一种基于生成式对话技术的医疗问答系统
本发明属于医疗保健信息学领域,具体涉及一种基于生成式对话技术的医疗问答系统。
背景技术:
在人工智能技术蓬勃发展的今天,人机对话技术有着广泛的运用,例如在智能音箱、智能客服等场景中,人机对话技术已经变得十分常见。但是,在医疗领域,多数场景下的患者问题依然是由人工进行回答,大部分在线问诊服务都需要医生亲自去回答患者问题,而其中的很多问题则是重复或相似的,如果能够将人机对话技术应用进来,则能够有效节约医疗资源。
对话系统一般分为三类:基于规则的对话系统、检索式对话系统和生成式对话系统。
其中,基于规则的对话系统指的是人为设定一定的回复规则,通过对提问者的话进行关键词提取和匹配,再经过基于规则的语义分析,给出事先设定好的回复格式。
常用的检索式对话有两种,第一种是通过问题匹配问题再到答案的检索方式,即通过计算用户提出的问题与数据库里已有问题的相似度,找到最相似的问题再输出相应的答案。另一种主流的检索式对话采用的是通过用户提出的问题直接在数据中搜寻答案的方式,在这种方式中,最需要解决的是问题和回复之间的信息差异。现有的解决信息差异方法有依存句法分析、主题模型等。在检索式对话系统中需要依赖数据库进行回复的检索,从而得到相应的答案。
生成式对话则无需数据库,可以通过问题直接生成回复。在生成式对话系统中,用到的主要是编码-解码模型,也叫做sequencetosequence模型,其中最常见的有卷积神经网络(cnn)和循环神经网络(rnn)等。
通过生成式对话技术来构建在线医疗问答系统,一方面能在数据量有限的情况下生成较为准确的回复,而无需像检索式对话系统一样需要庞大的数据库支持;另一方面人机对话技术在医疗问答中的运用,也可以简化患者的问诊流程,同时也可以减轻问诊平台医生的工作量,具有十分积极的社会效益。然而,现有的生成式对话系统都是直接对患者的问题进行预测,而不会预先分析该问题对应的所属科室,从而可能因为所属科室错误从而导致答复与问题毫无关系的情况。并且,也会导致答复文本生成的错误率较高。
技术实现要素:
为解决上述问题,提供了一种无需借助依赖庞大检索数据库就能自动生成与患者问题相对应的回复文本的问答系统,本发明采用了如下技术方案:
本发明提供了一种基于生成式对话技术的医疗问答系统,用于针对患者输入的问题文本生成相应的回复文本,其特征在于,包括:科室分类模块,利用预先训练好的科室分类模型对问题文本进行分类得到科室编码向量;科室编号生成模块,将科室编码向量根据字典转化得到与科室相对应的第一编号向量,将问题文本根据字典转化得到第二编号向量,将第一编号向量与第二编号向量进行拼接得到拼接编号向量;以及回复文本生成模块,将拼接编号向量输入预先训练好的生成式对话模型中,生成回复文本,其中,科室分类模型以及生成式对话模型的训练过程包括如下步骤:步骤s1,获取至少包括问题内容与医生答复的医疗问答数据集,对该医疗问答数据集进行整理,从而得到问题内容与医生答复相对应存储的组合数据;步骤s2,将组合数据中的问题内容作为预先搭建好的科室学习模型的输入,并将该问题内容所属的科室作为科室标签,从而训练得到用于将患者问题分类到具体科室的科室分类模型;步骤s3,将问题内容输入科室分类模型得到预测科室名称,并将该预测科室名称与对应的问题内容拼接得到拼接文本;步骤s4,将拼接文本输入预先搭建好的回复文本学习模型,并将医生答复作为答复标签,从而训练得到生成式对话模型。
根据本发明提供的一种基于生成式对话技术的医疗问答系统,还可以具有这样的技术特征,其中,步骤s1包括如下子步骤:步骤s1-1,获取至少包括问题内容与医生答复医疗问答数据集,并删除内容缺失或存在歧义的数据,从而得到精选数据集;步骤s1-2,对精选数据集中每条数据的问题内容按照对应的科室进行标记,得到问题内容与医生答复相对应存储的组合数据。
根据本发明提供的一种基于生成式对话技术的医疗问答系统,还可以具有这样的技术特征,其中,步骤s2包括如下子步骤:步骤s2-1,利用字典将问题内容中每个字转化为相应的数字形式的编号作为文字编号;步骤s2-2,科室学习模型中的编码器将文字编号组成的向量转化为带有上下文语意信息的问题内容向量化表示作为问题向量表示;步骤s2-3,科室学习模型中的全连接层根据问题向量表示进行分类,得到分类结果向量,用于表示问题文本对应所有科室的概率,将其中概率最大的科室作为分类预测结果;步骤s2-4,基于分类预测结果以及科室标签的交叉熵损失loss通过基于梯度下降法的反向传播进行训练更新,从而训练得到用于将患者问题分类到具体科室的科室分类模型,
式中,n为科室的总类别数,pi(x)为科室标签,qi(x)为分类向量中的第i位的数值,即科室学习模型预测的属于当前科室的概率。
根据本发明提供的一种基于生成式对话技术的医疗问答系统,还可以具有这样的技术特征,其中,科室编码向量由one-hot编码方法得到。
根据本发明提供的一种基于生成式对话技术的医疗问答系统,还可以具有这样的技术特征,其中,科室分类模型为bert模型,生成式对话模型为基于transformer架构的bert-gpt模型。
发明作用与效果
根据本发明的一种基于生成式对话技术的医疗问答系统,由于回复文本生成模块,将拼接编号输入预先训练好的生成式对话模型中从而生成回复文本,因此相较于传统的基于检索式的对话系统而言,无需依赖庞大检索数据库,只要利用训练好的生成式对话模型就能直接得到与患者输入的问题文本对应的医生回复文本,智能高效。
另外,由于科室编号生成模块将科室编码向量根据预定的字典文件转化与科室相对应的第一编号,将问题文本根据字典文件转化为第二编号,将第一科室编号与第二科室编号进行拼接得到拼接编号,因此,对患者问题的范围进行了进一步地限定,从而有效避免了在生成的回复与问题范围不相符问题,进一步提高了生成回复的准确性。
通过本发明的基于生成式对话技术的医疗问答系统可以在无庞大检索数据库下,实时自动生成与患者问题对应的问题,缓解了医疗资源的紧张,又能快速解决患者的问题,智能高效。
附图说明
图1为本发明实施例的一种基于生成式对话技术的医疗问答系统的结构框图;
图2为本发明实施例的一种基于生成式对话技术的医疗问答系统工作过程的流程图;
图3为本发明实施例的one-hot编码过程示意图;
图4为本发明实施例的科室分类模型以及生成式对话模型的训练过程的流程图;
图5为本发明实施例的回复文本生成模块工作过程的流程示意图;
图6为本发明实施例的一种基于生成式对话技术的医疗问答系统工作过程的流程图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的一种基于生成式对话技术的医疗问答系统作具体阐述。
<实施例>
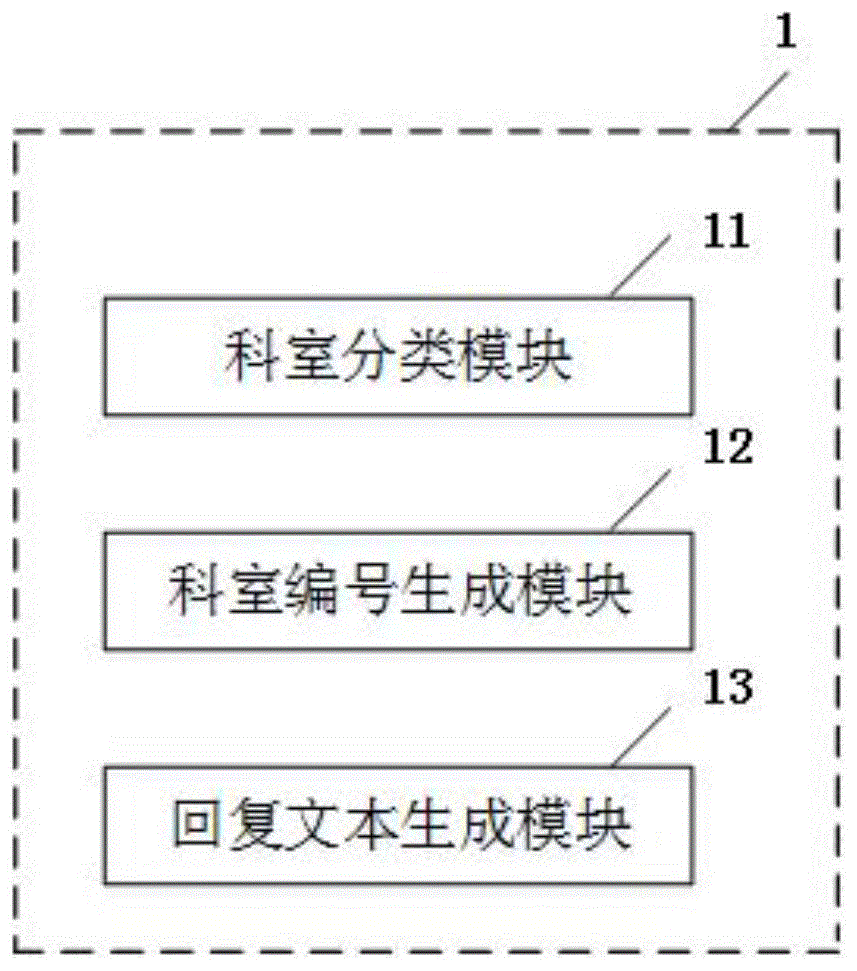
图1为本发明实施例的一种基于生成式对话技术的医疗问答系统的结构框图。
如图1所示,一种基于生成式对话技术的医疗问答系统1包括科室分类模块11、科室编号生成模块12以及回复文本生成模块13。
图2为本发明实施例的一种基于生成式对话技术的医疗问答系统工作过程的流程图。
如图2所示,科室分类模块11利用预先训练好的科室分类模型对问题文本进行分类得到科室编码向量(即one-hot编码向量)。
其中,科室分类模型科室分类模型为bert模型,至少包括编码器以及全连接层(即分类层)。
具体地,科室分类模型先将问题文本(例如“我头有点疼”)中每个字根据字典文件转化为问题的token向量(对应的为(1124,2765,3489,173,8876,1,1,1…………)token向量),再将问题的token向通过科室分类模型中的编码器转化为问题的embedding,然后通过科室分类模型中的分类层(即全连接层以及softmax网络层)将问题的embedding转化为代表相应类别的科室编码向量(即科室的one-hot向量)。
另外,图2中字典文件示意部分,每个文字前面的数字是第n行的序号,这个序号就是这个字的token,假设“我”、“头”、“有”、“点”、“疼”的token分别为1124、2765、3489、173、8676,则这句话对应的输入向量为(1124,2765,3489,173,8876),由于神经网络的输入维度是固定的,假设最长的一句话长度为100个字,那么当输入的句子长度小于100时,需要用一个默认的token将原始的向量长度填充到100,再输入神经网络,假设这个默认的token为1,那么原始的向量会被扩充为长度为100的向量:(1124,2765,3489,173,8876,1,1,1,1,1,1,1,1…………)。
图3为本发明实施例的one-hot编码过程示意图。
如图3所示,one-hot编码过程具体为:
假设有三个科室:内科、骨科、皮肤科,那么one-hot编码分别是(1,0,0)、(0,1,0)、(0,0,1),将科室汉字根据字典文件进行编码,分别得到对应的科室的token向量(108,27)、(1996,457)、(86,2293,25)(此时无需将token向量扩充到固定长度),再将one-hot编码对应到token向量上从而得到对应的科室字典,即内科对应为(1,0,0):(108,27)、骨科对应为(0,1,0):(1996,457)、皮肤科对应为(0,0,1):(86,2293,25)。
图4为本发明实施例的科室分类模型以及生成式对话模型的训练过程的流程图。
如图4所示,科室分类模型以及生成式对话模型的训练过程包括如下步骤:
步骤s1,获取至少包括问题内容与医生答复的医疗问答数据集,对该医疗问答数据集进行整理,从而得到问题内容与医生答复相对应存储的组合数据。
其中,步骤s1包括如下子步骤:
步骤s1-1,获取至少包括问题内容与医生答复的医疗问答数据集,对该医疗问答数据集进行整理,从而得到问题内容与医生答复相对应存储的组合数据;
步骤s1-2,对精选数据集中每条数据的问题内容按照对应的科室进行标记,得到问题内容与医生答复相对应存储的组合数据。
步骤s2,将组合数据中的问题内容作为预先搭建好的科室学习模型的输入,并将该问题内容所属的科室作为科室标签,从而训练得到用于将患者问题分类到具体科室的科室分类模型。
其中,步骤s2包括如下子步骤:
步骤s2-1,利用字典将问题内容中每个字转化为相应的数字形式的编号作为文字编号;
步骤s2-2,科室学习模型中的编码器将文字编号组成的向量转化为带有上下文语意信息的问题内容向量化表示作为问题向量表示;
步骤s2-3,科室学习模型中的全连接层根据问题向量表示进行分类,得到分类结果向量,用于表示问题内容对应所有科室的概率,将其中概率最大的科室作为分类预测结果;
步骤s2-4,基于分类预测结果以及科室标签的交叉熵损失loss通过基于梯度下降法的反向传播进行训练更新,从而训练得到用于将患者问题分类到具体科室的科室分类模型,
式中,n为科室的总类别数,pi(x)为科室标签,qi(x)为分类向量中的第i位的数值,即科室学习模型预测的属于当前科室的概率。
步骤s3,将问题内容输入科室分类模型得到预测科室名称,并将该预测科室名称与对应的问题内容拼接得到拼接文本。
具体地,根据步骤s2-3分类向量中概率最大值获得对应的科室名称(即科室名称),将科室名称与问题内容拼接得到拼接文本。
步骤s4,将拼接文本输入预先搭建好的回复文本学习模型,并将医生答复作为答复标签,从而训练得到生成式对话模型。
具体地,利用字典将拼接文本中的每个字转化为拼接编码,并将该拼接编码输入到预先搭建好的回复生成学习模型中。
回复生成学习模型中的编码器将拼接编码转化为拼接向量,并输入到解码器中。
回复生成学习模型同样基于步骤s2-4中的交叉熵损失以及梯度下降法进行训练。
另外,回复生成学习模型中解码器的最后一层为softmax网络,可以输出概率最大的下一个字或者结束标志符。
科室编号生成模块12将科室编码向量根据字典转化与科室相对应的第一编号向量(第一id),将问题文本根据字典文件转化为第二编号向量(第二id),将第一编号向量与第二编号向量进行拼接得到拼接编号向量(拼接id)。
具体地,将科室编码向量(0,1,0,0......)根据字典转化为科室的token向量(86,2293,25)(即第一编号向量),并与问题文本对应的token向量(1124,2765,3489,173,8876,1,1,1…………)(即第二编号向量)拼接,得到拼接编号向量(86,2293,25,1124,2765,3489,173,8876,1,1,1…………)
图5为本发明实施例的回复文本生成模块工作过程的流程示意图。
如图5所示,回复文本生成模块13将拼接编号(86,2293,25,1124,2765,3489,173,8876,1,1,1…………)输入预先训练好的生成式对话模型中,生成回复文本(头有点疼可能是感冒的症状,需要多注意休息,多喝热水,严重时请及时到医院就诊)。
其中,生成式对话模型为基于transformer架构的bert-gpt结构模型,至少包括编码器以及解码器。
图6为本发明实施例的一种基于生成式对话技术的医疗问答系统工作过程的流程图。
如图6所示,一种基于生成式对话技术的医疗问答系统工作过程包括如下步骤:
步骤t1,科室分类模块11利用科室分类模型对问题文本中进行分类得到科室编码向量,然后进入步骤t2;
步骤t2,科室编号生成模块12将科室编码向量转化与科室相对应的第一编号向量,将问题文本转化为第二编号向量,将第一编号向量与第二编号向量进行拼接得到拼接编号向量,然后进入步骤t2;
步骤t3,回复文本生成模块13利用生成式对话模型根据拼接编号向量得到回复文本,然后进入结束状态。
实施例作用与效果
根据本实施例提供的基于生成式对话技术的医疗问答系统1,由于回复文本生成模块13,将拼接编号向量输入预先训练好的生成式对话模型中从而生成回复文本,因此相较于传统的基于检索式的对话系统而言,无需依赖庞大检索数据库,只要利用训练好的生成式对话模型就能直接得到与患者输入的问题文本对应的医生回复文本,智能高效。
另外,由于科室编号生成模块12将科室编码向量根据预定的字典文件转化与科室相对应的第一编号向量,将问题文本根据字典文件转化为第二编号向量,将第一编号向量与第二编号向量进行拼接得到拼接编号向量,因此,对患者问题的范围进行了进一步地限定,从而有效避免了在生成的回复与问题范围不相符问题,进一步提高了生成回复的准确性。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
实施例中,医疗问答数据集包括问题内容与医生答复,对该医疗问答数据集进行整理后得到问题内容与医生答复相对应存储的组合数据,在本发明的其他方案中,医疗问答数据集还i可以为包括问题内容、科室以及医生答复,经过整理后形成问题内容、科室以及医生答复相一一对应存储的组合数据。此时,可以直接将科室与对应的问题内容拼接得到拼接文本,用于训练生成式对话模型。
实施例中,医疗问答数据集包括问题内容与医生答复,对该医疗问答数据集进行整理后得到问题内容与医生答复相对应存储的组合数据,在本发明的其他方案中,对医疗问题数据集进行的整理还包括为每个问题内容打上科室标签,从而得到科室标签、问题内容以及医生答复一一对应存储的组合数据,此时,可以直接将科室标签与对应的问题内容拼接得到拼接文本,用于训练生成式对话模型。
- 还没有人留言评论。精彩留言会获得点赞!