基于主题模型技术的中医智能辨证辅助决策方法与流程
本发明涉及一种中医辅助决策方法,具体地说,涉及一种基于主题模型技术的中医智能辨证辅助决策方法。
背景技术:
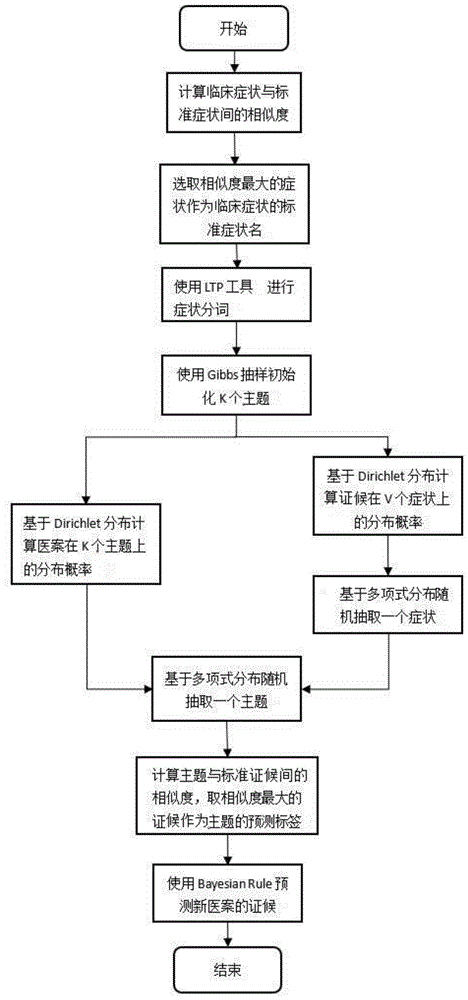
:“辨证论治”是传统中医的主要特点,即将望、闻、问、切(四诊)收集的症状,依四诊合参原则,加以分析和总结,确定疾病的病理、病性、病位和邪正关系,从而确定疾病的证型,并选择相应的治疗。中医辨证是中医诊断疾病的理论核心,也是中医诊断学的难题。传统中医的辨证模式是医生主要利用感官观察和患者对病感的主观描述获取患者的症状和体征信息,这种获取机体功能状态特征信息的方法,难以做出准确的定量描述,缺乏具体的量化方法,如有汗、汗出、微汗、少汗、大汗、汗出不止、大汗淋漓等对汗出状况的描述不够具体、精确,具有模糊性,且这种差异性的描述具有经验性的成分;中医信息的处理、整合由医生根据个人的知识和经验完成,诊断准确性在一定程度上也取决于医生的个人经验、诊断技巧、认识水平和思维能力,主观性较强,其辨证过程更是一个“黑箱理论”,难以诠释。为了解决这些问题,出现了一大批基于数据挖掘技术的中医辨证辅助决策方法,其中最新的研究运用数据挖掘技术从中医和西医两个角度分析中医证候,根据混合智能系统理论设计中医辨证过程的整体框架,以慢性乙型肝炎为例构建混合智能中医辨证模型,该模型首先利用基于多视图的混合属性选择算法获取与证候相关的症状,然后利用tf-idf算法计算症状的权重,最后利用混合辨证模型判断新样本的主证和次证,并成功获得了180例新样本的主证和次证。同时使用apriori算法对丁氏外科临床医案数据建模并对其进行关联规则分析,根据支持度和置信度构建网络结构图,用线条的粗细表示病种与六纲要素之间的关系,并结合频数统计法研究其辨证规律,实验结果表明在丁氏医案中对病种疽的辨治最为集中,约为20.31%。其主要缺陷在于:首先,在使用混合智能模型进行中医辨证时,所使用的慢性乙型肝炎数据集中包含的属性种类繁多且性质不同,虽然可以使用多视图的混合属性选择算法进行属性选择,但是它不能全面的获取与证候密切相关的关键属性。并且在中医领域常使用属性整体出现的频率来计算该属性的重要程度,但没有考虑在证候间分布的信息,导致辨证结果与真实结果相差甚大,辨证准确度较低。其次,参与辨证的客观指标不足,最新的一些数据挖掘方法只利用症状进行辨证,没有考虑病因、病位、舌象和脉象等指标,导致直接使用关联规则方法很难构建精确的诊断模型,并且一些症状存在“多词一义”和“一词多义”的现象,即对这些症状没有进行规范化处理,从而导致生成的辨证结果不够全面,准确度低等结果。技术实现要素:有鉴于此,本发明针对目前大多数中医智能辨证方法存在的辨证准确度低的问题,提供了一种基于主题模型技术的中医智能辨证辅助决策方法,能够解决“理-法-方-药”的辨证问题,提高辨证准确度。为了解决上述技术问题,本发明公开了一种基于主题模型技术的中医智能辨证辅助决策方法,具体包括:步骤1,对医案集中的症状名称进行规范化处理;步骤2,预处理医案数据集:使用语言技术平台(ltp)工具对每份医案进行分词处理;步骤3,生成医案主题模型,得到隐含在医案集中的所有主题;步骤4,基于《中医内科学》构建标准证候数据库,并通过计算主题下的症状群与标准证候之间的相似度来获得主题的标签,即证候名称;步骤5,基于步骤3、4挖掘得到的症候群进行证候预测。进一步地,步骤1中对医案集中的症状名称进行规范化处理,具体为:从医案集中随机选择一种症状,在给定的标准症状数据库的条件下,分别计算该症状与四君子标准tcm(中医)数据集中所有症状之间的相似度,寻找最大相似度对应的症状,并作为该症状的标准症状名称,计算公式如下:sim(s,s′)=jwd(s,s′)=jd(s,s′)+prefixlength·(1.0-jd(s,s′))(1)其中,s表示患者的临床症状名称,s′表示四君子标准tcm数据集的标准症状名称,n表示临床症状名称s和标准症状名称s′之间的匹配字符数,t为匹配字符的数量,|s|与|s′|分别是s和s′中的字符数,jd(s,s′)为字符串s与s′的匹配度,prefixlength为字符前缀长度。进一步地,步骤3中基于医案数据集生成医案主题模型,得到隐含在医案集中的所有主题,具体为:使用基于隐狄利克雷分布(lda)的主题模型方法挖掘隐藏在医案集中的所有主题,该主题是由相关症状构成的集合,每种症状均有对应的概率值,并根据概率值取前15种症状来表示主题,具体步骤如下所示:1)使用吉布斯采样(gibbs)方法模拟生成k个“证候”;2)根据超参数β获得症状分布即其中,表示第i种症状在第k个证候中的所占权重,v为症状数,nk,w表示症状w在证候k中的出现次数。3)根据超参数α获得第m个医案的证候分布θm=(θm1,θm2,…,θmk),即θm~dir(α);其中,θmk表示第k个证候在医案m中的所占权重,nm,k表示证候k在医案m中的出现次数。其中,α、β为狄利克雷(dirichlet)先验分布的参数。4)根据多项式分布mult(θm)生成证候zi,即zi~mult(θm);其中,表示在医案m中证候zi出现的概率。5)根据多项式分布分别生成症状wv,即取中权重大于0的症状构成证候zk,返回步骤4),直到遍历完第m个医案中的所有词;其中,为在证候k中症状i出现的概率。6)返回步骤2),直到生成整个医案训练集(所有的证候组成)。进一步地,1)使用gibbs方法模拟生成k个“证候”,具体为:初始化:随机给每个词分配主题编号;给第m个医案的词wi分配主题编号,取最大概率值对应的主题,计算公式如下:其中,k∈[1,2,…,k],为症状a在证候k中出现的次数,为证候k的词在第m个医案中出现的次数,v为医案集中出现的症状数,z-i为除证候i以外的所有证候的集合;使用公式(9)进行迭代更新,直至包含于主题中的症状保持不变,迭代收敛。进一步地,步骤4基于《中医内科学》构建标准证候数据库,并通过计算主题下的症状群zi与标准证候yj之间的相似度来获得主题的标签,即证候名称y,进一步地,步骤5,基于步骤3、4挖掘得到的症候群进行证候预测,具体如下:通过使用贝叶斯规则推断一个新医案的证候标签集,设定一个概率阈值t,取大于该阈值的证候标签为新医案的证候,公式如下:p(k|m)>t(12)其中,当t为1e-7经验值时,预测效果到达最佳,表示在证候k下症状si出现的概率,p(k|m)表示医案m的证候为k的概率。与现有技术相比,本发明可以获得包括以下技术效果:1)本发明对医案集中的症状名称进行规范化处理,实现中医书籍的自动标准化功能;且基于隐狄利克雷分布(lda)模型训练生成一种医案主题模型,使用该模型进行患者证候预测。2)本发明的证候预测方法通过对标准化的医案数据进行分析处理,实现中医诊疗系统的辨证功能,使得辨证结果更加准确。附图说明此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:图1是本发明实施例中计算辅助决策辨证过程图;图2是本发明实施例中步骤5辨证模型的生成过程图。具体实施方式以下将配合实施例来详细说明本发明的实施方式,藉此对本发明如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施。为了便于理解本发明,首先对本发明涉及的基本定义进行说明:症:是指疾病的症状,疾病的临床表现,如出汗、头晕、耳鸣、发热等,是判断疾病的原始依据。体征:生理学、医学用语,是指医生在检查病人时所发现的异常变化。与“症状”有别,“症状”是病人自己向医生陈述的异常表现,而“体征”是医生给病人检查时发现的具有诊断意义的证候。证:是综合分析各种症状,对疾病发生、发展过程中在某一阶段的病因、病位、病性等方面的病理概括。例如“肝胆湿热证”,病因为湿热,病位为肝胆,是属邪气有余的实证。辨证:就是分析、辨认疾病的证候,即以脏腑经络、病因、病机等基本理论为依据,通过对望诊、问诊所收集的症状以及其它临床资料进行分析、综合,辨清疾病的原因、性质、部位,以及邪正之间的关系,进而概括、判断属于何证。本发明公开了一种基于主题模型技术的中医智能辨证辅助决策方法,具体过程参见图1所示,具体包括:步骤1,对医案集中的症状名称进行规范化处理;具体为:从医案集中随机选择一种症状,在给定的标准症状数据库的条件下,分别计算该症状与四君子标准tcm(中医)数据集中所有症状之间的相似度,寻找最大相似度对应的症状,并作为该症状的标准症状名称,计算公式如下:sim(s,s′)=jwd(s,s′)=jd(s,s′)+prefixlength·(1.0-jd(s,s′))(1)其中,s表示患者的临床症状名称,s′表示四君子标准tcm数据集的标准症状名称,n表示临床症状名称s和标准症状名称s′之间的匹配字符数,t为匹配字符的数量,|s|与|s′|分别是s和s′中的字符数,jd(s,s′)为字符串s与s′的匹配度,prefixlength为字符前缀长度。步骤2,预处理医案数据集:使用语言技术平台(ltp)工具对每份医案进行分词处理;例如:原始医案【李某某,124,男,33,2012-05-21,咳嗽,头痛,发热,鼻塞,肝脏,心脏,气虚证,阴虚证,慢性支气管炎史,患咳喘十余年,冬重夏轻,近期加重】经过步骤1、2处理后的医案为【咳喘头痛发热鼻塞】。步骤3,生成医案主题模型,得到隐含在医案集中的所有主题;使用基于隐狄利克雷分布(lda)的主题模型方法挖掘隐藏在医案集中的所有主题,该主题是由相关症状构成的集合,每种症状均有对应的概率值,并根据概率值取前15种症状来表示主题,具体步骤如下所示:1)使用gibbs方法模拟生成k个“证候”;具体为:初始化:随机给每个词分配主题编号;给第m个医案的词wi分配主题编号,取最大概率值对应的主题,计算公式如下:其中,k∈[1,2,…,k],为症状a在证候k中出现的次数,为证候k的词在第m个医案中出现的次数,v为医案集中出现的症状数,z-i为除证候i以外的所有证候的集合;使用公式(3)进行迭代更新,直至包含于主题中的症状保持不变,迭代收敛。2)根据超参数β获得症状分布即其中,表示第i种症状在第k个证候中的所占权重,v为症状数,nk,w表示症状w在证候k中的出现次数。3)根据超参数α获得第m个医案的证候分布θm=(θm1,θm2,…,θmk),即θm~dir(α);其中,θmk表示第k个证候在医案m中的所占权重,nm,k表示证候k在医案m中的出现次数。其中,α、β为狄利克雷(dirichlet)先验分布的参数;4)根据多项式分布mult(θm)生成证候zi,即zi~mult(θm);其中,表示在医案m中证候zi出现的概率。5)根据多项式分布分别生成症状wv,即取中权重大于0的症状构成证候zk,返回步骤4),直到遍历完第m个医案中的所有词;其中,为在证候k中症状i出现的概率。6)返回步骤2),直到生成整个医案训练集(所有的证候组成)。步骤4,基于《中医内科学》构建标准证候数据库,并通过计算主题下的症状群zi与标准证候yj之间的相似度来获得主题的标签,即证候名称y,其中,标准证候示例如下:脾虚气陷证症状:尿浊反复发作,日久不愈,状如白浆,小腹坠胀,神倦无力,面色无华,劳累后发作或加重,舌淡苔白,脉虚软。证机概要:脾虚气陷,精微下泄。治法:健脾益气,升清固摄。代表方:补中益气汤加减。本补中益气,升清降浊,用于中气下陷,精微下泄之尿浊。常用药:党参、黄芪、白术、山药、益智仁、金樱子、莲子、芡实、升麻、柴胡。步骤5,基于步骤3、4挖掘得到的症候群构建证候预测模型,如图2所示。具体如下:通过使用贝叶斯规则推断一个新医案的证候标签集,设定一个概率阈值t,取大于该阈值的证候标签为新医案的证候,公式如下:p(k|m)>t(12)其中,当t为1e-7经验值时,预测效果到达最佳,其中,表示在证候k下症状si出现的概率,p(k|m)表示医案m的证候为k的概率。本发明的医案数据预处理方法通过对医案数据中症状名称的规范化处理来实现中医数据的自动标准化功能。本发明的证候预测方法通过对标准化的医案数据进行分析处理,实现中医诊疗系统的辨证功能,使得辨证结果更加准确。表1慢性肾病辨证结果主题(证候)症状群肺肾气虚证呼吸急促、胸闷气慌、咳嗽、多汗心肾阴虚证心痛憋闷、心悸盗汗、头晕耳鸣、口干、便秘脾肾阳虚证神疲乏力、多卧嗜睡、健忘、畏寒肢冷心肝火旺证急躁易怒、善忘、面红耳赤、口干、舌燥……邀请了电子科技大学校医院的中医医师分析了表1的辨证结果,结果发现每个证候下92.17%症状可以用《中医内科学》来验证。并且与最新的智能辨证方法相比,如子空间聚类算法、模糊识别等方法,本发明的辨证准确度达到了80.24%,而使用子空间聚类算法进行智能辨证时,所使用的数据集为5600名aids患者,且每位患者所包含的症状上的证候标签是由人工标记,不同的医生可能标记不同的结果,且一种症状上可能有多个证候标签,形成了不可靠的数据集,从而导致其辨证结果不可靠、辨证精度不真实。使用模糊识别进行智能辨证时,无具体的实验部分和数据集,因此,该方法是否可行无法得到验证。上述说明示出并描述了发明的若干优选实施例,但如前所述,应当理解发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离发明的精神和范围,则都应在发明所附权利要求的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1