一种糖尿病无创风险预测方法
1.本发明属于智能医疗领域,具体涉及一种基于人脸图像和残差注意力网络的糖尿病无创风险预测方法。
背景技术:
2.糖尿病是一种慢性的代谢疾病,病程早期在并发症出现之前一般难以及时发现。据国际糖尿病联盟(idf)发布的全球糖尿病地图(第9版)估计,全球成年糖尿病患者中约有2.32亿人未被正确诊断为糖尿病。尤其是在医疗资源较为匮乏的发展中国家,医务工作者对糖尿病的认识不足,血糖检测设施也较为有限,导致糖尿病常常被误诊为疟疾、肺炎或各种其他疾病。如果糖尿病的诊断被延误或误诊,那么出现严重并发症和死亡的风险就会增加。因此,对糖尿病易发人群进行早期风险预测具有十分重要的意义。
3.目前,常规的糖尿病检测方法大多是侵入式的,需要患者空腹到医院进行一系列的检验项目,这一过程不仅费时、费力,而且常常造成患者经济上和身心上的负担。特别是在贫困地区、中低收入国家尤为明显。糖尿病患者常常受限于医疗、经济等条件,无法及时进行有效的糖尿病筛查和治疗。糖尿病患者由于血糖升高、毛细血管病变,常常出现面部红肿、皮肤感染、瘙痒、干燥以及色素沉淀等症状,其中面部红肿的强度取决于浅静脉从的血管充血程度。因此,考虑到糖尿病患者面部图像信息的复杂性,为深度探究人脸面部图像与糖尿病之间的内在关联,本文提出了一种基于人脸图像和残差注意力网络的糖尿病无创风险预测方法。
技术实现要素:
4.本发明的目的是,提供一种糖尿病无创风险预测方法,该方法以人脸图像为基础,采用了注意力机制,能够感知面部重点区域目标信息,抑制其他无用信息,大幅度的提升了模型的拟合速度和泛化能力,能够快速、无创、准确的进行糖尿病风险预测。
5.为实现上述目的,本发明的技术方案是:
6.一种糖尿病无创风险预测方法,该方法包括以下内容:
7.获取或构建包含糖尿病病人和健康人人脸图像的数据集,
8.对数据集中的图像样本进行预处理,定位出人脸图像特征点,获得多个关键区域,将关键区域裁剪、拼接并标记糖尿病诊断信息,获得标记好的样本数据集;
9.构建残差注意力网络,对标记好的样本进行有监督的机器学习,通过训练调参后获得糖尿病无创风险预测模型。
10.所述数据集中的样本图像为在相同自然环境状态(光照、角度、表情)下通过高清摄像头采集的大量受试者正脸面部图像,为自建糖尿病患者和健康人人脸图像的数据集,具体过程是:
11.招募大量糖尿病受试者和健康人受试者,设置纳排标准:所有受试者年龄需在40~90岁之间;面部皮肤无明显的疤痕,且面部图像采集当日没有化妆,其中糖尿病受试者需
满足已在二级及以上医疗机构做出过明确的糖尿病诊断;健康人受试者血糖范围满足空腹全血血糖:3.9~6.1毫摩/升、餐后1小时:6.7-9.4毫摩/升、餐后2小时:≤7.8毫摩/升,或三个月内的体检报告中糖化血红蛋白h1a1c《6.5%,且无糖尿病史;所有受试者在年龄、性别等方面无明显统计学差异;
12.在一间光照良好的房间里,受试者端坐在桌子的一端,将头部固定在额托支架上,桌子的另一端放置一台高清摄像机,通过调整额托支架的高度,确保摄像机能够清晰的拍摄到受试者正脸的面部图像,整个样本采集的过程,尽可能保证受试者拍照角度、表情以及外部光照条件一致。
13.标注采用dlib工具包中预训练好的模型“shape_predictor_68_face_landmarks.dat”进行68点标定,利用opencv进行图像化处理,在人脸上画出68个点;根据68个特征点的坐标,进行关键区域的定位及裁剪;所述关键区域为避开包括眉毛、眼睛、鼻子、嘴巴的面部器官所在区域内分散选择,关键区域形状为矩形。
14.设置四个关键区域,分别为额头区域(a)、左颊区(b)、右颊区(c)、下鄂区(d);具体操作方式是:首先采用机器学习工具包dlib中的人脸特征点检测方法,对人脸样本进行68个关键点位的轮廓标注,每个点的坐标记为pi(x,y),i=1~68;以p9(x,y)所在的水平轴为横坐标轴记为x轴,p1(x,y)所在的垂直轴为纵坐标轴记为y轴,同时根据特征点之间的坐标关系划定4个大小相同的正方形关键区域(64
×
64像素),分别记为a、b、c、d;若要准确的定位关键区域在人脸图像中的位置,必须先定位关键区域中心点的坐标,记关键区域a、b、c、d中心点的坐标分别为pa(x,y)、pb(x,y)、pc(x,y)、pd(x,y);
15.关键区域a在人脸中轴线上方额头区域附近,pa(x,y)的横坐标取鼻尖特征点34的横坐标记为p
34
(x),纵坐标取眉毛最高点的特征点对应的纵坐标记为p
max-high
(y),同时加上关键区域像素值64对应长度的一半记为h,pa(x,y)的计算公式为:
16.pa(x,y)=(p
34
(x),p
max-high
(y)+h)
ꢀꢀꢀ
(1)
17.关键区域b、c分别在人脸的左右脸颊附近,pb(x,y)、pc(x,y)的计算公式为:
18.pb(x,y)=(p
42
(x),p
32
(y))
ꢀꢀꢀ
(2)
19.pc(x,y)=(p
47
(x),p
36
(y))
ꢀꢀꢀ
(3)
20.pb(x,y)的横纵坐标分别为左眼最低处的特征点42的横坐标记为p
42
(x),鼻子最左侧特征点32的纵坐标p
32
(y);pc(x,y)的横纵坐标分别为右眼最低处的特征点47的横坐标记为p
47
(x),鼻子最右侧特征点36的纵坐标记为p
36
(y);
21.关键区域d在嘴巴下方的中轴线附近,pd(x,y)的横坐标为嘴巴最下端特征点58的横坐标,记为p
58
(x),其纵坐标为特征点58与特征点9的垂直距离的一半;pd(x,y)的具体计算公式为:
[0022][0023]
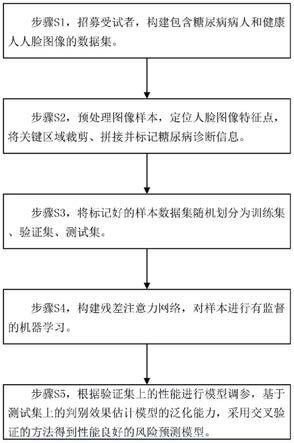
四个关键区域的中心点坐标确认后,便能根据中心点坐标计算出每个正方形的关键区域四个顶点的具体坐标,计算公式为:
[0024]
p
n,左上
(x,y)=(pn(x)-h,pn(y)+h)
ꢀꢀꢀ
(5)
[0025]
p
n,左下
(x,y)=(pn(x)-h,pn(y)-h)
ꢀꢀꢀ
(6)
[0026]
p
n,右上
(x,y)=(pn(x)+h,pn(y)+h)
ꢀꢀꢀ
(7)
[0027]
p
n,右下
(x,y)=(pn(x)+h,pn(y)-h)
ꢀꢀꢀ
(8)
[0028]
其中,n代表a、b、c、d;h为关键区域像素值64对应长度的一半;
[0029]
每张人脸图像裁剪后的关键区域均按照a、b、c、d的顺序拼接为面部组合图(128
×
128像素),数据集中所有样本的拼接顺序保证都相同。
[0030]
所述残差注意力网络为采用pytorch机器学习库搭建的56层的残差注意力网络,具体的网络架构是:
[0031]
标记好的样本图像被输入残差注意力网络,首先经第一个卷积层和最大池化层进行1次卷积和最大池化操作,然后穿插的经过3个残差单元和3个注意力模块,3个残差单元分别记为第一个残差单元、第二个残差单元和第三残差单元,再经过平均池化操作后到达全连接层,最终使用归一化指数函数softmax连接残差注意力网络末端的全连接层进行糖尿病风险预测,输出预测结果;
[0032]
每一个注意力模块分成两个分支,一个分支叫主分支,另一分支是软掩码分支,
[0033]
特征图首先经过1个残差单元进行预处理操作,然后分别进入主分支和软掩码分支,
[0034]
主分支主要包括2个串联的残差单元,
[0035]
软掩码分支包含快速前馈扫描和自上而下反馈两个步骤,特征图先经过两次下采样操作增大感受野,达到最低分辨率后,再通过相同数量的上采样操作将特征图的尺寸放大到与输入的原始特征图一致形成注意力特征图,紧接着接2个1
×
1的卷积层,最后通过sigmoid激活函数得到混合域的注意力;
[0036]
此外,在下采样和上采样之间添加了跳跃连接,以融合不同比例特征图的特征信息;软掩码分支的输出先与主分支输出进行矩阵相乘,其结果再与主分支输出进行矩阵相加,最后再经过p个残差单元即得到注意力模块的输出;
[0037]
注意力模块中的残差单元采用bottleneck结构以减少参数量,bottleneck结构中第一层卷积核大小为1
×
1,通道数为64;第二层卷积核大小为3
×
3,通道数为64;第三层卷积核大小为1
×
1,通道数为256,卷积层之间的激活函数设置为relu,bottleneck结构的输出为第三层卷积层的输出与identityblock的输出之和,大小为112
×
112;
[0038]
所述第一个卷积层包含大小为7
×
7的卷积核、步长为2
×
2,通道数为64,填充模式设置为valid,卷积层的输出为112
×
112;
[0039]
所述最大池化层的池化窗口大小为3
×
3,步长为2
×
2,经过最大池化操作后输出的特征图大小为56
×
56;
[0040]
第一个残差单元采用bottleneck结构以减少参数量。bottleneck结构中第一层卷积核大小为1
×
1,通道数为64;第二层卷积核大小为3
×
3,通道数为64;第三层卷积核大小为1
×
1,通道数为256;各卷积层之间的激活函数设置为relu。bottleneck结构的输出为第三层卷积层的输出与identityblock的输出之和,大小为56
×
56。
[0041]
第一个残差单元后连接第一个注意力模块,该注意力模块的输出大小为:56
×
56;
[0042]
第一个注意力模块后连接第二个残差单元,也采用bottleneck结构,设置3层卷积以减少参数量,其中第一层卷积核大小为1
×
1,通道数为128;第二层卷积核大小为3
×
3,通道数为128;第三层卷积核大小为1
×
1,通道数为512;各卷积层之间的激活函数设置为relu;bottleneck结构的输出为第三层卷积层的输出与identityblock的输出之和,大小为
28
×
28;
[0043]
第二个残差单元后连接第二个注意力模块,该注意力模块的输出大小为:28
×
28;
[0044]
第二个注意力模块后连接第三个残差单元,也采用bottleneck结构,设置3层卷积以减少参数量,其中第一层卷积核大小为1
×
1,通道数为256;第二层卷积核大小为3
×
3,通道数为256;第三层卷积核大小为1
×
1,通道数为1024;各卷积层之间的激活函数设置为relu;bottleneck结构的输出为第三层卷积层的输出与identityblock的输出之和,大小为14
×
14;
[0045]
第三个残差单元后连接第三个注意力模块,该注意力模块的输出大小为:14
×
14;
[0046]
第三个注意力模块后连接第四个残差单元,采用3个串联的bottleneck结构,设置3层卷积以减少参数量,每个bottleneck中第一层卷积核大小为1
×
1,通道数为512;第二层卷积核大小为3
×
3,通道数为512;第三层卷积核大小为1
×
1,通道数为2048;各卷积层之间的激活函数设置为relu,第四个残差单元的输出大小为7
×
7;
[0047]
第四个残差单元输出的特征图进行平均池化的操作,池化窗口的大小为7
×
7,步长为1
×
1,经过平均池化的特征图大小为1
×
1;
[0048]
最后使用归一化指数函数softmax连接残差注意力网络末端的全连接层进行糖尿病风险预测。
[0049]
本发明的有益效果在于:
[0050]
本发明采用残差注意力网络构建糖尿病无创风险预测模型,该网络通过端到端的训练方式与前馈网络体系结构相结合,由多个注意力模块堆叠构建而成。这些模块会生成注意力感知功能。视觉注意力机制是人类视觉所特有的大脑信号处理机制。通过快速扫描全局图像获得需要关注的目标区域,而后重点获取所需要关注的目标信息,抑制其他无用信息。注意力机制极大的提高了机器视觉信息处理的效率与准确性。相比于传统残差网络模型,残差注意力机制可以达到更细粒度的特征匹配,同时加强目标区域的影响力,抑制非目标区域的影响力,有利于提升模型的拟合速度和泛化能力;此外本发明采用非侵入式的检验方法,即通过模型分析受试者正脸面部图像,预测受试者未来糖尿病发病风险。本发明方法耗时短、成本低且支持大范围筛查及远程诊疗,有利于快速筛查高发病人群中的糖尿病患者,提醒他们尽早控制血糖,避免糖尿病并发症的发生。
[0051]
本技术用于糖尿病人的风险预测,通过人脸图像来区分是否患有糖尿病,在传统残差网络的基础上以人脸关键区域处理后为输入样本使得残差注意力网络具有关键特征感知能力,该网络相比于传统残差网络模型机制可以达到更细粒度的特征匹配,同时加强目标区域的影响力,抑制非目标区域的影响力,有利于提升模型的拟合速度和泛化能力,本发明优选的残差注意力网络相对于现有的残差注意力网络同等条件下,检测速度和识别准确性更高,在本技术实施例中能达到90%以上的准确率。该方法支持大范围筛查及远程诊疗,速度快,成本低,可由非专业人员操作。
[0052]
本技术中采用本单位自建的糖尿病人脸数据库(本单位前身为糖尿病专科医院,拥有丰富的糖尿病病人及病例,目前世界范围内罕有完整的糖尿病患者人脸样本数据集)为实验基础样本,突破性的自建糖尿病患者和健康人人脸样本数据集,利用残差注意力神经网络模型进行糖尿病风险预测。目前已经公开的糖尿病无创风险预测的文献中,还未有采用人脸图像+残差注意力网络进行糖尿病无创风险预测的相关方法,本技术第一次采用
残差注意力网络模型对糖尿病患者人脸图像进行有监督的机器学习,通过深度学习的方法进行糖尿病风险预测。
附图说明
[0053]
图1为本发明中,一种基于人脸图像和残差注意力网络的糖尿病无创风险预测方法的流程图;
[0054]
图2为本发明中,所述步骤s1进行样本采集的示意图。
[0055]
图3为本发明中,所述步骤s2进行样本特征点定位、裁剪以及拼接的示意图。
[0056]
图4为本发明中,注意力模块具体实施例的结构框图。
[0057]
图5为本发明中,深度为56的残差注意力网络具体实施例的结构框图。
具体实施方式
[0058]
下面将结合本发明中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通的技术人员在没有做出创造性劳动的前提下所获得的所有其它实施例,都属于本发明的保护范围。
[0059]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
[0060]
本发明提供一种基于人脸图像和残差注意力网络的糖尿病无创风险预测方法,属于智能医疗领域,如图1所示,主要有以下步骤:
[0061]
步骤s1,招募受试者,构建包含糖尿病病人和健康人人脸图像的数据集。
[0062]
步骤s1中的数据集中的图像为在相同自然环境状态(光照、角度、表情)下通过高清摄像头采集的受试者正脸面部图像。
[0063]
步骤s2,预处理图像样本,定位人脸图像特征点,将关键区域裁剪、拼接并标记糖尿病诊断信息,获得标记好的样本数据集。
[0064]
步骤s2中先采用dlib机器学习库进行人脸图像特征点定位,根据特征点点位依次裁剪出4个矩形的关键区域,然后按顺序拼接成一个完整的矩形图像,最后为每一个拼接样本标注对应的诊断信息。标注采用dlib工具包中预训练好的模型“shape_predictor_68_face_landmarks.dat”进行68点标定,利用opencv进行图像化处理,在人脸上画出68个点。根据68个特征点的坐标,进行关键区域的定位及裁剪,这些均是机器视觉技术中的常规技术。
[0065]
步骤s3,将标记好的样本数据集随机划分为训练集、验证集、测试集。步骤s3中的随机划分是指将样本数据集进行shuffle操作后,将样本数据集划分成k个大小相似的互斥子集,每次都用其中k-1个子集的并集作为训练集,余下那个子集作为测试集,同时在测试集中划分50%的样本作为验证集。
[0066]
步骤s4,构建残差注意力网络,对样本进行有监督的机器学习。步骤s4采用pytorch机器学习库搭建56层的残差注意力网络,使用归一化指数函数softmax连接残差注意力网络末端的全连接层进行样本分类。
[0067]
步骤s5,根据验证集上的性能进行模型调参,基于测试集上的判别效果估计模型
的泛化能力,采用交叉验证的方法得到性能良好的糖尿病无创风险预测模型。步骤s5中进行模型效果判别时取k个测试结果的均值。
[0068]
在本实施例中,步骤s1构建的数据集可以为本单位自建的糖尿病患者人脸图像样本数据集,命名为tmu-dfd(tianjin medical university-diabetes face dataset)。其中招募的384名糖尿病受试者来自于天津医科大学朱宪彝纪念医院的门诊、住院患者;137名健康人受试者来自于本院职工、家属、研究生及社会志愿者。本实施例在相同自然环境状态(相同光照、角度)下通过高清摄像头采集每名受试者2到3张清晰的正脸面部图像,在本实施方式中,步骤s1中收集到的糖尿病患者人脸图像样本为966例、健康人的人脸图像样本为411例。本实施例中所采集的对象绝大多数均为中国人,使用该样本数据集对糖尿病无创风险预测模型进行训练,更具有针对性,对中国人适用性好。
[0069]
在本实施例中,为了提高受试者招募效率以及样本质量,需要严格设置纳排标准。具体的,所有受试者年龄需在40~90岁之间;面部皮肤无明显的疤痕,且面部图像采集当日没有化妆。其中糖尿病受试者需满足已在二级及以上医疗机构做出过明确的糖尿病诊断;健康人受试者血糖范围满足空腹全血血糖:3.9~6.1毫摩/升、餐后1小时:6.7-9.4毫摩/升、餐后2小时:≤7.8毫摩/升,或三个月内的体检报告中糖化血红蛋白h1a1c《6.5%,且无糖尿病史。所有受试者在年龄、性别等方面无明显统计学差异。
[0070]
具体的,样本图像采集示意图如图2所示。在一间光照良好的房间里,受试者端坐在桌子的一端,将头部固定在额托支架上。桌子的另一端放置一台高清摄像机,通过调整额托支架的高度,确保摄像机能够清晰的拍摄到受试者正脸的面部图像。整个样本采集的过程,尽可能保证受试者拍照角度、表情以及外部光照等条件一致。
[0071]
糖尿病患者由于血糖升高、毛细血管病变,面部常见于红肿、皮肤感染、瘙痒、干燥以及色素沉淀等症状,其中面部红肿的强度取决于浅静脉丛的血管充血程度。因此本发明的研究重点集中在人脸面部的皮肤上。同时为了避免实验中眉毛、眼睛、鼻子、嘴巴等面部器官的干扰,本实施例提取面部图像中额头区域(a)、左颊区(b)、右颊区(c)、下鄂区(d)4个关键区域进行实验。具体操作方式如图3所示,首先采用机器学习工具包dlib中的人脸特征点检测(faciallandmarkdetection)方法,对人脸样本进行68个关键点位的轮廓标注,每个点的坐标记为pi(x,y)。以p9(x,y)所在的水平轴为横坐标轴记为x轴,p1(x,y)所在的垂直轴为纵坐标轴记为y轴,同时根据特征点之间的坐标关系划定4个大小相同的正方形关键区域(64
×
64像素),分别记为a、b、c、d。若要准确的定位关键区域在人脸图像中的位置,必须先定位关键区域中心点的坐标,记关键区域a、b、c、d中心点的坐标分别为pa(x,y)、pb(x,y)、pc(x,y)、pd(x,y)。
[0072]
关键区域a在人脸中轴线上方额头区域附近,pa(x,y)的横坐标取鼻尖特征点34的横坐标记为p
34
(x),纵坐标取眉毛最高点的特征点(一般为p
20
(y)或p
25
(y))对应的纵坐标记为p
max-high
(y),同时加上关键区域像素值64对应长度的一半记为h,pa(x,y)的计算公式如下:
[0073]
pa(x,y)=(p
34
(x),p
max-high
(y)+h)
ꢀꢀꢀ
(1)
[0074]
关键区域b、c分别在人脸的左右脸颊附近,pb(x,y)、pc(x,y)的计算公式如下:
[0075]
pb(x,y)=(p
42
(x),p
32
(y))
ꢀꢀꢀ
(2)
[0076]
pc(x,y)=(p
47
(x),p
36
(y))
ꢀꢀꢀ
(3)
[0077]
pb(x,y)的横纵坐标分别为左眼最低处的特征点42的横坐标记为p
42
(x),鼻子最左侧特征点32的纵坐标p
32
(y)。pc(x,y)的横纵坐标分别为右眼最低处的特征点47的横坐标记为p
47
(x),鼻子最右侧特征点36的纵坐标记为p
36
(y)。
[0078]
关键区域d在嘴巴下方的中轴线附近,pd(x,y)的横坐标为嘴巴最下端特征点58的横坐标,记为p
58
(x),其纵坐标为特征点58与9的垂直距离的一半。pd(x,y)的具体计算公式如下:
[0079][0080]
四个关键区域的中心点坐标确认后,便可根据中心点坐标计算出每个正方形的关键区域四个顶点的具体坐标,计算公式如下:
[0081]
p
n,左上
(x,y)=(pn(x)-h,pn(y)+h)
ꢀꢀꢀ
(5)
[0082]
p
n,左下
(x,y)=(pn(x)-h,pn(y)-h)
ꢀꢀꢀ
(6)
[0083]
p
n,右上
(x,y)=(pn(x)+h,pn(y)+h)
ꢀꢀꢀ
(7)
[0084]
p
n,右下
(x,y)=(pn(x)+h,pn(y)-h)
ꢀꢀꢀ
(8)
[0085]
其中,n的取值范围为a、b、c、d;h为关键区域像素值64对应长度的一半。每张样本裁剪后的关键区域均按照a、b、c、d的顺序拼接为面部组合图(128
×
128像素),数据集中所有样本的拼接顺序保证都相同,根据脸型的不同,选取的关键区域的四个位置存在差异。
[0086]
本发明采用有监督的机器学习算法进行糖尿病无创检测,因此需要对数据样本进行诊断标注。具体的通过检索本院his、emr、lis、体检等医疗系统,将受试者诊断信息与图像样本关联起来。针对院外招募的受试者样本,将根据受试者提供的医疗机构相关诊断材料(体检报告、病历等)进行标注。
[0087]
为了得到分类性能和泛化能力良好的糖尿病无创风险预测模型,本发明将步骤s3标记好的样本数据集随机划分为训练集、验证集、测试集。具体的,随机划分是指将数据集进行shuffle操作后,将数据集划分成5个大小相似的互斥子集,每次都用其中4个子集的并集作为训练集,余下那1个子集作为测试集。在测试集中,随机划分50%的样本作为验证集,且测试集、验证集和训练集均包括相同比例的糖尿病和健康人样本。
[0088]
优选的,本实施例采用pytorch机器学习库搭建一种深度为56的残差注意力网络(residual attention network),记为attention-56。该网络通过端到端的训练方式与前馈网络体系结构相结合,由多个注意力模块堆叠构建而成。
[0089]
这些注意力模块会生成注意力感知功能。视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像获得需要关注的目标区域,而后重点获取所需要关注的目标信息,抑制其他无用信息。注意力机制极大的提高了机器视觉信息处理的效率与准确性。相比于传统残差网络模型机制,残差注意力机制可以达到更细粒度的特征匹配,同时加强目标区域的影响力,抑制非目标区域的影响力,有利于提升模型的拟合速度和泛化能力。
[0090]
其中注意力模块的结构框图如图4所示,堆叠结构是混合注意机制的基本应用,它结合了空间域中的空间信息和通道域中的通道信息。每一个注意力模块可以分成两个分支,一个分支叫主分支,是基本的残差网络的结构。另一分支是软掩码分支,包含的主要部分就是残差注意力学习机制。软掩码的原理在于通过另一层新的权重,将图片数据中关键
的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力,其本质是希望通过学习得到一组可以作用在特征图上的权重分布。
[0091]
图4中参数p表示为主分支和软掩码分支之前的预处理残差单元数。t表示为主干分支的残差单元数。通常设置t、p参数的关系如公式(1)所示:
[0092]
t=2*p
ꢀꢀꢀ
(1)
[0093]
具体的在本实施例中设置p=1、t=2,将特征图记为x。特征图首先经过1个残差单元进行预处理操作,然后分别进入主分支和软掩码分支。该残差单元采用bottleneck结构以减少参数量,bottleneck结构中第一层卷积核大小为1
×
1,通道数为64;第二层卷积核大小为3
×
3,通道数为64;第三层卷积核大小为1
×
1,通道数为256,卷积层之间的激活函数设置为relu。bottleneck结构的输出为第三层卷积层的输出与identity block的输出之和,大小为112
×
112。
[0094]
主分支主要包括2个串联的残差单元,每个残差单元的结构与参数与预处理操作的残差单元一致,记其输出为t(x)。软掩码分支包含快速前馈扫描和自上而下反馈两个步骤,特征图先经过两次下采样操作增大感受野,达到最低分辨率后,再通过相同数量的上采样操作将特征图的尺寸放大到与输入的原始特征图一致形成注意力特征图,紧接着接2个1
×
1的卷积层,最后通过sigmoid激活函数得到混合域(结合了空间域中的空间信息和通道域中的通道信息)的注意力,sigmoid函数如公式(2)所示:
[0095][0096]
此外,在下采样和上采样之间添加了跳跃连接,以融合不同比例特征图的特征信息。软掩码分支的输出记为m(x),m(x)先与主分支输出t(x)进行矩阵相乘(element-wise product),其结果再与t(x)进行矩阵相加(element-wise sum)的输出h如公式(3)所示,再经过p个残差单元即得到注意力模块的输出:
[0097]
h(x)=(1+m(x))*t(x)
ꢀꢀꢀ
(3)
[0098]
优选的,残差注意力网络具体实施例的结构框图如图5所示。样本图像被输入残差注意力网络,首先进行1次卷积和最大池化操作,然后穿插的经过3个残差单元和3个注意力模块,再经过平均池化操作后到达全连接层,最终使用归一化指数函数softmax连接残差注意力网络末端的全连接层进行糖尿病风险预测,输出预测结果。
[0099]
具体的,第一个卷积层包含大小为7
×
7的卷积核、步长为2
×
2,通道数为64,填充模式设置为valid,卷积层的输出为112
×
112。
[0100]
最大池化层的池化窗口大小为3
×
3,步长为2
×
2,经过最大池化操作后输出的特征图大小为56
×
56。
[0101]
第一个残差单元采用bottleneck结构以减少参数量。bottleneck结构中第一层卷积核大小为1
×
1,通道数为64;第二层卷积核大小为3
×
3,通道数为64;第三层卷积核大小为1
×
1,通道数为256;各卷积层之间的激活函数设置为relu。bottleneck结构的输出为第三层卷积层的输出与identityblock的输出之和,大小为56
×
56。
[0102]
第一个残差单元后连接第一个注意力模块,该注意力模块的输出大小为:56
×
56。
[0103]
第一个注意力模块后连接第二个残差单元,也采用bottleneck结构,设置3层卷积以减少参数量,其中第一层卷积核大小为1
×
1,通道数为128;第二层卷积核大小为3
×
3,通
道数为128;第三层卷积核大小为1
×
1,通道数为512;各卷积层之间的激活函数设置为relu。bottleneck结构的输出为第三层卷积层的输出与identityblock的输出之和,大小为28
×
28。
[0104]
第二个残差单元后连接第二个注意力模块,该注意力模块的输出大小为:28
×
28。
[0105]
第二个注意力模块后连接第三个残差单元,也采用bottleneck结构,设置3层卷积以减少参数量,其中第一层卷积核大小为1
×
1,通道数为256;第二层卷积核大小为3
×
3,通道数为256;第三层卷积核大小为1
×
1,通道数为1024;各卷积层之间的激活函数设置为relu。bottleneck结构的输出为第三层卷积层的输出与identityblock的输出之和,大小为14
×
14。
[0106]
第三个残差单元后连接第三个注意力模块,该注意力模块的输出大小为:14
×
14。
[0107]
第三个注意力模块后连接第四个残差单元,采用3个串联的bottleneck结构,设置3层卷积以减少参数量。每个bottleneck中第一层卷积核大小为1
×
1,通道数为512;第二层卷积核大小为3
×
3,通道数为512;第三层卷积核大小为1
×
1,通道数为2048;各卷积层之间的激活函数设置为relu。第四个残差单元的输出大小为7
×
7。
[0108]
第四个残差单元输出的特征图进行平均池化的操作,池化窗口的大小为7
×
7,步长为1
×
1。经过平均池化的特征图大小为1
×
1。
[0109]
最后本实施例使用归一化指数函数softmax连接残差注意力网络末端的全连接层进行糖尿病风险预测。
[0110]
具体的,步骤s5中进行模型效果判别时采用5折交叉验证的方法,每次选择不同的1份样本作为测试集,其他4份样本作为训练集,重复5次实验。根据验证集上的性能进行模型调参,基于测试集上的判别效果估计模型的泛化能力,取5次模型测试的平均值作为最终模型的评价指标,得到性能良好的风险预测模型。
[0111]
本发明采用基于残差注意力网络来构建糖尿病无创风险预测模型,该残差注意力网络通过端到端的训练方式与最新的前馈网络体系结构相结合,由多个注意力模块堆叠构建而成。相比于传统残差网络模型,残差注意力网络可以达到更细粒度的特征匹配,同时加强目标区域的影响力,抑制非目标区域的影响力,有利于提升模型的拟合速度和泛化能力;此外本发明采用非侵入式的检验方法,即通过糖尿病无创风险预测模型分析受试者正脸面部图像,预测受试者未来糖尿病发病风险。本发明方法耗时短、成本低且支持大范围筛查及远程诊疗,有利于快速筛查高发病人群中的糖尿病患者,提醒他们尽早控制血糖,避免糖尿病并发症的发生。
[0112]
上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
[0113]
本发明未述及之处适用于现有技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1