基于蒸馏的半监督联邦学习的个性化模型的训练方法
本发明涉及联邦学习技术领域,具体涉及一种基于蒸馏的半监督联邦学习的个性化模型的训练方法。
背景技术:
联邦学习在保证一组客户端不上传本地数据集的前提下协同训练一个全局模型,每个用户只能访问自己的数据,从而保护了参与训练用户的隐私。联邦学习因为其优势在医学、金融和人工智能等行业有着广泛的应用前景,是最近几年的研究热点。然而联邦学习侧重于通过学习所有参与客户机的本地数据来获得高质量的全局模型,但由于现实场景中每个客户端的数据是异质的,当面临数据异质性问题,它无法训练出一个适用于所有客户端的全局模型。
使用知识蒸馏技术能够有效的解决联邦学习中的模型异构性问题,激起了大量学者的研究兴趣。知识蒸馏技术的主要思想是将复杂的教师网络的输出作为知识传给学生网络,使得学生网络在训练的过程中不仅能够学习数据真实标签的信息还能学习不同标签之间关系的信息,从而转换成一个精简的学生网络,这里的网络输出对应了相应类别的概率值。其中,教师模型和学生模型是两种不同的网络架构。因此将知识蒸馏技术应用到联邦学习中可以解决模型异构性问题。
然而,将知识蒸馏技术应用到联邦学习中必须要保证在同一个数据集上进行蒸馏,而联邦学习中各个客户端的本地数据都不同,因此怎么在客户端上构造相同的数据集实现蒸馏是一个难题。在联邦学习中,拥有不同数据的客户端由于数据质量参差不齐导致模型输出所提供知识的重要程度不同,所以简单地对其进行平均并不是一种有效的聚合方法。此外,在现实中,由于每个参与方(例如医院)本地拥有大量的无标签数据,而有标记数据却很少,因此在满足隐私保护的约束和半监督场景下,如何为每个客户端训练一个适合的模型(包括模型性能和模型框架),是一个亟待解决的问题。
技术实现要素:
本发明所要解决的是在联邦学习半监督场景下的数据异质性和模型异质性问题,提供一种基于蒸馏的半监督联邦学习的个性化模型的训练方法。
为解决上述问题,本发明是通过以下技术方案实现的:
基于蒸馏的半监督联邦学习的个性化模型的训练方法,包括步骤如下:
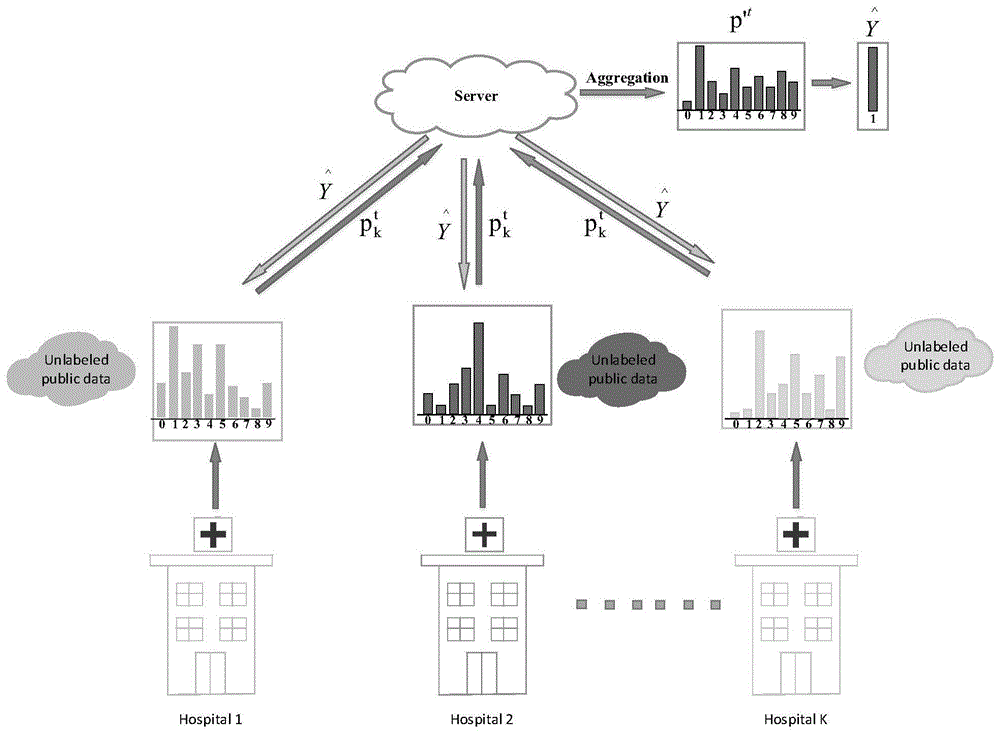
步骤1、每个客户端分别使用自己的无标签本地数据集训练一个对抗生成网络,并将对抗生成网络及其采样噪声的种子上传至中心服务器;中心服务器先利用每个客户端的对抗生成网络及其采样噪声的种子生成每个客户端的无标签合成样本,再从所有客户端的无标签合成样本中选择一部分作为无标签共享数据集;所有客户端从中心服务器上下载无标签共享数据集;
步骤2、令当前轮次t=1,中心服务器从所有客户端中选择一部分客户端作为参与方进行协同训练;在协同训练过程中,每个参与方分别先利用自己的有标签本地数据集和无标签本地数据集对自己的本地神经网络模型进行半监督训练,得到本轮训练的本地神经网络模型;再利用本轮训练的本地神经网络模型对无标签共享数据集进行预测,得到每个参与方在第t轮次的模型预测矩阵;
步骤3、中心服务器先计算第t轮次的聚合模型预测矩阵,再从第t轮次的聚合模型预测矩阵中挑选挑选概率最大的类别标签作为伪标签,后将伪标签传回给所有的客户端;
式中,
步骤4、令当前轮次t加1,中心服务器从所有客户端中选择一部分客户端作为参与方进行协同训练;在协同训练过程中,每个参与方先将伪标签作为无标签共享数据集的每个样本的标签,得到有标签共享数据集;再利用有标签共享数据集、自己的有标签本地数据集和无标签本地数据集对自己的本地神经网络模型进行半监督训练,得到本轮训练的本地神经网络模型;后利用本轮训练的本地神经网络模型对无标签共享数据集进行预测,得到每个参与方在第t轮次的模型预测矩阵;
步骤5、判断当前轮次t是否达到设定的最大轮次:如果是,则停止训练;否则,返回步骤3。
上述步骤中,参与方在第t轮次的模型预测矩阵的每一行为该参与方在第t轮次的无标签共享数据集的每一个样本的所有类别标签的概率分布。
上述步骤中,每个参与方的模型预测矩阵是一个np×d的矩阵,np为无标签共享数据集的样本数量,d为类别标签数量。
与现有技术相比,本发明具有如下特点:
1、在每个客户端上构造了相同的无标签共享数据。无标签共享数据利用生成式对抗网络(gan,generativeadversarialnetworks)生成,gan是一种能生成与原始数据相同分布的假数据的深度学习模型。这种在每个客户端上构造了相同数据集的方法使得所有客户端在相同的数据上进行观察从而实现蒸馏,防止了因客户端上的数据样本不同带来的影响。
2、采用半监督学习方法与知识蒸馏技术结合实现客户端本地模型训练。半监督学习同时利用公共数据和本地数据训练模型,相比于只用有本地数据训练出来的模型性能更好。
3、基于js散度的自适应加权平均聚合方法。根据每个客户端的模型输出与上一轮次聚合的模型输出的js散度值进行模型输出聚合,该聚合方法根据每个客户端提供知识的重要程度进行动态聚合,减少了低质量模型的权重,提高了模型的性能和模型的鲁棒性。
4、服务器端回传公共数据的伪标签。当前的知识蒸馏与联邦学习结合的方法都是通过在客户端和服务器端之间传输模型预测来训练模型,本发明采用客户端上传模型预测和服务器端回传共享的无标签数据的伪标签来构建模型,在不影响模型效果的同时,大大提高了联邦学习中的传输通讯效率。
附图说明
图1为基于蒸馏的半监督联邦学习的个性化模型的训练方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实例,对本发明进一步详细说明。
我们定义k∈k个客户端拥有本地数据集dk,其中dk包括有标记本地数据集
以医疗场景为例,参与联邦学习训练的客户端为不同地区的医院,本地数据集为医学影像数据集,如阿尔茨海默氏病神经影像数据,数据的标签表示是否患病。
参见图1,一种基于蒸馏的半监督联邦学习的个性化模型的训练方法,其具体包括步骤如下:
步骤1、每个客户端分别使用自己的无标签本地数据集训练一个对抗生成网络,并将对抗生成网络及其采样噪声的种子上传至中心服务器;中心服务器先利用每个客户端的对抗生成网络及其采样噪声的种子生成每个客户端的无标签合成样本,再从所有客户端的无标签合成样本中选择一部分作为无标签共享数据集;所有客户端从中心服务器上下载无标签共享数据集。
步骤1.1、k个客户端中的每个客户端k使用自己的无标签本地数据集
步骤1.2、中心服务器分别利用每个客户端k上传的对抗生成网络gk及其采样噪声的种子seedk生成该客户端k所对应的数量为mk的无标签合成样本fk;
步骤1.3、中心服务器从所有的无标签合成样本
步骤1.4、客户端再从中心服务器上下载无标签共享数据集dpublic,这样每个客户端和中心服务器都共享到了相同的数据。
由于每个客户端上所拥有的本地数据几乎都是不同的,为了将知识蒸馏技术应用到联邦学习中实现个性化,需要所有客户端在同一批数据集上进行观察,所以本发明为每个客户端构造了一个相同的无标签共享数据集。
步骤2、令当前轮次t=1,中心服务器从所有客户端中选择一部分客户端作为参与方进行协同训练;在本轮协同训练过程中,每个参与方分别先利用自己的有标签本地数据集和无标签本地数据集对自己的本地神经网络模型进行半监督训练,得到本轮训练的本地神经网络模型,再利用本轮训练的本地神经网络模型对无标签共享数据集进行预测,得到每个参与方在第t轮次的模型预测矩阵。
步骤2.1、中心服务器从k个客户端中随机选择k′=c*k个客户端作为参与方进行第t=1轮的协同训练,c∈(0,1]。
步骤2.2、k′个参与方中的每个参与方k′选择适合自己计算能力和存储能力的神经网络结构作为自己的本地神经网络模型,并随机初始化自己的本地神经网络模型
步骤2.3、每个参与方k′分别先利用自己的无标签本地数据集
如对于医学影像数据集,每个参与方k′针对有标签本地数据集
步骤2.4、每个参与方k′使用本轮训练的本地神经网络模型
步骤2.5、中心服务器利用所有参与方所上传的预测结果构建模型预测矩阵
步骤3、中心服务器先计算第t轮次的聚合模型预测矩阵,再从第t轮次的聚合模型预测矩阵中挑选挑选概率最大的类别标签作为伪标签,后将伪标签传回给所有的客户端。
步骤3.1、计算每个参与方k′聚合权重的中间值
步骤3.2、对每个参与方k′的聚合权重的中间值
步骤3.3、计算当前轮次t的聚合模型预测矩阵
步骤3.4、从当前轮次t的聚合模型预测矩阵
式中,
js散度衡量了两个概率分布的相似性,散度值越大表示相似性越小。客户端模型输出与上一次迭代的模型输出相似度越小,则该模型的质量越差,反之亦然。由于不同参与方的私人数据不同,因此不同参与方上传的模型预测值所包含信息的重要程度不同,根据参与方的模型输出与上一轮次聚合的模型输出的js散度值得出每个参与方的聚合权重,通过这种方式聚合,减少了拥有低质量模型参与方的权重,提高了模型预测的质量,进而提高了客户端局部模型的性能。
步骤4、令当前轮次t加1,中心服务器从所有客户端中选择一部分客户端作为参与方进行协同训练;在本轮协同训练过程中,每个参与方先将伪标签作为无标签共享数据集的每个样本的标签,得到有标签共享数据集;再利用有标签共享数据集、自己的有标签本地数据集和无标签本地数据集对自己的本地神经网络模型进行半监督训练,得到本轮训练的本地神经网络模型;后利用本轮训练的本地神经网络模型对无标签共享数据集进行预测,得到每个参与方在第t轮次的模型预测矩阵。
步骤4的协同训练过程与步骤2的协同训练不同的是需要利用伪标签为无标签共享数据集的每个样本进行标注,使其无标签共享数据变为有标签共享数据后,并与本地数据集一并参与后续的半监督训练。参与方使用公共的数据与本地数据共同训练,数据的增加,提高了客户端局部模型的性能。
步骤5、判断当前轮次t是否达到设定的最大迭代轮次:如果是,则停止训练,每个客户端在第t轮的本地神经网络模型即为其最终的本地神经网络模型;否则,返回步骤3。
本发明采用知识蒸馏技术,客户端通过上传模型预测而不是模型参数,使得每个客户端可以选择自己设计的模型架构,很好地保护了客户端关于模型的隐私信息。相比于仅本地数据训练,该方法有效地利用了公开的数据与客户端的本地数据一起进行训练,极大地提高模型的泛化能力。此外,该方法中的聚合方案能根据每个客户端提供知识的重要程度来进行动态聚合,使聚合的模型预测更好地融合了客户端的模型知识,由于客户端使用聚合的模型预测进行训练从而得到个性化模型,所以一个好的聚合模型预测会直接影响到后面模型的训练。值得一提的是,服务器聚合完成后,回传给客户端的不是公共数据的模型预测分布信息而是伪标签信息,利用这种方式进一步地提高了通信传输效率。
需要说明的是,尽管以上本发明所述的实施例是说明性的,但这并非是对本发明的限制,如其可以将实施例中的医学影像数据集替换为其他医学数据集,也可以将实施例中的医疗场景替换为银行场景,此时银行网点为客户端,数据集为银行流水数据,标签为黑客攻击等,因此本发明并不局限于上述具体实施方式中。在不脱离本发明原理的情况下,凡是本领域技术人员在本发明的启示下获得的其它实施方式,均视为在本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!