用于肿瘤免疫检查点抑制剂疗效预测的多模态迁移学习框架的制作方法
本申请涉及计算机技术领域,更具体地,本申请涉及一种用于肿瘤免疫检查点抑制剂的疗效预测的方法、装置和系统以及所述装置和系统的用途。
背景技术:
肿瘤的免疫治疗通过激活人体免疫系统来杀死肿瘤细胞,从而达到治愈的目的。对于某些患者,即使已经处于癌症晚期,在常规疗法失效以后,免疫肿瘤治疗依然可以缓和甚至终止患者病情的进一步发展,且在长达几年的缓和期中,患者遭受的药物副作用较轻。近年来,随着抗体制备等相关技术的成熟,免疫肿瘤治疗发展迅速,已经成为继手术、放疗、化疗、靶向治疗后癌症的另一有效治疗手段。尤其是明确了导致t细胞免疫反应抑制的“免疫检查点”机制后,已有多个免疫检查点相关药物获美国食品和药品监督管理局(foodanddrugadministration,fda)批准用于多种恶性肿瘤的治疗[pmc5973373]。
在临床应用中,免疫检查点抑制剂(immunecheckpointblockade,icb)疗法的响应率低、个体化差异大,如何对肿瘤患者进行有效的个体化的免疫检查点抑制剂的疗效预测,是肿瘤免疫治疗的关键问题之一。
目前对免疫检查点抑制剂(icb)的疗效预测的主要办法,是通过医学影像或者测序数据,预测免疫治疗的生物标志物,从而间接预测疗效。目前被广泛认可的生物标志物主要有pd-l1表达和肿瘤突变负荷(tmb),以及其他生物标志物如错配修复缺陷(dmmr),肿瘤浸润淋巴细胞(til),微卫星不稳定性(msi)等。可以通过免疫组化照片(ihc)得到pd-l1的表达从而预测疗效;或者通过血液或肿瘤组织的全外显子组测序(wholeexomesequencing,wes)或者二代测序(nextgenerationsequencing,ngs)大组(panel)测序,计算样本的tmb,从而预测疗效;近两年来也开始有通过病理组织切片的h&e染色图片(wsi)预测msi或tmb的一些研究工作。然而,(1)这些方法都受限于有临床数据的训练样本,(2)pd-l1或tmb仅提供对免疫治疗效果有限的预测能力。因此,通过预测pd-l1或tmb间接进行疗效预测的效果也同样有限。因此,本领域需要没有上述缺陷的能够有效预测免疫检查点抑制剂效果的方法、装置和系统。本申请的方案解决了所述需求。
技术实现要素:
本申请公开了一种用于预测免疫检查点抑制剂治疗效果的装置,该装置包括:数据输入模块、特征提取模块、数据学习模块、疗效预测模块和数据输出模块,其中数据输入模块读取训练集数据和测试集数据,其中训练集数据和测试集数据都包含肿瘤样本的多模态数据的一个子集,并且训练集数据还包括免疫检查点抑制剂疗效的标签数据;特征提取模块对训练集数据或测试集数据进行特征提取,分别得到训练集数据的特征值或测试集数据的特征值;数据学习模块以训练集数据的特征值作为输入数据,以所述免疫检查点抑制剂疗效的标签数据作为目标,进行监督式学习,得到用于预测免疫检查点抑制剂疗效的分类器;疗效预测模块以测试集数据的特征值作为输入数据,通过所述分类器进行目标预测,得到测试集数据相应的免疫检查点抑制剂治疗效果的预测值;数据输出模块输出所述预测值。
在所述装置的一个实施方案中,所述监督式学习使用全连接神经网络算法,randomforest,xgboost,
在所述装置的一个实施方案中,所述监督式学习使用全连接神经网络算法。
在所述装置的一个实施方案中,所述特征提取模块对训练集数据或测试集数据的每种类别的组学数据分别进行自监督学习,获得有效的降维算法,通过所述降维算法对不同组学数据进行特征提取得到特征提取模型,并将特征提取模型迁移到有标签数据的样本库的与之对应的同类组学数据(如rna表达谱数据),进行特征提取,得到特征值。
在所述装置的一个实施方案中,所述有标签数据的样本库包括tcga数据库和tcia数据库。
在所述装置的一个实施方案中,所述组学数据包括rna表达谱数据和h&e病理切片扫描图像数据。
在所述装置的一个实施方案中,所述组学数据还包括基因变异数据、甲基化测序数据,以及其他相关的临床数据。
在所述装置的一个实施方案中,所述基因变异数据包括snp,cnv,和体细胞突变数据。
本申请还提供了一种用于预测免疫检查点抑制剂治疗效果的系统,该系统包含所述装置。
本申请还公开了一种用于预测免疫检查点抑制剂治疗效果的方法,其中所述方法使用上述装置或系统进行预测。
本申请还公开了所述装置在制备用于预测免疫检查点抑制剂治疗效果的系统中的用途。
本申请还公开了所述装置或系统用于预测免疫检查点抑制剂治疗效果的用途。
附图说明
为了更完整地理解本发明及其优势,现在将参考结合附图的以下描述,其中:
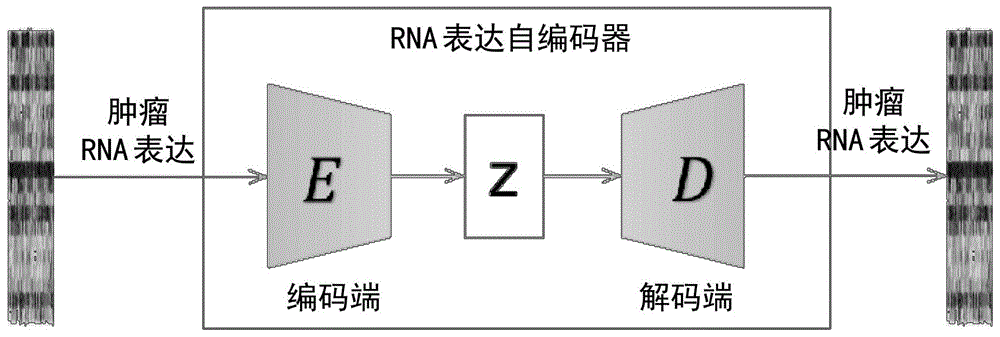
图1是基于rna表达谱数据的自监督学习的示意图。
图2是基于病理切片图像的自监督学习的示意图。
图3是基于卷积自编码神经网络的特征提取的示意图。
图4是基于多模态数据的监督式学习的示意图,其中分类器基于全连接神经网络。
图5是基于多模态数据全连接网络的免疫疗效预测的示意图。
具体实施方式
以下,将参照附图来描述本发明的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本发明的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本发明实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本发明。在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
在使用类似于“a、b和c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有a、b和c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有a和b、具有a和c、具有b和c、和/或具有a、b、c的系统等)。在使用类似于“a、b或c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有a、b或c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有a和b、具有a和c、具有b和c、和/或具有a、b、c的系统等)。
附图中示出了一些方框图和/或流程图。应理解,方框图和/或流程图中的一些方框或其组合可以由计算机程序指令来实现。这些计算机程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,从而这些指令在由该处理器执行时可以创建用于实现这些方框图和/或流程图中所说明的功能/操作的装置。本发明的技术可以硬件和/或软件(包括固件、微代码等)的形式来实现。另外,本发明的技术可以采取存储有指令的计算机可读存储介质上的计算机程序产品的形式,该计算机程序产品可供指令执行系统使用或者结合指令执行系统使用。
1.1多模态数据的迁移学习
在本申请中,发明人提出一个多模态数据的迁移学习框架,用于肿瘤免疫检查点抑制剂的疗效预测。迁移学习专注于已有问题的解决模型,并将其利用在不完全相同但是有一定相关性的其他问题上。深度学习需要大量的有标签的样本进行训练,然而,在临床医学,尤其是icb疗效预测上,目前已有临床数据的高质量的样本量远远不够用来训练复杂模型,导致深度学习在icb疗效预测的应用上有局限性。另一方面,在公共数据库如tcga,tcia上,收集了大量的没有临床数据的样本数据。因此我们提出先在这些数据上训练模型、再将训练好的模型迁移到icb疗效预测的问题上的多模态迁移学习框架。
该框架包括(1)对每种类别的组学数据分别进行自监督学习,获得有效的降维算法,对不同组学数据进行特征提取,(2)将自监督学习得到的特征提取模型,迁移到有标签数据的样本库的同类组学数据,进行特征提取,(3)综合来自所有类别的组学数据降维后的特征数据,利用有标签的样本库进行监督学习,获得疗效预测模型,(4)利用训练好的特征提取算法和疗效预测模型,对新的样本进行预测。在步骤(1)中,由于自监督学习不需要样本标签,我们可以利用tcga(见https://cancergenome.nih.gov)和tcia(见https://www.cancerimagingarchive.net)等数据库所有的大量样本进行深度学习,提取各种不同类别的数据中的有效特征。在此,样本标签指算法希望预测的结果,如os(overallsurvival),pfs(progression-freesurvival)。
方案通过综合包含影像和基因组学数据的多组学数据进行联合机器学习的办法来预测疗效,而不用简单的单一生物标志物(如pd-l1或tmb)来预测疗效。在本文给出的实例中,发明人采用了两种不同的组学数据,一是rna表达谱数据,二是h&e病理切片扫描图像数据。发明人的框架可以利用前述的方式进一步扩展以包括其他组学数据,包括但不局限于:基因变异数据(snp,cnv,体细胞突变),甲基化测序数据,以及其他相关的临床数据等等。
1.2基于rna表达谱数据的自监督学习
对rna表达谱数据,发明人通过自编码器深度学习神经网络降维的办法来获得每个样本的特征。自编码器(autoencoder)是一种人工神经网络,在自监督学习中用于有效编码。自编码器对数据本身进行压缩和解压,使得解压后的数据与原始输入数据最接近,从而对训练数据学习出一种表示(也称表征或编码),提炼出数据的有效特征。发明人通过自编码器模型进行数据特征提取和数据降维,模型可以基于公共数据库的rna表达谱数据进行训练。然后,将训练好的模型迁移到免疫疗效样本的同类数据(即:rna表达谱数据),按照训练得到的自编码器的压缩端,进行数据的降维和特征提取。基于rna表达谱数据的自监督学习如图1所示。
随着测序技术(ngs)的快速发展,目前通过rna测序或者基因表达芯片(microarray)已经可以准确的对样本基因表达值进行定量。在应用实例中,发明人从公共数据库tcga上下载了11048个样本的rna表达谱数据,加上黑色素瘤(见w.hugoetal.,“genomicandtranscriptomicfeaturesofresponsetoanti-pd-1therapyinmetastaticmelanoma,”cell,vol.165,no.1,pp.35–44,2016,n.riazetal.,“tumorandmicroenvironmentevolutionduringimmunotherapywithnivolumab,”cell,vol.171,no.4,pp.934-949.e15,2017)和结直肠癌(s.kimetal.,“comprehensivemolecularcharacterizationofclinicalresponsestopd-1inhibitioninmetastaticgastriccancer”,naturemedicine,vol.24,pp.1449–1458,2018)共91个样本的数据,用于自编码器训练。具体训练步骤如下:
(算法一)
1.从原始表达谱选取免疫治疗相关基因作为自编码器输入
2.对输入的基因的表达量进行归一化处理(z-normalization)
3.对每一个样本,通过自编码器的编码端(encoder),获得输入基因表达量的特征表示
4.通过自编码器的解码端(decoder),将基因表达量的特征表示还原为基因表达量
5.通过梯度下降的办法,调整编码端和解码端的参数,最小化原始的基因表达量和还原的基因表达量之间的差异。
在后续的监督式学习和疗效预测的过程中,发明人将通过(算法一)训练好的编码端模型迁移到疗效预测模型中,作为样本rna表达谱的特征提取算法,对rna表达谱数据进行特征提取。
1.3基于病理切片图像的自监督学习
h&e(苏木精-伊红)染色是人体组织学检查中对组织切片的标准染色方法,能够显示出明显的细胞结构。病理切片检查是由病理学医师对组织切片进行分析、从而确定肿瘤病情的一种肿瘤诊断技术。病理切片图像,不仅可以得到不同细胞(包括正常组织细胞,免疫细胞,肿瘤细胞等)的数量,还能得到不同类型的细胞在肿瘤微环境中的空间分布,可以用来预测tils,tmb,msi等重要的肿瘤免疫疗效标志物。
发明人从大量的病理切片图像进行自监督学习,用公共数据库tcia中的病理图像训练一个卷积自编码网络(convolutionalauto-encoder,cae),进行图像的特征提取。然后,将训练出来的卷积自编码网络的编码端模型,应用于免疫疗效样本的同类数据(即:病理图像),对其进行特征提取。
在应用实例中,基于病理切片图像的自监督学习按如下步骤进行。
(算法二)
1.将超高分辨率的wsi图像分割成多个小的图像块(tile)
2.对每一个小的图像块,通过图像处理算法,区分出背景(不含组织)的图像块和前景(含组织)图像块,剔除所有背景图像块,
3.对前景的图像块,训练一个卷积神经网络(cnn),区分出仅含有正常组织的图像块,和含有肿瘤组织的图像块(此处采用带有标签的训练样本数据),
4.对检测出来的含有肿瘤组织的图像块图像进行颜色归一化处理
5.将所有含有肿瘤组织的图像块作为卷积自编码神经网络的输入,进行训练。
基于病理切片图像的自监督学习的示意图见图2。
如图3所示,在后续的监督式学习和疗效预测的过程中,发明人将如(算法二)训练好的cae模型的编码端(encoder)模型迁移到疗效预测模型中,对病例图像数据进行特征提取。对病理图像数据的应用也需要先将病理图像进行如(算法二)的步骤1-3的预处理,然后,根据(算法二)步骤4中训练出来的卷积神经网络,得到所有含有肿瘤组织的图像块,将这些图像块作为输入,基于(算法二)步骤5中训练得到的卷积自编码神经网络的编码端,得到这些病理图像数据的特征。基于卷积自编码神经网络的特征提取的示意图见图3。
1.4基于多模态数据特征提取的监督式学习
在进行免疫疗效预测时,发明人的数据包括训练集数据和测试集数据,每组数据都包含肿瘤样本的多模态数据的一个子集,比如rna表达谱或病理图像数据。此外,训练集数据还包括免疫疗效的标签数据。在监督式学习过程中,发明人采用前述(2.2-2.3小节中)对不同类型的数据进行自监督学习训练出来的模型的特征提取器,对免疫疗效预测的训练集数据中的同类数据,分别进行特征提取。然后,将训练集数据中提取得到的特征值作为输入数据,以免疫疗效的标签数据作为目标,通过输入标签数据的监督机器学习算法训练一个分类器对免疫疗效进行预测。
在本系统中,发明人可以选用不同的监督学习算法,比如全连接神经网络,或者其他的机器学习算法,如randomforest,xgboost,
1.5对新样本的预测
对新样本的预测按如下步骤进行。首先,发明人采用前述(1.2-1.3小节中)对不同类型的数据进行自监督学习训练出来的模型的特征提取器,对免疫疗效预测的测试集数据中的同类数据,分别进行特征提取。随后,将测试集数据中提取到的特征值作为输入数据,通过训练好的分类器(例如基于2.4小节中训练的全连接神经网络),进行目标预测,得到测试集数据相应的免疫疗效的预测值如图5所示。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
参考资料:
w.hugoetal.,“genomicandtranscriptomicfeaturesofresponsetoanti-pd-1therapyinmetastaticmelanoma,”cell,vol.165,no.1,pp.35–44,2016.
n.riazetal.,“tumorandmicroenvironmentevolutionduringimmunotherapywithnivolumab,”cell,vol.171,no.4,pp.934-949.e15,2017.
s.kimetal.,“comprehensivemolecularcharacterizationofclinicalresponsestopd-1inhibitioninmetastaticgastriccancer”,naturemedicine,vol.24,pp.1449–1458,2018。
- 还没有人留言评论。精彩留言会获得点赞!