基于机器学习的原发性肝癌术后复发风险预测方法及系统与流程
本发明属于医学数据处理技术领域,尤其涉及一种基于机器学习的原发性肝癌术后复发风险预测方法及系统。
背景技术:
目前,原发性肝癌是目前世界上常见的恶性疾病之一,与其他肿瘤一样,手术切除应该是原发性肝癌患者的首选,与大多数恶性肿瘤不同,原发性肝癌患者的术后复发率较高且术后患者5年生存率很低。针对这种现状,探寻预后影响因素、制定个性化治疗措施是目前世界医学界的重大攻关课题之一。但由于患者数据中各影响因素对原发性肝癌术后复发预测的相关性较低,传统的数据处理模型对此类问题的评估准确度不高。
通过上述分析,现有技术存在的问题及缺陷为:传统的数据处理模型对原发性肝癌术后复发的评估准确度不高。
解决以上问题及缺陷的难度为:数据是非线性的,并且存在较多的缺失值;各影响因素对原发性肝癌术后复发预测的相关性较低。
解决以上问题及缺陷的意义为:可以显著提升原发性肝癌术后复发风险预测的准确度,以对患者采取对应的治疗措施。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于机器学习的原发性肝癌术后复发风险预测方法及系统。
本发明是这样实现的,一种基于机器学习的原发性肝癌术后复发风险预测方法,包括:
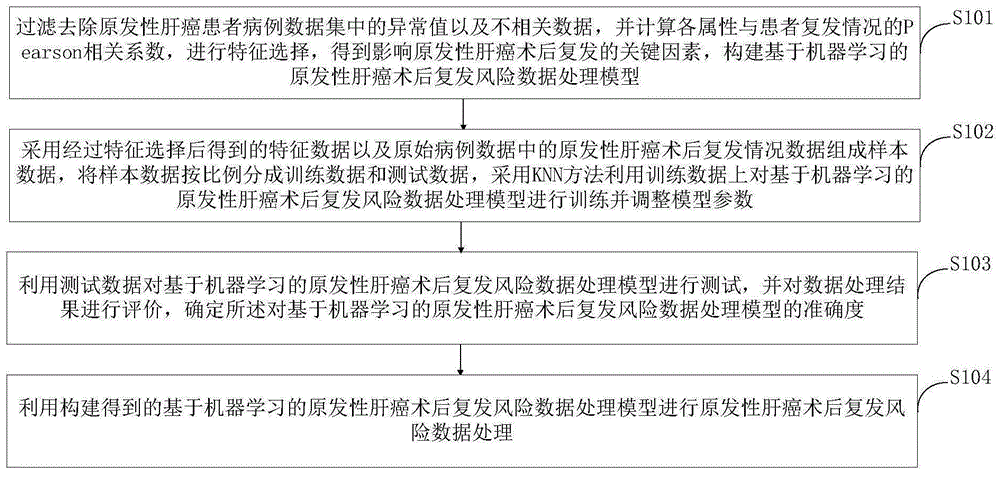
步骤一,过滤去除原发性肝癌患者病例数据集中的异常值以及不相关数据,并计算各属性与患者复发情况的pearson相关系数,进行特征选择,得到影响原发性肝癌术后复发的关键因素,构建基于机器学习的原发性肝癌术后复发风险数据处理模型;
步骤二,采用经过特征选择后得到的特征数据以及原始病例数据中的原发性肝癌术后复发情况数据组成样本数据,将样本数据按比例分成训练数据和测试数据,采用knn方法利用训练数据上对基于机器学习的原发性肝癌术后复发风险数据处理模型进行训练并调整模型参数;
步骤三,利用测试数据对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并对数据处理结果进行评价,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度;
步骤四,利用构建得到的基于机器学习的原发性肝癌术后复发风险数据处理模型进行原发性肝癌术后复发风险数据处理。
进一步,步骤一中,所述pearson相关系数计算方法公式为:
进一步,步骤二中,所述特征数据包括肿瘤大小、分化分级、是否有门脉癌栓、plt、afp、异常凝血酶、ast、wbc、和hbsag共9个属性。
进一步,所述步骤二包括:
训练数据与测试数据的比例为8:2,采用knn方法的k值为7,距离的度量方法为欧几里得距离;
所述利用knn方法进行训练并进行参数调整包括以下步骤:
(1)根据给定的距离度量,在训练集中找出与x最邻近的k个点,涵盖这k个点的x的邻域记作nk(x);
(2)在nk(x)中根据分类决策规则决定x的类别y:
其中i为指示函数,即当时i为1,否则i为0。
进一步,步骤三中,所述利用测试数据对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并对数据处理结果进行评价,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度包括:
1)采用训练后的knn预测方法利用测试数据对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并计算其tpr、tnr、fnr、fpr、精确率、准确率、拟合率作为评价指标;
2)以同样的方式训练并计算由朴素贝叶斯、决策树、logistic回归、深度神经网络及其他机器学习预测方法得到的数据,并与步骤1)得到的测试结果进行比较,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度。
本发明的另一目的在于提供一种实施所述基于机器学习的原发性肝癌术后复发风险预测方法的基于机器学习的基于机器学习的原发性肝癌术后复发风险预测系统,所述基于机器学习的术后复发风险数据处理系统包括:
数据预处理模块,用于过滤去除原发性肝癌患者病例数据集中的异常值以及不相关数据,并计算各属性与患者复发情况的pearson相关系数,进行特征选择,得到影响原发性肝癌术后复发的关键因素;
数据划分模块,用于将经过特征选择后得到的特征数据以及原始病例数据中的原发性肝癌术后复发情况数据组成样本数据,将样本数据按比例分成训练数据和测试数据;
模型构建模块,用于基于得到的关键因素进行原发性肝癌术后复发风险数据处理模型的构建;
模型训练以及参数调整模块,用于采用knn方法利用训练数据上对基于机器学习的原发性肝癌术后复发风险数据处理模型进行训练并调整模型参数;
模型评价模块,用于利用测试数据对对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并对数据处理结果进行评价,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度;
数据处理模块,用于利用构建得到的基于机器学习的原发性肝癌术后复发风险数据处理模型进行原发性肝癌术后复发风险数据处理。
本发明的另一目的在于提供一种接收用户输入程序存储介质,所存储的计算机程序使电子设备执行所述基于机器学习的原发性肝癌术后复发风险预测方法。
本发明的另一目的在于提供一种存储在计算机可读介质上的计算机程序产品,包括计算机可读程序,供于电子装置上执行时,提供用户输入接口以实施所述基于机器学习的原发性肝癌术后复发风险预测方法。
本发明的另一目的在于提供一种执行所述基于机器学习的原发性肝癌术后复发风险预测方法的计算机。
结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明采用基于knn的原发性肝癌术后复发风险数据处理方法,能达到相比于其他处理方法更好的预测效果。
本发明基于机器学习的原发性肝癌术后复发风险预测方法,通过计算每一属性与患者复发情况数据的pearson系数,可以筛选出对原发性肝癌术后复发情况影响较大的属性,采用基于knn的原发性肝癌术后复发风险预测方法,能达到相比于其他预测方法更好的预测效果。
附图说明
图1是本发明实施例提供的基于机器学习的原发性肝癌术后复发风险预测方法流程图。
图2是本发明实施例提供的基于机器学习的原发性肝癌术后复发风险预测方法原理图。
图3是本发明实施例提供的模型评价方法流程图。
图4是本发明实施例提供的基于机器学习的基于机器学习的原发性肝癌术后复发风险预测系统结构示意图。
图中:1、数据预处理模块;2、数据划分模块;3、模型构建模块;4、模型训练以及参数调整模块;5、模型评价模块;6、数据处理模块。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
针对现有技术存在的问题,本发明提供了一种基于机器学习的原发性肝癌术后复发风险预测方法及处理系统,下面结合附图对本发明作详细的描述。
如图1-图2所示,本发明实施例提供的基于机器学习的原发性肝癌术后复发风险预测方法包括:
s101,过滤去除原发性肝癌患者病例数据集中的异常值以及不相关数据,并计算各属性与患者复发情况的pearson相关系数,进行特征选择,得到影响原发性肝癌术后复发的关键因素,构建基于机器学习的原发性肝癌术后复发风险数据处理模型。
s102,采用经过特征选择后得到的特征数据以及原始病例数据中的原发性肝癌术后复发情况数据组成样本数据,将样本数据按比例分成训练数据和测试数据,采用knn方法利用训练数据上对基于机器学习的原发性肝癌术后复发风险数据处理模型进行训练并调整模型参数。
s103,利用测试数据对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并对数据处理结果进行评价,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度。
s104,利用构建得到的基于机器学习的原发性肝癌术后复发风险数据处理模型进行原发性肝癌术后复发风险数据处理。
步骤s101中,本发明实施例提供的pearson相关系数计算方法公式为:
步骤s102中,本发明实施例提供的特征数据包括肿瘤大小、分化分级、是否有门脉癌栓、plt、afp、异常凝血酶、ast、wbc、和hbsag共9个属性。
本发明实施例提供的步骤s102包括:
训练数据与测试数据的比例为8:2,采用knn方法的k值为7,距离的度量方法为欧几里得距离;
所述利用knn方法进行训练并进行参数调整包括以下步骤:
(1)根据给定的距离度量,在训练集中找出与x最邻近的k个点,涵盖这k个点的x的邻域记作nk(x);
(2)在nk(x)中根据分类决策规则决定x的类别y:
其中i为指示函数,即当时i为1,否则i为0。
如图3所示,步骤s103中,本发明实施例提供的利用测试数据对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并对数据处理结果进行评价,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度包括:
s201,采用训练后的knn预测方法利用测试数据对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并计算其tpr、tnr、fnr、fpr、精确率、准确率、拟合率作为评价指标;
s202,以同样的方式训练并计算由朴素贝叶斯、决策树、logistic回归、深度神经网络及其他机器学习预测方法得到的数据,并与步骤s201得到的测试结果进行比较,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度。
如图4所示,本发明实施例提供的基于机器学习的原发性肝癌术后复发风险预测系统包括:
数据预处理模块1,用于过滤去除原发性肝癌患者病例数据集中的异常值以及不相关数据,并计算各属性与患者复发情况的pearson相关系数,进行特征选择,得到影响原发性肝癌术后复发的关键因素;
数据划分模块2,用于将经过特征选择后得到的特征数据以及原始病例数据中的原发性肝癌术后复发情况数据组成样本数据,将样本数据按比例分成训练数据和测试数据;
模型构建模块3,用于基于得到的关键因素进行原发性肝癌术后复发风险数据处理模型的构建;
模型训练以及参数调整模块4,用于采用knn方法利用训练数据上对基于机器学习的原发性肝癌术后复发风险数据处理模型进行训练并调整模型参数;
模型评价模块5,用于利用测试数据对对基于机器学习的原发性肝癌术后复发风险数据处理模型进行测试,并对数据处理结果进行评价,确定所述对基于机器学习的原发性肝癌术后复发风险数据处理模型的准确度;
数据处理模块6,用于利用构建得到的基于机器学习的原发性肝癌术后复发风险数据处理模型进行原发性肝癌术后复发风险数据处理。
下面结合具体实施例对本发明的技术方案作进一步说明。
实施例1:
本发明实施例提供的一种基于机器学习的原发性肝癌术后复发风险预测方法,包括以下步骤:
s1去除原发性肝癌患者病例数据集中的异常值以及不相关数据,然后通过计算各属性与患者复发情况的pearson相关系数来进行特征选择,得到影响原发性肝癌术后复发的关键因素;
所述原发性肝癌患者病例数据集包括263例原发性肝癌患者病例,其中118例为复发病例,145例为未复发病例,数据集中每个病人的病理特征有63个,包括年龄、手术方式、肿瘤大小、afp、plt等。
首先对含有异常值以及不相关的数据进行剔除,剩余病例为220例,其中89例为复发病例,131例为未复发病例,剩余的病理特征有27个。
pearson相关系数是衡量线性关联性的程度,皮尔逊相关也称为积差相关(或积矩相关),是英国统计学家皮尔逊于20世纪提出的一种计算直线相关的方法。它用来衡量定距变量间的线性关系。其计算公式为:
医学上,许多症状和检查数据与疾病的轻重程度都有相互联系。本实施例通过计算pearson系数来评估每个病理特征与原发性肝癌患者术后是否复发之间的相关性。相关系数的绝对值越大则相关程度越大。本实施例计算剩余病例特征与原始病例数据中复发情况数据的pearson系数,并取相关性最大的9个属性作为训练数据的属性。
表1各个属性与原发性肝癌术后复发情况之间的pearson系数
s2采用经过特征选择后得到的特征数据以及原始病例数据中的肝癌术后复发情况数据组成样本数据,将样本数据按比例分成训练数据和测试数据,在训练数据上利用knn方法进行训练并调参;
经过处理得到相关性较高的病理特征数据包括肿瘤大小、分化分级、是否有门脉癌栓、plt、afp、异常凝血酶、ast、wbc、和hbsag等9个属性,训练数据与测试数据的比例为8:2,采用的knn方法的k值为7,距离的度量方法为欧几里得距离。
knn方法的具体过程为:
(1)根据给定的距离度量,在训练集中找出与x最邻近的k个点,涵盖这k个点的x的邻域记作nk(x);
(2)在nk(x)中根据分类决策规则决定x的类别y:
其中i为指示函数,即当时i为1,否则i为0。
本实施例的knn方法采用的距离度量方式为欧几里得度量,也被称为欧式距离。设特征空间x是n维实数向量空间rn,
s3在测试数据上对训练后得到的knn预测方法进行测试,得到一种基于机器学习的原发性肝癌术后复发风险预测方法,最后与其他预测方法进行比较以说明该方法拥有更高的准确度。
具体方法如下:利用训练后的knn预测方法在测试数据上进行测试,并计算其tpr、tnr、fnr、fpr、精确率、准确率、拟合率作为其评价指标,并以同样的方式训练并计算由其他机器学习预测方法得到的这些数据,包括朴素贝叶斯、决策树、logistic回归、深度神经网络等方法,与knn方法的预测结果进行比较,以说明knn方法在预测原发性肝癌术后复发风险上的预测效果优于其他预测方法。每种分类方法的各项结果都在相同的数据集下进行了5次测试并取平均值。
表2采用knn、朴素贝叶斯、决策树、logistic回归、深度神经网络方法分类的结果
根据以上表格数据,本实施例所采用的knn方法拥有相比于其他方法更高的准确率和精确率,准确率达到了0.706,精确率达到了0.701,而其他方法的这两项指标均未超过0.7;该方法在tpr、tnr、fnr、fpr等评价指标上同样有着良好的表现,其中tpr和tnr高于多数其他方法的值,fnr和fpr也低于多数其他方法的值,tpr达到了0.519,fnr为0.485,这两项指标上knn方法仅次于logistic回归,tnr达到了0.893,fpr为0.160,这两项指标上knn方法仅次于朴素贝叶斯;该方法在拟合率上的表现则稍显逊色,但也基本达到了该指标的平均水平。综合来看,实验结果说明了本实施例所采用的knn方法在预测原发性肝癌术后复发情况上的预测效果优于其他预测方法。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本发明可借助软件加必需的硬件平台的方式来实现,当然也可以全部通过硬件来实施。基于这样的理解,本发明的技术方案对背景技术做出贡献的全部或者部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!