一种基于不良反应监测报告的药品风险评估模型的制作方法
本发明涉及一种药品风险评估方法,具体构建基于药品不良反应监测报告中的西药数据,属于机器学习技术领域。
背景技术:
在药物警戒中,世界各国建立了基于网络的药品不良反应自发报告采集系统。但数据资源的利用和开发仍然不足,主要的研究集中在基于不平衡分析的信号检测方法改进与应用、信号挖掘比较分析、数据遮蔽效应的消除等方面。国内外有关于药品的研究,但是主要关注的是基于其中某类药品的风险,缺乏系统性评价,也不具有通用性。因此,随着我国自发报告量的迅速增加,建立一种基于不良反应监测报告的药品风险评估模型,为现有药品的风险评估建立一个可量化的参考模型,可以为医生、患者和生产商在使用或生产中起到决策指导作用。
技术实现要素:
本发明所要解决的技术问题是提供一种基于不良反应监测报告的药品风险评估模型,克服药物警戒中现有技术缺乏系统性评价和通用性的不足,为现有药品的风险评估建立一个可量化的参考模型。
为了达到以上目的,本发明提供一种基于不良反应监测报告的药品风险评估模型,其特征在于,包括以下步骤:
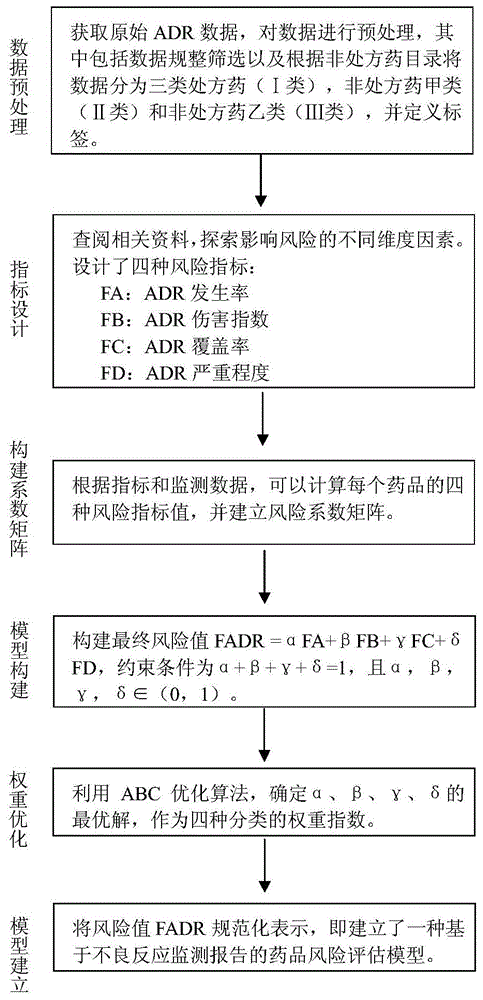
步骤1),获取原始我国药品不良反应adr(adversedrugrecation)数据库,进行数据预处理,并对符合要求的数据进行标记作为数据的测试分类标签;
步骤2),定义四个指标,分别为:fa:adr发生率;fb:adr伤害指数;fc:adr覆盖率;fd:adr严重程度;
步骤3),计算药品所有预处理后数据的四个指标的值;利用abc算法求出最优权重,并定义最终风险值fadr=αfa+βfb+γfc+δfd,其中约束条件为:α+β+γ+δ=1,且α,β,γ,δ∈(0,1);随机选取部分数据建立测试数据,以用于机器学习。
进一步的,步骤1的操作步骤为:
步骤1.1),获取原始adr数据库,所述原始adr数据库包含从国家药品不良反应监测中心获取的adr数据,该数据具体是国家药品评价中心药品不良反应自发呈报系统数据库中2010~2011年采集的不良反应报告;
步骤1.2),对数据进行预处理,所述预处理包括对原始adr数据库进行规整以及筛选,以得到报告频次大于或等于3的西药数据;
步骤1.3),对符合要求的数据进行标记,根据非处方药品公开目录将符合要求的数据分为三类:处方药,非处方药甲类和非处方药乙类,最终得到标准数据集。
进一步的,步骤1.1中所述的对原始adr数据库进行规整预处理后将数据按照最终得到的不良反应数量和药品数量分类。
进一步的,步骤2的操作步骤为:
步骤2.1),fa:adr发生率
定义:假设某一药品记为d,其对应的adr报告总数量为n(d),其中严重报告数量为sn(d),那么fa:adr发生率为,
步骤2.2),fb:adr伤害指数
按照用药后患者的机体反应定义其伤害程度,伤害程度一共分为六级,其分值分别为1-6分;
定义:假设某一药品记为d,其对应第i个分值c(i)的伤害相关报告数量为n(i),其中i=1,2,...6,其药品对应的adr报告总数量为n(d),那么fb:adr伤害指数为,
步骤2.3),fc:adr覆盖率
定义:假设某一药品记为d,其所引起的adr的种类数为k(d),所有可能的adr种类数为n,那么fc:adr覆盖率为,
步骤2.4),fd:adr严重程度
将药品损害程度分为5级,其分值为1-5分;
定义:假设某一药品记为d,其对应不良反应的严重程度为id,将药品不良反应进行对应,并按照打分最高值定义该不良反应的严重性,可计算出该药物引起该不良反应的严重程度,那么,
dadr=max(id)公式4
最终,根据药品引起的各种不良反应进行计算,其中对应第m个分值dadr(m)的伤害相关报告数量为n(m),其中m=1,2,...5,该药品对应的adr报告总数量为n(d),则该药品的不良反应严重程度定义为:
进一步的,步骤3的操作步骤为:
步骤3.1),构建风险系数矩阵
根据步骤2定义的四个指标公式,计算出每个药品di(i=1,2,3,...n)的四个因子(fa,fb,fc,fd)的值,建立如下风险系数矩阵:
步骤3.2),构建abc算法
对预处理后的数据进行初始化,将采蜜蜂与蜜源一一对应,更新蜜源信息,同时确定蜜源的花蜜量;观察蜂根据采蜜蜂所提供的信息采用一定的选择策略选择蜜源,更新蜜源信息,同时确定蜜源的花蜜量;确定侦查蜂,寻找新的蜜源;循环重复若干次,记忆迄今为止最好的蜜源,即为最优解;
步骤3.3),基于abc算法的最优权重计算
利用abc优化算法对步骤2中的四个参数进行优化,得到最优解;
定义:最终风险值fadr=αfa+βfb+γfc+δfd,约束条件为α+β+γ+δ=1,且α,β,γ,δ∈(0,1);根据约束条件,不断优化目标函数达到最佳精度使得最后收敛,得出收敛后的α,β,γ,δ的值;α,β,γ,δ分别为四个指标的权重系数,并将fadr规范化后表示出来;
随机抽取预处理后的已定义好标签和四个指标值的数据作为分类数据,抽取分类数据中的百分之八十定义为训练集,剩余的百分之二十定义为测试集,然后利用机器学习进行分类学习,得到学习后的类别标签值。
进一步的,步骤3中还具有步骤3.4),根据步骤1数据分析可知,三类标准数据集中药品处方药,非处方药甲类和非处方药乙类的药品数量比例分别为70%,20%,10%,根据已知药品的四个风险指标,将训练数据中药品的fadr的值计算出来并按照从大到小的顺序排序,同样按照上述比例进行划分,划分后的三类分别定义为学习后的类别标签值,所述abc优化算法使用的优化目标函数s可依据学习后的类别标签值和标准数据集中的已知类别标签值的比较来进行定义,所述学习后的类别标签值和标准数据集为原本数据实际定义的类别标签值;其中处方药,非处方药甲类和非处方药乙类的分类精确度分别为:p(1)=分处方药正确的药品数/标准数据中处方药的药品数,p(2)=分非处方药甲类正确的药品数/标准数据中非处方药甲类的药品数,p(3)=分非处方药乙类正确的药品数/标准数据中非处方药乙类的药品数;
那么目标函数公式如下:
本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明提供的一种基于不良反应监测报告的药品风险评估模型,以我国药品不良反应adr中的西药报告数据为基础,以非处方药甲类、非处方乙类和处方药三种类别分别作为数据标签,以fa:adr发生率、fb:adr伤害指数、fc:adr覆盖率、fd:adr严重程度四个指标建立综合评价指标,将药品的adr风险系数评分取相应权重并加和,可以反映该品种药品总体上发生adr的危害性大小,尝试将上述风险系数定义adr风险值fadr。利用abc优化算法尝试将上述风险值量化,求出最优权重,最终代入可自动识别所有药品的风险值评估。本发明制定的adr风险系数评分标准可以对药品不良反应进行严重程度的量化评分,且评分具有加和性,因此将所有某种药品的adr风险系数评分取相应权重并加和,可以反映该品种或该种类药品总体上发生adr的风险程度,从而可以据此进行定量对比。本发明为上市后药品安全监测与管理提供了一种用于药品风险量化表示的方法,为后期非处方药和处方药的类别转化提供一个方便可靠的自动识别的参考模型。
附图说明
图1为本发明的流程示意图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
步骤1)获取原始adr数据库,并进行数据预处理;
步骤1.1)
获取原始adr数据库,原始adr数据从国家药品不良反应监测中心获得;本数据是国家药品评价中心药品不良反应自发呈报系统数据库2010~2011年采集的不良反应报告,数据的处理包括对原始adr数据库进行规整以及筛选报告频次大于等于3的数据;
药品分类标准:(1)结合who药品分类等方法,将药品对不同器官损害进行分类,共分为30类,其中不良反应共有897种,每种不良反应均对应不同程度的器官损伤。(2)以药品品种名称为研究对象分析adr,本研究依据国家药品不良反应监测中心获取,药品共分为1763种。
步骤1.2)
根据非处方药品公开目录,对符合要求的数据进行标记,分别标记为处方药(ⅰ类),非处方药甲类(ⅱ类)和非处方药乙类(ⅲ类),作为数据的测试分类标签。
步骤2),查阅相关文献资料,确认药品不良反应风险的相关不同维度因素;影响药品不良反应分析的因素有很多,其中adr发生率、adr伤害指数、adr严重程度、adr覆盖率等均是影响adr集中评价的主要因素。但现有的adr分析方法却很少综合考虑多方面因素,并且现有adr的风险分级标准与方法主要是针对单个病例进行的,针对某种药物的adr风险量化研究相对缺乏。根据资料数据显示,单一指标无法评判adr的严重性,且数据是失真的,缺乏科学性,因此本发明具体设计定义了四个指标fa:adr发生率、fb:adr伤害指数、fc:adr覆盖率、fd:adr严重程度,并建立综合评价体系。
步骤2.1),fa:adr发生率(adrincidencerate)
定义:假设某一药品d,其对应的adr报告总数量为n(d),其中严重报告数量为sn(d),那么
步骤2.2),fb:adr伤害指数(adrinjuryindex)
根据全国数据报告,现将用药后的不良反应情况进行打分,根据其影响分为6个等级,其中:
1级:轻微的药品不良反应症状或疾病,停药后很快好转,无需治疗;评分计为1分;
2级:造成病人短暂损害,不需要住院或延长住院时间,需要治疗或干预,易恢复;评分计为2分;
3级:造成病人短暂损害,门诊病人需住院,住院病人需延长住院时间(7d以上);评分计为3分;
4级:造成病人永久性损害(系统和器官的永久性损害、“三致”、残疾等);评分计为4分;
5级:对生命有危险(如窒息、休克、昏迷、紫绀等需急救的症状);评分计为5分;
6级:死亡;评分计为6分。
按照其用药后患者的机体反应定义其伤害程度,一共分为六级,分值为1-6分,定义:假设某一药品d,其中对应第i个分值c(i)的伤害相关报告数量分别为n(i),i=1,2,...6,其药品对应的adr报告总数量为n(d),那么,
步骤2.3)fc:adr覆盖率(adrcoveragerate)
定义:假设某一药品d所引起的adr的种类数为k(d),所有可能的adr种类数为n,那么,
步骤2.4)fd:adr严重程度(adrseverity)
根据who药品分类相关准则,按照药品对不同器官的损伤,一共可以分为30类,代表其不良反应对应的器官损伤严重程度,结合资料以及专家意见按照其严重性对各种损伤进行打分,将损害程度分为5级,定义为1-5分,假设某一药品d,其对应不良反应的严重程度为id,将药品不良反应进行对应,按照打分最高值定义该不良反应的严重性,可计算出该药物引起该不良反应的严重程度,定义为
dadr=max(id)公式4。
假设该药品引起脱发不良反应,则其对应引起的是对皮肤及其附件损害(1分)和内分泌紊乱(2分),那么该药品引起脱发这个不良反应的分值则为最大值,即为2分,定义为dadr。
最终根据某种药品引起的各种不良反应进行计算,即其中对应第m个分值dadr(m)的伤害相关报告数量分别为n(m),m=1,2,...5,其药品对应的adr报告总数量为n(d),则该药品的不良反应严重程度定义为:
步骤3)
步骤3.1),构建风险系数矩阵;
根据上述步骤定义出的四个指标公式,计算出每个药品di(i=1,2,3,...n)的四个因子(fa,fb,fc,fd)的值,建立风险系数矩阵;
步骤3.2),构建abc算法;
abc算法的基本原理介绍:基本的abc算法通过模拟实际蜜蜂的采蜜机制将人工蜂群分为三类:采蜜蜂、观察蜂和侦察蜂。整个蜂群的目标是寻找花蜜量最大的蜜源。在标准的abc算法中,采蜜蜂利用先前的蜜源信息寻找新的蜜源并与观察蜂分享蜜源信息;观察蜂在蜂房中等待并依据采蜜蜂分享的信息寻找新的蜜源;侦查蜂的任务是寻找一个新的有价值的蜜源,它们在蜂房附近随机地寻找蜜源。
在该算法中,蜜蜂群体前半部分是采蜜蜂组成,后半部分为观察蜂。一只采蜜蜂对应一个食物源,即采蜜蜂的多少等于蜂箱周围的蜜源的多少。采蜜蜂的食物源耗尽之后变为侦查蜂。
根据abc算法,首先对数据进行初始化,将采蜜蜂与蜜源一一对应,更新蜜源信息,同时确定蜜源的花蜜量;观察蜂根据采蜜蜂所提供的信息采用一定的选择策略选择蜜源,更新蜜源信息,同时确定蜜源的花蜜量;确定侦查蜂,寻找新的蜜源;循环重复,记忆迄今为止最好的蜜源,即为最优解;
步骤3.3),基于abc算法的最优权重计算;
随机抽取已定义好标签和四个指标值的数据作为分类数据,其中百分之八十定义为训练集,剩余的百分之二十定义为测试集,利用机器学习进行分类学习。
根据步骤1数据分析可知,三类标准数据集中药品处方药(ⅰ类),非处方药甲类(ⅱ类)和非处方药乙类(ⅲ类)的药品数量比例分别为70%,20%,10%,根据已知药品的四个风险指标,将训练数据中药品的fadr的值计算出来并按照从大到小的顺序排序,同样按照上述比例进行划分,划分后的三类分别定义为学习后的类别标签值。
其中优化目标函数s可依据学习后的类别标签值和标准数据集中已有的类别标签值的比较来进行度量。其中三类标签处方药(ⅰ类),非处方药甲类(ⅱ类)和非处方药乙类(ⅲ类)的分类精确度分别为p(1)=分ⅰ类正确的药品数/标准数据中ⅰ类的药品数,p(2)=分ⅱ类正确的药品数/标准数据中ⅱ类的药品数,p(3)=分ⅲ类正确的药品数/标准数据中ⅲ类的药品数。
目标函数公式如下:
利用abc优化算法对指标中的四个参数进行优化,得到最优解,根据约束条件:α+β+γ+δ=1,且α,β,γ,δ∈(0,1);不断优化达到最佳精度使得最后收敛,得出收敛后的α,β,γ,δ的值,作为四种分类因素的权重指数,并将fadr规范化后表示出来。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!