利用人工智能AI模型组分析多类数据的方法及装置与流程
利用人工智能ai模型组分析多类数据的方法及装置
1.本申请要求于2019年09月09日提交的申请号为2019108496243、发明名称为“多类数据的分析方法及其装置、计算机设备、存储介质”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
技术领域
2.本申请涉及人工智能(artificial intelligence,ai)技术领域,特别涉及一种利用人工智能ai模型组分析多类数据的方法及装置。
背景技术:
3.随着人工智能的普及,ai模型应用到了越来越多的领域,例如:医疗、金融、交通等。在很多领域中,需要利用ai模型分析多类数据,以对目标事件进行预测。多类数据中的每一类数据用于表示影响目标事件的预测结果的一方面因素。根据多类数据对目标事件进行预测,能够分别获取多类数据的特征,提高对目标事件进行预测的准确性。例如,该多类数据可以为:具有不同的数学表达方式的多类数据,具有不同数据维度的多类数据,用于代表不同的含义的多类数据。
4.相关技术中,可以将多类数据输入至多层感知机(multilayer perceptron,mlp),然后,采用多层感知机分别获取该多类数据的特征,并根据该多类数据的特征对目标事件进行预测。其中,由于每类数据可以使用一个矩阵表示,将多类数据输入至多层感知机的实现方法是:将多类数据的矩阵按预设方式进行拼接,然后将经过拼接处理后的矩阵输入至多层感知机。
5.但是,由于多类数据的数据类型差异较大,直接将拼接后的多类数据的矩阵输入至多层感知机,多层感知机较难同时适配于多类数据,导致较难有效提取多类数据的特征,影响多层感知机根据数据的特征对目标事件进行预测的准确度。
技术实现要素:
6.本申请提供了一种利用人工智能ai模型组分析多类数据的方法及装置,可以解决多层感知机对简单拼接后的多类数据进行分析的准确度较低的问题。
7.第一方面,本申请提供了一种利用ai模型组分析多类数据的方法,该ai模型组包括多个第一ai模型和第二ai模型,其中,该多个第一ai模型中的每个第一ai模型对应多类数据中的一类数据,该方法包括:获取多类数据,多类数据中的每一类数据表示影响目标事件的结果的一方面的因素;输入多类数据中的每一类数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征;根据多个目标隐含层特征生成融合特征;输入融合特征至第二ai模型,根据第二ai模型对融合特征进行分析,输出预测值,预测值指示根据多类数据对目标事件进行预测的结果。
8.本申请实施例提供的利用ai模型组分析多类数据的方法,该方法通过采用ai模型组中多个第一ai模型中的每一个第一ai模型,分别对多类数据中的每类数据进行分析,然
后根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征,再根据该多个目标隐含层获取融合特征,然后采用第二ai模型根据融合特征对目标事件进行预测,相较于相关技术,由于预先采用多个第一ai模型分别获取多类数据的特征,然后对用于表示多类数据的特征的融合特征进行分析,使得ai模型组可以深度地挖掘每一类数据的特征,充分利用每一类数据的特征,有效地提高了根据多类数据对目标事件进行预测的准确性。
9.在一种可实现方式中,在输入多类数据中的每一类数据至对应的第一ai模型之前,该方法还可以包括:获取多类样本数据;根据多类样本数据确定多个第一ai模型,每个第一ai模型为由多类样本数据中的一类样本数据训练得到的ai模型;根据多类样本数据和多个第一ai模型确定第二ai模型,第二ai模型为由多类样本数据对应的融合样本特征训练得到的ai模型,融合样本特征根据多个第一ai模型的目标隐含层特征得到。
10.在ai模型组的训练过程中,由于用于确定第二ai模型时的特征,是预先根据多个第一ai模型分别对多类数据进行分析所得特征的融合特征,使得训练过程中可以充分利用每一类数据的特征,有效地提高了训练得到的ai模型组的模型性能。
11.在一种可实现方式中,每个第一ai模型包括输入层、输出层、一个或多个隐含层,第一ai模型的目标隐含层为第一ai模型中一个或多个隐含层中的一个。并且,不同第一ai模型的目标隐含层在对应第一ai模型中的次序可以相同或不同。
12.进一步的,该多个第一ai模型的模型结构可以相同或不同。同时,任一第一ai模型的模型结构和第二ai模型的模型结构也可以相同或不同。其中,ai模型的模型结构由ai模型的网络结构类型、ai模型中网络层数、每个网络层中神经元的数量和神经元之间连接方式、对模型进行训练时的批次输入数量、学习率和优化学习率的策略等模型参数定义。当两个ai模型的所有模型参数对应相同时,可以确定该两个ai模型的模型结构相同,当两个ai模型的模型参数中的任一个对应不同时,确定该两个ai模型的模型结构不同。
13.需要说明的是,本申请实施例提供的利用ai模型组分析多类数据的方法可以应用于多种场景,且当在应用场景中涉及的目标事件不同时,用于进行分析的多类数据不同。
14.在一种可能的场景中,当目标事件包括以下事件中的任意一种:预测细胞系对药物的敏感程度、预测细胞系的基因干扰敏感程度、预测对细胞系对应的病人分型的生物标志物时,该多类数据可以包括细胞系的以下数据中的两个或多个:基因突变数据、基因表达数据、脱氧核糖核酸甲基化数据、拷贝数变异数据、微核糖核酸表达数据、组蛋白修饰数据、基因融合数据、染色体异构数据和代谢物表达数据。
15.在另一种可能的场景中,当目标事件为车辆是否具有营运行为时,多类数据可以包括目标车辆的以下数据中的两个或多个:目标车辆在行车过程中经过的地点数据和经过对应地点时的时间数据等用于指示目标车辆的行车轨迹的数据,及目标车辆在一段时间内的出行次数数据、目标车辆在一段时间内的出行频率数据、目标车辆的类型数据、目标车辆出行的天气数据、目标车辆出行的时间段数据等用于指示目标车辆的出行特征的数据。
16.在又一种可能的场景中,当目标事件为地区的天气状况时,多类数据可以包括目标地区的太阳辐射数据、大气环流数据和洋流流动数据中的两个或多个。
17.在一种可实现方式中,根据多类样本数据确定多个第一ai模型的实现过程,具体可以包括以下步骤:确定每一类样本数据对应的多个第一备选ai模型,样本数据包括训练样本数据和验证样本数据;利用每一类样本数据中的训练样本数据,分别对对应的多个第
一备选ai模型进行训练,获得每一类训练样本数据对应的多个训练完成的第一备选ai模型;根据每一类样本数据中的验证样本数据,获得对应的训练完成的第一备选ai模型的性能参数,性能参数指示训练完成的第一备选ai模型对目标事件进行预测的结果的准确度;在每一类训练样本数据对应的多个训练完成的第一备选ai模型中,将性能参数所指示的准确度最高的第一备选ai模型确定为根据对应一类样本数据确定的第一ai模型。
18.相应的,根据多类样本数据和多个第一ai模型确定第二ai模型的实现过程,具体可以包括以下步骤:输入多类样本数据中的每一类训练样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类训练样本数据的目标隐含层训练特征;根据多个目标隐含层训练特征生成融合训练特征;利用融合训练特征,分别对多个第二备选ai模型进行训练,获得多个训练完成的第二备选ai模型;输入多类样本数据中的每一类验证样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类验证样本数据的目标隐含层验证特征;根据多个目标隐含层验证特征生成融合验证特征;根据融合验证特征,分别获得多个训练完成的第二备选ai模型的性能参数,性能参数指示训练完成的第二备选ai模型对目标事件进行预测的结果的准确度;在多个训练完成的第二备选ai模型中,将性能参数所指示的准确度最高的第二备选ai模型确定为第二ai模型。
19.其中,根据多个目标隐含层特征生成融合特征的实现方式,具体包括:对多个目标隐含层特征进行拼接处理,得到融合特征。
20.在一种可实现方式中,第一ai模型的结构可以为残差网络结构或密集连接网络;
21.由于残差网络结构的连接方式提高了信息在网络中的流通程度,避免了由于网络过深所引起的消失梯度问题和退化问题,有助于训练过程中梯度的反向传播,当根据样本数据确定的第一ai模型的网络结构类型为残差网络结构时,能够保证该第一ai模型的预测准确度。并且,由于该残差网络的连接方式能够体现层与层之间的调控作用,当第一ai模型用于分析具有相互影响关系的多类数据时,该残差网络能够体现多类数据之间的内部逻辑关系,能够进一步提高分析的准确性。且由于细胞系的基因调控网络复杂,且存在层次之间彼此调控的关系,当该第一ai模型用于分析细胞系的多类基因组学数据时,该作用表现的尤其明显。
22.类似的,当根据样本数据确定的第一ai模型的网络结构类型为密集连接网络时,由于在密集连接网络中,网络每一层的输入向量都是前面所有层输出向量的拼接向量,而每一层所学习的特征也会被直接传给其后面所有层作为输入,因此,也能够体现多类数据之的内部逻辑关系,能够进一步提高预测准确度。
23.基于类似的原因,第二ai模型的结构也可以为残差网络结构或密集连接网络。
24.第二方面,本申请提供了一种利用ai模型组分析多类数据的装置,该ai模型组包括多个第一ai模型和第二ai模型,其中,多个第一ai模型中的每个第一ai模型对应多类数据中的一类数据,该装置包括:第一获取模块,用于获取多类数据,多类数据中的每一类数据表示影响目标事件的结果的一方面的因素;提取模块,用于输入多类数据中的每一类数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征;融合模块,用于根据多个目标隐含层特征生成融合特征;预测模块,用于输入融合特征至第二ai模型,根据第二ai模型对融合特征进行分析,输出预测值,预测值指示根据多类数据对目标事件进行预测的结果。
25.在一种可实现方式中,装置还包括:第二获取模块,用于获取多类样本数据;第一确定模块,用于根据多类样本数据确定多个第一ai模型,每个第一ai模型为由多类样本数据中的一类样本数据训练得到的ai模型;第二确定模块,用于根据多类样本数据和多个第一ai模型确定第二ai模型,第二ai模型为由多类样本数据对应的融合样本特征训练得到的ai模型,融合样本特征根据多个第一ai模型的目标隐含层特征得到。
26.在一种可实现方式中,每个第一ai模型包括输入层、输出层、一个或多个隐含层,第一ai模型的目标隐含层为第一ai模型中一个或多个隐含层中的一个。
27.在一种可能的场景中,当目标事件包括以下事件中的任意一种:预测细胞系对药物的敏感程度、预测细胞系的基因干扰敏感程度、预测对细胞系对应的病人分型的生物标志物时,该多类数据可以包括细胞系的以下数据中的两个或多个:基因突变数据、基因表达数据、脱氧核糖核酸甲基化数据、拷贝数变异数据、微核糖核酸表达数据、组蛋白修饰数据、基因融合数据、染色体异构数据和代谢物表达数据。
28.在另一种可能的场景中,当目标事件为车辆是否具有营运行为时,多类数据可以包括目标车辆的以下数据中的两个或多个:目标车辆在行车过程中经过的地点数据和经过对应地点时的时间数据等用于指示目标车辆的行车轨迹的数据,及目标车辆在一段时间内的出行次数数据、目标车辆在一段时间内的出行频率数据、目标车辆的类型数据、目标车辆出行的天气数据、目标车辆出行的时间段数据等用于指示目标车辆的出行特征的数据。
29.在又一种可能的场景中,当目标事件为地区的天气状况时,多类数据可以包括目标地区的太阳辐射数据、大气环流数据和洋流流动数据中的两个或多个。
30.在一种可实现方式中,第一确定模块,具体用于:确定每一类样本数据对应的多个第一备选ai模型,每一类样本数据包括训练样本数据和验证样本数据;利用每一类样本数据中的训练样本数据,分别对对应的多个第一备选ai模型进行训练,获得每一类训练样本数据对应的多个训练完成的第一备选ai模型;根据每一类样本数据中的验证样本数据,获得对应的训练完成的第一备选ai模型的性能参数,性能参数指示训练完成的第一备选ai模型对目标事件进行预测的结果的准确度;在每一类训练样本数据对应的多个训练完成的第一备选ai模型中,将性能参数所指示的准确度最高的第一备选ai模型,确定为根据对应一类样本数据确定的第一ai模型。
31.在一种可实现方式中,第二确定模块,具体用于:输入多类样本数据中的每一类训练样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类训练样本数据的目标隐含层训练特征;根据多个目标隐含层训练特征生成融合训练特征;利用融合训练特征,分别对多个第二备选ai模型进行训练,获得多个训练完成的第二备选ai模型;输入多类样本数据中的每一类验证样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类验证样本数据的目标隐含层验证特征;根据多个目标隐含层验证特征生成融合验证特征;根据融合验证特征,分别获得多个训练完成的第二备选ai模型的性能参数,性能参数指示训练完成的第二备选ai模型对目标事件进行预测的结果的准确度;在多个训练完成的第二备选ai模型中,将性能参数所指示的准确度最高的第二备选ai模型确定为第二ai模型。
32.在一种可实现方式中,融合模块,具体用于:对多个目标隐含层特征进行拼接处理,得到融合特征。
33.在一种可实现方式中,第一ai模型的结构为残差网络结构或密集连接网络;和/或,第二ai模型的结构为残差网络结构或密集连接网络。
34.第三方面,本申请提供了一种计算设备,计算设备包括处理器和存储器;存储器中存储有计算机程序;处理器执行计算机程序时,计算设备执行第一方面提供的利用ai模型组分析多类数据的方法。
35.第四方面,本申请提供了一种计算机可读存储介质,该计算机可读存储介质可以为非瞬态的可读存储介质,当计算机可读存储介质中的指令被计算机执行时,该计算机实现第一方面提供的利用ai模型组分析多类数据的方法。该存储介质包括但不限于易失性存储器,例如随机访问存储器,非易失性存储器,例如快闪存储器、硬盘(hard disk drive,hdd)、固态硬盘(solid state drive,ssd)。
36.第五方面,本申请提供了一种计算机程序产品,计算机程序产品包括计算机指令,在被计算设备执行时,计算设备执行第一方面提供的利用ai模型组分析多类数据的方法。该计算机程序产品可以为一个软件安装包,在需要使用第一方面的利用ai模型组分析多类数据的方法的情况下,可以下载该计算机程序产品并在计算设备上执行该计算机程序产品。
附图说明
37.图1是本申请实施例提供的一种多层感知机的结构示意图;
38.图2是本申请实施例提供的一种resnet的结构示意图;
39.图3是本申请实施例提供的一种densenet的结构示意图;
40.图4是本申请实施例提供的一种预测装置的部署示意图;
41.图5是本申请实施例提供的一种预测装置的结构示意图;
42.图6是本申请实施例提供的一种计算设备的结构示意图;
43.图7是本申请实施例提供的一种训练ai模型组的方法流程图;
44.图8是本申请实施例提供的一种根据一类样本数据确定一个第一ai模型的方法流程图;
45.图9是本申请实施例提供的一种确定第一ai模型的方法流程图;
46.图10是本申请实施例提供的另一种确定第一ai模型的方法流程图;
47.图11是本申请实施例提供的一种确定第二ai模型的方法流程图;
48.图12是本申请实施例提供的一种根据多个目标隐含层训练特征生成融合训练特征,并将融合训练特征输入至第二备选ai模型的原理示意图;
49.图13是本申请实施例提供的一种利用ai模型组分析多类数据,对目标事件进行预测的方法流程图;
50.图14是本申请实施例提供的一种利用ai模型组分析多类数据装置的结构示意图。
具体实施方式
51.为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
52.目标事件的结果可能受到多方面的因素影响,该多方面的因素中的每一方面因素
均可以采用一类数据表示,因此,在对目标事件进行预测时,可以对多类数据进行分析,以获取每一类数据的特征,并根据该多类数据的特征对目标事件进行预测。例如,细胞系的生理特性受到该细胞系的多类组学数据(如基因突变数据和基因表达数据)的影响,通过对多类组学数据进行分析,能够获取该细胞系从不同方面表现的生理特征,并根据多类组学数据预测细胞系的生理特性,以保证对细胞系的生理特性进行预测的准确性。
53.相关技术中,可以采用多层感知机根据影响目标事件的结果的多类数据,对目标事件进行预测。并且,将该多类数据输入多层感知机的实现方法是:将用于表示多类数据中每类数据的矩阵按预设方式进行拼接,然后将经过拼接处理后的矩阵输入至多层感知机。
54.但是,由于该多类数据的分布差异通常较大,且数据类型不同(如多类组学数据中的基因突变数据为离散型数据,基因表达数据为连续型数据),并且,当用于采集数据的样本来源不同时,采集得到的数据之间也会存在批次差异,因此,当直接将用于表示多类数据的矩阵进行拼接并输入多层感知机时,多层感知机较难同时适配于多类数据,导致较难有效提取多类数据的特征,影响多层感知机根据数据的特征对目标事件进行预测的准确度。
55.本申请实施例提供了一种利用ai模型组分析多类数据的方法,该方法通过采用ai模型组中多个第一ai模型中的每一个第一ai模型,分别对多类数据中的每类数据进行分析,然后根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征,再根据该多个目标隐含层获取融合特征,采用第二ai模型根据融合特征对目标事件进行预测,相较于相关技术,由于预先采用多个第一ai模型分别获取多类数据的特征,然后对用于表示多类数据的特征的融合特征进行分析,使得ai模型组可以深度地挖掘每一类数据的特征,充分利用每一类数据的特征,有效地提高了根据多类数据对目标事件进行预测的准确性。
56.为便于理解,下面先对本申请实施例涉及的名词进行解释。
57.人工智能(artificial intelligence,ai),指在计算机科学的基础上,综合信息论、心理学、生理学、语言学、逻辑学和数学等知识,制造能模拟人类智能行为的计算机系统的学科。目前人工智能受到了学术界和工业界的广泛关注,ai的应用越来越广泛,其在不少应用领域都超乎普通人类水平。例如:ai技术在机器视觉领域(人类识别、图像分类、物体检测等)的应用使得机器视觉的准确率高于人类,ai技术在自然语言处理和推荐系统等领域也有较好的应用。
58.机器学习,是一种实现ai的核心手段,计算机针对要解决的技术问题,根据已有的数据构建一种ai模型,再利用ai模型预测结果,这种方法使得计算机像模仿人类的学习能力(例如:认知能力、辨别能力、分类能力)去解决技术问题,因此将这种方法称为机器学习。
59.ai模型,是利用机器学习实现ai的各种应用时所用到的数学模型(例如:神经网络(neuralnetwork)模型),ai模型本质是一种算法,其包括大量的参数和计算公式(或计算规则)。ai模型可以采用学习输入数据的内在规律和表示层次,以获取用于输入与输出之间映射关系的非线性函数,并根据该非线性函数对新的输入数据进行处理和分析。ai模型可用于生物、医疗、交通等多个应用场景,例如:当目标事件为预测细胞系对药物的敏感程度时,可以将细胞系的基因突变数据和基因表达数据等多类数据输入至ai模型,以使用该ai模型预测该细胞系对药物的敏感程度等。
60.ai模型多种多样,不同的应用场景和目标事件可采用不同的ai模型。
61.人工神经网络(artificial neural networks,anns)模型,也称为神经网络(nns)
模型或连接模型(connection model),神经网络模型是ai模型的一种典型代表。神经网络模型是一种模仿人脑神经网络的行为特征,进行分布式并行信息处理的数学计算模型。它的主要任务是借鉴人脑神经网络的原理,根据应用需求建造实用的人工神经网络,实现适用于应用需求的学习算法设计,模拟出人脑的智能活动,然后在技术上解决实际问题。神经网络是依靠网络结构的复杂程度,通过调整内部大量节点之间相互连接的关系,实现相应学习算法的设计的。
62.一个神经网络模型可以包括多种不同功能的神经网络层,每层包括参数和计算公式。根据计算公式的不同或功能的不同,神经网络模型中不同的层有不同的名称,例如:进行卷积计算的层称为卷积层,该卷积层常用于对输入信号(例如:图像)进行特征提取。一个神经网络模型也可以由多个已有的神经网络子模型组合构成。不同结构的神经网络模型可用于不同的场景(例如:分类、识别)或在用于同一场景时提供不同的效果,神经网络模型的结构不同主要体现为以下一项或多项:神经网络模型中网络层的层数不同、各个网络层的顺序不同、每个网络层中的权重、参数或计算公式不同。神经元,是神经网络模型的基本单元,神经元用于根据向其输入的多个输入向量和输入向量的权重进行计算,并将计算结果输出。其中,假设神经元共有n个输入向量,n个输入向量中的第i个输入向量为xi,该输入向量xi的权重为ωi,则该神经元的输入输出关系满足:
[0063][0064]
其中,f是神经元的激活函数,该激活函数用于将非线性引入神经元的输出,不同神经元所使用的激活函数可以根据应用需求确定。b为偏置,用于向神经元提供可训练的常量值。神经网络模型也有多种多样。
[0065]
多层感知机,是前向传播神经网络模型中的一种,mlp包括多种不同功能的网络层,分别为:一个输入层、一个输出层、一个或多个隐含层,一个或多个隐含层位于输入层和输出层之间,且mlp中隐含层的数量可以根据应用需求确定。在mlp中,信息单向传递,即信息由输入层开始前向移动,然后在一个或多个隐含层中逐层传递,再由最后一层隐含层传递至输出层。
[0066]
如图1所示,输入层包括多个神经元,输入层中的神经元又称输入节点,该输入节点用于接收从外部输入的输入向量,并将该输入向量传递至与其连接的隐含层中的神经元。其中,该输入节点不执行计算操作。
[0067]
如图1所示,隐含层包括多个神经元,隐含层中的神经元又称隐含节点,隐含节点用于根据向该隐含层输入的输入向量,提取该输入向量的特征,并将该特征传递至下一层中的神经元。且隐含节点提取特征的实现方式为:根据位于上一层的神经元的输出向量、及该隐含节点与该前一层神经元之间连接的权重值,按照该隐含节点的输入输出关系确定该隐含节点的输出向量。其中,上一层是指向该隐含节点所在隐含层输入信息的网络层,下一层是指接收该隐含节点所在隐含层输出信息的网络层。
[0068]
如图1所示,输出层包括一个或多个神经元,输出层中的神经元又称输出节点,该输出节点可以按照该输出节点的输入输出关系,根据其连接的隐含节点的输出向量、及其连接的隐含节点与该输出节点之间的权重值,确定该输出节点的输出向量,并将该输出向量传递至外部。
[0069]
其中,多层感知机相邻层之间全连接,即对于任意相邻的两层,上一层中的任一神经元均与下一层中的所有神经元连接。且相邻层的神经元之间的连接均配置有权重。
[0070]
残差网络(residual network,resnet):是神经网络中的一种,resnet也具有输入层、输出层和一个或多个隐含层,各层的功能请相应参考mlp中对应各层的功能。但是,resnet中各层的连接关系与mlp中各层的连接关系稍有不同。该不同主要表现为:该resnet中包含有跳跃连接(skip connection)或者捷径(short-cuts)连接。
[0071]
如图2所示,在resnet中,每一层网络将上一层的输入和输出作为输入,通过该连接方式,建立了前面层与后面层之间的捷径连接,使得上一层的输入可以直达当前层的输出,相应的,第n层的输出y
n
是第n-1层的输出y
n-1
加上对第n-1层输出的非线性变换f(y
n-1
),即y
n
=f(y
n-1
)+y
n-1
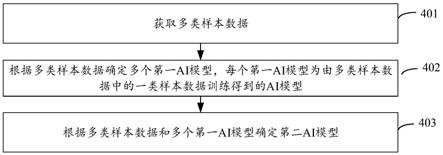
。这样可以使resnet的学习目标不再是学习一个完整的输出,而由原来的输出f(y
n-1
)变成输出与输入的差(即残差)y
n-y
n-1
,简化了resnet的学习目标和难度。这种连接方式提高了信息在网络中的流通程度,避免了由于网络过深所引起的消失梯度问题和退化问题,有助于训练过程中梯度的反向传播,从而能训练出网络层数更深的网络。
[0072]
其中,跳跃连接:是某一层的神经网络将前一层网络的输入和输出作为输入。这种连接方式也称做残差连接。捷径连接,是指直接将神经元的输入x传到该神经元的输出作为初始结果,使得该神经元的输出结果为y
n
=f(y
n-1
)+y
n-1
。
[0073]
密集连接网络(densely connected networks,densenet),是一种具有密集连接的卷积神经网络。densenet也具有输入层、输出层和一个或多个隐含层,各层的功能请相应参考mlp中对应各层的功能。但是,densenet中各层的连接关系与mlp中各层的连接关系稍有不同。该不同主要表现为:在densenet中,任何两层之间都有直接的连接,也即是,网络每一层的输入向量都是前面所有层输出向量的拼接向量,而每一层所学习的特征也会被直接传给其后面所有层作为输入,这实现了特征重用,提高了特征利用效率,且由于每个层从前面的所有层接收特征映射,使得网络可以更薄、网络结构更紧凑。如图3所示,第n层的输入向量不仅与第n-1层的输出向量yn-1相关,还有所有之前层的输出向量有关,因此,第n层的输出向量yn=f([y0,y1,
…
,y
n-1
]),其中,[y0,y1,
…
,y
n-1
]代表对y0,y1,
…
,y
n-1
执行拼接操作,该拼接操作是指将第0到n-1层的所有输出向量按通道组合在一起。
[0074]
在本申请实施例中,利用ai模型组分析多类数据,对目标事件进行预测的操作可以由预测装置执行。图4是本申请实施例提供的一种预测装置的部署示意图,如图4所示,该预测装置300可部署在云环境中,该云环境是云计算模式下利用基础资源向用户提供云服务的实体。云环境包括云数据中心和云服务平台,云数据中心包括云服务提供商拥有的大量基础资源(包括计算资源、存储资源和网络资源),云数据中心包括的计算资源可以是大量的计算设备(例如服务器)。可选的,预测装置300可以是云数据中心中用于对目标事件进行预测的服务器,也可以是创建在云数据中心中的用于对目标事件进行预测的虚拟机,还可以是部署在云数据中心中的服务器或者虚拟机上的软件装置。当预测装置300为部署在云数据中心中的服务器或者虚拟机上的软件装置时,该软件装置可以分布式地部署在多个服务器上、或者分布式地部署在多个虚拟机上、或者分布式地部署在虚拟机和服务器上。
[0075]
如图4所示,预测装置300可以由云服务提供商在云服务平台上,抽象成一种对目标事件进行预测的云服务,用户在云服务平台购买该云服务后,云环境可以利用该预测装置300向用户提供对目标事件进行预测的云服务。并且,用户可以在终端上通过应用程序接
口(application program interface,api),或者云服务平台提供的网页界面,将影响目标事件的结果的多类数据上传至云环境,以供预测装置300根据多类数据对目标事件进行预测。在完成分析后,预测装置300可以将预测结果发送至用户使用的终端,或者可以将预测结果存储在云环境,例如:呈现在云服务平台的网页界面上,以供用户查看。
[0076]
或者,该预测装置300可以由服务提供商以应用程序的形式发布,用户可以将该应用程序下载至用户使用的终端中,并在终端中使用该应用程序。
[0077]
当预测装置300为软件装置时,预测装置300可以在逻辑上分成多个部分,每个部分具有不同的功能。例如,如图5所示,预测装置300可以包括:第一获取模块301、提取模块302、融合模块303和预测模块304。其中,第一获取模块301可以获取多类数据,并将多类数据发送至提取模块302。提取模块302中可以部署有多个第一ai模型,提取模块302可以将接收到的多类数据对应输入至多个第一ai模型,以使用多个第一ai模型分别对对应类数据进行分析,并根据第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征。融合模块303可以获取多个目标隐含层特征,根据多个目标隐含层特征生成融合特征,并将融合特征发送至预测模块304。预测模块304中可以部署有第二ai模型,预测模块304可以将融合特征输入至第二ai模型,使用第二ai模型对融合特征进行分析,并根据该第二ai模型的预测结果输出预测值,该预测值指示根据多类数据对目标事件进行预测的结果。
[0078]
其中,每个第一ai模型包括输入层、输出层、一个或多个隐含层,多个第一ai模型的模型结构可以相同或不同,并且,任一第一ai模型的模型结构和第二ai模型的模型结构也可以相同或不同。ai模型的模型结构由ai模型的网络结构类型、ai模型中网络层数、每个网络层中神经元的数量和神经元之间连接方式、对模型进行训练时的批次输入数量、学习率和优化学习率的策略等模型参数定义。当两个ai模型的所有模型参数对应相同时,可以确定该两个ai模型的模型结构相同,当两个ai模型的模型参数中的任一个对应不同时,确定该两个ai模型的模型结构不同。
[0079]
并且,不同第一ai模型的目标隐含层在对应第一ai模型中的次序可以相同或不同。例如,当多个第一ai模型的模型结构相同时,每个第一ai模型的目标隐含层可以为对应第一ai模型中多个隐含层中最后一层隐含层。又例如,当多个第一ai模型的模型结构相同时,有的第一ai模型的目标隐含层可以为对应第一ai模型中多个隐含层中最后一层隐含层,有的第一ai模型的目标隐含层可以为对应第一ai模型中多个隐含层中倒数第二层隐含层。
[0080]
预测装置300的几个部分可以分别部署在不同的环境或设备中,例如:预测装置300中的一部分部署在云数据中心(具体部署在云数据中心中的服务器或虚拟机上),另一部分部署在边缘数据中心(具体部署在边缘数据中心中的服务器或虚拟机上),该边缘数据中心是部署在距离终端较近的边缘计算设备的集合。部署在不同环境或设备的预测装置300的各个部分之间协同实现根据多类数据对目标事件进行预测的功能。例如,在一种场景下,边缘数据中心中部署有第一获取模块301,云数据中心上部署有提取模块302、融合模块303和预测模块304,边缘数据中心通过第一获取模块301获取多类数据后,可以将多类数据发送至云数据中心中的提取模块302,以使用该提取模块302通过多个第一ai模型获得多类数据的目标隐含层特征,并通过融合模块303生成融合特征,然后使用预测模块304通过第二ai模型根据融合特征对目标事件进行预测,并通过该预测模块304将预测结果发送至用
户使用的终端。
[0081]
应理解的是,本申请不对预测装置300中各部分的部署方式进行限制性的划分,实际应用时可根据终端计算设备的计算能力或具体应用需求进行适应性的部署。并且,预测装置300的划分方式也不限于上述划分方式,上述划分方式仅为示意性的举例。
[0082]
在一种可实现方式中,当预测装置为软件装置时,预测装置也可以单独部署在任意环境的一个计算设备上。如图6所示,该计算设备100包括总线101、处理器102、通信接口103和存储器104。处理器102、存储器104和通信接口103之间通过总线101通信。
[0083]
其中,处理器102可以是硬件芯片,该硬件芯片可以是专用集成电路(application-specific integrated circuit,asic),可编程逻辑器件(programmable logic device,pld)或其组合。上述pld可以是复杂可编程逻辑器件(complex programmable logic device,cpld),现场可编程逻辑门阵列(field-programmable gate array,fpga),通用阵列逻辑(generic array logic,gal)或其任意组合。处理器810也可以是通用处理器,例如,中央处理器(central processing unit,cpu),网络处理器(network processor,np)或者cpu和np的组合。
[0084]
存储器104可以包括易失性存储器(volatile memory),例如随机存取存储器(random access memory,ram)。存储器104还可以包括非易失性存储器(non-volatile memory,nvm),例如只读存储器(read-only memory,rom),快闪存储器,hdd或ssd。存储器104中存储有预测装置所包括的可执行代码,处理器102读取存储器104中的该可执行代码以执行本申请实施例提供的利用ai模型组分析多类数据的方法。存储器104中还可以包括操作系统等其他运行进程所需的软件模块。操作系统可以为linux
tm
,unix
tm
,windows
tm
等。
[0085]
在本申请实施例中,第一ai模型和第二ai模型在被用于分析多类数据之前,需要先对多个第一ai模型和第二ai模型进行训练。该对多个第一ai模型和第二ai模型进行训练的操作可以由预测装置执行,即对模型的训练操作和利用完成的模型对目标事件进行预测的操作可以均由预测装置执行,或者,对多个第一ai模型和第二ai模型进行训练的操作可以由训练装置执行,即对模型的训练操作和利用完成的模型对目标事件进行预测的操作可以由不同的装置执行,本申请实施例对其不做具体限定。并且,当使用不同的装置执行预测操作和训练操作时,训练完的第一ai模型和第二ai模型会被部署于预测装置中。
[0086]
下面以由训练装置对多个第一ai模型和第二ai模型进行训练为例,对模型训练过程进行说明,使用预测装置对多个第一ai模型和第二ai模型进行训练的过程可以相应参考采用训练装置进行训练的实现过程。训练装置可以预先获取多类样本数据,该多类样本数据分别与多个第一ai模型对应,然后采用每一类样本数据,对与每一类样本数据对应的第一ai模型进行训练,并在完成多个第一ai模型的训练后,再分别向每个训练完成的第一ai模型输入对应的一类样本数据,并获取每个第一ai模型的目标隐含层针对对应的一类样本数据的目标隐含层训练特征,然后基于多个目标隐含层训练特征生成融合训练特征,并使用该融合训练特征对第二ai模型进行训练。
[0087]
其中,对任一ai模型进行训练的实质是以学习目标为标准,根据训练样本数据调整ai模型中的权重值等参数,使得训练完成的ai模型能够达到该学习目标。在有监督的训练过程中,学习目标可以通过样本标签和训练过程中ai模型根据训练样本数据对目标事件的预测结果体现。一种可实现方式中,该学习目标可以为ai模型根据训练样本数据对目标
事件的实际预测结果与样本标签所指示的期望预测结果的误差在指定范围内。因此,训练样本数据中还携带有样本标签,样本标签用于指示ai模型针对训练样本数据对目标事件的期望预测结果。此时,训练完成的ai模型能够达到该学习目标是指,该训练完成的ai模型针对训练样本数据的实际预测结果相对于期望预测结果的误差在指定范围内。
[0088]
例如,在需要使用第一ai模型预测细胞系对某药物的敏感程度时,目标事件指该细胞系对该药物的敏感程度,此时,每个细胞系的样本标签用于指示该细胞系对该药物的敏感程度,此该样本标签的可以为一个数值。相应的,训练完成的第一ai模型能够达到该学习目标是指,训练完成的第一ai模型针对输入的细胞系的训练样本数据预测出的敏感程度,与该训练样本数据携带的样本标签所指示的敏感程度的差值小于指定差值阈值。
[0089]
又例如,在需要使用第一ai模型分析多个细胞系对多种药物的敏感程度时,目标事件指该多个细胞系分别对多种药物的敏感程度,此时,多个细胞系的样本标签用于指示多个细胞系分别对多种药物的敏感程度,该样本标签可以为一向量,且该向量可以使用矩阵表示,该矩阵的多个行的行名分别为多个细胞系的名称,该矩阵的多个列的列名分别为多种药物的名称,该矩阵某行某列的元素为该行行名所指代的细胞系对该列的列名所指代的药物的敏感程度。相应的,训练完成的第一ai模型能够达到该学习目标的一种可能的描述为,训练完成的第一ai模型针对输入的任一种细胞系的训练样本数据预测出的该任一细胞系对任一种药物的敏感程度,与该训练样本数据携带的样本标签所指示的该任一细胞系对任一种药物的敏感程度的差值小于指定差值阈值。需要说明的是,此处对学习目标是一种示意性的实例,并不用于限定本申请。其中,第一ai模型的输出也可以采用矩阵表示,该矩阵的形式与样本标签对应的矩阵的形式相同。
[0090]
需要说明的是,本申请实施例中,在利用ai模型组分析多类数据,以对目标事件进行预测的方法中,ai模型组中的多个第一ai模型和第二ai模型均用于对同一目标事件进行预测,且该多个第一ai模型和第二ai模型的学习目标也可以相同。例如,当ai模型组用于对目标事件进行预测是指预测细胞系对某药物的敏感程度时,多个第一ai模型和第二ai模型均用于预测细胞系对某药物的敏感程度,此时,多个第一ai模型和第二ai模型的学习目标均可以是针对输入的细胞系的训练样本数据预测出的敏感程度,与该训练样本数据携带的样本标签所指示的敏感程度的差值小于指定差值阈值。
[0091]
并且,当多个第一ai模型和第二ai模型的作用,及多个第一ai模型和第二ai模型的学习目标相同时,能够保证通过多个第一ai模型提取的数据的特征与第二ai模型提取的特征的匹配程度,提高第二ai模型对多类数据的适配程度,进而提高对目标事件进行预测的准确度。
[0092]
下面结合图5对训练装置200和预测装置300的结构和功能进行介绍,应理解,本申请实施例仅是对训练装置200和预测装置300的结构和功能模块进行的示例性划分,本申请并不对其具体划分做任何限定。
[0093]
训练装置200用于对第一ai模型和第二ai模型进行训练,对第一ai模型和第二ai模型进行训练所需的训练样本数据可以被保存在数据库中。该训练样本数据可通过采集装置采集获得,例如,当该训练样本数据为细胞系的组学数据时,该采集装置可以为基因测序装置,该组学数据可以由基因测序装置对细胞系进行基因测序得到,且训练样本数据所携带的标签可以人工标注等方式得到。或者,也可不需要采集装置采集训练样本数据,例如:
可以从第三方直接获得该训练样本数据。其中,组学数据可以为基因突变数据、基因表达数据、脱氧核糖核酸(dna)甲基化数据、拷贝数变异数据、微核糖核酸(microrna)表达数据、组蛋白修饰数据、基因融合数据、染色体异构数据或代谢物表达数据等。
[0094]
训练装置200可以包括初始化模块201和训练模块202。在任一模型的训练过程中,初始化模块201用于对在启动对该模型的训练时,对该模型中的每个网络层的参数进行初始化(即向每个参数赋予一个初始值)。该训练模块202用于读取数据库中的样本数据对该模型进行训练,直到得到性能较好的模型,确定完成该模型的训练。
[0095]
训练装置200可以是软件装置,此时,该训练装置20的部署方式可以参考预测装置300的部署方式,例如,该训练装置200可以整个部署在同一计算设备上,也可以各部分分别部署在不同的计算设备上,且当各部分分别部署在不同的计算设备上时,不同的计算设备协同运行训练装置200中的各部分以实现训练装置200的全部功能。
[0096]
并且,当训练装置200和预测装置300都为软件装置时,训练装置200可与预测装置300部署在同一台计算设备上(例如:部署在同一台服务器上、或者部署在同一台服务器中的两个不同的虚拟机上)、训练装置200也可以与预测装置300部署在不同的计算设备上(例如:训练装置200部署在云环境中的一个或多个服务器上,预测装置300部署在边缘环境中的一个或多个服务器上)。
[0097]
值得注意的是,第一ai模型和第二ai模型也可由两个训练装置分别进行训练。或者,第一ai模型和/或第二ai模型还可以不需要由训练装置200进行训练,例如:第一ai模型和/或第二ai模型可以是由第三方已训练好的,且对样本对象的样本数据具有较高分析准确度的神经网络。
[0098]
下面对本申请实施例提供的利用ai模型组分析多类数据的方法的实现过程进行说明。该实现过程可以包括两个阶段,在第一阶段中对ai模型组进行训练,在第二阶段中采用训练完成的ai模型组对目标事件进行预测。因此,本申请实施例分别针对该两个阶段,对该利用ai模型组分析多类数据的方法的实现过程进行说明。
[0099]
图7是本申请实施例提供的一种训练ai模型组的方法流程图。如图7所示,该方法包括:
[0100]
步骤401、获取多类样本数据。
[0101]
在获取样本数据的一种可实现方式中,可以直接从第三方获取样本数据。目前,很多研究机构会开发一些样本库,例如,耶鲁大学开发的yale人脸库,剑桥大学开发的orl人脸库,英国桑格研究院开发的抗癌药物敏感性基因组学(genomics of drug sensitivity in cancer,gdsc)数据库,因此,可以直接从样本库中获取所需的样本数据。
[0102]
在获取样本数据的另一种实现方式中,可以采用采集装置采集样本数据。并且,根据不同的应用需求,该采用采集装置采集样本数据的实现方式至少可以分为以下两种:一种为直接采集样本数据。例如,可以采用图像采集设备、声音采集设备或指纹采集设备等采集设备采集信息,并将采集到的信息直接用作样本数据。另一种为样本数据的间接采集,该采集过程主要包括:在获取样本后,对样本执行预设的分析操作,并将预测结果用作样本数据。例如,当样本数据为细胞系的组学数据时,该样本数据的获取过程可以包括:先采集包括有样本细胞系的样本组织,然后,通过基因测序等方式获取样本组织中样本细胞系的组学数据。
[0103]
并且,可以通过有监督的训练过程确定第一ai模型。因此,样本数据中还可以携带有样本标签,样本数据中携带的样本标签可以为:向ai模型输入该样本数据后,该ai模型针对该样本数据应该输出的期望预测结果。相应的,对ai模型进行训练的过程,即为根据该期望预测结果和ai模型的实际预测结果,不断调节ai模型中权重值等参数的过程。并且,由于多类数据中的每一类数据表示影响目标事件的结果的一方面因素,即该多类数据对该目标事件的预测结果均会产生影响,因此,该多类数据所携带的样本标签相同。
[0104]
示例的,假设第一ai模型用于预测细胞系对药物的敏感程度,即目标事件为细胞系对药物的敏感程度,对第一ai模型进行训练时,样本细胞系的样本数据可以包括:样本细胞系的基因突变数据和基因表达数据等基因组学数据。此时,该样本数据携带的样本标签用于指示样本细胞系对药物的敏感程度。相应的,训练完成的第一ai模型能够达到学习目标是指,训练完成的第一ai模型针对样本细胞系的样本数据预测出的敏感程度,与该训练样本数据携带的样本标签所指示的敏感程度的差值小于指定差值阈值。
[0105]
步骤402、根据多类样本数据确定多个第一ai模型,每个第一ai模型为由多类样本数据中的一类样本数据训练得到的ai模型。
[0106]
该多个第一ai模型均用于根据对应一类样本数据对目标事件进行预测。通过根据多类样本数据确定多个第一ai模型,建立了多个第一ai模型与多类样本数据的对应关系,即建立了多个第一ai模型与多种类型的数据的对应关系,使得在后续根据多类数据对目标事件进行预测的过程中,可以按照该对应关系,向每个第一ai模型输入对应的一类数据,并使用对应的第一ai模型对该对应一类数据进行分析。为保证描述的简便与清楚,该步骤402中的技术细节在后文中进行描述。
[0107]
步骤403、根据多类样本数据和多个第一ai模型确定第二ai模型。
[0108]
其中,第二ai模型为由多类样本数据对应的融合样本特征训练得到的ai模型。该融合样本特征根据多个第一ai模型的目标隐含层特征得到,使得该融合样本特征能够体现多类数据的特征,根据多类样本数据的融合样本特征训练第二ai模型时,能够充分利用每一类数据的特征,能够提高训练得到的第二ai模型的模型性能。为保证描述的简便与清楚,该步骤403中的技术细节在后文中进行描述。
[0109]
在完成多个第一ai模型和第二ai模型的确定后,即确定了每个第一ai模型和第二ai模型的模型结构和模型中神经元之间连接的权重值。此时,可以将多个第一ai模型部署至提取模块中,将第二ai模型部署至预测装置中,以便于预测装置采用该多个第一ai模型和第二a模型对目标事件进行预测。
[0110]
下面以根据一类样本数据确定一个第一ai模型的实现过程为例,对上述步骤402的实现过程进行说明,该ai模型组中其他第一ai模型的确定过程,请相应参考该第一ai模型的确定过程。如图8所示,该实现过程可以包括:
[0111]
步骤4021、将一类样本数据划分为训练样本数据和验证样本数据。
[0112]
在训练第一ai模型的过程中,训练模块202可以根据训练样本数据,及训练样本数据携带的样本标签,对第一ai模型进行训练,直到第一ai模型输出的预测结果满足学习目标,确定完成该第一ai模型的训练。在训练完成后,训练模块202可以将验证样本数据输入训练完成的第一ai模型,并根据训练完成的第一ai模型针对验证样本数据的预测结果,及验证样本数据携带的样本标签,计算训练完成的第一ai模型的性能参数,该性能参数用于
指示训练完成的第一ai模型对目标事件进行预测的结果的准确度。
[0113]
每类样本数据可以为来源于多个样本对象的样本数据,在将一类样本数据划分为训练样本数据和验证样本数据时,可以以样本对象为单位,将来源于多个样本对象的一类样本数据划分为训练样本数据和验证样本数据,以根据来源于一部分样本对象的样本参数调整第一ai模型的参数,根据来源于另一部分样本对象的样本参数计算第一ai模型的性能参数。示例的,假设一类样本数据为来源于936个样本细胞系的样本基因突变数据,每个样本细胞系对应的样本数据为用于表示该样本细胞系的19350个基因的突变情况的样本基因突变数据,在将来源于该多个样本细胞系的样本基因突变数据划分为训练样本数据和验证样本数据时,可以将该936个样本细胞系的一部分细胞系对应的样本基因突变数据划分为训练样本数据,将该936个样本细胞系的另一部分细胞系对应的样本基因突变数据划分为验证样本数据。或者,可以按照预设比例(如8:2),将来源于该多个样本细胞系的样本基因突变数据随机地划分为训练样本数据和验证样本数据。
[0114]
步骤4022、基于一类样本数据中的训练样本数据和验证样本数据,确定第一ai模型。
[0115]
该步骤4022至少具有以下两种可实现方式:在一种可实现方式中,可以对模型结构已确定的第一预置模型进行训练,在该训练过程中根据学习目标调整该第一预置模型的权重值等参数,训练完成的第一预置模型即为根据该一类样本数据确定的第一ai模型。在另一种可实现方式中,可以采用模型搜索的方法搜索第一备选模型的结构,并在搜索过程中对搜索到的第一备选模型进行训练,以调整每个第一备选模型中权重值等参数,然后在训练完成的多个第一备选模型中确定作为第一ai模型的第一备选模型。
[0116]
下面先结合图9对该步骤4022的第一种可实现方式进行说明。如图9所示,对模型结构已确定的第一预置模型进行训练的过程,可以包括以下步骤:
[0117]
步骤4022a1、初始化第一预置模型中神经元之间连接的权重值等参数。
[0118]
初始化参数是指对参数赋予初始值。在一种可实现方式中,可以采用初始化模块201初始化第一预置模型中神经元之间连接的权重值等参数。该第一预置模型可以为业界已存在且预测性能较好的ai模型。例如:该第一预置模型可以为resnet、mlp或densenet等ai模型。
[0119]
步骤4022a2、将携带有样本标签的训练样本数据,按照指定的批次输入数量,分批次输入至第一预置模型。
[0120]
在一种可实现方式中,训练模块202可以将携带有样本标签的训练样本数据,按照指定的批次输入数量,分批次输入至第一预置模型。其中,批次输入数量是指对模型进行训练时每批次输入的样本对象的数量(即batch size)。
[0121]
例如,假设第一ai模型用于分析细胞系对药物的敏感程度,样本数据为来源于936个样本细胞系的样本基因突变数据,且来源于每个样本细胞系的样本基因突变数据为用于表示该样本细胞系的19350个基因的突变情况的样本基因突变数据,因此,该样本基因突变数据可以采用大小为936
×
19350的矩阵表示。且在步骤4021中预先将该样本基因突变数据分为训练样本基因突变数据和验证样本基因突变数据,训练样本基因突变数据包括来源于800个样本细胞系的样本基因突变数据,即该训练样本基因突变数据的大小为800
×
19350,验证样本基因突变数据包括来源于136个样本细胞系的样本基因突变数据,即验证样本基
因突变数据的大小为136
×
19350。
[0122]
当假设该第一预置模型的batch size为64时,在向第一预置模型输入训练样本数据的过程中,可以每次向第一预置模型输入64个细胞系的训练样本基因突变数据,即每批次的输入量为64
×
19350,直至将所有训练样本基因突变数据均输入至第一预置模型。
[0123]
步骤4022a3、针对每批次训练样本数据,获取该第一预置模型对该批次的训练样本数据的实际预测结果,并确定该实际预测结果与该批次的训练样本数据中携带的样本标签所指示的期望预测结果的误差。
[0124]
训练模块202将每批次的训练样本数据输入至第一预置模型后,可以获取该第一预置模型针对该批次的训练样本数据的实际预测结果,并确定该实际预测结果相对于期望预测结果的误差。并且,由于每批次输入的训练样本数据包括来源于多个样本对象的样本数据,在该步骤4022c中,可以分别针对每个样本对象获取误差,然后将该多个样本对象的误差的均值确定为该批次训练样本数据对应的误差。
[0125]
仍以步骤4022a2中的例子为例,假设每批次输入64个细胞系的训练样本基因突变数据,则第一预置模型针对每批次的输入有64个实际预测结果,可以根据任一细胞系对应的期望预测结果和第一预置模型针对该任一细胞系的训练样本基因突变数据的实际预测结果,确定该任一细胞系对应的误差,然后将该64个细胞系对应的误差的平均值确定为第一预置模型针对本批次样本数据的误差。
[0126]
步骤4022a4、将携带有样本标签的验证样本数据,按照指定的批次输入数量,分批次输入至第一预置模型。
[0127]
该步骤4022a4的实现过程请相应参考步骤4022a2的实现过程。
[0128]
步骤4022a5、针对每批次验证样本数据,获取该第一预置模型对该批次的验证样本数据的实际预测结果,并确定该实际预测结果与该批次的验证样本数据中携带的样本标签所指示的期望预测结果的误差。
[0129]
该步骤4022a5的实现过程请相应参考步骤4022a3的实现过程。
[0130]
步骤4022a6、根据误差调整第一预置模型中神经元之间连接的权重值等参数。
[0131]
训练模块202可以根据该第一预置模型对应的学习率和优化学习率的策略,调整不同神经元的连接的权重值等参数。
[0132]
步骤4022a7、对调整权重值等参数后的第一预置模型继续执行上述步骤4022a1至步骤4022a6,直到根据训练样本数据确定的误差达到最小值或直到训练次数达到指定训练次数,并将使得根据验证样本数据确定的误差取得最小值时的第一预置模型确定为训练完成的第一预置模型。
[0133]
下面结合图10对该步骤4022的第二种可实现方式进行说明。需要说明的是,本申请不对ai模型搜索的实现方式进行限定,图10所示的ai模型搜索的实现方式仅为一种示例,业界已有的或者未来出现的更优的ai模型搜索实现方式均适用于本申请。如图10所示,采用模型搜索的方法在多个备选模型中进行搜索,确定第一ai模型的实现过程,可以包括以下步骤:
[0134]
步骤4022b1、确定一类样本数据对应的多个第一备选ai模型。
[0135]
每两个第一备选ai模型的一个或多个模型参数不同。可选的,该模型参数可以包括以下一个或多个:ai模型的网络结构类型、ai模型的网络层数、每个网络层中的神经元的
数量、神经元之间连接方式、对模型进行训练时的批次输入数量、学习率和优化学习率的策略等。其中,学习率可以理解为在训练过程中,用于控制根据模型的实际预测结果与期望预测结果的误差调整权重值的超参数。
[0136]
并且,由于输入层中神经元的数量应等于样本数据中特征的总数,且输出层中神经元的数量应根据目标事件确定,因此,模型包括的每层网络中的神经元总数指的是隐含层包括的神经元的总数。例如,假设目标事件为分析936个样本细胞系对265种药物中每种药物的敏感程度,来源于每个样本细胞系的一类样本数据为用于表示该样本细胞系的19350个基因的突变情况的样本基因突变数据,则该第一备选ai模型的输入神经元的总数应为19350,输出神经元的总数应为265,相应的,该第一备选ai模型包括的每层网络中的神经元的数量指的是隐含层包括的神经元的数量,且该隐含层包括的神经元的数量可以根据应用需求确定。
[0137]
在该步骤4022b1中,可以将每个模型参数视为一个变量,并获取每个变量在不同取值时构成的多个模型参数集合,且每两个参数集合中至少存在一个差异变量,每个差异变量在该两个参数集合中的取值不同,每个模型参数集合用于定义一个第一备选ai模型的结构。相应的,对多个模型参数赋予不同的取值得到多个模型参数集合的过程,即为确定多个第一备选ai模型的过程。
[0138]
示例的,各个模型参数的取值可以根据实际需要确定。例如,模型的网络结构类型的取值可以为:mlp、resnet或densenet。模型的网络层数的取值范围可以为[2,20]中的整数。模型包括的每层网络中的神经元总数的取值范围可以为8、16、32、64、512、1024、2048或4096等。batch size的取值可以为32、64或128等。学习率的取值可以为0.1、0.01、0.001或0.0001等。优化学习率的策略可以为:随机梯度下降(stochastic gradient descent,sgd或自适应矩阵估计(adaptive moment estimation,adam)等算法。并且,当模型的网络结构类型为mlp时,该模型的网络结构类型的取值还可以包括:该mlp的结构为矩形结构,该mlp的结构为锥形升序结构,及该mlp的结构为锥形降序结构等。
[0139]
需要说明的是,当根据样本数据确定的第一ai模型的网络结构类型为resnet时,由于该resnet的连接方式提高了信息在网络中的流通程度,避免了由于网络过深所引起的消失梯度问题和退化问题,有助于训练过程中梯度的反向传播,能够保证该第一ai模型的预测准确度。并且,由于该resnet的连接方式能够体现层与层之间的调控作用,当第一ai模型用于分析具有相互影响关系的多类数据时,该resnet能够体现多类数据之间的内部逻辑关系,能够进一步提高分析的准确性。且由于细胞系的基因调控网络复杂,且存在层次之间彼此调控的关系,当该第一ai模型用于分析细胞系的多类基因组学数据时,该作用表现的尤其明显。
[0140]
类似的,当根据样本数据确定的第一ai模型的网络结构类型为densenet时,由于在densenet中,网络每一层的输入向量都是前面所有层输出向量的拼接向量,而每一层所学习的特征也会被直接传给其后面所有层作为输入,因此,也能够体现多类数据之的内部逻辑关系,能够进一步提高预测准确度。
[0141]
步骤4022b2、利用一类样本数据中的训练样本数据,分别对对应的多个第一备选ai模型进行训练,获得该一类训练样本数据对应的多个训练完成的第一备选ai模型。
[0142]
对多个第一备选ai模型进行训练的过程为:分别针对每个模型参数集合指示的一
个第一备选ai模型的模型结构,根据训练样本数据调整该第一备选ai模型的神经元之间连接的权重值等参数,以得到在对应模型结构下具有较好模型性能的第一备选ai模型。该步骤4022b2的实现过程请相应参考步骤4022a1至步骤4022a5,此处不再赘述。
[0143]
步骤4022b3、根据该一类样本数据中的验证样本数据,获得对应的多个训练完成的第一备选ai模型的性能参数,该性能参数指示训练完成的第一备选ai模型对目标事件进行预测的结果的准确度。
[0144]
在该步骤4022b3中,训练模块202在将该验证样本数据输入至每个训练完成的第一备选ai模型后,每个训练完成的第一备选ai模型会根据训练得到的该第一备选ai模型的输入输出关系,针对该验证样本数据产生实际预测结果,训练模块202可以根据每个训练完成的第一备选ai模型的实际预测结果,及验证样本数据携带的样本标签指示的期望预测结果,确定每个训练完成的第一备选ai模型的性能参数。
[0145]
示例的,该性能参数可以为精确率与召回率的调和平均数(即性能参数为f1值)。精确率是针对第一备选ai模型的输出值而言的,它表示的是预测为正的样本中有多少是真正的正样本,该精确率等于将正样本预测为正的样本的总数占所有预测为正的样本的总数的比例。召回率是针对样本而言的,它表示的是样本中的正样本有多少被预测正确了,该召回率等于将正样本预测为正的样本的总数占所有正样本的总数的比例。调和平均数(harmonic mean)又称倒数平均数,是总体各统计变量倒数的算术平均数的倒数。
[0146]
其中,在对目标事件进行预测时,可以通过参考条件对正样本和负样本进行区分,当样本数据携带的样本标签所指示的期望预测结果满足参考条件时,可将该样本数据确定为正样本,当样本数据携带的样本标签所指示的期望预测结果不满足参考条件时,可将该样本数据确定为负样本。类似的,也可以采用参考条件对第一备选ai模型的实际预测结果进行区分,当第一备选ai模型根据样本数据输出的实际预测结果满足参考条件时,可将该样本数据确定为预测为正的样本,当第一备选ai模型根据样本数据输出的实际预测结果不满足参考条件时,可将该样本数据确定为预测为负的样本。
[0147]
例如,样本中的正样本和负样本,及预测为正的样本和预测为负的样本可以通过阈值区分。例如,可以预先设置阈值,当样本数据所携带样本标签所指示的期望预测结果大于或等于该阈值时,将该样本数据确定为正样本,当样本数据所携带样本标签所指示的期望预测结果小于该阈值时,将该样本数据确定为负样本。当第一备选ai模型针对样本数据的实际预测结果大于或等于该阈值时,确定第一备选ai模型对该样本数据的预测为正,当第一备选ai模型针对样本数据的实际预测结果小于该阈值时,确定第一备选ai模型对该样本数据的预测为负。需要说明的是,由于在用于对目标事件进行预测的多类数据中,由于每一类数据表示影响目标事件的结果的一方面因素,即该多类数据对该目标事件的预测结果均会产生影响,因此,该样本对象的多类数据所携带的样本标签的数值相同。
[0148]
又例如,当使用第一备选ai模型预测样本细胞系对某一药物的敏感度时,当样本细胞系的样本组学数据所携带样本标签的数值大于或等于预设阈值时,可以将该样本细胞系的样本组学数据确定为正样本,当样本细胞系的样本组学数据所携带样本标签的数值小于预设阈值时,将该样本细胞系的样本组学数据确定为负样本。当第一备选ai模型针对该样本细胞系的样本组学数据的实际预测值大于或等于该预设阈值时,确定第一备选ai模型对该样本对象的样本组学数据的预测为正,当第一备选ai模型针对该样本细胞系的样本组
学数据的实际预测值小于该预设阈值时,确定第一备选ai模型对该样本对象的样本组学数据的预测为负。
[0149]
需要说明的是,也可以采用10
×
交叉验证方法获得每个训练完成的第一备选ai模型的性能参数。采用10
×
交叉验证方法获得训练完成的第一ai模型的实现过程包括:将该第一ai模型对应的一类样本数据随机均分为10份,先用其中任意9份做训练样本数据,以再次对训练完成的第一ai模型进行训练,然后采用剩余1份作为验证样本数据,并根据第一ai模型针对该验证样本数据的实际预测结果,获得第一ai模型的性能参数,按照该方式循环10次,直到将10份中的每份都用作训练样本数据,训练出10个模型,并获得与该10个模型一一对应的10个性能参数,然后将10个性能参数的均值作为通过10
×
交叉验证方法获得的第一ai模型的性能参数。其中,该性能参数也可以为f1值。
[0150]
步骤4022b4、在一类样本数据对应的多个训练完成的第一备选ai模型中,将性能参数所指示的准确度最高的第一备选ai模型,确定为根据该一类样本数据所确定的第一ai模型。
[0151]
由于任一训练完成的第一备选ai模型的性能参数用于指示该第一备选ai模型对目标事件进行预测的结果的准确度,当训练完成的第一备选ai模型的性能参数所指示的准确度越高,说明该训练完成的第一备选ai模型的预测性能越好,因此,训练模块202可以将性能参数所指示的准确度最高的第一备选ai模型,确定为根据该一类样本数据确定的第一ai模型,以保证第一ai模型的预测准确度。
[0152]
需要说明的是,上述步骤4022b1至步骤4022b4的实现过程具体可以通过网格搜索(gridsearch)方式实现,也即是,可以将每个变量在不同取值时的模型参数集合以表格的形式呈现,每个变量对应表格的一个维度,多个变量中任一变量在对应的维度上的取值不同时,多个变量在对应多个维度上的取值的集合组成一个模型参数集合,该一个模型参数集合的取值可以存放在表格内的对应网格中。相应的,在网格搜索过程中,可以依次遍历每个网格内的取值,采用一类样本数据,对每个网格内的取值所定义的一个第一备选ai模型的结构进行训练,然后,获得每个训练完成的第一备选ai模型的性能参数,并将性能参数所指示的准确度最高的第一备选ai模型,确定为根据该一类样本数据所确定的第一ai模型。
[0153]
以下面例子对网格搜索的实现过程进行举例说明:假设第一备选ai模型有模型参数a和模型参数b,即其对应的表格有两个维度,模型参数a对应一个维度,变量b对应另一个维度,模型参数a的取值可以为a1、a2和a3,模型参数b的取值可以为b1和b2,则可以以表1表示表格在该多个维度上的取值,因此,可以确定每个模型参数在不同取值时的模型参数集合包括:{a1,b1}、{a2,b1}、{a3,b1}、{a1,b2}、{a2,b2}和{a3,b2},每个模型参数集合存放在表1的一个网格中。
[0154]
表1
[0155] a1a2a3b1{a1,b1}{a2,b1}{a3,b1}b2{a1,b2}{a2,b2}{a3,b2}
[0156]
此时,每个模型参数集合定义一个第一备选ai模型的结构,相应的,在进行网格搜索时,可以采用一类样本数据,分别对该6个模型参数集合所定义的第一备选ai模型进行训练,得到训练完成的6个第一备选ai模型。然后分别获取该6个第一备选ai模型的性能参数,
并将性能参数所指示的准确度最高的第一备选ai模型,确定为根据该一类样本数据所确定的第一ai模型。
[0157]
下面对步骤403的实现过程进行说明。与确定第一ai模型不同的是,在确定第二ai模型时,其实现过程为:先获取多个第一ai模型中每个第一ai模型的目标隐含层针对对应一类训练样本数据的目标隐含层训练特征,并根据多个第一ai模型对应的目标隐含层训练特征生成融合训练特征,同时,获取多个第一ai模型中每个第一ai模型的目标隐含层针对对应一类验证样本数据的目标隐含层验证特征,并根据多个第一ai模型对应的目标隐含层验证特征生成融合验证特征,然后根据该融合训练特征和融合验证特征,确定第二ai模型。其中,第一ai模型对应的目标隐含层训练特征为该第一ai模型的目标隐含层针对对应一类训练样本数据的输出。
[0158]
并且,类似于基于一类样本数据中的训练样本数据和验证样本数据,确定第一ai模型的实现方式,根据该融合训练特征和融合验证特征,确定第二ai模型的实现过程,也可以具有至少两种可实现方式:在一种可实现方式中,可以对模型结构已确定的第二预置模型进行训练,在该训练过程中根据学习目标调整该第二预置模型的权重值等参数,训练完成的第二预置模型即为根据该一类样本数据确定的第二ai模型。在另一种可实现方式中,可以采用模型搜索的方法搜索第二备选模型的结构,并在搜索过程中对搜索到的第二备选模型进行训练,以调整每个第二备选模型中权重值等参数,然后在训练完成的多个第二备选模型中确定作为第二ai模型的第二备选模型。
[0159]
其中,该确定第二ai模型的第一种可实现方式的实现过程,可以相应参考确定第一ai模型的第一种可实现方式的实现过程,此处不再赘述。
[0160]
下面结合图11对从获取目标隐含层训练特征和目标隐含层验证特征,到根据该融合训练特征和融合验证特征,采用第二种可实现方式确定第二ai模型的实现过程进行说明。如图11所示,该步骤403可以包括:
[0161]
步骤4031、输入多类样本数据中的每一类训练样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类训练样本数据的目标隐含层训练特征。
[0162]
在前述步骤402中,在根据多类样本数据确定多个第一ai模型的过程中,相当于建立了多类样本数据与多个第一ai模型的一一对应关系,且第一ai模型对对应一类数据具有较高的预测准确度,因此,在该步骤4031中,训练模块202可以输入多类样本数据中的每一类训练样本数据至对应的第一ai模型,以保证第一ai模型对对应一类样本数据的预测准确度。且在该步骤4031中,向任一第一ai模型输入的训练样本数据,与在训练该任一第一ai模型的第一备选ai模型时,向该第一备选ai模型输入的训练样本数据相同,使得确定第一ai模型时该第一ai模型所使用的训练样本数据,与确定第二ai模型时该第一ai模型使用的训练样本数据的数据来源相同,以保证确定的第一ai模型和第二ai模型的匹配度,提高模型的分析准确度。
[0163]
步骤4032、根据多个目标隐含层训练特征生成融合训练特征。
[0164]
其中,该目标隐含层可以为第一ai模型的多层隐含层中的任一隐含层。并且,不同第一ai模型的目标隐含层在对应第一ai模型中的次序可以相同或不同。例如,每个第一ai模型的目标隐含层可以为第一ai模型的多层隐含层中的最后一层隐含层。由于该最后一层隐含层最接近第一ai模型的输出层,该最后一层隐含层的输出是第一ai模型的多个层的输
出中与预测结果联系最紧密的特征,当该目标隐含层为第一ai模型中最后一层隐含层时,能够最大程度地利用与该第一ai模型对应的一类数据的特征,有效地提高了特征的利用率,进而提高对目标事件进行预测的准确率。
[0165]
一般地,在神经网络中传输的数据均是以矩阵的形式传输的,因此,训练模块202根据多个目标隐含层特征生成融合特征的实质,是获取分别用于表示多个第一ai模型的目标隐含层所输出的目标隐含层特征的多个矩阵,并对该多个矩阵进行拼接处理,经过拼接处理后的矩阵即为用于表示融合特征的矩阵。并且,当用于表示样本数据的矩阵的行名为样本对象的名称、矩阵的列名为样本数据的特征名时,对该多个矩阵进行拼接处理的实现过程包括:将多个矩阵中具有相同行名的行确定为经过拼接处理后的矩阵的行,将多个矩阵中具有相同行名的行对应的列直接按列进行拼接。
[0166]
示例的,如下式所示,假设矩阵a1为2行3列的矩阵,第一行的行名为名称a1,第二行的行名为名称a2,第一列的列名为名称b1,第二列的列名为名称b2,第三列的列名为名称b3,且该矩阵a1的元素分别为:1,2,3。4,5,6。矩阵a2为3行3列的矩阵,第一行的行名为名称a3,第二行的行名,为名称a1,第三行的行名为名称a2,第一列的列名为名称b1,第二列的列名为名称b2,第三列的列名为名称b3,且该矩阵a2的元素分别为:7,8,9。0,1,0。1,0,0。对该矩阵1和矩阵2进行拼接处理后,拼接得到的矩阵a3为2行6列的矩阵,第一行的行名为名称a1,第二行的行名为名称a2,第一列的列名为名称b1,第二列的列名为名称b2,第三列的列名为名称b3,第四列的列名为名称b1,第五列的列名为名称b2,第六列的列名为名称b3。其中,矩阵a1、矩阵a2和矩阵a3分别表示为:
[0167][0168][0169][0170]
步骤4033、利用融合训练特征,分别对多个第二备选ai模型进行训练,获得多个训练完成的第二备选ai模型。
[0171]
训练完成的多个第二备选ai模型均用于对目标事件进行预测。且当训练完成的多个第二备选ai模型和训练完成的多个第一备选ai模型均用于对目标事件进行预测时,多个第二备选ai模型和多个第一备选ai模型的学习目标也可以相同,使得第一ai模型能够按照与第二ai模型相同的逻辑,起到对对应一类样本数据进行特征预提取的作用,能够最大化地保证提取的特征为第二ai模型所需的特征,使得根据多个第一ai模型的目标隐含层训练特征对第二备选ai模型进行训练时,能够保证第二ai模型对样本数据的利用率。
[0172]
其中,每两个第二备选ai模型的一个或多个模型参数不同,该第二备选ai模型的模型参数和模型参数的取值,可以对应参考第一备选ai模型的模型参数和模型参数的取值。且该步骤4033的实现过程,请相应参考步骤4022a1至步骤4022a5的实现过程,此处不再赘述。
[0173]
需要说明的是,当第二ai模型的网络结构类型为resnet时,由于该resnet的连接方式提高了信息在网络中的流通程度,避免了由于网络过深所引起的消失梯度问题和退化问题,有助于训练过程中梯度的反向传播,能够保证第二ai模型的预测准确度。并且,由于该resnet的连接方式能够体现层与层之间的调控作用,当第二ai模型用于分析数据中具有相互影响关系的多类数据时,该resnet能够体现多类数据之间的内部逻辑关系,能够进一步提高预测准确度。且由于细胞系的基因调控网络复杂,且存在层次之间彼此调控的关系,当该第二ai模型用于分析细胞系的多类基因组学数据时,该作用表现的尤其明显。
[0174]
类似的,当根据一类样本数据确定的第二ai模型的网络结构类型为densenet时,由于在densenet中,网络每一层的输入向量都是前面所有层输出向量的拼接向量,而每一层所学习的特征也会被直接传给其后面所有层作为输入,因此,也能够体现多类数据之的内部逻辑关系,能够进一步提高预测准确度。
[0175]
如图12所示,训练模块202在获取属于样本对象的多类样本数据后,可以将多类样本数据中的每一类训练样本数据输入至对应的第一ai模型,每个第一ai模型的目标隐含层输出目标隐含层训练特征后,训练模块202可以根据多个目标隐含层训练特征生成融合训练特征,并将融合训练特征输入至每个第二备选ai模型,利用该融合训练特征训练对应的第二备选ai模型,以确定第二ai模型。
[0176]
步骤4034、输入多类样本数据中的每一类验证样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类验证样本数据的目标隐含层验证特征。
[0177]
该步骤4034的实现过程请相应参考步骤4031的实现过程。
[0178]
步骤4035、根据多个目标隐含层验证特征生成融合验证特征。
[0179]
该步骤4035的实现过程请相应参考步骤4032的实现过程。
[0180]
步骤4036、根据融合验证特征,分别获得多个训练完成的第二备选ai模型的性能参数,性能参数指示训练完成的第二备选ai模型对目标事件进行预测的结果的准确度。
[0181]
其中,任一训练完成的第二备选ai模型的性能参数用于反映任一训练完成的第二备选ai模型的模型性能。该步骤4036的实现过程请相应参考步骤4022b3的实现过程。
[0182]
步骤4037、在多个训练完成的第二备选ai模型中,将性能参数所指示的准确度最高的第二备选ai模型确定为第二ai模型。
[0183]
由于任一训练完成的第二备选ai模型的性能参数用于指示该第二备选ai模型对目标事件进行预测的结果的准确度,当训练完成的第二备选ai模型的性能参数所指示的准确度越高,说明该训练完成的第二备选ai模型的模型预测性能越好,因此,训练模块202可以将性能参数所指示的准确度最高的第二备选ai模型,确定为第二ai模型,以保证第二ai模型的预测准确度。
[0184]
经过上述步骤401至步骤403训练得到的ai模型组可以应用于多种场景,其多种场景需要满足:在对目标事件进行分析时,所分析的多类数据中的每一类数据均表示影响目标事件的结果的一方面因素,即该多类数据中的每一类数据均对该目标事件的预测结果有贡献。例如,可以应用于根据用于指示样本车辆的行车轨迹的数据和用于指示样本车辆的出行特征的数据等,预测目标事件为车辆是否具有营运行为的应用场景。根据细胞系的多类组学数据,预测目标事件为细胞系对药物的敏感程度的应用场景。根据细胞系的多类组学数据,预测目标事件为细胞系的基因干扰敏感程度的应用场景。根据细胞系的多类组学
数据,预测目标事件为对病人分型的生物标志物的应用场景。根据太阳辐射数据、大气环流数据和洋流流动数据等,预测目标事件为地区天气状况的应用场景等。
[0185]
需要说明的是,当ai模型组的应用场景不同时,用于对该ai模型组进行训练时的样本数据和学习目标不同,下面分别以以下几种应用场景为例,对其样本数据和学习目标进行说明。
[0186]
当ai模型组用于预测车辆是否具有营运行为时,用于对该ai模型组进行训练时的样本数据可以包括:样本车辆在行车过程中经过的地点数据和经过对应地点时的时间数据等用于指示样本车辆的行车轨迹的数据,及样本车辆在一段时间内的出行次数数据、样本车辆在一段时间内的出行频率数据、样本车辆的类型数据、样本车辆出行的天气数据、样本车辆出行的时间段数据等用于指示样本车辆的出行特征的数据。此时,该样本数据携带的样本标签用于指示该样本车辆具有营运行为或者不具有营运行为的指示信息。相应的,训练完成的第一ai模型能够达到学习目标是指,训练完成的第一ai模型针对多个样本车辆的样本数据所输出的指示信息,相对于多个样本车辆的样本数据携带的样本标签中的指示信息的准确程度满足指定条件。此时,该ai模型组的输出用于指示待预测车辆是否具有营运行为。通过采用该ai模型组预测车辆是否具有营运行为,能够实现对非法运营车辆的自动化检测,并提高检测效率,有助于提高交通监管效率。
[0187]
当ai模型组用于预测细胞系对药物的敏感程度时,用于对该ai模型组进行训练时的样本数据和学习目标,可相应参考步骤401中的相关描述。此时,该ai模型组的输出用于指示细胞系对药物的敏感程度。其中,该细胞系可以为癌细胞系、动物组织中的细胞系、患某种疾病的病人的细胞系或异种移植模式动物的细胞系等。通过预测细胞系对药物的敏感程度,可以在对携带有对应细胞系的个体的用药过程中,根据预测结果有针对性地对个体用药,实现个体化精准医疗,以提高治疗效果。
[0188]
其中,细胞系对药物的敏感程度可以通过半数抑制浓度(half maximal(50%)inhibitory concentration,ic50)表示,该半数抑制浓度是指:对细胞系使用药物时,细胞系中凋亡细胞的总数与细胞系所包括的全部细胞的总数之比等于50%时所对应的药物浓度。
[0189]
当ai模型组用于预测细胞系的基因干扰敏感程度时,用于对该ai模型组进行训练时的样本数据可以包括:样本细胞系的基因突变数据和基因表达数据等基因组学数据。此时,该样本数据携带的样本标签用于指示在敲除样本细胞系中的指定基因时,该敲除的指定基因对样本细胞系发生死亡的影响程度。相应的,训练完成的第一ai模型能够达到学习目标是指,在向训练完成的第一ai模型输入多个样本细胞系的样本数据后,训练完成的第一ai模型输出的样本细胞系针对敲除指定基因发生死亡的影响程度的实际预测结果,相对于该样本数据携带的样本标签所指示样本细胞系,针对敲除指定基因发生死亡的影响程度的期望预测结果的准确程度满足指定条件。通过预测细胞系的基因干扰敏感程度,可以实现对抗癌靶基因的预测,使得在癌症治疗过程中对该抗癌靶基因采用反向遗传学手段,以实现对癌症的有效治疗。其中,抗癌靶基因的预测是指:通过假设敲除某基因时,确定癌细胞死亡的几率,以确定该基因对癌细胞死亡的影响程度,并将对癌细胞死亡程度影响较大的一个或多个基因确定为该癌细胞的抗癌靶基因。
[0190]
当ai模型组用于预测对病人分型的生物标志物时,用于对该ai模型组进行训练时
的样本数据可以包括:病人组织样本的基因突变数据和基因表达数据等基因组学数据。此时,该样本数据携带的样本标签用于指示病人组织样本所属的类型。此时,ai模型组是一个分类模型,训练完成的第一ai模型能够达到学习目标是指,训练完成的第一ai模型针对多个病人组织样本的分类结果,相对于病人组织样本的样本数据携带的样本标签指示的分类结果的准确程度满足指定条件。
[0191]
其中,预测对病人分型的生物标志物是指,在保证ai模型组根据样本数据输出的病人类型为某一类型的前提下,在多次预测过程中,逐次去掉样本数据中的一个特征,并确定去掉任一特征时该特征对预测的准确度的影响,然后将对预测的准确度影响最大的一个或多个特征确定为将病人类型分类为该某一类型的生物标志物。
[0192]
生物标志物是一组可衡量和评估正常生理或病理过程的指示物,常见的生物标志物有:具有高表达能力的基因、发生基因突变的基因、或dna位点发生甲基化的程度(即dna位点甲基化水平)。其中,dna位点用于指示dna序列的某一位置。
[0193]
由于病人遗传背景等因素的差异,根据病理学分类为患有同一种类型疾病的病人,通常也会存在对于相同的药物治疗或相同的免疫治疗出现不同反应的情况,以及,按照病理学被鉴定为同类型癌症的病人,也存在存活率差异大的问题。由此可以发现仅基于病理学无法对病人进行准确分类。因此,目前有学者提出在对病人分型时,也需要考虑病人遗传背景等因素。例如,在对病人分型时,可以针对不同的生物医学问题,根据病人的多组学数据分别提取对病人分型的生物标志物,并结合病人的临床数据,对病人进行分型。通过预测对病人分型的生物标志物,能够提高对病人分型的准确度,以便于针对不同类型的病人进行针对性治疗,提高病人的治愈几率。
[0194]
下面以ai模型组用于预测目标事件为癌细胞系对药物的敏感程度的应用场景,且采用基因表达数据和基因突变数据对ai模型组进行训练为例,对该ai模型组的训练过程进行举例说明。其中,基因表达数据和基因突变数据均为用于反映癌细胞系遗传特性的组学数据,即基因表达数据和基因突变数据均表示影响目标事件的结果的一方面因素。
[0195]
在步骤s11中,获取多个癌细胞系的基因表达数据和基因突变数据。
[0196]
可以从gdsc数据库中,获取936个癌细胞系涉及19350个基因的基因突变数据,936个癌细胞系涉及17419个基因的基因表达数据,及该936个癌细胞系对265个抗癌药物的半数抑制浓度。该基因突变数据用作该936个癌细胞系的一类样本组学数据,该基因表达数据用作该936个癌细胞系的另一类样本组学数据,一个癌细胞系对一个抗癌药物的半数抑制浓度用于确定该癌细胞系的样本组学数据所携带的样本标签的标签值。且一个癌细胞系对一个抗癌药物的半数抑制浓度用于指示该癌细胞系对该抗癌药物的敏感程度。
[0197]
其中,936个癌细胞系涉及19350个基因的基因突变数据可以采用936
×
19350的矩阵表示,该矩阵的行名为癌细胞系包括的癌细胞的名称,列名为癌细胞包括的基因的名称。矩阵中的元素表示对应癌细胞的对应基因是否发生突变,该元素的取值为离散型数值,当元素为0时,表示对应基因未发生突变,当元素为1时,表示对应基因发生了突变。
[0198]
936个癌细胞系涉及17419个基因的基因表达数据可以采用936
×
17419的矩阵表示,该矩阵的行名为癌细胞系包括的癌细胞的名称,列名为癌细胞包括的基因的名称。矩阵中的元素表示对应癌细胞的对应基因的基因表达量高低,该元素的取值为连续型数值,且该元素的取值可以为经过0-1标准化的数值,元素的取值越大表示基因表达量越高,元素的
取值越小表示基因表达量越低。
[0199]
936个癌细胞系对265个抗癌药物的半数抑制浓度可以采用936
×
265的矩阵表示,该矩阵的行名为癌细胞系包括的癌细胞的名称,列名为抗癌药物的名称。矩阵中的元素表示对应癌细胞对对应抗癌药物的半数抑制浓度,该元素的取值为连续型数值,元素的取值越大表示半数抑制浓度越高,元素的取值越小表示半数抑制浓度越低。并且,还可以获取每个半数抑制浓度的自然对数,并在半数抑制浓度的自然对数小于浓度阈值(例如为-2)时,将该半数抑制浓度对应的基因划分至药物敏感组(即划分为正样本组),在半数抑制浓度的自然对数大于或等于浓度阈值(例如为-2)时,将该半数抑制浓度对应的基因划分至药物抵抗组(即划分为负样本组),以便于根据该正样本组中的正样本和负样本组中的负样本确定训练完成的模型的预测性能,以便确定模型参数。
[0200]
在步骤s12中,基于多个癌细胞系的基因表达数据,确定一个第一ai模型,基于多个癌细胞系的基因突变数据,确定另一个第一ai模型,得到两个第一ai模型,其中,两个第一ai模型均用于预测癌细胞系对药物的敏感程度。
[0201]
确定两个第一ai模型的实现过程可以均参考步骤4021至步骤4022的实现过程。并且,在每个第一ai模型的训练过程中,可以采用均方误差(mean squared error,mse)衡量被训练的第一ai模型的实际预测结果与期望预测结果的误差,用斯皮尔相关系数(spearman correlation coefficient,scc)评估预测值与学习目标之间的数值线性相关性,以根据该误差和该斯皮尔相关系数调整第一ai模型中神经元对应的权重值等参数。
[0202]
在步骤s13中,在完成两个第一ai模型的训练后,向基于多个癌细胞系的基因表达数据确定的第一ai模型,再次输入该多个癌细胞系的基因表达数据,向基于多个癌细胞系的基因突变数据确定的第一ai模型,再次输入该多个癌细胞系的基因突变数据,以根据每个第一ai模型的目标隐含层获得对应一类训练样本数据的目标隐含层训练特征。
[0203]
在步骤s14中,根据两个第一ai模型的目标隐含层训练特征生成融合训练特征。
[0204]
其中,步骤s14的实现过程,请相应参考步骤4032的实现过程。
[0205]
在步骤s15中,利用融合训练特征,确定第二ai模型,其中,第二ai模型用于预测癌细胞系对药物的敏感程度。
[0206]
该步骤s15的实现过程请相应参考步骤403的实现过程。
[0207]
由上可知,在ai模型组的训练过程中,通过分别确定多个第一ai模型,并采用确定的多个第一ai模型中的每一个第一ai模型,分别对多类样本数据中的每类样本数据进行分析,然后根据每个训练完成的第一ai模型的目标隐含层获得对应一类样本数据的目标隐含层训练特征和目标隐含层验证特征,再根据该多个目标隐含层训练特征获取融合训练特征,根据该多个目标隐含层验证特征获取融合验证特征,然后根据融合训练特征和融合验证特征,确定第二ai模型,相较于相关技术,由于用于确定第二ai模型时的特征,是预先根据多个第一ai模型分别对多类数据进行分析所得特征的融合特征,使得训练过程中可以充分利用每一类数据的特征,有效地提高了训练得到的ai模型组的模型性能。
[0208]
进一步的,为证明本申请实施例训练得到的ai模型组的性能,本申请实施例采用相同的训练样本数据,按照相关技术中的训练方法对相关技术中的mlp模型进行了训练,并采用10
×
交叉验证方法获取了训练完成的mlp模型的f1值,其f1值为0.707(下文称为第一f1值)。并且,本申请实施例还直接将用于训练的基因表达数据和基因突变数据进行拼接,
然后采用拼接后的数据,使用本申请实施例提供的网格搜索方法训练残差网络,并采用10
×
交叉验证方法获取了训练完成的模型的f1值,其f1值为0.725(下文称为第二f1值)。同时,采用10
×
交叉验证方法,分别获取了使用基因表达数据训练完成的第一ai模型、使用基因突变数据训练完成的第一ai模型、及ai模型组的f1值,使用基因表达数据训练完成的第一ai模型的f1值为0.732(下文称为第三f1值),使用基因突变数据训练完成的第一ai模型的f1值为0.708(下文称为第四f1值),ai模型组的f1值的f1值为0.891(下文称为第五f1值)。根据第一f1值至第五f1值的对比可以看出:采用本申请实施例提供的模型训练方法训练得到的ai模型组的性能最好。
[0209]
并且,根据第二f1值和第五f1值的对比可以看出:由于多类数据之间存在差异,即使都用残差网络,在直接将多个数据进行拼接,训练出的模型的预测性能相当于使用单独一类数据训练的模型的性能的调和,其没有发挥多类数据的优势,而采用本申请实施例提供的训练方法训练得到的ai模型组的性能,优于采用每个单独一类数据训练得到的模型的性能,起到了整合多类数据的优势。
[0210]
下面对利用ai模型组分析多类数据,对目标事件进行预测的实现过程进行说明。如图13所示,其实现过程可以包括以下步骤:
[0211]
步骤501、获取多类数据,该多类数据中的每一类数据表示影响目标事件的结果的一方面因素。
[0212]
当需要使用ai模型组预测目标事件时,该多类数据中的每一类数据为影响目标事件的结果的一方面因素。需要使用预测装置对目标事件进行预测的用户,可以通过终端向预测装置发送的数据。当目标事件不同时,该多类数据不同,本申请实施例以以下几种为例进行说明:
[0213]
当目标事件包括以下事件中的任意一种:预测细胞系对药物的敏感程度、预测细胞系的基因干扰敏感程度、预测对细胞系对应的病人分型的生物标志物时,多类数据可以包括细胞系的以下数据中的两个或多个:基因突变数据、基因表达数据、脱氧核糖核酸甲基化数据、拷贝数变异数据、微核糖核酸表达数据、组蛋白修饰数据、基因融合数据、染色体异构数据和代谢物表达数据。
[0214]
当目标事件为车辆是否具有营运行为时,多类数据可以包括目标车辆的以下数据中的两个或多个:目标车辆在行车过程中经过的地点数据和经过对应地点时的时间数据等用于指示目标车辆的行车轨迹的数据,及目标车辆在一段时间内的出行次数数据、目标车辆在一段时间内的出行频率数据、目标车辆的类型数据、目标车辆出行的天气数据、目标车辆出行的时间段数据等用于指示目标车辆的出行特征的数据。
[0215]
当目标事件为地区的天气状况时,多类数据可以包括目标地区的太阳辐射数据、大气环流数据和洋流流动数据中的两个或多个。
[0216]
示例的,假设需要使用预测装置根据基因突变数据和基因表达数据,预测目标癌细胞系对药物的敏感程度时,用户可以通过终端向预测装置发送基因突变数据和基因表达数据,预测装置可以接收该基因突变数据和基因表达数据,以获得该基因突变数据和基因表达数据。
[0217]
该基因突变数据可以为目标癌细胞系涉及19350个基因的基因突变数据,且该基因突变数据可以采用大小为1
×
19350的矩阵1表示,基因表达数据可以为目标癌细胞系涉
及17419个基因的基因表达数据,且该基因表达数据可以采用大小为1
×
17419的矩阵2表示。
[0218]
步骤502、输入多类数据中的每一类数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征。
[0219]
由于任一第一ai模型由与该任一第一ai模型对应的一类样本数据训练得到,使得该任一第一ai模型对该对应一类样本数据具有较好的分析效果,因此,向每个第一ai模型输入对应一类数据,能够保证第一ai模型对目标事件进行预测的准确度。
[0220]
并且,在完成第一ai模型的训练后,即完成了该第一ai模型中各个神经元的输入输出关系的设计,因此,在向第一ai模型输入对应一类数据后,该第一ai模型可以根据该第一ai模型中各神经元的输入输出关系,针对输入的一类数据执行运算,以对目标事件进行预测。第一ai模型在对目标事件进行预测的过程中,第一ai模型中每一层均会产生对应层的输出结果,此时,可以获取该第一ai模型中目标隐含层对该对应一类数据的输出结果,该输出结果即为目标隐含层特征。
[0221]
仍以步骤501中的例子为例,在该步骤502中,可以向第一个第一ai模型输入用于表示目标癌细胞系的基因突变数据的矩阵1,使得第一个第一ai模型根据矩阵1,预测目标癌细胞系对药物的敏感程度,向第二个第一ai模型输入用于表示目标癌细胞系的基因表达数据的矩阵2,使得第二个第一ai模型根据矩阵2,预测目标癌细胞系对药物的敏感程度,并获取第一个第一ai模型的目标隐含层针对矩阵1输出的目标隐含层特征,获取第二个第一ai模型的目标隐含层针对矩阵2输出的目标隐含层特征。
[0222]
步骤503、根据多个目标隐含层特征生成融合特征。
[0223]
其中,该步骤503的实现方式,请相应参考上述步骤4032的实现方式,此处不再赘述。
[0224]
该目标隐含层可以为第一ai模型的多层隐含层中的任一隐含层。并且,不同第一ai模型的目标隐含层在对应第一ai模型中的次序可以相同或不同。例如,每个第一ai模型的目标隐含层可以为第一ai模型的多层隐含层中的最后一层隐含层。由于该最后一层隐含层最接近第一ai模型的输出层,该最后一层隐含层的输出是第一ai模型的多个层的输出中与预测结果联系最紧密的特征,当该目标隐含层为第一ai模型中最后一层隐含层时,能够最大程度地利用与该第一ai模型对应的一类数据的特征,有效地提高了特征的利用率,进而提高对目标事件进行预测的准确率。
[0225]
继续以步骤502中的例子为例,在该步骤503中,假设第一个第一ai模型的目标隐含层包括384个神经元,则该第一个第一ai模型的目标隐含层特征可以采用大小为1
×
384的矩阵表示,第二个第一ai模型的目标隐含层包括1536个神经元,则该第二个第一ai模型的目标隐含层特征可以采用大小为1
×
1536的矩阵表示,根据该第一个第一ai模型的目标隐含层特征和第二个第一ai模型的目标隐含层特征生成的融合特征可以采用大小为1
×
(384+1536)的矩阵表示。
[0226]
步骤504、输入融合特征至第二ai模型,根据第二ai模型对融合特征进行分析,输出预测值,该预测值指示根据多类数据对目标事件进行预测的结果。
[0227]
在完成第二ai模型的训练后,即完成了该第二ai模型中各个神经元的输入输出关系的设计,在向第二ai模型输入融合特征后,该第二ai模型可以根据该第二ai模型的中各
神经元的输入输出关系,针对该融合特征进行运算,以对目标事件进行预测。
[0228]
其中,由于第二ai模型和多个第一ai模型均用于对目标事件进行预测,能够保证第二ai模型和多个第一ai模型的预测目标相同,使得第一ai模型能够按照与第二ai模型相同的逻辑,起到对对应一类样本数据进行特征预提取的作用,能够最大化的保证提取的特征为第二ai模型所需的特征,能够保证第二ai模型对样本数据的利用率。
[0229]
继续以步骤503中的例子为例,在该步骤504中,假设使用ai模型组预测目标癌细胞系对n种药物的敏感程度,该第二ai模型的输出可以采用大小1
×
n的矩阵表示,该矩阵的行用于指示该目标癌细胞系,该矩阵的多个列的列名分别为n种药物的名称,该矩阵某列的元素为该癌细胞系对该列的列名所指代的药物的敏感程度。
[0230]
综上所述,本申请实施例提供的利用ai模型组分析多类数据的方法,该方法通过采用ai模型组中多个第一ai模型中的每一个第一ai模型,分别对多类数据中的每类数据进行分析,然后根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征,再根据该多个目标隐含层获取融合特征,采用第二ai模型根据融合特征对目标事件进行预测,相较于相关技术,由于预先采用多个第一ai模型分别获取多类数据的特征,然后对用于表示多类数据的特征的融合特征进行分析,使得ai模型组可以深度地挖掘每一类数据的特征,充分利用每一类数据的特征,有效地提高了根据多类数据对目标事件进行预测的准确性。
[0231]
本申请实施例提供的利用ai模型组分析多类数据的方法的步骤先后顺序可以进行适当调整,步骤也可以根据情况进行相应增减。任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化的方法,都应涵盖在本申请的保护范围之内,因此不再赘述。
[0232]
本申请提供了一种利用ai模型组分析多类数据的装置,该ai模型组包括多个第一ai模型和第二ai模型,其中,多个第一ai模型中的每个第一ai模型对应多类数据中的一类数据。该利用ai模型组分析多类数据的装置可以包括前述预测装置300。如图5所示,该装置可以包括:
[0233]
第一获取模块301,用于获取多类数据,多类数据中的每一类数据表示影响目标事件的结果的一方面的因素。
[0234]
提取模块302,用于输入多类数据中的每一类数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征。
[0235]
融合模块303,用于根据多个目标隐含层特征生成融合特征。
[0236]
预测模块304,用于输入融合特征至第二ai模型,根据第二ai模型对融合特征进行分析,输出预测值,预测值指示根据多类数据对目标事件进行预测的结果。
[0237]
在一种可实现方式中,当对多个第一ai模型和第二ai模型进行训练的操作由预测装置300执行时,如图14所示,预测装置300还可以包括:
[0238]
第二获取模块305,用于获取多类样本数据。
[0239]
第一确定模块306,用于根据多类样本数据确定多个第一ai模型,每个第一ai模型为由多类样本数据中的一类样本数据训练得到的ai模型。
[0240]
第二确定模块307,用于根据多类样本数据和多个第一ai模型确定第二ai模型,第二ai模型为由多类样本数据对应的融合样本特征训练得到的ai模型,融合样本特征根据多
个第一ai模型的目标隐含层特征得到。
[0241]
在一种可实现方式中,每个第一ai模型包括输入层、输出层、以及、一个或多个隐含层,第一ai模型的目标隐含层为第一ai模型中一个或多个隐含层中的一个。
[0242]
在一种可能的场景中,当目标事件包括以下事件中的任意一种:预测细胞系对药物的敏感程度、预测细胞系的基因干扰敏感程度、预测对细胞系对应的病人分型的生物标志物时,该多类数据可以包括细胞系的以下数据中的两个或多个:基因突变数据、基因表达数据、脱氧核糖核酸甲基化数据、拷贝数变异数据、微核糖核酸表达数据、组蛋白修饰数据、基因融合数据、染色体异构数据和代谢物表达数据。
[0243]
在另一种可能的场景中,当目标事件为车辆是否具有营运行为时,多类数据可以包括目标车辆的以下数据中的两个或多个:目标车辆在行车过程中经过的地点数据和经过对应地点时的时间数据等用于指示目标车辆的行车轨迹的数据,及目标车辆在一段时间内的出行次数数据、目标车辆在一段时间内的出行频率数据、目标车辆的类型数据、目标车辆出行的天气数据、目标车辆出行的时间段数据等用于指示目标车辆的出行特征的数据。
[0244]
在又一种可能的场景中,当目标事件为地区的天气状况时,多类数据可以包括目标地区的太阳辐射数据、大气环流数据和洋流流动数据中的两个或多个。
[0245]
在一种可实现方式中,第一确定模块306,具体用于:确定每一类样本数据对应的多个第一备选ai模型,样本数据包括训练样本数据和验证样本数据;利用每一类样本数据中的训练样本数据,分别对对应的多个第一备选ai模型进行训练,获得每一类训练样本数据对应的多个训练完成的第一备选ai模型;根据每一类样本数据中的验证样本数据,获得对应的训练完成的第一备选ai模型的性能参数,性能参数指示训练完成的第一备选ai模型对目标事件进行预测的结果的准确度;在每一类训练样本数据对应的多个训练完成的第一备选ai模型中,将性能参数所指示的准确度最高的第一备选ai模型,确定为根据对应一类样本数据确定的第一ai模型。
[0246]
在一种可实现方式中,第二确定模块307,具体用于:输入多类样本数据中的每一类训练样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类训练样本数据的目标隐含层训练特征;根据多个目标隐含层训练特征生成融合训练特征;利用融合训练特征,分别对多个第二备选ai模型进行训练,获得多个训练完成的第二备选ai模型;输入多类样本数据中的每一类验证样本数据至对应的第一ai模型,根据每个第一ai模型的目标隐含层获得对应一类验证样本数据的目标隐含层验证特征;根据多个目标隐含层验证特征生成融合验证特征;根据融合验证特征,分别获得多个训练完成的第二备选ai模型的性能参数,性能参数指示训练完成的第二备选ai模型对目标事件进行预测的结果的准确度;在多个训练完成的第二备选ai模型中,将性能参数所指示的准确度最高的第二备选ai模型确定为第二ai模型。
[0247]
在一种可实现方式中,融合模块303,具体用于:对多个目标隐含层特征进行拼接处理,得到融合特征。
[0248]
在一种可实现方式中,第一ai模型的结构为残差网络结构或密集连接网络;和/或,第二ai模型的结构为残差网络结构或密集连接网络。
[0249]
综上所述,本申请实施例提供的利用ai模型组分析多类数据的装置,提取模块采用ai模型组中多个第一ai模型中的每一个第一ai模型,分别对多类数据中的每类数据进行
分析,融合模块根据每个第一ai模型的目标隐含层获得对应一类数据的目标隐含层特征,预测模块根据该多个目标隐含层获取融合特征,采用第二ai模型根据融合特征对目标事件进行预测,相较于相关技术,由于预先采用多个第一ai模型分别获取多类数据的特征,然后对用于表示多类数据的特征的融合特征进行分析,使得ai模型组可以深度地挖掘每一类数据的特征,充分利用每一类数据的特征,有效地提高了根据多类数据对目标事件进行预测的准确性。
[0250]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置和模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0251]
本申请还提供了一种计算设备,该计算设备包括处理器和存储器;该存储器中存储有计算机程序;该处理器执行该计算机程序时,该计算设备执行本申请提供的利用ai模型组分析多类数据的方法。该计算设备的结构可以参考图6所示的计算设备的结构。
[0252]
本申请还提供了一种计算机可读存储介质,该计算机可读存储介质可以为非瞬态的可读存储介质,当计算机可读存储介质中的指令被计算机执行时,该计算机用于执行本申请提供的利用ai模型组分析多类数据的方法。该计算机可读存储介质包括但不限于易失性存储器,例如随机访问存储器,非易失性存储器,例如快闪存储器、硬盘(hard disk drive,hdd)、固态硬盘(solid state drive,ssd)。
[0253]
本申请还提供了一种计算机程序产品,所述计算机程序产品包括计算机指令,在被计算设备执行时,所述计算设备执行本申请提供的利用ai模型组分析多类数据的方法。该计算机程序产品可以为一个软件安装包,在需要使用第一方面的利用ai模型组分析多类数据的方法的情况下,可以下载该计算机程序产品并在计算设备上执行该计算机程序产品。
[0254]
本申请实施例还提供了一种芯片,该芯片包括可编程逻辑电路和/或程序指令,当所述芯片运行时用于实现本申请实施例提供的利用ai模型组分析多类数据的方法。
[0255]
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0256]
在本申请实施例中,术语“第一”、“第二”和“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。术语“一个或多个”是指一个或多个,术语“多个”指两个或两个以上,除非另有明确的限定。
[0257]
本申请中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
[0258]
以上所述仅为本申请的可选实施例,并不用以限制本申请,凡在本申请的构思和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1