测量装置和测量方法与流程
本发明涉及无创血糖水平测量技术。
背景技术:
近年来,糖尿病患者在世界范围内增加,并且不需要血液采样的无创血糖测量技术正变得越来越理想。在这点上,已经提出了各种方法,包括使用近红外或中红外区域中的辐射和拉曼光谱的技术。与使用近红外区域中的辐射的方法相比,使用与葡萄糖表现出强吸收的指纹区域相对应的中红外区域中的辐射的方法对于提高测量敏感度是有利的。
诸如量子级联激光器(qcl)的发光器件可以用作用于发射中红外区域中的光的光源。然而,在这种情况下,激光光源的数量由所使用的波数的数量确定。因此,为了实现设备小型化,用于测量血糖水平的中红外区域中的波数的数量优选地减少到不超过几个波数。
已经提出了一种通过使用与葡萄糖的吸收峰值相对应的波数(1035cm-1、1080cm-1、1110-1)的衰减全反射(atr)使用中红外区域中的辐射来精确地测量葡萄糖水平的方法(例如,参见专利文献1)。此外,已经提出了用于创建用于无创血糖测量的校准模型的方法(例如,参见专利文献2)。
引用列表
专利文献
[专利文献1]第5376439号日本专利
[专利文献2]第4672147号日本专利
技术实现要素:
技术问题
在开发无创血糖测量技术的实际应用中,对于各种条件和环境变化的测量鲁棒性和测量可靠性是特别重要的。然而,对于使用葡萄糖吸收峰值波数的测量技术,确保相对于其它代谢物的影响和测量条件的改变的鲁棒性一直是一个挑战。
本发明的一个方面涉及提供一种具有高测量可靠性和环境鲁棒性的无创血糖水平测量装置和测量方法。
解决问题的技术方案
根据本发明的一个方面,一种测量装置包括:光源,其被配置为输出中红外区域中的光;检测器,其被配置为利用从所述光源输出的所述光照射测量对象并检测由所述测量对象反射的反射光;以及血糖水平测量设备,其被配置为测量所述测量对象的血糖水平。葡萄糖的多个吸收峰值波数之间的波数被用作用于测量所述血糖水平的血糖水平测量波数。
发明的有益效果
根据本发明的一个方面,可以实现具有高测量可靠性和环境鲁棒性的血糖水平测量。
附图说明
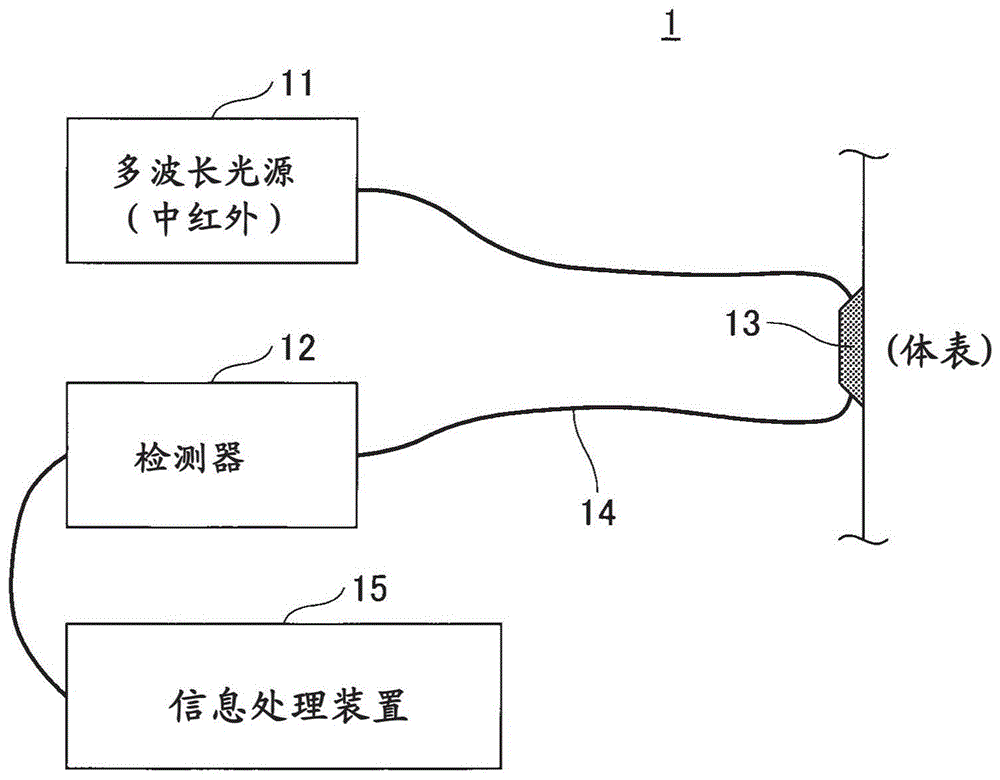
图1a是实现本发明的一个方面的测量装置的示意图。
图1b是在测量装置中使用的atr棱镜的示意图。
图2a是根据本发明的实施方式的测量装置的示意图。
图2b是在根据本发明的实施方式的测量装置中使用的atr棱镜的示意图。
图2c是在根据本发明的实施方式的测量装置中使用的中空光纤的示意图。
图3是指示在本发明的实施方式中使用的数据集的表。
图4是示出波数选择过程的流程图。
图5是表示紧接在测量之后和在经过固定时间段之后的血糖水平的示例性内插的图。
图6是示出在本发明的实施方式中使用的一般的留一法交叉验证和系列交叉验证之间的差异的对比图。
图7a是表示数据集1的吸收光谱的图。
图7b是表示数据集2的吸收光谱的图。
图8a是表示在系列交叉验证中延迟和波数数量的相关系数图的图。
图8b是表示在系列交叉验证中延迟和成分数量的相关系数图的图。
图9是表示根据波数和延迟而选择的波数的数量的直方图。
图10是表示根据针对所选波数和葡萄糖吸收峰值波数的时间延迟的相关系数的图。
图11a是多线性回归模型中的数据集1的克拉克误差网格。
图11b是pls模型中的数据集1的克拉克误差网格。
图12a是多线性回归模型中的数据集2的克拉克误差网格。
图12b是pls模型中的数据集2的克拉克误差网格。
图13是示出atr棱镜和测量表面之间存在空间的情况的示意图。
图14是当选择两个波数并且时间延迟为0分钟时的确定系数的映射。
图15是当选择两个波数并且时间延迟为10分钟时的确定系数的映射。
图16是当选择两个波数并且时间延迟为20分钟时的确定系数的映射。
图17是当选择两个波数并且时间延迟为30分钟时的确定系数的映射。
图18是当选择两个波数并且时间延迟为40分钟时的确定系数的映射。
图19是当选择两个波数并且在较宽波数范围上时间延迟为20分钟时的确定系数的映射。
图20是表示根据候选波数和时间延迟的组合的确定系数的变化的图。
图21是表示根据候选波数和时间延迟的组合的确定系数的变化的图。
图22是表示根据当从候选波数中选择两个波数时的时间延迟的回归系数的变化的图。
图23是表示根据当从候选波数中选择两个波数时的时间延迟的回归系数的变化的图。
图24是表示根据当从候选波数中选择两个波数时的时间延迟的回归系数的变化的图。
图25是示出糖酵解路径的一部分的图。
图26是表示葡萄糖水溶液和全血样本的红外atr吸收光谱的图。
图27是表示在本实施方式中选择的各物质和波数的吸收光谱的图。
图28是示出当选择两个波数时对各物质的敏感度的图。
图29是示出当选择两个波数时对各物质的敏感度的图。
图30是示出当选择两个波数时对各物质的敏感度的图。
图31是表示当根据波数位移来调整确定系数时所选择的波数的公差评估的图。
图32是表示当根据波数位移来调整确定系数时所选择的波数的公差评估的图。
图33是表示当根据波数位移来调整确定系数时所选择的波数的公差评估的图。
图34是表示当确定系数固定时所选波数的公差评估的图。
图35是表示当确定系数固定时所选波数的公差评估的图。
图36是表示当确定系数固定时所选波数的公差评估的图。
图37是示出血糖水平测量的异常检测的图。
图38是示出从本实施方式中使用的三个波数中排除一个波数时的血糖水平回归的确定系数的表。
图39是示出测量装置的变形示例的图。
图40是使用根据本发明的实施方式的测量装置执行无创校准的信息处理装置的功能框图。
图41是示出预测结果的学习和评价过程的流程图。
图42是示出在图41的过程中使用的训练数据和测试数据的图。
图43是在根据本发明的实施方式的校准器中使用的网络图。
图44是示出在图43的网络中实现的学习过程的流程图。
图45是示出模型学习过程中的各步骤的损失的变化的图。
图46a是表示没有域自适应的数据集2的代表性系列的数据分布的图。
图46b是表示具有域自适应的数据集2的代表性系列的数据分布的图。
图47a是用于在没有域自适应的情况下获取的预测模型的克拉克误差网格。
图47b是用于在具有域自适应的情况下获取的预测模型的克拉克误差网格。
图48是比较用于各种模型的克拉克误差网格的区域a中的相关系数和数据点的比率的表。
图49是示出噪声对数据集1的相关系数的影响的图。
图50是示出噪声对数据集2的相关系数的影响的图。
具体实施方式
在下文中,将参照附图描述本发明的实施方式。
为了实现具有高可靠性和鲁棒性的无创血糖测量,本发明的实施方式涉及以下方面:
(1)在中红外区域中找到少量适用于无创血糖测量的波数,以及
(2)构建能够适应广泛个体差异、测量环境差异等的稳健预测模型。
关于与波数选择有关的第一方面,中红外分光计是昂贵的并且需要冷却。因此,考虑到成本和器件配置,优选地使用诸如qcl的激光光源,并且要使用的波数的数量优选地减少到几个波数。在波数选择中,考虑葡萄糖以及能够同时测量的其它物质和体内代谢物质的吸光度来选择能够提高血糖水平测量精度的波数。
在本发明的实施方式中,代替使用通常使用的葡萄糖吸收峰值波数,使用葡萄糖吸收峰值波数以外的波数作为血糖水平测量波数。例如,可以使用葡萄糖的一个吸收峰值和另一个吸收峰值之间的波数。例如,假设k表示中红外区域中的波数,可以从1035cm-1<1080cm-1的波数范围和/或1080cm-1<k<1100cm-1的波数范围中选择一个或多个血糖水平测量波数。优选地,所使用的波数的数量小于或等于三。例如,除了使用一个或多个血糖水平测量波数之外,还可以使用除血糖水平测量波数之外的波数来估计测量的可靠性。
关于与建立具有高环境鲁棒性的预测模型有关的第二方面,许多可变因素影响无创血糖测量的准确性,例如膳食含量的差异、个体患者之间的身体差异以及测量时的环境变化。除非能够建立适应这些因素的稳健预测模型,否则无创血糖测量技术的实际应用可能是困难的。在本发明的实施方式中,代替使用通常用作预测模型的验证方法的留一法交叉验证(loocv),使用更严格的交叉验证,其中包括同时执行的一系列餐后测量的数据组不同时用于模型估计和精度验证(不同系列的数据组用于模型估计和精度验证)。在本发明的实施方式中使用的这种交叉验证在下文中被称为“系列交叉验证”。
通过基于实现系列交叉验证的预测模型来选择中红外区域中的波数,可以实现较少依赖于特定环境或特定数据的测量。如下所述,通过使用根据本发明的实施方式的预测模型,可以在中红外区域中使用三个波数或两个波数来执行测量,并且测量的精度可以与例如使用至少几十个波数来执行多波数测量的情况相当。此外,通过使用实现系列交叉验证的预测模型,可以获取相关性,而无需对例如在不同日期/时间、不同季节、不同对象、不同膳食和不同设备获取的数据执行校准。
此外,通过将在域适应中使用对抗性训练的神经网络(dann:域对抗性神经网络)应用于血糖测量,可以实现无需血液采样的校准。
<装置配置>
图1a是应用本发明的测量装置1的示意图。在图1a中,测量装置1包括多波长光源11、包括atr棱镜131的光学头13、检测器12和信息处理装置15。多波长光源11、光学头13和检测器12通过光纤14彼此连接。从多波长光源11发射的中红外光经由光纤14和光学头13照射到测量对象(例如,诸如皮肤、嘴唇等的体表)上。
如图1b中所示,光学头13的atr棱镜131被放置成与待测量的样本20接触。在atr棱镜131处,红外光经历与测量对象的红外吸收光谱相对应的衰减。衰减的光被检测器12接收,并且测量每个波数的强度。测量结果被输入到信息处理装置15。信息处理装置15分析测量数据并输出血糖水平和测量可靠性。
红外衰减全反射(atr)方法对于可以获取强葡萄糖吸收的中红外区域中的光谱检测是有效的。在红外atr方法中,红外光以高折射率入射在atr棱镜131上,并且使用当在棱镜和外部(例如,样本)之间的边界表面处发生全反射时发生的“穿透场”。如果在待测样本20与atr棱镜131接触的同时进行测量,则穿透场被样本20吸收。
当来自具有2-12μm的宽波长范围的红外灯的光用作入射光时,根据样本20的分子振动能量的相关波长的光被吸收,并且透射通过atr棱镜131的光的相关波长的光吸收表现为倾斜。在该方法中,透射通过atr棱镜131的检测光可能不会维持显著的能量损失,使得其在使用具有弱功率的灯光的红外光谱中特别有利。
当使用红外光时,从atr棱镜131到样本20的光的穿透深度仅为约几微米,使得光不到达存在于约几百微米的深度处的毛细管。然而,诸如血管中的血浆的成分作为组织液(间质液)泄漏到皮肤和粘膜细胞中。通过检测存在于这样的组织液中的葡萄糖成分,能够测量血糖水平。
假定间质液中葡萄糖成分的浓度在更靠近毛细管的深度处增加,因此,atr棱镜131在测量时总是以恒定的压力压靠样本。在这方面,在本发明的实施方式中,使用具有梯形横截面的多次反射atr棱镜。
图2a是根据本发明的实施方式的测量装置2的示意图。在图2a中,测量装置2包括傅里叶变换红外光谱(ftir)设备21、包括atr棱镜23的atr探针28、检测器22和信息处理装置25。从ftir设备21输出的红外光通过离轴抛物面镜27入射到中空光纤24上,并且在atr棱镜23处经历与样本20的红外光吸收光谱相对应的衰减。通过中空光纤24和透镜26的衰减光由检测器22检测。检测结果作为测量数据被输入到信息处理装置25。
信息处理装置25包括血糖水平测量设备251和可靠性估计设备252。血糖水平测量设备251使用如下所述的预测模型基于测量数据(红外光谱)测量血糖水平,并输出血糖水平测量结果。注意,血糖水平测量设备251是本发明的血糖水平测量设备的示例。可靠性估计设备252例如使用与用于血糖水平测量的波数不同的波数来计算测量可靠性,并且如下所述地输出计算出的测量可靠性。
测量装置2使用数个波数用于血糖测量,并且这些波数选自葡萄糖的一个吸收峰值和另一个吸收峰值之间的范围。例如,可以使用1050±6cm-1、1070±6cm-1和1100±6cm-1的波数的吸收光谱。
如图2b所示,atr棱镜23是梯形棱镜。葡萄糖检测敏感度可以通过atr棱镜23处的多次反射来增强。此外,atr棱镜23可以确保与样本20的相对大的接触面积,使得可以减小由于atr棱镜23压靠在样本20上的压力的变化而引起的检测值的波动。atr棱镜23的底面可以具有例如24mm的长度l。atr棱镜23被布置为相对薄以实现多次反射,并且例如,其厚度t可以被设为1.6mm、2.4mm等。
棱镜的潜在材料包括对人体无毒并且在与正被测量的葡萄糖的吸收带相对应的10μm波长附近表现出高透射特性的材料。在本实施方式中,使用由zns(硫化锌)制成的棱镜,该棱镜具有低折射率(折射率:2.2)和高穿透性以能够在更深的深度处进行检测。与通常用作红外材料的znse(硒化锌)不同,已知zns(硫化锌)不具有致癌性质,并且还作为无毒染料(立德粉)用于牙科材料。
在一般的atr测量装置中,棱镜固定在相当大的壳体中,使得待测量的区域通常限于诸如指尖或前臂的皮肤表面。然而,这些皮肤区域被厚度为约20μ的厚角质层覆盖,因此,检测到的葡萄糖成分浓度趋于低。此外,角质层的测量例如受到汗液和皮脂分泌的影响,使得测量再现性受到限制。在这方面,根据本实施方式的测量装置2使用能够以低损耗传输红外光的中空光纤24,以及具有附接到中空光纤24的末端的atr棱镜23的atr探针28。例如,通过使用atr探针28,可以在耳垂处进行测量,耳垂具有相对靠近皮肤表面定位的毛细血管并且不易受到汗液和皮脂的影响,或者在口腔粘膜处没有角质化层。
图2c是在测量装置2中使用的中空光纤24的示意图。用于葡萄糖测量的具有相对长波长的中红外光被玻璃吸收并且不能透射通过普通石英玻璃光纤。尽管已经开发了使用特殊材料的用于红外传输的各种类型的光纤,但是由于毒性、吸湿性、化学耐久性等问题,这些材料不适合用于医疗用途。另一方面,中空光纤24具有金属薄膜242和介电薄膜241,该金属薄膜242和介电薄膜241以上述顺序围绕由诸如玻璃或塑料的无害材料制成的管243的内表面布置。金属薄膜242由诸如银的具有低毒性的材料制成,并且涂覆有介电薄膜241以提供化学和机械耐久性。此外,中空光纤24具有由不吸收中红外光的空气形成的芯245,并且以这种方式,中空光纤24能够在宽波长范围内低损失地传输中红外光。
<演示实验>
使用图2的测量装置2,测量口腔粘膜的吸光度。如上所述,测量装置2使用中空光纤24作为传送路径,该中空光纤24能够以较小的毒性有效地将中红外光传播到嘴唇。使用布鲁克公司制造的“张量”和“顶点”作为ftir设备21。作为atr棱镜23,使用两种类型的棱镜,包括厚度(t)为1.6mm的棱镜1和厚度(t)为2.4mm的棱镜2。棱镜的底表面的长度l都是24mm。与棱镜2(t=2.4mm)相比,更薄的棱镜1(t=1.6mm)可以促进atr棱镜23内部更多的光反射,并且具有更高的敏感度。
为了测量血液中的血糖水平用作参考,使用市售的血糖水平自测量设备进行采血。使用泰尔茂株式会社生产的“medisafemini(注册商标)”和强生公司生产的“onetouchultraview(注册商标)”作为自测量设备。因为在这两个自测量设备之间对于相同血液样本指示的血糖水平存在偏差,所以通过线性表达式校正“medisafemini”的测量值以匹配“onetouchultraview”的测量值。
作为用于数据采集的基本测量方法,在餐后开始测量,并且间歇地继续测量直到餐后约3小时血糖水平稳定。在约3小时的测量期间,通过使用市售的测量设备的血液取样和根据本发明的实施方式的光学无创血糖水平测量来执行几次至几十次血糖水平测量,并且记录测量结果(血液中的血糖水平和光谱信息)。以下将在同一测量时刻采集的一系列数据称为“数据系列”。
图3是示出通过测量获取的数据集1和数据集2的特性的表。特征包括样本的数量(数据点)、对象的数量、数据系列的数量、摄取的物品、ftir设备21的类型、atr棱镜23的类型、自测量设备的类型和数据采集周期。
数据集1包含来自在五个月的时间段内对被要求在测量之前摄入各种膳食的健康成人进行的13个系列的测量的131个数据点。数据集2包含来自在15个月的时间段内对五个健康成人(不同于数据集1的对象)执行的18个系列测量的414个数据点,该五个健康成人被要求在测量之前摄入各种膳食或葡萄糖饮料。葡萄糖饮料含有溶解在150ml水中的75g葡萄糖。数据集2包括使用不同atr棱镜和不同ftir设备采集的数据。
使用数据集1和数据集2,搜索要在血糖水平测量中使用的中红外波数,并且构建预测模型用于验证。首先,使用对从单个对象获取的数据集1的系列交叉验证,提取相关波数,并构建预测模型。接下来,使用基于数据集1创建的模型,确定数据集2的数据的预测结果是否与血糖水平相关。数据集2的数据在其采集的季节、受试者、膳食和所使用的测量设备方面不同于数据集1的数据。因此,如果使用使用数据集1构建的预测模型发现与数据集2的相关性,则可以得出可以实现独立于各种条件的稳健血糖测量的结论。
pls(偏最小二乘法)回归、svm(支持向量机)、nn(神经网络)等已知为将测量的光谱数据回归到血糖水平的模型。在该实施方式中,作为血糖水平的回归模型,使用具有较少参数和较少过拟合的简单多元线性回归(mlr)模型,以避免由于过拟合引起的鲁棒性劣化。预测模型由等式(1)表示。在本实施方式中,使用简单多元线性回归(mlr)模型作为血糖水平回归模型。mlr具有少量参数,并且避免过度拟合可能导致鲁棒性劣化的特定条件或数据。预测模型由下面的等式(1)表示。
[数学式1]
y=ax(1)
在上述等式(1)中,y表示预测血糖浓度,x表示测量的吸光度光谱数据,并且a表示具有稀疏系数的回归模型。
为了获取预测模型而要解决的问题由下面的等式(2)表示。
[数学式2]
在上述等式(2)中,l表示要使用的波数的数量。模型优化问题是寻找在波数的数量有限时使最小二乘误差最小化的稀疏回归模型a。
在本实施方式中,假设波数l的数量在1到3的范围内,并且为了模型优化,针对l(波数的数量)的每个值搜索所有波数的组合,使得最小二乘误差相对于每个系列的系列交叉验证被最小化。注意,下面详细描述上述方法。此外,作为参考,将使用少量波数的mlr方法的结果与从使用大量波数的pls回归获取的结果进行比较,该pls回归通常用作血糖水平的光谱分析和回归模型。上面的比较也将在下面详细描述。
<波数选择过程>
图4是示出波数选择过程的流程图。首先,每2cm-1提取(内插)由ftir设备21获取的与存在葡萄糖的吸收光谱的980cm-1至1200cm-1的区域相对应的吸光度数据x的一部分,以生成光谱信息(步骤s11)。注意,在创建数据集1和2时,删除了可以从光谱数据感知到的明显异常测量的样本。
接着,调整葡萄糖测量数据的时间延迟(步骤s12)。组织液或细胞内代谢系统中的葡萄糖水平达到血管中的血糖水平值需要更多的时间。因此,通过将血糖水平的数据采集时间相对于相应谱的数据采集时间以2分钟为增量从0分钟延迟到40分钟来检查该延迟对回归精度的影响。具体地,将线性插值应用于在中红外光谱测量时测量的血糖水平,以获取各个时间的血糖水平。
假定餐后初始血糖测量时间设置为“0分钟”,则将低于“0分钟”的血糖水平内插到“0分钟”的血糖水平,因为禁食期间的血糖水平被认为是不变的。
图5示出了针对0分钟和5分钟的时间延迟的示例血糖水平插值结果。在图5中,十字标记(×)表示餐后通过自测量设备测量的血液中的血糖水平,实线表示线性内插的血糖水平,圆形标记(〇)表示时间延迟为“0分钟”的中红外光谱的血糖水平,方形标记表示时间延迟为“5分钟”的中红外光谱的血糖水平。对于每个数据点执行这种时间延迟设置。注意,对于数据集2,为了消除两种类型的atr棱镜23的反射次数的差异的影响,相对于与葡萄糖的吸收光谱的下降相对应的波数1000cm?1对光谱进行归一化。
返回参考图4,针对每个系列划分数据集以执行系列交叉验证(步骤s13)。在系列交叉验证中,一个数据系列被用作测试数据,而其余的数据系列被用作训练数据。每个系列包括在同一场合采集的多个数据点。
在通常的留一法交叉验证中,数据集中的一个点被用作测试数据,其余的点被用作用于预测模型生成的训练数据。使用训练数据创建预测模型,并验证测试数据的精度。因此,假设一个系列涉及一个受试者在吃了某一餐之后的血糖水平的变化,则训练数据和测试数据将包含同一系列内的数据。在膳食相同的情况下,很容易预测血糖水平。因此,即使通过使用相同系列的测量数据点作为训练数据的留一法交叉验证来获取所需精度,对于在不同条件(不同膳食)下采集的数据,例如在每个系列中摄入不同膳食的本实施方式的数据集,也不一定实现精度。此外,即使使用留一法交叉验证来选择具有高相关性的波数,该波数也未必适合于一般情况。
相反,系列交叉验证是一种方法,其中所有数据中仅一个系列被用作测试数据,并且所有其余的系列被用作训练数据。使用系列交叉验证的验证比使用留一法交叉验证的验证更严格,并且其产生更接近实际情况的结果。
图6是比较留一法交叉验证和系列交叉验证的原理的示意图。在图6中,在顶部示出了留一法交叉验证,在底部示出了系列交叉验证。点表示样本,并且其各种形状表示不同的系列。在留一法交叉验证中,仅一个数据点被用作测试数据,而在系列交叉验证中,包括在给定系列中的所有数据点被用作测试数据。如果在系列交叉验证中实现高精度,则对训练数据的过拟合将是不可能的,并且即使存在未知数据也将更有可能确保预测精度。然而,因为系列交叉验证比留一法交叉验证更严格,所以测试结果的相关值(例如相关系数)将可能更低。
返回参考图4,使用训练数据,搜索波数的所有组合以找到将使多元线性回归模型中的相关系数最大化的波数的组合,并且使用波数的组合创建回归模型(步骤s14)。使用所获取的回归模型,预测测试数据(步骤s15)。使用多元线性回归模型a的预测模型y由上述等式(1)表示。
对于每个数据系列重复步骤s13至s15。当预测了所有测试数据时,通过组合所有数据序列的预测结果来计算相关系数,并且执行精度评估(步骤s16)。
在该波长选择过程中,选择在系列交叉验证中提供良好验证结果的波数,使得可以获取能够适应各种测量条件和环境条件的稳健预测模型。此外,通过将波数的数量减少到小的数量,可以用最小量的数据进行预测,可以提高泛化性能,并且可以确保环境鲁棒性。
<实验结果>
图7a和图7b是分别指示在步骤s11中生成的数据集1和数据集2的吸收光谱数据的图。纵轴表示吸光度,横轴表示波数。注意,图7a和图7b中所示的光谱数据未归一化。图7a和图7b右侧的渐变条示出了当时间延迟为0分钟时(即,在饭后第一次测量时)的血糖水平。因为数据集1是使用相同设备针对相同受试者获取的测量数据,所以数据集1的光谱数据是一致的。因为数据集2包括在各种条件下获取的测量数据,所以数据集2的光谱数据具有比数据集1的光谱数据更大的变化。然而,数据集2的光谱数据在某些波数处显示峰值。注意,在数据集2的光谱数据中以波数1000cm-1出现倾斜,并且该波数用于数据集2的归一化。
图8a示出了当在步骤s14中实施系列交叉验证时,多元线性回归模型a中的特征的数量(波数的数量)和时间延迟的相关系数图。波数的数量是1到3。右侧的渐变条示出了相关系数。相关系数越大,渐变颜色越浅。如从图8a可以理解的,其中时间延迟是从20到30分钟并且波数的数量是2到3的区域具有较大相关系数。当时间延迟为26分钟并且波数的数量为3时,相关系数最大化。此时的相关系数为0.49。注意,在0分钟的时间延迟处不存在大的相关性表示血液中的血糖水平的变化需要一些时间来反映在红外光谱中。
图8b示出了当实施系列交叉验证时pls模型中的时间延迟和特征的数量(分量的数量)的相关系数图。在pls模型中,作为特征的数量,分量的数量被设置为从1到10的范围。可以理解,在分量的数量在4和7之间并且时间延迟为大约20分钟的区域中,相关系数变大。当分量的数量为6并且时间延迟为20分钟时,相关系数达到其最大值,并且此时的相关系数是0.51。注意,pls模型的一个分量包括所有输入波数的分量(从980cm-1至1200cm-1区域每2cm-1提取的吸光度数据)。也就是说,即使一个分量也包含几百波数的信息。
从上述结果可以理解,即使当所选择的波数的数量减少为三个波数时,也可以获取与在pls模型中选择大量波数的情况相当的相关性。在pls模型中,即使使用大量波数,也不能选择最小数量和最佳波数。在根据本实施方式的使用中红外光的血糖水平测量中,通过仅使用2至3个波数,可以获取与使用实质上更大数量的波数时相同的测量精度水平。
图9是示出在多元线性回归模型a中将波数的数量设置为l=3(即,选择三个波数)的情况下在每个数据系列中的不同时间延迟处选择每个波数(或波长)的次数的直方图。数据系列是用于系列交叉验证的每个系列的数据。可以理解,所选择的波数几乎没有变化,并且在时间延迟为20至30分钟的高相关性区域中,选择大约1050cm-1(±若干cm-1)、大约1070cm-1(±若干cm-1)和大约1100cm-1(±若干cm-1)。而且,所选择的波数根据时间延迟而变化,从而表明适合于血糖水平中红外光谱测量的波数相对于与体内代谢相关联的变化而变化。
注意1050cm-1(±若干cm-1)、1070cm-1(±若干cm-1)和1100cm-1(±若干cm-1)的波数在葡萄糖指纹区域中,但它们不对应于葡萄糖吸收峰值。当葡萄糖的吸收峰值简单地用于体内测量时,由于其他物质的干扰,可能难以获取与血糖水平的相关性。即,例如,很可能该测量代表身体中其它物质和葡萄糖代谢物的吸收。
图10示出了当所选择的波数为1050cm-1、1070cm-1和1100cm-1时,在系列交叉验证中相关系数相对于时间延迟的变化。当时间延迟为20至30分钟时,相关性大于或等于0.55,并且当时间延迟为26分钟时,相关性达到其最大值。
为了比较目的,图10中的虚线指示当所选波数为1036cm-1、1080cm-1和1110cm-1时与葡萄糖的吸收峰值相对应的相关系数相对于时间延迟的变化。注意,关于所选择的波数1036cm-1,尽管葡萄糖的吸收峰值实际上是1035cm-1,但是为了方便起见选择1036cm-1,这是因为每2cm-1分析吸光度数据(参见图4的步骤s11)。当使用葡萄糖的吸收峰值波数时,相关系数低于使用在本实施方式中选择的波数获取的相关系数。这可能是因为体内测量的吸收光谱与许多干扰物质的吸收光谱重叠。考虑到各种干扰物质的存在,与简单地关注葡萄糖的吸收并且使用葡萄糖的吸收峰值波数的情况相比,在本实施方式中选择的波数可以更适于体内测量。可以理解,在体内测量中,当使用葡萄糖的吸收峰值波数时,不能获取高相关性。
图11a至图12b表示图4的步骤s16的精度评价结果。图11a和图11b表示基于数据集1的预测模型的评价结果。图12a和图11b表示基于数据集2的预测模型的评价结果。图11a是克拉克误差网格,其组合了使用波数1050cm?1、1070cm?1和1100cm?1的多元线性回归模型的所有系列的系列交叉验证。横轴表示参考血糖水平,纵轴表示预测血糖水平。时间延迟被设置为26分钟,其对应于使相关系数最大化的时间延迟。区域a包含86.3%的样本,这表明获取了良好的精度。即,评价结果表明,仅使用三个波数就可以根据红外光谱准确地测量血糖水平。
图11b是将用于pls回归模型的所有系列的系列交叉验证组合的克拉克误差网格,该pls回归模型使用更大数量的波数作为比较。假设在pls回归模型中使用具有最高相关系数的六个分量,并且时间延迟为20分钟。与在多元线性回归模型中使用三个波数的情况一样,区域a包含86.3%的样本。
如从图11a和图11b中可以理解的,克拉克误差网格还表明,根据本实施方式的使用三个波数的多元线性回归方法可以实现与在使用更大数量的波数的pls方法中实现的测量精度相当的测量精度。
图12a示出了使用基于数据集1获取的多元线性回归模型预测的数据集2的精度评价结果。在数据集2中,相对于1000cm?1处的吸光度对光谱数据进行归一化,以消除所使用的两个棱镜之间的反射次数的差异的影响。与处理数据集2之后的方法类似,使用1050cm?1、1070cm?1和1100cm?1的波数,使用归一化为1000cm?1的数据集1的所有数据来创建预测模型。所获取的预测模型可以由下面的等式(3)表示。
[数学式3]
在上述等式(3)中,y表示预测血糖水平,x(k)表示在波数k处测量的吸光度。在图12a中,三波数多元线性回归模型的相关系数为0.36,100%的数据在区域a和区域b内。
图12b是使用基于使用pls回归作为比较的数据集1获取的预测模型预测的数据集2的克拉克误差网格。pls模型的相关系数为0.25,并且98.8%的数据在区域a和区域b内。从上文可以理解,与pls回归模型相比,根据本实施方式的三波数多元线性回归模型可以获取更高的相关系数。在三波长多元线性回归模型的评价结果中,不存在相关性的零假设的p值为3.7x10-14,表明存在强相关性。
尽管数据集1和数据集2的条件在许多方面不同,但是可以在不进行校准的情况下获取数据集2的相关性。这表明根据本实施方式的三波数多元线性回归模型能够通过独立于诸如受试者的个体差异和环境因素的条件的回归来提取适合于预测血糖水平的特征。与利用使用更多波数的pls模型所获取的相关性相比,利用三波数多元线性回归模型对数据集2所获取的相关性更高的事实可以归因于由于减少波数的数量而导致的估计模型的改进的泛化性能。注意,可以通过对每个受试者执行校准来进一步提高精度。
以上实验结果证明,在本实施方式中选择了用于无创血糖测量的适当波数,并且所选择的波数和预测模型对于血糖测量具有高鲁棒性。
<光学系统模型>
下面,将分析atr棱镜的光学系统模型。通过atr棱镜测量吸收强度a。吸收强度a由下面的等式(4)定义。
[数学式4]
在上述等式(4)中,i表示包括样本的atr棱镜的透射光强度,i0表示atr背景噪声强度。
<无空间时的反射>
首先,将分析当atr棱镜和介质之间没有空间时光对介质(例如口腔粘膜)的影响。在下面的描述中,假设n1表示atr棱镜的折射率,n2表示介质的折射率。入射到atr棱镜上的光被全反射在介质的表面上。
假设用于单次反射的模型dp表示全反射中倏逝波的穿透深度。使用波长x和折射率n1和n2,模型dp可以由下面的等式(5)表示。
[数学式5]
使用模型dp,吸收强度a可以由下面的等式(6)表示。
[数学式6]
注意,作为上述等式(6)中的测量值所期望的值是每个样本膜厚的吸收系数α。
常数项“a”由下面的等式(7)定义。
[数学式7]
吸收强度a可以由下面的等式(8)表示。
[数学式8]
假设n表示atr棱镜中发生的反射次数,并且考虑到吸收强度a是对数的事实,多次反射的吸收强度am可以由下面的等式(9)表示。
[数学式9]
<存在空间时的反射>
接下来,将预期在atr棱镜和介质之间存在空间的情况下的反射。实际上,在atr棱镜和口腔粘膜之间存在空气空间或由诸如唾液的液体形成的空间形式的空间,并且该空间的状态可以在每次进行测量时改变,从而构成外部干扰。因此,预期当atr棱镜和介质之间存在空间时的多重反射模型。
图13是示出atr棱镜和测量表面(例如口腔粘膜)之间存在空间的情况的示意图。下面,假设n0表示atr棱镜的折射率,m表示空间的折射率,n2表示介质的折射率,z表示空间宽度,x表示反射位置。在atr棱镜和介质之间存在空间的情况下的多重反射模型可以由以下等式(10)表示。
[数学式10]
衰减项“c”由下面的等式(11)定义。
[数学式11]
基于上述等式(9),考虑到衰减项“c”为负(c<0)的事实,在atr棱镜和介质之间存在空间的情况下的吸收强度amz可以由以下等式(12)表示。
[数学式12]
注意,因为“ckzn”可以近似为零(0),所以“exp”内的项的maclaurin系列将如下。
[数学式13]
exp(x)≈1+x
因此,吸收强度amz可以由下面的等式(13)表示。
[数学式14]
空间宽度“zt”的总值由以下等式定义。
[数学式15]
在这种情况下,吸收强度amz可以由下面的等式(14)表示。
[数学式16]
空间的影响在项(n+ckzt)中,并且测量的光谱由此以波数k的线性方程的形式相乘。
注意,期望作为测量值的值是介质的每个膜厚的吸收系数α。基于上面的等式(14),α可以由下面的等式(15)表示。
[数学式17]
注意,空间的影响由构成上述等式(15)的分母的项(n+ckzt)表示。
<空间影响修正>
假设上述等式(15)中的吸收系数α是恒定的,即,测量目标是恒定的,如果可以校正项(n+ckzt)的变化,则吸收强度amz也可以是恒定的。因此,在吸收系数α不波动的波长带中计算线性方程(n+ckzt),并且由此如以上等式(15)所示划分吸收强度amz的测量值。此外,为了消除吸收系数α不波动的区域,将吸收强度amz除以代表性样本光谱amz'。因为当总空间宽度zt接近0(zt?0)时,代表性样本光谱对应于样本,所以可以使用具有最高吸光度的样本。基于上面的等式(14),可以如下获取校正项(n+ckzt)。
[数学式18]
注意,从棱镜设计中已知nref,因此,通过将线性方程拟合到波数k来获取校正项(n+ckzt)。
更简单地,如果波数k的范围是小范围,则k可以被视为常数,并且(n+ckzt)可以被视为与波数k无关的常数。在这种情况下,测量的吸收光谱可以简单地关于吸收系数α不波动的波数(即,表现出几乎不吸收葡萄糖的波长等)归一化。
<双波数回归模型确定图的系数>
图14至图18是用于使用多元线性回归模型的回归的确定系数的图,所述多元线性回归模型使用两个选定波数(两个波数回归模型),其中波数的数量被设置为l=2,以从980cm-1至1200cm-1的波数范围中选择两个波数,并且时间延迟从0分钟改变为40分钟。确定系数(也称为r平方)由相关系数的平方表示,并且是表示预测精度的指标。在本实施方式中,使用多元线性回归模型来执行使用所有数据的回归,而没有交叉验证。注意,在图14至图18中所示的图表中,在右上半部中表示确定系数,并且在左下半部中插入0(零),因为结果将与右上半部相同。此外,注意,在每个图表中,具有最大确定系数的区域由方形标记(□)指示。
图14是时间延迟为0分钟时的确定系数的图。可以理解,当时间延迟为0分钟时的图包括波数1200cm-1附近的具有较大确定系数的小区域。图15是时间延迟为10分钟时的确定系数的图。可以理解,当时间延迟为10分钟时的图包括波数1050cm-1附近的具有较大确定系数的区域。图16至图18分别是当时间延迟为20分钟、30分钟和40分钟时的确定系数的图。当时间延迟为20分钟时(图16)和当时间延迟为30分钟时(图17),可观察到较高的相关性。当时间延迟为20分钟时,确定系数大致在1050cm-1和1070cm-1的波数附近达到其最大值。另外,在波数1070cm-1和1100cm-1周围以及波数1030cm-1和1070cm-1周围观察到峰值。当时间延迟为30分钟时,在图中观察到类似的趋势。
图19是在相同预测条件下以20分钟的时间延迟在较宽波数范围(850cm-1至1800cm-1)上观察的确定系数的图。即使当波数范围变宽时,可以理解,当选择两个波数时,高相关部分集中在存在葡萄糖吸收光谱的从980cm-1至1200cm-1的波数范围中。
<波数组合>
当使用激光器作为光源时,所使用的波数的数量的增加导致所使用的激光器的数量的增加。因此,可以选择的波数不太多。即,为了减小测量设备的尺寸和降低成本,希望将所使用的波数的数量减少到较小的数量。在上述结果的基础上,优选了1050±6cm-1、1070±6cm-1和1100±6cm-1的波数。注意,与通过血液采样测量的血液中的血糖水平具有高相关性的光谱测量数据对应于在通过血液采样测量血液中的血糖水平之后20至30分钟获取的光谱测量数据。换句话说,由红外光谱测量数据指示的血糖水平反映了比实际光谱测量时间早20至30分钟的血液中的血糖水平。
图20和图21是表示确定系数的变化的图,该变化取决于通过由系列交叉验证执行系数验证而获取的候选波数的不同组合的时间延迟。在图20中,对于三波数模型选择波数1050cm-1、1072cm-1和1098cm-1,对于二波数模型选择波数1050cm-1和1072cm-1。在图21中,对于三波数模型选择波数1072cm-1、1098cm-1和1050cm-1,对于二波数模型选择波数1072cm-1和1098cm-1。
关于图20的波数组合,当时间延迟在20分钟至30分钟的范围内时,三波数模型的确定系数大于或等于0.3,而当时间延迟在20分钟至30分钟的范围内时,二波数模型的确定系数大于或等于0.25。关于图21的波数组合,如在图20的情况下,当时间延迟在从20分钟到30分钟的范围内时,三波数模型的确定系数大于或等于0.3。当时间延迟在23至33分钟的范围内时,用于双波数模型的确定系数最高,但是上述时间延迟范围与用于三波数模型的时间延迟范围大部分重叠。
图22至图24是指示根据当从候选波数中选择某些波数时的时间延迟的回归系数的变化的图。回归系数是由上述等式(3)表示的预测模型的每一项的系数。乘以每个波数的回归系数根据时间延迟而改变。常数项是常数。在图22中,使用了波数1072cm-1和1098cm-1。在图23中,使用了波数1050cm-1和1072cm-1。在图24中,使用了三个波数,包括1050cm-1、1072cm-1和1098cm-1。在图22至图24中,如等式(3)的预测模型所示,1072cm-1的回归系数在正值范围内变化,1050cm-1和1098cm-1的回归系数在负值范围内变化。
在图22至图24中,当执行系列交叉验证时,将回归系数的值与表示每个系列的结果的标准偏差的误差条一起示出。可以理解,即使当时间延迟改变时,标准偏差也是基本恒定的,从而指示稳定地获取回归系数。通过使用根据本实施方式的预测模型,可以实现高度可靠的回归。
<体内葡萄糖测量>
图25是示出糖酵解路径的一部分的示意图。葡萄糖-6-磷酸(g6p)和果糖-6-磷酸(f6p)是糖酵解路径中最早的中间代谢物。葡萄糖-1-磷酸(g1p)是储存在细胞中的糖原的降解物质。如下所述,这些物质在与葡萄糖的吸收光谱相同的波数区域中也具有吸收光谱,并且这些物质的存在很可能影响被测量的吸收光谱。
因为葡萄糖代谢涉及活体内部,所以与测量葡萄糖水溶液或全血中的葡萄糖相比,体内葡萄糖测量是困难的。因为葡萄糖水溶液的吸收光谱没有干扰物质,所以可以容易地在葡萄糖的吸收峰值波数处测量葡萄糖水平。在全血的情况下,光谱可以显示其他物质的吸收,但是物质本身没有经历太多变化,并且血糖水平测量是可能的。
图26显示葡萄糖水溶液的红外atr吸收光谱(表示为“gluaq.”)和餐前和餐后全血样本的吸收差光谱(表示为“ablood”)。在全血的吸收差光谱中,在900cm-1至1200cm-1波数区域中可以观察到与葡萄糖吸收类似的吸收。
图27示出了葡萄糖在10wt%下的吸收光谱以及代谢物物质(g1p、g6p和糖原)的吸收光谱。注意,在图27中,在本实施方式中选择的波数1050cm-1、1072cm-1、1098cm-1由垂直线指示。在这三个波长中,1098cm-1对应于g1p的峰值波长,但是其他两个选择的波长不与代谢物物质的任何峰值重叠。
在葡萄糖的一个吸收峰值和另一个吸收峰值之间的波数范围内,例如1035cm-1和1110cm-1之间的波数范围,或1080cm-1和1110cm-1之间的波数范围内,葡萄糖和其它代谢物物质的吸收光谱之间的差异显著。因此,通过使用葡萄糖的一个吸收峰值和另一个吸收峰值之间的波数范围,可以仅分离和提取葡萄糖的吸收光谱。
图28至图30是示出当选择某些波数时对每种物质的敏感度的图。另外,敏感度由等式(3)的预测模型的回归系数和各物质的吸收光谱求出。图28示出了在选择波数1072cm-1和1098cm-的情况下的敏感度。图29示出了在选择波数1050cm-1和1072cm-1的情况下的敏感度。图30示出了在选择波数1050cm-1、1072cm-1和1098cm-1的情况下的敏感度。
在图28中,两个波数的回归系数都是负值,因此,葡萄糖的敏感度被指示为正值。在图29和图30中,包括负回归系数和正回归系数,因此,葡萄糖的敏感度被指示为负值。
图28和图30中使用的波数1098cm-1对应于g1p的峰值波长,并且g1p在某种程度上与红外光测量光谱相关的可能性很高。此外,图28和图30中对g6p的敏感度也很高,因此,也可以检测到g6p。
<选定波数公差评估>
图31至图36是示出所选择的波数的公差评估的图。图31至图33示出了每当波数发生位移时调整预测模型的回归系数(例如,参见等式(3))时的公差评估。图34至图36示出了当预测模型的回归系数固定时的公差评估。时间延迟被设置为对应于当确定系数被优化时的26分钟,并且通过在一个波数发生位移而剩余的两个波数固定时确定该确定系数来执行评估。波数在±10cm-1的范围内以2cm-1的增量发生位移。
图31至图33示出了当应用交叉系列验证时,即,当每次波数发生位移时调整预测模型的回归系数时,确定系数响应于给定波数位移量而减小的程度。关于示出1050cm-1波段确定系数的图31,通过将波数设置为1050±6cm-1,确定系数可以大于或等于0.25,通过将波数设置为1050±2cm-1,确定系数可以大于或等于0.3。
关于示出1070cm-1波段确定系数的图32,通过将波数设置为1070±6cm-1,确定系数可以大于或等于0.2,通过将波数设置为1070±4cm-1,确定系数可以大于或等于0.25。此外,通过将波数设置为1071±2cm-1,确定系数可以大于或等于0.3。
关于示出1100cm-1波段确定系数的图33,可以理解,1100cm-1波段与其它两个波数相比具有更大的公差。具体地,当波数在1100±4cm-1的范围内时,确定系数可以大于或等于0.3,并且即使当波数在1100±6cm-1的范围内时,确定系数也可以保持在0.29或更高。注意,在图33中,在波数1098cm-1处,确定系数未被优化。这可归因于图33的数据的最佳波数与作为系列交叉验证的结果从所选波数光谱的模式值导出的波数之间的微小差异。然而,2cm-1的误差是基本上不影响确定系数的变化的可接受范围。
基于上述结果并考虑到测量设备的配置,每个选定波数的公差范围优选设置为±6cm-1。另外,通过适当地将公差范围设置为±4cm-1或±2cm-1,可以进一步提高测量精度。
图34至图36示出了当预测模型的回归系数固定时与图31至图33相同的选定波数的公差评估。例如,回归系数可以被设置为系列交叉验证的每个折叠的平均值。在该评估中,使用以下等式作为预测模型(回归方程)。
[数学式19]
y=-1160·x(1050cm-1)+1970·x(1072cm-1)
-978·x(1098cm-1)+218
根据上式,1050cm-1的回归系数为-1160,1072cm-1的回归系数为1970,1098cm-1的回归系数为-978。在将回归系数固定到上述值的情况下,一个波数发生位移并且对确定系数进行评估。
关于示出1050cm-1波段确定系数的图34,波数偏差(公差范围)优选限制在±4cm-1,以保持1050cm-1波段确定系数大于或等于0.3。关于示出1070cm-1波段确定系数的图35,波数偏差优选限制在±2cm-1,以保持1070cm-1波段确定系数大于或等于0.3。关于示出1100cm-1波段确定系数的图36,波数偏差优选限制在±2cm-1,以保持1100cm-1波段确定系数大于或等于0.35。
<可靠性输出>
图37是示出血糖水平测量的异常检测的图。当信息处理装置25的可靠性估计设备252输出测量的可靠性时,使用异常检测。当输出可靠性时,可靠性估计设备252例如基于多层神经网络的堆叠式自动编码器(sae)的重构误差量来计算lof(局部离群因子)。图37的图示出了当使用包括1150cm-1和1048cm-1的两个波数进行测量时的lof输出。注意,尽管1048cm-1对应于本实施方式中使用的血糖水平测量波数,但是1150cm-1不对应于本实施方式中使用的任何血糖水平测量波数。
在图37中,实线表示正常光谱数据,虚线表示异常数据。正常光谱数据具有相似的光谱形状并且集中在某些区域中。异常数据具有基本上向上和向下偏离的特征值。异常光谱与正常光谱有明显的区别,可以分离。通过使用血糖水平测量波数以外的波数来进行可靠性计算,可以准确地检测光谱异常,并且可以提高可靠性输出的精度。通过计算可靠性,例如,当由于测量样本和棱镜之间的不充分接触而发生测量失败时,可以要求诸如重新进行测量的适当措施,从而提高测量精度。
注意,在使可靠性估计设备252确定测量数据是否对应于异常数据时,例如可以定义每个受试者的正常数据并将其用于学习。以这种方式,可以考虑个体差异来计算和输出可靠性。
此外,在使用血糖水平测量波数以外的波数来进行可靠性计算的情况下,可能必须增加测量装置中使用的激光光源的数量。考虑到上述情况,例如,三个波数中的两个波数可以用作血糖水平测量波数,并且一个波数可以用作用于可靠性计算的波长。可选地,例如,两个波数中的一个可以用作血糖水平测量波数,并且两个波数中的另一个可以用作用于可靠性计算的波数。
基于逻辑回归分析,可以选择1098cm-1和1150cm-1两个波数作为最适合于区分异常数据和正常数据的两个波数。在这种情况下,异常数据和正常数据之间的区分精度为81.8%。虽然波数1098cm-1可以用作血糖水平测量波数,但是其也可以用作用于可靠性计算的波数。例如,波数1048cm-1和1072cm-1中的至少一个可以用于血糖水平测量,并且波数1098cm-1可以用于可靠性计算。波数1150cm-1可以专门用作用于可靠性计算的波数。注意,当例如1048cm-1和1150cm-1的波数的另一组合用于异常检测时,在异常数据和正常数据之间进行区分的精度为77.2%。
如上所述,即使当波数的数量减少时,通过使用与用于血糖水平测量的波数不同的波数来计算可靠性,也可以提高可靠性估计设备252输出的可靠性的精度。
图38是示出排除了使用的三个波数中的一个波数的情况下的血糖水平回归的确定系数的表。在本示例中,使用1150cm-1作为波数1,1048cm-1作为波数2,1098cm-1作为波数3。当排除波数1时,确定系数为0.4。当排除波数2时,确定系数为0.33。当排除波数3时,确定系数为0.47。可以理解,即使当从血糖测量中排除波数1或波数3时,也可以保持相对高的确定系数。因此,即使当这些波数用于可靠性计算(排除在血糖测量之外)时,排除对表示血糖水平预测精度的确定系数的影响也可以相对较小。另一方面,当排除波数2时,确定系数减小到0.33,指示相关性减弱。
从上文可以理解,波数1将专门用于可靠性计算,波数2将专门用于血糖水平测量,并且波数3可以既用于可靠性计算又用于血糖水平测量。
图38中所示的结果可以如下表示。
当通过组合血糖水平测量波数的数据组和用于可靠性估计的波数的数据组来预测(回归)血糖水平时,假设a表示排除与血糖水平测量波数的数据组中包括的一个波数相关的数据时的预测精度,并且b表示排除与用于可靠性估计的波数的数据组中包括的一个波数相关的数据时的预测精度,以下关系成立:(b的任何值)≧(a的最大值)。
即,排除与可靠性估计的波数相关的数据时的预测精度总是大于或等于排除与血糖测量波数相关的数据时的最大预测精度。注意,例如,如图38所示的用于回归的确定系数可以用作预测精度。根据本实施方式的一个方面,通过使用三个波数,可以准确地输出血糖水平和可靠性(正常数据/异常数据确定)。
<修改示例>
图39是示出根据修改示例的测量装置3的配置的示意图。测量装置3包括第一激光光源31-1、第二激光光源31-2、第三激光光源31-3、atr棱镜33、第一检测器32-1、第二检测器32-2、第三检测器32-3和信息处理装置35。测量装置3还包括二向色棱镜41至44以及准直透镜36和37。
从激光光源31-1至31-3输出的红外区域中的光束被二向色棱镜41和42组合成单个光路,并且通过准直透镜36会聚在中空光纤341上。通过中空光纤341传播的红外光根据与atr棱镜33接触的样本或体表(口腔粘膜)的红外光吸收光谱在atr棱镜33处经历衰减。承载样本的血糖水平信息的反射光从中空光纤342入射到准直透镜37上。atr棱镜33和中空光纤341和342构成atr探针38。反射光由准直透镜36会聚到二向色棱镜43上,并且由第一检测器32-1检测第一波数的光。透射通过二向色棱镜43的光中包括的第二波数的光被二向色棱镜44反射,并通过第二检测器32-2检测。透射通过二向色棱镜44的光由第三检测器32-3检测。第一检测器32-1、第二检测器32-2和第三检测器32-3的检测结果被输入到信息处理装置35。信息处理装置35的血糖水平测量设备351基于使用利用血糖水平测量波数获取的测量数据的预测模型来确定血糖水平,并且输出所确定的血糖水平。信息处理装置35的可靠性估计设备352使用利用用于可靠性估计的波数获取的数据来估计测量可靠性,并且输出所估计的可靠性。
在测量装置3中使用的三个波数中,选择与葡萄糖吸收峰值之间的波数相对应的两个波数作为血糖测量波数,并且使用与血糖水平测量波数不同的一个波数作为用于可靠性估计的波数。测量装置3可以在不受受试者之间的个体差异和环境条件变化的影响的情况下执行测量,并且可以精确地计算存在代谢物和其它物质的活体中的血糖水平。测量装置3还可以精确地计算和输出测量可靠性。
注意,本发明的实施方式不限于血糖水平测量。测量目标不限于葡萄糖,根据本发明的上述实施方式的诸如波数(波长)选择和确定的技术概念也可以应用于活体中诸如蛋白质、癌细胞等的其它成分的测量。
在图39的修改示例中使用的复用元件/解复用元件不限于二向色棱镜。例如,也可以使用利用半透半反镜或衍射的分光元件。光源不限于激光光源,例如,可以使用发射宽波长范围的光的光源和分光器的组合。在使用激光光源的情况下,代替如上所述组合多个激光输出,在一些实施方式中,例如,可以按时间系列切换多个激光光源的发光时间。在这种情况下,可以进一步减少激光光源的数量,并且例如,测量装置可以具有用于接收光的一个检测器。
图39中的激光光源的数量不限于三个,例如,可以使用输出1048±6cm-1的光的第一激光光源和输出1098cm-1的光的第二激光光源来照射两个波数的光以确定血糖水平。或者,1048cm-1的光可以用于血糖测量,1098cm-1的光可以用于可靠性估计,使得可以估计测量的可靠性。
此外,注意,用于使数据集归一化以生成预测模型的波数不限于1000cm-1,并且可以是除血糖测量波数之外的中红外区域中的一些其他波数。例如,小于或等于1035cm-1的波数或大于或等于1110cm-1的波数可用于归一化。
<校准应用dann>
在下文中,将描述校准。通常,在无创血糖测量技术中,针对每个个体或以周期性间隔执行校准,以便确保对于包括个体差异的各种条件的鲁棒性,或者使通过血液采样测量的血液中的血糖水平与通过无创血糖测量获取的测量数据之间的相关性最大化。在这种校准过程中,为了获取训练数据,必须通过血液采样来测量血液中的血糖水平。
换句话说,为了执行精确测量,最终需要有创血糖测量。注意,专利文献2的上述技术也不能解决为了校准目的而需要血液采样的问题。
此外,在使用根据本实施方式的测量装置的用户之间存在个体差异,并且为了使无创地获取的测量数据与每个用户的实际血糖水平之间的相关性最大化,优选地在用户站点处自动执行校准。传统上,需要血液采样来测量用户血液中的血糖水平,并将测量结果用作训练数据。然而,在本实施方式中,使用测量的光谱数据而不是使用用户的血液中的血糖水平作为训练数据来执行校准。
图40是示出在根据本实施方式的测量装置中执行无创校准的信息处理装置45的功能配置的框图。信息处理装置45包括:测量数据输入单元451,其输入使用中红外光获取的测量光谱数据;存储器452,其存储预先收集的训练数据453;以及校准器455,其使用测量数据和训练数据453来校准血糖水平测量。校准器455使用作为神经网络执行对抗性学习的dann(域咨询神经网络)来生成预测模型,并基于该预测模型输出血糖水平。该预测模型具有域自适应(da)功能。
测量数据是使用从除葡萄糖的吸收峰值之外的中红外区域中选择的特定波数(或波长)在诸如内唇的粘膜处光学地测量的光谱数据。在测量数据的校准中,不需要血糖水平的标记,并且不需要血液采样。因为用于基于光谱数据的血糖水平的回归(预测)的预测模型具有域自适应(da)函数,所以可以通过在没有标签的情况下学习来执行校准。
域自适应是迁移学习的一种形式,涉及将某一任务中的学习结果应用于其他任务。当训练数据(也称为“学习数据”)和用于评估的测试数据具有不同的分布时,使用具有示教标签的训练数据来精确地预测具有与训练数据不同的分布的测试数据。
校准器455使用输入的测量光谱数据作为用于评估的测试数据,并且还将测量光谱数据合并在从存储器452检索的训练数据453中以用作训练数据。
在下文中,将描述使用图3所示的相同数据集1和数据集2来评估根据本实施方式的校准器455的处理功能。
数据集1是包括在不同场合从单个受试者获取的数据的数据集,数据集2是包括在多个场合从五个受试者(不同于数据集1的受试者)获取的数据的数据集。
图41是示出与回归结果的预处理、学习和评估相关的校准器455的处理流程的流程图。
首先,将1050cm-1、1070cm-1和1100cm-1波数用作血糖水平回归的工作波数,将各个波数处的吸光度数据相对于1000cm-1处的吸光度归一化,并且将归一化的数据用作特征值(步骤s21)。
因为间质液和细胞内代谢系统中的葡萄糖水平达到血管中的葡萄糖水平需要一些时间,所以调节测量数据的延迟时间以反映上述延迟(步骤s22)。在本实施方式中,如上所述,测量数据延迟20至30分钟,优选26分钟(即,测量数据被视为表示从26分钟之前开始的血液中的血糖水平的数据)。注意,步骤s21和s22对应于预处理过程步骤。
使用经过预处理的数据集1和数据集2来训练dann模型。具体地,数据集1被用作具有血糖水平标签的训练数据,并且数据集2的每个数据系列被用作未标记的测试数据以训练dann模型(步骤s23)。然后,使用所获取的模型来预测测试数据(步骤s24)。注意,步骤s23和s24对应于学习过程步骤。重复步骤s23和s24,直到完成所有数据系列的学习。
当关于所有数据系列的学习完成时,通过组合所有测试数据的结果来评估精度(步骤s25)。通过对每个数据系列实施系列交叉验证来对数据集2的所有数据执行精度评估。注意,步骤s23对应于评估过程步骤。
在步骤s23和s24的学习过程中,为了实现域自适应(da),与测试数据相对应的数据集2的数据也被用作没有血糖水平标签的训练数据。
图42示出了训练数据和测试数据的处理。用于评估的测试数据对应于数据集2的一个系列的数据(无监督数据)。另一方面,训练数据包括数据集1的所有系列的数据(监督数据)和数据集2的一个系列的数据(非监督数据)。
注意,图42中数据点形状的差异代表数据系列的差异。为了训练(或学习),使用包括具有血糖水平标签的数据的数据集1的所有系列的数据和包括未标记数据的数据集2的一个系列的数据。为了评估,使用用于训练的数据集2的相同的一个系列的数据。对数据集2的所有系列的数据重复上述过程,以评估预测精度。注意,即使在训练期间使用时,数据集2的数据也未标记有血糖水平教导数据。这样,虽然数据集2的相同系列的数据被用于训练和评估,但是在训练时没有给出血糖水平的真实值。
图43示出了在校准器455中使用的网络的配置。1050cm-1、1070cm-1和1100cm-1处的吸光度被输入到网络中。该网络包括回归网络和分类网络。在图43中,lx表示回归网络的每一层,lcx表示分类网络的每一层。回归网络在层l3处分支以连接到分类网络。wx和wcx分别表示相应层网络的权重。
使用负区域中的梯度为ai=0.2的漏整流线性单元(relu)作为激活函数。使用欧几里德损失作为回归的损失函数,使用软最大交叉熵(softmaxcrossentropy)作为分类的损失函数。此外,对每个层使用批处理归一化。adam(自适应矩估计)被用作优化方法。
如下所述,因为分类网络更新权重wc3至wc5以区分或识别数据集1和数据集2,所以分类网络也可以被称为“鉴别器”。
回归网络更新预测模型的学习,使得无法基于分类网络(鉴别器)的学习结果来区分数据集1和数据集2。
图44是示出使用图43的网络的学习过程的流程图。通过更新图44的步骤s32和s33中的权重,可以在将层l1至层l3中的数据集1和数据集2的分布重叠的同时执行具有高精度的回归。
首先,在步骤s31中,将输入数据集1的吸光度数据用作训练数据,以训练用于执行血糖水平回归的网络。此时,使用回归结果的欧几里德损失来更新层l1至层l4的权重w1至w4。
然后,在步骤s32中,除了数据集1之外,将没有数据集2的标记数据的一个系列的吸光度数据添加作为输入数据,以训练用于在数据集1的数据和数据集2的数据之间进行区分的网络。在分类网络或鉴别器中执行训练(学习)。数据集2的一个系列的数据被用作对抗数据。对抗数据是作为故意噪声少量添加到训练数据的数据,以导致输出与原始训练数据的预测显著不同的预测。用于通过训练网络输出与原始训练数据的预测类似的对抗数据的预测来提高预测模型的性能的技术被称为对抗学习。
与步骤s32同时,在步骤s33中,对回归网络的权重w1和w2进行更新,使得不能区分数据集1和数据集2。以这种方式,在层l3的输出处提取能够使血糖水平回归并且不能区分数据集1和数据集2的特征值。结果,在校正数据集1的分布与已经输入的数据集2的一个系列的数据的偏差的同时训练用于估计血糖水平的网络。
图44的处理流程中的学习方法和参数如下。在前1800个时期期间,网络的学习涉及使用数据集1的监督数据仅执行步骤s31,以学习权重w1至w4。
此后,除了步骤s31之外,同时执行步骤s32和s33,以使用除了数据集1之外的数据集2的非监督数据来促进学习。在步骤s33中,为了平衡回归性能和域自适应,仅执行其中步骤s31的回归损失值小于320的迭代过程,并且步骤s33的损失值乘以350,以便实现与步骤s31和s32的损失的平衡。在学习完成之前总共运行2600个时期(epoch)。
图45是表示数据集2的代表性系列中模型的学习过程的每个步骤的损失的变化的图。实线表示相对于图44的步骤s31的损失,长短虚线表示相对于步骤s32的损失,虚线表示相对于步骤s33的损失。可以理解,随着学习的进行,每个步骤的损失减小。
图46a和图46b是示出具有和不具有域自适应(da)的数据集2的代表性系列的数据分布的图。图46a表示输入到层l1(无da)的输入数据的分布。图46b表示来自层l3(具有da)的输出数据的分布。精细点表示数据集1的数据点(监督数据),圆形标记表示数据集2的数据点(非监督数据)。
图46a和图46b都是通过使用主成分分析将三维数据缩减为二维来绘制的。在如图46a所示的输入阶段,数据集1的分布和数据集2的分布基本上不同。然而,在表示来自层l3的输出数据的图46b中,数据集1和数据集2的分布彼此显著重叠。从这些发现可以理解,根据本实施方式的网络可以吸收数据集1和数据集2之间的差异。
图47a和图47b是示出了使用和不使用域自适应(da)获取的预测模型的预测精度的克拉克误差网格。图47a是当da未被实现时数据集2的克拉克误差网格,并且表示通过仅执行图44中的步骤s31从数据集1的数据获取的预测模型的预测精度。图47b是当实施da时数据集2的克拉克误差图,并且表示通过执行图44的步骤s31至s33获取的预测模型的预测精度。
对于不利用da获取的预测模型,相关系数为0.38,53.6%的数据点包含在图47a的区域a中。对于利用da获取的预测模型,相关系数为0.47,63.8%的数据点在图47b的区域a+b中。从以上比较可以理解,通过使用根据本实施方式的校准器455,可以实现更高的相关系数,并且可以减少误差。即,通过实现域自适应,可以在不需要血液采样的情况下适当地校准预测模型。此外,所使用的测试数据包括饮食、受试者、测量温度等方面的各种情况的数据,并且可以相对于这种未指定的数据找到相关性的事实表明可以实现高概括性能和稳健测量。
图48是比较使用校准器455和各种其它模型的dann的相关系数和包括在克拉克误差网格的区域a中的数据点的比率的表格。注意,图48的表格反映了图11a至图12b中获取的针对mlr(多元线性回归)模型和pls(偏最小二乘)的结果。图48还指示不实现域自适应和对抗更新的神经网络(nn)的结果。
注意,上述四个模型都共享不执行通过血液采样的校准的共同条件。在除了dann之外的模型中,不针对每个系列的五个受试者数据集(数据集2)执行校准。因为pls模型具有波数选择功能,所以假定其输入为(从980cm-1至1200cm-1每2cm-1测量的)宽光谱吸光度数据。pls以外的模型的输入波数为1050cm-1、1070cm-1和1100cm-1。
已经表明,通常用于光谱分析的pls在没有校准的情况下不能给出可接受的结果。这被认为是由于输入光谱的波数的数量大于数据的数量的事实,使得性能由于过拟合的影响而劣化。由于nn模型能处理非线性分量,因此比mlr模型更精确。在所测试的技术中,dann显示出最好的结果。
通过使用根据本实施方式的校准器455,用于校准的血液采样变得不必要,并且可以减少与执行校准相关联的障碍。可以在测量时在用户站点处自动执行校准,并且可以提高测量精度。例如,即使当将根据本实施方式的测量装置应用于简单的家用监视装置时,也可以显著提高测量精度。根据本发明的实施方式的测量装置和校准方法不限于应用于血糖水平测量,而是可以应用于通常需要针对涉及诸如血液采样的有创过程的每个个体进行校准的其他各种测量。
<光源噪声对预测模型的影响>
在下文中,将考虑光源噪声对预测模型的影响。例如,当如图39所示使用多个激光器作为光源时,优选地考虑光源噪声的影响。
选择性用于无创血糖水平测量的波数可包括1050±6cm-1、1070±6cm-1和1100±6cm-1中的至少一种。例如,可以使用1050cm-1、1070cm-1和1100cm-1的波数。注意,尽管在上述实施方式中选择性地使用除了要用于测量的波数之外的波数作为归一化波数,但是在其他实施方式中,可以将要用于测量的波长之一用于归一化。
作为预测模型,使用利用包括1050cm-1、1070cm-1和1100cm-1的三个波数的线性回归模型(模型1),以及使用上述波数之一用于归一化的归一化线性回归模型(模型2)。在本示例中,波数1050cm-1被用作归一化线性回归模型中的归一化波长。然而,可以将上述三个波数中的任何一个设置为归一化线性回归模型的分母(归一化的波数),而不会在结果中产生显著差异。
在使用量子级联激光器(qcl)作为光源的情况下,考虑到由于qcl制造方面的波数偏差,预期使用具有1092cm-1的实际输出的qcl作为上述所选波数1100cm-1的光源。即,在下面的描述中,预期使用包括1050cm-1、1070cm-1和1092cm-1的三个波数的预测模型。
模型1(线性回归模型)可以由以下等式(16)表示。
[数学式20]
y=-1253·x(1050cm-1)+2159·x(1070cm-1)-1029.x(1092cm-1)+198(16)
模型2(归一化线性回归模型)可以由以下等式(17)表示。
[数学式21]
在上述等式(16)和(17)中,x(λ)表示波长λ处的吸光度,y表示血液中血糖水平的预测值。在模型1和模型2中,学习图3的数据集1的所有数据以获取预测模型的回归系数。
作为噪声模型,可以预期两种类型的噪声,包括被称为“wd噪声”的波长相关噪声(或波数相关噪声)和被称为“winoise”的波长无关噪声(或波数无关噪声)。噪声模型可以由下面的等式(18)表示。
[数学式22]
xn(λ)=nwi·nwd(λ)·x(λ)(18)
在上述等式(18)中,x(λ)表示在波长λ处测量的吸光度,并且xn(λ)表示添加了噪声的吸光度。nwi表示波长无关噪声(winoise)的量,并且nwd(λ)表示波长相关噪声(wdnoise)的量。波长相关噪声表示由于功率波动、波长波动、每个波长(波数)的qcl的偏振波动引起的噪声以及由于伴随的传输线和atr模式波动引起的噪声。另一方面,波长无关噪声表示由于被认为与波长无关的因素(例如atr光学元件和待测样本之间的接触状态的变化)引起的噪声。
上述噪声项由以下模型定义。
[数学式23]
nwi=n(1,noisewi2)
nwd(λ)=n(1,noisewd2)
注意,上述模型的n(1,noisewi2)和n(1,noisewd2)分别表示具有噪声wi和噪声wd的平均值1和标准偏差的正态分布。
作为评价方法,生成正态分布的随机数,并且通过计算等式(18)来模拟添加有噪声的输入信号。使用输入信号,通过蒙特卡洛模拟获取使用每个模型的预测结果的相关系数,并且将每个条件下的相关系数视为性能评价值。每个条件的迭代次数是10次,并且平均值被认为模拟结果。
关于波长无关噪声(winoise)和波长相关噪声(wdnoise)中的每一个以及关于模型1和模型2中的每一个执行模拟。此外,关于每种类型的噪声以及关于数据集1和数据集2中的每一个执行模拟。然而,关于数据集1,因为数据集1也用于参数学习,所以其可以用作参考值。
图49示出了数据集1的模拟结果,图50示出了数据集2的模拟结果。在图49和图50中,横轴表示噪声,纵轴表示相关系数。关于波长无关噪声(winoise),因为模型2被归一化,所以模型2对于波长无关噪声的量不敏感。而且,从图50的数据集2的模拟结果可以理解,与模型1相比,模型2在泛化性能方面显示出更好的结果。即,通过使用利用所使用的波数(波长)中的一个波数(波长)归一化的预测模型2,可以增强未知数据的性能。此外,即使当使用非归一化模型1时,与波长相关噪声(wdnoise)的敏感度相比,波长无关噪声(winoise)的敏感度高至少一个数量级。即,当光源噪声被布置为波长无关噪声(winoise)时,可以提高测量精度。
注意,因为数据集1和数据集2都已经由于个体波动、相对于ftir的测量时间波动等而具有各种类型的噪声(包括wdnoise和winoise),所以图49和图50的图左侧的相关系数已经饱和。因此,在模拟中添加的噪声占主导的图中的区域,即,在相关系数减小的图的右侧的区域,构成关于噪声量的精度的有效预测结果。
至于波长无关噪声(winoise)的量,图50中示出的数据集2的模拟结果表明,为了使相关系数r大于0.3(r>0.3),允许的变化量按标准差约为0.5%。尽管图49所示的数据集1的模拟结果对应于用作学习数据的参考值,但结果表明,为了获取大于0.5的相关系数r(r>0.5),必须按标准偏差将变化量控制为大约0.2%。
基于以上模拟,用于实现大于0.3的相关系数r(r>0.3)的波长无关噪声的容许变化量以标准偏差计约为0.5%。为了获取大于0.5的相关系数r(r>0.5),优选通过标准偏差将变化量控制为大约0.2%。对于预测模型,考虑到其泛化性能和对波长无关噪声的不敏感性,优选使用归一化线性回归模型而不是一般线性回归模型。
尽管已经关于说明性实施方式描述了本发明,但是本发明不限于这些实施方式,并且可以在不脱离本发明的范围的情况下进行许多变化和修改。
本申请基于并要求于2017年8月23日提交的第2017-160481号日本专利申请和于2018年5月23日提交的第2018-099150号日本专利申请的优先权日期的权益,其全部内容通过引用结合于此。
- 还没有人留言评论。精彩留言会获得点赞!