基于BPMLP-XGBoost的产品活性值和ADMET性质的预测方法及系统
基于bpmlp-xgboost的产品活性值和admet性质的预测方法及系统
技术领域
1.一种基于bpmlp-xgboost的产品活性值和admet性质的预测方法及系统,用于药物产品筛选,属于生物医药与计算科学交叉技术领域,该方法也可间接应用于用于元器件产品筛选。
背景技术:
2.为了提高药物产品研发的成功率,除了筛选潜在的具有较高生物活性值的化合物产品,还需要防止因admet性质不良而引起的副作用,使得药物疗效不理想,因此需要在研发这些化合物的早期阶段进行筛选预测和优化功效,在提高化合物生物活性值的同时,降低了admet性质的风险。因此,从大量化合物中筛选出较高生物活性值和良好admet性质的化合物是筛选药物的关键工作之一。目前,对药物进行体外或体内实验主要用于测试化合物的吸收性、分布性、代谢性、排泄性和毒性。由于化合物的生物活性值和admet性质的未知或难以预测,因此只能通过动物实验获得。然而,由于物种差异,这些方法的成本高、耗时长,并且通常很难从体外推断到体内或者从动物推断到人类。此外,一方面,随着数据规模不断变大,人类大脑的算力也越来越有限,对生物活性值的计算与判断亟需计算机的帮助;另一方面,目前化合物的admet性能优化主要依靠专家经验,这些经验部分来源于化学生物学知识,部分来源于以往实验的总结,但这些经验和实验结果都是有限的。
3.因此,随着越来越多的实验数据的产生和计算机技术的发展,人们越来越重视从数据中建立模型,并寻找规律,即以数据驱动的方式预测和优化化合物。使用仿真模型不仅可以降低成本,而且在某种程度上可能比体外实验更准确,计算过程比人类更智能。因此,可以利用机器学习模型在短时间内对大量候选药物的生物活性值和药代动力学性质、安全性做出预测,以便从大量候选药物中快速识别出具有较高生物活性值和较好admet性质的化合物。
4.但现有技术存在如下技术问题:
5.1.对药物产品的生物活性值和admet性质的预测准确率低;
6.2.实现复杂,计算效率低,且内存需求高;
7.3.所采用的模型的参数的更新受梯度的伸缩变换影响且得到的超参数不具有很好的解释性。
技术实现要素:
8.针对上述研究的问题,本发明的目的在于提供一种基于bpmlp-xgboost的产品活性值和admet性质的预测方法及系统,解决现有技术对药物产品的生物活性值和admet性质的预测准确率低的问题。
9.为了达到上述目的,本发明采用如下技术方案:
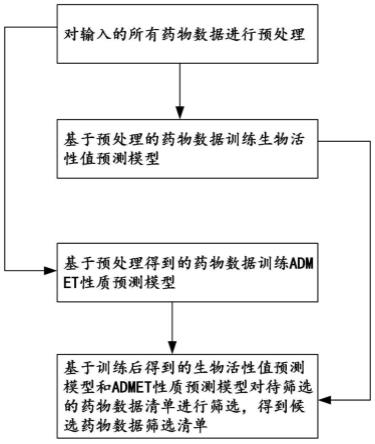
10.一种基于bpmlp-xgboost的产品活性值和admet性质的预测方法,包括如下步骤:
11.步骤1、对输入的所有药物产品数据进行预处理,其中,药物数据为分子描述符数据;
12.步骤2、对预处理得到的药物产品数据进行特征提取,提取后训练生物活性值预测模型,得到训练好的生物活性值预测模型;
13.步骤3、基于预处理得到的药物产品数据训练admet性质预测模型,得到训练好的admet性质预测模型;
14.步骤4、基于训练后得到的生物活性值预测结果、admet性质预测结果和筛选条件,对待筛选的药物产品数据清单进行筛选,得到候选药物产品筛选清单。
15.进一步,所述步骤1的具体步骤为:
16.步骤11、若各分子描述符的相对方差小于给定阈值,则删去此分子描述符数据,否则,保留;
17.步骤12、基于步骤11得到的结果,判断任意两个分子描述符数据的相关系数是否大于给定的阈值,若是,则删去任一分子描述符,否则,都保留并转到步骤13;
18.步骤13、保存步骤12保留的所有分子描述符数据,即得到预处理后的药物产品数据。
19.进一步,所述步骤2中的生物活性值预测模型为基于反向传播优化的多层感知机bpmlp模型,即采用adam优化器在mlp的基础上加入误差反向传播优化。
20.进一步,所述步骤2的具体步骤为:
21.步骤21、基于预处理后的药物产品数据训练分子描述符数据提取器lgbm:
22.步骤22、基于训练后的分子描述符数据提取器lgbm返回的特征重要性与生物活性值相关性较高的前20个分子描述符;
23.步骤23、将得到的前20个分子描述符数据训练生物活性值预测模型,得到训练好的生物活性值预测模型。
24.进一步,所述步骤3中的admet性质预测模型为xgboost模型。
25.进一步,所述步骤4的具体步骤为:
26.步骤41、基于训练好的生物活性值预测模型对待筛选的药物数据清单中的药物数据进行预测,得到预测结果a;
27.步骤42、基于训练好的生物活性值预测模型对待筛选的药物数据清单中的药物数据进行预测,得到预测结果b;
28.步骤43、设置生物活性值及admet性质的筛选条件;
29.步骤44、预测结果a与生物活性值筛选条件进行比较,筛选出符合筛选条件的药物产品数据,保存符合筛选条件的药物产品数据;
30.步骤45将预测结果b与admet性质筛选条件进行比较,筛选出符合筛选条件的药物产品数据,保存符合筛选条件的药物产品数据;
31.步骤46.取步骤44得到的筛选结果与步骤45得到的筛选结果的交集,得到候选药物产品筛选清单。
32.一种基于bpmlp-xgboost的产品活性值和admet性质的预测系统,包括:
33.预处理模块:对输入的所有药物产品数据进行预处理,其中,药物产品数据为分子描述符数据;
34.生物活性值预测模型训练模块:对预处理得到的药物产品数据进行特征提取,提取后训练生物活性值预测模型,得到训练好的生物活性值预测模型;
35.admet性质预测模型训练模块:基于预处理得到的药物数据训练admet性质预测模型,得到训练好的admet性质预测模型;
36.筛选模块:基于训练后得到的生物活性值预测结果、admet性质预测结果和筛选条件,对待筛选的药物产品数据清单进行筛选,得到候选药物产品筛选清单。
37.进一步,所述预处理模块的具体实现步骤为:
38.步骤11、若各分子描述符的相对方差小于给定阈值,则删去此分子描述符数据,否则,保留;
39.步骤12、基于步骤11得到的结果,判断任意两个分子描述符的相关系数是否大于给定的阈值,若是,则删去任一分子描述符数据,否则,都保留并转到步骤13;
40.步骤13、保存步骤12保留的所有分子描述符数据,即得到预处理后的药物产品数据。
41.进一步,所述生物活性值预测模型训练模块中的生物活性值预测模型为基于反向传播优化的多层感知机bpmlp模型,即采用adam优化器在mlp的基础上加入误差反向传播优化;
42.所述生物活性值预测模型训练模块的具体实现步骤为:
43.步骤21、基于预处理后的药物产品数据训练分子描述符数据提取器lgbm;
44.步骤22、基于训练后的分子描述符数据提取器lgbm返回的特征重要性与生物活性值相关性较高的前20个分子描述符数据;
45.步骤23、将得到的前20个分子描述符数据训练生物活性值预测模型,得到训练好的生物活性值预测模型。
46.进一步,所述admet性质预测模型训练模块中的admet性质预测模型为xgboost模型;
47.所述筛选模块的具体实现步骤为:
48.步骤41、基于训练好的生物活性值预测模型对待筛选的药物产品数据清单中的药物产品数据进行预测,得到预测结果a;
49.步骤42、基于训练好的生物活性值预测模型对待筛选的药物产品数据清单中的药物数据进行预测,得到预测结果b;
50.步骤43、设置生物活性值及admet性质的筛选条件;
51.步骤44、预测结果a与生物活性值筛选条件进行比较,筛选出符合筛选条件的药物数据,保存符合筛选条件的药物数据;
52.步骤45将预测结果b与admet性质筛选条件进行比较,筛选出符合筛选条件的药物数据,保存符合筛选条件的药物数据;
53.步骤46.取步骤44得到的筛选结果与步骤45得到的筛选结果的交集,得到候选药物数据筛选清单。
54.本发明同现有技术相比,其有益效果表现在:
55.一、本发明对药物产品数据进行了专门的数据预处理,减少了不相关和冗余的分子描述符的干扰,从而减少了数据规模,提高了运算效率;
56.二、本发明基于生物活性值预测模型和admet性质预测模型对药物数据清单中的符合生物活性值和admet性质的药物产品数据进行筛选,可在短时间内对大量药物产品的生物活性值和药代动力学性质、安全性做出预测,以便从大量药物中快速识别出具有较高生物活性值和较好admet性质的化合物;
57.三、本发明采用基于反向传播优化的多层感知机bpmlp模型(即基于反向传播优化的多层感知机神经网络模型)进行药物产品的生物活性值预测,利于捕捉数据集中内部维度的特征,使数据内部结构挖掘得更充分,可用于回归型问题预测,同时采用xgboost模型进行admet性质预测,通过两个模型预测后进行筛选,并求交集,不仅实现简单,计算高效,且内存需求低,还提高了预测准确率,经过本文数据预处理后数据,采用xgboost模型与不预处理对比,有显著提升,准确率分别提高了:caco-2:2.61%,cyp3a4:2.78%,herg:0.36%,hob:0.57%,mn:1.43%,与正则化xgboost模型相比,herg、hob预测准确率相当,其他指标有明显提高,准确率分别提高了:caco-2:2.1%,cyp3a4:2%,mn:1.3%,因此,在采用本案的两个模型,其准确率总体得到提高。
附图说明
58.图1是本发明的流程示意图;
59.图2是本发明中对预处理得到的药物产品数据进行特征提取,提取后训练生物活性值预测模型,得到训练好的生物活性值预测模型的流程示意图;
60.图3是本发明中基于训练后得到的生物活性值预测结果、admet性质预测结果以及设置的筛选条件,对待筛选的药物产品数据清单进行筛选,得到候选药物数据筛选清单的流程示意图。
具体实施方式
61.下面将结合附图及具体实施方式对本发明作进一步的描述。
62.本发明设计了一种基于bpmlp-xgboost的产品活性值和admet性质的预测方法,本发明提出的模型可以预测化合物的生物活性值和admet性质,帮助筛选出具备良好的生物活性值和药代动力学性质(admet性质)、安全性的候选药物产品。
63.具体如下:
64.步骤1、对输入的药物产品数据进行预处理;具体是通过python-excel接口读入excel文件中的药物数据,并转化为数组形式保存,以方便操作运算,最终得到所有的药物产品数据,为729列分子描述符数据,即729类分子描述符数据;
65.具体步骤为:
66.步骤11、若各分子描述符数据的相对方差小于给定阈值,则删去此分子描述符,否则,保留;即分别计算729类分子描述符的方差,将方差小于0.05的列删去;否则,保留;
67.步骤12、基于步骤11得到的结果,判断任意两类分子描述符的相关系数是否大于给定的阈值,若是,则删去任一分子描述符数据,否则,都保留并转到步骤13;即运用corr()计算两列之间的相关系数,并将相关系数大于0.95的任意一列分子描述符删去,否则,保留。
68.步骤13、保存步骤12保留的所有分子描述符数据,即得到预处理后的药物产品数
据。
69.步骤2、对预处理得到的药物产品数据进行特征提取,提取后训练生物活性值预测模型,得到训练好的生物活性值预测模型;生物活性值预测模型为基于反向传播优化的多层感知机bpmlp模型,即采用adam优化器在mlp的基础上加入误差反向传播优化。
70.基于反向传播优化的多层感知机bpmlp模型为4层,依次包括输入层、第一全连接层和第二全层和输出层。感知器(即指基于反向传播优化的多层感知机bpmlp模型的各层)的输出通过relu函数进行变换。输入层的输入尺寸设置为20。第一全连接层和第二全层的输入和输出维度设置为300,输出层的输出维度设置为1。
71.多层感知机bpmlp模型的评价指标为:损失函数采用预测准确率率率表示预测值,yi表示真实值,n表示数据维度。
72.实现具体步骤为:
73.步骤21、基于预处理后的药物产品数据训练分子描述符数据提取器lgbm;
74.步骤22、基于训练后的分子描述符数据提取器lgbm返回的特征重要性与生物活性值(即指产品活性值)相关性较高的前20个分子描述符数据;即根据feature_importance值的大小,返回重要性排名前20的分子描述符数据。feature_importance选出数值跨度较大的作为分界,例如:数值为10,9.8,9.6,8.9,4,3.2,3则提取前4个作为分子描述符,之后的分子描述符不具有代表性。
75.步骤23、将得到的影响率较高的前20个分子描述符数据训练生物活性值预测模型,得到训练好的生物活性值预测模型。
76.即将前20个分子描述符的80%数据用于训练优化后的多层感知机bpmlp模型,得到最优化参数设置如下:
77.学习率为0.001;处理尺寸batch_size为2;训练轮数为30;lgbm相关参数包括:boosting_type(即指提升算法类型)、objective(即指学习任务/目标)、n_estimators(即指弱学习器的数目)、learning_rate(即指学习率)、num_leaves(即指叶子数目)、feature_fraction(即指选择特征比例)、bagging_fraction(即指删除),bagging_fraction效果跟feature_fraction类似、min_child_weight(即指叶结点的最小权重);具体参数设置如下:
78.boosting_type=
′
gbdt’,objective=
′
regression
′
,n_estimators=10,learning_rate=0.1,num_leaves=31,feature_fraction=0.8,,min_child_weight=0.001;
79.将前20个分子描述符数据余下的20%用于验证,得到预测准确率为89.2%。
80.步骤3、基于预处理得到的药物产品数据训练admet性质预测模型,得到训练好的admet性质预测模型;其中,admet性质预测模型为xgboost模型;
81.将预处理后的药物产品数据的80%用于训练xgboost模型,训练好后,将余下的20%的药物产品数据用于验证,并选用预测准确率和auc(area under roc curve,特征曲线面积)值作为评价模型,两者均小于等于1,且预测准确率和aug值越大,说明模型表现能力越好。得到最终的模型预测准确率分别为caco-2(即指小肠上皮细胞渗透性):94.0%,cyp3a4(即指细胞色素p450酶3a4亚型):95.7%,herg(即指化合物心脏安全性评价):
89.4%,hob(即指人体口服生物利用度):88.6%,mn(即指微核试验):96.2%;auc值为caco-2:0.933、cyp3a4:0.954、herg:0.891、hob:0.839、mn:0.939。
82.xgboost模型所使用参数包括booster(即指计算类型)、silent(即指是否打印运行信息),eta(即指收缩步长)、0bjective(即指学习人物/目标)、eval_metric(即指评价指标)、subsample(即指训练模型的子样本占整个样本集合的比例);具体的参数设置如下:
83.booster=
′
gbtree
′
,silent=0,eta=0.3,objective=
′
binary:logistic
′
,eval_metric=
′
error
′
,subsample=1
84.本文在增加数据预处理的基础上,经过数据预处理后的药物产品数据,在xgboost模型上的预测准确率,优于现有技术,因为防止过拟合,直接应用xgboost模型损失函数加入的正则化项进行计算,对比现有技术,herg、hob预测准确率相当,其他指标有明显提高,准确率分别提高了:caco-2:2.1%,cyp3a4:2%,mn:1.3%,对比其他方法有显著提升。
85.同时,对比此领域常用的其他预测模型:支持向量机svm,随机森林rf,线性判别分类lda,k-近邻knn,朴素贝叶斯nb,以及各种分类模型的变种,本发明提出的基于bpmlp-xgboost模型的预测准确率都优于上述模型的预测准确率,具有较高的实际指导性。bpmlp-xgboost与其他机器学习模型的预测准确率对比结果如下:
[0086][0087][0088]
步骤4、基于训练后得到的生物活性值预测结果、admet性质预测结果以及筛选条件,对待筛选的药物产品数据清单进行筛选,得到候选药物产品筛选清单。具体为:
[0089]
步骤41、基于训练好的生物活性值预测模型对待筛选的药物产品数据清单中的药物数据进行预测,得到预测结果a;
[0090]
步骤42、基于训练好的生物活性值预测模型对待筛选的药物产品数据清单中的药物数据进行预测,得到预测结果b;
[0091]
步骤43、设置生物活性值及admet性质的筛选条件,如admet性质全1,或者某几个性质(caco-2,cyp3a4,mn等)为1;生物活性值>0.85等;
[0092]
步骤44、预测结果a与生物活性值筛选条件进行比较,筛选出符合筛选条件的药物产品数据,保存符合筛选条件的药物产品数据;
[0093]
步骤45将预测结果b与admet性质筛选条件进行比较,筛选出符合筛选条件的药物产品数据,保存符合筛选条件的药物产品数据;
[0094]
步骤46.取步骤44得到的筛选结果与步骤45得到的筛选结果的交集,得到候选药物产品数据筛选清单。
[0095]
综上所述,基于反向传播优化的多层感知机神经网络模型有助于捕捉数据集中内部维度的特征,使数据内部结构挖掘得更充分,可用于回归型问题预测;在建立神经网络模型时,使用adam优化器,与普通的梯度下降优化器相比,adam优化器具有的优点包括:实现简单,计算高效,对内存需求少;参数的更新不受梯度的伸缩变换影响;超参数具有很好的解释性,且通常无需调整或仅需很少的微调等。同时加入了误差反向传播优化,使得预测的误差更小。
[0096]
xgboost使用梯度上升框架,可用于分类问题预测,并且用于解决有监督学习问题。构建多个弱分类器对数据集进行预测,然后将每个基分类器结果相加,作为最终预测结果。它在计算速度、泛化性能和可扩展性方面改进了传统的梯度提升决策树(gbdt)算法。此外,xgboost支持并行化,在选择最佳分裂点,进行枚举的时候并行处理,大大提高了算法的运行效率。
[0097]
本案与现有数据预测不同分子描述符的准确率的对比表如下:
[0098] caco-2cyp3a4herghobmnxgboost90.39%92.92%89.04%88.03%94.77%xgboost+lr91.91%93.76%89.88%88.87%94.94%xgboost++lr+fln\a94.77%n\an\an\axgboost+bpmlp94.0%95.7%89.4%88.6%mn:96.2%
[0099]
综上所述,本案预测的准确率总体得到提高。
[0100]
以上仅是本发明众多具体应用范围中的代表性实施例,对本发明的保护范围不构成任何限制。凡采用变换或是等效替换而形成的技术方案,均落在本发明权利保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1