制备基于艾日布林的抗体-药物缀合物的方法与流程
68[非专利文献5]christoph et al.(2014)clin.lung cancer15(5):320-30[非专利文献6]king et al.(1985)science 229:974-6[非专利文献7]slamon et al.(1989)science 244:707-12[非专利文献8]gajria and chandarlapaty(2011)expert rev.anticancer ther.11:263-75[非专利文献9]o’shannessy et al.,(2011)oncotarget 2:1227-43
技术实现要素:
技术问题
[0008]
本发明的目的是提供一种以高产率制备抗体-药物缀合物的方法和可用于该方法的合成中间体。问题的解决方案
[0009]
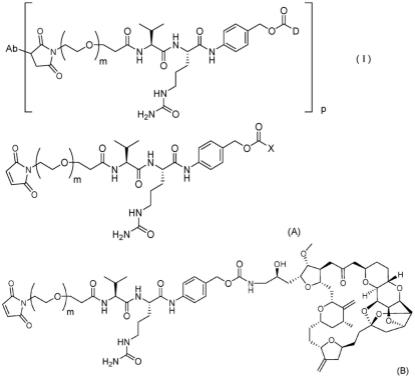
本发明提供了以下[1]至[8]。[1]一种制备式(i)所示的抗体-药物缀合物的方法,在该式中,ab为抗体或其抗原结合片段,d为艾日布林,m为1至10的整数,并且p为1至8的整数,该方法包括:步骤1:通过艾日布林或其盐与式(a)所示的化合物的反应获得式(b)所示的化合物,在该式中,m为1至10的整数,并且x为苯氧基或硝基苯氧基,并且
在该式中,m为1至10的整数,和步骤2:通过式(b)所示的化合物与ab的反应获得式(i)所示的抗体-药物缀合物。[2]根据[1]所述的方法,其中ab包含(i)包含seq id no:1所示的氨基酸序列的重链结构域和包含seq id no:6所示的氨基酸序列的轻链结构域,(ii)包含seq id no:23所示的氨基酸序列的重链可变结构域和包含seq id no:24所示的氨基酸序列的轻链可变结构域,(iii)包含seq id no:27所示的氨基酸序列的重链可变结构域和包含seq id no:28所示的氨基酸序列的轻链可变结构域,或(iv)包含seq id no:347所示的氨基酸序列的重链结构域和包含seq id no:308所示的氨基酸序列的轻链结构域。[3]根据[1]或[2]所述的方法,其中p为3或4。[4]根据[1]至[3]中任一项所述的方法,其中艾日布林或其盐为艾日布林甲磺酸盐。[5]根据[1]至[4]中任一项所述的方法,其中步骤1在碱存在下进行。[6]一种制备式(b)所示的化合物的方法,在该式中,m为1至10的整数,该方法包括:通过艾日布林或其盐与式(a)所示的化合物的反应获得式(b)所示的化合物的步骤,在该式中,m为1至10的整数,并且x为苯氧基或硝基苯氧基。
[7]根据[6]所述的方法,其中该步骤在碱存在下进行。[8]一种式(a)所示的化合物,在该式中,m为1至10的整数,并且x为苯氧基或硝基苯氧基。本发明的有益效果
[0010]
本发明可提供一种以高产率制备抗体-药物缀合物的方法。此外,本发明还可提供一种合成中间体,其可用于以高产率制备抗体-药物缀合物。
具体实施方式
[0011]
下文将详细地描述本发明的实施例。
[0012]
本发明的实施例涉及一种制备式(i)所示抗体-药物缀合物的方法。
[0013]
首先,将描述式(i)所示的adc。
[0014]
adc可结合、内化并杀死肿瘤细胞(例如,表达fra的肿瘤细胞)。此外,优选的是,在adc中使用的抗体部分(ab)为抗体或其抗原结合片段且靶向肿瘤细胞。抗体或抗原结合片段包含,例如:(a)由kabat编号系统(kabat,sequences of proteins of immunological interest[具有免疫学重要性的蛋白序列](美国马里兰州贝塞斯达的美国国立卫生研究院(national institutes of health,bethesda,md.)(1987和1991)))定义的三个重链cdr和三个轻链cdr,该三个重链cdr包含seq id no:2所示的重链互补决定区(重链cdr)1、seq id no:3所示的重链cdr2和seq id no:4所示的重链cdr3的氨基酸序列,并且该三个轻链cdr包含seq id no:7所示的轻链互补决定区(轻链cdr)1、seq id no:8所示的轻链cdr2和seq id no:9所示的轻链cdr3的氨基酸序列;或(b)由imgt编号系统(国际免疫遗传学信息系统(international immunogenetics information system,imgt)(注册商品名))定义的三个重链cdr和三个轻链cdr,该三个重链cdr包含seq id no:13所示的重链cdr1、seq id no:14所示的重链cdr2和seq id no:15所示的重链cdr3的氨基酸序列,并且该三个轻链cdr包含seq id no:16所示的轻链cdr1、seq id no:17所示的轻链cdr2和seq id no:18所示的轻链cdr3的氨基酸序列。
[0015]
在本说明书中,术语“抗体-药物缀合物”、“抗体缀合物”、“缀合物”、“免疫缀合物”和“adc”可互换使用,指的是与抗体(例如,抗fra抗体)连接的并且由式(i)[在该式中,ab为抗体部分(即,抗体或其抗原结合片段),l为接头部分,d为艾日布林,并且p为每个抗体部分上的艾日布林部分的数量]定义的化合物或其衍生物。
[0016]
术语“抗体”在最广泛意义上用于指经由免疫球蛋白分子的可变结构域内的至少一个抗原识别位点识别且特异性结合如蛋白质、多肽、碳水化合物、多核苷酸、脂质或前述
物质的组合等的靶标的免疫球蛋白分子。抗体的重链由重链可变结构域(vh)及重链恒定结构域(ch)构成。抗体的轻链由轻链可变结构域(v
l
)及轻链恒定结构域(c
l
)构成。出于本技术的目的,成熟的重链可变结构域和轻链可变结构域各自包含从n-末端至c-末端排列的四个框架区(fr1、fr2、fr3和fr4)内的三个互补决定区(cdr1、cdr2和cdr3):fr1、cdr1、fr2、cdr2、fr3、cdr3和fr4。“抗体”可为天然存在的或人造的,如通过常规杂交瘤技术产生的单克隆抗体。术语“抗体”包括全长单克隆抗体、全长多克隆抗体和单链抗体。此外,抗体的抗原结合片段的实例包括fab、fab'、f(ab')2和fv。抗体可以是免疫球蛋白的五种主要类别中的任一种:iga、igd、ige、igg、以及igm,或其亚类(例如,同种型igg1、igg2、igg3、igg4)。该术语进一步涵盖人抗体、嵌合抗体、人源化抗体及任何含有抗原识别位点的经修饰的免疫球蛋白分子,只要其展现所需生物活性即可。
[0017]
如本文所用的,术语“单克隆抗体”是指自实质上均质的抗体群体获得的抗体,即,除了可能少量存在的可能的天然存在的突变之外,构成该群体的各个抗体为相同的。单克隆抗体针对单个抗原表位具有高度特异性。相反,常规的(多克隆)抗体制剂典型地包括针对不同表位或对其具有特异性的多种抗体。修饰语“单克隆”表示从实质上均质的抗体群体获得的抗体的特征,而不应解释为要求通过任何特定方法制备抗体。例如,将根据本披露使用的单克隆抗体可通过首先由kohler等人(1975)nature[自然]256:495描述的杂交瘤方法来制造,或可通过重组dna方法(例如,参见,美国专利号4,816,567)来制造。单克隆抗体还可使用例如clackson等人(1991)nature[自然]352:624-8以及marks等人(1991)j.mol.biol.[分子生物学杂志]222:581-97中所述的技术自噬菌体抗体文库分离。
[0018]
本文所述的单克隆抗体具体地包括“嵌合”抗体(其中重链和/或轻链的一部分与来源于特定物种或属于特定抗体类别或子类别的抗体中的对应序列相同或同源,而链的其余部分与来源于另一物种或属于另一抗体类别或子类别的抗体中的对应序列相同或同源),以及此类抗体的片段;只要它们特异性结合靶抗原和/或表现出所需的生物学活性。
[0019]
术语“同源物”是指因例如在对应位置处具有相同或相似的化学残基的序列而展现与另一分子的同源性的分子。
[0020]
如本文所用的,术语“人抗体”是指由人类产生的抗体或具有由人类产生的抗体的氨基酸序列的抗体。
[0021]
如本文所用的,术语“嵌合抗体”是指其中免疫球蛋白分子的氨基酸序列来源于两个或更多个物种的抗体。在一些情况下,重链及轻链两者的可变结构域对应于来源于具有所需特异性、亲和力及活性的一个物种的抗体的可变结构域,而恒定区与来源于另一物种(例如人)的抗体同源以使后一物种中的免疫反应减至最少。
[0022]
如本文所用的,术语“人源化抗体”是指含有来自非人(例如鼠)抗体以及人类抗体的序列的抗体形式。此类抗体为含有来源于非人免疫球蛋白的最小序列的嵌合抗体。一般而言,人源化抗体包含至少一个且典型地两个可变结构域的实质上全部,其中全部或实质上全部高变环对应于非人免疫球蛋白的高变环且全部或实质上全部框架(fr)区为人免疫球蛋白序列的框架区。人源化抗体任选地还包含免疫球蛋白恒定区(fc)的至少一部分,典型地包含人免疫球蛋白的恒定区(fc)。人源化抗体可通过fv框架区中和/或所替换的非人残基内残基的取代而进一步修饰,以改进及优化抗体特异性、亲和力和/或活性。
[0023]
如本文所用的,术语抗体的“抗原结合片段”是指保留特异性结合抗原(例如,fra)
的能力的一个或多个抗体片段。抗原结合片段优选地还保留内化至表达抗原的细胞中的能力。在一些实施例中,抗原结合片段还保留免疫效应子活性。已证明全长抗体的片段可执行全长抗体的抗原结合功能。术语抗体的“抗原结合片段”内所涵盖的结合片段的实例包括:(i)fab片段,由v
l
、vh、c
l
和c
h1
结构域组成的单价片段;(ii)f(ab')2片段,包含通过铰链区中的二硫桥连接的两个fab片段的二价片段;(iii)fd片段,由vh结构域和c
h1
结合域组成;(iv)fv片段,由抗体的单臂的v
l
结构域和vh结构域组成;(v)dab片段,其包含单个可变结构域,例如,vh结构域(例如,参见ward等人(1989)nature[自然]341:544-6;和winter等人或wo90/05144);以及(vi)经分离的互补决定区(cdr)。此外,尽管fv片段的两个结构域v
l
和vh由单独基因编码,但它们可使用重组方法通过使它们能够以单个蛋白链形式制造的合成接头来接合,其中v
l
结构域和vh结构域配对以形成单价分子(称为单链fv(scfv))。参见,例如,bird等人(1988)science[科学]242:423-6;及huston等人(1988)proc.natl.acad.sci.usa[美国国家科学院院刊]85:5879-83。此类单链抗体也旨在被涵盖在术语抗体的“抗原结合片段”内,并且在本领域中已知为能在结合之后内化至细胞中的示例性结合片段类型。参见,例如,zhu等人(2010)9:2131-41;he等人(2010)j nucl.med.[核医学杂志]51:427-32;及fitting等人(2015)mabs[单克隆抗体]7:390-402。在某些实施例中,scfv分子可以掺入融合蛋白中。还涵盖其他形式的单链抗体,如双抗体。双抗体是双特异性双抗体,其中vh和v
l
结构域在单个多肽链上表达,但使用过短以致不允许同一链上的两个区之间配对的接头,由此迫使这些结构域与另一链的互补区配对并产生两个抗原结合位点(参见,例如,holliger等人(1993)proc.natl.acad.sci.usa[美国国家科学院院刊]90:6444-8;和poljak等人(1994)structure[结构]2:1121-3)。抗原结合片段使用本领域技术人员已知的常规技术获得,并且抗原结合片段以与完整抗体相同的方式进行效用(例如,结合亲和力、内化)筛选。抗原结合片段可通过裂解完整蛋白、例如通过蛋白酶或化学裂解来制备。
[0024]
在本说明书中,抗体或其抗原结合片段是内化性抗体或其内化性抗原结合片段。如本文所用的,关于抗体或抗原结合片段的“内化”是指抗体或抗原结合片段在与细胞结合后能够穿过细胞的脂质双层膜进入内部隔室(即,“被内化”),优选进入细胞中的降解隔室如溶酶体中。例如,内化性抗fra抗体为能够在与细胞膜上的fra结合之后进入细胞中的抗体。
[0025]
如本文所用的,术语“叶酸受体α”或“fra”是指任何天然形式的人fra。该术语涵盖全长fra(例如,ncbi参考序列:np_000793;seq id no:19),以及得自细胞加工的任何形式的人fra。该术语还涵盖天然存在的fra的变体,包括但不限于剪接变体、等位基因变体及同种型。fra可自人类分离,或能以重组方式或通过合成方法产生。
[0026]
术语“抗fra抗体”或“特异性结合fra的抗体”是指任何形式的特异性结合fra的抗体或其抗原结合片段,并且涵盖单克隆抗体(包括全长单克隆抗体)、多克隆抗体及生物学功能性抗体片段,只要它们特异性结合fra即可。优选地,用于本文披露的adc中的抗fra抗体为抗体或其抗原结合片段。morab-003为示例性抗人fra抗体。如本文所用的,术语“特异性”和“特异性结合”是指抗体与靶抗原表位的选择性结合。可通过在一组给定条件下比较与适当抗原的结合和与不相关抗原或抗原混合物的结合来测试抗体的结合特异性。如果抗体与适当抗原结合的亲和力为与不相关抗原或抗原混合物结合的亲和力的至少2、5、7倍且优选10倍,则认为其具有特异性。在一个实施例中,特异性抗体为仅与fra抗原结合但不与
其他抗原结合(或表现出最小结合)的抗体。
[0027]
如本文所用的,术语“人表皮生长因子受体2”、“her2”或“her2/neu”是指任何天然形式的人her2。该术语涵盖全长her2(例如,ncbi参考序列:np_004439.2;seq id no:21),以及得自细胞加工的任何形式的人her2。该术语还涵盖天然存在的her2的变体,包括但不限于剪接变体、等位基因变体及同种型。her2可自人类分离,或能以重组方式或通过合成方法产生。
[0028]
术语“抗her2抗体”或“特异性结合her2的抗体”是指任何形式的特异性结合her2的抗体或其抗原结合片段,并且涵盖单克隆抗体(包括全长单克隆抗体)、多克隆抗体及生物学功能性抗体片段,只要它们特异性结合her2即可。美国专利号5,821,337(通过引用并入本文)提供了示例性her2结合序列,包括示例性抗her2抗体序列。优选地,用于本文披露的adc中的抗her2抗体为抗体或其抗原结合片段。曲妥珠单抗(trastuzumab)为示例性抗人her2抗体。
[0029]
术语“表位”是指能够由抗体识别且特异性结合的抗原的部分。当抗原为多肽时,表位可由连续氨基酸或通过多肽的三级折叠而邻接的非连续氨基酸形成。抗体所结合的表位可使用本领域中已知的任何表位作图技术来识别。表位作图技术的实例包括用于表位识别的x射线结晶学(其通过直接目测抗原-抗体复合物进行),监测抗体与抗原的片段或突变型变体的结合,和监测抗体和抗原的不同部分的溶剂可及性。用于对表位作图的示例性策略包括但不限于基于阵列的寡肽扫描、限制性蛋白水解、定点诱变、高通量诱变作图、氢-氘交换和质谱法(例如,参见,gershoni等人(2007)21:145-56;以及hager-braun和tomer(2005)expert rev.proteomics[蛋白质组学专家评论]2:745-56)。
[0030]
还可使用竞争性结合和表位聚类来确定共有相同或重叠表位的抗体。竞争性结合可使用交叉阻断分析来评估,如“antibodies,a laboratory manual[抗体,实验室手册]”,cold spring harbor laboratory[冷泉港实验室出版社],harlow和lane(1988年第1版,2014年第2版)中所述的分析。在一些实施例中,当在交叉阻断分析中,测试抗体或其抗原结合片段使参考抗体或其抗原结合片段与靶抗原如fra或her2(例如,包含cdr和/或选自表2、4和6中所识别的那些可变结构域的可变结构域的结合蛋白)的结合减少至少约50%(例如,50%、60%、70%、80%、90%、95%、99%、99.5%或更高或其间的任何百分比)时,测试抗体或其抗原结合片段的结合被评价为竞争性的,和/或反之亦然。在一些实施例中,竞争性结合可归因于相同或相似(例如,部分重叠)的表位,或者归因于空间位阻,其中抗体或其抗原结合片段与邻近表位结合。参见,例如,tzartos,methods in molecular biology[分子生物学中的方法](morris编辑,(1998)第66卷,第55页至第66页)。在一些实施例中,竞争性结合可用于对享有相似表位的结合蛋白组进行分类,例如,竞争结合的那些结合蛋白可被“分箱”为具有重叠或邻近表位的结合蛋白组,而不竞争的那些结合蛋白则分类为不具有重叠或邻近表位的单独的结合蛋白组。
[0031]
术语“k
on”或“k
a”是指抗体与抗原缔合以形成抗体/抗原复合物的缔合速率常数。该速率可使用如biacore或elisa分析的标准分析来测定。
[0032]
术语“k
off”或“k
d”是指抗体自抗体/抗原复合物解离的解离速率常数。该速率可使用如biacore或elisa分析的标准分析来测定。
[0033]
术语“k
d”是指特定抗体-抗原相互作用的平衡解离常数。kd通过ka/kd来计算。该速
率可使用如biacore或elisa分析的标准分析来测定。
[0034]
术语“p”或“抗体:药物比”是指每个抗体部分(ab)上包含接头部分和艾日布林的结构单元的数量(即,载药量)。在一些实施例中,p为1至10、1至9、1至8、1至7、1至6、1至5、1至4、1至3或1或2的整数,并且优选3或4的整数。在包含式i所示adc的多个拷贝的组合物中,“p”是指每个抗体部分(ab)上包含接头部分和艾日布林的结构单元的平均数量(也称为平均载药量)。当p由平均载药量表示时,p可为3至4、3.2至3.8、3.5至4.5、3.6至4.4或4。
[0035]
在一些实施例中,p为1至6、2至5或者3或4的整数。当p为较大数字时,每个抗体部分上艾日布林部分的数量增加。因此,用单个抗体能将更大数量的艾日布林递送至靶细胞,并且能进一步增加其药理学作用。
[0036]
当adc存在于细胞外部时,adc保持完整。当adc被内化到细胞(例如,癌细胞)中时,adc的接头部分被裂解,并且艾日布林在细胞中被释放。在细胞外部,接头部分典型地为稳定的。即,adc识别表达对抗体部分(ab)具有特异性的抗原的细胞(例如,癌细胞)并且进入该细胞。对于细胞中的adc,连接艾日布林和抗体部分(ab)的接头部分被裂解,从而释放出艾日布林并且显示出药理学作用。
[0037]
1.抗体部分(ab)adc中的抗体部分(ab)为抗体或其抗原结合片段(特别是,抗叶酸受体α(fra)抗体或其抗原结合片段),并且可与表达fra的肿瘤细胞结合。
[0038]
在一些实施例中,抗体或其抗原结合片段与叶酸受体α(fra)结合,并且可靶向表达fra的肿瘤细胞。此外,在一些实施例中,抗体或其抗原结合片段包含:(a)由kabat编号系统定义的三个重链cdr(seq id no:2所示的重链cdr1、seq id no:3所示的重链cdr2和seq id no:4所示的重链cdr3)和三个轻链cdr(seq id no:7所示的轻链cdr1、seq id no:8所示的轻链cdr2和seq id no:9所示的轻链cdr3);或(b)由imgt编号系统定义的三个重链cdr(seq id no:13所示的重链cdr1、seq id no:14所示的重链cdr2和seq id no:15所示的重链cdr3)和三个轻链cdr(seq id no:16所示的轻链cdr1、seq id no:17所示的轻链cdr2和seq id no:18所示的轻链cdr3)。此外,在一些实施例中,抗体或其抗原结合片段包含人类框架序列。在一些实施例中,抗体或其抗原结合片段包含seq id no:23所示的重链可变结构域和seq id no:24所示的轻链可变结构域。在一些实施例中,抗体或抗原结合片段包含人igg1重链恒定结构域及igκ轻链恒定结构域。在一些实施例中,抗体或抗原结合片段竞争结合和/或与包含seq id no:23所示的重链可变结构域及seq id no:24所示的轻链可变结构域的抗体结合相同的表位。在一些实施例中,抗体或其抗原结合片段与包含丙氨酸-组氨酸-赖氨酸-天冬氨酸(ala-his-lys-asp,seq id no:345)的表位结合(非专利文献9)。在一些实施例中,抗体或抗原结合片段与包含ntsqeahkdvsyl(asn-thr-ser-gln-glu-ala-his-lys-asp-val-ser-tyr-leu,seq id no:346)的表位结合。
[0039]
在其他实施例中,抗体或其抗原结合片段与人表皮生长因子受体2(her2)结合,并且可靶向表达her2的肿瘤细胞。在一些实施例中,抗体或其抗原结合片段可包含:(a)由kabat编号系统定义的三个重链cdr(seq id no:71所示的重链cdr1、seq id no:72所示的重链cdr2和seq id no:73所示的重链cdr3)和三个轻链cdr(seq id no:74所示的轻链cdr1、seq id no:75所示的轻链cdr2和seq id no:76所示的轻链cdr3);或(b)由imgt编号系统定义的三个重链cdr(seq id no:191所示的重链cdr1、seq id no:192所示的重链cdr2
和seq id no:193所示的重链cdr3)和三个轻链cdr(seq id no:194所示的轻链cdr1、seq id no:195所示的轻链cdr2和seq id no:196所示的轻链cdr3)。此外,在一些实施例中,抗体或其抗原结合片段包含人类框架序列。在一些实施例中,抗体或其抗原结合片段包含seq id no:27所示的重链可变结构域和seq id no:28所示的轻链可变结构域。在一些实施例中,抗体或抗原结合片段包含人igg1重链恒定结构域及igκ轻链恒定结构域。在一些实施例中,抗体或抗原结合片段竞争结合和/或与包含seq id no:27所示的重链可变结构域及seq id no:28所示的轻链可变结构域的抗体结合相同的表位。
[0040]
在其他实施例中,抗体或其抗原结合片段与间皮素(msln)结合,并且可靶向表达msln的肿瘤细胞。在一些实施例中,抗体或其抗原结合片段可包含:(a)由kabat编号系统定义的三个重链cdr(seq id no:65所示的重链cdr1、seq id no:66所示的重链cdr2和seq id no:67所示的重链cdr3)和三个轻链cdr(seq id no:68所示的轻链cdr1、seq id no:69所示的轻链cdr2和seq id no:70所示的轻链cdr3);或(b)由imgt编号系统定义的三个重链cdr(seq id no:185所示的重链cdr1、seq id no:186所示的重链cdr2和seq id no:187所示的重链cdr3)和三个轻链cdr(seq id no:188所示的轻链cdr1、seq id no:189所示的轻链cdr2和seq id no:190所示的轻链cdr3)。在一些实施例中,抗体或抗原结合片段包含seq id no:25所示的重链可变结构域和seq id no:26所示的轻链可变结构域。在一些实施例中,抗体或抗原结合片段包含人igg1重链恒定结构域及igκ轻链恒定结构域。在一些实施例中,抗体或抗原结合片段竞争结合和/或与包含seq id no:25所示的重链可变结构域及seq id no:26所示的轻链可变结构域的抗体结合相同的表位。
[0041]
在本发明实施例中,优选的抗体部分(ab)为抗叶酸受体α抗体或其抗原结合片段,包含:(a)由kabat编号系统定义的包含seq id no:2(重链cdr1)、seq id no:3(重链cdr2)和seq id no:4(重链cdr3)所示的氨基酸序列的三个重链cdr或包含seq id no:7(轻链cdr1)、seq id no:8(轻链cdr2)和seq id no:9(轻链cdr3)所示的氨基酸序列的三个轻链cdr;或(b)由imgt编号系统定义的包含seq id no:13(重链cdr1)、seq id no:14(重链cdr2)和seq id no:15(重链cdr3)所示的氨基酸序列的三个重链cdr或包含seq id no:16(轻链cdr1)、seq id no:17(轻链cdr2)和seq id no:18(轻链cdr3)所示的氨基酸序列的三个轻链cdr。另一种优选的抗体部分(ab)为抗人表皮生长因子受体2(her2)抗体或其抗原结合片段,包含:(c)由kabat编号系统定义的包含seq id no:71(重链cdr1)、seq id no:72(重链cdr2)和seq id no:73(重链cdr3)所示的氨基酸序列的三个重链cdr或包含seq id no:74(轻链cdr1)、seq id no:75(轻链cdr2)和seq id no:76(轻链cdr3)所示的氨基酸序列的三个轻链cdr;或(d)由imgt编号系统定义的包含seq id no:191(重链cdr1)、seq id no:192(重链cdr2)和seq id no:193(重链cdr3)所示的氨基酸序列的三个重链cdr或包含seq id no:194(轻链cdr1)、seq id no:195(轻链cdr2)和seq id no:196(轻链cdr3)所示的氨基酸序列的三个轻链cdr。更优选的是,抗体部分(ab)为抗叶酸受体α抗体或其抗原结合片段。
[0042]
抗体部分(ab)包括与范围内的癌细胞上的靶抗原特异性结合的任何抗体或抗原结合片段。抗体或抗原结合片段可与靶抗原结合,其中当通过例如biacore(注册商品名)分析测量时,解离常数(kd)≤1mm、≤100nm或≤10nm或为其间任何量。在某些实施例中,kd为1pm至500pm。在一些实施例中,kd为500pm至1μm、1μm至100nm或者100mm至10nm。
[0043]
在一些实施例中,抗体部分为包含两个重链及两个轻链的四链抗体(也称为免疫球蛋白)。在一些实施例中,抗体部分为免疫球蛋白的双链半抗体(一个轻链及一个重链)或其抗原结合片段。
[0044]
表1-9清楚地示出了根据本披露的示例性抗体的氨基酸及核酸序列。
[0045]
[表1]mab类别/同种型靶标morab-003人源化人叶酸受体αmorab-009小鼠-人嵌合人间皮素曲妥珠单抗人源化人her2/neu33011-xi兔-人嵌合人间皮素33011-zu人源化人间皮素111b10-xi兔-人嵌合人间皮素111b10-zu人源化人间皮素201c15-xi兔-人嵌合人间皮素201c15-zu人源化人间皮素346c6-xi兔-人嵌合人间皮素346c6-zu人源化人间皮素缩写:xi为嵌合抗体,并且zu为人源化抗体。
[0046]
mab可变结构域的氨基酸序列[表2] seq id nomabigg链123morab-003重链224morab-003轻链325morab-009重链426morab-009轻链527曲妥珠单抗重链628曲妥珠单抗轻链72933011-xi重链83033011-xi轻链93133011-zu重链103233011-zu轻链1133111b10-xi重链1234111b10-xi轻链1335111b10-zu重链1436111b10-zu轻链1537201c15-xi重链1638201c15-xi轻链1739201c15-zu重链1840201c15-zu轻链
1941346c6-xi重链2042346c6-xi轻链2143346c6-zu重链2244346c6-zu轻链
[0047]
编码mab可变结构域的核酸序列[表3] seq id nomabigg链145morab-003重链246morab-003轻链347morab-009重链448morab-009轻链54933011-xi重链65033011-xi轻链75133011-zu重链85233011-zu轻链953111b10-xi重链1054111b10-xi轻链1155111b10-zu重链1256111b10-zu轻链1357201c15-xi重链1458201c15-xi轻链1559201c15-zu重链1660201c15-zu轻链1761346c6-xi重链1862346c6-xi轻链1963346c6-zu重链2064346c6-zu轻链
[0048]
mab kabat cdr的氨基酸序列[表4]
[表4(续)] seq id nomabigg链43101201c15-xihc cdr144102201c15-xihc cdr245103201c15-xihc cdr346104201c15-xilc cdr147105201c15-xilc cdr248106201c15-xilc cdr349107201c15-zuhc cdr150108201c15-zuhc cdr251109201c15-zuhc cdr352110201c15-zulc cdr153111201c15-zulc cdr254112201c15-zulc cdr355113346c6-xihc cdr156114346c6-xihc cdr257115346c6-xihc cdr358116346c6-xilc cdr159117346c6-xilc cdr260118346c6-xilc cdr361119346c6-zuhc cdr162120346c6-zuhc cdr263121346c6-zuhc cdr364122346c6-zulc cdr165123346c6-zulc cdr266124346c6-zulc cdr3
[0049]
编码mab kabat cdr的核酸序列[表5] seq id nomabigg链1125morab-003hc cdr12126morab-003hc cdr23127morab-003hc cdr3
4128morab-003lc cdr15129morab-003lc cdr26130morab-003lc cdr37131morab-009hc cdr18132morab-009hc cdr29133morab-009hc cdr310134morab-009lc cdr111135morab-009lc cdr212136morab-009lc cdr31313733011-xihc cdr11413833011-xihc cdr21513933011-xihc cdr31614033011-xilc cdr11714133011-xilc cdr21814233011-xilc cdr31914333011-zuhc cdr12014433011-zuhc cdr22114533011-zuhc cdr32214633011-zulc cdr12314733011-zulc cdr22414833011-zulc cdr325149111b10-xihc cdr126150111b10-xihc cdr227151111b10-xihc cdr328152111b10-xilc cdr129153111b10-xilc cdr230154111b10-xilc cdr331155111b10-zuhc cdr132156111b10-zuhc cdr233157111b10-zuhc cdr334158111b10-zulc cdr135159111b10-zulc cdr236160111b10-zulc cdr3[表5(续)] seq id nomabigg链37161201c15-xihc cdr138162201c15-xihc cdr239163201c15-xihc cdr340164201c15-xilc cdr1
41165201c15-xilc cdr242166201c15-xilc cdr343167201c15-zuhc cdr144168201c15-zuhc cdr245169201c15-zuhc cdr346170201c15-zulc cdr147171201c15-zulc cdr248172201c15-zulc cdr349173346c6-xihc cdr150174346c6-xihc cdr251175346c6-xihc cdr352176346c6-xilc cdr153177346c6-xilc cdr254178346c6-xilc cdr355179346c6-zuhc cdr156180346c6-zuhc cdr257181346c6-zuhc cdr358182346c6-zulc cdr159183346c6-zulc cdr260184346c6-zulc cdr3
[0050]
mab imgt cdr的氨基酸序列[表6]
[表6(续)] seq id nomabigg链
43221201c15-xihc cdr144222201c15-xihc cdr245223201c15-xihc cdr346224201c15-xilc cdr147225201c15-xilc cdr248226201c15-xilc cdr349227201c15-zuhc cdr150228201c15-zuhc cdr25!229201c15-zuhc cdr352230201c15-zulc cdr153231201c15-zulc cdr254232201c15-zulc cdr355233346c6-xihc cdr156234346c6-xihc cdr257235346c6-xihc cdr358236346c6-xilc cdr159237346c6-xilc cdr260238346c6-xilc cdr36!239346c6-zuhc cdr162240346c6-zuhc cdr263241346c6-zuhc cdr364242346c6-zulc cdr165243346c6-zulc cdr266244346c6-zulc cdr3
[0051]
编码mab imgt cdr的核酸序列[表7]
[表7(续)]
[0052]
全长mab ig链的氨基酸序列[表8]
[0053]
编码全长mab ig链的核酸序列[表9]
示例性序列不包括前导序列。
[0054]
adc可包含上表中列出的任何一组重链和轻链可变结构域(例如,morab-003重链和轻链可变结构域,或曲妥珠单抗重链和轻链可变结构域),或来自重链和轻链组的一组六个cdr序列。在一些实施例中,adc包含人重链和轻链恒定结构域或其片段。例如,adc可包含人igg重链恒定结构域(例如,igg1)以及人κ或λ轻链恒定结构域。抗体部分包含人免疫球蛋白g亚型1(igg1)重链恒定区连同人igκ轻链恒定区。
[0055]
adc的靶癌症抗原可为叶酸受体α(fra)。
[0056]
抗fra抗体或其抗原结合片段可包含由kabat编号系统定义的三个重链cdr(seq id no:2所示的重链cdr1、seq id no:3所示的重链cdr2和seq id no:4所示的重链cdr3)和三个轻链cdr(seq id no:7所示的轻链cdr1、seq id no:8所示的轻链cdr2和seq id no:9所示的轻链cdr3)。
[0057]
此外,抗fra抗体或其抗原结合片段可包含由imgt编号系统定义的三个重链cdr(seq id no:13所示的重链cdr1、seq id no:14所示的重链cdr2和seq id no:15所示的重链cdr3)和三个轻链cdr(seq id no:16所示的轻链cdr1、seq id no:17所示的轻链cdr2和seq id no:18所示的轻链cdr3)。
[0058]
在各个实施例中,抗fra抗体或其抗原结合片段包含:包含seq id no:23所示的氨基酸序列的重链可变结构域以及包含seq id no:24所示的氨基酸序列的轻链可变结构域;或包含seq id no:1所示的氨基酸序列的重链可变结构域以及包含seq id no:6所示的氨基酸序列的轻链可变结构域。在一些实施例中,抗fra抗体或其抗原结合片段包含seq id no:23所示的重链可变结构域氨基酸序列以及seq id no:24所示的轻链可变结构域氨基酸序列,或者包含与上述序列具有至少95%一致性的序列。在一些实施例中,抗fra抗体或其抗原结合片段包含与seq id no:23具有至少96%、至少97%、至少98%或至少99%一致性的重链可变结构域氨基酸序列和与seq id no:24具有至少96%、至少97%、至少98%或至少99%一致性的轻链可变结构域氨基酸序列。
[0059]
抗fra抗体可包含人igg1重链恒定结构域连同人igκ轻链恒定结构域。
[0060]
抗fra抗体包含seq id no:1所示的重链氨基酸序列或与seq id no:1具有至少95%一致性的序列以及seq id no:6所示的轻链氨基酸序列或与seq id no:6具有至少95%一致性的序列。在某些实施例中,抗体包含seq id no:1所示的重链氨基酸序列以及seq id no:6所示的轻链氨基酸序列,或者包含与上述序列具有至少95%一致性的序列。在一些实施例中,抗fra抗体包含与seq id no:1具有至少96%、至少97%、至少98%或至少99%一致性的重链氨基酸序列和/或与seq id no:6具有至少96%、至少97%、至少98%或至少99%一致性的轻链氨基酸序列。在一些实施例中,抗fra抗体包含由seq id no:11(包含编码前导序列的核苷酸)或seq id no:325(不包含编码前导序列的核苷酸)所示的核苷酸序列编码的重链以及由seq id no:12(包含编码前导序列的核苷酸)或seq id no:326(不包含编码前导序列的核苷酸)所示的核苷酸编码的轻链。在一些实施例中,重链氨基酸序列缺少c-末端赖氨酸。在各个实施例中,抗fra抗体具有由以下细胞系产生的抗体的氨基酸序列或者缺少重链c-末端赖氨酸的此类序列:该细胞系根据条款按照布达佩斯条约(budapest treaty)于2006年4月24日保藏于美国模式培养物集存库(american type culture collection)(atcc,美国弗吉尼亚州马纳萨斯市大学路10801号(10801university blvd.,manassas,va.),20110-2209),保藏号为pta-7552。在各个实施例中,抗fra抗体为morab-003(usan名称:法妥组单抗(farletuzumab))(ebel等人(2007)cancer immunity[癌症免疫学]7:6),或其抗原结合片段。
[0061]
adc的靶癌症抗原可为人表皮生长因子受体2(her2)。
[0062]
此外,抗her2抗体或其抗原结合片段可包含由kabat编号系统定义的三个重链cdr(seq id no:71所示的重链cdr1、seq id no:72所示的重链cdr2和seq id no:73所示的重
链cdr3)和三个轻链cdr(seq id no:74所示的轻链cdr1、seq id no:75所示的轻链cdr2和seq id no:76所示的轻链cdr3)。
[0063]
此外,抗her2抗体或其抗原结合片段可包含由imgt编号系统定义的三个重链cdr(seq id no:191所示的重链cdr1、seq id no:192所示的重链cdr2和seq id no:193所示的重链cdr3)和三个轻链cdr(seq id no:194所示的轻链cdr1、seq id no:195所示的轻链cdr2和seq id no:196所示的轻链cdr3)。
[0064]
在各个实施例中,抗her2抗体或其抗原结合片段包含:包含seq id no:27所示的氨基酸序列的重链可变结构域以及包含seq id no:28所示的氨基酸序列的轻链可变结构域;或包含seq id no:347所示的氨基酸序列的重链结构域以及包含seq id no:308所示的氨基酸序列的轻链结构域。在一些实施例中,抗her2抗体或其抗原结合片段包含seq id no:27所示的重链可变结构域氨基酸序列以及seq id no:28所示的轻链可变结构域氨基酸序列,或者包含与上述序列具有至少95%一致性的序列。在一些实施例中,抗her2抗体或其抗原结合片段包含与seq id no:27具有至少96%、至少97%、至少98%或至少99%一致性的重链可变结构域氨基酸序列和/或与seq id no:28具有至少96%、至少97%、至少98%或至少99%一致性的轻链可变结构域氨基酸序列。
[0065]
抗her2抗体可包含人igg1重链恒定结构域和人igκ轻链恒定结构域。
[0066]
在各个实施例中,抗her2抗体包含seq id no:307所示的重链氨基酸序列或与seq id no:307具有至少95%一致性的序列以及seq id no:308所示的轻链氨基酸序列或与seq id no:308具有至少95%一致性的序列。在某些实施例中,抗体包含seq id no:307所示的重链氨基酸序列以及seq id no:308所示的轻链氨基酸序列,或者包含与上述序列具有至少95%一致性的序列。在一些实施例中,抗her2抗体包含与seq id no:307具有至少96%、至少97%、至少98%或至少99%一致性的重链氨基酸序列和与seq id no:308具有至少96%、至少97%、至少98%或至少99%一致性的轻链氨基酸序列。在各个实施例中,抗her2抗体为曲妥珠单抗或其抗原结合片段。
[0067]
在各个实施例中,抗fra抗体或其抗原结合片段包含morab-003的三个重链cdr和三个轻链cdr,或者包含通过在重链cdr1(kabat系统定义的seq id no:2或imgt系统定义的seq id no:13)、重链cdr2(kabat系统定义的seq id no:3或imgt系统定义的seq id no:14)、重链cdr3(kabat系统定义的seq id no:4或imgt系统定义的seq id no:15)、轻链cdr1(kabat系统定义的seq id no:7或imgt系统定义的seq id no:16)、轻链cdr2(kabat系统定义的seq id no:8或imgt系统定义的seq id no:17)和轻链cdr3(kabat系统定义的seq id no:9或imgt系统定义的seq id no:18)上进行一个以下、两个以下、三个以下、四个以下、五个以下或六个以下氨基酸的添加、缺失或取代而获得的氨基酸序列。
[0068]
在各个其他实施例中,抗her2抗体或其抗原结合片段包含曲妥珠单抗的三个重链cdr和三个轻链cdr,或者包含通过在重链cdr1(kabat系统定义的seq id no:71或imgt系统定义的seq id no:191)、重链cdr2(kabat系统定义的seq id no:72或imgt系统定义的seq id no:192)、重链cdr3(kabat系统定义的seq id no:73或imgt系统定义的seq id no:193)、轻链cdr1(kabat系统定义的seq id no:74或imgt系统定义的seq id no:194)、轻链cdr2(kabat系统定义的seq id no:75或imgt系统定义的seq id no:195)和轻链cdr3(kabat系统定义的seq id no:76或imgt系统定义的seq id no:196)上进行一个以下、两个
以下、三个以下、四个以下、五个以下或六个以下氨基酸的添加、缺失或取代而获得的氨基酸序列。
[0069]
在各个实施例中,氨基酸取代为单个残基的取代。插入通常为约1至约20个氨基酸残基的插入,但显著更大的插入可为容许的,只要保留生物学功能(例如与fra或her2结合)即可。缺失通常为约1至约20个氨基酸残基范围内的缺失,但在一些情况下,缺失可能要大得多。取代、缺失、插入或其任何组合可用于获得最终衍生物或变体。一般而言,对数个氨基酸作出这些改变以最小化分子的更改,特别是最小化抗原结合蛋白的免疫原性和特异性的更改。然而,在某些情况下,更多改变可为容许的。保守取代一般根据以下表10所示的图表进行。
[0070]
[表10]
[0071]
通过选择保守性低于表10中所示的取代的取代来作出功能或免疫属性中的实质性改变。例如,可进行更显著地影响以下的取代:更改区域中多肽主链的结构,例如α-螺旋或β-折叠结构;靶位点处该分子的电荷或疏水性;或侧链的体积。通常有望产生多肽性质最大变化的取代为以下(a)至(d):(a)亲水氨基酸残基(例如,ser或thr)被疏水氨基酸残基(例如,leu、ile、phe、val
或ala)取代;(b)cys或pro被任何其他残基取代;(c)具有正电侧链的氨基酸残基(例如,lys、arg或his)被负电氨基酸残基(例如,gln或asn)取代;和(d)具有大体积侧链的残基(例如,phe)被没有侧链的氨基酸(例如,gly)取代。
[0072]
在其中变体抗体序列用于adc中的各个实施例中,变体通常展现相同的定性生物学活性并且引发相同的免疫反应,但还可根据需要选择变体以改变抗原结合蛋白的特征。可替代地,变体可设计成使得抗原结合蛋白的生物学活性得到改变。例如,如本文所讨论,可更改或去除糖基化位点。
[0073]
在根据本发明实施例的adc中,可使用各种抗体来靶向癌细胞。于肿瘤细胞而非健康细胞上表达、或于肿瘤细胞上以高于健康细胞的表达量表达的合适抗原以及针对这类抗原的抗体为本领域中已知的。这些抗体可与本文所披露的接头和艾日布林一起使用。
[0074]
adc中的抗体部分可为靶向fra的抗体部分,如morab-003。在一些实施例中,根据本披露的接头和艾日布林可令人惊讶地在几种不同的靶向肿瘤的抗体中有效。当adc中的抗体部分为靶向fra的抗体部分如morab-003时,adc可带来药物:抗体比、肿瘤靶向性、旁杀伤效应和治疗功效的特别改善以及脱靶杀伤的减少。治疗功效改善可在体外或体内测量,并且可包括肿瘤生长速率降低和/或肿瘤体积减小。
[0075]
当adc中的抗体部分为靶向her2的抗体部分如曲妥珠单抗时,观察到其部分或全部的有利功能性质。此外,adc中的抗体部分可为靶向her2的抗体部分如曲妥珠单抗。当adc中的抗体部分为靶向msln的抗体部分如morab-009时,观察到其部分或全部的有利功能性质。
[0076]
在一些实施例中,将游离半胱氨酸残基引入抗体部分的氨基酸序列中。例如,可制备其中亲本抗体的氨基酸序列中的一个或多个氨基酸被半胱氨酸替换的抗体(半胱氨酸修饰的抗体)。例如,通过将半胱氨酸引入亲本fab抗体的片段中,可形成半胱氨酸修饰的fab抗体(也称为“thiofab”)。类似地,通过将半胱氨酸引入亲本单克隆抗体中,可形成半胱氨酸修饰的单克隆抗体(也称为“thiomab”)。单位点突变在thiofab中产生单个经修饰的半胱氨酸残基,而由于igg抗体的二聚体特质,单位点突变在thiomab中产生两个经修饰的半胱氨酸残基。编码亲本多肽的氨基酸序列变体的dna可由本领域中已知的各种方法制备(参见,例如,wo 2006/034488中所述的方法)。这些方法包括但不限于通过先前所制备的编码多肽的dna的定点(或寡核苷酸介导的)诱变、pcr诱变和盒式诱变进行的制备。重组抗体的变体还可通过限制性片段操作或通过使用合成寡核苷酸的重叠延伸pcr来构建。式i所示的adc包括但不限于具有一个、两个、三个或四个经修饰的半胱氨酸的抗体(lyon等人(2012)methods enzymol.[酶学方法]502:123-38)。在一些实施例中,当一个或多个游离半胱氨酸残基已经存在于抗体部分中时,已存在的游离半胱氨酸残基可用于将抗体部分与艾日布林缀合而不是修饰。
[0077]
2.接头部分本发明实施例的接头部分具有以下化学结构,并且由五个单元构成,这五个单元从邻近抗体部分侧开始包括马来酰亚胺单元(mal)、氧乙烯单元(peg)、丙酸单元(pa)、氨基酸单元(val-cit)和自消融单元(pab:对氨基苄氧基羰基)。
cit)在靶细胞中因自消融单元(pab)的自消融而裂解时,未经修饰的艾日布林可被释放,而不在艾日布林侧保留多余的官能团。
[0083]
自消融化学为本领域中已知的,并且可被容易地选择用于根据本披露的adc。在各个实施例中,将接头中的可裂解部分与药物部分(例如,艾日布林)相结合的间隔子单元为自消融的,并在细胞内条件下在可裂解部分的裂解同时或之前/之后不久经历自消融。
[0084]
另一方面,马来酰亚胺单元(mal)、氧乙烯单元(peg)和丙酸单元(pa)被排列在缬氨酸与抗体ab之间。马来酰亚胺中的α,β-不饱和羰基与抗体中的半胱氨酸残基(具体而言,巯基(-sh))有反应性,并且发挥功能以使接头部分和艾日布林与抗体结合。接头部分包含马来酰亚胺单元,并且经由该马来酰亚胺单元连接到抗体。结果,可进一步改善抗体载药量(p:每个抗体部分上艾日布林部分的数量)。
[0085]
氧乙烯单元(peg)为由一个或多个氧乙烯基团构成的单元,并且为实质上亲水的。艾日布林可用于降低艾日布林可能通过多药耐药(mdr)转运体或功能上类似的转运体从耐药癌细胞中泵出的程度。在一些实施例中,接头部分为较短的peg接头,并且相较于较长的peg接头而言提供了改善的稳定性和降低的聚集。在式(i)中,氧乙烯基团的数量由m表示,并且m为1至10的整数。m优选为2。当m为小于2的整数时,接头部分的长度减小,并且可展示出与包含更长接头部分(例如,m为8)的adc相比更低的聚集水平和/或更高的载药量。
[0086]
在一些实施例中,相对于包含替代性的可裂解部分的adc,包含可裂解肽部分的adc聚集水平更低、抗体:药物比改善、癌细胞的中靶杀伤增加、非癌细胞的脱靶杀伤减少和/或载药量(p)升高。在一些实施例中,相对于不可裂解的接头,添加可裂解部分增加了细胞毒性和/或效力。在一些实施例中,可在表达中等水平的adc抗体部分所靶向的抗原(例如,中等fra表达)的癌症中观察到增加的效力和/或细胞毒性。在一些实施例中,可裂解肽部分可通过酶裂解,并且接头为可酶裂解接头。在一些实施例中,酶为组织蛋白酶,并且接头为组织蛋白酶可裂解的接头。在一些实施例中,与替代性裂解机制相比,酶可裂解的接头(例如组织蛋白酶可裂解的接头)展现上述改善性质中的一项或多项。
[0087]
此外,接头部分可能会影响adc的物理化学性质。由于许多细胞毒性剂本质上具疏水性,故将其连接至具有额外疏水性部分的抗体可能引起聚集。adc聚集物不可溶且通常限制抗体上可实现的载药量,这可能不利地影响adc的效力。通常,生物制品的蛋白质聚集物还与免疫原性增加相关。根据本发明实施例的接头得到具有低聚集水平和所需载药量水平的adc。
[0088]
在各个实施例中,接头被设计为通过和接头-艾日布林和/或单独的艾日布林向邻近细胞扩散来促进细胞内化、细胞内化后的裂解以及旁杀伤效应(邻近细胞的杀伤)。在一些实施例中,接头被设计为使细胞外环境中的裂解最小化,由此降低对脱靶组织(例如非癌组织)的毒性,同时保持adc与靶组织的结合以及不表达adc抗体部分所靶向的抗原、但围绕表达该抗原的靶癌组织的癌组织的旁杀伤效应。根据本发明实施例的接头部分在提供这些功能特征方面特别有效,例如,当将抗fra抗体部分如morab-003与药物部分如艾日布林接合时。在一些实施例中,在没有抗fra抗体部分和/或没有抗morab-003的情况下也可观察到这些功能特征中的至少部分特征。根据本发明实施例的接头部分可有效地提供这些功能特征的部分或全部,例如,当将抗her2抗体部分如曲妥珠单抗与药物部分如艾日布林接合时。
[0089]
已发现adc显示了所需性质的特定组合,特别是当与抗fra抗体如morab-003或其
抗原结合片段配对时。这些性质包括但不限于有效的载药量水平(p≥约4)、低聚集水平、在储存条件下或在体内循环时的稳定性(例如血清稳定性)、保持与未缀合抗体相当的对表达靶标的细胞的亲和力、针对表达靶标的细胞的强细胞毒性、低脱靶细胞杀伤水平、高旁杀伤效应水平和/或有效的体内抗癌活性,所有性质为与使用其他接头-艾日布林和/或抗体部分的adc进行比较。
[0090]
3.艾日布林如本文所用的,术语“艾日布林”是指软海绵素b的合成类似物,该软海绵素b是一种自海洋海绵冈田软海绵(halichondria okadais)分离的大环化合物。艾日布林为微管动力学抑制剂,其被认为结合微管蛋白且通过抑制有丝分裂纺锤体组合件来诱导细胞周期停滞于g2/m期。术语“艾日布林甲磺酸盐”是指艾日布林的甲磺酸盐,其以商品名halaven(商标)上市。在根据本发明实施例的adc中,艾日布林经由艾日布林的伯氨基与adc的接头结合。
[0091]
4.抗体-药物缀合物(adc)在根据本发明实施例的adc中,艾日布林经由上述接头部分与抗体部分结合。抗体部分可为,例如,抗fra抗体、抗间皮素抗体、抗her2抗体如曲妥珠单抗。
[0092]
根据本发明实施例的adc可将有效剂量的细胞毒性剂或细胞生长抑制剂选择性递送至癌细胞或递送至肿瘤组织。已发现adc针对表达对应靶抗原(例如,fra或her2)的细胞具有强细胞毒性活性和/或细胞生长抑制活性。在一些实施例中,adc的细胞毒性活性和/或细胞生长抑制活性依赖于细胞中的靶抗原表达水平。在一些实施例中,与表达低水平相同抗原的癌细胞相比,根据本披露的adc可特别有效地杀伤表达中等水平的靶抗原的癌细胞。
[0093]
术语“癌症”是指哺乳动物中的生理病状,其中细胞群体的特征为不受调控的细胞生长。癌症的实例包括但不限于癌、淋巴瘤、胚细胞瘤、肉瘤和白血病。此类癌症的更特别的实例包括鳞状细胞癌、小细胞肺癌、非小细胞肺癌、肺腺癌、肺鳞状癌、腹膜癌、肝细胞癌、胃肠癌、胰腺癌、胶质母细胞瘤、宫颈癌、卵巢癌、肝癌(liver cancer)、膀胱癌、肝细胞瘤、乳腺癌(例如,三阴性乳腺癌)、骨肉瘤、黑素瘤、结肠癌、结肠直肠癌、子宫内膜(例如,浆液性)或子宫癌、唾液腺癌、肾癌、肝癌(liver cancer)、前列腺癌、外阴癌、甲状腺癌、肝癌(hepatic carcinoma)和各种类型的头颈癌。三阴性乳腺癌是指对于雌激素受体(er)、孕酮受体(pr)或her2/neu的基因表达为阴性的乳腺癌。
[0094]
术语“肿瘤”是指因过量细胞生长或增殖所致的良性或恶性的任何组织块,包括癌前病变。
[0095]
术语“癌细胞”和“肿瘤细胞”是指来源于肿瘤的单个细胞或全部细胞群体,包括非
致瘤细胞及癌症干细胞。当仅提及缺乏更新及分化能力的那些肿瘤细胞时,如本文所用的术语“肿瘤细胞”由术语“非致瘤”修饰以将那些肿瘤细胞与癌症干细胞区分开。
[0096]
示例性高表达fra的癌症包括但不限于卵巢癌(例如,浆液性卵巢癌、透明细胞卵巢癌)、肺类癌、三阴性乳腺癌、子宫内膜癌和非小细胞肺癌(例如,腺癌)。示例性中等表达fra的癌症包括但不限于胃癌和结肠直肠癌。示例性低表达fra的癌症包括但不限于黑素瘤和淋巴瘤。示例性高表达her2的癌症包括但不限于乳腺癌、胃癌、食管癌、卵巢癌和子宫内膜癌。示例性中等表达her2的癌症包括但不限于肺癌和膀胱癌。
[0097]
如本文所用的,术语“抑制(inhibit或inhibition of)”意指减少可测量的量,并且可包括但不需要完全预防或抑制。
[0098]
如本文所披露的adc的“有效量”是足以进行具体陈述的目的(例如,在施用后产生治疗效果,如减小肿瘤生长速率或肿瘤体积、减少癌症症状或治疗功效的某些其他指标)的量。有效量可以与所陈述目的相关的常规方式来测定。术语“治疗有效量”是指有效治疗受试者的疾病或障碍的adc的量。在癌症的情况下,治疗有效量的adc可减少癌细胞的数目、减小肿瘤尺寸、抑制(例如,减缓或停止)肿瘤转移、抑制(例如,减缓或停止)肿瘤生长和/或缓解一种或多种症状。“预防有效量”是指在必要的剂量和时间段内达到预期预防效果的有效量。典型地,由于预防剂量在疾病之前或在疾病早期阶段时用于受试者中,所以预防有效量将小于治疗有效量。
[0099]
如本文所用的,“治疗”或“治疗性”和语法上相关的术语是指疾病的任何后果的任何改善,如延长的存活期、较低的发病率和/或减轻的由替代性治疗模式引起的副作用。如本领域容易理解的,对于治疗行为,完全根除是优选的而并不是必需的。如本文所用的,“治疗(treatment或treat)”是指将所述adc施用给受试者,例如患者。治疗可为治愈、愈合、减轻、缓解、改变、补救、改善、缓和、改良或影响障碍(例如,癌症)、该障碍的症状或患该障碍的倾向性。
[0100]
在一些实施例中,使用经标记的adc。合适的“标记”包括放射性核素、酶、受质、辅因子、抑制因子、荧光部分、化学发光部分、磁性粒子等。
[0101]
如本文所用的,“蛋白质”意指至少两个共价结合的氨基酸。该术语涵盖多肽、寡肽和肽。在一些实施例中,两个或更多个共价结合的氨基酸经由肽键结合。蛋白质可由天然存在的氨基酸和肽键构成,例如当蛋白质使用表达系统和宿主细胞以重组方式制成时。可替代地,蛋白质可包括合成氨基酸(例如,高苯丙氨酸、瓜氨酸、鸟氨酸及正白氨酸)或模拟肽结构(即,“肽或蛋白质类似物”,如类肽)。类肽为一类示例性的模拟肽,其侧链附接至肽主链的氮原子而非附接至α-碳(因为其在氨基酸中),并且与肽相比具有不同的氢键结合及构象特征(参见,例如,simon等人(1992)proc natl acad sci.usa[美国国家科学院院刊]89:9367)。因此,类肽可能对蛋白水解或其他生理或储存条件具有抗性,并且有效地渗透细胞膜。可并入此类合成氨基酸,特别是当通过本领域中熟知的常规方法体外合成抗体时如此。此外,还可使用模拟肽的、合成和天然存在的残基/结构的任何组合。“氨基酸”还包括亚氨基酸残基如脯氨酸及羟基脯氨酸。氨基酸“r基”或“侧链”可呈(l)-或(s)-构型。在具体实施例中,氨基酸呈(l)-或(s)-构型。
[0102]“重组蛋白”是使用重组技术、使用本领域中已知的任何技术和方法制成的蛋白质,即,通过表达重组核酸制成的蛋白质。用于产生重组蛋白的方法和技术在本领域中众所
周知。
[0103]“分离的”蛋白质未伴随在其天然状态下通常与其缔合的至少某种材料,例如占给定样品中总蛋白质的至少约5重量%或至少约50重量%。应理解,取决于情况,分离的蛋白质可占总蛋白质含量的5重量%至99.9重量%。举例而言,可经由使用诱导型启动子或高表达启动子以显著较高的浓度制造蛋白质,以使得以经增加的浓度水平制造蛋白质。该定义包括在本领域中已知的广泛多种的生物体和/或宿主细胞中产生抗体。
[0104]
对于氨基酸序列,序列一致性和/或相似性可使用本领域中已知的标准技术来确定,这些技术包括但不限于smith和waterman(1981)adv.appl.math.[应用数学进展]2:482的局域序列一致性算法、needleman和wunsch(1970)j.mol.biol.[分子生物学杂志]48:443的序列一致性比对算法、pearson和lipman(1988)proc.nat.acad.sci.usa[美国国家科学院院刊]85:2444的相似性方法的检索、这些算法的计算机化实施方案(在威斯康星州麦迪逊市科学路575号(575science drive,madison,wis.)的遗传学计算机组(genetics computer group)的威斯康星遗传学软件包(wisconsin genetics software package)中的gap、bestfit、fasta和tfasta)、由devereux等人(1984)nucl.acid res.[核酸研究]12:387-95所述的最佳拟合序列程序,优选使用默认设定,或通过检验。一致性百分比可参考“current methods in sequence comparison and analysis[序列比较与分析的现有方法]”,macromolecule sequencing and synthesis,selected methods and applications[大分子测序和合成、选择的方法和应用],第127-149页(1988),alan r.liss,inc[阿兰
·r·
利斯出版公司]来计算,或者优选通过fast db数据库基于以下参数计算。不匹配罚分:1空位罚分:1空位尺寸罚分:0.33接合罚分:30
[0105]
适用算法的实例为pileup。pileup使用渐进式成对比对由一组相关序列产生多序列比对。其还可绘制显示用于产生比对的丛集关系的树形图。pileup使用feng和doolittle(1987)j.mol.evol.[分子进化杂志]35:351-60的渐进性比对方法的简化形式;该方法类似于higgins和sharp(1989)cabios 5:151-3所述的方法。适用pileup参数包括预设空隙权重3.00、预设空隙长度权重0.10及加权末端空隙。
[0106]
适用算法的另一实例为以下中所述的blast算法:altschul等人(1990)j.mol.biol.[分子生物学杂志]215:403-10;altschul等人(1997)nucleic acids res.[核酸研究]25:3389-402;和karin等人(1993)proc.natl.acad.sci.usa[美国国家科学院院刊]90:5873-87。特别适用的blast程序为自altschul等人(1996)methods in enzymology[酶学方法]266:460-80获得的wu-blast-2程序。wu-blast-2使用若干检索参数,其中大部分设定成默认值。用以下值设定可调参数:重叠间隔=i、重叠分数=0.125、字临限值(t)=ii。hsp s及hsp s2参数为动态值且通过程序本身视特定序列的组成及检索目的序列所对照的特定数据库的组成而确立;然而可调节这类值以提高敏感性。
[0107]
额外的适用算法为altschul等人(1993)nucl.acids res.[核酸研究]25:3389-402所报告的带空隙的blast。带空隙的blast使用blosum-62取代计分;临限值t参数设定成9;二次打击法(two-hit method)用于触发无空隙的延伸部分,加入空隙长度k,代价为10+
k;xu设定成16,并且xg在数据库检索阶段设定成40,并且在算法输出阶段设定成67。空隙比对由对应于约22比的计分触发。
[0108]
通常,本文所披露的蛋白质和其变体(包括fra的变体、her2的变体、微管蛋白序列的变体及抗体可变结构域的变体(包括单个变体cdr))与本文所述序列之间的氨基酸同源性、相似性或一致性为至少80%,并且更典型地优选具有至少85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、几乎100%或100%的增加同源性或一致性。
[0109]
以类似方式,关于抗体及本文所识别的其他蛋白质的核酸序列的“核酸序列一致性百分比(%)”被定义为候选序列中与抗原结合蛋白编码序列中的核苷酸残基相同的核苷酸残基的百分比。具体的方法利用设定成默认参数的wu-blast-2的blastn模块,其中重叠间隔和重叠分数分别设定成1和0.125。
[0110]
尽管引入氨基酸序列变化的位点或区域为预先确定的,但突变本身无需预先确定。举例而言,为使给定位点处的突变的效能优化,可在靶密码子或区域处进行随机诱变且筛选经表达的抗原结合蛋白cdr变体的所需活性的最佳组合。用于在具有已知序列的dna中的预确定位点处进行取代突变的技术为众所周知的,例如mi3引物诱变及pcr诱变。
[0111]
接下来,将描述制备根据本发明实施例的式(i)所示的adc的方法。
[0112]
本发明实施例为制备式(i)所示的抗体-药物缀合物(adc)的方法,并且包括以下步骤1和步骤2。[在该式中,ab为抗体或其抗原结合片段,d为艾日布林,m为1至10的整数,并且p为1至8的整数。]步骤1:通过艾日布林或其盐与式(a)所示的化合物的反应获得式(b)所示的化合物的步骤。[在该式中,m为1至10的整数,并且x为苯氧基或硝基苯氧基。]
[在该式中,m为1至10的整数。]步骤2:通过式(b)所示的化合物与ab的反应获得式(i)所示的抗体-药物缀合物的步骤。
[0113]
步骤1为通过艾日布林或其盐与式(a)所示的化合物的反应获得式(b)所示的化合物的步骤。
[0114]
艾日布林可为游离形式的艾日布林,或者可为艾日布林的盐。艾日布林的盐的实例包括艾日布林甲磺酸盐。在游离形式的艾日布林的情况下,所用的艾日布林或其盐的量可为1g至1000g,或者可为10g至300g。
[0115]
式(a)所示的化合物为对应于adc中接头部分的化合物,其末端的马来酰亚胺结构与抗体有反应性,并且其另一侧的末端x与艾日布林有反应性。x为苯氧基或硝基苯氧基。硝基苯氧基可为邻硝基苯氧基、间硝基苯氧基和对硝基苯氧基中的任一者。当x为苯氧基或硝基苯氧基时,x与艾日布林末端处的伯氨基有反应性。式(a)所示的化合物可使用以下所述方法制备。
[0116]
相对于1mol艾日布林,所用的式(a)所示的化合物的量可为0.5mol至2.0mol、0.6mol至3.0mol、1.0mol至2.0mol或1.3mol至1.8mol。
[0117]
在步骤1中,可使用碱。碱不受限制,只要其不抑制艾日布林与式(a)所示的化合物的反应即可,并且碱的实例包括叔胺(如三乙胺或n,n-二异丙基乙胺)和含氮芳族化合物(如吡啶或2,6-二甲基吡啶)。相对于1mol艾日布林,所用的碱的量可为0.5mol至3.0mol、1.0mol至2.0mol或1.1mol至1.5mol。
[0118]
步骤1可在不存在溶剂的情况下进行或在溶剂中进行,并且优选在溶剂中进行。溶剂不受限制,只要其不抑制艾日布林与式(a)所示的化合物的反应即可,并且溶剂的实例包括n,n-二甲基甲酰胺(dmf)、二甲亚砜(dmso)、n-甲基吡咯烷酮(nmp)和吡啶。相对于1g艾日布林,所用的溶剂的量可为5ml至20ml或6ml至15ml。
[0119]
步骤1中的反应温度不受限制,只要其为艾日布林与式(a)所示的化合物的反应进行的温度即可。反应温度可为正常温度,或为20℃至25℃。
[0120]
为促进步骤1的反应,可使用促进剂如4-二甲氨基吡啶。相对于1mol艾日布林,所用的促进剂的量可为0.01g至0.8g或0.1g至0.3g。
[0121]
在下文中,将描述纯化方法的实例。然而,纯化方法不限于该实例,并且纯化可使用化学中已知的方法进行。当步骤1的方法完成时,反应混合物可在反相柱上纯化。反相柱是例如其中使用具有十八基(c18)的硅胶作为填料的柱。将反应混合物置于反相柱顶上,并且用极性溶剂如乙腈或水来萃取。任选地,优选使用乙酸或类似物以使萃取溶剂的ph为酸
性的。将二氯甲烷添加至获得的萃取物中,将形成的式(b)所示的化合物输送到二氯甲烷层(有机层)。在萃取期间,任选地,可用碳酸氢钠水溶液调节ph。获得的有机层可用剩余的酸来中和,如碳酸氢钠水溶液。将获得的有机层减压浓缩以将残余物溶解在二氯甲烷、甲醇或类似物中,并且将溶液逐滴添加到戊烷中。结果,析出式(b)所示的化合物。获得的固体用戊烷洗涤,并且减压干燥。结果,可获得所需的化合物。
[0122]
步骤2为通过式(b)所示的化合物与ab的反应获得式(i)所示的抗体-药物缀合物的步骤。抗体部分(ab)中的半胱氨酸残基与式(b)所示的化合物中的马来酰亚胺结构经历迈克尔加成(michael addition),从而在其间形成共价键。多个式(b)所示的化合物可与一个抗体部分ab结合。形成的键的数量对应于式(a)中的p。
[0123]
对于抗体部分ab,所用的式(b)所示的化合物的量可为1.0mol至8.0mol或3.0mol至5.0mol。
[0124]
典型地,步骤2在缓冲溶液中进行。缓冲溶液不受限制,只要其不改变要使用的抗体ab并且不抑制与式(b)所示的化合物的结合即可。缓冲溶液可为磷酸盐缓冲溶液、硼酸盐缓冲溶液、三(羟甲基)氨基甲烷缓冲溶液、乙二胺四乙酸缓冲溶液或其任何组合。缓冲溶液的ph优选为6.0至8.0,且更优选为6.5至7.5。
[0125]
在步骤2中,可将极性有机溶剂添加到缓冲溶液中。极性有机溶剂不受限制,只要其能与缓冲溶液混合并且能改善式(b)所示的化合物的溶解度即可。例如,可将式(b)所示的化合物溶解在极性有机溶剂中的溶液添加到溶解了抗体ab的缓冲溶液中。
[0126]
极性有机溶剂的实例包括n,n-二甲基甲酰胺、n,n-二甲基乙酰胺和二甲亚砜。相对于1mg式(b)所示的化合物,所用的有机溶剂的量可为60ml至300ml、110ml至240ml、130ml至210ml或140ml至180ml。
[0127]
步骤2中的反应温度不受限制,只要其为式(b)所示的化合物与抗体ab的反应进行的温度即可。反应温度可为正常温度,或为20℃至25℃。
[0128]
更具体而言,反应温度如下。首先,将抗体ab通过过滤器(渗透膜)过滤并通过向其添加缓冲溶液来溶解。通过将tcep-hcl(三(2-羧乙基)膦盐酸盐)添加至获得的溶液中进行部分还原,抗体分子中的二硫键被裂解以形成巯基。接下来,添加式(b)所示的化合物或式(b)所示的化合物溶解于极性有机溶剂中的溶液以使式(b)所示的化合物与抗体彼此结合。当步骤2的反应结束时,可添加,例如,n-乙酰半胱氨酸。使n-乙酰半胱氨酸与剩余的式(b)所示的化合物反应并且还使其与通过部分还原形成的巯基反应。
[0129]
在下文中,将描述纯化方法的实例。然而,纯化方法不限于该实例,并且纯化可使用化学中已知的方法进行。在结束反应之后,使用切向流过滤方法(tff)将反应溶液的缓冲溶液替换为另一种缓冲溶液。接下来,添加柠檬酸水溶液,通过过滤器过滤,并且用缓冲溶液纯化。
[0130]
这里,将描述制备式(a)所示的化合物的方法。式(a)所示的化合物可例如由式(1)所示的化合物和式(2)所示的化合物通过如下所述的两步来制备。
[0131]
步骤3为活化式(1)所示的化合物的羧基并且将式(1)所示的化合物与式(2)所示的化合物缩合的步骤。通过式(1)所示的化合物和式(2)所示的化合物的缩合获得式(3)所示的化合物。
[0132]
式(1)所示的化合物可获得自东京化成工业株式会社(tokyo chemical industry co.,ltd.),商品名为“mal-peg
2-酸”(目录代码:m3203)。此外,式(1)所示的化合物可用有机化学中已知的方法使用丙烯酸叔丁酯及类似物与具有相应长度的聚乙二醇作为起始材料来制备。
[0133]
相对于1mol式(2)所示的化合物,所用的式(1)所示的化合物的量可为1.0mol至1.5mol或1.1mol至2.0mol。
[0134]
式(2)所示的化合物可获得自东京化成工业株式会社,商品名为“fmoc-val-cit-pab-oh”(目录代码:f1223)。此外,式(2)所示的化合物可用有机化学中已知的方法使用n-fmoc-瓜氨酸、对氨基苯甲醇和n-fmoc-缬氨酸来制备。“fmoc”是一种氨基保护基,其为9-芴基甲氧基羰基。
[0135]
优选步骤3在缩合剂存在下进行。缩合剂不受限制,只要其能加快羧酸与伯胺的缩合反应即可,并且缩合剂的实例包括二氯己基碳二亚胺(dcc)、1-(3-二甲氨基丙基)-3-乙基碳二亚胺和4-(4,6-二甲氧基-1,3,5-三嗪-2-基)-4-甲基吗啉鎓氯化物(dmt-mm)。
[0136]
相对于1mol式(1)所示的化合物,所用的缩合剂的量可为1.0mol至2.0mol或1.3mol至1.5mol。
[0137]
在步骤3中,可使用碱。碱不受限制,只要其不抑制式(1)所示的化合物与式(2)所示的化合物的反应即可,并且碱的实例包括叔胺(如三乙胺或n,n-二异丙基乙胺)和含氮芳族化合物(如吡啶或2,6-二甲基吡啶)。相对于1mol式(1)所示的化合物,所用的碱的量可为0.5mol至2.0mol、1.0mol至1.5mol或1.1mol至1.3mol。
[0138]
步骤3可在不存在溶剂的情况下进行或在溶剂中进行,并且优选在溶剂中进行。溶剂不受限制,只要其不抑制式(1)所示的化合物和与式(2)所示的化合物的反应即可,并且溶剂的实例包括n,n-二甲基甲酰胺(dmf)、四氢呋喃(thf)、甲醇(meoh)及其混合溶剂。相对于1g式(1)所示的化合物,所用的溶剂的量可为10ml至40ml或20ml至30ml。
[0139]
步骤3中的反应温度不受限制,只要其为式(1)所示的化合物与式(2)所示的化合物的反应进行的温度即可。反应温度可为正常温度,或为15℃至35℃。
[0140]
步骤4为通过使用酰化剂对式(3)所示的化合物中的羟基进行酰化来获得式(a)所示的化合物的步骤。
[0141]
所用的式(3)所示的化合物的量可根据反应适当选择。例如,所用的式(3)所示的化合物的量可为10g至500g或100g至300g。
[0142]
酰化剂的实例包括碳酸二苯酯、二(4-硝基苯基)碳酸酯、二(2-硝基苯基)碳酸酯、二(3-硝基苯基)碳酸酯、氯甲酸苯酯、氯甲酸4-硝基苯基酯、氯甲酸2-硝基苯基酯和氯甲酸3-硝基苯基酯。酰化剂的一部分对应于式(a)中的x,并且酰化剂的种类可根据所需的x基团的选择来选择。
[0143]
相对于1mol式(3)所示的化合物,所用的酰化剂的量可为1.0mol至5.0mol或2.0mol至4.0mol。
[0144]
步骤4可在不存在溶剂的情况下进行或在溶剂中进行,并且优选在溶剂中进行。溶剂不受限制,只要其不抑制式(3)所示的化合物的酰化反应即可,溶剂的实例包括n,n-二甲基甲酰胺(dmf)、n,n-二甲基乙酰胺、甲苯、二甲亚砜(dmso)和n,n-二甲基乙酰胺(dma)。相对于1g式(3)所示的化合物,所用的溶剂的量可为5ml至20ml或6ml至15ml。
[0145]
步骤4中的反应温度不受限制,只要其为式(3)所示的化合物的酰化反应进行的温度即可。反应温度可为正常温度,或为20℃至25℃。实例
[0146]
在下文中,将使用生产实例和对比生产实例来更详细地描述本发明。实例中使用的缩写与本领域中的缩写相同,例如,如下所示。dipea:n,n-二异丙基乙胺dma:n,n-二甲基乙酰胺dmf:n,n-二甲基甲酰胺dmt-mm:4-(4,6-二甲氧基-1,3,5-三嗪-2-基)-4-甲基吗啉鎓氯化物edta:乙二胺四乙酸thf:四氢呋喃
[0147]
《生产实例1》(11s,14s)-14-[3-(氨甲酰氨基)丙基]-1-(2,5-二氧代-2,5-二氢-1h-吡咯-1-基)-n-[4-(羟甲基)苯基]-9,12-二氧代-11-(丙-2-基)-3,6-二氧杂-10,13-二氮杂十五烷-15-酰胺
[0148]
将(2s)-2-{[(2s)-2-氨基-3-甲基丁酰基]氨基}-5-(氨甲酰氨基)-n-[4-(羟甲基)苯基]戊酰胺(184g)、3-{2-[2-(2,5-二氧代-2,5-二氢-1h-吡咯-1-基)乙氧基]乙氧基}丙酸(150g)、dmt-mm(174g)、甲醇(2.76l)和thf(2.76l)的混合物在氮气气氛中于15℃至35℃搅拌24小时。将反应混合物减压浓缩,并且向其中添加乙腈。将析出的沉淀物过滤并进一步用乙腈洗涤。将获得的固体与乙腈混合并过滤以获得固体。将获得的固体减压干燥以获得标题化合物(267g,89%产率)。
[0149]
《生产实例2》(4-{[(11s,14s)-14-[3-(氨甲酰氨基)丙基]-1-(2,5-二氧代-2,5-二氢-1h-吡
咯-1-基)-9,12,15-三氧代-11-(丙-2-基)-3,6-二氧杂-10,13-二氮杂十五烷-15-基]氨基}苯基)甲基=4-硝基苯基=碳酸酯
[0150]
将生产实例1中获得的化合物(250g)、二(4-硝基苯基)碳酸酯(615g)、dipea(157g)和dmf(5.0l)的混合物在氮气气氛中于15℃至35℃搅拌3小时。将反应混合物减压浓缩并在硅胶柱(二氯甲烷/丙酮)上纯化,并且将包含标题化合物的部分减压浓缩。结果,获得标题化合物(162g,51%产率),其为固体。
[0151]
《生产实例3》(4-{[(11s,14s)-14-[3-(氨甲酰氨基)丙基]-1-(2,5-二氧代-2,5-二氢-1h-吡咯-1-基)-9,12,15-三氧代-11-(丙-2-基)-3,6-二氧杂-10,13-二氮杂十五烷-15-基]氨基}苯基)甲基={(2s)-2-羟基-3-[(2r,3r,3as,7r,8as,9s,10ar,11s,12r,13ar,13bs,15s,18s,21s,24s,26r,28r,29as)-3-甲氧基-26-甲基-20,27-二亚甲基二十六氢-11,15:18,21:24,28-三环氧基-7,9-桥亚乙基-12,15-桥亚甲基-9h,15h-呋喃并[3,2-i]呋喃并[2',3':5,6]吡喃并[4,3-b][1,4]二氧杂环二十五-5(4h)-酮-2-基]丙基}氨基甲酸酯
[0152]
将艾日布林甲磺酸盐(93g)、dipea(26ml)、生产实例2中获得的化合物(116g)和dmf(930ml)的混合物在氮气气氛中于20℃至25℃搅拌20小时。将反应混合物在反相柱(商品名:kromasil c18)(乙腈/水/乙酸)上纯化,并将包含标题化合物的部分用二氯甲烷萃取。将有机层用碳酸氢钠水溶液和水依次洗涤,并且随后减压浓缩。将浓缩的残余物溶解在二氯甲烷、甲醇和乙酸的混合溶剂中,并且将溶液逐滴添加到戊烷中。将析出的沉淀物过滤,并且将获得的固体用戊烷洗涤并减压干燥。结果,获得标题化合物(109.6g,71%产率)。1h-nmr(400mhz,cd3od):δ(ppm)7.59(d,j=8.4hz,2h),7.31(d,j=8.4hz,2h),6.81(s,2h),5.13(s,1h),5.06(d,j=12.4hz,1h),5.02(s,1h),5.01(d,j=12.4hz,1h),4.87(s,1h),4.82(s,1h),4.71(t,j=4.0hz,1h),4.61(t,j=4.4hz,1h),4.50(dd,j=5.2,9.2hz,1h),4.47(d,j=10.8hz,1h),4.32-4.27(m,2h),4.19(dd,j=6.8,11.6hz,1h),4.13-4.07(m,2h),3.98(t,j=10.4hz,1h),3.88-3.82(m,3h),3.76-3.64(m,6h),3.62-3.51(m,6h),3.38(s,3h),3.22-3.08(m,4h),2.93(dd,j=2.4,9.6hz,1h),2.92-2.84(m,
1h),2.76-2.63(m,2h),2.52(t,j=6.0hz,2h),2.44-2.29(m,5h),2.21-1.97(m,8h),1.93-1.83(m,3h),1.80-1.66(m,5h),1.66-1.28(m,10h),1.11(d,j=6.4hz,3h),1.07-1.01(m,1h),0.99(d,j=6.8hz,3h),0.97(d,j=6.4hz,3h)。lcms(m+h):m/z 1374.9
[0153]
《对比生产实例1》
[0154]
《对比生产实例1-1》4-{[(2s)-5-(氨甲酰氨基)-2-{[(2s)-2-{[(9h-芴-9-基甲氧基)羰基]氨基}3-甲基丁酰基]氨基}戊酰基]氨基}苄基={(2s)-2-羟基-3-[(2r,3r,3as,7r,8as,9s,10ar,11s,12r,13ar,13bs,15s,18s,21s,24s,26r,28r,29as)-3-甲氧基-26-甲基-20,27-二亚甲基二十六氢-11,15:18,21:24,28-三环氧基-7,9-桥亚乙基-12,15-桥亚甲基-9h,15h-呋喃并[3,2-i]呋喃并[2',3':5,6]吡喃并[4,3-b][1,4]二氧杂环二十五-5(4h)-酮-2-基]丙基}氨基甲酸酯
[0155]
将艾日布林甲磺酸盐(93g)、dipea(25ml)、4-{[(2s)-5-(氨甲酰氨基)-2-{[(2s)-2-{[(9h-芴-9-基甲氧基)羰基]氨基}3-甲基丁酰基]氨基}戊酰基]氨基}苄基=4-硝基苯基碳酸酯(103.6g)和dmf(930ml)的混合物在氮气气氛中于20℃至25℃搅拌16小时。
[0156]
《对比生产实例1-2》4-{[(2s)-2-{[(2s)-2-氨基-3-甲基丁酰基]氨基}-5-(氨甲酰氨基)戊酰基]氨基}苄基={(2s)-2-羟基-3-[(2r,3r,3as,7r,8as,9s,10ar,11s,12r,13ar,13bs,15s,18s,21s,24s,26r,28r,29as)-3-甲氧基-26-甲基-20,27-二亚甲基二十六氢-11,15:18,21:24,28-三环氧基-7,9-桥亚乙基-12,15-桥亚甲基-9h,15h-呋喃并[3,2-i]呋喃并[2',3':5,6]吡喃并[4,3-b][1,4]二氧杂环二十五-5(4h)-酮-2-基]丙基}氨基甲酸酯
[0157]
将二乙胺(234ml)添加到反应混合物中并于20℃至25℃搅拌0.5小时。将乙酸乙酯和盐酸添加到反应混合物中,并将水层用庚烷洗涤。将甲基四氢呋喃和碳酸钾氯化钠水溶液添加到水层中,并且将有机层用氯化钠水溶液洗涤。将有机层用硫酸镁干燥并且减压浓缩。1h-nmr(400mhz,cd3od):δ(ppm)7.56(d,j=8.4hz,2h),7.32(d,j=8.4hz,2h),5.14(s,1h),5.06(d,j=12.4hz,1h),5.03(s,1h),5.01(d,j=12.4hz,1h),4.87(s,1h),4.83(s,1h),4.71(t,j=4.4hz,1h),4.62(t,j=4.4hz,1h),4.57(dd,j=4.8,8.8hz,1h),4.47(d,j=10.8hz,1h),4.32-4.27(m,2h),4.18(dd,j=4.8,6.4hz,1h),4.13-4.07(m,2h),3.98(t,j=10.4hz,1h),3.88-3.82(m,3h),3.76-3.70(m,4h),3.60(d,j=6.0hz,1h),3.38(s,3h),3.26-3.10(m,3h),2.93(dd,j=2.0,11.2hz,1h),2.91-2.84(m,1h),2.75-2.64(m,2h),2.44-2.29(m,5h),2.21-1.97(m,8h),1.93-1.83(m,3h),1.79-1.72(m,5h),1.68-1.29(m,8h),1.11(d,j=6.8hz,3h),1.07-1.01(m,1h),1.06(d,j=7.2hz,3h),1.02(d,j=7.2hz,3h)lcms(m+h):m/z1135.7
[0158]
《对比生产实例1-3》(4-{[(11s,14s)-14-[3-(氨甲酰氨基)丙基]-1-(2,5-二氧代-2,5-二氢-1h-吡咯-1-基)-9,12,15-三氧代-11-(丙-2-基)-3,6-二氧杂-10,13-二氮杂十五烷-15-基]氨基}苯基)甲基={(2s)-2-羟基-3-[(2r,3r,3as,7r,8as,9s,10ar,11s,12r,13ar,13bs,15s,18s,21s,24s,26r,28r,29as)-3-甲氧基-26-甲基-20,27-二亚甲基二十六氢-11,15:18,21:24,28-三环氧基-7,9-桥亚乙基-12,15-桥亚甲基-9h,15h-呋喃并[3,2-i]呋喃并[2',3':5,6]吡喃并[4,3-b][1,4]二氧杂环二十五-5(4h)-酮-2-基]丙基}氨基甲酸酯
[0159]
将41-[2-(2-{3-[(2,5-二氧代吡咯烷-1-基)氧基]-3-氧代丙氧基}乙氧基)乙基]-1h-吡咯-2,5-二酮(47.9g)、dipea(20ml)和dmf(913ml)添加至对比生产实例1-2中获得的浓缩残余物中,并且于20℃至25℃搅拌3小时。将反应混合物在反相柱(商品名:silmerck 10013)(乙腈/水/乙酸)上纯化,并将包含标题化合物的部分用二氯甲烷萃取。将有机层用碳酸氢钠水溶液和水洗涤,并且随后减压浓缩。将浓缩的残余物溶解在二氯甲烷、甲醇和乙酸中,并且将溶液逐滴添加到戊烷中。结果,过滤出析出的沉淀物。将获得的固体用戊烷洗涤并且减压干燥。结果,获得了标题化合物(88.1g,三步产率为57%)。
[0160]
《生产实例4》将1493ml用于稀释的缓冲水溶液(10mmol/l磷酸三钠、100mmol/l氯化钠、3w/v%蔗糖,ph 6.5)和1098ml用于ph调节的缓冲溶液(0.25mol/l三(羟甲基)氨基甲烷盐酸盐、20mmol/l edta,ph 7.7)添加到7854ml含有morab-003的缓冲水溶液(26.6mg/ml morab-003、10mmol/l磷酸三钠、100mmol/l氯化钠、3w/v%蔗糖,ph 6.5)中。于20℃添加三(2-羧乙基)膦水溶液(10mmol/l,311g)并搅拌2.5小时。添加生产实例3中获得的化合物的dma溶液(8.37mmol/l,809ml)并搅拌0.5小时。添加n-乙酰半胱氨酸水溶液(30mmol/l,452g)以停止反应并搅拌0.5小时。将抗体-药物缀合物(adc)通过透析过滤在以下条件下纯化。(纯化条件)过滤器(渗透膜):pellicon 3(1.14m
2 30kda
×
1,0.57m230kda
×
1)tmp(跨膜压差):15psi另外的缓冲溶液:25mmol/l的柠檬酸水溶液(ph 6.3)温度:17.0℃至23.0℃
渗透:163.2kg
[0161]
通过添加25mmol/l柠檬酸水溶液(3013g,ph 6.3)和5668g用于调节的缓冲水溶液(25mmol/l柠檬酸、1mol/l蔗糖,0.24w/v%,聚山梨醇酯80,ph 6.3),获得了adc水溶液(蛋白质浓度:10.6mg/ml,总重量:20.9kg,adc含量:213.430g,99%产率)。接下来,将adc水溶液进行无菌过滤(millipore durapore pvdf)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1