使用移动装置持续监测用户健康的制作方法
相关申请的交叉引用
本申请要求于2018年10月5日提交的美国申请号16/153,345的优先权,美国申请号16/153,345是于2016年12月28日提交的美国申请序列号15/393,077的部分延续申请,美国申请序列号15/393,077是于2015年6月3日提交的美国申请序列号14/730,122(其现在是于2017年2月21日公布的美国专利号9,572,499)的延续申请,美国申请序列号14/730,122是于2014年12月12日提交的美国申请序列号14/569,513(其现在是于2016年8月23日公布的美国专利号9,420,956)的延续申请,美国申请序列号14/569,513要求于2013年12月12日提交的美国临时申请号61/915,113的权益(该申请通过引用并入本文)、2014年3月14日提交的美国临时申请号61/953,616的权益、2014年3月21日提交的美国临时申请号61/969,019的权益、2014年3月26日提交的美国临时申请号61/970,551的权益(该申请通过引用并入本文)、以及2014年6月19日提交的美国临时申请号62/014,516的权益(该申请通过引用并入本文)。本申请还要求于2017年10月6日提交的美国临时申请62/569,309(其全部内容通过引用并入本文)和于2017年11月21日提交的美国临时申请62/589,477(其全部内容通过引用并入本文)的权益。
背景技术:
个体生理健康的指标(“健康指标”)(例如但不限于:心率、心率变异性、血压和ecg(心电图)等)可以是根据为了测量健康指标而收集的数据在任何离散的一个或多个时间点处测量或计算出的。在许多情况下,特定时间的健康指标的值、或随着时间的推移而发生的变化提供了与个体健康状况有关的信息。例如,低或高的心率或血压、或清晰展现了心肌缺血的ecg可以展现出对于立即干预的需求。但是需要注意,这些指标的读数、一系列读数或读数随着时间的推移的变化可能提供用户或甚至健康专业人员不能识别的信息。
心律失常例如可能持续发生或者可能间歇性发生。持续发生的心律失常可以由个体的心电图最明确地诊断出来。由于持续心律失常总是存在,因此可以在任何时间应用ecg分析,以诊断心律失常。ecg也可用于诊断间歇性心律失常。然而,由于间歇性心律失常可能是无症状的和/或按照定义是间歇性的,因此诊断呈现出在个体正在经历心律失常时应用诊断技术的挑战。因此,间歇性心律失常的实际诊断非常困难。这种特殊的困难与无症状心律失常(占美国心律失常的近40%)相结合。borianig.和pettorellid.,atrialfibrillationburdenandatrialfibrillationtype:clinicalsignificanceandimpactontheriskofstrokeanddecisionmakingforlong-termanticoagulation,vasculpharmacol.,83:26-35(2016年8月),第26页。
存在允许经常或持续监测并记录健康指标的传感器和移动电子技术。然而,这些传感器平台的能力常常超过传统医学科学解释传感器所产生的数据的能力。例如心率等的健康指标参数的生理意义经常仅在特定的医学上下文中得到很好的定义:例如,在脱离上下文的情况下,传统上根据可能影响健康指标的其它数据/信息将心率评价为单个标量值。在每分钟60~100次跳动(bpm)的范围内的静息心率可被认为是正常的。用户大体上可能每天一次或两次地手动测量他们的静息心率。
移动传感器平台(例如:移动血压袖带;移动心率监视器;或移动ecg装置)可以能够持续监测健康指标(例如,心率),例如能够每秒或每5秒产生一次测量,同时还获取与用户有关的其它数据,诸如但不限于:活动水平、身体位置、以及例如气温、气压、位置等的环境参数。在24小时时间段内,这可能导致数千次独立的健康指标测量。与每天一次或两次的测量相对,关于数千次测量的“正常”序列看起来如何,存在相对少的数据或医学共识。
目前用于持续测量用户/患者的健康指标的装置从体积庞大、具有侵入性且不便利的装置到简单的可穿戴式或手持式移动装置不等。目前,这些装置未提供用以有效地利用数据来持续监测个人健康的能力。依赖于用户或健康专业人员来根据可能影响健康指标的其它因素来评估这些健康指标以确定用户的健康状况。
附图说明
在所附权利要求书中特别地阐述了这里描述的某些特征。将通过参考阐述了利用这里描述的原理的例示性实施例的以下具体说明和附图来获得对所公开的实施例的特征和优点的更好理解,在附图中:
图1a~1b描绘了根据如这里描述的一些实施例可以使用的卷积神经网络;
图2a~2b描绘了根据如这里描述的一些实施例可以使用的递归神经网络;
图3描绘了根据如这里描述的一些实施例可以使用的可选递归神经网络;
图4a~4c描绘了用以展现如这里描述的一些实施例的应用的假设数据标绘图;
图5a~5e描绘了根据如这里描述的一些实施例的可选递归神经网络以及用于描述这些实施例中的一些的假设标绘图;
图6描绘了根据如这里描述的一些实施例的展开递归神经网络;
图7a~7b描绘了根据如这里描述的一些实施例的系统和装置;
图8描绘了根据如这里描述的一些实施例的方法;
图9a~9b描绘了根据如这里描述的一些实施例的方法以及用以展现一个或多个实施例的心率相对于时间的假设标绘图;
图10描绘了根据如这里描述的一些实施例的方法;
图11描绘了用以展现如这里描述的一些实施例的应用的假设数据标绘图;以及
图12描绘了根据如这里描述的一些实施例的系统和装置。
具体实施方式
大数据量、健康指标与其它因素之间相互作用的复杂性以及有限的临床指导可能限制尝试基于传统医学实践通过具体规则来检测连续和/或流动传感器数据中的异常的任何监测系统的有效性。这里描述的实施例包括可以利用预测机器学习模型根据健康指标数据单独或与其它因素(如这里定义)数据相结合以无监督的方式检测的时间序列中的异常的装置、系统、方法和平台。
心房颤动(af或afib)在一般人群中的发生率为1~2%,并且af的存在增加了诸如中风和心脏衰竭等的发病风险以及不利结果。borianig.和pettorellid.,atrialfibrillationburdenandatrialfibrillationtype:clinicalsignificanceandimpactontheriskofstrokeanddecisionmakingforlong-termanticoagulation,vasculpharmacol.,83:26-35(2016年8月),第26页。在许多人中(据估计高达40%的af患者中),afib可能是无症状的,并且这些无症状患者与有症状患者具有类似的中风和心脏衰竭的风险状况。参见同上出处。然而,有症状患者可以采取积极的措施(诸如服用血液稀释剂或其它药物)以降低负面结果的风险。使用植入式电气装置(cied)可以检测无症状af(所谓的沉默性af或saf)以及患者处于af中的持续时间。同上出处。根据该信息,可以确定这些患者处于af或af负荷时所度过的时间。同上出处。大于5~6分钟、特别地大于1小时的af负荷与中风和其它负面健康结果的显著增加的风险相关联。同上出处。因此,测量无症状患者中的af负荷的能力可以使得早期介入治疗,并且可以降低与af相关联的负面健康结果的风险。同上出处。saf的检测是有挑战性的,通常需要某种形式的持续监测。目前,对af的持续监测需要体积庞大、有时具有侵入性且昂贵的装置,其中这种监测需要高水平的医学专业人员监督和审查。
许多装置持续获得数据以提供对健康指标数据的测量或计算,例如但不限于
如这里使用的,平台包括一个或多个定制软件应用(或“应用”),该一个或多个定制软件应用被配置为在本地或通过包括云和因特网的分布式网络彼此交互。如这里描述的平台的应用被配置为收集和分析用户数据,并且可以包括一个或多个软件模型。在平台的一些实施例中,平台包括一个或多个硬件组件(例如,一个或多个感测装置、处理装置或微处理器)。在一些实施例中,平台被配置为与一个或多个装置和/或一个或多个系统一起操作。也就是说,在一些实施例中,如这里描述的装置被配置为使用内置处理器来运行平台的应用,并且在一些实施例中,平台被包括与平台的一个或多个应用进行交互或运行平台的一个或多个应用的一个或多个计算装置的系统所利用。
本发明描述了用于结合与可能影响健康指标的因素(这里被称为“其它因素”)相关的(时间上)相应数据来持续监测来自用户装置的与一个或多个健康指标相关的用户数据(例如但不限于ppg信号、心率或血压等)以通过例如但不限于以下内容判定或与例如但不限于以下内容相比较来判断用户是否具有正常健康的系统、方法、装置、软件和平台:i)受类似的其它因素影响的一组个体;或者ii)受类似的其它因素影响的用户自己。在一些实施例中,测量健康指标数据单独地或与其它因素数据相结合地输入到经训练的机器学习模型中,其中该机器学习模型确定用户的测量健康指标被考虑为在健康范围内的概率,并且在用户的测量健康指标被考虑为不在健康范围内的情况下向用户通知这种情况。不处于健康范围内的用户可能会增加用户可能正在经历需要高保真度信息以确认诊断的健康事件(诸如可能有症状或无症状的心律失常)的可能性。通知可以采取例如请求用户获得ecg的形式。可以请求其它高保真度测量(血压、脉搏血氧计等),ecg只是一个示例。高保真度测量(在本实施例中为ecg)可以通过算法和/或医学专业人员进行评价,以进行通知或诊断(这里统称为“诊断”,认识到只有医师才能进行诊断)。在ecg示例中,诊断可能是afib或使用ecg进行诊断的任何其它数量的众所周知的状况。
在进一步的实施例中,诊断用于标记低保真度数据序列(例如,心率或ppg),该低保真度数据序列可以包括其它因素数据序列。这种高保真度诊断标记后的低保真度数据序列用于训练高保真度机器学习模型。在这些进一步的实施例中,高保真度机器学习模型的训练可以通过无监督学习来训练,或者可以利用新的训练示例不时更新。在一些实施例中,用户的测量低保真度健康指标数据序列以及可选的其它因素的(时间上)相应数据序列被输入到经训练的高保真度机器学习模型中,以确定用户正在经历或经历过诊断状况的概率和/或预测,其中,高保真度机器学习模型是针对该诊断状况而训练的。这种概率可以包括事件何时开始以及事件何时结束的概率。例如,一些实施例可以计算用户的心房颤动(af)负荷、或者用户随时间经历af的时间量。先前,af负荷只能使用麻烦且昂贵的动态心电图或植入式持续ecg监测设备来确定。因此,这里描述的一些实施例可以通过单独地或与其它因素的相应数据相结合地持续监测从用户佩戴的装置获得的健康指标数据(例如但不限于ppg数据、血压数据和心率数据等),来持续监测用户的健康状况并向用户通知健康状况变化。如这里使用的“其它因素”包括可能影响健康指标和/或可能影响表示健康指标的数据(例如,ppg数据)的任何因素。这些其它因素可以包括各种因素,诸如但不限于:气温、海拔、锻炼水平、体重、性别、饮食、站着、坐着、跌倒、躺下、天气、以及bmi等。在一些实施例中,可以使用并非机器学习模型的数学或经验模型来确定何时通知用户获得高保真度测量,然后该高保真度测量可被分析并用于训练如这里描述的高保真度机器训练模型。
这里描述的一些实施例可以通过如下操作以无监督的方式检测用户的异常:接收健康指标数据的主时间序列;可选择地接收在时间上与健康指标数据的主时间序列相对应的一个或多个其它因素数据的次时间序列,这些次序列可以来自传感器或者来自外部数据源(例如,通过网络连接、计算机api等);将主时间序列和次时间序列提供至预处理器,该预处理器可以对数据进行诸如滤波、高速缓存、求平均、时间对齐、缓冲、上采样和下采样等的操作;将数据的时间序列提供至机器学习模型,该机器学习模型被训练和/或配置为利用主时间序列和次时间序列的值来预测主时间序列在未来时间处的下一值;将特定时间t处的由机器学习模型生成的预测主时间序列值与时间t处的主时间序列的测量值进行比较;以及在预测未来时间序列与测量时间序列之间的差超过阈值或标准的情况下警告或提示用户采取动作。
因此,这里描述的一些实施例检测相对于时间的流逝和/或响应于所观察到的数据的次序列而观察到的生理数据的主序列的行为何时与在给定用于训练模型的训练示例的情况下所预期的行为不同。在从正常个体或从特定用户的先前被归类为正常的数据中收集训练示例的情况下,系统可以用作异常检测器。如果数据仅仅是在没有任何其它分类的情况下从特定用户获取的,则系统可以用作变化检测器,用于检测主序列正在测量的健康指标数据相对于捕获训练数据的时间的变化。
这里描述了如下的软件平台、系统、装置和方法:用于生成经训练的机器学习模型,并使用该模型来预测或确定受其它因素(次序列)影响的用户的测量健康指标数据(主序列)在受类似其它因素影响的健康人群的正常界限(即,全局模型)外、或者在受类似其它因素影响的该特定用户的正常界限(即,个性化模型)外的概率,其中向用户提供这样的通知。在一些实施例中,可以提示用户获得可用于标记先前获取的低保真度用户健康指标数据的附加的测量高保真度数据,以生成不同的经训练的高保真度机器学习模型,该模型具有仅使用低保真度健康指标数据来预测或诊断异常或事件的能力,其中这种异常通常仅使用高保真度数据进行识别或诊断。
这里描述的一些实施例可以包括输入用户的健康指标数据,以及可选地将其它因素的(时间上)相应数据输入到经训练的机器学习模型中,其中经训练的机器学习模型预测未来时间步骤处的用户的健康指标数据或健康指标数据的概率分布。在一些实施例中,将预测与预测时间步骤处的用户的测量健康指标数据进行比较,其中,如果差的绝对值超过阈值,则向用户通知他或她的健康指标数据在正常范围外。在一些实施例中,该通知可以包括诊断或做某事的指示,例如但不限于获得附加的测量或联系健康专业人员。在一些实施例中,使用来自健康人群的健康指标数据和其它因素的(时间上)相应数据来训练机器学习模型。应当理解,用于训练机器学习模型的训练示例中的其它因素可能不是人群的平均,相反,其它因素中的各因素的数据在时间上与训练示例中的个体的健康指标数据的集合相对应。
一些实施例被描述为接收时间上的离散数据点、根据输入预测未来时间处的离散数据点、然后判断未来时间处的离散测量输入与未来时间处的预测值之间的损失是否超过阈值。本领域技术人员将容易理解,输入数据和输出预测可以采取除离散数据点或标量之外的形式。例如但不限于,健康指标数据序列(这里也称为主序列)和其它数据序列(这里也称为次序列)可被划分成时间片段。本领域技术人员将认识到,数据分段的方式是设计选择的问题,并且可以采取许多不同的形式。
一些实施例将健康指标数据序列(这里也称为主序列)和其它数据序列(这里也称为次序列)分割成两个片段:过去,表示特定时间t之前的所有数据;以及未来,表示时间t处或之后的所有数据。这些实施例将过去时间片段的健康指标数据序列和过去时间片段的所有其它数据序列输入到机器学习模型中,该机器学习模型被配置为预测健康指标数据的最可能的未来片段(或可能的未来片段的分布)。可选地,这些实施例将过去时间片段的健康指标数据序列、过去时间片段的所有其它数据序列和未来片段的其它数据序列输入到机器学习模型,该机器学习模型被配置为预测健康指标数据的最可能的未来片段(或可能的未来片段的分布)。将预测的健康指标数据的未来片段与未来片段处的用户的测量健康指标数据进行比较以判断损失以及该损失是否超过阈值,在这种情况下,采取一些动作。动作可以包括例如但不限于:通知用户获得附加数据(例如,ecg或血压);通知用户联系健康专业人员;或自动触发附加数据的获取。自动获取附加数据可以包括例如但不限于经由可操作地(有线或无线)耦接至用户佩戴的计算装置的传感器的ecg获取、或经由围绕用户的手腕或其它适当身体部位并且耦接至用户佩戴的计算装置的移动袖带的血压。数据片段可以包括单个数据点、某一时间段内的许多数据点、该时间段内的这些数据点的平均值,其中平均值可以包括真正平均值、中值或众数。在一些实施例中,片段可以在时间上重叠。
这些实施例检测受(时间上)如相应的其它因素数据序列所影响的那样、相对于时间流逝而观察到的健康指标数据序列的行为或测量何时与根据训练示例所预期的行为或测量不同,其中训练示例是在类似的其它因素下收集到的。如果训练示例是从类似的其它因素下的健康个体、或者从类似的其它因素下的特定用户的先前被归类为健康的数据中收集到的,则这些实施例分别用作来自健康人群或特定用户的异常检测器。如果训练示例仅仅是在没有任何其它分类的情况下从特定用户获取的,则这些实施例用作变化检测器,用于检测特定用户的测量时的健康指标相对于收集训练示例的时间的变化。
这里描述的一些实施例利用机器学习来持续监测在一个或多个其它因素的影响下的一个人的健康指标,并且根据在类似其它因素的影响下的被归类为健康的人群来评估这个人是否是健康的。如本领域技术人员将容易理解的,在不超出这里描述的范围的情况下,可以使用多种不同的机器学习算法或模型(包括但不限于bayes、markov、gausian过程、聚类算法、生成模型、核和神经网络算法)。如本领域技术人员所理解的,典型的神经网络采用例如但不限于非线性激活函数的一个或多个层来预测接收输入的输出,并且除了输入层和输出层之外,还可以包括一个或多个隐藏层。这些网络中的一些网络的各隐藏层的输出用作网络中的下一层的输入。神经网络的示例包括例如但不限于生成神经网络(generativeneutralnetwork)、卷积神经网络和递归神经网络。
健康监测系统的一些实施例监测作为低保真度数据(例如,心率或ppg数据)的个体的心率和活动数据,并检测通常使用高保真度数据(例如,ecg数据)进行检测的状况(例如,afib)。例如,个体的心率可以由传感器持续地或以离散的间隔(诸如每五秒)提供。心率可以基于ppg、脉搏血氧计或其它传感器来确定。在一些实施例中,活动数据可被生成为所进行的迈步数、感测到的移动量或指示活动水平的其它数据点。然后,低保真度(例如,心率)数据和活动数据可被输入到机器学习系统中,以确定高保真度结果的预测。例如,机器学习系统可以使用低保真度数据来预测心律失常或用户心脏健康的其它指示。在一些实施例中,机器学习系统可以使用数据输入的片段的输入来确定预测。例如,一小时的活动水平数据和心率数据可被输入到机器学习系统中。然后,系统可以使用这些数据来生成对诸如心房颤动等的状况的预测。以下更详尽地讨论了本发明的各种实施例。
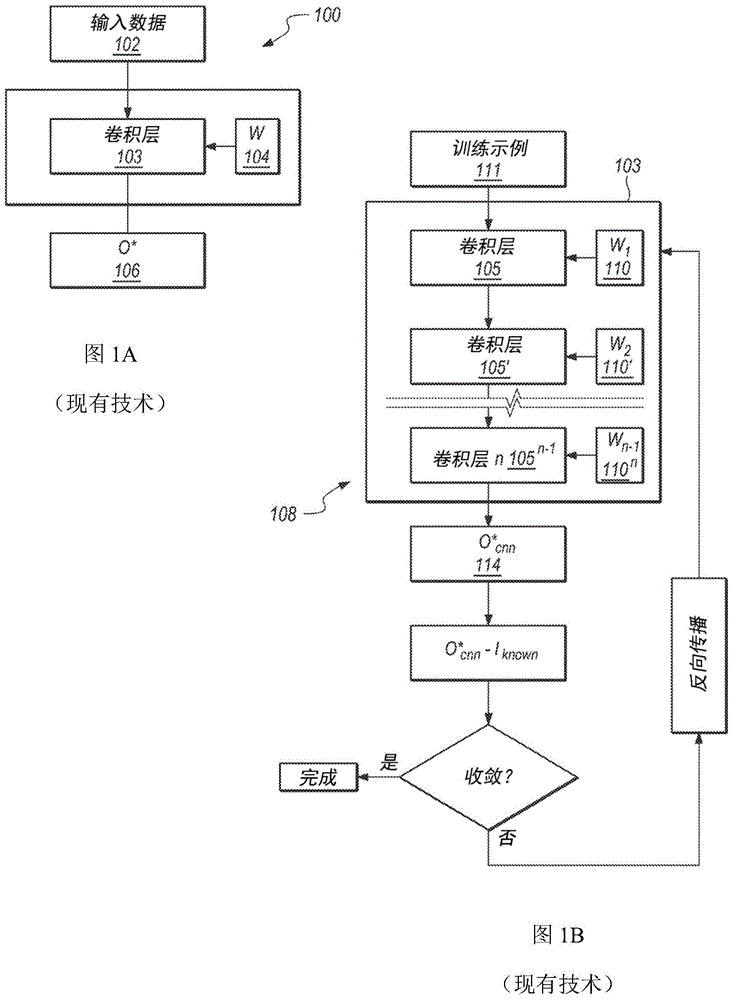
参考图1a,经训练的卷积神经网络(cnn)100(前馈网络的一个示例)将输入数据102(例如,船的图片)带入到卷积层(又称隐藏层)103中,对各卷积层103中的输入数据106应用一系列经训练的权重或滤波器104。第一卷积层的输出是激活映射(未示出),该激活映射是应用了经训练的权重或滤波器(未示出)的第二卷积层的输入,其中后续卷积层的输出得到表示第一层的输入数据的越来越复杂的特征的激活映射。在各卷积层之后,应用非线性层(未示出)来引入非线性问题,其中非线性层可以包括tanh、sigmoid或relu。在一些情况下,可以在非线性层之后应用池化层(未示出)(也称为下采样层),其中该池化层基本上采用相同长度的滤波器和步长(stride),并将其应用于输入,并输出滤波器进行卷积运算的每个子区域的最大数量。池化的其它选项是平均池化和l2范数池化。池化层降低了输入体积的空间维度,从而降低了计算成本并控制了过度拟合。网络的最后层是全连接层,该全连接层获取上一个卷积层的输出并输出表示要预测的量(例如,图像分类的概率:20%汽车,75%船,5%公交车以及0%自行车)的n维输出向量,即,得到预测输出106(o*),例如,这可能是船的图片。输出可以是网络正在预测的标量值数据点,例如股票价格。如以下更全面地描述,经训练的权重104对于各卷积层103可能是不同的。为了实现这种现实世界的预测/检测(例如,它是一个船),需要就已知数据输入或训练示例对神经网络进行训练,从而得到经训练的cnn100。为了训练cnn100,将许多不同的训练示例(例如,许多船的图片)输入到模型中。神经网络领域的技术人员将充分理解,以上说明提供了cnn的某种简单化观点以针对当前讨论提供某种上下文,并且将充分理解单独应用任何cnn或与其它神经网络相结合地应用cnn将是同样适用的、并且在这里描述的一些实施例的范围内。
图1b展现了训练cnn108。在图1b中,卷积层103被示出为单个隐藏卷积层105、105’直到卷积层105n-1,并且最后的第n层是全连接层。应当理解,最后的层可以是多于一个全连接层。将训练示例111输入到卷积层103中,将非线性激活函数(未示出)和权重110、110’到110n连续应用于训练示例111中,其中任何隐藏层的输出是下一层的输入,依此类推,直到最后的第n个全连接层105n产生输出114。将输出或预测114与训练示例111(例如,船的图片)进行比较,得到输出或预测114与训练示例111之间的差116。如果差或损失116小于某个预设损失(例如,输出或预测114预测物体是船),则cnn收敛并被认为是经训练的。如果cnn尚未收敛,则使用反向传播技术,根据预测与已知输入多接近来更新权重110和110’到110n。本领域技术人员将理解,可以使用除反向传播之外的方法来调整权重。输入第二个训练示例(例如,不同的船的图片),并利用更新后的权重再次重复该处理,然后再次更新权重,依此类推,直到已经输入第n个训练示例(例如,第n个船的第n个图片)。通过相同的n个训练示例反复重复该处理,直到卷积神经网络(cnn)被训练或收敛于已知输入的正确输出。一旦cnn108被训练,权重110、110’到110n(即如图1a中所描绘的权重104)就固定并用于经训练的cnn100。如所解释的,对于各卷积层103和各全连接层存在不同的权重。然后,向经训练的cnn100或模型馈送图像数据,以确定或预测它被训练以预测/识别的事物(例如,船),如以上所述。任何经训练的模型、cnn、rnn等可以利用附加训练示例或者由模型输出、继而用作训练示例的预测数据来进一步训练,即,可以允许修改权重。机器学习模型可以“离线”训练,例如在与使用/执行经训练的模型的平台分离的计算平台上进行训练、然后被传送至使用/执行经训练的模型的平台。可选地,这里描述的实施例可以基于新获取的训练数据来定期或持续地更新机器学习模型。这种更新训练可以在通过网络连接将更新后的经训练模型传递至使用/执行再训练的模型的平台的单独计算平台上进行,或者训练/再训练/更新处理可以在获取到新数据时在使用/执行再训练的模型的平台本身上进行。本领域技术人员将理解,cnn适用于固定阵列中的数据(例如,图片、字符、词等)或数据的时间序列。例如,可以使用cnn来对序列化的健康指标数据和其它因素数据进行建模。一些实施例利用具有跳跃连接和高斯混合模型输出的前馈cnn来确定预测健康指标(例如,心率、ppg或心律失常)的概率分布。
一些实施例可以利用其它类型和配置的神经网络。卷积层的数量以及全连接层的数量可以增加或减少。一般来说,卷积层相对于全连接层的最佳数量和比例可以通过确定哪种配置对于给定数据集提供了最佳性能来以实验的方式设置。卷积层的数量可以减少至0,剩下全连接网络。卷积滤波器的数量和各滤波器的宽度也可以增加或减少。
神经网络的输出可以是与对主时间序列的精确预测相对应的单个标量值。可选地,神经网络的输出可以是逻辑回归,在该逻辑回归中,各类别与主时间序列值的特定范围或种类相对应,其中这些主时间序列值是本领域技术人员容易理解的任意数量的可选输出。
在一些实施例中,使用高斯混合模型输出旨在约束网络学习形式良好的概率分布、并改进有限训练数据的一般化。在一些实施例中,在高斯混合模型中使用多个元素旨在允许该模型学习多模式概率分布。还可以使用对不同神经网络的结果进行组合或聚合的机器学习模型,其中可以组合各结果。
具有来自先前预测的可更新的记忆或状态以应用于后续预测的机器学习模型是用于对序列化数据进行建模的另一种方法。特别地,这里描述的一些实施例利用递归神经网络。参考图2a的示例,示出经训练的递归神经网络(rnn)200的图。经训练的rnn200具有可更新的状态(s)202和经训练的权重(w)204。将输入数据206输入到应用权重(w)204的状态202中,并且输出预测206(p*)。与线性神经网络(例如,cnn100)相对,状态202基于输入数据进行更新,从而用作来自先前状态的记忆以依次用于利用下一数据的下一预测。更新状态为rnn提供了环状或循环特征。为了更好地展现,图2b示出展开的经训练的rnn200以及它对于序列化数据的适用性。在展开时,rnn表现得与cnn类似,但在展开的rnn中,各明显类似的层表现为具有更新后的状态的单个层,其中在循环的各迭代中应用相同的权重。本领域技术人员将理解,单个层本身可能具有子层,但是为了清楚解释,这里描述了单个层。将时间t处的输入数据(it)208输入到时间t处的状态(st)210,并且在时间t处的神经元(ct)212内应用经训练的权重204。ct212的输出是时间步骤t+1处的预测
与cnn一样,rnn可以处理作为输入的数据串,并输出预测数据串。用以解释使用rnn的该方面的简单方式是使用自然语言预测的示例。以下面的短语为例:theskyisblue(天空是蓝色的)。词串(即,数据)具有上下文。因此,随着状态更新,数据串从一个迭代更新到下一迭代,从而提供了用以预测blue(蓝色)的上下文。正如刚刚描述的,rnn具有用以辅助对序列化数据进行预测的记忆分量。然而,rnn的更新后的状态中的记忆可能在它可以回溯多远这一方面受到限制,类似于短期记忆。当期望在更长回溯(类似于长期记忆)的情况下预测序列化数据时,可以使用对刚刚描述的rnn的微调来实现这一点。从前面或周围紧邻的词不清楚要预测的词的句子又是用以解释以下内容的简单示例:maryspeaksfluentfrench(mary讲流利的法语)。从前面紧邻的词不清楚french(法语)是正确的预测;只清楚某种语言是正确的预测,但哪种语言是正确的预测呢?正确的预测可能存在于以比单个词串更大的间隔分隔的词的上下文中。长期记忆(longtermmemory,lstm)网络是一种特殊的rnn,它能够学习这些(更)长期依赖关系。
如上所述,rnn具有相对简单的重复结构,例如,它们包括具有非线性激活函数(例如,tanh或sigmoid)的单个层。类似地,lstm具有链状结构,但是(例如)具有四个神经网络层,而不是一个。这些附加的神经网络层为lstm提供了通过使用被称为神经元门的结构来相对于状态(s)删除或添加信息的能力。同上出处。图3示出用于lstmrnn的神经元300。线302表示神经元状态(s),并且可被视为信息高速公路;它相对容易地使信息沿着未改变的神经元状态流动。同上出处。神经元门304、306和308确定有多少信息被允许通过该状态或沿着信息高速公路。神经元门304首先决定要从神经元状态st、即所谓的遗忘门层中删除多少信息。同上出处。接着,神经元门306和306’确定哪些信息将被添加到神经元状态,并且神经元门308和308’确定将从神经元状态输出什么信息作为预测
在利用rnn的一些实施例中,在各时间步骤处,主时间序列和次时间序列可以不作为向量被提供给rnn。作为替代,仅向rnn提供主时间序列和次时间序列的当前值、以及预测间隔内的次时间序列的未来值或聚合函数。以这种方式,rnn使用持久状态向量来保留与先前值有关的信息,以供在进行预测时使用。
机器学习非常适合持续监测一个或多个标准以识别与用于训练模型的训练示例相比的输入数据中的大小不一的异常或趋势。因此,这里描述的一些实施例将用户的健康指标数据和可选的其它因素数据输入到经训练的机器学习模型中,该经训练的机器模型预测健康人的健康指标数据在下一时间步骤处的样子,并将预测与未来时间步骤处的用户的测量健康指标数据进行比较。如果差的绝对值(例如,下文所述的损失)超过阈值,则向用户通知他或她的健康指标数据不在正常或健康的范围内。阈值是由设计者设置的数字,并且在一些实施例中可以由用户更改以允许用户调整通知灵敏度。可以通过来自健康人群的健康指标数据单独地或与(时间上)相应的其它因素数据相结合地对这些实施例的机器学习模型进行训练,或者可以通过其它训练示例对这些实施例的机器学习模型进行训练,以满足模型的设计需求。
来自健康指标的数据(例如,心率数据)是序列化数据,更特别地是时间序列化数据。心率例如但不限于可以以多种不同的方式测量,例如,测量来自胸带或从ppg信号导出的电信号。一些实施例获得从装置导出的心率,其中各数据点(例如,心率)以大致相等的间隔(例如,5秒)产生。但是,在一些情况下以及在其它实施例中,所导出的心率不是以大致相等的时间步骤提供的,这例如是因为导出所需的数据不可靠(例如,因为装置移动或由于光污染,ppg信号是不可靠的)。对于从用于收集其它因素数据的运动传感器或其它传感器获得次数据序列也如此。
原始信号/数据(来自ecg、胸带或ppg信号的电信号)本身是可根据一些实施例使用的数据的时间序列。为了清楚起见而非限制,本说明书使用ppg来指代表示健康指标的数据。本领域技术人员将容易理解,根据这里描述的一些实施例,可以使用健康指标数据、原始数据、波形或由原始数据或波形导出的数字的形式。
可以与这里描述的实施例一起使用的机器学习模型包括例如但不限于bayes、markov、gausian过程、聚类算法、生成模型、核和神经网络算法。一些实施例利用基于经训练的神经网络的机器学习模型,其它实施例利用递归神经网络,以及附加实施例使用ltsmrnn。为了清楚起见而非限制,将使用递归神经网络来描述本说明书的一些实施例。
图4a~4c示出ppg(图4a)、所进行的迈步(图4b)和气温(图4c)相对于时间的假设标绘图。ppg是健康指标数据的示例,其中迈步、活动水平和气温是可能影响健康指标数据的其它因素的示例性其它因素数据。本领域技术人员将会理解,其它数据可以从包括但不限于加速度计数据、gps数据、体重秤、用户输入等的许多已知来源中的任何一个获得,并且可以包括但不限于气温、活动(跑步、步行、坐着、骑车、跌倒、爬楼梯、迈步等)、bmi、体重、身高、年龄等。在所有三个标绘图上垂直延伸的第一条虚线表示获得用户数据以供输入到(以下讨论的)经训练的机器学习模型中的时间t。图4a中的散列标绘线表示预测的或可能的输出数据402,以及图4a中的实线404表示测量数据。图4b是各个时间的用户迈步数的假设标绘图,以及图4c是各个时间的气温的假设标绘图。
图5a~5b描绘了经训练的递归神经网络500接收图4a~4c中所描绘的输入数据(即,ppg(p)、迈步(r)和气温(t))的示意图。再次强调,这些输入数据(p、r和t)仅仅是健康指标数据和其它因素数据的示例。还应当理解,可以输入和预测多于一个健康指标的数据,并且可以使用多于或少于两个其它因素数据,其中选择是取决于模型被设计用于什么。本领域技术人员还将理解,收集其它因素数据以在时间上与健康指标数据的收集或测量相对应。在一些情况(例如,体重)下,其它因素数据在某个时间段内将保持相对恒定。
图5a将经训练的神经网络500描绘为循环。将p、t和r输入到rnn500的应用了权重w的状态502中,并且rnn500输出预测ppg504(p*)。在步骤506中,计算差p-p*(δp*),并且在步骤508处,判断|δp*|是否大于阈值。如果是,则步骤510向用户通知/警告他/她的健康指标在被预测为正常或针对健康人所预测的界限/阈值外。警告/通知/检测可以是例如但不限于提议看医生/咨询医生、诸如触觉反馈等的简单通知、请求采取诸如ecg等的附加测量、或者没有任何建议的简单注释、或其任意组合。如果|δp*|小于或等于阈值,则步骤512不进行任何操作。在这两个步骤510和512中,利用新的用户数据在下一时间步骤处重复该处理。在本实施例中,在预测数据被输出之后更新状态,并且可以在更新状态时使用预测数据。
在另一实施例(未示出)中,将(例如,从ppg信号导出的)心率数据的主序列以及其它因素数据的次序列提供给经训练的机器学习模型,该经训练的机器学习模型可以是rnn、cnn、其它机器学习模型或这些模型的组合。在本实施例中,机器学习模型被配置为接收参考时间t处的以下内容作为输入:
a.直到且包括时间t处的任何健康指标数据的最后300个健康指标样本(例如,以每分钟跳动次数为单位的心率)的长度为300的向量(vh);
b.包含vh中的各样本的近似时间处的最近其它因素数据(例如,步数)的长度为300的至少一个向量(vo);
c.长度为300的向量(vtd),其中索引为i的输入vdt(i)包含健康指标样本vh(i)的时间戳和vh(i-1)的时间戳之间的时间差;以及
d.表示在从t到t+τ的时间段测量到的平均其它因素速率(例如,迈步速率)的标量预测间隔其它因素速率orate(例如但不限于迈步速率),其中τ可以是例如但不限于2.5分钟,并且是未来预测间隔。
本实施例的输出可以是例如表征从t到t+τ的时间段测量到的预测心率的概率分布。在一些实施例中,利用包括健康指标数据的连续时间序列和其它因素数据序列的训练示例来对机器学习模型进行训练。在一个可选实施例中,通知系统为各预测健康指标(例如,心率)分布指派时间戳t+τ/2,从而将预测分布集中在预测间隔(τ)内。在本实施例中,通知逻辑然后考虑长度为wl=2*(τ)或在本示例中为5分钟的滑动窗口(w)内的所有样本,并计算三个参数:
1.时间窗口内的所有健康指标序列化数据的平均值
2.预测时间戳落在时间窗口内的健康指标的所有模型预测的平均值
3.时间窗口内的各预测健康指标分布的均方根的中间值
4.在一个实施例中,如果
在本实施例中,在特定窗口w内的测量健康指标多于离预测健康指标值的平均值的标准偏差的一定倍数的情况下,生成警告。窗口w可以以滑动的方式应用在测量健康指标值和预测健康指标值的序列中,其中各窗口在时间上与前一个窗口重叠设计者指定的分数(例如,0.5分钟)。
通知可以采取任何数量的不同形式。例如但不限于,可以通知用户获得ecg和/或血压,可以指导计算系统(例如,可穿戴式计算系统等)自动获得ecg或血压(例如),可以通知用户去看医生,或者简单地告知用户健康指标数据不正常。
在本实施例中,作为模型的输入的vdt的选择旨在允许模型利用vh中的健康指标数据之间的可变间距中所包含的信息,其中可变间距可能来自从不太一致的原始数据中导出健康指标数据的算法。例如,心率样本由applewatch算法仅在具有足够可靠的原始ppg数据来输出可靠心率值的情况下生成,这导致心率样本之间的时间间隙不规则。以类似的方式,本实施例利用具有与其它向量相同长度的其它因素数据(vo)的向量来处理主序列(健康指标)和次序列(其它因素)之间的不同且不规则的采样速率。在本实施例中,次序列被再映射或插值到与主时间序列相同的时间点上。
此外,在一些实施例中,可以修改未来预测时间间隔(例如,在t之后)的作为机器学习模型的输入所存在的次时间序列中的数据的配置。在一些实施例中,可以利用多个标量值(例如,每个次时间序列一个标量值)来修改包含预测间隔内的平均其它因素数据速率的单个标量值。或者,可以使用预测间隔内的值向量。另外,可以调整预测间隔本身。例如,较短的预测间隔可以提供对变化的更快响应以及对基本时间度量(较)短的事件的改进检测,但也可能对来自噪声源的干扰(例如,运动伪影)更敏感。
类似地,机器学习模型本身的输出预测无需是标量。例如,一些实施例可以针对t和t+τ之间的时间间隔内的多个时间t生成预测的时间序列,并且警告逻辑可以将这些预测中的各预测与同一时间间隔内的测量值进行比较。
在该前一实施例中,机器学习模型本身可以包括例如7层前馈神经网络。前3层可以是包含32个核的卷积层,各核的核宽度为24并且步长为2。第一层在三个通道中可以具有作为输入的阵列vh、vo和vtd。最后4层可以是全连接层,除了最后一层之外,所有全连接层利用双曲正切激活函数。第三层的输出可以平整化为一个阵列,以供输入到第一全连接层中。最后一层输出30个值,从而将高斯混合模型参数化为10个混合(针对各混合,具有平均值、方差和权重这三个参数)。网络在第一全连接层和第三全连接层之间使用跳跃连接,使得层6的输出与层4的输出求和,以产生层7的输入。标准批归一化可以在除最后一层之外的所有层上使用,衰减为0.97。使用跳跃连接和批归一化可以提高通过网络传播梯度的能力。
机器学习模型的选择可能影响系统的性能。机器学习模型配置可以分为两种类型的考虑。首先是模型的内部架构,即模型类型的选择(卷积神经网络、递归神经网络、随机森林等的广义非线性回归)、以及表征模型的实现的参数(一般为参数的数量、以及/或者层的数量、决策树的数量等)。其次是模型的外部架构——正被馈送到模型中的数据的布置以及模型被要求解决的问题的具体参数。外部架构的特征可以部分地在于作为模型的输入而提供的数据的维度和类型、该数据所跨越的时间范围、以及对数据进行的预处理或后处理。
一般而言,外部架构的选择是增加参数的数量和增加作为输入提供的信息量之间的平衡,这可以增加机器学习模型的预测能力(具有用以训练和评价较大模型的可用存储和计算能力)以及用以防止过度拟合的足够数据量的可用性。
在一些实施例中讨论的模型的外部架构的许多变化是可能的。可以修改输入向量的数量以及绝对长度(元素数)和所覆盖的时间跨度。各输入向量无需是相同的长度或覆盖相同的时间跨度。数据无需等时间地采样,例如但不限于,可以提供6小时的心率数据历史,其中,少于t之前的一小时的数据以1hz的速率进行采样,多于t之前的1小时但少于t之前的2小时的数据以0.5hz的速率进行采样,以及早于2小时的数据以0.1hz的速率进行采样,其中t是参考时间。
图5b示出展开的经训练的rnn500。将输入数据513(pt、rt和tt)输入到时间t处的状态(st)514,并且应用经训练的权重516。神经元(ct)518的输出是时间t+1处的预测
图5c示出用以判断用户的健康指标序列化数据(在我们的示例中为ppg)是否在健康人的带或阈值内的经训练的rnn的可选实施例。本实施例中的输入数据是线性组合
it和ot是状态st的输入,其中在一些实施例中,状态st输出时间步骤t+1处的预测健康指标数据
为了说明这一概念,图5d示出时间t+1处的假设健康指标数据范围的假设概率分布。例如以最大概率0.95对该函数进行采样,以确定时间t+1处的预测健康指标
可以定义损失以帮助判断是否要向用户通知他或她的健康状况不在经训练的机器学习模型所预测的正常范围内。选择损失以对预测数据与实际或测量数据有多接近进行建模。本领域技术人员将理解用以定义损失的许多方式。在这里描述的其它实施例中,例如,预测数据和实际数据之间的差的绝对值(|δp*|)是损失。在一些实施例中,损失(l)可以是l=-ln[β(p)],其中
<prange>由对某一时间范围内的测量健康指标数据求平均的方法确定;
可以使用的求平均的方法包括例如但不限于平均值、算术平均、中值和众数。在一些实施例中,删除离群点以便不使计算出的数字偏离。
返回参考图5c中所描绘的实施例的输入数据
实施例中的机器学习模型使用经训练的机器学习模型。在一些实施例中,机器学习模型使用递归神经网络,该递归神经网络需要经训练的rnn。作为示例而非限制,图6描绘了根据一些实施例的展开的rnn以展现训练rnn。神经元602具有初始状态s0604和权重矩阵w606。将时间步骤0处的迈步速率数据r0、气温数据t0和初始ppg数据p0输入到状态s0中,应用权重w,并从神经元602输出第一时间步骤处的预测ppg
图7a描绘了用于预测用户的测量健康指标是在针对类似其它因素下的健康人而言正常的阈值内还是外的系统700。系统700具有机器学习模型702和健康检测器704。例如(但不限于),机器学习模型702的实施例包括经训练的机器学习模型、经训练的rnn、cnn或其它前馈网络。可以通过来自从中收集到健康指标数据和(时间上)相应的其它因素数据的健康人群的训练示例对经训练的rnn、其它网络或网络的组合进行训练。可选地,可以通过来自特定用户的训练示例对经训练的rnn、其它网络或网络的组合进行训练,使其成为个性化的经训练的机器学习模型。本领域技术人员将理解,一般情况下可以根据经训练的网络和系统的使用或设计来选择来自不同人群的训练示例。本领域技术人员也将容易理解,本实施例和其它实施例中的健康指标数据可以是一个或多个健康指标。可以使用例如但不限于ppg数据、心率数据、血压数据、体温数据和血氧浓度数据等中的一个或多个来训练模型并预测用户的健康。健康检测器704使用来自机器学习模型702的预测708和输入数据710来判断损失或通过用测量数据分析预测输出而确定的其它度量是否超过被认为正常的阈值、并因此是不健康的。然后,系统700输出通知或用户的健康状况。该通知可以采用如这里所讨论的许多形式。输入生成器706利用传感器(未示出)从佩戴该传感器或与该传感器接触的用户持续获得数据,其中数据表示用户的一个或多个健康指标。(时间上)相应的其它因素数据可以由另一传感器收集,或者通过这里所描述的或对本领域技术人员显而易见的其它手段获取。
输入生成器706也可以收集数据以确定/计算其它因素数据。例如但不限于,输入生成器可以包括智能手表、可穿戴或移动装置(例如,apple
参考图7b,描绘了根据实施例的智能手表712。智能手表712包括手表714,其包含本领域技术人员已知的所有电路、微处理器和处理装置(未示出)。手表714还包括显示器716,其中在该显示器716上,可以显示用户的健康指标数据718(在本示例中为心率数据)。显示器716上还可以显示针对正常或健康人群的预测的健康指标带720。在图7b中,用户的测量心率数据不超过预测健康带,因此在该特定示例中,将不进行通知。手表714还可以包括手表带722和高保真度传感器724(例如ecg传感器)。可选地,手表带722可以是用以测量血压的可扩展袖带。在手表714的背面设置低保真度传感器726(以阴影示出)以收集诸如ppg数据等的用户健康指标数据,该数据可用于导出例如心率数据或诸如血压等的其它数据。可选地,如本领域技术人员将理解的,在一些实施例中,可以使用健身手环(诸如fitbit或polar等),其中健身手环具有类似的处理能力和其它因素测量装置(例如,ppg和加速度计)。
图8描绘了用于持续监测用户的健康状况的方法800的实施例。步骤802接收用户输入数据,该用户输入数据可以包括一个或多个健康指标的数据(又称为主数据序列)和其它因素的(时间上)相应数据(又称为次数据序列)。步骤804将用户数据输入到经训练的机器学习模型中,该模型可以包括经训练的rnn、cnn、如这里描述的其它前馈网络或本领域技术人员已知的其它神经网络。在一些实施例中,健康指标输入数据可以是预测健康指标数据和测量健康指标数据中的一个或组合,例如线性组合,如这里的一些实施例中所述。步骤806输出某一时间步骤处的一个或多个预测健康指标的数据,其中输出可以包括例如但不限于单个预测值、作为预测值的函数的概率分布。步骤808基于预测健康指标来确定损失,其中例如但不限于,损失可以是预测健康指标和测量健康指标之间的简单差、或一些其它适当选择的损失函数(例如,测量健康指标的值的评价的概率分布的负对数)。步骤810判断损失是否超过被认为是正常或不健康的阈值,其中阈值可以是例如但不限于设计者所选择的简单数字、或与预测相关的一些参数的更复杂函数。如果损失大于阈值,则步骤812向用户通知他或她的健康指标超过被认为是正常或健康的阈值。如这里所述,通知可以采取许多形式。在一些实施例中,该信息可以对用户可视。例如但不限于,信息可以显示在用户界面上,诸如示出以下内容的图(i)作为时间的函数的测量健康指标数据(例如,心率)和其它因素数据(例如,步数)、(ii)机器学习模型所生成的预测健康指标数据(例如,预测心率值)的分布。以这种方式,用户可以在视觉上将测量数据点与预测数据点进行比较,并通过视觉观察来判断例如其心率是否落在机器学习模型所期望的范围内。
这里描述的一些实施例已经提到使用阈值来判断是否要通知用户。在这些实施例中的一个或多个实施例中,用户可以改变阈值以调整或微调系统或方法以更紧密地匹配用户的个人健康知识。例如,如果所使用的生理指标是血压、并且用户具有较高的血压,则实施例可能根据通过健康人群进行训练的模型频繁地向用户警告/通知其健康指标在正常或健康的范围外。因此,某些实施例允许用户增大阈值,使得不会如此频繁地向用户通知他/她的健康指标数据超过被认为是正常或健康的范围。
一些实施例优选使用健康指标的原始数据。如果对原始数据进行处理以导出特定测量(例如,心率),则可以根据实施例使用该导出的数据。在一些情况下,健康监测设备的提供者无法控制原始数据,相反,所接收到的数据是以所计算的健康指标(例如,心率或血压)的形式进行处理的数据。如本领域技术人员将会理解,用于训练机器学习模型的数据的形式应当与从用户收集并输入到经训练的模型中的数据的形式相匹配,否则预测可能会被证明是错误的。例如,applewatch提供不等的时间步骤处的心率测量数据,而不提供原始ppg数据。在本示例中,用户佩戴applewatch,该applewatch根据apple的ppg处理算法利用不等的时间步骤处的心率数据来输出心率数据。通过该数据对模型进行训练。apple决定改变其提供心率数据的算法,这可能使通过来自先前算法的数据进行训练的模型对于使用来自新算法的数据输入是过时的。为了解决这一潜在问题,一些实施例在收集数据以训练模型的情况下将不规则间隔的数据(心率、血压数据或ecg数据等)重新采样到规则间隔的栅格上并且根据规则间隔的栅格进行采样。如果apple或其它数据供应商改变了其算法,则只需要通过新收集的训练示例来对模型进行重新训练,而无需对模型进行重构以考虑算法变化。
在进一步的实施例中,经训练的机器学习模型可以通过用户数据进行训练,从而得到个性化的经训练的机器学习模型。这种经训练的个性化机器学习模型可以代替这里描述的通过健康人群进行训练的机器学习模型使用或者与其组合使用。如果使用个性化的经训练的机器学习模型本身,则将用户的数据输入到该机器学习模型中,该机器学习模型将输出对于该用户而言正常的下一时间步骤中的个体健康指标的预测,然后该预测以与这里描述的实施例一致的方式与来自下一时间步骤的实际/测量数据进行比较以判断用户的健康指标是否与针对该用户而言被预测为正常的健康指标相差某一阈值。另外,这种个性化的机器学习模型可以与通过来自健康人群的训练示例进行训练的机器学习模型组合使用,以生成与针对该个体用户而言被预测为正常的健康指标和针对健康人群而言被预测为正常的健康指标这两者有关的预测和相关通知。
图9a描绘了根据另一实施例的方法900,以及图9b示出为了解释目的的(例如但不限于)作为时间的函数的心率的假设标绘图902。步骤904(图9a)接收用户心率数据(或其它健康指标数据)以及可选的(时间上)相应的其它因素数据,并将该数据输入到个性化的经训练的机器学习模型中。在一些实施例中,如这里所述,通过用户的个体健康指标数据以及可选的(时间上)相应的其它数据对个性化的经训练的模型进行训练。因此,在步骤906中,个性化的经训练的机器学习模型预测在其它因素的条件下的该个体用户的正常心率数据,并且步骤908将用户的健康指标数据与针对该特定用户被预测为正常的健康指标数据相比来识别该用户的健康指标数据的反常或异常。如本说明书中所讨论的,一些实施例从用户身上的可穿戴式装置(例如,applewatch、智能手表、
可以定义损失以帮助判断是否要在步骤908中向用户通知该用户的测量数据对于针对该特定用户被预测为正常的数据而言是异常的。选择损失以对预测与实际或测量数据有多接近进行建模。本领域技术人员将理解用以定义损失的许多方式。在这里描述且同样适用的其它实施例中,例如,预测值和测量值之间的差的绝对值|δp*|是损失的形式。在一些实施例中,损失(l)可以是l=-ln[β(p)],其中
步骤908判断是否存在异常。如所讨论的,可以判断损失是否超过阈值。如前所述,阈值是由设计者的选择并基于正在设计的系统的目的来设置的。在一些实施例中,阈值可以由用户修改,但优选地,在本实施例中不进行修改。如果不存在异常,则在步骤904处重复该处理。如果存在异常,则步骤910通知或警告用户获得高保真度测量,例如但不限于ecg或血压测量。在步骤912中,高保真度数据由算法、健康专业人士或这两者进行分析,并被描述为正常或不正常,并且如果不正常,则可以根据所获得的高保真度测量来指派一些诊断,例如afib、心动过速、心动过缓、心房颤动或高/低血压。为清楚起见,应当注意,用以记录高保真度数据的通知在其它实施例以及上述使用一般模型的特定实施例中是同样适用且可能的。在一些实施例中,高保真度测量可以由用户使用移动监测系统(诸如ecg或血压系统等)直接获得,在一些实施例中,该移动监测系统可以与可穿戴式装置相关联。可选地,通知步骤910使得自动获取高保真度测量。例如,可穿戴式装置可以(通过硬连线或经由无线通信)与传感器进行通信并获得ecg数据,或者它可以与血压袖带系统(例如,可穿戴式装置的腕带或臂环袖带)进行通信以自动获得血压测量,或者它可以与诸如起搏器或ecg电极等的植入式装置进行通信。例如,alivecor,inc.提供了用于远程获得ecg的系统,这种系统包括(但不限于)与在两个或更多个位置中的用户接触的一个或多个传感器,其中传感器收集有线或无线地发送至移动计算装置的心电数据,其中app根据数据生成ecg带,该ecg带可以由算法、医学专业人员或这两者进行分析。可选地,传感器可以是血压监视器,其中血压数据被有线或无线地发送至移动计算装置。可穿戴式装置本身可以是血压系统,其具有能够测量健康指标数据的袖带并且可选地具有与上述的ecg传感器类似的ecg传感器。ecg传感器还可以包括诸如共同拥有的us临时申请号61/872,555中所述的ecg传感器,其内容通过引用而并入于此。移动计算装置可以是例如但不限于平板计算机(例如,ipad)、智能手机(例如,
在步骤914中,由计算系统接收高保真度测量的诊断或分类,其中在一些实施例中,该计算系统可以是用于收集用户的心率数据(或其它健康指标数据)的移动或可穿戴式计算系统,并且在步骤916中,通过诊断来标记低保真度健康指标数据序列(在本示例中为心率数据)。在步骤918中,使用标记的用户低保真度数据序列来训练高保真度机器学习模型,并且可选地还提供其它因素数据序列来训练模型。在一些实施例中,经训练的高保真度机器学习模型能够接收测量低保真度健康指标数据序列(例如,心率数据或ppg数据)和可选的其它因素数据,并给出用户正在经历通常使用高保真度数据诊断或检测到的事件的概率,或预测或诊断或检测用户何时经历通常使用高保真度数据诊断或检测到的事件。经训练的高保真度机器学习模型能够做到这一点,这是因为已经通过利用对高保真度数据的诊断进行标记的用户健康指标数据(和可选的其它因素数据)对经训练的高保真度机器学习模型进行了训练。因此,经训练的模型能够仅基于测量低保真度健康指标输入数据序列(例如,心率或ppg数据)(和可选的其它因素数据)来预测用户何时发生与一个或多个标记相关联的事件(例如,afib、高血压等)。本领域技术人员将理解,高保真度模型的训练可以在用户的移动装置上、远离用户的移动装置、这两者兼有地、或在分布式网络中进行。例如但不限于,用户的健康指标数据可以存储在云系统中,并且该数据可以使用来自步骤914的诊断在云中进行标记。本领域技术人员将容易理解用以存储、标记和访问该信息的任何数量的方法和方式。可选地,可以使用全局训练的高保真度模型,该模型将通过来自正在经历通常利用高保真度测量诊断或检测到的这些状况的人群的标记训练示例进行训练。这些全局训练示例将提供利用使用高保真度测量诊断出的状况(例如,医学专业人员或算法根据ecg称为的afib)标记的低保真度数据序列(例如,心率)。
现在参考图9b,标绘图902示出作为时间的函数进行标绘的心率的示意图。相对于用户的正常心率数据的反常920发生在时间t1、t2、t3、t4、t5、t6、t7、8处。如上文所述,正常意味着该特定用户的预测数据在测量数据的阈值内,其中反常在阈值外。在相对于正常的反常时,一些实施例提示用户获得更明确或高保真度的读数,例如但不限于被标识为ecg1、ecg2、ecg3、ecg4、ecg5、ecg6、ecg7、ecg8的ecg读数。如上文所述,可以自动获得高保真度读数,用户可以获得高保真度读数,或者高保真度读数可以是除了ecg以外的事物,例如血压。通过算法、健康专业人员或这两者来分析高保真度读数,以将高保真度数据识别为正常/异常,并进一步识别/诊断异常(例如但不限于afib)。该信息用于标记用户的序列化数据中的异常点920处的健康指标数据(例如,心率或ppg数据)。
高保真度和低保真度数据之间的区别是高保真度数据或测量通常用于进行判断、检测或诊断,而低保真度数据可能不易用于这种判断、检测或诊断。例如,ecg扫描可用于识别、检测或诊断心律失常,而心率或ppg数据通常不提供这种能力。如本领域技术人员将理解的,这里关于机器学习算法(例如,bayes、markov、gausian过程、聚类算法、生成模型、核和神经网络算法)的描述同样适用于这里描述的所有实施例。
在一些情况下,尽管可能存在这些问题,但用户仍然无症状,并且即使存在症状,获得进行诊断或检测所必需的高保真度测量也可能是不切实际的。例如但不限于,可能不存在心律失常、尤其是af,并且即使症状确实存在,记录该时刻的ecg也是非常困难的,并且在没有昂贵、体积庞大且有时有创的监测装置的情况下,持续监测用户是非常困难的。如本文其它各处所讨论的,了解用户何时经历af是很重要的,这是因为除了其它严重状况之外,af至少可能是中风的起因。类似地并且如其它各处所讨论地,af负荷可能有类似的输入。一些实施例允许仅使用对低保真度健康指标数据(诸如心率或ppg)以及可选的其它因素数据的持续监测来持续监测心律失常(例如,af)或其它严重状况。
图10描绘了根据健康监测系统和方法的一些实施例的方法1000。步骤1002接收测量或实际的用户低保真度健康指标数据(例如,来自可穿戴式装置上的传感器的心率或ppg数据),并且可选地接收(时间上)相应的其它因素数据,该其它因素数据可能影响这里描述的健康指标数据。如本文其它各处所讨论的,低保真度健康指标数据可以由诸如智能手表、其它可穿戴式装置或平板计算机等的移动计算装置测量。在步骤1004中,将用户的低保真度健康指标数据(以及可选的其它因素数据)输入到经训练的高保真度机器学习模型中,该经训练的高保真度机器学习模型在步骤1006中基于测量低保真度健康指标数据(以及可选的(时间上)相应的其它因素数据)来输出针对用户的预测识别或诊断。步骤1008询问识别或诊断是否是正常的,如果是,则重新开始处理。如果识别或诊断是不正常的,则步骤1010向用户通知问题或检测。可选地,可以设置系统、方法或平台以通知用户、家人、朋友、医学护理专业人员或急救911等的任何组合。通知这些人中的哪个人可以取决于识别、检测或诊断。在识别、检测或诊断危及生命的情况下,则可以联系或通知某些人,这些人在诊断不危及生命的情况下可以不进行通知。另外,在一些实施例中,将测量健康指标数据序列输入到经训练的高保真度机器学习模型中,并计算用户正在经历异常事件的时间量(例如,预测异常事件的开始和停止之间的差),从而允许更好地理解用户的异常负荷。特别地,在预防中风和其它严重状况方面,理解af负荷可以是非常重要的。因此,一些实施例允许利用移动计算装置、可穿戴式计算装置、或能够仅获取低保真度健康因素数据的其它便携式装置以及可选的其它因素数据来持续监测异常事件。
图11描绘了根据这里描述的一些实施例的基于低保真度数据进行分析以生成高保真度输出预测或检测的示例数据1100。虽然参考心房颤动的检测进行描述,但是针对基于低保真度测量的高保真度诊断的附加预测可以生成类似的数据。第一个图1110示出用户随时间的心率计算。心率可以基于ppg数据或其它心率传感器来确定。第二个图1120示出同一时间段期间的用户的活动数据。例如,活动数据可以基于步数或用户移动的其它测量来确定。第三个图1130示出从机器学习模型输出的分类器以及何时生成通知的水平阈值。机器学习模型可以基于低保真度测量的输入来生成预测。例如,第一个图1110和第二个图1120中的数据可以由如以上进一步描述的机器学习系统进行分析。可以提供机器学习系统分析的结果作为图1130中所示的心房颤动概率。当概率超过阈值(在这种情况下示出为高于0.6置信度)时,健康监测系统可以触发针对用户、医师或与用户相关联的其他用户的通知或其它警告。
在一些实施例中,图1110和1120中的数据可以作为持续测量提供给机器学习系统。例如,可以每5秒生成心率和活动水平作为测量,以进行准确的测量。然后可以将具有多个测量的时间片段输入到机器学习模型中。例如,前一小时的数据可以用作机器学习模型的输入。在一些实施例中,可以提供较短或较长的时间段,而不是一小时。如图11所示,输出图1130提供了用户正在经历异常健康事件的时间段的指示。例如,健康监测系统可以使用预测高于某个置信度水平的时间段来确定心房颤动。然后,可以使用这个值来确定测量时间段期间的用户的心房颤动负荷。
在一些实施例中,可以基于标记的用户数据来训练用以生成图1130中的预测输出的机器学习模型。例如,可以基于在低保真度数据(例如,ppg、心率等)和其它数据(例如,活动水平或迈步等)也可用的时间段内获取的高保真度数据(诸如ecg读数等)来提供标记的用户数据。在一些实施例中,机器学习模型被设计用于判断在前一时间段期间是否可能存在心房颤动。例如,机器学习模型可以获取一小时的低保真度数据作为输入,并提供发生事件的可能性。因此,训练数据可能包括个体群体的多个小时的记录数据。在基于高保真度数据诊断出状况的情况下,该数据可以是健康事件标记时间。因此,如果存在基于高保真度数据的健康事件标记时间,则机器学习模型可以判断为输入到未经训练的机器学习模型中的具有该事件的任何一个小时窗口的低保真度数据应当提供健康事件的预测。然后,可以基于将预测与标记进行比较来更新未经训练的机器学习模型。在重复多次迭代并判断为机器学习模型已经收敛之后,健康监测系统可以使用该机器学习模型,以基于低保真度数据来监测用户的心房颤动。在各种实施例中,可以使用低保真度数据来检测除心房颤动之外的其它状况。
图12示出计算机系统1200的示例形式中的机器的示意性表示,其中在计算机系统1200内,可以执行用于使机器进行这里所讨论的任何一个或多个方法的指令集。在可选实施例中,机器可以连接(例如,联网)到局域网(lan)、内联网、外联网或因特网中的其它机器。机器可以在客户端-服务器网络环境中以服务器或客户端机器的能力进行操作,或者作为对等(或分布式)网络环境中的对等机器进行操作。机器可以是个人计算机(pc)、平板pc、机顶盒(stb)、个人数字助理(pda)、蜂窝电话、web设备、服务器、网络路由器、交换机或桥接器、集线器、接入点、网络接入控制装置、或者能够执行用于指定该机器所要采取的动作的(顺序的或其它形式的)指令集的任何机器。此外,虽然仅示出单个机器,但术语“机器”也应被视为包括单独地或共同地执行一个(或多个)指令集以进行这里所讨论的任何一个或多个方法的机器的任何集合。在一个实施例中,计算机系统1200可以代表被配置为进行这里描述的健康监测的服务器、移动计算装置或可穿戴式装置等。
示例性计算机系统1200包括经由总线1230彼此通信的处理装置1202、主存储器1204(例如,只读存储器(rom)、闪速存储器、动态随机存取存储器(dram))、静态存储器1206(例如,闪速存储器、静态随机存取存储器(sram)等)、以及数据存储装置1218。通过这里描述的各种总线提供的任何信号可以与其它信号进行时间复用,并通过一个或多个公共总线提供。另外,电路组件或块之间的互连可被示出为总线或单信号线。各总线可以可选地是一个或多个单信号线,并且各单信号线可以可选地是总线。
处理装置1202表示一个或多个通用处理装置,诸如微处理器、中央处理单元或其他处理装置等。更具体地,处理装置可以是复杂指令集计算(cisc)微处理器、精简指令集计算机(risc)微处理器、超长指令字(vliw)微处理器、或实现其它指令集的处理器、或实现指令集组合的处理器。处理装置1202也可以是一个或多个专用处理装置,诸如专用集成电路(asic)、现场可编程门阵列(fpga)、数字信号处理器(dsp)或网络处理器等。处理装置1202被配置为执行处理逻辑1226,该处理逻辑1226可以是用于进行这里讨论的操作和步骤的健康监视器1250和相关系统的一个示例。
数据存储装置1218可以包括机器可读存储介质1228,在该机器可读存储介质1228上存储了体现这里描述的功能的任何一个或多个方法的一个或多个指令集1222(例如,软件),包括用以使处理装置1202执行这里描述的健康监视器1250和相关处理的指令。在计算机系统1200执行指令1222期间,指令1222也可以完全或至少部分地存在于主存储器1204内或处理装置1202内;主存储器1204和处理装置1202也构成机器可读存储介质。指令1222还可以经由网络接口装置1208通过网络1220发送或接收。
如这里所述,机器可读存储介质1228也可以用于存储用以进行用于监测用户健康的方法的指令。虽然在示例性实施例中、机器可读存储介质1228被示出为单个介质,但术语“机器可读存储介质”应被视为包括存储一个或多个指令集的单个介质或多个介质(例如,集中式或分布式数据库或相关的高速缓存和服务器)。机器可读介质包括用于以机器(例如,计算机)可读的形式(例如,软件、处理应用)存储信息的任何机构。机器可读介质可以包括但不限于磁性存储介质(例如,软盘)、光存储介质(例如,cd-rom)、磁光存储介质、只读存储器(rom)、随机存取存储器(ram)、可擦除可编程存储器(例如,eprom和eeprom)、闪速存储器、或适合存储电子指令的其它类型的介质。
以上说明阐述了许多具体细节,诸如具体系统、组件和方法等的示例,以提供对本发明的多个实施例的良好理解。然而,对于本领域技术人员显而易见的是,本发明的至少一些实施例可以在没有这些具体细节的情况下实现。在其它情况下,众所周知的组件或方法未详细描述或以简单的框图格式呈现,以避免不必要地使本发明模糊。因此,所阐述的具体细节仅仅是示例性的。具体实施例可以与这些示例性细节不同,并且仍可被预期在本发明的范围内。
另外,一些实施例可以在分布式计算环境中实现,其中机器可读介质存储在多于一个计算机系统上或由多于一个计算机系统执行。另外,可以在连接计算机系统的通信介质中拉取或推送计算机系统之间所传送的信息。
所要求保护的主题的实施例包括但不限于这里描述的各种操作。这些操作可以由硬件组件、软件、固件或它们的组合进行。
尽管这里的方法的操作以特定的顺序示出和描述,但是可以改变各方法的操作的顺序,使得某些操作可以以相反的顺序进行,或者使得某些操作可以至少部分地与其它操作同时进行。在另一实施例中,不同操作的指令或子操作可以采用间歇性或交替的方式。
以上对本发明的例示实现的描述(包括摘要中所描述的内容)并非旨在是详尽的或将本发明限于所公开的确切形式。如本领域技术人员将认识到,虽然这里为了例示性目的而描述了本发明的具体实现和示例,但是各种等效修改也可以在本发明的范围内。这里使用的“示例”或“示例性”一词意味着用作示例、实例或例证。这里描述为“示例”或“示例性”的任何方面或设计不一定被理解为比其它方面或设计优选或有利。相反,使用“示例”或“示例性”一词旨在以具体方式呈现概念。如本申请中所使用,术语“或”旨在意味着包容性的“或”而不是排他性的“或”。也就是说,除非另有规定或从上下文中清楚可见,否则“x包括a或b”旨在意味着任何自然的包容性排列。也就是说,如果x包括a、x包括b、或者x包括a和b这两者,则在上述任何情况下,满足“x包括a或b”。另外,本申请和所附权利要求书中所使用的冠词“一个(a)”和“一个(an)”一般应被理解为意味着“一个或多个”,除非另有规定或从上下文中清楚可见针对单一形式。此外,在整个说明书中使用术语“实施例”或“一个实施例”或“实现”或“一个实现”并不旨在意味着相同的实施例或实现,除非被描述为这样。此外,这里使用的术语“第一”、“第二”、“第三”、“第四”等是指用以区分不同元件的标记,并且可能不一定具有根据其数字指定的序数意义。
应当理解,以上公开的和其它的特征和功能的变形或其替代方案可以组合到其它不同系统或应用中。本领域技术人员随后可以进行目前未预见到的或未预期到的各种替代、修改、变形或改进,这些替代、修改、变形或改进也旨在被以下权利要求书所涵盖。权利要求书可以涵盖硬件、软件或其组合中的实施例。
除上述的实施例外,本发明还包括但不限于以下示例实现。
一些示例实现提供了监测用户的心脏健康的方法。该方法可以包括:接收第一时间处的用户的测量健康指标数据和其它因素数据;通过处理装置将健康指标数据和其它因素数据输入到机器学习模型中,其中,机器学习模型生成下一时间步骤处的预测健康指标数据;接收下一时间步骤处的用户的数据;通过处理装置来确定下一时间步骤处的损失,其中,损失是下一时间步骤处的预测健康指标数据和下一时间步骤处的用户的测量健康指标数据之间的测度;判断为损失超过阈值;以及响应于判断为损失超过阈值而向用户输出通知。
在任何示例实现的方法的一些示例实现中,经训练的机器学习模型是经训练的生成神经网络。在任何示例实现的方法的一些示例实现中,经训练的机器学习模型是前馈网络。在任何示例实现的方法的一些示例实现中,经训练的机器学习模型是rnn。在任何示例实现的方法的一些示例实现中,经训练的机器学习模型是cnn。
在任何示例实现的方法的一些示例实现中,通过来自以下内容中的一个或多个内容的训练示例对经训练的机器学习模型进行训练:健康人群、患有心脏病的人群、以及用户。
在任何示例实现的方法的一些示例实现中,下一时间步骤处的损失是下一时间步骤处的预测健康指标数据和下一时间步骤处的用户的测量健康指标之间的差的绝对值。
在任何示例实现的方法的一些示例实现中,预测健康指标数据是概率分布,并且其中,下一时间步骤处的预测健康指标数据是根据概率分布进行采样的。
在任何示例实现的方法的一些示例实现中,根据选自包含以下内容的组中的采样技术对下一时间步骤处的预测健康指标数据进行采样:最大概率的预测健康指标数据;以及根据概率分布对预测健康指标数据进行随机采样。
在任何示例实现的方法的一些示例实现中,预测健康指标数据是概率分布(β),并且其中,损失是基于利用下一时间步骤处的用户的测量健康指标进行评价的下一时间步骤处的概率分布的负对数来确定的。在任何示例实现的方法的一些示例实现中,方法还包括概率分布的自采样。
在任何示例实现的方法的一些示例实现中,方法还包括:对时间步骤的时间段内的预测健康指标数据求平均;对时间步骤的时间段内的用户的测量健康指标数据求平均;以及基于预测健康指标数据和测量健康指标数据之间的差的绝对值来确定损失。
在任何示例实现的方法的一些示例实现中,测量健康指标数据包括ppg数据。在任何示例实现的方法的一些示例实现中,测量健康指标数据包括心率数据。
在任何示例实现的方法的一些示例实现中,方法还包括将不规则间隔的心率数据重新采样到规则间隔的栅格上,其中,根据规则间隔的栅格对心率数据进行采样。
在任何示例实现的方法的一些示例实现中,测量健康指标数据是选自包含以下内容的组中的一个或多个健康指标数据:ppg数据、心率数据、脉搏血氧计数据、ecg数据和血压数据。
一些示例限制提供了一种设备,该设备包括移动计算装置,该移动计算装置包括:处理装置;显示器;健康指标数据传感器;以及存储器,其上存储了在由处理装置执行时使处理装置进行以下操作的指令:接收第一时间处的来自健康指标数据传感器的测量健康指标数据以及第一时间处的其它因素数据;将健康指标数据和其它因素数据输入到经训练的机器学习模型中,并且其中,经训练的机器学习模型生成下一时间步骤处的预测健康指标数据;接收下一时间步骤处的测量健康指标数据和其它因素数据;确定下一时间步骤处的损失,其中,损失是下一时间步骤处的预测健康指标数据和下一时间步骤处的测量健康指标数据之间的测度;以及在下一时间步骤处的损失超过阈值的情况下输出通知。
在任何示例设备的一些示例实现中,经训练的机器学习模型包括经训练的生成神经网络。在任何示例设备的一些示例实现中,经训练的机器学习模型包括前馈网络。在任何示例设备的一些示例实现中,经训练的机器学习模型是rnn。在任何示例实现的方法的一些示例实现中,经训练的机器学习模型是cnn。
在任何示例设备的一些示例实现中,通过来自包含以下内容的组中的一个内容的训练示例对经训练的机器学习模型进行训练:健康人群、患有心脏病的人群、以及用户。
在任何示例设备的一些示例实现中,预测健康指标数据是下一时间步骤处的用户健康指标的点预测,并且其中,损失是下一时间步骤处的预测健康指标数据和下一时间步骤处的测量健康指标数据之间的差的绝对值。
在任何示例设备的一些示例实现中,预测健康指标数据是根据由机器学习模型生成的概率分布进行采样的。
在任何示例设备的一些示例实现中,根据选自包含以下内容的组中的采样技术对预测健康指标数据进行采样:最大概率;以及根据概率分布进行随机采样。
在任何示例设备的一些示例实现中,预测健康指标数据是概率分布(β),并且其中,损失是基于利用下一时间步骤处的用户的测量健康指标进行评价的β的负对数来确定的。
在任何示例设备的一些示例实现中,处理装置还用于定义范围为0至1的函数α,其中it包括作为α的函数的用户的测量健康指标数据和预测健康指标数的线性组合。
在任何示例设备的一些示例实现中,处理装置还用于进行概率分布的自采样。
在任何示例设备的一些示例实现中,处理装置还用于:使用求平均方法对时间步骤的时间段内的根据概率分布采样的预测健康指标数据求平均;使用求平均方法对时间步骤的时间段内的用户的测量健康指标数据求平均;定义损失为平均的预测健康指标数据和测量健康指标数据的差的绝对值。
在任何示例设备的一些示例实现中,求平均方法包括选自包含以下内容的组中的一个或多个方法:计算平均值、计算算术平均、计算中值和计算众数。
在任何示例设备的一些示例实现中,测量健康指标数据包括来自ppg信号的ppg数据。在任何示例设备的一些示例实现中,测量健康指标数据是心率数据。在任何示例设备的一些示例实现中,通过将不规则间隔的心率数据重新采样到规则间隔的栅格上并且根据规则间隔的栅格来对心率数据进行采样来收集心率数据。在任何示例设备的一些示例实现中,测量健康指标数据是选自包含以下内容的组中的一个或多个健康指标数据:ppg数据、心率数据、脉搏血氧计数据、ecg数据和血压数据。
在任何示例设备的一些示例实现中,移动装置选自包含以下内容的组:智能手表;健身手环;平板计算机;和膝上型计算机。
在任何示例设备的一些示例实现中,移动装置还包括用户高保真度传感器,其中通知请求用户获得高保真度测量数据,并且其中,处理装置还用于:接收对高保真度测量数据的分析;利用分析来标记用户的测量健康指标数据,以生成标记的用户健康指标数据;以及使用标记的用户健康指标数据作为训练示例,以对经训练的个性化高保真度机器学习模型进行训练。
在任何示例设备的一些示例实现中,经训练的机器学习模型存储在存储器中。在任何示例设备的一些示例实现中,经训练的机器学习模型存储在远程存储器中,其中,远程存储器与计算装置分离,并且其中,移动计算装置是可穿戴式计算装置。在任何示例设备的一些示例实现中,经训练的个性化高保真度机器学习模型存储在存储器中。在任何示例设备的一些示例实现中,经训练的个性化高保真度机器学习模型存储在远程存储器中,其中,远程存储器与计算装置分离,并且其中,移动计算装置是可穿戴式计算装置。
在任何示例设备的一些示例实现中,处理装置还用于预测用户正在经历心房颤动并确定用户的心房颤动负荷。
一些示例实现提供了监测用户的心脏健康的方法。该方法可以包括:接收第一时间处的测量低保真度用户健康指标数据和其它因素数据;将包括第一时间处的用户健康指标数据和其它因素数据的数据输入到个性化的经训练的高保真度机器学习模型中,其中,个性化的经训练的高保真度机器学习模型预测用户的健康指标数据是否异常;以及在预测异常的情况下发送用户的健康异常的通知。
在任何示例实现的方法的一些示例实现中,通过利用对高保真度测量数据的分析进行标记的测量低保真度用户健康指标数据来对经训练的个性化高保真度机器学习模型进行训练。
在任何示例实现的方法的一些示例实现中,对高保真度测量数据的分析是基于用户特定的高保真度测量数据的。
在任何示例实现的方法的一些示例实现中,个性化高保真度机器学习模型输出概率分布,其中,根据概率分布对预测进行采样。
在任何示例实现的方法的一些示例实现中,根据选自包含以下内容的组中的采样技术对预测进行采样:最大概率的预测;以及根据概率分布对预测进行采样。
在任何示例实现的方法的一些示例实现中,通过使用求平均方法对时间步骤的时间段内的预测求平均来确定平均预测,并且其中,使用平均预测来判断用户的健康指标数据是正常的还是异常的。
在任何示例实现的方法的一些示例实现中,求平均方法包括选自包含以下内容的组中的一个或多个方法:计算平均值、计算算术平均、计算中值和计算众数。
在任何示例实现的方法的一些示例实现中,个性化的高保真度训练机器学习模型存储在用户可穿戴式装置的存储器中。在任何示例实现的方法的一些示例实现中,测量健康指标数据和其它因素数据是某一时间段内的数据的时间片段。
在任何示例实现的方法的一些示例实现中,个性化的高保真度训练机器学习模型存储在远程存储器中,其中,远程存储器位于远离用户可穿戴式计算装置的位置处。
在一些示例实现中,健康监测设备可以包括移动计算装置,该移动计算装置包括:微处理器;显示器;用户健康指标数据传感器;以及存储器,其上存储了在由微处理器执行时使处理装置进行以下操作的指令:接收第一时间处的测量低保真度健康指标数据和其它因素数据,其中,测量健康指标数据是由用户健康指标数据传感器获得的;将包括第一时间处的健康指标数据和其它因素数据的数据输入到经训练的高保真度机器学习模型中,其中,经训练的高保真度机器学习模型预测用户的健康指标数据是正常的还是异常的;以及响应于预测是异常的,向至少所述用户发送该用户的健康异常的通知。
在任何示例实现的健康监测设备的一些示例实现中,经训练的高保真度机器学习模型是经训练的高保真度生成神经网络。在任何示例实现的健康监测设备的一些示例实现中,其中,经训练的高保真度机器学习模型是经训练的递归神经网络(rnn)。在任何示例实现的健康监测设备的一些示例实现中,经训练的高保真度机器学习模型是经训练的前馈神经网络。在任何示例实现的健康监测设备的一些示例实现中,经训练的高保真度机器学习模型是cnn。
在任何示例实现的健康监测设备的一些示例实现中,通过基于用户特定的高保真度测量数据进行标记的测量用户健康指标数据来对经训练的高保真度机器学习模型进行训练。
在任何示例实现的健康监测设备的一些示例实现中,通过基于高保真度测量数据进行标记的低保真度健康指标数据来对经训练的高保真度机器学习模型进行训练,其中,低保真度健康指标数据和高保真度测量数据来自受试者的群体。
在任何示例实现的健康监测设备的一些示例实现中,高保真度机器学习模型输出概率分布,其中,根据该概率分布对预测进行采样。
在任何示例实现的健康监测设备的一些示例实现中,根据选自包含以下内容的组中的采样技术对预测进行采样:最大概率的预测;以及根据概率分布对预测进行随机采样。
在任何示例实现的健康监测设备的一些示例实现中,通过使用求平均方法对时间步骤的时间段内的预测求平均来确定平均预测,并且其中,使用平均预测来判断用户的健康指标数据是正常的还是异常的。
在任何示例实现的健康监测设备的一些示例实现中,测量健康指标数据和其它因素数据是某一时间段内的数据的时间片段。
在任何示例实现的健康监测设备的一些示例实现中,求平均方法包括选自包含以下内容的组中的一个或多个方法:计算平均值、计算算术平均、计算中值和计算众数。
在任何示例实现的健康监测设备的一些示例实现中,个性化的高保真度训练机器学习模型存储在存储器中。在任何示例实现的健康监测设备的一些示例实现中,个性化的高保真度训练机器学习模型存储在远程存储器中,其中,远程存储器位于远离可穿戴式计算装置的位置处。在任何示例实现的健康监测设备的一些示例实现中,移动装置选自包含以下内容的组:智能手表;健身手环;平板计算机;和膝上型计算机。
- 还没有人留言评论。精彩留言会获得点赞!