基于医药知识体系自动梳理药品标签的方法和装置与流程
本发明涉及计算机的中文分词领域。更具体地,涉及基于医药知识体系自动梳理药品标签的方法。
背景技术:
作为医药管理系统,经常会有大量的新药需要录入管理系统。由于录入者众,标准各异,导致对新录入药品的描述也存在重大差异。特别是因为有运营和市场介入的话的,描述发布者比较容易站在自己的kpi立场上考虑问题,慢慢商品就很可能被维护的功能变形了或者成为神奇的,包治百病的药品。
因此,需要开发出能够根据药品的描述快速且自动地将药品归类至医药管理系统,且分析计算出药品真正的、只管他主治功能的标签,还原药品的本来面目。
需要开发一种新技术,来解决针对各异的药品描述,能够尽量规范,能够给各种药品自动标注出规范化标签,以便后续开发中,正确地调取该药品。
技术实现要素:
本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
本发明还有一个目的是提供一种低频rfid电源管理方法,其能够降低电路中储能电容的储蓄量,减少储蓄电容面积,从而缩小芯片面积。。
为了实现根据本发明的这些目的和其它优点,提供了一种低频rfid电源管理方法,包括:
主体,其为上端开口的长方体结构,所述主体的底部铺设有钢筋网;
支撑构件,其包括多个支撑杆和多个钢筋,所述多个支撑杆等间距平行设置在所述钢筋网的下方,所述多个钢筋等间距设置在相邻两个支撑杆之间,且钢筋的铺设方向与支撑杆的铺设方向垂直;
行走构件,其包括一对平行设置的第一滑轨和设置在所述主体一侧壁上的推拉件,所述第一滑轨的两端分别安装在待施工的桥梁下方两侧的路基上,所述推拉件与安装在待施工的桥梁旁的驱动构件连接;
其中,所述主体的底部安装有两组平行设置的滚轮,多个滚轮的安装位置与所述第一滑轨对应,每一滚轮的转轴设置在相邻两个钢筋之间。
优选的是,所述的用于桥梁施工和维护的简易可移动式吊篮,主体的竖直支撑杆包括一外杆和一内杆,所述内杆套设在所述外杆中,所述外杆的内壁上设置有第二滑轨,所述内杆的外壁上设置有与所述第二滑轨配合的滑块,且所述外杆顶部设置有定位件。
优选的是,所述的用于桥梁施工和维护的简易可移动式吊篮,所述定位件为一可拆卸的弯折件,所述弯折件设置为u型,所述弯折件的一支臂设置在所述外杆和内杆之间,另一支臂设置在所述外杆外侧。
优选的是,所述的用于桥梁施工和维护的简易可移动式吊篮,所述推拉件为液压油缸,所述驱动构件为液压泵。
优选的是,所述的用于桥梁施工本发明的一个目的是至少解决上述问题,并提供后面将说明的其它优点;
本发明另一个目的是提供一种基于医药知识体系自动梳理药品标签的方法,能够显著提高药品描述的可靠性;
本发明的又一个目的是提供基于医药知识体系自动梳理药品标签的方法,能够提高梳理药品的效率;以及
本发明的再一个目的是提供基于医药知识体系自动梳理药品标签的装置,电子设备,以及存储介质,以实现上述方法。
为了实现根据本发明的这些目的和其它优点,提供了一种基于医药知识体系自动梳理药品标签的方法,其中,包括以下步骤:
构建树状结构的医药知识体系,其中,树状结构的各末端叶子节点上的数据均为疾病标识,各疾病标识对应有症状标签和/或隐意词元标签;
基于上述医药知识体系,利用支持识别词性的分词工具,将待梳理的药品的注释采用随机游走算法模型获取一条最长游走结果,即对应至上述树状结构中的一条具体枝干,将该待梳理的药品对应至该条具体枝干的末端叶子节点上;
由此,将相应的末端叶子节点上的疾病标识所对应的症状标签和/或隐意词元标签赋予该待梳理的药品,以完成该药品的自动标签梳理工作。
例如疾病标识为风热感冒,或者为风热感冒的id。对应的症状标签有:黄痰,黄鼻涕,咳嗽,发烧等,隐意词元有风温,温病,中风,伤寒等。待梳理的药品例如为同仁堂风热感冒颗粒,将这个药品挂在风热感冒这个末端叶子节点上。或者说,将同仁堂风热感冒颗粒的id与风热感冒的id关联起来。并且,风热感冒的id还可以关联更多的药品id。如小儿风热颗粒,风热感冒胶囊等等。这样,新录入的药品,如同仁堂风热感冒颗粒就能够获得症状标签黄痰,黄鼻涕,咳嗽,发烧等,和隐意词元标签风温,温病,中风,伤寒等。
所述的基于医药知识体系自动梳理药品标签的方法,其中,在所述构建树状结构的医药知识体系的步骤中,包括:人工标注出一批样本数据;和根据该样本数据,利用分词工具训练和学习在专业站点上定期爬出来的专业数据,由此构建树状结构的医药知识体系。
这是一种人工智能的学习方法。
所述的基于医药知识体系自动梳理药品标签的方法,其中所述识别词性为将各疾病标识定义为不同的词性,将该待梳理的药品对应至末端叶子节点即将相应的词性赋予该待梳理的药品。
也就是说,这里需要利用能够识别词性的分词工具,但并不是直接利用分词工具来区分名词,动词,形容词等。而是将个疾病标识定义为不同的词性,例如将风热感冒的id定义为一种词性,目的是用来区分待梳理的药品应当归属的疾病标识。
所述的基于医药知识体系自动梳理药品标签的方法,其中,所述疾病标识为最细粒度的疾病的唯一识别码。
所述的基于医药知识体系自动梳理药品标签的方法,其中,所述该待梳理的药品包括药品名称与其唯一识别码。
最终,药品的识别码与疾病的识别码相关联。
所述的基于医药知识体系自动梳理药品标签的方法,其中,若待梳理的药品的注释不能与医药知识体系相匹配,则将该药品移至待人工处理区,供后续人工进行处理。
这说明,没有挂进知识库里的药品也会进行记录,然后可以人工在知识库里维护,也会把药品名称的信息推到训练集里去,供后续离线训练继续训练它。目前这种识别不了的,大多是人工干处理。识别不到新上架的药品频率很低。因为建数据,外部来源抽取数据后,新增药品很少很慢,药品上市流程很长,出现这种情况的大多是些保健药品,如补充蛋白、维生素和一些微信里卖的减肥药、神奇药膏等。
所述的基于医药知识体系自动梳理药品标签的方法,其中,当爬出专业数据对树状结构的医药知识体系进行更新后,对所有药品也重新进行梳理,以更新各药品的标签。
实际应用中,每天都会根据新的信息更新知识树,之后会重新计算药品与知识树的关系。假定有八十万种药品,大概只需要5分钟的时间,就能够针对更新后的知识树重新梳理完成八十万种药品的标签。
本发明还提供了基于医药知识体系自动梳理药品标签的装置,其中,包括:构建医药知识体系模块,其构建树状结构的医药知识体系模块,所构建的树状结构的各末端叶子节点上的数据均为疾病标识,各疾病标识对应有症状标签和/或隐意词元标签;
梳理模块,用于基于上述医药知识体系,利用支持识别词性的分词工具,将待梳理的药品的注释采用随机游走算法模型获取一条最长游走结果,即对应至上述树状结构中的一条具体枝干,将该待梳理的药品对应至该条具体枝干的末端叶子节点上;
由此,将相应的末端叶子节点上的疾病标识所对应的症状标签和/或隐意词元标签赋予该待梳理的药品,以完成该药品的自动标签梳理工作。
所述的基于医药知识体系自动梳理药品标签的装置,其中,所述构建医药知识体系模块包括:样本标注模块,用于由人工标注出一批样本数据;和
训练模块,用于根据该样本数据,利用分词工具训练和学习在专业站点上定期爬出来的专业数据,由此构建树状结构的医药知识体系。
本发明还公开了一种电子设备,其中,包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器执行上述方法中任一项所述的方法。
本发明还公开了一种存储介质,其上存储有计算机程序,其中,该程序被处理器执行时,实现上述方法中任一项所述的方法。
本发明至少包括以下有益效果:1)规范化药品描述;2)提高药品录入效率;3)提药品标签的可靠性,从而显著提升药品数据库的后续利用效率和效果。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
图1为表达本发明药品标签梳理系统的流程示意意图;
图2为通过本发明梳理出的药品标签的使用示意图;
图3为本发明药品知识系统的结构示意图;以及
图4为本发明的基于医药知识体系自动梳理药品标签的装置的示意图。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不配出一个或多个其它元件或其组合的存在或添加。
利用人工智能的方式整理数据,通常需要基于图数据库形成的知识图谱。
知识图谱需要大量的数据进行训练,其准确性受制于数据质量和算法质量,在逻辑关系比较复杂医药领域内暂时没有更好的应用实例。我们分析了医药知识的特点,以预测准确、反应迅速为目标,发明了针对医药知识体系的药品标签梳理方法,搭建自己的医药知识森林,作为一个准确、中立的商品标签供公司各部门使用。
医药商品库,由于运营人员、市场人员的介入越来越深越来越频繁,而各方诉求、kpi等目标不一致等,录入的药品注释(药品说明书)差别很大,也未必客观准确,导致维护的商品数据偏差与错误几率逐渐加大。有让大部分药品包治百病的发展趋势。
本功能利用已形成的医药知识体系对商品重新进行商品标签、商品图谱刻画,让药品回归药品说明中本该主治的病症。让上层的搜索、推荐、用户画像能够使用一份准确、中立的商品标签。
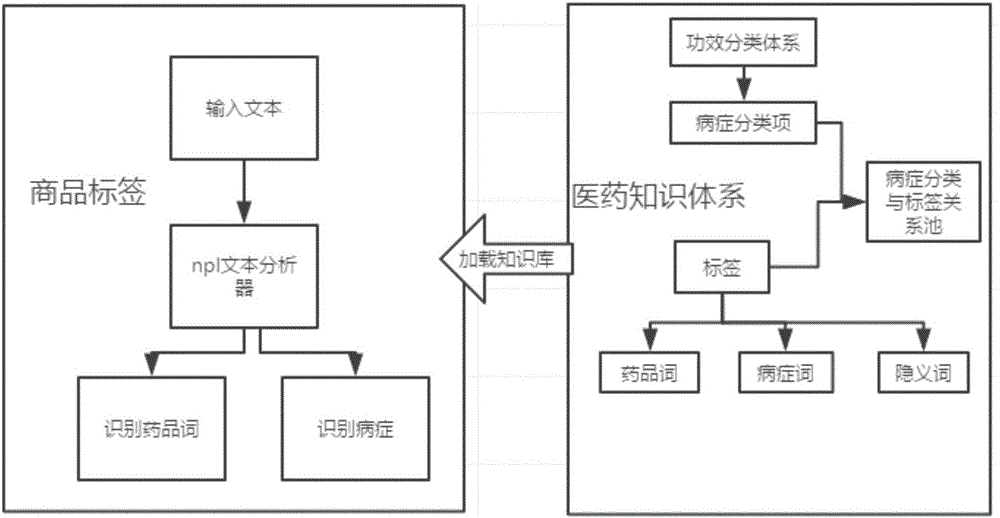
因此,如图1所示,首先使用层级结构设计出term树链,顶层为概括性分类,层层细化病症,最后落到叶子节点为一个最细粒度的疾病。而在疾病下面又对应挂载有对应疾病常出现的症状、有效治疗的药品和一些隐义的term(部分也能表述成此疾病的term)以此形成具有n颗树状结构的医药知识森林。
然后,执行步骤1:基于上述知识体系在程序中使用ansj等支持识别词性的nlp分词工具进行知识装载与学习(所有term均挂载最终叶子节点的标识,可多个叶子节点绑定到一个term上即1:n);
步骤2:装载药品的名称与唯一标识;
步骤3:迭代药品名使用nlp分词工具利用随机游走算法模型获取一条最长游走结果进行知识森林中找到具体某棵知识树中的某个具体枝干(最终叶子节点);
步骤4:通过识别到的叶子节点即可清洗出该药品能治哪些疾病,并具有哪些明细症状等标签;
步骤5:将自动识别到的药品标签进行固化供后续业务使用;
由于本实现方案执行效率方面,单药品识别执行效率能保证在50ms以内出预测结果,故能同时应用于实时在线识别预测与离线识别清洗商品图谱。
通过药品名能自动清洗出一份干净的商品图谱(一份能自动过滤掉运营的干扰词汇与描述等,让药品回归真正的本性的商品标签数据),再将商品图谱根据用户行为数据即可丰富底层的用户画像标签,能准确勾画出用户可能存在的疾病与症状。通过用户画像中标签再进行商品推荐与排序模型影响带来与更贴近用户的购物体验并尽可能缩短用户购物路径,增加用户购买的可能性。如图2所示,图2给出了一种本发明的使用方法。也就是在本发明得到了药品标签的基础上,在结合用户的行为数据,就能够给用户推荐合适的药品。
图3给出了本发明的一种医药知识图谱的示意图,例如将感冒分出痰热壅肺,这就是这一知识树的末端叶子节点。而下面的症状分支和隐义词,就是旁边药品的标签。
多个不同的药品可以拥有相同的标签。
图4为本发明公开的装置,用来实现本发明的方法。
这样,本发明能够实现:
1、通过药品知识体系的term体系快速识别到最细疾病节点算法
2、基于医药知识体系自动梳理药品标签的方法
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!