一种基于血红蛋白浓度分析预测系统及其设备的制作方法
本发明涉及大数据分析技术领域,尤其涉及一种基于血红蛋白浓度分析预测系统及其设备。
背景技术:
人体血红蛋白的正常参考值是成人100-160g/l,青少年110-160g/l。血红蛋白检测是血常规检查和血液流变学检查的项目,可以用于贫血的鉴别、营养状况判断等。传统的血红蛋白检测需要离体检测,即获取人血样后采用多组化学试剂进行测定,效率较低。许多检测时需要无创进行血红蛋白检测,手术时需要连续检测血红蛋白水平,因此传统的离体检测无法在需要连续检测血红蛋白的场合使用,无需试剂、无创的进行血红蛋白水平的实时检测或者实时预测是非常必要的。
机器学习可以根据合理预设的模型,结合对上述大量采集的训练数据进行迭代学习,必然能够进行精确、快速及无创的预测,满足血红蛋白实时预测的需要。
技术实现要素:
有鉴于此,本发明提出了一种能够对血红蛋白浓度进行合理预测、挑选合适输出结果的基于血红蛋白浓度分析预测系统及其设备。
本发明的技术方案是这样实现的:
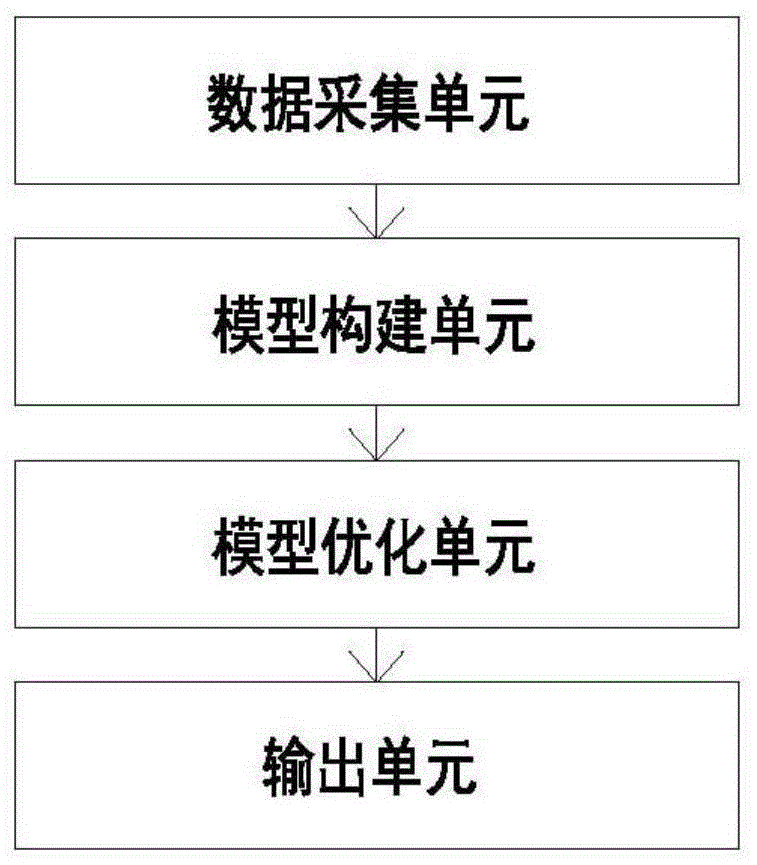
一方面,本发明提供了一种基于血红蛋白浓度分析预测系统,包括数据采集单元、模型构建单元、模型优化单元和输出单元,输出采集单元的输出端与模型构建单元的输入端信号连接;模型构建单元的输出端与模型优化单元的输入端信号连接,模型优化单元的输出端与输出单元信号连接;
数据采集单元,采用无创nir光谱检测待测人员的在体血样本,获取在体血样本对近红外光的吸收光谱和化学值浓度,并构建相应的矩阵;
模型构建单元,根据获取的在体血样本对近红外光的吸收光谱和化学值浓度的矩阵,构建样本库,并利用样本库的参数建立最小二乘pls模型;
模型优化单元,对建立的偏最小二乘pls模型的参数进行遍历,评价并选取最优的局部最小二乘pls模型;
输出单元,输出相应的血红蛋白浓度预测结果。
在以上技术方案的基础上,优选的,所述获取的在体血样本对近红外光的吸收光谱和化学值浓度并构建相应的矩阵,是获取各待测人员在体血样本对近红外光的吸收光谱构建的矩阵x和对应的各待测人员在体血样本的化学值浓度矩阵y后,对构建的吸收光谱矩阵x和化学浓度矩阵y分解:y=uq+f;x=tp+e;其中u和t分别是化学浓度矩阵y和吸收光谱矩阵x的得分矩阵;q和p分别是化学浓度矩阵y和吸收光谱矩阵x的荷载矩阵;f和e为建立偏最小二乘pls模型拟合化学浓度矩阵y和吸收光谱矩阵x引入的误差;对得分矩阵u和t进行线性回归,得到关联矩阵b,b=(ttt-1)ttu;样本的预测值模型为:y*=t*bq;y*和t*分别是待预测样本的化学浓度矩阵和吸收光谱矩阵的得分矩阵;通过吸收光谱矩阵x、化学浓度矩阵y和待预测样本的化学浓度矩阵y*构建样本库。
进一步优选的,所述利用样本库的参数建立偏最小二乘pls模型,是设定起点波长i、波长个数n、波长间隔g和pls因子数f,将近红外光的吸收光谱的波长范围进行分割,设定吸收光谱的波长范围内总波长个数为n*,波长个数n=[0,n*],在吸收光谱的波长范围内找到满足i+(n-1)g≤n*的所有组合并结合对应的pls因子数f,构建四参数集合(i,n,g,f);对每一个四参数集合分别构建偏最小二乘pls模型。
更进一步优选的,所述评价并选取最优的局部最小二乘pls模型,是采用局部最优模型根据建模预测均方根误差rmsepm评价:
局部最优模型根据固定的参数不同分为:起点波长i固定的局部最优模型、波长个数n固定的局部最优模型和波长间隔g固定的局部最优模型:
分别对上述三个最优模型进行建模预测均方根误差rmsepm评价,筛选得到所有的符合条件的四参数集合(i,n,g,f)的组合及其对应的局部最优模型。
再进一步优选的,所述筛选得到所有的符合条件的四参数集合(i,n,g,f)的组合及其对应的局部最优模型,是选择同时满足i∈(700,980);n∈(50,100);g∈(2,10)以及f∈(3,10)的局部最优模型。
更进一步的优选的,所述输出单元输出相应的血红蛋白浓度预测结果,是基于多元回归分析预测,构建线性评价组合f(x)=w1i+w2n+w3g+w4f+b1+b2;其中w1、w2、w3和w4分别为四参数集合(i,n,g,f)内各参数对应的权重,b1是海拔调整项,b2是基础状况调整项。
另一方面,本发明还提供了一种实现基于血红蛋白浓度分析预测系统的设备,包括至少一个处理器和存储器,所述处理器接收无创nir光谱检测待测人员的在体血样本,获取在体血样本对近红外光的吸收光谱和化学值浓度的数据,并实现上述的数据采集单元、模型构建单元、模型优化单元和输出单元的功能,并将输出的血红蛋白浓度预测结果发送至存储器中进行保存。
本发明提供的一种基于血红蛋白浓度分析预测系统及其设备,相对于现有技术,具有以下有益效果:
(1)本发明采用无创的获取近红外nir光谱,基于样本建立筛选模型和模型参数,不断优化和筛选局部最优的模型,结合海拔变化和样本的基础情况,输出较可信的血红蛋白值的预测结果,实时性好;
(2)样本库可根据需要分为预计集和验证集,进一步对预测结果进行对比,提高预测结果的可靠性;
(3)采用局部最优方式预测,并采用预测均方根误差评价预测的可信度,提高预测结果的准确度;
(4)合理选择参数范围,有利于筛选局部最优的模型及其预测结果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种基于血红蛋白浓度分析预测系统及其设备的系统框图。
具体实施方式
下面将结合本发明实施方式,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
如图1所示,一方面,本发明提供了一种基于血红蛋白浓度分析预测系统,包括数据采集单元、模型构建单元、模型优化单元和输出单元,输出采集单元的输出端与模型构建单元的输入端信号连接;模型构建单元的输出端与模型优化单元的输入端信号连接,模型优化单元的输出端与输出单元信号连接;
数据采集单元,采用无创nir光谱检测待测人员的在体血样本,获取在体血样本对近红外光的吸收光谱和化学值浓度,并构建相应的矩阵;相比传统试剂检测方法,采用无创手段检测,如舌诊、无创静脉照射等,获取检测结果更迅速。
模型构建单元,根据获取的在体血样本对近红外光的吸收光谱和化学值浓度的矩阵,构建样本库,并利用样本库的参数建立最小二乘pls模型;样本库可以根据需要分隔为试验集和验证集,通常将部分历史数据作为验证集,待检测样本结合其余历史样本作为试验集;
上述获取的在体血样本对近红外光的吸收光谱和化学值浓度并构建相应的矩阵,是获取各待测人员在体血样本对近红外光的吸收光谱构建的矩阵x和对应的各待测人员在体血样本的化学值浓度矩阵y后,对构建的吸收光谱矩阵x和化学浓度矩阵y分解:y=uq+f;x=tp+e;其中u和t分别是化学浓度矩阵y和吸收光谱矩阵x的得分矩阵;q和p分别是化学浓度矩阵y和吸收光谱矩阵x的荷载矩阵;f和e为建立偏最小二乘pls模型拟合化学浓度矩阵y和吸收光谱矩阵x引入的误差;对得分矩阵u和t进行线性回归,得到关联矩阵b,b=(ttt-1)ttu;样本的预测值模型为:y*=t*bq;y*和t*分别是待预测样本的化学浓度矩阵和吸收光谱矩阵的得分矩阵;通过吸收光谱矩阵x、化学浓度矩阵y和待预测样本的化学浓度矩阵y*构建样本库。光谱矩阵x是对应无创nir光谱检测的吸收光谱数值对应的矩阵;化学浓度矩阵y是确切获取具体血红蛋白浓度的在体血样本的血红蛋白浓度,待预测样本的化学浓度矩阵y*的结果是预估值,是未知的。
上述利用样本库的参数建立偏最小二乘pls模型,是设定起点波长i、波长个数n、波长间隔g和pls因子数f,将近红外光的吸收光谱的波长范围进行分割,设定吸收光谱的波长范围内总波长个数为n*,波长个数n=[0,n*],在吸收光谱的波长范围内找到满足i+(n-1)g≤n*的所有组合并结合对应的pls因子数f,构建四参数集合(i,n,g,f);对每一个四参数集合分别构建偏最小二乘pls模型。
模型优化单元,对建立的偏最小二乘pls模型的参数进行遍历,评价并选取最优的局部最小二乘pls模型;
其中,评价并选取最优的局部最小二乘pls模型,是采用局部最优模型根据建模预测均方根误差rmsepm评价:
局部最优模型根据固定的参数不同分为:起点波长i固定的局部最优模型、波长个数n固定的局部最优模型和波长间隔g固定的局部最优模型:
分别对上述三个最优模型进行建模预测均方根误差rmsepm评价,筛选得到所有的符合条件的四参数集合(i,n,g,f)的组合及其对应的局部最优模型:
选择同时满足i∈(700,980);n∈(50,100);g∈(2,10)以及f∈(3,10)的局部最优模型。该最优模型对应的血红蛋白浓度预测结果存入样本库中,作为新的样本。
输出单元,输出相应的血红蛋白浓度预测结果,是基于多元回归分析预测,构建线性评价组合f(x)=w1i+w2n+w3g+w4f+b1+b2;其中w1、w2、w3和w4分别为四参数集合(i,n,g,f)内各参数对应的权重,b1是海拔调整项,b2是基础状况调整项。海拔调整项b1是基于海拔升高1000米,血红蛋白升高4%作为调整,是基于前四项的计算结果;基础状况调整项b2是检测对象是否有血液相关基础疾病,如凝血症、血友病、贫血、铁营养不良或者甲亢等,是单独计算的变量,实际数据还可根据失血、输血等情况进一步调整。
另外,本发明还提供了一种实现基于血红蛋白浓度分析预测系统的设备,包括至少一个处理器和存储器,所述处理器接收无创nir光谱检测待测人员的在体血样本,获取在体血样本对近红外光的吸收光谱和化学值浓度的数据,并实现上述的数据采集单元、模型构建单元、模型优化单元和输出单元的功能,并将输出的血红蛋白浓度预测结果发送至存储器中进行保存。
以上所述仅为本发明的较佳实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!