基于单分子测序的发酵金鲳深度学习质量判别方法及系统
1.本技术涉及发酵水产食品快速分析检测领域,具体而言,涉及基于单分子测序的发酵金鲳深度学习质量判别方法及系统。
背景技术:
2.传统发酵金鲳是一种传统的固态自然发酵鱼制品,是沿海地区特色的发酵鱼制品。据统计,2019年我国发酵鱼制品产量达152万吨,约占水产品加工总量(2171万吨)的7.01%,约占海水加工产品(1776万吨)的8.57%。传统发酵金鲳具有营养丰富和风味独特等主要优势,深受消费者的青睐,但由于传统发酵鱼生产体系缺乏系统的理论支持,自动化生产水平低。因此,实现传统发酵金鲳靶向工艺调控和品质监测是水产品加工行业迫切需要解决的关键问题之一。
3.由于发酵体系中微生物与代谢产物之间复杂的物质和能力交换,发酵金鲳的内部营养成分存在明显差异。目前,发酵金鲳品质的鉴定主要依赖色泽、气味和硬度等人工经验式感官判别,存在主观性强、标准化程度低和产品品质不稳定等问题。在固态自然发酵体系中,传统发酵金鲳的品质与不同微生物区系在发酵过程中复杂的生物学相互作用密切相关。单分子实时测序技术具读长长,通量高,物种注释准的优点,能够准确有效地分析微生物群落结构。深度学习是机器学习的一个分支,利用神经网络算法建立相应的模型,使机器具有学习分析能力并实现智能测判。单分子实时测序技术和机器学习结合能高效地对发酵金鲳的品质进行判别,目前尚未见利用单分子实时测序技术和机器学习技术对发酵金鲳的质量等级进行判别的报道。
技术实现要素:
4.为了解决上述问题,本发明的目的是通过单分子实时测序对传统发酵金鲳的微生物群落结构进行分析,并基于发酵金鲳的微生物菌群组成及丰度,利用神经网络算法的机器学习技术对传统发酵金鲳的品质进行判别。该方法能够高效、准确对传统发酵金鲳的品质进行测判,满足现代水产食品快速检测和分析的要求。
5.为了实现上述技术目的,本技术提供了基于单分子测序的发酵金鲳深度学习质量判别方法,包括以下步骤:
6.制备不同品质等级的传统发酵金鲳粉末状样品,传统发酵金鲳粉末状样品用于单分子实时测序进行微生物群落结构分析;
7.提取传统发酵金鲳粉末状样品的宏基因组dna,并检验片段完整度、纯度及浓度;
8.基于宏基因组dna,获取发酵金鲳样品的物种丰度数据,作为神经网络模型的训练样本数据;
9.通过训练样本数据,对神经网络模型进行训练,并使用训练好的神经网络模型,对不同传统发酵金鲳的品质等级进行判别,其中,神经网络模型采用tansig作为隐藏层传递函数,采用purelin函数作为输出层传递函数,采用梯度下降法进行训练。
10.优选地,在制备不同品质等级的传统发酵金鲳检测样品的过程中,将若干传统发酵金鲳去皮去骨后,每条鱼从起点开始向尾部方向依次以中线和上表层为基点制取2cm
×
2cm
×
1cm的待测块状样品;
11.将待测块状样品,采用液氮冷却后研磨5-8s,每个样品重复研磨3次,制得传统发酵金鲳粉末状样品。
12.优选地,在提取宏基因组dna的过程中,采用omniscripy rt kit提取宏基因组dna,通过单分子实时测序对不同样品的dna进行测序,通过对ccs序列进行过滤、聚类,并进行物种注释和丰度分析,获取物种丰度数据。
13.优选地,在获取物种丰度数据的过程中,还包括以下步骤:
14.pcr扩增程序为:95℃预变性2min;98℃变性10s,55℃退火30s,72℃延伸90s,共循环30次;72℃终端延伸2min;
15.ccs序列识别:根据minpasses≥5,minpredictedaccuracy≥0.9识别初始ccs序列。
16.优选地,在对ccs序列进行过滤的过程中,通过识别barcode序列,识别不同样品的初始ccs序列,并去除嵌合体,得到高质量的ccs序列。
17.优选地,在对ccs序列进行聚类的过程中,基于ccs序列,在相似性97%的水平上对序列进行聚类,获取特征序列,其中,以所有序列数的0.005%作为阈值过滤otus;
18.以silva为参考数据库,使用朴素贝叶斯分类器结合比对的方法,对特征序列进行分类学注释,得到每个特征对应的物种分类信息,并在各个水平统计各样品群落组成,利用qime软件获得不同分类水平的物种丰度表,其中,各个水平包括门、纲、目、科、属。
19.优选地,在对神经网络模型进行训练的过程中,利用mapminmax函数将训练样本数据归一化到[0,1]之间,其计算公式为:
[0020]
y=(y
max-y
min
)
×
(x-x
min
)/(x
max-x
min
)+y
min
[0021]
其中,y为归一化之后的值,x
max
为样本数据的最大值,x
min
为样本数据的最小值。
[0022]
优选地,在对神经网络模型进行训练的过程中,tansig函数的表达式为:purelin函数的表达式为y=x。
[0023]
优选地,在对神经网络模型进行训练的过程中,基于梯度下降法对网络权值和阈值进行调整,其中,
[0024]
隐含层到输出层的权值:w
jk
=w
jk
+ηh
jek
;
[0025]
输入层到隐含层的权值:
[0026]
隐含层到输出层的阈值:bk=bk+ηek;
[0027]
输入层到输出层的阈值:
[0028]
其中:w
ij
为输出层到隐藏层的权值,w
jk
为隐藏层到输出层的权值,bk为隐含层到输出层的阈值,aj为输入层到隐含层的阈值,η为学习速率,hj为隐含层输出。
[0029]
基于单分子测序的发酵金鲳深度学习质量判别系统,包括:
[0030]
数据采集模块,用于通过制备不同品质等级的传统发酵金鲳粉末状样品,传统发酵金鲳粉末状样品用于单分子实时测序进行微生物群落结构分析;提取传统发酵金鲳粉末状样品的宏基因组dna,并检验片段完整度、纯度及浓度;
[0031]
样本构建模块,用于基于宏基因组dna,获取发酵金鲳样品的物种丰度数据,作为神经网络模型的训练样本数据;
[0032]
数据识别模块,用于通过训练样本数据,对神经网络模型进行训练,并使用训练好的神经网络模型,对不同传统发酵金鲳的品质等级进行判别,其中,神经网络模型采用tansig作为隐藏层传递函数,采用purelin函数作为输出层传递函数,采用梯度下降法进行训练。
[0033]
本发明公开了以下技术效果:
[0034]
本发明的方法突破了人工经验式判断发酵阶段存在的主观性强,标准化程度低和产品品质不稳定等问题,利用单分子实时测序获得样品的微生物群落结构组成,并结合机器学习判断传统发酵金鲳的品质等级,具有准确性高的特点,有利于传统发酵金鲳的品质监测和工业化生产。
[0035]
神经网络具有极强的信息处理能力,具有强大的容错性和适应性,能够自动排除干扰因素并抽取有效数据特征,以获得准确结果。利用神经网络对传统发酵金鲳微生物丰度数据判断传统发酵金鲳的品质质量,对保证传统发酵金鲳品质稳定性有重要的指导意义。
附图说明
[0036]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0037]
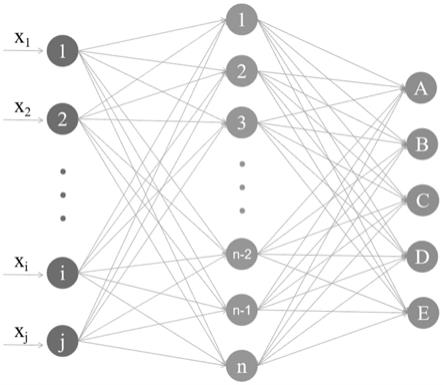
图1传统发酵金鲳质量判别神经网络原理图;
[0038]
图2不同等级的传统发酵金鲳的微生物丰度图;
[0039]
图3传统发酵金鲳质量判别神经网络模型拟合图。
具体实施方式
[0040]
下为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本技术实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0041]
如图1-3所示,本技术提供了基于单分子测序的发酵金鲳深度学习质量判别方法,包括以下步骤:
[0042]
制备不同品质等级的传统发酵金鲳粉末状样品,传统发酵金鲳粉末状样品用于单
分子实时测序进行微生物群落结构分析;
[0043]
提取传统发酵金鲳粉末状样品的宏基因组dna,并检验片段完整度、纯度及浓度;
[0044]
基于宏基因组dna,获取发酵金鲳样品的物种丰度数据,作为神经网络模型的训练样本数据;
[0045]
通过训练样本数据,对神经网络模型进行训练,并使用训练好的神经网络模型,对不同传统发酵金鲳的品质等级进行判别,其中,神经网络模型采用tansig作为隐藏层传递函数,采用purelin函数作为输出层传递函数,采用梯度下降法进行训练。
[0046]
进一步优选地,在制备不同品质等级的传统发酵金鲳检测样品的过程中,将若干传统发酵金鲳去皮去骨后,每条鱼从起点开始向尾部方向依次以中线和上表层为基点制取2cm
×
2cm
×
1cm的待测块状样品;
[0047]
将待测块状样品,采用液氮冷却后研磨5-8s,每个样品重复研磨3次,制得传统发酵金鲳粉末状样品。
[0048]
进一步优选地,在提取宏基因组dna的过程中,采用omniscripy rt kit提取宏基因组dna,通过单分子实时测序对不同样品的dna进行测序,通过对ccs序列进行过滤、聚类,并进行物种注释和丰度分析,获取物种丰度数据。
[0049]
进一步优选地,在获取物种丰度数据的过程中,还包括以下步骤:
[0050]
pcr扩增程序为:95℃预变性2min;98℃变性10s,55℃退火30s,72℃延伸90s,共循环30次;72℃终端延伸2min;
[0051]
ccs序列识别:根据minpasses≥5,minpredictedaccuracy≥0.9识别初始ccs序列。
[0052]
进一步优选地,在对ccs序列进行过滤的过程中,通过识别barcode序列,识别不同样品的初始ccs序列,并去除嵌合体,得到高质量的ccs序列。
[0053]
进一步优选地,在对ccs序列进行聚类的过程中,基于ccs序列,在相似性97%的水平上对序列进行聚类,获取特征序列,其中,以所有序列数的0.005%作为阈值过滤otus;
[0054]
以silva为参考数据库,使用朴素贝叶斯分类器结合比对的方法,对特征序列进行分类学注释,得到每个特征对应的物种分类信息,并在各个水平统计各样品群落组成,利用qime软件获得不同分类水平的物种丰度表,其中,各个水平包括门、纲、目、科、属。
[0055]
进一步优选地,在对神经网络模型进行训练的过程中,利用mapminmax函数将训练样本数据归一化到[0,1]之间,其计算公式为:
[0056]
y=(y
max-y
min
)
×
(x-x
min
)/(x
max-x
min
)+y
min
[0057]
其中,y为归一化之后的值,x
max
为样本数据的最大值,x
min
为样本数据的最小值。
[0058]
进一步优选地,在对神经网络模型进行训练的过程中,tansig函数的表达式为:purelin函数的表达式为y=x。
[0059]
优选地,在对神经网络模型进行训练的过程中,基于梯度下降法对网络权值和阈值进行调整,其中,
[0060]
隐含层到输出层的权值:w
jk
=w
jk
+ηh
jek
;
[0061]
输入层到隐含层的权值:
[0062]
隐含层到输出层的阈值:bk=bk+ηek;
[0063]
输入层到输出层的阈值:
[0064]
其中:w
ij
为输出层到隐藏层的权值,w
jk
为隐藏层到输出层的权值,bk为隐含层到输出层的阈值,aj为输入层到隐含层的阈值,η为学习速率,hj为隐含层输出。
[0065]
基于单分子测序的发酵金鲳深度学习质量判别系统,包括:
[0066]
数据采集模块,用于通过制备不同品质等级的传统发酵金鲳粉末状样品,传统发酵金鲳粉末状样品用于单分子实时测序进行微生物群落结构分析;提取传统发酵金鲳粉末状样品的宏基因组dna,并检验片段完整度、纯度及浓度;
[0067]
样本构建模块,用于基于宏基因组dna,获取发酵金鲳样品的物种丰度数据,作为神经网络模型的训练样本数据;
[0068]
数据识别模块,用于通过训练样本数据,对神经网络模型进行训练,并使用训练好的神经网络模型,对不同传统发酵金鲳的品质等级进行判别,其中,神经网络模型采用tansig作为隐藏层传递函数,采用purelin函数作为输出层传递函数,采用梯度下降法进行训练。
[0069]
实施例1:本发明公开了基于单分子测序的发酵金鲳深度学习质量判别方法,包括如下步骤:
[0070]
(1)制备不同品质等级的传统发酵金鲳检测样品,若干传统发酵金鲳去皮去骨后,每条鱼从起点开始向尾部方向依次以中线和上表层为基点制取2cm
×
2cm
×
1cm(长
×
宽
×
厚)的待测块状样品;上述的块状样品采用液氮冷却后研磨5-8s,每个样品重复研磨3次,制得传统发酵金鲳粉末状样品;
[0071]
(2)采用dna提取试剂盒对步骤(1)中不同品质等级传统发酵金鲳样品提取宏基因组dna,采用单分子实时测序对不同样品的dna进行测序,通过对ccs(circular consensus sequencing)序列进行过滤、聚类,并进行物种注释和丰度分析,揭示样品中微生物的群落结构。
[0072]
(3)将不同品质等级的发酵金鲳样品的物种丰度数据,作为训练样本数据。利用mapminmax函数将训练样本数据归一化到[0,1]之间,其计算公式为:y=(y
max-y
min
)*(x-x
min
)/(x
max-x
min
)+y
min
。其中,y为归一化之后的值,x
max
为样本数据的最大值,x
min
为样本数据的最小值。
[0073]
(4)确定神经网络层数,各层节点数,隐含层神经元个数、训练次数、学习速率及训练目标最小误差等。使用tansig为隐藏层传递函数,purelin函数作为输出层传递函数,采用梯度下降法进行训练,建立神经网络模型。
[0074]
(5)初始化所述神经网络的权值与阈值在[-1,1]之间。利用步骤(3)中归一化后的训练样本数据对步骤(4)所述神经网络模型进行训练,当训练误差小于训练目标最小误差,并符合预设精度要求时,停止对所述神经网络进行训练,以得到训练好的神经网络。
[0075]
(6)利用训练好的神经网络对不同传统发酵金鲳的品质进行判别。
[0076]
实施例2:
[0077]
1、本发明提出的方法应用于传统发酵金鲳品质判别,本实施例中所用的金鲳购于阳江市宏凯渔风有限公司,品质等级分别为a、b、c、d和e等级的样品各10条,共计50条,根据
发明专利中步骤(1)中的方法将传统发酵金鲳进行预处理,每条鱼从起点开始向尾部方向依次切取5块2cm宽的鱼块,小心切除每一个鱼块上表层的和中线部位的鱼肉,然后以中线和上表层为基点制取1cm
×
1cm
×
1cm(长
×
宽
×
厚)的待测样品,随后将块状的传统发酵金鲳样品置于液氮环境中进行冷却,随后用研磨机进行研磨5-8s,每个样品重复研磨3次,制得传统发酵金鲳粉末状样品,获得的样品用于单分子实时测序进行微生物群落结构分析。
[0078]
(2)采用omniscripy rt kit对步骤(1)中不同品质等级传统发酵金鲳样品提取宏基因组dna,随后检测dna的片段完整度、纯度及浓度。pcr扩增程序为:95℃预变性2min;98℃变性10s,55℃退火30s,72℃延伸90s,共循环30次;72℃终端延伸2min。各样品产物纯化后,用pacbio smrt测序平台构建文库。使用smrt link v8.0软件,按照minpasses≥5,minpredictedaccuracy≥0.9识别ccs序列。使用lima v1.7.0通过识别barcode序列识别不同样品的ccs序列并去除嵌合体,得到高质量的ccs序列。使用usearch软件(version10.0)在相似性97%的水平上对序列进行聚类,以所有序列数的0.005%作为阈值过滤otus。以silva为参考数据库使用朴素贝叶斯分类器结合比对的方法对特征序列进行分类学注释,可得到每个特征对应的物种分类信息,进而在各个水平(门、纲、目、科、属)统计各样品群落组成,利用qime软件获得不同分类水平的物种丰度表。
[0079]
(3)将不同品质等级的发酵金鲳样品的物种丰度数据,作为训练样本数据。利用mapminmax函数将训练样本数据归一化到[0,1]之间,其计算公式为:y=(y
max-y
min
)
×
(x-x
min
)/(x
max-x
min
)+y
min
。其中,y为归一化之后的值,x
max
为样本数据的最大值,x
min
为样本数据的最小值。
[0080]
(4)确定神经网络层数,各层节点数,隐含层神经元个数、训练次数、学习速率及训练目标最小误差等。使用tansig为隐藏层传递函数,purelin函数作为输出层传递函数,采用梯度下降法进行训练,建立神经网络模型。其中,tansig函数表达式为:
[0081][0082]
而purelin函数表达式为:
[0083]
y=x;
[0084]
初始化所述神经网络的权值阈值在[-1,1]之间。基于梯度下降法对网络权值和阈值进行调整:
[0085]
隐含层到输出层的权值:
[0086]wjk
=w
jk
+ηh
jek
;
[0087]
输入层到隐含层的权值:
[0088][0089]
隐含层到输出层的阈值:
[0090]bk
=bk+ηek;
[0091]
输入层到输出层的阈值:
[0092]
[0093]
其中:w
ij
为输出层到隐藏层的权值,w
jk
为隐藏层到输出层的权值,bk为隐含层到输出层的阈值,aj为输入层到隐含层的阈值,η为学习速率,hj为隐含层输出。
[0094]
利用步骤(3)中归一化后的样本数据对步骤(4)所述神经网络模型进行训练,当训练误差小于训练目标最小误差,并符合预设精度要求时,停止对所述神经网络进行训练,以得到训练好的神经网络。不同品质等级的传统发酵金鲳各有10组数据,每个品质等级将70%的数据即7组数据,五个品质等级共35组数据作为样本训练数据,20%的数据,每个品质等级2组,共10组数据作为样本验证数据,剩余的5%的数据,每个品质等级1组,共5组数据作为样本的测试数据。
[0095]
(6)利用训练好的神经网络对不同传统发酵金鲳的品质等级进行判别。
[0096]
综上,本技术突破发酵水产食品经验式鉴别发酵程度的限制,能够从微生物角度科学分析发酵阶段,为实现传统发酵金鲳靶向工艺调控和品质监测提供技术支撑。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1