一种基于多任务学习的用户反馈分析方法与流程
1.本发明属于医院流程优化技术领域,尤其涉及一种基于多任务学习的用户反馈分析方法。
背景技术:
2.目前,医院一般依靠大数据、人工智能等“互联网+”应用手段,通过开发医院流程化系统提高医院内部管理水平,不断提升医疗服务水平。
3.任何应用、系统从研发到投入线上运行都需要一段“磨合期”,开发人员主要解决功能能否实现,而用户是最有资格说明功能是否实用,使用是否“顺手”。收集用户的使用反馈,指导开发人员有针对性地对系统持续优化升级,可以提高医疗门诊效率,提升用户满意度。
4.现有技术中将收集到的用户反馈信息按是否满意进行分类,由于多数大型的三甲医院人流量大,若采用人工分类耗时耗力且效率不高。采用直接以数字的形式打分进行对系统的评价,无法指导改进方案。
技术实现要素:
5.本发明的目的是提供一种基于多任务学习的用户反馈分析方法,使用多任务联合训练框架,对评论文本进行定义抽取和词粒度bio标注两项任务进行联合建模,通过增强推理bert对实体关系进行分类,加上规则辅助对关系抽取任务进行预测,分析用户对流程优化产品的反馈信息,以指导产品后续持续的优化升级,不断提升医疗服务水平。
6.本发明提供了一种基于多任务学习的用户反馈分析方法,包括:
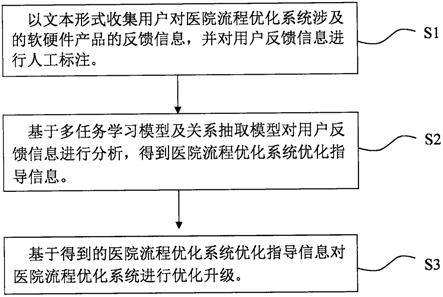
7.步骤1,以文本形式收集用户对医院流程优化系统涉及的软硬件产品的反馈信息,并对用户反馈信息进行人工标注;
8.步骤2,基于多任务学习模型及关系抽取模型对用户反馈信息进行分析,得到医院流程优化系统优化指导信息;
9.步骤3,基于得到的医院流程优化系统优化指导信息对医院流程优化系统进行优化升级。
10.进一步地,步骤1中所述反馈信息通过爬虫程序或后台接口直接读取,并存储于数据库。
11.进一步地,所述步骤2包括:
12.基于多任务学习模型进行联合学习,将联合学习得到的结果使用关系抽取模型进行关系抽取,通过模型融合得到最终用户反馈信息,对得到的最终用户反馈信息进程筛选排查,得到有用的系统优化指导信息。
13.进一步地,所述步骤2包括:
14.在对用户反馈信息进行分析之前通过语料清洗、分词、去除停用词操作对用户反馈信息进行数据预处理。
15.进一步地,步骤2中所述多任务学习模型包括:
16.文本分类模型,用于句子分类,用以判断某句子中是否有新的定义,作为任务1;
17.词粒度bio标签预测模型,用于序列标注,作为任务2;
18.所述关系抽取模型,用于关系抽取,作为任务3。
19.进一步地,所述步骤2还包括:
20.对多任务学习模型采用先训练任务2,再训练任务1,交替训练的方法进行模型训练。
21.进一步地,步骤2中所述关系抽取模型采用增强推理bert模型。
22.借由上述方案,通过基于多任务学习的用户反馈分析方法,分析用户对医院流程优化相关产品的反馈评价,评估软硬件产品的用户满意度,可供后续有方向性的优化升级相应产品,提升用户体验。
23.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例详细说明如后。
附图说明
24.图1是本发明基于多任务学习的用户反馈分析方法的流程图;
25.图2是本发明系统模块架构示意图;
26.图3是本发明模型训练流程图;
27.图4是本发明数据处理流程图;
28.图5是本发明bert结构图;
29.图6是本发明5折交叉示意图;
具体实施方式
30.下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但是不用来限制本发明的范围。
31.参图1所示,本实施例提供了一种基于多任务学习的用户反馈分析方法,包括:
32.步骤s1,以文本形式收集用户对医院流程优化系统涉及的软硬件产品的反馈信息,并对用户反馈信息进行人工标注;
33.步骤s2,基于多任务学习模型及关系抽取模型对用户反馈信息进行分析,得到医院流程优化系统优化指导信息;
34.步骤s3,基于得到的医院流程优化系统优化指导信息对医院流程优化系统进行优化升级。
35.通过该基于多任务学习的用户反馈分析方法,分析用户对医院流程优化相关产品的反馈评价,评估软硬件产品的用户满意度,可供后续有方向性的优化升级相应产品,提升用户体验。
36.在本实施例中,步骤s1中所述反馈信息通过爬虫程序或后台接口直接读取,并存储于数据库。
37.在本实施例中,步骤s2包括:
38.基于多任务学习模型进行联合学习,将联合学习得到的结果使用关系抽取模型进
行关系抽取,通过模型融合得到最终用户反馈信息,对得到的最终用户反馈信息进程筛选排查,得到有用的系统优化指导信息。
39.在本实施例中,步骤s2包括:
40.在对用户反馈信息进行分析之前通过语料清洗、分词、去除停用词操作对用户反馈信息进行数据预处理。
41.在本实施例中,步骤s2中所述多任务学习模型包括:
42.文本分类模型,用于句子分类,用以判断某句子中是否有新的定义,作为任务1;
43.词粒度bio标签预测模型,用于序列标注,作为任务2;
44.所述关系抽取模型,用于关系抽取,作为任务3。
45.在本实施例中,步骤s2还包括:
46.对多任务学习模型采用先训练任务2,再训练任务1,交替训练的方法进行模型训练。
47.在本实施例中,步骤s2中所述关系抽取模型采用增强推理bert模型。
48.下面对本发明作进一步详细说明。
49.本实施例对用户在医院内对使用流程优化产品包括软硬件以及整体系统的使用体验的评论作情感倾向性分类,即好评或差评;通过对分类结果的统筹分析用户整体满意度,并对负反馈率最高的评论作关键词摘取作为后续的改进方向。
50.参图2所示,本发明在具体应用中,整体可以分为4个模块:产品模块、数据收集模块、数据分析模块、调试模块。其中,产品模块即医院流程优化系统涉及的各种软硬件产品,从中可收集到用户的评价反馈;数据收集模块主要负责数据的收集,可通过爬虫程序或后台接口直接读取,并存储于数据库;数据分析模块是核心模块利用数据处理、特征工程、建模等技术分析用户对系统的使用满意度,同时可以从中挖掘用户指出的系统哪些地方值得改进等信息;调试模块是由开发人员通过数据分析的结果制订合理的优化策略,再对系统进行进一步的优化升级。
51.参图3所示,反馈文本信息的数据分析流程如下:
52.原始数据无法直接作为特征输入模型进行训练,需要先进行预处理,原因有以下几点:1)采集到的文本数据可能格式不规范,同时也可能存在无效字符,需要进行过滤;2)用户评论通常会比较口语化,比较“不规范”,一些语气助词的存在会使得同一个意思有多种表述方式,不够简洁;3)不管是机器学习还是深度学习本质上都是对数字的建模,而无法对字符(单词)建模,因此需要先将单词映射到向量空间里,并用向量来表示,即词嵌入技术。
53.数据预处理的具体操作实现包括:语料清洗、分词、去除停用词。
54.语料清洗:1)后台采集到的数据可能是标签、html等格式,需要先将其格式规范化,结合正则表达式,提取纯文本内容;2)对于重复的评论需要删除;3)获取表情符号,具有情感色彩的标点符号组合(例如连续的感叹号和问好都具有加强语气的效果,区别与常规文本分类方法直接删除标点)以及常用特殊单词(具有明显情感色彩)组成情绪符号库;4)分行的文本进行合并,过长的文本进行截选,过短的文本直接过滤出(为空的直接删除,短文本过滤出可单独处理)。
55.分词:使用jieba分词工具进行分词。
56.去停用词:将文本分词后与指定的停用词词库(包括一些无效的词或者符号)比较,过滤停用词。
57.建模前需要先对一部分数据进行人工标注,作为训练数据集,数据格式如下:
58.token是句子里的词;
59.source标识当前句子来源于第几个评论;
60.start/end是词在评论中的起始位置;
61.tag初步分词后的标签,符合bio标注格式,其中definition表示新定义的命名实体,term表示简单的实体,o表示其他;
62.tag_id是tag标签的一个唯一标识,如果o标签则为-1;
63.relation是主谓宾的标签,其中s表示主语,p表示谓语,o表示宾语,d表示形容词,a表示副词。
[0064][0065]
任务1判断一句话是否包含定义,任务2已知前四列信息,预测第五列tag,作为任务3已知前六列信息,预测关系。
[0066]
各任务的评估方法如下:
[0067]
任务1:句子分类,用准确率,召回率和f1值进行评估;
[0068]
任务2:序列标注,用准确率,召回率和f1值进行评估以及所有类别的整体macro-andmicro-averaged f1(宏平均和微平均的加权f1)进行评估;
[0069]
任务3:关系抽取,用准确率,召回率和f1值进行评估以及所有类别的整体macro-andmicro-averaged f1进行评估;
[0070]
其中macro-andmicro-averaged f1是指分别计算每个类别的f1,然后做平均(各类别f1的权重相同)
[0071]
以上多个任务存在较强的关联性,任务2中如果预测出一些单词为definition(即新定义的命名实体),则对应句子在任务1中应属于正样本。为解决传统方法的累积误差,本实施例引入多任务联合学习框架。在建模过程中采用hard parameter sharing的方式,区别于soft parameter sharing,定义抽取任务和序列标注任务共享一个shared layer(共享层)用以学习句子单词通用的表达,然后不同的任务各自有自己的task specific layer(任务单独执行层)。
[0072]
其中,shared layer用bert预训练模型,学习句子的通用表示;task specific layer为分类任务(定义抽取)接mlp(全连接层),词粒度标注任务接crf(conditional random field,条件随机场);序列标注任务的输入可以是单句或者段落。
[0073]
关于损失函数,定义如下:
[0074]
词粒度标签预测得分:
[0075][0076]
其中,是第i个单词标签tag的概率,是crf里转移矩阵标签到的概率,序列标注的损失函数为最大路径得分除以所有路径得分再取log的负数。
[0077]
softmax归一化:
[0078][0079]
其中,s(x,y)即词粒度标签预测得分。
[0080]
word level bio tag(即上诉的序列标注的损失函数)损失函数:
[0081][0082]
分类任务损失函数:
[0083]
l
de
=-α*(1-p
t
)
γ
*y*log(p
t
)-(1-α)*(p
t
)
γ
*(1-y)*log(1-p
t
)
[0084]
其中,p
t
即上式中的p(y_tag|x),y是正确标签,是预测概率,本实施例在交叉熵的基础上增加了两个超参数,用来控制正负样本的权重和容易分类样本对整体损失贡献的权重。当样本为正的时候,标签y=1,损失函数第二项((1-α)*(p
t
)
γ
*(1-y)*log(1-p
t
))为0,α的大小控制着正样本的权重,α越大,把正样本分错产生的损失也越大。当一个正样本比较容易分类,预测值会非常接近1,当γ越大的时候,容易分类样本贡献的损失也会越小,难分类样本贡献的损失会越大。
[0085]
联合训练损失函数:
[0086][0087]
其中σ和τ是权重系数,属于超参。
[0088]
训练过程本实施例采用先训练任务2,再训练任务1,交替训练的方法,在训练两个中任何一个任务时,共享层的参数都会改变。为解决训练数据不足,本实施例引入pseudo-label的技巧,但控制数量占比不超过有标签数据的十分之一。所谓pseudo-label,就是先用有标签数据训练一个模型,然后预测无标签数据,将概率较高的无标签数据打上伪标签,然后加入到训练数据中重新训练模型。计算联合loss(损失函数),保存中间结果对应的模型,并打印macro-andmicro-averaged f1。
[0089]
本实施例使用增强推理bert模型对关系进行抽取。模型输入两个实体,其中词向量取bert最后四层hidden states的token embedding求平均。计算两个实体之间单词的attention,然后通过textb里词向量乘以一个归一化参数得到texta的交互表达,同样的方式得到textb的交互表达,最后通过差积,点积等操作,经过mlp,softmax层输出关系label。
[0090]
参图4所示,共享层share layer包括词嵌入、预训练模型、输出向量,其中预训练模型可采样bert、xlm-roberta等多种模型,本实施例采用bert预训练模型,如图5所示,其中e表示词嵌入,t表示输出向量,trm是bert时序展开的单元结构,词嵌入作为预训练模型
的输入又分为3部分:position embedding(位置信息)、token embedding(词向量)、segment embedding(所属句子信息),输出向量是预训练模型的输出(向量化表示不同文本的信息),同时也作为下一步mlp和crf模型的输入,可得到两个不同的损失函数包括分类损失和序列标注损失,即上述提到的l
de
和l
tag
,两者加权作为最终的损失输出loss-total,五折交叉验证得到5个预测结果,模型融合方面,如图6所示,每次训练时,将数据集划分为5块,其中4块(learn)用于训练,一块用于预测(predict),预测得到的predications也可视为融合模型的特征,最后采用hard voting的方式输出结果。
[0091]
模型融合之后,本实施例辅助一些实体纠正规则,用来解决一些嵌套ner(named entity recognition,命名实体识别),一词多tag的情况。
[0092]
本发明结合人工智能技术中的nlp技术针对医院流程优化这一特殊领域,提出了一种系统用户反馈分析方法,可辅助系统优化升级。为解决传统方法的累积误差,本发明引入多任务联合学习框架。同时实现隐式数据增强,更通用的文本表达以及特征选择双重检验的效果。最后将联合学习得到的结果使用多模型进行关系抽取,通过模型融合得到最终的用户反馈信息。对得到的反馈信息进程筛选排查,获得有用的系统优化指导信息,从而针对性的对系统加以优化改进。
[0093]
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1