基于临床标志物构建中国人群生物学年龄评价模型的方法及评价方法与流程
本发明适于生物学年龄评价技术领域,具体是涉及一种基于临床常规标志物构建生物学年龄评价模型的方法及评价方法,适用于中国人群。
背景技术:
促进健康老龄化客观上要求降低老年疾病(如高血压、糖尿病)负担。时序年龄(chronologicalage)毫无疑问是这些慢性疾病及死亡的最大风险因素。但同样时序年龄的个体对于这些疾病的易感性仍存有差异,原因之一可能是时序年龄不能准确反映一个个体的衰老程度。对应地,生物学年龄(biologicalage)则能较准确地评价衰老,进而帮助识别衰老高危个体,尤其是在生命早期(如中青年期),另一方面也能帮助识别衰老过程的影响因素,辅助衰老干预措施的效力评估,具有重要理论和现实意义。
公开号为cn106202989a的专利文献公开了一种基于口腔微生物群落获得儿童个体生物年龄的方法,该方法通过获得含有所述儿童个体口腔微生物的样品;并提取口腔微生物的dna;将所述dna信息转化为微生物群落信息,利用随机森林算法,对口腔微生物群落信息与年龄进行回归,回归模型,获得所述中国人群儿童个体年龄。
公开号为cn110408684a的专利文献公开了一种端粒长度检测试剂盒与方法及生物学年龄评价方法,其首先利用其提供的试剂盒及平均校准因子计算方法,建立中国人群端粒长度检测校准t/s数据库,并绘制校准t/s值-年龄分布图;然后依据上述端粒长度校准t/s值-年龄模型分布图,建立端粒长度-生物学年龄的算法模型系统;利用该系统进行生物学年龄计算,并给出端粒长度在人群中的分布情况。
公开号为cn110392740a的专利文献公开了一种预测生物学年龄的方法,其首先确定待测个体所属人群样本的以性别年龄分类的各生物学年龄预测生物指标集;基于待测个体对应的以性别年龄分类的生物学年龄预测生物指标集,计算所述待测个体的生物学年龄初步估计值basc;以不同人群的样本年龄分布数据为参照,对所述生物学年龄初步估计值basc进行最大后验概率计算处理,以便确定所述待测个体的预测生物学年龄ba。
临床常规标志物反映机体不同系统不同层面的健康状况,在临床上被日常监测,具有应用价值;如加以整合,可构建反映机体整体衰老情况的生物学年龄指标。相比于其他方法预测生物学年龄,如基于dna甲基化数据,这种基于临床常规标志物构建生物学年龄评价指标,性价比高和可操作性强,在大规模流行病调查和临床实践中具有更佳的应用价值。
技术实现要素:
本发明提供了一种基于临床常规标志物构建中国人群生物学年龄评价模型的方法,利用所述模型预测的生物学年龄与时序年龄相关,且在扣除时序年龄影响后,可预测全因死亡,并与疾病个数关联显著。
本发明还提供了一种中国人群生物学年龄评价方法,使用者利用该发明可实现个体生物学年龄科学评价,提前采取相应的防控措施延缓衰老、降低老年疾病患病风险。
一种基于临床常规标志物构建生物学年龄评价模型的方法,包括:
(1)利用生物学和统计学标准选择了代表不同病理生理系统或功能的标志物;
(2)利用选择的标志物,基于kdm算法,构建生物学年龄评价模型;
(3)对得到的生物学年龄评价模型进行评估,若效果欠佳,返回步骤(1)和(2),进行下一轮模型构建操作;若效果符合要求,则输出所构建的生物学年龄评价模型。
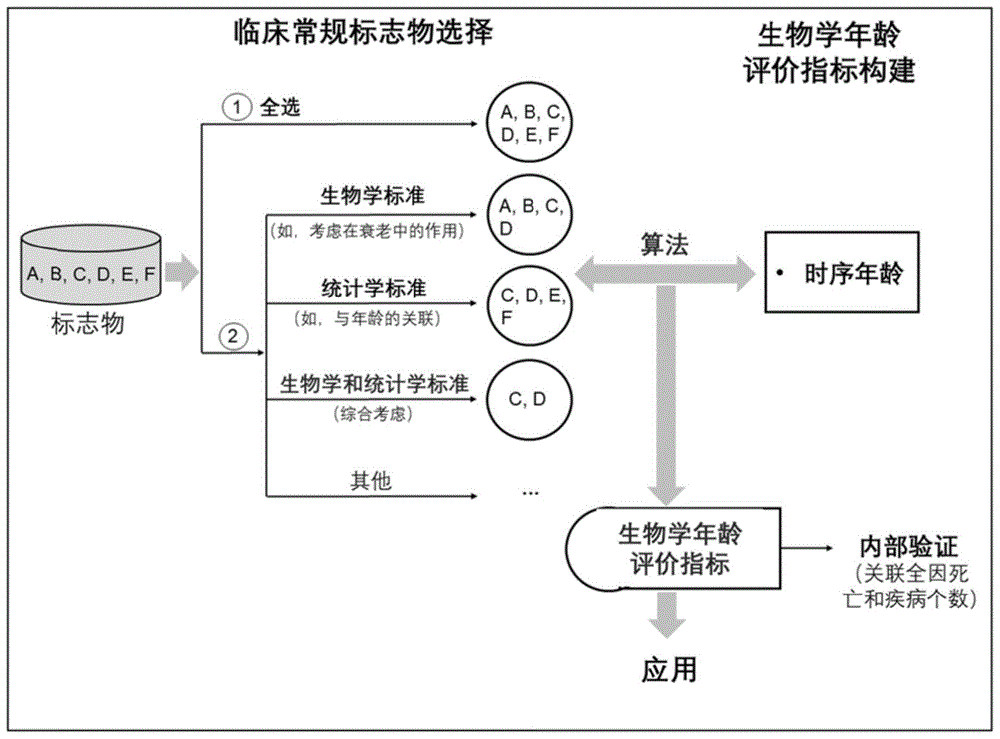
标志物的获得和选择是本发明的难点之一。标志物的获得很大程度上取决于所依托的数据资源。例如,由于诸多限制(如尿液样本采集相对困难),大规模流行病学调查所提供的标志物基本来自于血浆或血清,且数目有限。标志物的选择有一些不同的方法/标准(图1)。本发明中我们采用生物学和统计学标准并用的方法,这在一定程度上能提高后期的统计效率。作为一种实施方案,我们采用的标准如下:a)标志物在衰老过程中具有一定作用;b)标志物在之前衰老研究中被使用到;c)标志物在目前大部分流行病学调查中被测量;d)标志物与时序年龄具有较强的关联。其中a)是典型的基于生物学标准的选择方法,d)是典型的基于统计学标准的选择方法。作为一种实施方案,所选标志物必须代表如下病理生理系统或功能中的一种或多种:免疫功能、心脏代谢功能、肝功能、肾功能。基于以上标志物的获得和选择标准可知,所选择标志物的数量没有具体限制,以包括c反应蛋白(或者高敏c反应蛋白)、肌酐、收缩压为佳。一般选择3~20个标志物。
对于标志物的获得,作为一种实施方案,提供所述标志物的人群具有一定要求,具体为:1000例以上、年龄范围覆盖20-60岁。作为优选,人群为:2000例以上、年龄分布在20-79岁之间的个体。作为一种具体的实施方案,本发明中我们选择2009年中国健康与营养调查(chinahealthandnutritionsurvey,chns)中20-79岁的人群。
对于标志物的选择,本发明中提供一种优选方案,所述标志物(12种)包括总胆固醇、甘油三酯、糖化血红蛋白、尿素、肌酐、白蛋白、高敏c反应蛋白、红细胞计数、血小板计数、铁蛋白、转铁蛋白和收缩压。利用上述这些标志物数据构建的模型预测效力较好。作为一种次优选方案,所述标志物(8种)包括总胆固醇、甘油三酯、糖化血红蛋白、尿素、肌酐、高敏c反应蛋白、血小板计数和收缩压。所述高敏c反应蛋白也可以替换为c反应蛋白,本发明对此没有限制。
算法的选择是本发明另外一个需要克服的难点。算法被众多学者用来基于标志物预测时序年龄,或者从标志物与年龄关系中提取信息,进而构建生物学年龄评价指标。目前存在的算法包括多重线性回归法、因子分析、主成分分析法以及kdm算法(klemeraanddoubalmethod,kdm)等。其中kdm算法原理和计算稍显复杂,但更优秀且未被用于中国人群生物学年龄构建,故本发明中我们选用kdm算法。kdm算法在2006年由klemera和doubal提出,其推演细节请参见文献(klemerap,doubals.mechageingdev2006,127(3):240-248.)。简言之,kdm算法从时序年龄与m个标志物的m个回归曲线中获取信息,最终转化为单位为岁的生物学年龄kdm-ba。详见下面公式:
其中m为所选择的标志物总数量,xj为某一个体对应的标志物j的数值,ca为该个体对应的时序年龄。对于每个标志物j,通过将该标志物与时序年龄进行回归,估算得到所述参数qj,kj和sj;其中qj为标志物j对应的回归截距,kj为标志物j对应的回归系数,sj为标志物j对应的均方根误差;sba为标度因子,等于在数据集中所选择的标志物组所能解释的时序年龄的变异的平方根。
为了扣除时序年龄的影响,我们将计算得到kdm-ba与时序年龄进行回归,得到残差,即为kdm-ba年龄加速(baacceleration)。年龄加速为0则意味着一个个体的生物学年龄与基于其时序年龄的预期情况一致,而年龄加速为正值则意味着一个个体具有一个较他/她年龄年老的个体拥有的临床标志物谱;反之,则意味着一个个体具有一个比他/她年龄年轻的个体所拥有的临床标志物谱。
作为一种实施方案,本发明对得到的生物学年龄评价模型进行评估。作为优选的实施方案,本发明中基于该生物学年龄评价模型,计算生物学年龄,分析该生物学年龄与所述个体的全因死亡和疾病个数之间的关联,基于得到的关联分析结果,进行所述步骤(3)中的评估。
作为一种实施方案,本发明中我们利用cox比例风险回归模型分析生物学年龄评价指标与全因死亡之间的关联,记录风险比(hazardratio)值和p值。风险比大于1,p值小于0.05,则认为生物学年龄评价指标与全因死亡显著相关。我们采用线性回归模型或泊松回归模型分析生物学年龄评价指标与疾病个数的关联,记录回归系数coef值和p值。coef大于0,p值小于0.05,则认为生物学年龄评价指标与疾病个数显著相关。生物学年龄评价指标与全因死亡和疾病个数显著相关则证实其具有预测效力和应用价值。
本发明还提供了一种生物学年龄评价方法,利用上述任一项技术方案所述的生物学年龄评价模型进行评价。
评价时,根据待评价对象的时序年龄,结合本发明得到的评价模型,即可得到其对应的生物学年龄。
作为一种优选(12个标志物),所述模型公式如下:
其中:kdm-ba为所构建的生物学年龄指标。urea为尿素(单位:mmol/l),hscrp为高敏c反应蛋白(mg/l),cre为肌酐(μmol/l),fet为铁蛋白(ng/ml),rbc为红细胞计数(1012cells/l),plt为血小板计数(109cells/l),alb为白蛋白(g/l),tg为甘油三酯(mmol/l),tc为总胆固醇(mmol/l),trf为转铁蛋白(mg/dl),hba1c为糖化血红蛋白(%),sbp为收缩压(mmhg),ca为时序年龄(岁)。
作为一种次优选(8个标志物),所述模型公式如下:
其中:kdm-ba为所构建的生物学年龄指标。urea为尿素(单位:mmol/l),hscrp为高敏c反应蛋白(mg/l),cre为肌酐(μmol/l),plt为血小板计数(109cells/l),tg为甘油三酯(mmol/l),tc为总胆固醇(mmol/l),trf为转铁蛋白(mg/dl),hba1c为糖化血红蛋白(%),sbp为收缩压(mmhg),ca为时序年龄(岁)。
本发明基于临床常规标志物构建评价生物学年龄的模型,并利用该模型实现对中国人群生物学年龄的评价,本发明依托已建立的国家层面大型队列(中国营养与健康调查)中生物标志物数据,首先利用生物学和统计学标准从数十种临床常规标志物中选择具有代表性的几种(比如8种或者12种),进而应用kdm算法构建模型,预测生物学年龄。数据证明,本发明构建的模型评价得到的生物学年龄与时序年龄相关,且在扣除时序年龄后,可以预测全因死亡,并与疾病个数关联显著。使用者利用该发明可实现个体生物学年龄科学评价,提前采取相应的防控措施降低老年疾病患病风险。
我们进一步证明,即使考虑了ca和性别因素,本发明的生物学年龄评价模型对全因死亡也有很高的预测性,并且与ca和性别的基本模型相比,在模型识别方面有显著的改善。除了极少数例外,这些死亡预测在不同的亚人群中都是可靠的,特别是按年龄、民族、性别、教育和健康行为。最后,本发明的生物学年龄评价模型与疾病计数相关。
总的来说,本发明提供了一种可以评价我国人群生物学年龄的方法。该方法可应用在对于我国人群衰老的早期识别和预防以及针对老年疾病的干预效果评估上,具有实用性,应用潜力巨大。
附图说明
图1为基于临床常规检查标志物构建生物学年龄评价指标的流程框架:其中,a到f指代不同的标志物。
图2展示了kdm-ba年龄加速的分布情况及kdm-ba与时序年龄的相关性情况:其中,kdm-ba为由kdm算法构建的生物学年龄评价指标,ca为时序年龄。a图展示了kdm-ba年龄加速(矫正了时序年龄)的分布;b图展示了kdm-ba与时序年龄的相关性。
图3展示了每增加一种疾病所预测的kdm-ba年龄加速情况:其中,kdm-ba为由kdm算法构建的生物学年龄评价指标。x轴显示了根据每个受试者的疾病个数进行分类的组(无任何疾病、1种疾病、2种疾病和3种及以上疾病)。y轴显示与无任何疾病受试者相比,具有1种、2种或3种及以上疾病受试者其kdm-ba年龄加速的数值。图中结果是基于一个线性回归模型,并对年龄和性别进行了调整。
图4展示了每增加一种疾病所预测的kdm-ba(基于次优选方案的8个标志物)年龄加速情况:其中,kdm-ba为基于次优选方案(8个标志物)由kdm算法构建的生物学年龄评价指标。x轴显示了根据每个受试者的疾病个数进行分类的组(无任何疾病、1种疾病、2种疾病和3种及以上疾病)。y轴显示与无任何疾病受试者相比,具有1种、2种或3种及以上疾病受试者其kdm-ba年龄加速的数值。图中结果是基于一个线性回归模型,并对年龄和性别进行了调整。
具体实施方式
下面结合实施例和附图对本发明做进一步说明:
实施例的具体内容:
1、综合考虑生物学和统计学标准,选择临床常规标志物,应用kdm算法在chns(2009年)队列20-79岁人群中构建生物学年龄评价指标。
我们选择的标志物来自2009年中国健康与营养调查(chinahealthandnutritionsurvey,chns)数据。chns是一个关于中国全年龄段人群(从0岁开始)的国家层面的前瞻性队列研究,其目的在于跨时空探索社会经济和人口转变如何影响整个人群营养和健康状况。chns在1989年启动,随后分别在1991年、1993年、1997年、2000年、2004年、2006年、2009年、2011年和2015年进行了重复调查。chns采用了多阶段整群抽样方法,从全国9个省份招募受访者。截止2011年,chns一共招募了30000余人(据2010年人口普查数据显示,这9个省份贡献了我国总人口的47%)。在chns调查中,所有受访者都提供了包括人口学、社会经济学、饮食、生活方式和慢性疾病等各方面信息。2009年,chns第一次采集受访者的血样并进行了临床常规标志物(如总胆固醇、甘油三酯)的检测。所有受访者都提供了知情同意书。chns调查通过了北卡罗来纳大学和美国国家营养与食物安全研究所的伦理批准,数据对外公开,经申请后免费使用。
2009年chns提供了25个临床常规标志物,加上收缩压和舒张压,一共27个标志物可供选择。其中几组标志物之间具有较高的相关性(r>0.7),比如总胆固醇、低密度脂蛋白胆固醇和载脂蛋白b,糖化血红蛋白和血糖,收缩压和舒张压。综合考虑标志物在临床上的价值和本身的性能以及其是否也在其他大多数调查中被检测,在以上每组(具有较高相关性的标志物定义为一组)中我们保留一个标志物进入第一轮候选,即总胆固醇、糖化血红蛋白和收缩压。紧接着,我们选择与年龄相关性大于0.1的标志物作为最终候选。最终纳入12个标志物,包括总胆固醇、甘油三酯、糖化血红蛋白、尿素、肌酐、白蛋白、高敏c反应蛋白、红细胞计数、血小板计数、铁蛋白、转铁蛋白和收缩压。它们代表了不同的病理生理系统或功能,包括免疫功能(高敏c反应蛋白、红细胞计数和血小板计数)、心脏代谢功能(总胆固醇、甘油三酯、糖化血红蛋白、铁蛋白和收缩压)、肝功能(白蛋白)和肾功能(尿素和肌酐)。在进行构建生物学年龄评价指标前,非正态分布的标志物(高敏c反应蛋白、铁蛋白和甘油三酯)进行了对数转换,以满足模型前提要求。这12个最终候选标志物在临床上非常常见,增加了生物学年龄评价模型的性价比和可操作性。
本实施例中,我们选择了2009年chns中具有临床常规标志物的8394例个体,年龄分布在20-79岁。在删除标志物缺失的275例之后,剩下8119例为最终分析样本。删除样本在基本人口学特征上与最终分析样本类似,比如年龄(删除样本48.4岁vs.分析样本49.9岁,p=0.061),汉族比例(删除样本88.9%vs.分析样本88.3%,p=0.854),但删除样本中男性比例较高(删除样本53.5%vs.分析样本46.5%,p=0.027)。
kdm算法模型如下:
其中kdm-ba为生物学年龄,m为所选择的标志物总数量,xj为某一个体对应的标志物j的数值,ca为该个体对应的时序年龄。对于每个标志物j,通过将该标志物与时序年龄进行回归,估算得到所述参数qj,kj和sj;其中qj为标志物j对应的回归截距,kj为标志物j对应的回归系数,sj为标志物j对应的均方根误差;sba为标度因子,等于在数据集中所选择的标志物组所能解释的时序年龄的变异的平方根。
基于前面所述的kdm算法模型,利用以上所选择的12个标志物,我们进行了模型构建,最终得到如下结果:
其中:kdm-ba为所构建的生物学年龄指标。urea为尿素(单位:mmol/l),hscrp为高敏c反应蛋白(mg/l),cre为肌酐(μmol/l),fet为铁蛋白(ng/ml),rbc为红细胞计数(1012cells/l),plt为血小板计数(109cells/l),alb为白蛋白(g/l),tg为甘油三酯(mmol/l),tc为总胆固醇(mmol/l),trf为转铁蛋白(mg/dl),hba1c为糖化血红蛋白(%),sbp为收缩压(mmhg),ca为时序年龄(岁)。
我们将计算得到kdm-ba与时序年龄进行回归,得到残差,即为kdm-ba年龄加速(baacceleration),年龄加速的分布如图2所示。我们看到,kdm-ba范围为15.1到87.3岁(均值49.9岁,中位数50.3岁,标准差14.3岁)。kdm-ba年龄加速均大致呈现出正态分布(图2a),但kdm-ba与时序年龄具有较强的相关性(图2b,部分原因由于时序年龄被包括在kdm-ba计算公式中)。
2、基于chns基线(即:chns2009年)及随访数据,在全人群和亚人群(如不同年龄层、不同健康状态的人群)中,分析以上所构建的生物学年龄评价指标基线水平与全因死亡之间的关联。
chns在每轮调查中都采集了前一轮死亡个体的死亡时间。我们定义生存时间为基线(2009年调查时间)到随访终点——死亡或者删失的时间(删失时间为2013年或2015年调查时间。死亡和删失二者中谁先到,则为随访终点)。chns在2009年调查中采集了高血压、糖尿病、心梗、卒中、髋部骨折、哮喘和癌症等疾病信息。我们将其简单相加,得到一个疾病个数变量(从0到7),数字越大,表示个体所患疾病越多。基于疾病个数变量,我们构建一个分类变量:无任何疾病、1种疾病、2种疾病和3种及以上疾病。
我们还利用其它相关协变量信息如下:年龄、性别、民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数(bodymassindex,bmi)。这些协变量是在调查时通过问卷或体检采集的。其中大多数协变量为两分类变量,包括性别(男性、女性)、民族(汉族、其他)、婚姻状况(目前已婚、其他)、吸烟状况(不吸烟、吸烟)和饮酒状况(不饮酒、饮酒)。教育程度为四分类变量,包括为未正式上过学、小学、中学和高中及以上。身体质量指数bmi的计算方法是体重(千克)除以身高(米)的平方。我们将bmi四分类:低体重定义为bmi<18.5kg/m2;正常定义为18.5≤bmi<25.0kg/m2;超重定义为24.0≤bmi<28.0kg/m2;肥胖定义为bmi≥28kg/m2。
我们采用cox比例风险回归模型(cox回归模型)分析生物学年龄评价指标与全因死亡之间的关联,结果见表1。模型1调整了时序年龄和性别。我们发现kdm-ba年龄加速每增加一年,个体死亡率增加14%(风险比=1.14,95%置信区间=1.08,1.19)。模型2中进一步调整民族、教育程度、婚姻状况、吸烟状况、饮酒状况、身体质量指数(按分类变量处理),结果并未出现较大变动。当根据kdm-ba年龄加速的五分位数对样本进行分层时,我们发现与最低五分位数(q1,参照组)相比,最高五分位数(q5)的个体死亡风险增加了83%(风险比=1.83,95%置信区间=1.24,2.71)。在进一步调整其他协变量(包括民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数,模型2)后,这些关联并没有任何实质性变化。由以上关联分析结果可知,利用本发明的预测模型得到的生物学年龄能够很好地预测死亡风险。
表1.全人群中kdm-ba与全因死亡的关联分析
表1中:kdm-ba为由klemera-doubal法计算得到的生理学年龄;q1-q5为五分位数(从最低到最高)。模型1中调整了时序年龄和性别。模型2中进一步调整了民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数(按分类变量处理)。
为评估本实施例得到的生物学年龄对5年死亡率的预测效力,我们构建了2个logistic模型:模型1的自变量包括kdm-ba+时序年龄+性别;模型2的自变量包括ca+性别。分别计算模型1和模型2的roc曲线下面积auc,为0.810和0.803,二者相比无显著性差异(使用“delong”方法时p值为0.450,见表2)。然而,与模型2相比,模型1的模型区分度(idi:0.36%,p值=0.033)有显著改善。这说明,我们所构建的kdm-ba在时序年龄基础上提高了对于死亡的预测效力。
我们关心kdm-ba是否在貌似健康的人群中是否能准确预测死亡,因此我们定义了“健康”:即没有汇报任何疾病和拥有正常身体质量指数。我们发现在“健康”个体中,kdm-ba与死亡率相关(风险比=1.18,95%置信区间=1.05,1.31,表3)。在对5年死亡率的预测效力上,kdm-ba在调整时序年龄+性别基础上,增加了预测效力(auc=0.817,idi:0.76%,p=0.034,表2)。
表2.kdm-ba对于5年死亡率的预测情况
表2中:auc为roc曲线下面积;连续净重新分类指数:continuousnetreclassificationindex,nri;综合判别改善指数:integrateddiscriminationimprovement,idi。以上利用r包(“predictabel”)计算得到。nri等于x%意味着,与没有发生结局事件的个体相比,发生结局事件的个体向上移动(到一个类别)的概率比向下移动的概率高出近x%(这取决于发生结局事件的个体被正确分配了更高的概率,而没有发生结局事件的个体在更新的模型中被正确分配了更低的概率(例如,模型1)与初始模型(即,模型2)相比。idi等于x%意味着在更新的模型中(例如,模型1)发生和没有发生结局事件的个体之间的平均预测风险差增加了x%。
为了进一步探索所构建的生物学年龄评价指标是否适用于不同亚人群,我们在不同亚人群中应用cox比例风险回归模型分析了kdm-ba与全因死亡的关联。我们发现,无论亚组如何,这些模型中的大多数结果是一致的(表3)。例如,当按年龄、民族、性别、教育程度、吸烟状况或饮酒状况分层时,kdm-ba的风险比从1.11(老年人)到1.27(高中或以上教育程度)不等,与全人群中1.14(表1)中的风险比一致。在无任何疾病的受试者中,我们没有观察到死亡率与kdm-ba有显著相关性(风险比=1.05,95%置信区间=0.97,1.13)。而在两种及以上疾病的患者中,kdm-ba(风险比=1.14,95%置信区间=1.02,1.27)与全因死亡显著相关。在那些被定义为健康(即没有疾病和正常身体质量指数)的个体中,我们发现kdm-ba与全因死亡相关(风险比=1.18,95%置信区间=1.05,1.31)。这说明我们所构建的生物学年龄评价指标不受个体的基本特征所影响,具有一定的普适性。
表3.不同亚人群中kdm-ba与全因死亡的关联分析
表3中:kdm-ba,由klemera-doubal法计算得到的生物学年龄。以上所有模型调整了时序年龄和性别(除性别分层分析外)。
*身体质量指数bmi的计算方法是体重(公斤)除以身高(米)的平方。低体重定义为bmi<18.5kg/m2;正常定义为18.5≤bmi<25.0kg/m2;超重定义为24.0≤bmi<28.0kg/m2;肥胖定义为bmi≥28kg/m2。
3、基于chns基线数据,在全人群中分析以上所构建的生物学年龄评价指标基线水平与疾病个数之间的关联
图3显示了与无任何疾病的受试者相比,对每增加一种疾病所预测的kdm-ba年龄加速情况。总的来看,有疾病的受试者比没有任何疾病的受试者具有更高的kdm-ba年龄加速。汇报一种疾病者的年龄加速为1.2岁,患两种疾病者的年龄加速约为1.9岁,患三种及以上疾病者的年龄加速为2.4岁。由此可知,疾病与利用本发明预测的生物学年龄具有很强的相关性。
为了进一步了解所构建的生物学年龄指标与疾病个数之间的关联,我们使用泊松回归模型来检验2009年全人群样本中kdm-ba与疾病个数之间的关系(表4)。模型1对年龄和性别进行了调整,结果显示,kdm-ba与疾病计数显著相关(coef.=0.19,se=0.008,p<0.001)。模型2进一步调整了民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数,结果仍然保持不变。图3和表4均证实本发明预测的生物学年龄与疾病个数显著相关。
表4.kdm-ba与疾病个数的关联分析
表4中:kdm-ba,由klemera-doubal法计算得到的生物学年龄;coef,回归系数;se,标准误差。模型1中调整了时序年龄和性别。模型2中进一步调整了民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数(按分类变量处理)。
作为一种次优选,同样基于kdm算法,我们也构建了基于8个标志物(分别为:尿素、高敏c反应蛋白、肌酐、血小板计数、甘油三酯、总胆固醇、糖化血红蛋白、收缩压)的模型,最终得到如下结果:
其中:kdm-ba为基于次优选方案中8个标志物所构建的生物学年龄指标。urea为尿素(单位:mmol/l),hscrp为高敏c反应蛋白(mg/l),cre为肌酐(μmol/l),plt为血小板计数(109cells/l),tg为甘油三酯(mmol/l),tc为总胆固醇(mmol/l),hba1c为糖化血红蛋白(%),sbp为收缩压(mmhg),ca为时序年龄(岁)。
我们同样采用cox比例风险回归模型(cox回归模型)分析次优选方案中生物学年龄评价指标与全因死亡之间的关联,结果见表5。模型1调整了时序年龄和性别。我们发现kdm-ba年龄加速每增加一年,个体死亡率增加5%(风险比=1.05,95%置信区间=1.03,1.08)。模型2中进一步调整民族、教育程度、婚姻状况、吸烟状况、饮酒状况、身体质量指数(按分类变量处理),结果并未出现较大变动。以上结果提示,利用次优选的预测模型得到的生物学年龄同样能够很好地预测死亡风险。
表5.全人群中kdm-ba与全因死亡的关联分析
表5中:kdm-ba为基于次优选方案中8个标志物由klemera-doubal法计算得到的生理学年龄。模型1中调整了时序年龄和性别。模型2中进一步调整了民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数(按分类变量处理)。
图4显示了与无任何疾病的受试者相比,对每增加一种疾病所预测的次优选方案中kdm-ba年龄加速情况。总的来看,有疾病的受试者比没有任何疾病的受试者具有更高的kdm-ba年龄加速。汇报一种疾病者的年龄加速为2.9岁,患两种疾病者的年龄加速约为4.5岁,患三种及以上疾病者的年龄加速为5.0岁。由此可知,疾病与利用本发明预测的生物学年龄具有很强的相关性。
使用泊松回归模型,我们进一步观察到对次优选方案中kdm-ba与疾病个数之间的关系(表6)。模型1对年龄和性别进行了调整,结果显示,kdm-ba与疾病计数显著相关(coef.=0.10,se=0.004,p<0.001)。模型2进一步调整了民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数,结果仍然保持不变。图4和表5均证实本发明预测的生物学年龄与疾病个数显著相关。
表6.kdm-ba与疾病个数的关联分析
表6中:kdm-ba为基于次优选方案中8个标志物由klemera-doubal法计算得到的生物学年龄;coef,回归系数;se,标准误差。模型1中调整了时序年龄和性别。模型2中进一步调整了民族、教育程度、婚姻状况、吸烟状况、饮酒状况和身体质量指数(按分类变量处理)。
综上所述,利用全国人群前瞻性队列研究的数据,我们使用优选的12种临床标志物,构建了一种评价我国人群生物学年龄的方法:kdm-ba。我们进一步证明,即使考虑了时序年龄和性别因素,这种生物学年龄评价指标对全因死亡也有很高的预测效力,并且与时序年龄和性别的基本模型相比,在模型识别方面有显著的改善。除了极少数例外,这些死亡预测在不同的亚人群中都是可靠的,特别是按年龄、民族、性别、教育和健康行为。最后,这个生物学年龄评价指标与疾病计数相关。这都充分证实所构建的生物学年龄评价方法对疾病和死亡具有预测效力,应用潜力巨大。
- 还没有人留言评论。精彩留言会获得点赞!