一种相似病例推荐方法及装置与流程
1.本发明涉及医疗数据处理领域,尤其涉及一种相似病例推荐方法,本技术 还提供一种相似病例推荐装置。
背景技术:
2.医生在为患者进行诊断治疗的过程中,相似病例及其相似病例的疗法,对患 者的诊断治疗具有不可或缺的作用,是医生为患者快速确诊,查找病因,临床 医治的重要参考。
3.现有技术中,相似病例的获取,一般通过患者的病例信息对数据库中的病例 数据进行匹配。具体的做法是,将所述病历信息包括若干属性信息;利用方差 分析算法,剔除各个病历信息中离散度大于默认第一阈值的属性信息;提取各 个病历信息对应的特征向量;并计算各个病历信息对应的特征向量之间的相似 度;将相似度大于默认第二阈值的特征向量对应的病历信息确定为相似病历信 息。但是,利用方差分析算法,需要剔除各个病例中的离散度大于默认阈值的 属性信息,其中的阈值难以确定。并且现有技术中的病例数据的比较是全量和 实时的比较,对性能要求高,用时长,不利于诊断的高效进行。
技术实现要素:
4.为解决上述技术问题,本技术提供一种相似病例推荐方法及一种额度确定 装置。
5.本技术提供一种相似病例推荐方法,包括:
6.获取历史病例数据,将该历史病例数据依照患者病例数据的属性类别分割 为多个类别数据;
7.将所述类别数据进行向量化和归一化处理,并根据所述类别数据依次计算 所述患者病例数据和历史病例数据的文本相似度和信息相似度;
8.根据所述文本相似度和信息相似度,筛选所述历史病例数据获得筛选病例 数据,为所述筛选病例数据进行类分组,并提取类特征;
9.将所述患者病例数据与所述类特征和类分组内病例进行比较,获得推荐病 例。
10.可选的,所述属性类别包括:患者基本信息、病症主诉、现病史、idc诊 断、数值型检验检测结果、文本型检验检测结果、医嘱和病程数据。
11.可选的,所述每个属性类别的数据采用不同的编码方式处理,包括:
12.采用构造文本分词后的字典,对词语进行one-hot编码;
13.对所述现病历采用词袋模型进行词袋化;
14.对所述病症主诉和现病史进行word2vec编码处理。
15.可选的,所述归一化包括:
16.线性函数转换、对数函数转换、反正切转换或z-score标准化。
17.可选的,所述相似度包括:基于欧式距离、余弦距离或杰卡德方式计算相似 度。
18.本技术还提供一种相似病例推荐装置,包括:
19.获取模块,用于获取历史病例数据,将该历史病例数据依照患者病例数据 的属性
类别分割为多个类别数据;
20.处理模拟,用于将所述类别数据进行向量化和归一化处理,并根据所述类 别数据依次计算所述患者病例数据和历史病例数据的文本相似度和信息相似度;
21.提取模块,用于根据所述文本相似度和信息相似度,筛选所述历史病例数 据获得筛选病例数据,为所述筛选病例数据进行类分组,并提取类特征;
22.结果模块,用于将所述患者病例数据与所述类特征和类分组内病例进行比 较,获得推荐病例。
23.可选的,所述属性类别包括:患者基本信息、病症主诉、现病史、idc诊 断、数值型检验检测结果、文本型检验检测结果、医嘱和病程数据。
24.可选的,所述每个属性类别的数据采用不同的编码方式处理,包括:
25.采用构造文本分词后的字典,对词语进行one-hot编码;
26.对所述现病历采用词袋模型进行词袋化;
27.对所述病症主诉和现病史进行word2vec编码处理。
28.可选的,所述归一化包括:
29.线性函数转换、对数函数转换、反正切转换或z-score标准化。
30.可选的,所述相似度包括:基于欧式距离、余弦距离或杰卡德方式计算相似 度。
31.本技术的优点是:
32.申请提供一种相似病例推荐方法,包括:获取历史病例数据,将该历史病 例数据依照患者病例数据的属性类别分割为多个类别数据;将所述类别数据进 行向量化和归一化处理,并根据所述类别数据依次计算所述患者病例数据和历 史病例数据的文本相似度和信息相似度;根据所述文本相似度和信息相似度, 筛选所述历史病例数据获得筛选病例数据,为所述筛选病例数据进行类分组, 并提取类特征;将所述患者病例数据与所述类特征和类分组内病例进行比较, 获得推荐病例。通过分类处理历史病例数据,使得只需要小批量的实时计算, 就能够获得相似病例,并且本方案无需专业人员确定方差,操作更为简易。
附图说明
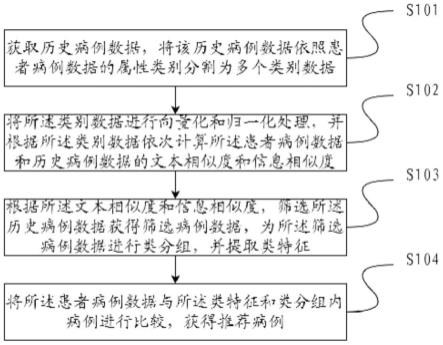
33.图1是本技术中通过比较确定额度的流程示意图。
34.图2是本技术中通过比较进行额度确定的装置示意图。
35.具体实施方式
36.在下面的描述中阐述了很多具体细节以便于充分理解本技术,但是本技术 能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背 本技术内涵的情况下做类似推广,因此本技术不受下面公开的具体实施的限制。
37.申请提供一种相似病例推荐方法,包括:获取历史病例数据,将该历史病例 数据依照患者病例数据的属性类别分割为多个类别数据;将所述类别数据进行 向量化和归一化处理,并根据所述类别数据依次计算所述患者病例数据和历史 病例数据的文本相似度和信息相似度;根据所述文本相似度和信息相似度,筛 选所述历史病例数据获得筛选病例
数据,为所述筛选病例数据进行类分组,并 提取类特征;将所述患者病例数据与所述类特征和类分组内病例进行比较,获 得推荐病例。通过分类处理历史病例数据,使得只需要小批量的实时计算,就 能够获得相似病例,并且本方案无需专业人员确定方差,操作更为简易。
38.图1是本技术中相似病例推荐流程图。
39.请参照图1所示,s101获取历史病例数据,将该历史病例数据依照患者病 例数据的属性类别分割为多个类别数据。
40.所述历史病例数据可以是已存在的全部病例数据,本技术所述病例数据还可 以是一个医院的全部病例数据,这些病例数据的电子数据,或者纸张记录的数 据电子化后的病例数据。
41.所述病例数据可以包括全部科室,疾病的病例数据,但是在具体的应用中, 所述病例数据是特征与患者相同科室的病例数据,如此划分有助于提高相似病 例的查找速度。但是,当所述患者科室无法确认患者病症所属类目时,还可以 将所述历史病例数据的范围扩大到整个医院。
42.获取所述历史病例数据,将所述历史病例数据按照患者的病例数据的属性类 别进行分割,形成多个类别的类别数据。上述提到的历史病例数据是针对历史 上的每个患者,单独且完整的病例数据,因此首先需要对所述数据进行分割, 并将分割后的所述类别数据与患者的属性类别进行一一对应
43.请参考图1所示,s102将所述类别数据进行向量化和归一化处理,并根据 所述类别数据依次计算所述患者病例数据和历史病例数据的文本相似度和信息 相似度。
44.对所述分割后的数据来说,其并不是处于相同维度的,每个患者的情况不同, 其产生的数据的属性类别也不尽相同,为了能够进行更好的比较,需要对所述 类别数据进行以下处理。在本技术中,所述类别数据至少包括:患者基本信息、 病症主诉、现病史、idc诊断、数值型检验检测结果、文本型检验检测结果、 医嘱和病程数据。
45.所述对类别数据的处理针对不同类别的类别数据进行不同的处理方式,包括: 向量化处理和归一化处理。
46.所述向量化处理包括:
47.本技术通过one-hot编码对所述数据词语进行向量化改造,采用构造文本 分词后的字典,对词语进行one-hot编码。
48.词袋化处理,本技术对所述现病史采用词袋模型进行词袋化。
49.word2vec编码处理,对所述病症主诉和现病史进行word2vec编码处理。
50.所述归一化包括:
51.线性函数转换,所述线性函数转换的公式如下:
52.y=(x-minvalue)/(maxvalue-minvalue)
53.其中x、y分别为转换前、后的值,maxvalue、minvalue分别为样本的最 大值和最小值。
54.对数函数转换:所述对数函数转换的公式如下:
55.y=log10(x)
56.其中x、y分别为转换前、后的值。
57.反正切函数转换:所述反正切函数转化公式如下:
58.y=atan(x)*2/pi
59.其中,x、y分别为转换前、后的值,所述pl是常数。
60.z-score标准化:所述z-score标准化的公式如下:
61.z=(x-μ)/σ
62.其中,x为某一具体分数,μ为平均数,σ为标准偏差,z值的大小代表着原 始分数和母体平均值之间的距离,是以标准偏差为单位计算。
63.经过上述处理,所述历史病例信息实现了向量化和归一化,接下来在此基础 上进行信息相似度的计算。
64.本技术中所述信息相似度的计算是通过基于欧式距离、余弦距离或杰卡德方 式计算相似度。
65.所述欧式距离计算相似度的方法是:
66.将所述历史病例数据和患者病例数据的两个数值向量,表示两个实例在欧式 空间中的位置:a=(a1,a2,
…
ai,
…
an),b=(b1,b2,
…
bi,
…
bn)。
67.二者的欧氏距离为:
68.例如,a=(a1,a2)和b=(b1,b2),二者在x轴上的差异大小是a1-b1,在y轴 上的差异是a2-b2。综合两个坐标轴上的差异,就得到了两点之间的距离:
[0069][0070]
基于欧式距离的文本相似度计算相似度的公式是:sim=1/(d+0.001)。
[0071]
分母中的”1”用来保证相似度最高是1。当然,相似度可以根据场景要求花 式定义。
[0072]
所述余弦距离的方式计算相似度的方法是:
[0073]
余弦距离来源于向量之间夹角的余弦值。所述历史病例数据和患者病例数 据两个向量a=(a1,a2,
…
ai,
…
an),b=(b1,b2,
…
bi,
…
bn)。
[0074]
二者的夹角的余弦值等于:
[0075]
通过余弦距离计算相似度的公式是:sim=1-cos。
[0076]
所述杰卡德相似度的计算方式如下:
[0077]
所述历史病例数据和患者病例数据两个向量的集合a和b,那么二者的杰 卡德相似度为:
[0078]
进一步的,在杰卡德相似度的分母增加一个对文本长度差异的惩罚,则得 到:
[0079][0080]
其中,α是一个超参数,可以根据相似度的效果重设大小。
[0081]
请参照图1所示,s103根据所述文本相似度和信息相似度,筛选所述历史 病例数据获得筛选病例数据,为所述筛选病例数据进行类分组,并提取类特征。
[0082]
本技术中,所述相似度确定后,则需要根据所述相似度对所述历史病例数 据进行筛选,并将所述病例数据分组。具体的,包括:信息相似性计算和类的 计算。
[0083]
所述信息相似性计算是指:
[0084]
已知病历信息相似性sim(vi,vj),其相似性公式如下:已知病历信息相似性sim(vi,vj),其相似性公式如下:
[0085]
其中所述αk是第k个信息项所对应的权重,它的所有信息项权重总和为 100%,sim(vik,vjk)是指两条病历信息(vi,vj)中仍中的第k个信息项的 相似程度,每个信息项如果相同则定义为1,不同则定义为0。
[0086]
当所述sim(vi,vj)》=80%时,可认为此两条信息(vi,vj)高度相似。 如果病历信息不完整,则将缺失的信息项的权值分配给其他信息项,分配比例 按照未缺失信息项在未缺失项权重总和中所占的化例来运算;若信息缺失的项 较多(按下表所示,折合权重不足60%时),则不再比较相似程度,直接以不相 似来认定。各信息项的比对优先级及对应的权重α值。
[0087]
所述类的计算如下:
[0088]
以所述相似性大小为基础设置分支点,所述分支节点下对两两比较后相似 度较为近似的(相似度超过80以上)定义为相似分组。同时使用聚类的方式来 快速的对电子病历进行聚类分组。具体步骤为在相同的诊断疾病、相同性别、 相同年龄组分组下,对分别对组内主诉现病史、主诉现病史+基础检验检查、主 诉现病史+基础检验检查+专项检验检查、主诉现病史+基础检验检查+专项检验 检查+医嘱四种情形计算聚类。或使用相似度超过80%的病历作为相近分组。
[0089]
将所述每个组设置为一个类,并提取所述类的特征。
[0090]
请参考图1所示,s104将所述患者病例数据与所述类特征和类分组内病例 进行比较,获得推荐病例。
[0091]
获得所述类以及类的特征后,将所述患者的病例数据与所述类特征相比较, 然后确定所述类后与所述类内的历史病例数据相比较,最终获得推荐病例。
[0092]
本技术还提供一种相似病例推荐装置,包括:获取模块201,处理模拟202, 提取模块203,结果模块204。
[0093]
图2是本技术中相似病例推荐装置示意图。
[0094]
请参照图2所示,获取模块201,用于获取历史病例数据,将该历史病例 数据依照患者病例数据的属性类别分割为多个类别数据。
[0095]
所述历史病例数据可以是已存在的全部病例数据,本技术所述病例数据还可 以是一个医院的全部病例数据,这些病例数据的电子数据,或者纸张记录的数 据电子化后的病例数据。
[0096]
所述病例数据可以包括全部科室,疾病的病例数据,但是在具体的应用中, 所述病例数据是特征与患者相同科室的病例数据,如此划分有助于提高相似病 例的查找速度。
但是,当所述患者科室无法确认患者病症所属类目时,还可以 将所述历史病例数据的范围扩大到整个医院。
[0097]
获取所述历史病例数据,将所述历史病例数据按照患者的病例数据的属性类 别进行分割,形成多个类别的类别数据。上述提到的历史病例数据是针对历史 上的每个患者,单独且完整的病例数据,因此首先需要对所述数据进行分割, 并将分割后的所述类别数据与患者的属性类别进行一一对应
[0098]
请参考图2所示,处理模拟202,用于将所述类别数据进行向量化和归一化 处理,并根据所述类别数据依次计算所述患者病例数据和历史病例数据的文本 相似度和信息相似度。
[0099]
对所述分割后的数据来说,其并不是处于相同维度的,每个患者的情况不同, 其产生的数据的属性类别也不尽相同,为了能够进行更好的比较,需要对所述 类别数据进行以下处理。在本技术中,所述类别数据至少包括:患者基本信息、 病症主诉、现病史、idc诊断、数值型检验检测结果、文本型检验检测结果、 医嘱和病程数据。
[0100]
所述对类别数据的处理针对不同类别的类别数据进行不同的处理方式,包括: 向量化处理和归一化处理。
[0101]
所述向量化处理包括:
[0102]
本技术通过one-hot编码对所述数据词语进行向量化改造,采用构造文本 分词后的字典,对词语进行one-hot编码。
[0103]
词袋化处理,本技术对所述现病史采用词袋模型进行词袋化。
[0104]
word2vec编码处理,对所述病症主诉和现病史进行word2vec编码处理。
[0105]
所述归一化包括:
[0106]
线性函数转换,所述线性函数转换的公式如下:
[0107]
y=(x-minvalue)/(maxvalue-minvalue)
[0108]
其中x、y分别为转换前、后的值,maxvalue、minvalue分别为样本的最 大值和最小值。
[0109]
对数函数转换:所述对数函数转换的公式如下:
[0110]
y=log10(x)
[0111]
其中x、y分别为转换前、后的值。
[0112]
反正切函数转换:所述反正切函数转化公式如下:
[0113]
y=atan(x)*2/pi
[0114]
其中,x、y分别为转换前、后的值,所述pl是常数。
[0115]
z-score标准化:所述z-score标准化的公式如下:
[0116]
z=(x-μ)/σ
[0117]
其中,x为某一具体分数,μ为平均数,σ为标准偏差,z值的量代表着原始 分数和母体平均值之间的距离,是以标准偏差为单位计算。
[0118]
经过上述处理,所述历史病例信息实现了向量化和归一化,接下来在此基础 上进行信息相似度的计算。
[0119]
本技术中所述信息相似度的计算是通过基于欧式距离、余弦距离或杰卡德方 式计算相似度。
[0120]
所述欧式距离计算相似度的方法是:
[0121]
将所述历史病例数据和患者病例数据的两个数值向量,表示两个实例在欧式 空间中的位置:a=(a1,a2,
…
ai,
…
an),b=(b1,b2,
…
bi,
…
bn)。
[0122]
二者的欧氏距离为:
[0123]
例如,a=(a1,a2)和b=(b1,b2),二者在x轴上的差异大小是a1-b1,在y轴 上的差异是a2-b2。综合两个坐标轴上的差异,就得到了两点之间的距离:
[0124][0125]
基于欧式距离的文本相似度计算相似度的公式是:sim=1/(d+0.001)。
[0126]
分母中的”1”用来保证相似度最高是1。当然,相似度可以根据场景要求花 式定义。
[0127]
所述余弦距离的方式计算相似度的方法是:
[0128]
余弦距离来源于向量之间夹角的余弦值。所述历史病例数据和患者病例数 据两个向量a=(a1,a2,
…
ai,
…
an),b=(b1,b2,
…
bi,
…
bn)。
[0129]
二者的夹角的余弦值等于:
[0130]
通过余弦距离计算相似度的公式是:sim=1-cos。
[0131]
所述杰卡德相似度的计算方式如下:
[0132]
所述历史病例数据和患者病例数据两个向量的集合a和b,那么二者的杰 卡德相似度为:
[0133]
进一步的,在杰卡德相似度的分母增加一个对文本长度差异的惩罚,则得 到:
[0134][0135]
其中,α是一个超参数,可以根据相似度的效果重设大小。
[0136]
请参照图2所示,提取模块203,用于根据所述文本相似度和信息相似度, 筛选所述历史病例数据获得筛选病例数据,为所述筛选病例数据进行类分组, 并提取类特征。
[0137]
本技术中,所述相似度确定后,则需要根据所述相似度对所述历史病例数 据进行筛选,并将所述病例数据分组。具体的,包括:信息相似性计算和类的 计算。
[0138]
所述信息相似性计算是指:
[0139]
已知病历信息相似性sim(vi,vj),其相似性公式如下:已知病历信息相似性sim(vi,vj),其相似性公式如下:
[0140]
其中所述αk是第k个信息项所对应的权重,它的所有信息项权重总和为 100%,sim(vik,vjk)是指两条病历信息(vi,vj)中仍中的第k个信息项的 相似程度,每个信息项
如果相同则定义为1,不同则定义为0。
[0141]
当所述sim(vi,vj)》=80%时,可认为此两条信息(vi,vj)高度相似。 如果病历信息不完整,则将缺失的信息项的权值分配给其他信息项,分配比例 按照未缺失信息项在未缺失项权重总和中所占的化例来运算;若信息缺失的项 较多(按下表所示,折合权重不足60%时),则不再比较相似程度,直接以不相 似来认定。各信息项的比对优先级及对应的权重α值。
[0142]
所述类的计算如下:
[0143]
以所述相似性大小为基础设置分支点,所述分支节点下对两两比较后相似 度较为近似的(相似度超过80以上)定义为相似分组。同时使用聚类的方式来 快速的对电子病历进行聚类分组。具体步骤为在相同的诊断疾病、相同性别、 相同年龄组分组下,对分别对组内主诉现病史、主诉现病史+基础检验检查、主 诉现病史+基础检验检查+专项检验检查、主诉现病史+基础检验检查+专项检验 检查+医嘱四种情形计算聚类。或使用相似度超过80%的病历作为相近分组。
[0144]
将所述每个组设置为一个类,并提取所述类的特征。
[0145]
请参考图2所示,结果模块204,用于将所述患者病例数据与所述类特征 和类分组内病例进行比较,获得推荐病例。
[0146]
获得所述类以及类的特征后,将所述患者的病例数据与所述类特征相比较, 然后确定所述类后与所述类内的历史病例数据相比较,最终获得推荐病例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1