同源序列和同源序列中串联重复序列的检测方法、计算机可读介质和应用与流程
本发明涉及基因测序
技术领域:
,尤其是涉及一种同源序列和同源序列中串联重复序列的检测方法、计算机可读介质和应用。
背景技术:
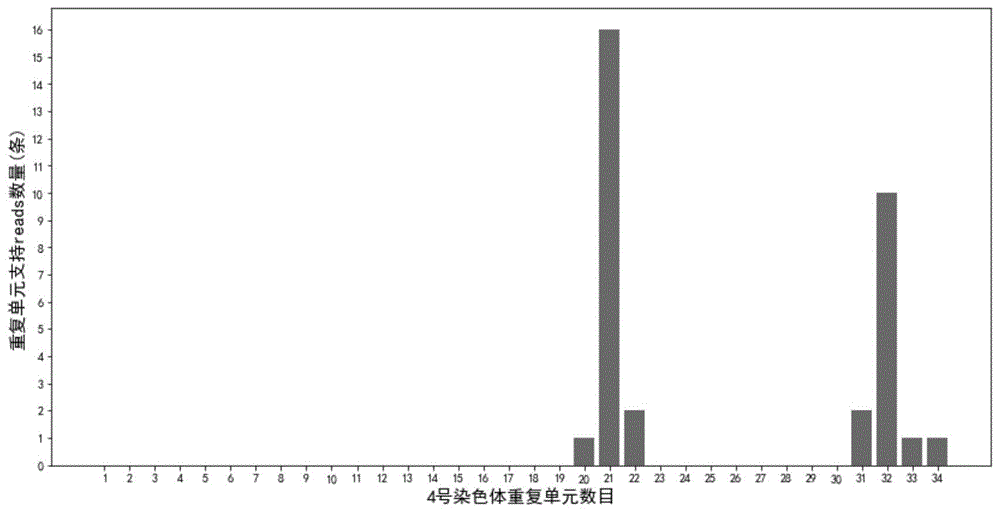
:同源序列是指两条dna序列具有极高的相似性,一般只有少数的核苷酸的差异。同源序列通常处于基因组的不同区域,在基因分型时容易混淆,并且会对基因组结构造成重要影响。重复序列指的是单倍体基因组中重复多次的dna序列,它们存在于所有的生物体中,原核生物基因组中的重复序列较少,真核生物基因组中存在大量的重复dna。重复序列主要有卫星dna、小卫星dna和微卫星dna,和具有其他长度的重复序列。串联重复序列是由重复序列依次分布在一段dna区域中,形成重复dna聚集区,这种聚集区在基因组的编码区和非编码区都存在。现有的针对包含较短的重复序列的同源序列检测方法通常采用pcr扩增的方法,通过检测扩增产物以检测同源序列中重复序列的重复数目,需要针对不同的同源序列设计引物,工作量大,效率低。其他检测包含重复序列的同源序列的方法还有southernblot法和bionano组装算法:southernblot法用特异的限制性内切酶将基因组dna切成片段后,以探针进行杂交,通过琼脂糖凝胶电泳来估算dna分子的长度。southernblot法的缺陷为对dna的质量要求高,实验操作繁琐,成本高,周期长,存在酶切位点不识别造成的实验失败,很难精确计算重复片段大小。bionano组装算法采用bionano光学图谱测序:利用内切酶对dna进行酶切并标记荧光,通过荧光成像生成酶切位点分布图,之后将这些带有酶切位点的分子进行组装,将组装的结果与参考基因组比较进而计算长串联重复的数据。基于bionano光学图谱技术的组装算法(参考https://bionanogenomics.com/wp-content/uploads/2014/10/bionano-poster-ashg2014-chan-long-repeats-cnv.pdf),将reads组装成contig,再比对到参考基因组序列,对含有重复序列的同源序列进行肉眼计数。该方法的缺陷有:(1)荧光酶切位点假阳性、假阴性高,酶切位点之间的距离估算偏差大,对酶的要求比较高而导致的适用性差。(2)需要对数据进行组装,bionano数据中存在大量插入、缺失错误,易导致组装错误;组装计算时间长,消耗计算资源大。因此,一种更准确的,且高效的同源序列的检测方法是目前需要的。有鉴于此,特提出本发明。技术实现要素:本发明的第一目的在于提供一种同源序列的检测方法,能够将测序reads匹配至与其同源性最高的同源序列。本发明的第二目的在于提供一种同源序列中串联重复序列的检测方法,缓解了现有技术中缺乏一种兼具效率和准确度的检测重复序列方法的问题。本发明的第三目的在于提供一种具有处理器可执行的非易失的程序代码的计算机可读介质,所述程序代码使所述处理器执行上述同源序列的检测方法,或上述同源序列中串联重复序列的检测方法。本发明的第四目的在于提供一种上述同源序列的检测方法、上述同源序列中串联重复序列的检测方法或上述计算机可读介质的应用。为解决上述技术问题,本发明特采用如下技术方案:根据本发明的一个方面,本发明提供了一种同源序列的检测方法,该检测方法包括以下步骤:选择目标同源序列间的差异位点作为打分位点;然后计算每一条测序reads相对于每一个目标同源序列的得分;再比较测序reads相对于不同目标同源序列的得分;若最高得分与次高得分之差≥第一阈值,则判定所述测序reads与最高得分对应的目标同源序列同源;若最高得分与次高得分之差<第一阈值,则舍去所述测序reads;若存在至少两个相同的最高分,舍去所述测序reads。根据本发明的另一个方面,本发明还提供了一种同源序列中串联重复序列的检测方法,该检测方法包括采用上述同源序列的检测方法区分同源序列,所述检测方法还包括:(a)将测序reads与目标同源序列的重复单元标准序列比对,将比对数记为所述测序reads中重复序列的重复数;其中,所述重复单元标准序列为与所述目标同源序列内所有重复序列的相似性最高的序列;(b)统计所述同源序列中,具有相同重复数的测序reads数,记为所述重复数的支持数;(c)以符合预设标准的支持数判断所述同源序列中重复序列的重复数。根据本发明的另一个方面,本发明还提供了一种具有处理器可执行的非易失的程序代码的计算机可读介质,所述程序代码使所述处理器执行上述同源序列的检测方法,或上述同源序列中串联重复序列的检测方法。根据本发明的另一个方面,本发明还提供了上述同源序列的检测方法、上述同源序列中串联重复序列的检测方法或上述计算机可读介质的应用。与现有技术相比,本发明具有如下有益效果:由于生物的基因中存在一些位于不同位置,但是同源性较高的区域,这些同源序列会干扰拼接或分析测序获得的测序reads,无法将测序reads匹配至合适的位置。本发明提供的同源序列的检测方法,采用先提取出目标同源序列间的差异位点,然后将这些差异位点作为打分位点给测序reads打分,并通过合理的计算分值的方法,将测序reads匹配至与其同源性最高的同源序列中,提高了数据分析的准确性。本发明提供的同源序列中串联重复序列的检测方法,目的是检测同源序列中特定的重复序列的重复数量,该检测方法基于上述同源序列的检测方法,采用经和同源序列匹配过的reads,避免统计到属于与该同源序列含有同源性的其他同源序列的reads,进一步提高了后续分析的准确性。本发明提供的串联重复序列的检测方法,以与同源区域内所有重复序列的相似性最高的重复单元标准序列作为比对的单元,可以提高reads比对到所有重复序列的可能。该检测方法无需设计多种针对不同区域的引物并检测扩增产物,实验操作也更简洁,操作简单且效率高。本发明提供的具有处理器可执行的非易失的程序代码的计算机可读介质,所述程序代码使所述处理器执行上述同源序列的检测方法,或上述同源序列中串联重复序列的检测方法,以用于后续的生物信息学分析。本发明提供的上述同源序列的检测方法、上述同源序列中串联重复序列的检测方法或上述计算机可读介质的应用,其应用范围广泛,可应用于多态性位点分析,亲缘关系鉴定以及制备用于诊断疾病的产品等方面。附图说明为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例提供的4q26区域d4z4重复序列的重复数;图2为本发明实施例提供的10q35区域d4z4重复序列的重复数;图3为本发明实施例提供的同源序列中串联重复序列的检测方法和bionano组装算法的运行时间的比较。具体实施方式下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明中,如果没有特别的说明:本文所提到的所有实施方式以及优选实施方法可以相互组合形成新的技术方案;本文所提到的所有技术特征以及优选特征可以相互组合形成新的技术方案;各个反应或操作步骤可以顺序进行,也可以不按照顺序进行;本文中所用的专业与科学术语与本领域熟练人员所熟悉的意义相同。根据本发明的一个方面,本发明提供了一种同源序列的检测的方法,该方法包括如下步骤:选择目标同源序列间的差异位点作为打分位点;然后计算每一条测序reads相对于每一个目标同源序列的得分;再比较测序reads相对于不同目标同源序列的得分;若最高得分与次高得分之差≥第一阈值,则判定所述测序reads与最高得分对应的目标同源序列同源;若最高得分与次高得分之差<第一阈值,则舍去所述测序reads;若存在至少两个相同的最高分,舍去所述测序reads。所述的reads指的是待测同源序列,即测序产生的读段,需要说明的是本发明中,reads指的是至少一条读段,即可以指一条读段,也可以指多条读段。目标同源序列指的是当存在至少两个同源序列时,将reads与其同源性最高的目标同源序列相匹配。同源序列指的是两条dna序列具有极高的相似性,一般只有少数的核苷酸的差异。同源序列通常处于基因组的不同位置,在基因分型时容易混淆,并且会对基因组结构造成重要影响。在一些优选的实施方式中,本发明提供的同源序列的检测方法包括:以各目标同源序列内的差异位点作为打分位点。在一些优选的实施方式中,将多个目标同源序列依次命名为l1、l2…lk…ln,将这些目标同源序列进行比较找出差异位点对应的碱基,其中目标同源序列来源于参考基因组的序列。将差异位点作为打分位点,将打分位点位置信息、每个目标同源序列在打分位点对应的碱基作为真阳性数据集。每条reads在一个目标同源序列下得到的总分数为在该reads上所有得分位点的得分数的和;比较测序reads在不同目标同源序列的总分数:若最高得分和次高得分的差≥第一阈值,则此候选reads匹配于最高得分的目标同源序列;若最高得分和次高得分的差<第一阈值,表明无法区分,则舍去此测序reads;若存在至少两个数值相同的最高分,表明无法区分,舍去该测序reads。所述第一阈值可以根据本领域常规的规则界定,在一些优选的实施方式中,所述第一阈值为次高得分分值的5%~20%时,匹配结果较佳,例如可以为但不限于为5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%或20%;优选为5%~15%;更优先为10%。在一些优选的实施方式中,按照如下方式打分:若测序reads在打分位点的碱基序列与目标同源序列内的差异位点一致则得分,分数为一致碱基数量×s,s>0;若测序reads在打分位点的碱基序列与目标同源区域内的差异位点不一致则不得分;若测序reads在打分位点的碱基序列未覆盖则不得分,所述未覆盖指的是测序reads在打分位点无碱基序列。以如下为例,对打分方式做进一步的说明:以两个目标重复序列为例,每条测序reads会得到2个得分,按照s=1.5计算:目标同源序列aaattaaac目标同源序列a’aaggaaag测序reads1aaggaaacreads1对a’得分,1.5*2=3(最高);reads1对a得分,1.5*1=1.5(次高);3-1.5=1.5,超过次高1.5的10%,reads1归为同源序列a’。在一些优选的实施方式中,所述测序reads可来源于本领域可接受的测序平台,包括但不限于为基于二代测序的roche454、illumina、lifesolid/iontorrent或pacbiors测序平台,或基于三代测序的pacbiosmrt或oxfordnanopore测序平台。优选使用读长更长的三代测序平台来获得待测样品的测序reads。可以理解的是,本发明对测序策略和测序时的建库方式均没有限制。在一些可选的实施方式中,所述同源序列的检测方法还包括将待测样品经测序得到的reads进行质控。可以理解的是,本领域可接受的常规的对测序数据的质控方法均可用于对测序得到的reads进行质控。在一些优选的实施方式中,按照如下步骤进行质控获得的reads质量更佳:先对原始数据进行过滤,根据整条reads的质量值过滤掉质量值低的reads;然后使用对比软件,将过滤后的数据比对到目标同源序列所述物种的参考基因组;然后根据比对结果筛选,根据每条reads的比对结果和比对质量将比对质量低的reads过滤掉,同时保留比对到多处的reads中比对结果最好的情况。在一些优选的实施方式中,所述测序reads包括覆盖同源序列全长的测序reads。在一些优选的实施方式中,按照如下方法获得覆盖同源序列的reads:根据同源序列在参考基因组上的位置,提取同源序列上游和下游的序列特征,作为marker(序列标签);然后将测序reads与marker进行比对,根据比对结果筛选比对上marker的reads,这些reads为覆盖到同源序列较好的reads,即后续分析所使用的reads。其中marker的设置按照如下方式较佳:在同源序列的上游、下游同时设置marker,每侧至少设置1个marker;marker需要具备特异性,所述特异性是指marker的序列在非同源序列中不存在与其同源的序列,当每侧只设置单个marker特异性不佳时,增加marker数量,以使marker的组合具有所述特异性,即该marker的组合在非同源序列不存在同源marker的组合。marker的主要功能是为了筛选覆盖全长的reads,其中的全长,是指reads可以覆盖到所述同源序列的所有序列。可选地,不同同源序列上设置的marker可以相同也可以不相同。当不同的同源序列上设置的marker不相同时,还可以起到区分不同的同源序列的作用。根据本发明的另一个方面,本发明还提供了一种同源序列中串联重复序列的检测方法,所述检测方法包括采用上述同源序列的检测方法区分同源序列。所述检测方法还包括:(a)将测序reads与目标同源序列的重复单元标准序列比对,将比对数记为所述测序reads中重复序列的重复数;其中,所述重复单元标准序列为与所述目标同源序列内所有重复序列相似性最高的序列。与同源序列内所有重复序列的相似性最高的序列的重复单元标准序列作为比对的单元,可以提高reads比对到所有重复序列的可能。可以理解的是,本领域技术人员可以采用本领域常规的方法,例如使用可以执行blast功能的软件,将同源序列内的重复序列进行互相比对,得到一个和其他重复序列的相似性最高的重复序列,作为重复单元标准序列。在一些可选的实施方式中,将覆盖同源序列的reads和重复单元标准序列比对,可参考如下步骤:首先,设置同源序列重复单元标准序列:提取同源序列中的重复序列命名为r1、r2…rn,从这些重复序列中筛选出最具代表性的一个作为重复单元标准序列,重复单元标准序列应当有如下特征:重复单元标准序列与其他的重复序列的相似性应当是所有重复序列中最高的。然后将覆盖同源序列的reads和重复单元标准序列进行blast比对,然后以重复单元标准序列比对到reads上的位置构建距离矩阵m,对同一个重复单元标准序列长度内的比对结果按照一个比对处理。在一些优选的实施方式中,若测序reads与重复单元标准序列的第一个比对与第二个比对的间距大于第二阈值,则第一个比对不计入所述测序reads的重复数,若测序reads与重复单元标准序列的最后一个比对与倒数第二个比对的间距大于第二阈值,则最后一个比对不计入所述测序reads的重复数;所述第二阈值可以根据本领域常规的规则界定,在一些优选的实施方式中,所述第二阈值为重复单元标准序列长度的45%~55%时,检测结果较佳,所述第二阈值例如可以为但不限于为45%、46%、47%、48%、49%、50%、51%、52%、53%、54%或55%;优选为48%~52%;更优选为50%。(b)将具有相同的重复序列的重复数的reads的数量记为同源序列中串联重复序列的重复数的支持reads数numi,例如经过上一步骤的比对,得到测序reads中重复序列的重复数为10,当将所有的测序reads与目标同源序列比对后,共有5条reads中重复序列的重复数为10,则重复序列的重复数10的支持reads数numi为5。(c)然后以符合预设标准的重复序列的重复数作为同源序列中含有的重复序列的数量,所述预设标准可以根据本领域常规规则设定。在一些优选地实施方式中,所述预设标准按照如下方式实施较佳:将重复序列的重复数的支持reads数numi从大到小排列,记为num1、num2、num3……numn,将所有重复序列的重复数的支持reads数numi的和记为e;m1:当num1/e×100%>70%,且num1/num2>3时,同源序列中含有的重复序列的数量为num1支持的重复序列的重复数;m2:如不满足m1,当(num1+num2)/e×100%>70%,且num2/num3>3时,同源序列中含有的重复序列的数量为num1和num2支持的重复序列的重复数;m3:如不满足m2,当(num1+num2+num3)/e×100%>70%,且num3/num4>3时,同源序列中含有的重复序列的数量为num1、num2和num3支持的重复序列的重复数。需要说明的是,本发明不限制对测序reads打分,并判定所述测序reads与目标同源序列是否同源的步骤和上述步骤a的先后关系。可选地,可以先判定所述测序reads与目标同源序列是否同源,然后将该同源的reads与重复单元标准序列比对,获得该reads中重复序列的重复数;可选地,可以先将所有测序的reads与重复单元标准序列比对,获得每条reads中重复序列的重复数,然后再将该条reads通过打分匹配至相应的同源序列中。本发明对此不做限制。在统计具有相同的重复序列的重复数的reads的数量时,采用经和同源序列匹配过的reads,避免统计到不属于该同源序列,而是属于与该同源序列含有相似序列的其他区域的reads,进一步提高了后续分析的准确性。本发明检测的同源序列可以是含有首尾相连的重复序列的串联重复序列,也可以是在重复序列之间存在间隔碱基的重复序列组成的串联重复序列。本发明对串联重复序列的重复序列长度不做限制,既可以是重复序列长度小于1kb的较短的重复序列,包括但不限于为卫星dna、小卫星dna和微卫星dna;也可以为长度大于1kb的较长的重复序列。在一些优选的实施方式中,所述目标同源序列包括人类基因组的4q35区域和10q26区域,所述重复序列为d4z4重复序列。面肩肱型肌营养不良症是一种遗传性肌肉疾病,其发病率居于肌肉系统疾病的第三位,发病率为1/20,000。大部分病人在20岁之前已有症状产生,受其影响最严重的是脸、肩、上臂等部位的肌肉,会出现逐渐加重的肌力减退以及肌肉的萎缩。面肩肱型肌营养不良症分为fshd1型(占发病人数的95%)和fshd2型(占发病人数的5%)。fshd1型需要由两个遗传因素同时存在才能导致发病:(1)大约95%的患者(fshd1型)在染色体4q35区域具有一个称为d4z4的3.3kb的重复序列的数量缺失,正常人一般有11-150个重复,但是患者只有10个或更少的重复。重复数目与临床表型之间有负相关的关系,重复序列数目越少,发病年龄越早,病情则越严重。(2)最后一个重复序列远端需要存在一个称为4qa的变体结构才能导致疾病发生。检测人类基因组的4q35区域和10q26区域中的d4z4重复序列,有助于对面肩肱型肌营养不良症发病机理的研究和药物的开发。需要说明的是,只检测人类基因组的4q35区域和10q26区域中的d4z4重复序列,无法得到面肩肱型肌营养不良症的诊断结果,当检测人类基因组的4q35区域和10q26区域中的d4z4重复序列时,得到的检测结果无法用于面肩肱型肌营养不良症的诊断。在一些优选的实施方式中,所述同源序列中串联重复序列的检测方法还包括同源序列基因型的判定,所述检测方法还包括同源序列基因型的判定,判定标准包括:n1:当num1/e×100%>70%,且num1/num2>3时,判定为纯合基因型;n2:如不满足n1,当(num1+num2)/e×100%>70%,且num2/num3>3时,判定为杂合基因型;n3:如不满足n2,当(num1+num2+num3)/e×100%>70%,且num3/num4>3时,判定为嵌合基因型。根据本发明的另一个方面,本发明还提供了一种具有处理器可执行的非易失的程序代码的计算机可读介质,所述程序代码使所述处理器执行上述同源序列的检测方法,或上述同源序列中串联重复序列的检测方法。该计算机可读介质可以便捷的执行上述串联重复序列的检测方法,以用于后续的生物信息学分析。根据本发明的另一个方面,本发明还提供了上述同源序列的检测方法、上述同源序列中串联重复序列的检测方法或上述计算机可读介质的应用。所述应用可选地,用于多态性位点的分析,在一个具体的实施方式中,例如检测多个含有同源序列中的ssr的重复数,来分析该同源序列的多态性;可选地,用于亲缘关系鉴定,在一个具体的实施方式中,例如检测多个同源序列中的重复序列的数量,以构建进化树并分析待测样品的亲缘关系。可选地,制备用于诊断疾病的产品,由于串联重复序列中重复序列的分布与一些疾病相关,例如白细胞介素4基因中第2个内含子内的串联重复序列区域vntr多态性与中国西南地区汉族人慢性阻塞性肺疾病易感性相关;三核苷酸重复序列突变与神经退行性疾病相关;白细胞介素1受体拮抗剂基因86bp可变串联重复序列多态性与椎间盘疾病相关等,因此可以将该检测同源序列的方法应用于制备用于诊断疾病的产品。在一些优选的实施方式中,所述应用包括制备用于诊断面肩肱型肌营养不良症的产品。将上述串联重复序列的检测方法或上述计算机可读介质用于制备诊断面肩肱型肌营养不良症的产品,可以快速的得到待测样品中4q35区域重复序列d4z4的数量,以协助诊断面肩肱型肌营养不良症。可选地,所述产品可以为包含所述计算机可读介质的设备,或者执行所述串联重复序列的检测方法的模块或者由多个模块单元组成的系统。在一些优选的实施方式中,当上述同源序列的检测方法、上述同源序列中串联重复序列的检测方法或上述计算机可读介质用于制备诊断面肩肱型肌营养不良症的产品时,所述目标同源序列包括人类基因组的4q35区域和10q26区域,所述重复序列为d4z4重复序列。由于4q35区域和10q26区域具有同源区域,但是10q26区域中重复序列的改变不会引起面肩肱型肌营养不良症,因此同时以这两个区域作为目标同源序列,可以区分reads所属的目标同源序列,避免匹配于10q26区域的reads中d4z4重复序列的重复数对4q35区域中d4z4重复序列的重复的统计产生干扰。下面结合优选实施例进一步说明本申请的技术方案和有益效果。实施例为了评估本方案的可行性,我们选择人基因组中跨度较大,复杂度较高且高度同源的两个区域作为目标同源序列(分别位于4q35和10q26,具体坐标为chr4:190,015,229-190,091,593和chr10:133,614,430-133,684,256),上述区域存在多个重复序列d4z4。将人血液样本采用试剂盒提取全基因组dna,dna样品质检合格后采用nanopore纳米孔测序平台测序,将获得的测序数据采用如下方式处理:(a)数据质控(a1)原始数据质控根据整条reads的质量值过滤掉质量值低的reads,质量值≤7认为reads质量不合格。过滤结果统计如表1所示,以样本s-61为例:表1样本s-61的原始数据质控结果样本名称过滤前reads数量过滤前数据量(bp)过滤后reads数量过滤后数据量(bp)s-6115,123399,526,10214,696378,417,004(a2)采用minimap2软件,将步骤a1中过滤后得到的reads比对到人类hg38参考基因组。(a3)根据每条reads的比对结果,将比对质量低于30的reads过滤掉,同时保留比对到多处的reads中比对结果最好的情况。(b)覆盖同源序列全长reads筛选(b1)提取人类hg38参考基因组4q35区域,d4z4重复下游3段序列做为marker,分别为:marker1(chr4:190,099,110-190,100,271)、marker2(chr4:190,101,001-190,106,258)、marker3(190,113,857-190,116,363)。这3个marker有如下特征:特异性,即在4号染色体上其他区域没有同源序列;通用性,即10q26区域d4z4重复下游有这3个marker同源序列,而且在10号染色体其他区域没有同源序列,这3个marker可以同时做为10号染色体的marker。(b2)将步骤(a3)得到的reads和步骤(b1)中提取出的3个marker进行blast比对,保留至少比对到1个marker的reads,这些reads就是覆盖到d4z4重复下游区域的reads。(b3)用samtools软件,对步骤(b2)中保留的reads进行筛选,以d4z4重复区域上游10-100个碱基作为上游区域的marker,比对到d4z4重复区域上游10-100个碱基区域的reads即认为覆盖到d4z4重复上游。这些reads即为完整覆盖到样本4q35和10q26区域d4z4重复序列的reads,结果如表2所示:表2完整覆盖d4z4重复reads数量样本名称完整覆盖d4z4重复reads数量s-6183(c)区分同源序列(c1):抽取人类hg38参考基因组4q35、10q26区域包含d4z4重复的同源序列(chr4:190,015,229-190,091,593、chr10:133,614,430-133,684,256),将两段序列进行比较找出差异位点及对应的碱基,这些差异位点作为打分位点,位点对应的碱基作为真阳性数据集。示例采用4号染色体一段3295bp(chr4:190,065,229-190,068,523)和10号染色体一段3310bp(chr10:133,664,430-133,667,739)的同源序列结果作为示例,得到28个差异位点,真阳性数据集位点信息如表3所示:表3部分真阳性数据集位点信息(c2):将步骤(b)得到的完整覆盖到d4z4重复区域的reads用mininap2软件比对到4q35区域。(c3):基于步骤(c2)中的比对结果得到每条reads比对到真阳性数据集中打分位点的碱基,建立打分表。(c4):结果打分,依次将各条reads比对到打分位点的碱基与chr4或chr10在此位点的碱基进行比较,碱基一致,则此条reads在对应染色体的此位点得分,分数为碱基数量n×1.5,在chr4或chr10的分数累加;若不一致则不得分,未覆盖视为不一致;最后统计此条reads分别在chr4和chr10的总得分。下表为reads1打分结果,其中得分1是reads1在chr4的得分情况,得分2是reads1在chr10的得分情况,最终reads1在chr4总得分21,reads1在chr10总得分10.5,所以判定reads1为chr4的reads,结果如表4所示:表4reads1打分结果(d)重复序列计数(d1):提取4q35和10q26区域的所有重复序列,用blast软件进行相互比对,筛选出与其他重复序列相似性(identity)最高的一个重复序列作为重复单元标准序列。重复单元标准序列信息chr4:190065229-190068523,长度l=3295bp。(d2):将步骤(b)中得到的完整覆盖d4z4重复区域的reads与步骤(d1)中的重复单元标准序列进行blast比对。(d3):根据步骤(d2)的比对结果构建矩阵m,除第一行标题外,每一行代表一个比对,reads1的比对结果矩阵m示例如表5所示:表5reads1的比对结果矩阵m(d4):重复序列计数,根据步骤(d3)得到的矩阵m,以比对到reads上的位置为坐标,计算步骤d2中首尾相邻两个比对之间的距离d,所述距离为readsend坐标与其下游相邻的readsstart的坐标之间的距离,设定l/2(1/2的重复单元标准序列rm长度)为阈值,d>l/2时不计数,得出重复序列数目。示例矩阵中reads1与标准序列有18个比对结果,最后一个比对与倒数第二个比对之间的距离超过阈值,最后一个比对不计入结果中,所以最终reads1为17个d4z4重复序列。(d5):peaks(峰值)检测,按照以上步骤得出每个同源序列中每条reads的重复序列的重复数。将重复序列的重复数的支持reads数numi从大到小排列,记为num1、num2、num3……numn,将所有重复序列的重复数的支持reads数numi的和记为e;m1:当num1/e×100%>70%,且num1/num2>3时,同源序列中含有的重复序列的数量为num1支持的重复序列数量;m2:如不满足m1,当(num1+num2)/e×100%>70%,且num2/num3>3时,同源序列中含有的重复序列的数量为num1和num2支持的重复序列的数量;m3:如不满足m2,当(num1+num2+num3)/e×100%>70%,且num3/num4>3时,同源序列中含有的重复序列的数量为num1、num2和num3支持的重复序列的重复数。结果如表6和图1~图2所示,最后d4z4重复及reads支持数如表6所示:最终s-61的重复数目为chr4:21、32个d4z4重复;chr10:4、38、38个d4z4重复。然后按如下标准确定纯合、杂合、嵌合:n1:纯合:num1/e×100%>70%,且num1/num2>3;n2:杂合:(num1+num2)/e×100%>70%,且num2/num3>3;n3:嵌合:(num1+num2+num3)/e×100%>70%,且num3/num4>3。表64q35区域和10q26区域中d4z4重复序列的重复数计算过程如下:chr4:num1=16,num2=10,num3=2,num4=2,num5=1,num6=1,num7=1;e=num1+num2+num3+num4+num5+num6+num7=33。m1:num1/e×100%=16/33×100%=48.48%<70%;num1/num2=16/10=1.6<3;m2:(num1+num2)/e×100%=(16+10)/33×100%=78.79%>70%;num2/num3=10/2=5>3;可得出,chr4重复数目为num1和num2支持的21个重复和32个重复。chr10:num1=21,num2=14,num3=12,num4=2,num5=1;e=num1+num2+num3+num4+num5=50。m1:num1/e×100%=21/50×100%=42%<70%;num1/num2=21/14=1.5<3;m2:(num1+num2)/e×100%=(21+14)/50×100%=70%=70%;num2/num3=14/12=1.17<3;m3:(num1+num2+num3)/e×100%=(21+14+12)/50×100%=94%>70%;num3/num4=12/2=6>3;可得出,chr10重复数目为num1、num2和num3支持的21个重复、14个重复和12个重复。(e)对61例样本进行处理,获取其同源序列的重复序列数目,同时与bionano组装算法、southernblot方法重复序列计数结果比较。目前,行业内认为southernblot检测结果最为可信,但southernblot方法由于其酶切位点的限制不能鉴定10q26区域的d4z4重复数目。结果如表7所示:表761例样本的d4z4重复数目本实施例方法和southernblot比较:61例样本中,本实施例方法57例(93.44%)在4q35区域的结果与southernblot方法结果一致。剩余4例(6.56%)样本(s-17、s-22、s-36、s-50)southernblot因未能找到合适的ecori/blni酶切位点,未得到合理结果实验失败。本实施例方法和bionano组装算法比较:本实施例方法与bionano组装算法在4q35区域和10q26区域有52例(85.25%)结果完全相同。5例(8.20%)样本(s-04、s-06、s-08、s-27、s-61)bionano方法鉴定为杂合,而本实施例方法鉴定为嵌合体,这5例样本中4例样本(s-04、s-06、s-08、s-27)southernblot方法鉴定的结果和本实施例一致都是嵌合体,另外1例样本(s-61)因为southernblot方法本身的限制性无法鉴定10q26区域的重复数目。2例(3.28%)样本(s-38、s-46)在4q35区域bionano组装算法鉴定为纯合,而本实施例方法和southernblot方法均鉴定为杂合,可见bionano组装算法不能很好的区分重复数目接近的reads。2例(3.28%)样本(s-10、s-14)在4q35区域和10q26区域bionano组装算法鉴定的结果与本实施例方法在重复数量上一致,但是区分同源序列时结果不一致,southernblot方法在4q35区域鉴定的结果与本实施例方法一致,可见bionano组装算法不能很好的区分同源序列。综上,本实施例方法在4q35区域的结果与southernblot方法有很高的一致性,在10q26区域与bionano组装算法的结果也有很高的一致性,并且本实施例方法能鉴定出southernblot方法不能鉴定的10q26区域,同样克服bionano组装算法无法鉴定杂合、不能很好的区分同源序列、不能很好的区分重复数接近的基因型的缺陷,故本实施例方法有很好的可信性。在时间消耗上,对本实施例方法与bionano组装算法进行了比较,结果发现采用相同集群配置,与bionano组装算法比较,在运行时间上,本实施例方法平均运行核时为2,003.64s,而bionano组装算法平均运行核时为50,892.52s,二者差异极显著,结果如图3所示。最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1