一种基于半监督学习框架的T细胞受体序列分类方法与流程
本发明属于数据科学技术领域,具体涉及一种基于半监督学习框架的t细胞受体序列分类方法。
背景技术:
t细胞受体(英文名称:tcellreceptor,英文缩写:tcr)指携带在t细胞表面的蛋白质复合物,能够与宿主细胞上主要组织相容性复合物(英文名称:majorhistocompatibilitycomplex,英文缩写:mhc)分子呈递的抗原表位——抗原肽-mhc分子复合物(英文名称:peptide-mhc,英文缩写:pmhc)相结合,将t细胞表面发生识别的信号传递至t细胞核内,从而激活t细胞。t细胞受体对给定抗原表位的亲和力和结合的特异性大多数情况下仅用β链即可确定。t细胞受体与抗原肽-mhc分子复合物结合的主要区域则是第三互补决定(cdr3)区域。现有技术通过获得特异性识别肿瘤抗原的t细胞受体序列,可以将编码抗原特异性的t细胞受体基因序列导入患者自身t细胞中,获得特异性识别肿瘤抗原的t细胞,称为t细胞受体改造的t细胞(tcr-t),可用于治疗癌症。因此,了解t细胞受体与表位抗原之间的关系极为重要。
既有方法主要采用机器学习模型预测t细胞受体的结合表位。这些方法根据学习机制的不同,可以分为监督学习方法和无监督学习方法。无监督方法如john等人提出的deeptcr方法,对t细胞受体序列进行编码,使用变分自编码器学习高维空间中t细胞受体序列数据的基本分布以聚类相同抗原的t细胞受体序列。然而,对于深度学习这种需要大量数据的模型来说,受制于t细胞受体和表位数据的数量,发现t细胞受体序列下的数据分布仍然是一项艰巨的任务。监督学习方法如随机森林分类t细胞受体方法,利用整个cdr3区域上平均物理化学性质、序列长度、统计氨基酸个数、以及v基因和j基因等共计632个特征,使用随机森林方法对两个表位进行了一对一分类和一对多分类,其中v基因是可变区,j基因是连接点。受制于训练样本数据,又没有考虑到正例和负例之间的平衡,该方法的假阴性较高。
制约上述方法的原因之一是标注数据量非常有限,导致机器学习模型存在欠拟合、过拟合问题。但是,标注数据的量短时间内难以提高,原因主要包括:
1、获得t细胞受体对应的抗原表位需要进行复杂的实验;
2、在vdjdb公开数据库中,除几个人类白细胞抗原(英文名称:humanleukocyteantigen,英文缩写:hla)基因如hla-a*02:01等,主要组织相容性复合物分子对应的人类白细胞抗原基因往往和表位是一一对应的。
采用监督学习框架会浪费大量无标注数据,因此,考虑采用无监督学习框架,更为充分的利用有限的标注数据。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于半监督学习框架的t细胞受体序列分类方法,解决面向t细胞受体序列数据,当序列数据较少、训练数据规模小的情况下,使用机器学习策略有分类t细胞受体序列数据与其抗原表位的问题。
本发明采用以下技术方案:
一种基于半监督学习框架的t细胞受体序列分类方法,包括以下步骤:
s1、分别选取已分类和待分类cdr3β区域的t细胞受体数据作为输入数据,对两类数据按相同的规则进行特征编码;
s2、分别选择支持向量机、随机森林和决策树的监督学习算法作为监督学习模型;将步骤s1得到的已分类数据作为初始训练集,分别代入3个监督学习模型进行训练,构造3个对应的初始分类器c1、c2、c3;
s3、将步骤s1得到的未分类数据作为初始测试集,对步骤s2中的初始分类器c1、c2、c3进行测试;每1轮测试后,对于每个分类器,用一致选择策略整合另外两个分类器的测试结果,对分类器的训练集进行扩充;逐个分析未分类数据的每一个样本,扩充3个分类器的训练集;进入下一轮测试前,使用本轮扩充后的3个训练集分别对应的训练c1、c2、c3,完成对分类器的更新;当扩充后的3个训练集分别和上一轮扩充后的3个训练集完全相同时,停止迭代;
s4、步骤s3停止迭代后,获得训练完成的三个分类器c1、c2、c3;再将未分类数据分别代入c1、c2、c3,使用投票机制获得集成结果,实现t细胞受体序列的分类。
具体的,步骤s1具体为:
s101、已分类数据通过读取公开数据集dash和vdjdb中的数据获取,未分类数据由使用者提供;根据氨基酸的理化特性和疏水性对这两类数据进行特征编码;
s102、对于步骤s101中的vdjdb数据集,只提取其中可信度大于1且t细胞受体库中对应的记录超过50条的表位数据。
具体的,步骤s3中,对于未分类数据中的每一个样本,将样本分别代入三个分类器进行测试,每个分类器生成1个分类结果,称为伪标记;进入下一轮测试前,使用扩充后的3个训练集分别对应的训练三个分类器;逐轮迭代直至满足迭代终止条件,即在一轮扩充完成后,c1、c2、c3的扩充后的训练集与扩充前的训练集没有变化。
进一步的,当3个伪标记相同时,将样本和对应的伪标记同时加入三个分类器的训练集中;当2个伪标记相同且与另1个伪标记不同时,判断是否满足准确率条件;若满足准确率条件,则将样本和对应的伪标记加入伪标记不同的分类器的训练集中;若不满足准确率条件,则跳过样本;逐个分析未分类数据的每个样本,完成一轮训练集扩充。
更进一步的,若2个伪标记相同且与另1个伪标记不同,判断是否满足准确率条件具体为:
s301、计算c1的分类器在第t轮扩充和训练后的准确率:将步骤s1得到的已分类数据作为验证测试集,隐去分类标签;对于其中的任意一个样本x,若将x代入分类器c1进行分类,c1则会输出对x的分类结果c1(x);遍历已分类数据中的所有样本,计算分类正确的样本数占总样本数的比例,即为分类器c1在第t轮扩充和训练后的准确性,记为
s302、用步骤s301中的方法依次作用于分类器c2和c3,分别计算得出分类器c2和c3在第t轮扩充和训练后的准确性,分别记为
s303、若2个伪标记相同且与另1个伪标记不同,可以形式化表示为ci(x)与cj(x)相同且与ck(x)不同,i、j、k∈{1,2,3}且i、j、k互不相同;比较第t轮和第t-1轮的分类器正确率。
更进一步的,步骤s301中,当c1(x)与隐去的已知分类标签相同,判断c1分类正确;当c1(x)与隐去的已知分类标签不同,判断c1分类错误。
更进一步的,步骤s303中,第t轮和第t-1轮的分类器存在以下情况:
若
若
若
若
若
若
若
具体的,步骤s4中,采用加权投票的方法对分类结果进行集成,具体为:计算最后一轮扩充和训练后三个分类器c1、c2、c3的分类器准确率;对于未分类数据中的每一个样本,将该样本分别代入三个分类器进行计算,则每个分类器都会生成1个分类结果;用分类器准确率对样本的分类结果进行加权,以加权后得分最高的类别作为最终结果。
与现有技术相比,本发明至少具有以下有益效果:
本发明一种基于半监督学习框架的t细胞受体序列分类方法,基于t细胞受体序列数据与其抗原表位,针对其中存在数据量少的问题,引用半监督学习模型;模型提取t细胞受体的氨基酸理化特性和疏水性作为特征,对特征进行二分类半监督学习(区分表位与不是表位);训练完成后,使用经过训练的模型分类t细胞受体与抗原表位;本方法利用了半监督学习模型的优势,较好的解决了小规模训练数据下难以有效使用机器学习分类模型的难题。
进一步的,氨基酸疏水性等性质是学界比较公认的特征属性;各个t细胞受体序列的长短不一致,本发明的编码方法能够对齐序列,有助于特征提取;只提取其中可信度大于1且t细胞受体库中对应的记录超过50条的表位数据能够避免低质量数据对模型精度的影响。
进一步的,步骤s3的训练集来自于每次迭代训练过程中的未分类数据。未分类数据既是模型的求解目标,也是有助于改进模型精度的潜在训练集。因此,逐步扩充训练集有助于模型基于更多的数据开展学习。
进一步的,在迭代训练过程中,当单分类器的分类性能较差时,分类器可能将错误的分类结果引入到其余两个分类器中,但根据噪声理论,满足步骤s303的条件时,分类错误有更大的概率被正确标记的训练集抵消,使得模型在迭代过程中保证了分类器的分类错误越来越少。
综上所述,本发明提出了一种基于半监督学习框架的t细胞受体序列分类方法;该方法属于一类机器学习分类策略,设计和使用了一种半监督学习框架。针对监督机器学习策略的缺点——需要大规模训练数据,通过半监督学习模型予以解决:第一,半监督学习模型相比于已有方法,所需的样本量显著减少,适用于t细胞受体序列训练数据难以获得的现状;第二,本发明的模型设计中,将待测数据与学习过程中的未标记样本相统一,也就是半监督学习中的直推学习,在未标记样本上获得较优的泛化性能。实验数据证明,本发明的性能显著优于已有方法。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
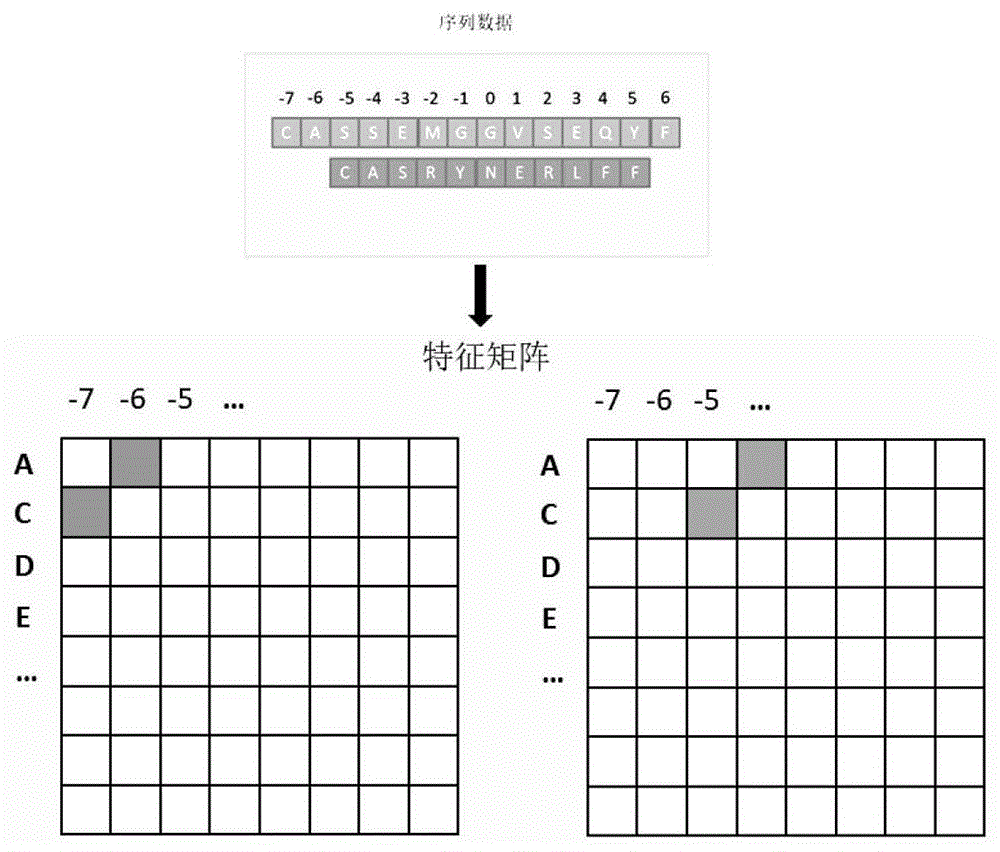
图1为特征矩阵建立的过程;
图2为tri-training框架流程图;
图3为semitcr与tcrgp的小提琴比较图;
图4为表位pp65与对照表(none)均值变化图;
图5为表位pp65与bmlf的roc曲线图。
具体实施方式
本发明提供了一种基于半监督学习框架的t细胞受体序列分类方法,使用支持向量机、随机森林和决策树的监督学习算法构建三重学习法框架解决前述的数据量少的难题。支持向量机、随机森林以及决策树都有各自的优缺点。首先,支持向量机在小样本集上具有良好的性能(表位数据集在不同比例划分时,数据量会减少),因此在方法中可以提高初始分类器预测的准确性,这有助于模型的迭代提高最终模型的预测精度。随机森林不易过拟合,并且在异常值和噪声方面具有很高的容忍度,对于不平衡的数据具有较强的鲁棒性。决策树适合高维数据以及适合处理有缺失属性的样本,使用决策树可以减少缺少值的影响(特征序列存在0值)。
请参阅图2,本发明一种基于半监督学习框架的t细胞受体序列分类方法,包括以下步骤:
s1、对t细胞受体数据进行特征编码
s101、已分类数据通过读取公开数据集dash和vdjdb中的数据获取,未分类数据由使用者提供;根据氨基酸的理化特性和疏水性对这两类数据进行特征编码;
s102、对于步骤s101中的vdjdb数据集,只提取其中可信度大于1且t细胞受体库中对应的记录超过50条的表位数据。
s103、仅选取cdr3β区域作为输入数据,选择氨基酸理化特性和疏水性的编码方法;
请参阅图1,以数据集中最长的序列长度为基准,中间对齐的方式进行其余序列的特征编码,并考虑每种氨基酸的在序列中的位置;将原始特征矩阵表示为x={x1,x2,…,xn},y={y1,y2,...,yn},其中,xi∈rm表示一个cdr3序列样本,yi∈r表示cdr3序列样本的一个表位类别,n表示为训练集样本数,m表示为维度数。
s2、构造初始分类器
将步骤s1得到的已分类数据作为初始训练集,分别代入上述3个监督学习模型进行训练,构造出3个对应的初始分类器,用c1、c2、c3表示;
s3、训练集和模型的更新
s301、对于未分类数据中的每一个样本,将该样本分别代入三个分类器进行测试,则每个分类器都会生成1个分类结果,称为伪标记;
s302、若3个伪标记相同,则将该样本和对应的伪标记同时加入三个分类器的训练集中;
s303、若2个伪标记相同且与另1个伪标记不同,则判断是否满足准确率条件;
s30301、计算c1的分类器在第t轮扩充和训练后的准确率:将步骤s1得到的已分类数据作为验证测试集,隐去分类标签;对于其中的任意一个样本x,若将x代入分类器c1进行分类,c1则会输出对x的分类结果c1(x);此时,存在两种情况:其一,c1(x)与隐去的已知分类标签相同,说明c1分类正确;其二,c1(x)与隐去的已知分类标签不同,说明c1分类错误;遍历已分类数据中的所有样本,计算分类正确的样本数占总样本数的比例,即为分类器c1在第t轮扩充和训练后的准确性,记为
s30302、用步骤s301中的方法依次作用于分类器c2和c3,分别计算得出分类器c2和c3在第t轮扩充和训练后的准确性,分别记为
s30303、若2个伪标记相同且与另1个伪标记不同,可以形式化表示为ci(x)与cj(x)相同且与ck(x)不同,其中i、j、k∈{1,2,3}且i、j、k互不相同;比较第t轮和第t-1轮的分类器正确率,存在以下7种情况:
1、若
2、若
3、若
4、若
5、若
6、若
7、若
s30304、若满足准确率条件,则将该样本和对应的伪标记加入那个伪标记不同的分类器的训练集中;若不满足准确率条件,则跳过该样本;
s304、迭代步骤s302~s303,直至完成对未分类数据的每个样本的分析,完成一轮训练集扩充;
s305、使用扩充后的3个训练集分别对应的训练三个分类器;
s306、迭代步骤s301-s305,直至满足迭代终止条件,即在一轮扩充完成后,c1、c2、c3的扩充后的训练集与扩充前的训练集没有变化。
s4、三个分类器通过加权投票机制作为一个分类器集成进行使用。
计算最后一轮扩充和训练后三个分类器c1、c2、c3的分类器准确率;对于未分类数据中的每一个样本,将该样本分别代入三个分类器进行计算,则每个分类器都会生成1个分类结果;用分类器准确率对样本的分类结果进行加权,以加权后得分最高的类别作为最终结果。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中的描述和所示的本发明实施例的组件可以通过各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
数据集
使用dash和vdjdb两个知名的公开数据集。dash数据集从10个类别中收集了带注释的t细胞受体序列,共有2336个序列,包括3种人类表位来源于hla-a*02:01基因(pp65、m1、vdjdb)、7种小鼠表位来源于db基因(np、pa、f2、m45)、kb基因(pb1、m38、m139)。vdjdb数据集包含具有已知抗原特异性的t细胞受体序列。
实验数据
针对dash和vdjdb两个数据集中的32个表位数据,以测试集比例为0.2、0.4、0.5、0.6、0.7、0.8、0.9进行划分数据集。采用5折分层交叉验证。保证训练集和测试集的正例和负例数量保持一致。以数据集比例为0.9左右为例,10%左右的数据作为训练集,90%左右的数据作为测试集,在训练时,将这90%左右的测试集作为无标签数据加入半监督学习中,训练结束后经过5折交叉验证预测90%左右的测试集。以此研究半监督学习较于监督学习的性能。5折交叉验证即将数据分为5个部分,每次取其中一个部分,剩余部分用来做测试,共需要进行5次。
(1)对semitcr的性能评估:
dash数据集中人类和老鼠的32表位数据集不同划分比例下,从表1和表2中可以看出,各个表位体现了在测试集划分下,测试集占比越低,准确率曲线持续上升,符合正常现象。并且通过特征分析比较了两个表位bmlf和pp65,发现从特征分析即可说明pp65数据的表现较低,请参阅表1、图4和图5。针对pp65是最多样化的表位,因此,高度多样性是pp65数据难以区分的一个原因。
表1dash数据集人类和老鼠各个表位数据集不同划分比例
表2vdjdb各个表位数据集不同划分比例
(2)将最新技术tcrgp与semitcr进行对比
结果分别如表3和图3所示,以及从在各个划分比例下的小提琴图显示,semitcr的结果分布更加集中,在不同划分比例下,semitcr对22个表位的平均准确率均高于tcrgp,并且测试集划分的越大,semitcr性能越明显。
表3semitcr与tcrgp在dash和vdj数据集上的平均准确率对比结果
综上所述,本发明提出了一种基于半监督学习框架的t细胞受体序列分类方法;该方法属于一类机器学习分类策略,设计和使用了一种半监督学习模型,具备机器学习分类的优势。同时,针对机器学习策略的缺点——需要大规模训练数据,通过半监督学习模型予以解决:第一,半监督学习模型相比于已有方法使用的监督学习模型,所需的样本量显著减少,适用于t细胞受体序列数据难以获得的情况;第二,本发明的模型设计中,将待测数据与学习过程中的未标记样本相统一,也就是半监督学习中的直推学习,在未标记样本上获得最优的泛化性能。实验数据证明,本发明模型性能显著优于已有方法。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!