一种实部虚部联合的复数fMRI数据稀疏表示方法与流程
本发明涉及生物医学信号处理领域,涉及一种实部虚部联合的复数功能磁共振成像(functionalmagneticresonanceimaging,fmri)数据稀疏表示方法。
背景技术:
fmri是一种在科研和临床领域都非常有价值的非侵入式医学影像技术。因为目前人们对大脑的认知程度仍然有限,利用数据驱动的方法如稀疏表示,不需要任何先验知识,就可以从fmri数据中提取一系列空间激活脑区(spatialmap,sm)成分及其时间序列成分。这些成分属于源信号,在脑认知和脑疾病相关的研究中有着重要的价值,如用于脑功能激活区域定位,作为功能网络连接的节点来考察与疾病相关的脑功能连接模式,以及作为生物标志物(biomarker)区分健康人与病人等。
稀疏表示已经在幅值fmri数据分析中获得了引人注目的成果,尤其是在脑网络的提取和脑功能连接研究中。稀疏表示方法能比独立成分分析(independentcomponentanalysis,ica)方法提取到更多的脑激活区和感兴趣成分,在分类精度和稳定性上优于ica方法和非负矩阵分解方法。然而,完备的fmri数据是复数的,包括幅值和相位两部分。相位数据虽然在噪声上大于幅值,但含有幅值数据所不具有的独特且生理意义明确的脑功能信息,同时具有指纹特性。现有研究表明,从完备的fmri复数数据中可以提取到更为完整的脑激活区域。因此,采用稀疏表示方法从复数fmri数据中挖掘脑功能信息具有重要意义。
技术实现要素:
本发明的目的在于,通过联合分析复数fmri的实部和虚部数据,实现一种完备复数fmri数据的稀疏表示方法,比幅值fmri数据提取到更多的激活体素。
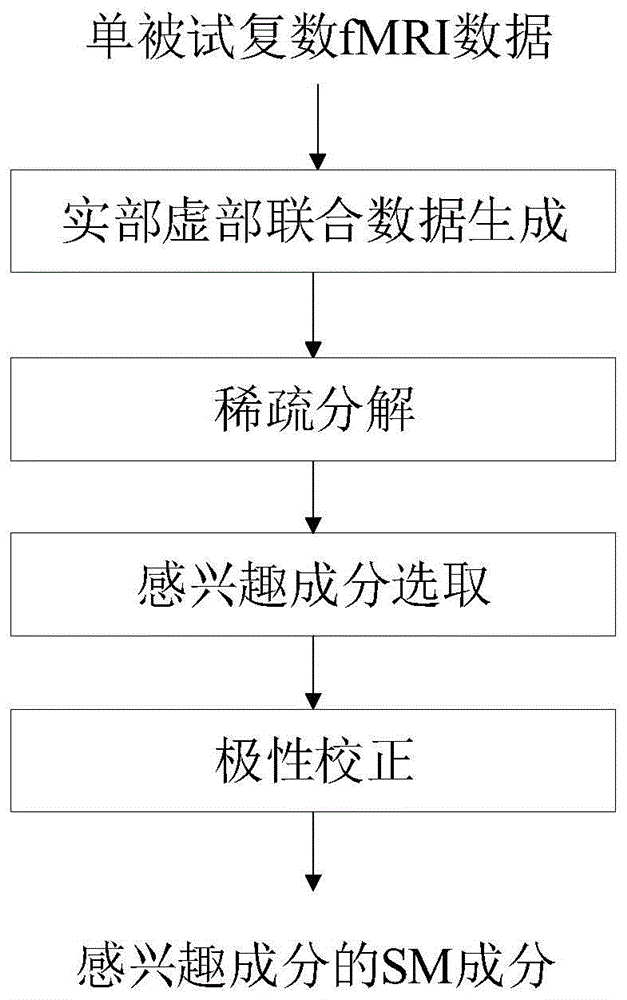
本发明的技术方案是,首先,将fmri复数数据分成实部和虚部两部分,生成实部虚部联合数据;接着,利用稀疏表示算法分离联合数据,估计得到一系列sm成分;然后,根据感兴趣成分的空间参考网络,基于与sm成分相关系数绝对值最大化原则,从稀疏表示估计得到的所有成分中选取感兴趣成分索引,并做极性校正;最后,输出感兴趣成分的sm成分。具体实现步骤如下:
第一步:输入单被试复数fmri数据
第二步:生成实部虚部联合数据。将x分成实部和虚部两部分,记实部数据为
第三步:稀疏分解。假设x的实部数据xre和虚部数据xim共享系数矩阵α,则对y进行稀疏分解的模型如下:
其中,
根据稀疏分解模型(2),采用k-svd算法(aharonm,eladm,brucksteina,k-svd:analgorithmfordesigningovercompletedictionariesforsparserepresentation.ieeetransactionsonsignalprocessing,4311-4322,2006)交替求解d和α,直到达到最大迭代次数。其中,交替求解d和α的目标函数分别如下:
(1)已知d,求解稀疏系数α,目标函数如下:
其中,δ是一个正常数,表征了αi的稀疏程度,i=1,...,v。yi是y的列矢量。在k-svd算法中,稀疏系数α求解应用了omp算法(patiyc,rezaiifarr,krishnaprasadps,orthogonalmatchingpursuit:recursivefunctionapproximationwithapplicationstowaveletdecomposition.proceedingsof27thasilomarconferenceonsignals,systemsandcomputers,40-44,1993)。
(2)已知稀疏系数α,学习字典d,目标函数如下:
稀疏表示算法收敛后,α的行矢量
第四步:感兴趣成分选取。利用感兴趣成分的空间参考网络αref,基于相关系数绝对值最大化原则,从m个sm成分
其中,“corr”表示相关系数。
第五步:极性校正。对感兴趣成分的sm成分
其中,“sign”表示取符号。
第六步:输出感兴趣成分的sm成分
本发明所达到的效果和益处是,与广泛应用的幅值fmri数据稀疏表示方法相比,通过联合实部虚部数据对完备的fmri数据加以利用,能提取到更多有意义的激活体素。例如,针对16被试敲击手指任务下采集的复数fmri数据,以稀疏分解所获取sm成分的激活体素数,以及与感兴趣成分空间参考(如附图2(1)所示)的相关系数为性能指标,较之幅值fmri数据稀疏表示方法得到的sm成分(如附图2(3)所示),本发明所估计任务相关(task)成分(如附图2(2a)所示)的相关系数提高了16%,多提取到了87%的激活体素,主要增加在主运动区和辅助运动区;所估计默认网络dmn(defaultmodenetwork)成分(如附图2(2b)所示)的相关系数相近,但多提取到了28%的激活体素,主要增加在难于提取的dmn子区域acc(anteriorcingulatecortex)。因此,本发明能够有效分析完备的复数fmri数据,比幅值fmri数据稀疏分解获得了更加全面的脑功能信息,在脑功能研究和脑疾病诊断方面有着良好的应用前景。
附图说明
图1是本发明实现流程图。
图2是本发明方法与幅值fmri稀疏表示方法得到的sm成分对比图。
具体实施方式
下面结合技术方案,详细叙述本发明的一个具体实施例。
现有k=16被试在敲击手指任务下采集的复数fmri数据。时间维度上有t=165次扫描,每次扫描都获得了53×63×46的全脑数据,脑内体素数v=59610。采用本专利的单被试fmri稀疏表示方法进行多被试(16被试)分析,进而得到组平均sm成分。具体实现步骤如下:
第一步:令k=1。
第二步:输入被试k复数fmri数据
第三步:生成实部虚部联合数据。将xk分成实部和虚部两部分,其中,实部数据为
第四步:对yk进行稀疏分解。设δ=20,字典大小m=400。采用k-svd算法交替求解过完备字典矩阵
第五步:感兴趣成分选取。假设task成分和dmn成分为两个感兴趣信号,利用这两个感兴趣成分的空间参考网络(kuangld,linqh,gongxf,congfy,calhounvd,adaptiveindependentvectoranalysisformulti-subjectcomplex-valuedfmridata.journalofneurosciencemethods,49-63,2017),记为
第六步:极性校正。代入公式(6),对两个感兴趣成分的sm成分
第七步:重复第四步到第六步r=10次,采用“kuangld,linqh,gongxf,congf,suij,calhounvd.modelordereffectsonicaofresting-statecomplex-valuedfmridata:applicationtoschizophrenia.journalofneurosciencemethods304,24-38,2018”中的方法获取bestrun,最终提取两个感兴趣成分的sm成分
第八步:k=k+1,若k>16,跳至第八步;否则,重复第二步到第八步。
第九步:输出两个感兴趣成分的组平均sm成分
- 还没有人留言评论。精彩留言会获得点赞!