疾病多源数据的处理方法、装置、存储介质及电子装置与流程
1.本技术涉及数据处理领域,具体而言,涉及一种疾病多源数据的处理方法、装置、存储介质及电子装置。
背景技术:
2.发明人发现,大数据判断疾病中基于西医或中医进行处理、建模并疾病分类,但是仅从中医角度进行分析处理,得到的辅助诊断结果往往不够精确,仅从西医角度进行分析处理,得到的辅助诊断结果又难以代表整体。
3.针对相关技术中无法将西医和中医相结合造成辅助诊断结果不够精确或难以代表整体的问题,目前尚未提出有效的解决方案。
技术实现要素:
4.本技术的主要目的在于提供一种疾病多源数据的处理方法、装置、存储介质及电子装置,以解决无法将西医和中医相结合造成辅助诊断结果不够精确或难以代表整体的问题。
5.为了实现上述目的,根据本技术的一个方面,提供了一种疾病多源数据的处理方法。
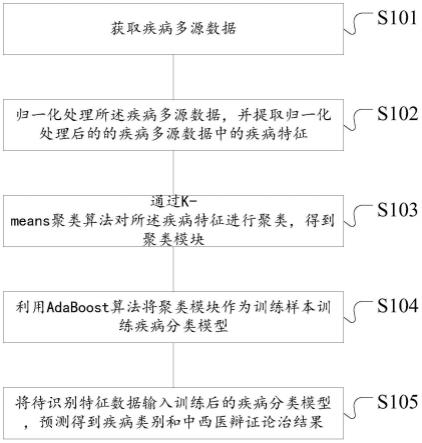
6.根据本技术的疾病多源数据的处理方法包括:获取疾病多源数据;其中,所述疾病多源数据包括:中西医辩证论治数据和患者疾病数据;归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征;通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块;利用adaboost算法将聚类模块作为训练样本训练疾病分类模型;将待识别特征数据输入训练后的疾病分类模型,预测得到疾病类别和中西医辩证论治结果。
7.进一步的,所述患者疾病数据至少包括:患者的疾病病史、主次要症状信息、常规检查信息和查体信息。
8.进一步的,所述中西医辩证论治数据至少包括:疾病主次要症状、中医辨病辩证依据、西医诊断标砖和依据以及中西医辩证论治方法和处方。
9.进一步的,归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征包括:
10.对所述疾病多源数据进行分词并去除停用词处理;
11.采用tf-idf分词技术从处理后的疾病多源数据中提取特征词,作为疾病特征。
12.进一步的,通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块包括:
13.给定聚类k和疾病特征的数据集t={t1,t2……
,tn},ti=(xi,yi);
14.随机选择k作为初始质心点;
15.对于所剩下的对象,则根据它们与聚类中心的距离,分别将其分配给与其最相似的聚类;
16.计算每个所获新聚类的聚类中心;
17.如果满足标准,则停止。
18.进一步的,利用adaboost算法将聚类模块作为训练样本训练疾病分类模型包括:
19.将聚类模块作为训练样本,每一个训练样本有初始化权重:
[0020][0021]
计算基本分类器的训练偏差:
[0022][0023]
循环迭代t次,并对每个训练样本的权重进行更新:
[0024]zt
是标准化因子,λ
t
是基本分类器;
[0025]
强分类器h通过多个带权重的基本分类器表示:
[0026][0027]
为了实现上述目的,根据本技术的另一方面,提供了一种疾病多源数据的处理装置。
[0028]
根据本技术的疾病多源数据的处理装置包括:获取模块,用于获取疾病多源数据;其中,所述疾病多源数据包括:中西医辩证论治数据和患者疾病数据;处理模块,用于归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征;聚类模块,用于通过 k-means聚类算法对所述疾病特征进行聚类,得到聚类模块;训练模块,用于利用adaboost算法将聚类模块作为训练样本训练疾病分类模型;预测模块,用于将待识别特征数据输入训练后的疾病分类模型,预测得到疾病类别和中西医辩证论治结果。
[0029]
进一步的,所述处理模块包括:对所述疾病多源数据进行分词并去除停用词处理;采用tf-idf分词技术从处理后的疾病多源数据中提取特征词,作为疾病特征。
[0030]
为了实现上述目的,根据本技术的另一方面,提供了一种计算机可读存储介质。
[0031]
根据本技术的计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项所述的疾病多源数据的处理方法。
[0032]
为了实现上述目的,根据本技术的另一方面,提供了一种电子装置。
[0033]
根据本技术的电子装置,包括:存储器和处理器,所述存储器中存储有计算机程序,其中,所述处理器被设置为运行所述计算机程序以执行上述任一项所述的疾病多源数据的处理方法。
[0034]
在本技术实施例中,采用处理疾病多源数据的方式,通过获取疾病多源数据;其中,所述疾病多源数据包括:中西医辩证论治数据和患者疾病数据;归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征;通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块;利用adaboost算法将聚类模块作为训练样本训练疾
病分类模型;将待识别特征数据输入训练后的疾病分类模型,预测得到疾病类别和中西医辩证论治结果;达到了将中医和西医相结合的目的,从而实现了提高辅助诊断结果精确性或足以代表整体的技术效果,进而解决了由于无法将西医和中医相结合造成的辅助诊断结果不够精确或难以代表整体的技术问题。
附图说明
[0035]
构成本技术的一部分的附图用来提供对本技术的进一步理解,使得本技术的其它特征、目的和优点变得更明显。本技术的示意性实施例附图及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
[0036]
图1是根据本技术实施例的疾病多源数据的处理方法的流程示意图;
[0037]
图2是根据本技术实施例的疾病多源数据的处理装置的结构示意图。
具体实施方式
[0038]
为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分的实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本技术保护的范围。
[0039]
需要说明的是,本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本技术的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
[0040]
在本技术中,术语“上”、“下”、“左”、“右”、“前”、“后”、“顶”、“底”、“内”、“外”、“中”、“竖直”、“水平”、“横向”、“纵向”等指示的方位或位置关系为基于附图所示的方位或位置关系。这些术语主要是为了更好地描述本发明及其实施例,并非用于限定所指示的装置、元件或组成部分必须具有特定方位,或以特定方位进行构造和操作。
[0041]
并且,上述部分术语除了可以用于表示方位或位置关系以外,还可能用于表示其他含义,例如术语“上”在某些情况下也可能用于表示某种依附关系或连接关系。对于本领域普通技术人员而言,可以根据具体情况理解这些术语在本发明中的具体含义。
[0042]
此外,术语“安装”、“设置”、“设有”、“连接”、“相连”、“套接”应做广义理解。例如,可以是固定连接,可拆卸连接,或整体式构造;可以是机械连接,或电连接;可以是直接相连,或者是通过中间媒介间接相连,又或者是两个装置、元件或组成部分之间内部的连通。对于本领域普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
[0043]
需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
[0044]
根据本发明实施例,提供了一种疾病多源数据的处理方法,如图1 所示,该方法包括如下的步骤s101至步骤s105:
[0045]
步骤s101、获取疾病多源数据;其中,所述疾病多源数据包括:中西医辩证论治数据和患者疾病数据;
[0046]
根据本发明实施例,优选的,所述患者疾病数据至少包括:患者的疾病病史、主次要症状信息、常规检查信息和查体信息。
[0047]
比如,男,50岁,干部,胃脘痛10年,劳累后加重5天。患者从10 年前经常胃脘部隐痛,每因劳累或饮食失调疼痛加重。曾先后服用多种中西药物治疗,均无明显疗效。5天前,因工作劳累而出现胃脘部隐痛,喜温喜按,神疲乏力、纳呆、四肢倦怠、手足欠温、大便溏薄,遂来就诊;查体:t:36.5、,p:75次/分、r:19次/分,bp:110/75mmhg;神志清、精神可、体形偏瘦、剑突下压痛、舌质淡而苔白、脉沉弱;胃镜显示:粘膜充血、水肿、呈花斑状、红白相间。
[0048]
根据本发明实施例,优选的,所述中西医辩证论治数据至少包括:疾病主次要症状、中医辨病辩证依据、西医诊断标准和依据以及中西医辩证论治方法和处方。
[0049]
比如,出现慢性上腹隐痛、饱胀不适、嗳气、泛酸、呕吐等症状应考虑慢性胃炎的可能。如果舌苔上舌红、舌边有齿印、舌苔白、脉弦细,这是典型的痞满(脾胃虚弱)。同时,可能舌头上会有苦味。这就是西医所说的浅表性胃炎的症状。另外,慢性浅表性胃炎辨病辨证主要依据为:脾胃为仓廪之官,主受纳和运化水谷,由于反复的劳倦过度,或饮食失调,均能引起脾阳不振。中焦虚寒,则胃痛隐隐,喜温喜按;脾胃虚寒,运化失常,则纳呆,食少;脾在体合肉,健运四肢,中阳不足,则健运无权,肌肉筋脉失其温养,故神疲乏力、手足不温;脾虚生湿,下渗肠间,故大便溏薄;舌质淡,苔白,脉沉弱,皆为脾胃虚寒,中气不足之象;慢性浅表性胃炎的诊断标准和依据为:
①
胃镜下可见胃腔内黏液增多,并且附着在胃黏膜上不易脱落,用水冲后,附着处黏膜表面呈红色或糜烂脱落,黏液斑不易被水冲脱;
②
胃黏膜产生红、白相间,以红为主或花斑样黏膜改变;
③
胃黏膜水肿,反光强,苍白,胃小窝明显;
④
胃黏膜充血,可呈线状或片状,充血处呈鲜红色,界限不清,与不充血处相间,呈斑片样;
⑤
胃黏膜糜烂,有红肿、黏液斑,可呈局限性;病灶中新旧出血点均可见,或有小丘疹状隆起,顶部有脐样凹陷;
⑥
胃黏膜出血,可呈小点状或小片状,出血可新鲜,也可陈旧。符合上述诊断标准和依据中一条者,即可诊断患有慢性浅表性胃炎;符合1-4条可诊断为单纯型浅表性胃炎;符合第5条的可诊断为糜烂型浅表性胃炎;符合第6 条的可诊断为出血型浅表性胃炎。
[0050]
步骤s102、归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征;
[0051]
根据本发明实施例,优选的,归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征包括:
[0052]
对所述疾病多源数据进行分词并去除停用词处理;
[0053]
采用tf-idf分词技术从处理后的疾病多源数据中提取特征词,作为疾病特征。
[0054]
考虑到上述信息和数据多为文本数据,故进行分词并去除停用词处理,得到数据文本,采用tf-idf分词技术从数据文本中提取特征词;数据文本中包含n个文档,每个文档中包含若干个词语,用d表示数据文本中的文档,t表示数据文本中的词语,所述tf-idf的计算公式为:
[0055]wdt
=(m
dt
/m
t
).lg(n/n
t
+0.01)
[0056]
其中,w
dt
为词语t在文档d中的权重,m
dt
表示词语t在文档d中出现的次数,m
t
表示文档d中词语的总数,n
t
为数据文本中包含t的文档数。
[0057]
比如,男,40岁,胸闷痛反复发作3年,加重2天。患者近3年来,反复发作性胸部疼痛、胸闷不适。昨日因高兴,过量饮食而诱发胸部疼痛,疼痛剧烈,胸闷如窒,痛引肩背,表情焦虑,同时伴有气喘短促,肢体沉重,休息5分钟后可缓解。病人形体肥胖,痰多,平素喜嗜食肥甘厚味。查体:t:36.7℃,p:115次/分,r:23次/分,bp:120/ 80mmhg,舌淡,苔浊腻,脉滑。心电图示:ⅱ、ⅲ,avf s-t段下移,t 波倒置。
[0058]
处理后可得到“胸部疼痛、疼痛剧烈、胸闷如窒、痛引肩背、反复发作、胸闷不适、伴有气喘短促、肢体沉重、在休息后缓解;舌淡、苔浊腻、脉滑;ⅱ、ⅲ,avf s-t段下移,t波倒置;形体肥胖、痰多、喜嗜食肥甘厚味”等重要特征。
[0059]
步骤s103、通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块;
[0060]
根据本发明实施例,优选的,通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块包括:
[0061]
给定聚类k和疾病特征的数据集t={t1,t2……
,tn},ti=(xi,yi);
[0062]
随机选择k作为初始质心点;
[0063]
对于所剩下的对象,则根据它们与聚类中心的距离,分别将其分配给与其最相似的聚类;
[0064]
计算每个所获新聚类的聚类中心;
[0065]
如果满足标准,则停止。
[0066]
为便于模型训练并提高模型的泛化能力,特地按中医辨病辨证的依据和西医诊断的标准和依据将数据集进行聚类分块进行划分。聚类的原理是以样本数据对象间的距离作为聚类标准,即样本间距离越小则表示两样本具有较高的相似性,并会朝向一个中心点聚集;而距离越大则表示相似性较低,并远离该中心点。重复上述过程,直到相应标准测试函数收敛为止。k-means算法作为一种经典的聚类算法,有着广泛应用。给定聚类k和数据集t={t1,t2……
,tn},ti=(xi,yi),其基本思想如下:
[0067]
步骤1、随机选择k作为初始质心点;
[0068]
步骤2、对于所剩下的对象,则根据它们与这些聚类中心的距离,分别将其分配给与其最相似的聚类;
[0069]
步骤3、计算每个所获新聚类的聚类中心;
[0070]
步骤4、如果满足标准,则停止;否则跳转到步骤2,直到满足停止条件。
[0071]
停止条件设定如下:没有需要分配的任务到不同的簇时,质心不再发生变化,或均方误差值e下降幅度很小,计算公式方误差值e下降幅度很小,计算公式其中,ck是第k个簇,mk是簇ck的质心,d(x,m
k )是x和质心mk之间的距离。距离公式为
[0072][0073]
使用k-means算法主要为了分割数据集,根据某个特征做聚类分成若干的小数据集,提高模型精准度。
[0074]
举一个例子:导致出现胸部疼痛的疾病是非常多的,例如常见的有消化道的疾病,比如食管炎等;呼吸系统的疾病也会导致出现胸痛。例如肺部感染、胸膜炎等;心血管疾病也会导致出现胸痛的现象,例如急性心肌梗死、心绞痛等。具体到本步骤,如果选定“胸部疼痛”症状作为聚类特征,由于数据跨越度较大,聚类区分效果明显。仅常见消化道的疾病类
别可能通常计为100种,此处k值最终选定为100,并找到100 个聚类中心点,通过聚类算法得到100个子块数据集。
[0075]
步骤s104、利用adaboost算法将聚类模块作为训练样本训练疾病分类模型;
[0076]
adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特征,并放在关键的训练数据上面。具体来说,该算法是通过每个病历样本对应的权重来实现,给定训练样本集 d={(x1,y1),(x2,y2)...(xn,yn),y∈{1,2,3,4,5,6,...}},其中y标签数值对应疾病类别集合中某种疾病。初始时每个疾病样本所对应的权重相等,即,并按照给定分块疾病样板数据集进行训练,训练出一弱分类器。对于错分的疾病样本适当增加该权重,未错分的样本适当降低其权重,以此更新训练集样本的分布。在新的样本分布下,再次对基本学习分类器进行训练,得到。反复迭代t次,得到t个弱分类器,最终的集成分类器是每个基本分类器的加权投票,具体到本应用,选取svm作为基本分类器。
[0077]
根据本发明实施例,优选的,利用adaboost算法将聚类模块作为训练样本训练疾病分类模型包括:
[0078]
将聚类模块作为训练样本,每一个训练样本有初始化权重:
[0079][0080]
计算基本分类器的训练偏差:
[0081][0082]
循环迭代t次,并对每个训练样本的权重进行更新:
[0083]zt
是标准化因子,λ
t
是基本分类器;
[0084]
强分类器h通过多个带权重的基本分类器表示:
[0085][0086]
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。adaboost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被突显出来,从而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。依次类推,经过t次循环,得到t个弱分类器,把这t个弱分类器按一定的权重叠加(boost)起来,得到最终想要的强分类器。
[0087]
这里,利用网格搜索法对基本分类器svm进行参数调优,进行模型优化。关于svm参数的优化选取,一般通过大量的实验比较来确定参数,这种方法不仅浪费时间,而且不易寻得最优参数。网格搜索法是将待搜索参数在一定的空间范围中划分成网格,通过遍历网格中所有的点来寻找最优参数。这种方法在寻优区间足够大且步距足够小的情况下可以找出全局最优解。寻优过程如下:
[0088]
1)设定网格搜索变量的范围及搜索步距。其中的初始设置为,的初始设置为,初始步距为0.5;
[0089]
2)采用k-cv交叉验证方式对各训练集进行训练测试,其中k值设定为5,得到使svm分类准确率最高的局部最优参数即c=1、g=0.00092。最后根据得到的最优局部参数,选择临近搜索区间进行二次寻优,步距与1)中步距相等。上述过程具有不易过早收敛且易于快速定位参数空间等特点,可高效实现参数调优。
[0090]
步骤s105、将待识别特征数据输入训练后的疾病分类模型,预测得到疾病类别和中西医辩证论治结果。
[0091]
待识别特征数据经上述所训练的预测模型即可得到疾病类别和中西医辩证论治结果。
[0092]
比如,男,40岁,胸闷痛反复发作3年,加重2天。患者近3年来,反复发作性胸部疼痛、胸闷不适。昨日因高兴,过量饮食而诱发胸部疼痛,疼痛剧烈,胸闷如窒,痛引肩背,表情焦虑,同时伴有气喘短促,肢体沉重,休息5分钟后可缓解。病人形体肥胖,痰多,平素喜嗜食肥甘厚味。查体:t:36.7℃,p:115次/分,r:23次/分,bp:120/ 80mmhg,舌淡,苔浊腻,脉滑。心电图示:ⅱ、ⅲ,avf s-t段下移,t 波倒置。
[0093]
辨病辨证依据:痰浊盘踞,胸阳失展,故胸闷如窒而痛;阻滞脉络,故痛引肩背;气机痹阻不畅,故见气短喘促;脾主四肢,痰浊困脾,脾气不运,故肢体沉重;形体肥胖,痰多,苔浊腻,脉滑均为痰浊壅阻之征。
[0094]
西医诊断依据:1)、胸部疼痛反复发作,疼痛剧烈,常放射至肩背; 2)、疼痛可在休息后缓解;3)、心电图示:ⅱ、ⅲ,avf s-t段下移,t 波倒置。中医诊断:胸痹;痰浊壅塞;西医诊断:心绞痛;冠状动脉粥样硬化性心脏病;治法:通阳泄浊,豁痰开结。方药:栝蒌薤白半夏汤加减。栝蒌30g薤白10g半夏9g陈皮15g茯苓15g甘草3g;服法:三剂,水煎服。日一剂,早晚分服。
[0095]
再比如,男,25岁,腹部疼痛1天。患者因出差,旅途劳累,饮食不节,时觉中上腹胀痛不适,夜间上腹疼痛加剧,呈阵发性,伴恶心呕吐一次,今晨腹痛转移至右下腹,痛势剧烈,持续不减,无腹泻,轻度发热,遂来就诊。查体:t:37.2℃,p:90次/分,r:19次/分,bp: 110/70mmhg.神清,痛苦面容,心肺未见异常,腹平坦,右下腹压痛明显,murphy征阳性,反跳痛,右下腹局限性肌紧张,肠鸣音未见异常,舌红,苔薄黄而腻,脉弦数。实验室检查:血常规:白细胞15.2
×ꢀ
1012/l,中性粒细胞86%,血红蛋白135g/l,血小板198
×
109/l.尿常规:正常。b超检查腹部未见明显异常。
[0096]
辨病辨证依据:患者饮酒多食肥甘,导致运化失职,糟粕积滞,渐生湿热,湿热内蕴,瘀滞不散,热盛肉腐则成肠痈;痈阻肠道,气滞血瘀,不通则痛,故见右下腹剧痛;湿热内蕴,而见发热;舌红苔薄黄腻,脉弦数,为湿热内蕴之象。
[0097]
西医诊断依据:1)、转移性右下腹痛半天,伴发热;2)、t: 37.2℃,腹平坦,右下腹
压痛明显、反跳痛、局部肌紧张,murphy征阳性;3)、实验室检查:血常规:白细胞16.2
×
109/l,中性粒细胞89%。
[0098]
中医诊断:肠痈;湿热内蕴、气滞血瘀;西医诊断:急性阑尾炎。
[0099]
治法:行气祛瘀,通腑泄热;方药:大黄牡丹汤加减。大黄后下6g 丹皮12g桃仁12g蒲公英30g芒硝冲服6g红藤30g紫花地丁30g连翘15g玄胡索15g金银花12g甘草6g;服法:三剂,水煎服。日一剂,早晚分服。
[0100]
从以上的描述中,可以看出,本发明实现了如下技术效果:
[0101]
在本技术实施例中,采用处理疾病多源数据的方式,通过获取疾病多源数据;其中,所述疾病多源数据包括:中西医辩证论治数据和患者疾病数据;归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征;通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块;利用adaboost算法将聚类模块作为训练样本训练疾病分类模型;将待识别特征数据输入训练后的疾病分类模型,预测得到疾病类别和中西医辩证论治结果;达到了将中医和西医相结合的目的,从而实现了提高辅助诊断结果精确性或足以代表整体的技术效果,进而解决了由于无法将西医和中医相结合造成的辅助诊断结果不够精确或难以代表整体的技术问题。
[0102]
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
[0103]
根据本发明实施例,还提供了一种用于实施上述疾病多源数据的处理方法的装置,如图2所示,该装置包括:
[0104]
获取模块10,用于获取疾病多源数据;其中,所述疾病多源数据包括:中西医辩证论治数据和患者疾病数据;
[0105]
根据本发明实施例,优选的,所述患者疾病数据至少包括:患者的疾病病史、主次要症状信息、常规检查信息和查体信息。
[0106]
比如,男,50岁,干部,胃脘痛10年,劳累后加重5天。患者从10 年前经常胃脘部隐痛,每因劳累或饮食失调疼痛加重。曾先后服用多种中西药物治疗,均无明显疗效。5天前,因工作劳累而出现胃脘部隐痛,喜温喜按,神疲乏力、纳呆、四肢倦怠、手足欠温、大便溏薄,遂来就诊;查体:t:36.5、,p:75次/分、r:19次/分,bp:110/75mmhg;神志清、精神可、体形偏瘦、剑突下压痛、舌质淡而苔白、脉沉弱;胃镜显示:粘膜充血、水肿、呈花斑状、红白相间。
[0107]
根据本发明实施例,优选的,所述中西医辩证论治数据至少包括:疾病主次要症状、中医辨病辩证依据、西医诊断标准和依据以及中西医辩证论治方法和处方。
[0108]
比如,出现慢性上腹隐痛、饱胀不适、嗳气、泛酸、呕吐等症状应考虑慢性胃炎的可能。如果舌苔上舌红、舌边有齿印、舌苔白、脉弦细,这是典型的痞满(脾胃虚弱)。同时,可能舌头上会有苦味。这就是西医所说的浅表性胃炎的症状。另外,慢性浅表性胃炎辨病辨证主要依据为:脾胃为仓廪之官,主受纳和运化水谷,由于反复的劳倦过度,或饮食失调,均能引起脾阳不振。中焦虚寒,则胃痛隐隐,喜温喜按;脾胃虚寒,运化失常,则纳呆,食少;脾在体合肉,健运四肢,中阳不足,则健运无权,肌肉筋脉失其温养,故神疲乏力、手足不温;脾虚生湿,下渗肠间,故大便溏薄;舌质淡,苔白,脉沉弱,皆为脾胃虚寒,中气不足之象;慢性浅表性胃炎的诊断标准和依据为:
①
胃镜下可见胃腔内黏液增多,并且附着在胃黏膜上不易脱
落,用水冲后,附着处黏膜表面呈红色或糜烂脱落,黏液斑不易被水冲脱;
②
胃黏膜产生红、白相间,以红为主或花斑样黏膜改变;
③
胃黏膜水肿,反光强,苍白,胃小窝明显;
④
胃黏膜充血,可呈线状或片状,充血处呈鲜红色,界限不清,与不充血处相间,呈斑片样;
⑤
胃黏膜糜烂,有红肿、黏液斑,可呈局限性;病灶中新旧出血点均可见,或有小丘疹状隆起,顶部有脐样凹陷;
⑥
胃黏膜出血,可呈小点状或小片状,出血可新鲜,也可陈旧。符合上述诊断标准和依据中一条者,即可诊断患有慢性浅表性胃炎;符合1-4条可诊断为单纯型浅表性胃炎;符合第5条的可诊断为糜烂型浅表性胃炎;符合第6 条的可诊断为出血型浅表性胃炎。
[0109]
处理模块20,用于归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征;
[0110]
根据本发明实施例,优选的,归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征包括:
[0111]
对所述疾病多源数据进行分词并去除停用词处理;
[0112]
采用tf-idf分词技术从处理后的疾病多源数据中提取特征词,作为疾病特征。
[0113]
考虑到上述信息和数据多为文本数据,故进行分词并去除停用词处理,得到数据文本,采用tf-idf分词技术从数据文本中提取特征词;数据文本中包含n个文档,每个文档中包含若干个词语,用d表示数据文本中的文档,t表示数据文本中的词语,所述tf-idf的计算公式为:
[0114]wdt
=(m
dt
/m
t
).lg(n/n
t
+0.01)
[0115]
其中,w
dt
为词语t在文档d中的权重,m
dt
表示词语t在文档d中出现的次数,m
t
表示文档d中词语的总数,n
t
为数据文本中包含t的文档数。
[0116]
比如,男,40岁,胸闷痛反复发作3年,加重2天。患者近3年来,反复发作性胸部疼痛、胸闷不适。昨日因高兴,过量饮食而诱发胸部疼痛,疼痛剧烈,胸闷如窒,痛引肩背,表情焦虑,同时伴有气喘短促,肢体沉重,休息5分钟后可缓解。病人形体肥胖,痰多,平素喜嗜食肥甘厚味。查体:t:36.7℃,p:115次/分,r:23次/分,bp:120/ 80mmhg,舌淡,苔浊腻,脉滑。心电图示:ⅱ、ⅲ,avf s-t段下移,t 波倒置。
[0117]
处理后可得到“胸部疼痛、疼痛剧烈、胸闷如窒、痛引肩背、反复发作、胸闷不适、伴有气喘短促、肢体沉重、在休息后缓解;舌淡、苔浊腻、脉滑;ⅱ、ⅲ,avf s-t段下移,t波倒置;形体肥胖、痰多、喜嗜食肥甘厚味”等重要特征。
[0118]
聚类模块30,用于通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块;
[0119]
根据本发明实施例,优选的,通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块包括:
[0120]
给定聚类k和疾病特征的数据集t={t1,t2……
,tn},ti=(xi,yi);
[0121]
随机选择k作为初始质心点;
[0122]
对于所剩下的对象,则根据它们与聚类中心的距离,分别将其分配给与其最相似的聚类;
[0123]
计算每个所获新聚类的聚类中心;
[0124]
如果满足标准,则停止。
[0125]
为便于模型训练并提高模型的泛化能力,特地按中医辨病辨证的依据和西医诊断
的标准和依据将数据集进行聚类分块进行划分。聚类的原理是以样本数据对象间的距离作为聚类标准,即样本间距离越小则表示两样本具有较高的相似性,并会朝向一个中心点聚集;而距离越大则表示相似性较低,并远离该中心点。重复上述过程,直到相应标准测试函数收敛为止。k-means算法作为一种经典的聚类算法,有着广泛应用。给定聚类k和数据集t={t1,t2……
,tn},ti=(xi,yi),其基本思想如下:
[0126]
步骤1、随机选择k作为初始质心点;
[0127]
步骤2、对于所剩下的对象,则根据它们与这些聚类中心的距离,分别将其分配给与其最相似的聚类;
[0128]
步骤3、计算每个所获新聚类的聚类中心;
[0129]
步骤4、如果满足标准,则停止;否则跳转到步骤2,直到满足停止条件。
[0130]
停止条件设定如下:没有需要分配的任务到不同的簇时,质心不再发生变化,或均方误差值e下降幅度很小,计算公式方误差值e下降幅度很小,计算公式其中,ck是第k个簇,mk是簇ck的质心,d(x,m
k )是x和质心mk之间的距离。距离公式为
[0131][0132]
使用k-means算法主要为了分割数据集,根据某个特征做聚类分成若干的小数据集,提高模型精准度。
[0133]
举一个例子:导致出现胸部疼痛的疾病是非常多的,例如常见的有消化道的疾病,比如食管炎等;呼吸系统的疾病也会导致出现胸痛。例如肺部感染、胸膜炎等;心血管疾病也会导致出现胸痛的现象,例如急性心肌梗死、心绞痛等。具体到本步骤,如果选定“胸部疼痛”症状作为聚类特征,由于数据跨越度较大,聚类区分效果明显。仅常见消化道的疾病类别可能通常计为100种,此处k值最终选定为100,并找到100 个聚类中心点,通过聚类算法得到100个子块数据集。
[0134]
训练模块40,用于利用adaboost算法将聚类模块作为训练样本训练疾病分类模型;
[0135]
adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特征,并放在关键的训练数据上面。具体来说,该算法是通过每个病历样本对应的权重来实现,给定训练样本集 d={(x1,y1),(x2,y2)...(xn,yn),y∈{1,2,3,4,5,6,...}},其中y标签数值对应疾病类别集合中某种疾病。初始时每个疾病样本所对应的权重相等,即,并按照给定分块疾病样板数据集进行训练,训练出一弱分类器。对于错分的疾病样本适当增加该权重,未错分的样本适当降低其权重,以此更新训练集样本的分布。在新的样本分布下,再次对基本学习分类器进行训练,得到。反复迭代t次,得到t个弱分类器,最终的集成分类器是每个基本分类器的加权投票,具体到本应用,选取svm作为基本分类器。
[0136]
根据本发明实施例,优选的,利用adaboost算法将聚类模块作为训练样本训练疾病分类模型包括:
[0137]
将聚类模块作为训练样本,每一个训练样本有初始化权重:
[0138][0139]
计算基本分类器的训练偏差:
[0140][0141]
循环迭代t次,并对每个训练样本的权重进行更新:
[0142]zt
是标准化因子,λ
t
是基本分类器;
[0143]
强分类器h通过多个带权重的基本分类器表示:
[0144][0145]
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类能力。adaboost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被突显出来,从而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。依次类推,经过t次循环,得到t个弱分类器,把这t个弱分类器按一定的权重叠加(boost)起来,得到最终想要的强分类器。
[0146]
这里,利用网格搜索法对基本分类器svm进行参数调优,进行模型优化。关于svm参数的优化选取,一般通过大量的实验比较来确定参数,这种方法不仅浪费时间,而且不易寻得最优参数。网格搜索法是将待搜索参数在一定的空间范围中划分成网格,通过遍历网格中所有的点来寻找最优参数。这种方法在寻优区间足够大且步距足够小的情况下可以找出全局最优解。寻优过程如下:
[0147]
1)设定网格搜索变量的范围及搜索步距。其中的初始设置为,的初始设置为,初始步距为0.5;
[0148]
2)采用k-cv交叉验证方式对各训练集进行训练测试,其中k值设定为5,得到使svm分类准确率最高的局部最优参数即c=1、g=0.00092。最后根据得到的最优局部参数,选择临近搜索区间进行二次寻优,步距与1)中步距相等。上述过程具有不易过早收敛且易于快速定位参数空间等特点,可高效实现参数调优。
[0149]
预测模块50,用于将待识别特征数据输入训练后的疾病分类模型,预测得到疾病类别和中西医辩证论治结果。
[0150]
待识别特征数据经上述所训练的预测模型即可得到疾病类别和中西医辩证论治结果。
[0151]
比如,男,40岁,胸闷痛反复发作3年,加重2天。患者近3年来,反复发作性胸部疼
痛、胸闷不适。昨日因高兴,过量饮食而诱发胸部疼痛,疼痛剧烈,胸闷如窒,痛引肩背,表情焦虑,同时伴有气喘短促,肢体沉重,休息5分钟后可缓解。病人形体肥胖,痰多,平素喜嗜食肥甘厚味。查体:t:36.7℃,p:115次/分,r:23次/分,bp:120/ 80mmhg,舌淡,苔浊腻,脉滑。心电图示:ⅱ、ⅲ,avf s-t段下移,t 波倒置。
[0152]
辨病辨证依据:痰浊盘踞,胸阳失展,故胸闷如窒而痛;阻滞脉络,故痛引肩背;气机痹阻不畅,故见气短喘促;脾主四肢,痰浊困脾,脾气不运,故肢体沉重;形体肥胖,痰多,苔浊腻,脉滑均为痰浊壅阻之征。
[0153]
西医诊断依据:1)、胸部疼痛反复发作,疼痛剧烈,常放射至肩背; 2)、疼痛可在休息后缓解;3)、心电图示:ⅱ、ⅲ,avf s-t段下移,t 波倒置。中医诊断:胸痹;痰浊壅塞;西医诊断:心绞痛;冠状动脉粥样硬化性心脏病;治法:通阳泄浊,豁痰开结。方药:栝蒌薤白半夏汤加减。栝蒌30g薤白10g半夏9g陈皮15g茯苓15g甘草3g;服法:三剂,水煎服。日一剂,早晚分服。
[0154]
再比如,男,25岁,腹部疼痛1天。患者因出差,旅途劳累,饮食不节,时觉中上腹胀痛不适,夜间上腹疼痛加剧,呈阵发性,伴恶心呕吐一次,今晨腹痛转移至右下腹,痛势剧烈,持续不减,无腹泻,轻度发热,遂来就诊。查体:t:37.2℃,p:90次/分,r:19次/分,bp: 110/70mmhg.神清,痛苦面容,心肺未见异常,腹平坦,右下腹压痛明显,murphy征阳性,反跳痛,右下腹局限性肌紧张,肠鸣音未见异常,舌红,苔薄黄而腻,脉弦数。实验室检查:血常规:白细胞15.2
×ꢀ
1012/l,中性粒细胞86%,血红蛋白135g/l,血小板198
×
109/l.尿常规:正常。b超检查腹部未见明显异常。
[0155]
辨病辨证依据:患者饮酒多食肥甘,导致运化失职,糟粕积滞,渐生湿热,湿热内蕴,瘀滞不散,热盛肉腐则成肠痈;痈阻肠道,气滞血瘀,不通则痛,故见右下腹剧痛;湿热内蕴,而见发热;舌红苔薄黄腻,脉弦数,为湿热内蕴之象。
[0156]
西医诊断依据:1)、转移性右下腹痛半天,伴发热;2)、t: 37.2℃,腹平坦,右下腹压痛明显、反跳痛、局部肌紧张,murphy征阳性;3)、实验室检查:血常规:白细胞16.2
×
109/l,中性粒细胞89%。
[0157]
中医诊断:肠痈;湿热内蕴、气滞血瘀;西医诊断:急性阑尾炎。
[0158]
治法:行气祛瘀,通腑泄热;方药:大黄牡丹汤加减。大黄后下6g 丹皮12g桃仁12g蒲公英30g芒硝冲服6g红藤30g紫花地丁30g连翘15g玄胡索15g金银花12g甘草6g;服法:三剂,水煎服。日一剂,早晚分服。
[0159]
从以上的描述中,可以看出,本发明实现了如下技术效果:
[0160]
在本技术实施例中,采用处理疾病多源数据的方式,通过获取疾病多源数据;其中,所述疾病多源数据包括:中西医辩证论治数据和患者疾病数据;归一化处理所述疾病多源数据,并提取归一化处理后的的疾病多源数据中的疾病特征;通过k-means聚类算法对所述疾病特征进行聚类,得到聚类模块;利用adaboost算法将聚类模块作为训练样本训练疾病分类模型;将待识别特征数据输入训练后的疾病分类模型,预测得到疾病类别和中西医辩证论治结果;达到了将中医和西医相结合的目的,从而实现了提高辅助诊断结果精确性或足以代表整体的技术效果,进而解决了由于无法将西医和中医相结合造成的辅助诊断结果不够精确或难以代表整体的技术问题。
[0161]
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用
的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
[0162]
以上所述仅为本技术的优选实施例而已,并不用于限制本技术,对于本领域的技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1