一种残基接触辅助策略自适应的蛋白质结构预测方法与流程
本发明涉及生物信息学、计算机应用领域,尤其涉及的是一种残基接触辅助策略自适应的蛋白质结构预测方法。
背景技术:
蛋白质分子在生物细胞化学反应过程中起着至关重要的作用。它们的结构模型和生物活性状态对我们理解和治愈多种疾病有重要的意义。蛋白质只有折叠成特定的三维结构才能产生其特有的生物学功能。因此,要了解蛋白质的功能,就必须获得其三维空间结构。
测定蛋白质三维结构的实验方法主要包括x射线晶体衍射和多维核磁共振(nmr)。x射线晶体衍射是目前测定蛋白质结构最有效的方法,所达到的精度是其它方法所不能比拟的,主要缺点是蛋白质晶体难以培养且晶体结构测定的周期较长;nmr方法可以直接测定蛋白质在溶液中的构象,但是对样品的需要量大、纯度要求高,目前只能测定小分子蛋白质。实验测定结构方法存在的主要问题在于两个方面:一方面,对于现代药物设计的主要靶标—膜蛋白而言,极难获得其结构;另外,实验测定过程费时费钱费力,代价不菲,比如,使用nmr方法测定一个蛋白质结构通常需要15万美元以及半年的时间。所以蛋白质三级结构预测是生物信息学的一个重要任务。
目前,蛋白质结构预测方法大致可以分为两类,基于模板的方法和从头预测方法。其中,从头预测方法直接基于蛋白质物理或知识能量模型,利用优化算法在构象空间搜索全局最低能量构象解。构象空间优化(或称采样)方法是目前制约蛋白质结构从头预测精度最关键的因素之一。优化算法应用于从头预测采样过程必须首先解决以下三个方面的问题:(1)能量模型的复杂性。蛋白质能量模型考虑分子体系成键作用以及范德华力、静电、氢键、疏水等非成键作用,致使其形成的能量曲面极其粗糙,局部极小解数量随着序列长度的增加呈指数增长;能量模型的漏斗特性也必然会产生局部高能量障碍,导致算法极易陷入局部解。(2)能量模型高维特性。就目前而言,从头预测方法只能应对尺寸较小(<150残基)的目标蛋白,一般不超过100。对尺寸超过150残基以上的目标蛋白,现有优化方法均无能为力。这也就进一步说明了随着尺寸规模的增加,必然造成维数灾问题,完成如此浩瀚的构象搜索过程所涉及的计算量是目前最先进的计算机也难以承受的。(3)能量模型的不精确性。对于蛋白质这类复杂的生物大分子,除了考虑各种物理成键和知识推理的作用之外,还要考虑它与周围溶剂分子的相互作用,目前还无法给出精确的物理描述。考虑到计算代价问题,近十年来研究者陆续提出了一些列基于物理的力场简化模型(amber,charmm等)、基于知识的力场简化模型(rosetta,quark等)。然而,我们还远远无法构建起能引导目标序列朝正确方向折叠的足够精确力场,导致数学上的最优解并不一定对应于目标蛋白的天然态结构;此外,模型的不精确性也必然会导致无法对算法性能进行客观地分析,从而阻碍了高性能算法在蛋白质结构从头预测领域中的应用。
随着氨基酸序列的增长,蛋白质分子体系自由度也增大,利用传统群体算法采样获得大规模蛋白质构象空间的全局最优解成为一项挑战性的工作;其次,粗粒度模型虽然减小了构象搜索空间,但是也导致了相互作用力之间的信息丢失,从而直接影响预测精度。
因此,现有的蛋白质结构预测方法采样效率和预测精度方面存在不足,需要改进。
技术实现要素:
为了克服现有的蛋白质结构预测方法对蛋白质构象空间采样效率低、预测精度较低的不足,本发明在基本差分进化算法框架下,引入自适应变异策略来指导构象空间搜索,同时结合残基接触信息作为辅助评价指标选择构象,提出一种采样效率高、预测精度高的残基接触辅助策略自适应的蛋白质结构预测方法。
本发明解决其技术问题所采用的技术方案是:
一种残基接触辅助策略自适应的蛋白质结构预测方法,所述预测方法包括以下步骤:
1)给定目标蛋白的序列信息;
2)根据目标蛋白序列从robetta服务器(http://www.robetta.org/)上得到片段库文件,其中包括3片段库文件和9片段库文件;
3)根据目标蛋白序列,利用raptorx-contact服务器(http://raptorx.uchicago.edu/contactmap/)预测得到目标蛋白的残基-残基接触置信度,记为csi,j,其中,i≠j,i和j均属于{1,2,3,4…,rsd},csi,j表示raptorx-contact服务器得到的第i个残基和第j个残基接触的置信度,rsd为氨基酸序列长度;
4)设置参数:种群大小np,算法的最大迭代代数g,交叉因子cr,温度因子β,学习周期lp,第一种变异策略被选择的概率
5)种群初始化:随机片段组装生成np个初始构象ci,i={1,2,…,np};
6)对种群中的每个个体ci进行如下操作:
6.1)将ci设为目标个体
6.2)若
6.3)若
6.4)若
6.5)若
6.6)对cmutant进行一次片段组装生成新构象cmutant′;
6.7)生成随机数pcr,其中pcr∈(0,1),若pcr<cr,则从
6.8)如果
其中,score3为rosetta能量函数,i和j是预测残基接触信息中第n对残基对应的残基号,di,j为构象c中残基i和j的之间的cα原子距离,ci(c)表示构象c的残基接触总能量,ctn为预测的残基-残基接触信息中残基对的数量,cin为根据公式(1)计算得到构象c中第n对残基i和j的残基接触能量;
如果
7)当g>lp时,根据公式(3)更新变异策略选择的概率
8)g=g+1,迭代运行步骤6)~8),至g>g为止;
9)输出构象score3能量与残基接触能量之和最低的构象为最终结果。
本发明的技术构思为:在进化算法框架下,首先,建立四种不同的自适应变异策略,算法前期四种变异策略都等概率被选择,当算法经历一段学习周期后,算法采取自适应的变异策略对构象进行变异,并且对生成的变异构象进行一次片段组装,生成变异构象;其次对变异构象进行交叉操作;最后用rosetta能量函数score3、残基接触能量ci、蒙特卡洛玻尔兹曼接收准则对构象进行选择,结合残基接触信息的自适应变异策略蛋白质结构预测方法不仅可以增强种群的多样性,而且能够缓解能量函数不精确的问题,提高采样效率。
本发明的有益效果为:根据自适应变异策略选用不同的变异策略指导构象变异,不仅能够提高种群的多样性,而且符合种群进化的规律,增强进化算法全局探索和局部增强的能力,提高收敛速度;使用残基接触信息辅助能量函数对构象选择,缓解了能量函数不精确导致的预测误差的问题,进而提高预测精度。
附图说明
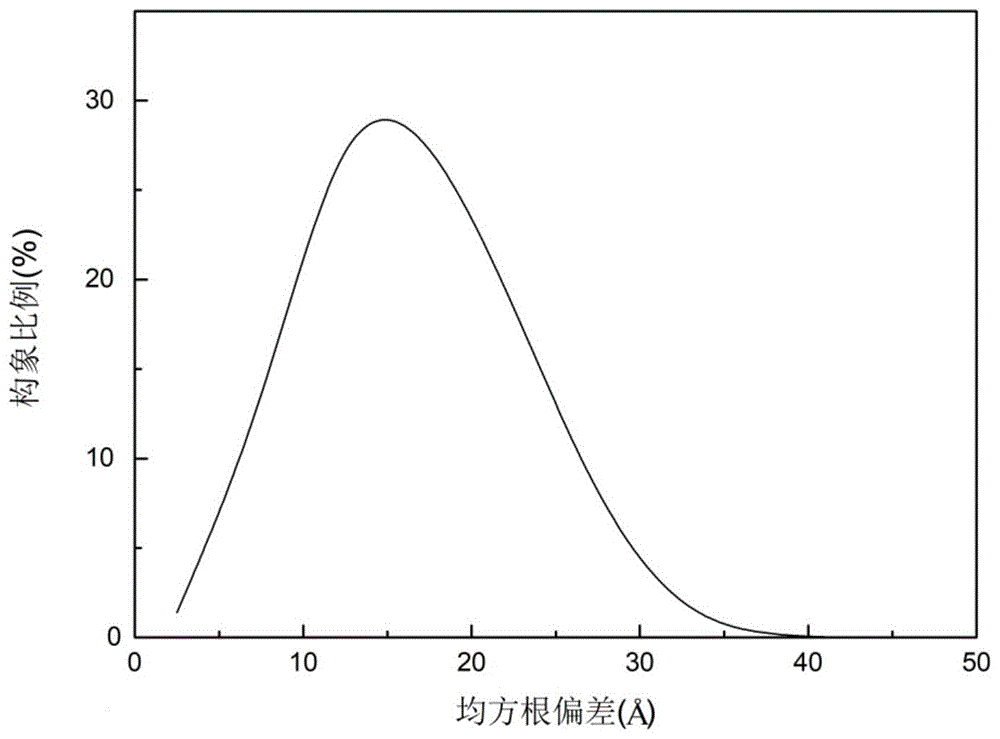
图1是一种残基接触辅助策略自适应的蛋白质结构预测方法对蛋白质256b采样得到的构象分布图。
图2是一种残基接触辅助策略自适应的蛋白质结构预测方法对蛋白质256b采样时的构象更新示意图。
图3是一种残基接触辅助策略自适应的蛋白质结构预测方法对蛋白质256b结构预测得到的三维结构。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图3,一种残基接触辅助策略自适应的蛋白质结构预测方法,所述预测方法包括以下步骤:
1)给定目标蛋白的序列信息;
2)根据目标蛋白序列从robetta服务器(http://www.robetta.org/)上得到片段库文件,其中包括3片段库文件和9片段库文件;
3)根据目标蛋白序列,利用raptorx-contact服务器(http://raptorx.uchicago.edu/contactmap/)预测得到目标蛋白的残基-残基接触置信度,记为csi,j,其中,i≠j,i和j均属于{1,2,3,4…,rsd},csi,j表示raptorx-contact服务器得到的第i个残基和第j个残基接触的置信度,rsd为氨基酸序列长度;
4)设置参数:种群大小np,算法的最大迭代代数g,交叉因子cr,温度因子β,学习周期lp,第一种变异策略被选择的概率
5)种群初始化:随机片段组装生成np个初始构象ci,i={1,2,…,np};
6)对种群中的每个个体ci进行如下操作:
6.1)将ci设为目标个体
6.2)若
6.3)若
6.4)若
6.5)若
6.6)对cmutant进行一次片段组装生成新构象cmutant′;
6.7)生成随机数pcr,其中pcr∈(0,1),若pcr<cr,则从
6.8)如果
其中,score3为rosetta能量函数,i和j是预测残基接触信息中第n对残基对应的残基号,di,j为构象c中残基i和j的之间的cα原子距离,ci(c)表示构象c的残基接触总能量,ctn为预测的残基-残基接触信息中残基对的数量,cin为根据公式(1)计算得到构象c中第n对残基i和j的残基接触能量;
如果
7)当g>lp时,根据公式(3)更新变异策略选择的概率
8)g=g+1,迭代运行步骤6)~8),至g>g为止;
9)输出构象score3能量与残基接触能量之和最低的构象为最终结果。
本实施例以序列长度为106的α蛋白256b为实例,一种残基接触辅助策略自适应的蛋白质结构预测方法,包括以下步骤:
1)给定目标蛋白的序列信息;
2)根据目标蛋白序列从robetta服务器(http://www.robetta.org/)上得到片段库文件,其中包括3片段库文件和9片段库文件;
3)根据目标蛋白序列,利用raptorx-contact服务器(http://raptorx.uchicago.edu/contactmap/)预测得到目标蛋白的残基-残基接触置信度,记为csi,j,其中,i≠j,i和j均属于{1,2,3,4…,rsd},csi,j表示raptorx-contact服务器得到的第i个残基和第j个残基接触的置信度,rsd为氨基酸序列长度;
4)设置参数:种群大小np=200,算法的最大迭代代数g=3000,交叉因子cr=0.5,温度因子β=2,学习周期lp=1000,第一种变异策略被选择的概率
5)种群初始化:随机片段组装生成np个初始构象ci,i={1,2,…,np};
6)对种群中的每个个体ci进行如下操作:
6.1)将ci设为目标个体
6.2)若
6.3)若
6.4)若
6.5)若
6.6)对cmutant进行一次片段组装生成新构象cmutant′;
6.7)生成随机数pcr,其中pcr∈(0,1),若pcr<cr,则从
6.8)如果
其中,score3为rosetta能量函数,i和j是预测残基接触信息中第n对残基对应的残基号,di,j为构象c中残基i和j的之间的cα原子距离,ci(c)表示构象c的残基接触总能量,ctn为预测的残基-残基接触信息中残基对的数量,cin为根据公式(1)计算得到构象c中第n对残基i和j的残基接触能量;
如果
7)当g>lp时,根据公式(5)更新变异策略选择的概率
8)g=g+1,迭代运行步骤6)~8),至g>g为止;
9)输出构象score3能量与残基接触能量之和最低的构象为最终结果。
以序列长度为106的α蛋白256b为实施例,运用以上方法得到了该蛋白质的近天然态构象,运行3000代所得到的结构与天然态结构之间的平均均方根偏差为
以上阐述的是本发明给出的一个实例展现出来的结果,显然本发明不仅适合上述实施例,在不偏离本发明基本精神及不超出本发明实质内容所涉及内容的前提下可对其做种种变化加以实施。
- 还没有人留言评论。精彩留言会获得点赞!