一种基于fNIRS的阿尔兹海默症患者数据识别方法及系统与流程
一种基于fnirs的阿尔兹海默症患者数据识别方法及系统
技术领域
1.本发明属于病患数据识别技术领域,具体涉及一种基于fnirs的阿尔兹海默症患者数据识别方法及系统。
背景技术:
2.老年认知功能障碍是常见的神经系统性疾病,是仅次于脑血管疾病的神经科疾病,而阿尔茨海默病(ad)是老年认知功能障碍中最常见的一种症状。国内外常用认知功能评估量表作为ad初步筛查的工具,但是由于个体差异大、含有主观成分等原因,诊断效果较差。随着技术的发展,各种影像技术被广泛地应用于ad及脑部疾病的诊断和研究,比如:正电子断层扫描(pet),磁共振成像(mri),弥散张量成像(dti)等医学影像技术,但是这些影像技术通常诊断时间相对较长而且相对昂贵,不利于大规模快速筛查。还有一些研究者通过脑电erp(事件相关电位)、眼动(eye move-ment,em)以及脑电图等技术手段探索ad患者及其大脑认知功能状态,但其缺点是空间分辨率较差,难以定位信号发生源。另外,功能性磁共振成像(functional magnetic resonance imaging,fmri)虽然有极高的空间分辨率,但其时间分辨率相对较差,且其对被试者的活动限制较高。
3.功能性近红外光谱成像(functional near-infrared spectroscopy,fnirs)作为一种光学检测手段,将近红外光直射于头皮表面,通过测定大脑皮质中散射光的强度可间接检测出被试者执行任务过程中大脑特定区域氧合血红蛋白(oxyhemoglobin,hbo)浓度的变化,并以此反映大脑皮质的激活情况。fnirs具有无创、时间空间分辨率均较高、便携等优点,而且fnirs可以容忍被试采集数据时适度的移动状态,具备较好的抗噪声能力。
4.近几年,随着人工神经网络在自然语言处理(nlp)、图像识别(cv)等领域的快速的发展,神经网络的应用边界也快速拓宽。在ad检测领域,目前已有一些基于神经网络采用fnirs辅助诊断ad的相关研究,但是由于采集ad患者数据的流程较为复杂、成本较高,通常这些研究可采用的有标签训练数据较少,没有很好的发挥神经网络的学习能力,使得小数据量下的模型训练效果较差。
技术实现要素:
5.针对上述问题,本发明提供了一种基于fnirs的阿尔兹海默症患者数据识别方法,包括以下步骤:
6.sa:采用基于因果卷积神经网络的方式对fnirs数据做数据增扩;
7.sb:采用自监督学习和模型微调的方式对fnirs数据进行训练。
8.作为一种优选的技术方案,还包括以下步骤:
9.s1:采集fnirs数据;
10.s2:构建数据增扩网络;
11.s3:训练数据增扩网络;
12.s4:构建自监督模型;
13.s5:训练自监督模型;
14.s6:模型微调。
15.作为一种优选的技术方案,步骤1中单人单次实验数据的呈现方式为204*650的二维矩阵。
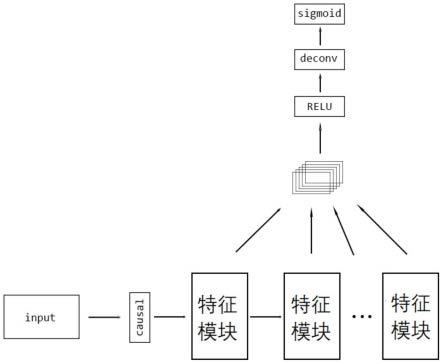
16.作为一种优选的技术方案,步骤2中所述数据增扩网络包括输入、卷积层、特征模块、relu激活函数、反卷积层,sigmoid激活函数;数据增扩网络输入一个204x650大小的二维矩阵,经过一层卷积层,后依次顺序经过若干个特征模块进行特征提取,特征模块首尾相连,每个特征模块会额外再输出一个旁支特征数据。将所有旁支特征数据作叠加后,输入到relu激活函数进行非线性变换,然后再做反卷积放大特征数据尺寸,使其与数据尺寸一致,再经过sigmoid激活函数使输出归一化到(-1,1)之间。
17.作为一种优选的技术方案,步骤2中所述特征模块输入、扩张卷积函数、tanh激活函数、sigmoid激活函数、2个反卷积层、2个输出;输入经过扩张卷积之后分别进入tanh激活函数和sigmoid激活函数得到两个激活后的矩阵,将两个激活后的矩阵相乘后分别经过两个不同的反卷积层得到两个输出,分别为旁支输出和后向输出,后向输出与作残差连接相加后得到第一输出,第一输出后接下一个特征模块的输入;旁支输出作为第二输出;每个所述特征模块的旁支输出保持数据尺寸一致,输入的数据和输出的数据尺寸保持一致。
18.所述特征模块的扩张卷积函数的扩张率是1、5、9、13、17、21中的一个。
19.作为一种优选的技术方案,步骤3包括以下分步骤:
20.s3.1:将输入的二维矩阵做随机变换,从204x650的二维矩阵中随机选出100个像素点,对这些像素点值的大小随机放大或缩小10%,然后将得到的二维矩阵数值归一化到(-1,1)之间;
21.s3.2:将随机变换后的二维矩阵输入到数据增扩网络进行训练。
22.作为一种优选的技术方案,步骤4所述自监督模型结构中,输入数据经过数据增扩网络生成出两个与相似的数据x1和x2,分别经过编码模块提取特征后得到f1和f2,然后再分别经过全连接和relu激活函数进行非线性变换后得到g1和g2,最后自监督模型的目标是最大化g1和g2的相似度。
23.所述编码模块中,输入经过若干个扩张卷积函数层后最终输出一维特征数据,各层之间采用残差连接,每层选用不一样的扩张率,扩张率选用1、5、9、13、17、21中的一个,另外每层将输入矩阵的通道分成20组分别进行卷积,每组输出矩阵的通道为5,然后将20组卷积后的输出合并在一起传入下一层;扩张卷积函数层的数量根据输入的二维矩阵大小确定。
24.作为一种优选的技术方案,步骤5包括以下分步骤:
25.s5.1:将输入的二维矩阵做随机变换,从204x650的二维矩阵中随机选出100个像素点,对这些像素点值的大小随机放大或缩小10%,然后将得到的二维矩阵数值归一化到(-1,1)之间;
26.s5.2:将随机变换后的二维矩阵输入到自监督模型中进行训练,通过最大化g1和g2的相似度计算相应的loss,使得loss大小不再更新。
27.作为一种优选的技术方案,步骤6中的模型微调包括将训练好的自监督模型的编码模块及其后的dense层参数拿出来,后接softmax层形成独立的分类网络,然后在采集的
原始真实数据上进行模型微调训练,得到最终的ad诊断模型。
28.本发明还提供了一种基于fnirs的阿尔兹海默症患者数据识别系统,包括以上任一所述的基于fnirs的阿尔兹海默症患者数据识别方法。
29.有益效果:
30.(1)本发明提供了一种基于fnirs的阿尔兹海默症患者数据识别方法及系统,应用于阿尔兹海默症辅助诊断过程中,创造性地提出采用基于因果卷积神经网络的方式对fnirs数据做数据增扩,以弥补采集数据量的不足。避免了采集ad患者数据流程复杂、成本过高的困难。
31.(2)本发明提供了一种基于fnirs的阿尔兹海默症患者数据识别方法及系统,创造性地提出采用自监督学习+模型微调的方式对fnirs数据进行训练,以弥补标签训练数据的不足。更好地发挥了神经网络的学习能力,使得在少量可用的fnirs数据下,基于神经网络的ad诊断模型依然可以达到70%左右的准确率。
附图说明
32.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
33.图1是数据增扩网络的结构示意图;
34.图2是特征模块的结构示意图;
35.图3是自监督模型的结构示意图;
36.图4是编码模块的结构示意图;
具体实施方式
37.结合以下本发明的优选实施方法的详述以及包括的实施例可进一步地理解本发明的内容。
38.当描述本技术的实施方式时,使用“优选的”、“优选地”、“更优选的”等是指,在某些情况下可提供某些有益效果的本发明实施方案。然而,在相同的情况下或其他情况下,其他实施方案也可能是优选的。除此之外,对一个或多个优选实施方案的表述并不暗示其他实施方案不可用,也并非旨在将其他实施方案排除在本发明的范围之外。
39.在本文中,诸如第一、第二等之类的关系术语仅仅用来将一个实体与另一个实体区分开来,而不一定要求或者暗示这些实体之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他辩题已在涵盖非排他性的包含,从而使得包括一系列要素的部件、装置或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种不见、装置或者设备所固有的要素。
40.本发明提供了一种基于fnirs的阿尔兹海默症患者数据识别方法,包括以下步骤:
41.sa:采用基于因果卷积神经网络的方式对fnirs数据做数据增扩;
42.sb:采用自监督学习和模型微调的方式对fnirs数据进行训练。
43.在一些优选的实施例中,还包括以下步骤:
44.s1:采集fnirs数据;
45.s2:构建数据增扩网络;
46.s3:训练数据增扩网络;
47.s4:构建自监督模型;
48.s5:训练自监督模型;
49.s6:模型微调。
50.在一些优选的实施例中,步骤1中单人单次实验数据的呈现方式为204*650的二维矩阵。
51.本实施例实验设备采用韩国obelab公司的多通道近红外设备nirsit,它有24个光源(激光二极管)和32个探测器(共204个通道),以8.138hz的采样率检测前额叶皮层fnirs信号。
52.nirsit是一种可穿戴设备,使用近红外光(波长采用780nm和850nm)通过大脑皮层的不同吸收率来测量氧和血红蛋白(hbo)和脱氧血红蛋白(hbr)。光源与探测器的距离有多种,分别为1.5cm、2.12cm、3cm、3.35cm。在每个受试者的前额叶皮层共204个通道,通过串口与主机电脑连接,实验期间数据采集在主机电脑上。
53.确定实验范式,这里采用n-back任务设计(也可以使用其他fnirs实验范式)。n-back的刺激内容为伪随机顺序在屏幕上显示的数字,两次数字之间的时间间隔为1s,当数字出现时,要求被试者迅速按键反应。本实施例采用1-back和2-back两组任务,1-back任务下,如果屏幕上出现的数字和其前一位数字相同则按“《
‑”
键,否则按
“‑
》”键。2-back任务下,如果屏幕上出现的数字与其往前数第二位数字相同则按“《
‑”
键,否则按
“‑
》”键。
54.本实施例一共采集40位被试人员的fnirs数据,其中20位为ad患者(根据美国精神病学会的精神障碍诊断和统计手册修订第ⅳ版(dsm
‑ⅳ‑
r)中的ad诊断标准),另外20位是与ad患者年龄、性别、文化程度相匹配的健康老年人。所有被试均进行实验室和影像学检查,包括血常规、血生化、肝功、肾功、外科综合、叶酸、维生素b12、ct、mri等,排除那些存在其他身体状况的严重疾病患者。每位被试一共做3次采集实验,每次采集实验做一次1-back任务(30s)和一次2-back任务(30s),1-back任务与2-back任务完成后均进入30s的静息态。
55.每次采集实验采集时间为2分钟,将部分静息态数据丢弃(两次静息态的后20s丢弃)剩余80s的数据,近红外设备采样率为8.138hz、204个通道,所以每次采集实验可以得到一个204x650的二维矩阵。每位被试最终得到3个204x650的二维矩阵,40位被试一共得到120个二维矩阵。
56.在一些优选的实施例中,步骤2中所述数据增扩网络如图1所示,包括输入(input)、卷积层(causal)、特征模块(feature block)、relu激活函数、反卷积层,sigmoid激活函数;数据增扩网络输入一个204x650大小的二维矩阵,经过一层卷积层后依次顺序经过若干个特征模块进行特征提取,特征模块首尾相连,每个特征模块会额外再输出一个旁支特征数据。将所有旁支特征数据作叠加后,输入到relu激活函数进行非线性变换,然后再做反卷积放大特征数据尺寸,使其与数据尺寸一致,再经过sigmoid激活函数使输出归一化到(-1,1)之间。
57.旁支特征数据的尺寸大小为102*325。
58.在一些优选的实施例中,步骤2中所述特征模块如图2所示,包括输入(input)、扩
张卷积函数(dilated conv)、tanh激活函数、sigmoid激活函数、2个反卷积层(deconv)、2个输出(output);输入经过扩张卷积函数扩张卷积之后分别进入tanh和sigmoid激活函数得到两个激活后的矩阵,将两个激活后的矩阵相乘后分别经过两个不同的反卷积层得到两个输出,分别为旁支输出和后向输出,后向输出与作残差连接相加后得到第一输出,第一输出后接下一个特征模块的输入;旁支输出作为第二输出;每个所述特征模块的旁支输出保持数据尺寸一致,输入的数据和输出的数据尺寸保持一致。
59.所述特征模块的扩张卷积函数的扩张率是1、5、9、13、17、21中的一个。
60.每个所述特征模块的扩张率可以选择不一样的值。
61.在一些优选的实施例中,步骤3包括以下分步骤:
62.s3.1:将输入的二维矩阵做随机变换,从204x650的二维矩阵中随机选出100个像素点,对这些像素点值的大小随机放大或缩小10%,然后将得到的二维矩阵数值归一化到(-1,1)之间;
63.s3.2:将随机变换后的二维矩阵输入到数据增扩网络进行训练;具体的训练参数可以根据可用训练数据量的多少来定。
64.loss函数采用图片的重构误差,可以用平均平方误差来度量。
65.在一些优选的实施例中,步骤4所述自监督模型结构中,如图3所示,输入数据经过数据增扩网络生成出两个与相似的数据x1和x2,分别经过编码模块(encoder block)提取特征后得到f1和f2,然后再分别经过全连接和relu激活函数进行非线性变换后得到g1和g2,最后自监督模型的目标是最大化g1和g2的相似度。
66.如图4所示,所述编码模块中,输入经过若干个扩张卷积函数层后最终输出一维特征数据,各层之间采用残差连接,每层选用不一样的扩张率,扩张率选用1、5、9、13、17、21中的一个,另外每层将输入矩阵的通道分成20组分别进行卷积,每组输出矩阵的通道为5,然后将20组卷积后的输出合并在一起传入下一层;扩张卷积函数层的数量根据输入的二维矩阵大小确定;本实施例中采用10层。
67.优选的,扩张卷积函数层的数量为8-12层。
68.在一些优选的实施例中,步骤5包括以下分步骤:
69.s5.1:将输入的二维矩阵做随机变换,从204x650的二维矩阵中随机选出100个像素点,对这些像素点值的大小随机放大或缩小10%,然后将得到的二维矩阵数值归一化到(-1,1)之间;
70.s5.2:将随机变换后的二维矩阵输入到自监督模型中进行训练,通过最大化g1和g2的相似度计算相应的loss,使得loss大小不再更新。
71.在一些优选的实施例中,步骤6中的模型微调包括将训练好的自监督模型的编码模块及其后的dense层参数拿出来,后接softmax层形成独立的分类网络,然后在采集的原始真实数据上进行模型微调训练,得到最终的ad诊断模型。
72.本发明还提供了一种基于fnirs的阿尔兹海默症患者数据识别系统,包括以上任一所述的基于fnirs的阿尔兹海默症患者数据识别方法。
73.最后应当说明的是,以上内容仅用以说明本发明的技术方案,而非对本发明保护范围的限制,本领域的普通技术人员对本发明的技术方案进行的简单修改或者等同替换,均不脱离本发明技术方案的实质和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1