基于癌症基因组大数据核心算法的诊断、预测以及大健康管理平台的制作方法
1.本发明创造涉及健康管理领域,具体涉及一种基于癌症基因组大数据核心算法的诊断、预测以及大健康管理平台。
背景技术:
2.科学技术地进步推动各行各业快速改革,特别是生物学方面,全基因测序的成功,使得对癌症基因表达数据的获取代价急剧下降,为系统的研究癌症基因组提供了广阔的平台。以基因数据为基础,运用机器学习对基因数据进行计算机辅助诊断,具有较高的病变诊断的精度。但是基因数据的特性是维度高、样本量少、信噪比大、特征维度高、相关性强,将机器学习分类算法应用到这样的基因数据时,容易引起训练过拟合与维数灾难。因此,如何在这样的基因数据集中挖掘出有价值的信息,是研究的热点问题。聚类是大数据预处理的一种重要方法,广泛应用于医疗数据分析、图像处理和文本处理等领域,因为这些领域的许多数据都具备样本少、噪音大、维数高的特点,对基因大数据进行聚类分析,可以发现基因数据中隐含的类结构,将数据对象分成不同的簇或类,使得同一类的对象之间相似度较大,而不同类对象之间相似度较小,从而能够有效的简化大数据的结构,并且在聚类的过程中能够同时去除大数据中的噪声数据,从而避免噪声数据对机器分类算法准确度的影响。
技术实现要素:
3.针对上述问题,本发明旨在提供一种基于癌症基因组大数据核心算法的诊断、预测以及大健康管理平台。
4.本发明创造的目的通过以下技术方案实现:
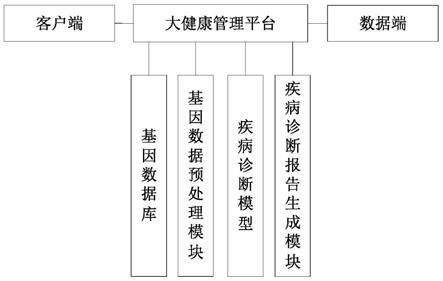
5.基于癌症基因组大数据核心算法的诊断、预测以及大健康管理平台,包括客户端、数据端和大健康管理平台;
6.用户通过客户端进行注册,注册完成后通过客户端向大健康管理平台发送基因数据;
7.所述数据端用于按照预设的采集周期周期性的获取基因大数据,在当前采集周期结束后将获取的基因大数据传输至大健康管理平台,对大健康管理平台中存储的基因大数据进行更新;
8.所述大健康管理平台包括基因数据库、基因数据预处理模块、疾病诊断模型和疾病诊断报告生成模块,所述基因数据库采用区块链节点存储基因大数据,当有新的基因大数据存储至基因数据库中时,令基因数据预处理模块对基因数据库中存储的基因大数据进行预处理,并利用预处理后的基因大数据重新训练bp神经网络,从而生成基于bp神经网络的疾病诊断模型,当大健康管理平台接收到客户端发送的基因数据时,疾病诊断报告生成模块将接收到的基因数据输入至疾病诊断模型,并将疾病诊断模型的诊断结果发送至相应的客户端。
9.优选地,利用预处理后的基因大数据训练bp神经网络时,采用基因数据预处理模块聚类所得的各个类中的基因数据分别对bp神经网络进行训练,从而获得基于bp神经网络的疾病诊断模型。
10.优选地,所述基因数据预处理模块采用密度峰值聚类算法对基因大数据进行聚类,对密度峰值聚类算法中数据的局部密度的计算方式进行改进,具体为:
11.设y表示基因大数据集,y
i
表示基因大数据集y中的第i个基因数据,n(y
i
)表示基因数据y
i
的邻域基因数据集合,且n(y
i
)={y
i,j
||y
i,j
‑
y
i
|≤d
c
,j=1,2,...,m(y
i
)},其中,d
c
表示截断距离,y
i,j
表示集合n(y
i
)中的第j个基因数据,m(y
i
)表示集合n(y
i
)中的基因数据量;定义m(y
i
)表示基因数据y
i
的局部密度值,则m(y
i
)的值为:其中,ω(y
i
)表示基因数据y
i
的局部密度补偿系数,且ω(y
i
)的值为:
[0012][0013]
其中,设y
i,l
表示集合n(y
i
)中的第l个基因数据,且y
i,l
≠y
i,j
,n(y
i,j
)表示基因数据y
i,j
的邻域基因数据集合,η(y
i,l
,n(y
i,j
))表示基因数据y
i,l
和集合n(y
i,j
)之间的判断函数,且f(y
i,j
,y
i
)表示基因数据y
i,j
和基因数据y
i
之间的判断函数,且j(y
i,j
)表示基因数据y
i,j
在集合n(y
i
)中的密度系数,且j(y
i
)表示基因数据y
i
在集合n(y
i
)中的密度系数,且θ为给定的正整数,用于保证分母不为0。
[0014]
优选地,所述基因数据预处理模块采用密度峰值聚类算法对基因大数据进行聚类,对基因大数据集y中各基因数据的局部密度值进行修正,设m
′
(y
i
)表示对基因数据y
i
进行修正后的局部密度值,则m
′
(y
i
)的值为:
[0015]
m
′
(y
i
)=m(y
i
)ρ(y
i
)
[0016][0017]
式中,y
i,k
表示集合n(y
i
)中的第k个基因数据,且y
i,k
≠y
i
,ρ(y
i
)表示基因数据y
i
对应的噪声惩罚系数,m(y
i,k
)表示基因数据y
i,k
的局部密度值,s(y
i
)表示基因数据y
i
的区域检测系数,且s(y)表示基因大数据集y中全体基因数据
对应的区域检测系数,且其中,表示基因大数据集y中基因数据的区域检测系数的均值,且σ(y)表示基因大数据集y中基因数据的区域检测系数的均方差,且α表示调节参数,m(y)表示基因大数据集y中的基因数据量。
[0018]
本发明创造的有益效果:以基因大数据为基础,运用bp神经网络算法对基因大数据进行学习,从而建立疾病诊断模型对疾病进行诊断,具有较高的病变诊断的精度;针对基因大数据的特性是维度高、信噪比大、相关性强的特点,将bp神经网络算法应用到这样的基因大数据时,容易引起训练过拟合和较高的复杂性,针对上述缺陷,本发明对基因大数据进行聚类预处理,进而利用聚类所得的类中的基因数据分别对bp神经网络算法进行训练,从而能够有效的简化基因大数据的结构,避免bp神经网络算法学习的复杂性和过拟合;此外,在聚类的过程中能够有效的去除基因大数据集中的噪声数据,从而避免噪声数据影响训练所得的疾病诊断模型的诊断精度。
附图说明
[0019]
利用附图对发明创造作进一步说明,但附图中的实施例不构成对本发明创造的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
[0020]
图1是本发明结构示意图。
具体实施方式
[0021]
结合以下实施例对本发明作进一步描述。
[0022]
参见图1,本实施例的基于癌症基因组大数据核心算法的诊断、预测以及大健康管理平台,包括客户端、数据端和大健康管理平台;
[0023]
用户通过客户端进行注册,注册完成后通过客户端向大健康管理平台发送基因数据;
[0024]
所述数据端用于按照预设的采集周期周期性的获取基因大数据,在当前采集周期结束后将获取的基因大数据传输至大健康管理平台,对大健康管理平台中存储的基因大数据进行更新;
[0025]
所述大健康管理平台包括基因数据库、基因数据预处理模块、疾病诊断模型和疾病诊断报告生成模块,所述基因数据库采用区块链节点存储基因大数据,当有新的基因大数据存储至基因数据库中时,令基因数据预处理模块对基因数据库中存储的基因大数据进行预处理,并利用预处理后的基因大数据重新训练bp神经网络,从而生成基于bp神经网络的疾病诊断模型,当大健康管理平台接收到客户端发送的基因数据时,疾病诊断报告生成模块将接收到的基因数据输入至疾病诊断模型,并将疾病诊断模型的诊断结果发送至相应的客户端。
[0026]
本优选实施例以基因大数据为基础,运用bp神经网络算法对基因大数据进行学
习,从而建立疾病诊断模型对疾病进行诊断,具有较高的病变诊断的精度。
[0027]
优选地,所述基因数据预处理模块用于对基因数据库中存储的基因大数据进行聚类,并在聚类的过程中去除基因大数据中的噪声数据。
[0028]
优选地,利用预处理后的基因大数据训练bp神经网络时,采用基因数据预处理模块聚类所得的各个类中的基因数据分别对bp神经网络进行训练,从而获得基于bp神经网络的疾病诊断模型。
[0029]
本优选实施例针对基因大数据的特性是维度高、信噪比大、相关性强的特点,将bp神经网络算法应用到这样的基因大数据时,容易引起训练过拟合和较高的复杂性,针对上述缺陷,本发明对基因大数据进行聚类预处理,进而利用聚类所得的类中的基因数据分别对bp神经网络进行训练,从而能够有效的简化基因大数据的结构,避免bp神经网络算法学习的复杂性和过拟合;此外,在聚类的过程中能够有效的去除基因大数据集中的噪声数据,从而避免噪声数据影响训练所得的疾病诊断模型的诊断精度。
[0030]
优选地,所述基因数据预处理模块采用密度峰值聚类算法对基因大数据进行聚类,对密度峰值聚类算法中数据的局部密度的计算方式进行改进,具体为:
[0031]
设y表示基因大数据集,y
i
表示基因大数据集y中的第i个基因数据,n(y
i
)表示基因数据y
i
的邻域基因数据集合,且n(y
i
)={y
i,j
||y
i,j
‑
y
i
|≤d
c
,j=1,2,...,m(y
i
)},其中,d
c
表示截断距离,y
i,j
表示集合n(y
i
)中的第j个基因数据,m(y
i
)表示集合n(y
i
)中的基因数据量;定义m(y
i
)表示基因数据yi的局部密度值,则m(y
i
)的值为:其中,ω(y
i
)表示基因数据y
i
的局部密度补偿系数,且ω(y
i
)的值为:
[0032][0033]
其中,设y
i,l
表示集合n(y
i
)中的第l个基因数据,且y
i,l
≠y
i,j
,n(y
i,j
)表示基因数据y
i,j
的邻域基因数据集合,η(y
i,l
,n(y
i,j
))表示基因数据y
i,l
和集合n(y
i,j
)之间的判断函数,且f(y
i,j
,y
i
)表示基因数据y
i,j
和基因数据y
i
之间的判断函数,且j(y
i,j
)表示基因数据y
i,j
在集合n(y
i
)中的密度系数,且j(y
i
)表示基因数据y
i
在集合n(y
i
)中的密度系数,且θ为给定的正整数,用于保证分母不为0,θ的值可以取0.001。
[0034]
本优选实施例对传统的密度峰值聚类算法中数据的局部密度的计算方式进行改
进,传统的聚类算法在计算数据的局部密度时通过对数据集指定一个截断距离d
c
来确定数据的邻域数据信息,但现实中,当数据集中类的尺寸不同时,采用同一个截断距离d
c
并不能准确的描述数据集中各数据的邻域数据信息,使得计算所得的数据的局部密度并不能准确的反应数据所处区域的数据密度,从而影响聚类中心选取的准确性,因此,本优选实施例在局部密度的计算过程中引入了局部密度补偿系数,所述局部密度补偿系数用于对数据的局部密度值进行补偿,从而解决采用同一截断距离d
c
并不能准确获得数据集中各数据的局部密度值的缺陷,在本优选实施例提出的局部密度补偿系数中,当数据所处类的尺寸较大,截断距离d
c
内的数据都为同一类数据时,该数据的局部密度补偿系数的值将接近于1,即不改变数据的密度系数,当数据所处类的尺寸较小,而截断距离d
c
较大时,该数据的密度补偿系数的值将较大,即增加该数据的局部密度值,从而避免截断距离d
c
的影响;综上所述,本优选实施例提出的密度峰值聚类算法中数据的局部密度的计算方式,能够很好的解决当数据集中存在多尺寸类时采用同一截断距离d
c
不能很好的反应数据的邻域数据信息,从而影响聚类中心选取准确性的缺陷。
[0035]
优选地,所述基因数据预处理模块采用密度峰值聚类算法对基因大数据进行聚类,对基因大数据集y中各基因数据的局部密度值进行修正,设m
′
(y
i
)表示对基因数据y
i
进行修正后的局部密度值,则m
′
(y
i
)的值为:
[0036]
m
′
(y
i
)=m(y
i
)ρ(y
i
)
[0037][0038]
式中,y
i,k
表示集合n(y
i
)中的第k个基因数据,且y
i,k
≠y
i
,ρ(y
i
)表示基因数据y
i
对应的噪声惩罚系数,m(y
i,k
)表示基因数据y
i,k
的局部密度值,s(y
i
)表示基因数据y
i
的区域检测系数,且s(y)表示基因大数据集y中全体基因数据对应的区域检测系数,且其中,表示基因大数据集y中基因数据的区域检测系数的均值,且σ(y)表示基因大数据集y中基因数据的区域检测系数的均方差,且α表示调节参数,α的值可以取2.5,m(y)表示基因大数据集y中的基因数据量;
[0039]
密度峰值聚类算法根据修正后的基因数据的局部密度对基因大数据集y中的基因数据进行聚类。
[0040]
本优选实施例考虑到数据集中处于类边缘的数据的局部密度相较于处于类内部的数据的局部密度较小,并且当噪声数据距离类边缘较近时,采用截断距离计算所得的噪声数据的局部密度和其距离较近的边缘数据的局部密度将较为接近,即根据数据的局部密度进行聚类的过程中,容易出现将边缘数据误认为噪声数据或者将噪声数据误认为边缘数据的情况,为了进一步提高聚类的准确度,避免噪声数据影响聚类结果的准确度的情况,本优选实施例进一步地对基因大数据集中基因数据的局部密度值进行修正,根据基因数据的区域检测系数和基因大数据集y中全体数据对应的区域检测系数对基因数据的局部密度值
进行修正,当基因数据为边缘数据时,其区域检测系数的值将较小,即噪声惩罚系数的值将接近于1,即不对该基因数据的局部密度值进行改变,当基因数据为噪声数据时,其区域检测系数的值将较大,即噪声惩罚系数的值将较小,即进一步的减小了噪声数据的局部密度值,从而加强了基因大数据集中类内数据和噪声数据之间的局部密度值的差异,尤其是加强类边缘数据和噪声数据之间局部密度值的差异,从而使得密度峰值聚类算法在根据修正后的局部密度值进行聚类时,能够更好地区分类中数据和噪声数据,避免噪声数据影响聚类结果的准确性,即提高了聚类结果的准确性。
[0041]
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1