍数变化值,该倍数变化与使用所有箱获得的肿瘤等位基因数量有关。它们显示了32个包括简单核苷酸变体(snv)的真阳性突变。真阳性突变是从一项经验研究中得知的。使用包括突变片段的优先箱,在32个突变的31个中,倍数变化值大于1。使用所有优先箱集合(包括包含突变片段的箱和不包含突变片段的箱)获得的倍数变化值,在32个突变的28个中都大于1。对于使用包含短于150bp片段的箱的方法,可以检测到32个真实突变中的30个,其倍数变化水平大于1。表3的底行显示,没有突变的信号低于检测限。因此,表3中的数据显示,使用优先箱可以提高在生物样品中检测32个真阳性突变的信号水平。
图10显示了针对32个真阳性突变的倍数变化数据,其分为具有不同水平的原始等位基因频率的组。图10的水平轴表示生物学样品的突变的原始等位基因频率。图10的y轴表示倍数变化。深灰色条显示了使用包含突变的优先箱集合获得的倍数变化值。浅灰色的灰色条显示了使用优先箱集合获得的倍数变化值。中间的灰色条显示了使用包含短于150bp片段的箱获得的数据。图10中的数据表明,使用优先箱的方法倍数变化值大于1,除了原始等位基因频率为7.89%以外(如图中箭头所示)。
此外,当突变具有较低的等位基因频率时,如当等位基因频率低于1(如左侧虚线框所示),倍数变化值显得更大。
使用优先箱集合可有助于检测等位基因频率低于0.05%检测限的突变。表4显示了五行中5个突变的等位基因频率,当使用所有箱进行数据分析时,其等位基因频率均低于检测限(参见左第二栏)。使用包含感兴趣突变的优先箱,将突变mda_10134a:kras、mda10070a:kras和msk080:kras的等位基因频率提高至检测限以上(参见左第三栏)。对于使用优先箱集合中所有箱的方法,也获得了相似的结果(参见左第四栏)。相比之下,使用包含短于150bp的片段的箱的方法,不能挽救属于检测限以下的5个突变中任何一个(参见左第五栏)。这样,表4中的数据表明,使用优先箱分析cfdna片段可有助于检测等位基因频率低于检测限的肿瘤变体,从而有效地挽救原本会错过的突变检测。
- 还没有人留言评论。精彩留言会获得点赞!