高血糖危象长期死亡风险预测与评估方法与流程
1.本发明属于医疗技术领域,具体涉及一种高血糖危象长期死亡风险预测与评估方法。
背景技术:
2.既往研究均采用医疗数据分析中常用的广义线性模型预测hce(高血糖危象发作)死亡风险,并基于传统的统计学检验方法和广义线性模型分析hce死亡风险因素,比如,医学统计学中常用的t检验、卡方检验等单因素分析方法,以及lr模型中的比值比(odds ratio,or)和cox比例风险模型中的风险比(hazard ratio,hr)等多因素分析方法。虽然这些传统的广义线性模型可用于死亡风险的预测,但线性模型并不能拟合风险因素间复杂的高维和非线性的关系,容易导致模型欠拟合,使用该类方法构建的预测模型的准确性和泛化能力往往均不尽如人意。并且,上述方法只能用于分析研究人群整体的危险因素,并不能提供特定于某个患者的个性化风险因素分析,且既往研究发现的风险因素并不统一,更强调了个性化风险因素分析的重要性。
3.lightgbm和shap可以解决传统的统计学检验方法和广义线性模型存在的上述缺陷,所以二者应用较多。lightgbm在表格数据的处理中表现出了十分出色的性能,但目前尚未被应用于hce死亡风险预测,shap算法作为目前最流行的模型可解释性算法之一,往往被用于解释图像数据,但在表格数据的解释中应用较少,且未被应用于hce相关预测模型的解释中。lightgbm模型应用的参数包括learning_rate、 n_estimators、subsample、colsample_bytree、reg_alpha、reg_lamba、max_depth 、num_leaves、min_child_samples,研究根据纳入模型的数据规模和特征数量确定了参数的调优范围,所有参数共同参与调节模型的拟合能力和泛化能力间的平衡。但是因参数较多,所以计算成本高。
4.本发明将贝叶斯超参数优化与交叉验证相结合,在降低计算成本的同时提高了模型的鲁棒性。
技术实现要素:
5.为了解决上述技术问题,本发明提供了一种高血糖危象长期死亡风险预测与评估方法。
6.本发明的目的是提供一种高血糖危象长期死亡风险预测与评估方法,包括以下步骤:
7.步骤一,确定用于预测和评估高血糖危象长期死亡风险的特征变量;
8.步骤二,训练lightgbm参数优化模型:
9.建立训练集hce样本,获得训练集hce样本的特征变量的原始数据;
10.数据预处理:删除原始数据中的异常值,然后进行数据标准化,最后填充原始数据中的缺失值;
11.将预处理后的数据进行lightgbm模型超参数优化,完成lightgbm参数优化模型的
训练;
12.步骤三,采用platt scaling算法进行lightgbm参数优化模型的校准,获得校准模型;
13.步骤四,根据校准模型预测和评估高血糖危象长期死亡风险。
14.优选的,上述高血糖危象长期死亡风险预测与评估方法,所述特征变量包括:
15.人口统计学:性别、年龄、体重指数、糖尿病类型;
16.临床实验室指标:患者的临床实验室指标为入院后初次通过采集检测静脉血、动脉血和尿液测得的检验结果,包括:bg、β-羟丁酸、糖化血红蛋白、甘油三酯、总胆固醇、低密度脂蛋白胆固醇、scr、bun、胱抑素c、脂肪酶、淀粉酶、肌酸激酶、心肌肌钙蛋白i、肌酐激酶mb同工酶、谷丙转氨酶、谷草转氨酶、crp、降钙素原、wbc、中性粒细胞百分比、淋巴细胞数、plt、na
+
、血清钾、血清氯、ph、碱剩余、hco
3-、血浆有效渗透压;
17.3)并发症和合并症:感染、脓毒性休克、高血压、冠心病、心力衰竭、脑梗塞、痴呆、糖尿病肾病、急性肾损伤、肿瘤。
18.优选的,上述高血糖危象长期死亡风险预测与评估方法,步骤二中,采用箱型图法并结合指标正常范围和临床专家的指导对异常值进行判断,删除异常值,并采用零-均值规范化的方法进行数据标准化;
19.采用knn算法对原始数据中的缺失值进行填充。
20.优选的,上述高血糖危象长期死亡风险预测与评估方法,lightgbm模型超参数优化的具体方法如下:采取k折交叉验证与贝叶斯优化算法结合的方式进行超参数优化,通过贝叶斯优化更快地寻找潜在的最优超参数组合,并通过 k折交叉验证评估选择的超参数组合的泛化能力,在降低计算成本的同时提高了模型的鲁棒性。
21.优选的,上述高血糖危象长期死亡风险预测与评估方法,选取10折交叉验证和贝叶斯调参对模型迭代100次,其中迭代次数由两部分组成,随机搜索的步数和贝叶斯优化的步数,随机搜索用于扩大搜索空间,跳出局部最优,贝叶斯优化用于寻找最大值,随机搜索步数为5,贝叶斯优化步数为95。
22.优选的,上述高血糖危象长期死亡风险预测与评估方法,lightgbm模型超参数优化涉及的参数为:学习率、迭代次数、行采样率、列采样率、l1正则化系数、l2正则化系数、树的最大树深度,最大叶子节点的数量和叶子节点所包含的最小数据数量。
23.优选的,上述高血糖危象长期死亡风险预测与评估方法,建立训练集hce 样本,获得训练集hce样本的特征变量的原始数据之后,还包括:
24.建立测试集hce样本,获得测试集hce样本的特征变量的原始数据;
25.将预处理后的数据进行lightgbm模型超参数优化之后,还包括:
26.采用测试集hce样本的原始数据对lightgbm参数优化模型进行测试。
27.优选的,上述高血糖危象长期死亡风险预测与评估方法,训练集与测试集的hce样本数量的比例为3-4:1。
28.优选的,上述高血糖危象长期死亡风险预测与评估方法,在选取经测试集评估的预测能力最优的模型后,再对测试集进行二次划分,并将划分后的数据集分别用于模型的校准和测试评估,获得用于预测和评估高血糖危象长期死亡风险校准模型。
29.优选的,上述高血糖危象长期死亡风险预测与评估方法,校准模型用于预测和评
估hce患者3年内死亡风险。
30.与现有技术相比,本发明具有以下有益效果:
31.本发明采用lr、svm、rf、lightgbm和dnn算法构建hce患者入院后3年内死亡风险预测模型,并比较不同算法的预测能力。其中,lr和svm 是过去在构建疾病预后预测模型时常用的经典机器学习算法。rf和lightgbm 分别是基于树的bagging和boosting算法的前沿实现,近年来被广泛应用于 kaggle、drivendata等数据挖掘竞赛,并在表格数据的预测中展现出了十分优越的性能。dnn是深度学习的基础,近年来被广泛应用于计算机视觉、信号处理和自然语言处理等领域并取得了极好的效果。
32.通过比较各模型的预测结果,发现本发明所得的lightgbm参数优化的模型具有较好的预测能力,可用于预测高血糖危象长期死亡风险。
附图说明
33.图1为hba1c的箱型图;
34.图2为原始数据缺失值占比;
35.图3为k值对应的auc;
36.图4为模型的roc曲线和auc值;
37.图5为lightgbm模型的校准曲线和brier score;
38.图6为基于shap算法的个性化风险因素分析示例(死亡);
39.图7为基于shap算法的个性化风险因素分析示例(survival);
40.图8为dnn网络结构示意图;
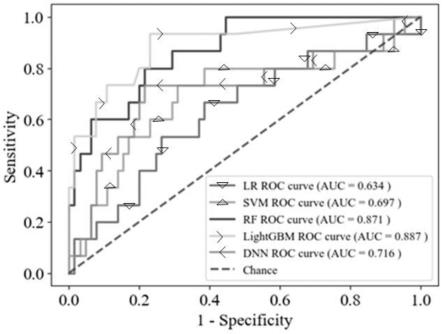
41.图9为5个模型的roc曲线和auc值。
具体实施方式
42.为了使本领域技术人员更好地理解本发明的技术方案能予以实施,下面结合具体实施例和附图对本发明作进一步说明。在本发明的描述中,如未特殊说明,所用方法均为本领域常规技术。
43.一、本发明实施例的数据来源
44.本研究数据来源于2016年5月1日至2020年5月1日期间在重庆大学附属中心医院内分泌科、重庆市西南医院内分泌科、重庆医科大学附属第二医院内分泌科和重庆市巴南区人民医院内分泌科住院的hce患者。
45.二、本发明实施例的纳入与排除标准
46.病例的纳入与排除标准如下表1-2所示。
47.表1dka(糖尿病酮症酸中毒)和hhs(高血糖高渗状态)诊断标准
[0048][0049]
表2纳入与排除标准
[0050][0051]
根据上述纳入排除标准,本发明实施例最终纳入hce患者337例,其中 dka患者207例,hhs患者56例、合并dka-hhs患者74例。
[0052]
实施例1
[0053]
一种高血糖危象长期死亡风险预测与评估方法,包括以下步骤:
[0054]
步骤一,确定特征变量
[0055]
从人口统计学、临床和实验室指标、并发症和合并症三个方面确定了以下个可能的风险因素:
[0056]
1)人口统计学:性别(sex)、年龄(age)、体重指数(body massindex,bmi)、糖尿病类型(diabetes type)。
[0057]
2)临床实验室指标:患者的临床实验室指标为入院后初次通过采集检测静脉血、动脉血和尿液测得的检验结果,包括:bg(血型)、β-羟丁酸(β
‑ꢀ
hydroxybutyrate,β-ohb)、糖化血红蛋白(hemoglobin a1c,hba1c)、甘油三酯(triglyceride,tg)、总胆固醇(total cholesterol,tc)、低密度脂蛋白胆固醇(low-density lipoprotein cholesterol,ldl-c)、血清肌酐(serum creatinine, scr)、bun(血尿素氮)、胱抑素c(cystatin c,cysc)、脂肪酶(lipase, lip)、淀粉酶(amylase,amy)、肌酸激酶(creatine kinase,ck)、心肌肌钙蛋白i(cardiac troponin i,ctni)、肌酐激酶mb同工酶(creatinine kinasesmb isoenzyme,ckmb)、谷丙转氨酶(alanine aminotransferase,alt)、谷草转氨酶(aspartate aminotransferase,ast)、c反应蛋白(c-reactive protein, crp)、降钙素原(procalcitonin,pct)、白细胞(white blood cells,wbc)、中性粒细胞百分比(percentage of neutrophils,neut%)、淋巴细胞数 (lymphocyte,lym)、血小板计数(platelet,plt)、
血清钠(serum sodium, na
+
)、血清钾(serum potassium,k
+
)、血清氯(serum chloride,cl-)、ph、碱剩余(base excess,be)、hco
3-、血浆有效渗透压(effective serumosmolality)。
[0058]
3)并发症和合并症:感染(infection)、脓毒性休克(septic shock)、高血压(hypertension)、冠心病(coronary heart disease,chd)、心力衰竭 (heart failure)、脑梗塞(cerebral infarction,ci)、痴呆(dementia)、糖尿病肾病(diabetic nephropathy,dn)、急性肾损伤(acute kidney injury, aki)、肿瘤(tumor)。
[0059]
步骤二,训练集和测试集的建立
[0060]
本实施例最终选择将重庆大学附属中心医院内分泌科和重庆医科大学附属第二医院内分泌科的hce数据作为训练集,将重庆市西南医院和重庆市巴南医院的数据作为测试集。训练集和测试集均由两家医院的数据组成,按上述方式划分后的训练集包含257例hce患者,测试集包含80例hce患者,划分比例约为3:1。训练集和测试集患者的基线特征如表3所示,其中服从正太分布的连续特征使用平均值
±
标准差表示;不服从正太分布的连续变量使用中位数 (上四分位数,下四分位数)表示;分类变量使用数量(百分比)表示。
[0061]
表3训练集和测试集患者的基线特征
[0062]
[0063][0064]
步骤三,数据预处理
[0065]
初步收集整理的原始数据集中存在可能因设备故障或人工记录偏差导致的异常
值和缺失值等问题,这些问题可能会影响数据的真实性和有效性,导致模型不能从中学习到正确的知识和规律。因此,在预测模型构建之前,需要分析并处理原始数据中存在的缺失值、异常值、量纲不一致等问题,以求提高数据质量。为防止数据窥探,模型预处理相关操作均先在训练集中进行,并将训练集中得到的各种参数应用于测试集。
[0066]
①
异常值分析与处理
[0067]
异常值是指数据中的一些值明显偏离其余值的样本点,常由设备故障和人工记录错误导致。本实施例采用箱型图法并结合指标正常范围和临床专家的指导对异常值进行判断。
[0068]
箱型图是用于显示数据集分散情况的统计图,可直观反映数据的分布,是一种简便且十分有效的可视化分析离群点的方法。该方法重点关注于五个数据节点:上四分位数q3、中位数、下四分位数q1、下边缘(q
1-1.5iqr)、上边缘(q3+1.5iqr),其中iqr=q
3-q1,表示四分位距。异常值被定义为取值小于下边缘或大于上边缘的值。由于本实施例的原始数据集相对较小,为避免引起偏差,在使用箱型图对异常值进行检测的基础上,本实施例结合指标的取值范围和临床专家的建议,对使用箱型图筛选出的异常值进行进一步的判断,并删除最终确定为异常值的数据点。
[0069]
图1为hba1c的箱型图,反映了hba1c数据的分布,其中菱形点为由箱型图判定的异常值,但经综合分析与评估后,认定上述数据点为真实数据,而非因设备故障或人工录入错误等原因导致,因此选择保留。其余特征同样按上述方法进行了异常值分析与处理。
[0070]
数据标准化是指将数据按一定的比例或规则缩放到一定的范围内。在数据输入到模型之前,对数据进行标准化处理可消除量纲带来的影响,有利于对有着不同数量级和单位的数据进行处理和比较。一些基于距离度量的模型,例如knn和svm,对特征间不同的取值范围较为敏感,标准化有助于提高此类模型的精度。此外,一些通过梯度下降进行求解的模型,例如gbdt和 lightgbm,在模型训练前对数据进行标准化有助于减少迭代次数,加快梯度下降法的收敛速度。
[0071]
本实施例采用的数据标准化方法是零-均值规范化(z-score标准化),该方法适用于原始数据最大值和最小值未知的情况,是目前最常用的数据标准化方式之一,其计算公式如下:
[0072][0073]
其中,为原始数据的均值,σ为原始数据的标准差,表示标准化后的数据,x表示原始数据。
[0074]
②
缺失值分析与处理
[0075]
本实施例构建的原始数据集中较多的特征均存在不同程度的数据缺失,而大部分机器学习算法并不能有效处理缺失值。因此,缺失值的填充对提高预测模型的预测能力有着重要意义。
[0076]
原始数据集中缺失值占比最高的10个特征如图2所示。
[0077]
当特征的缺失值占比过高时,进行缺失值填充可能会引起较大的偏差,甚至会使预测模型学习到错误的规律。因此,删除了缺失值占比大于50%的特征(lip(79.4%)和amy(61.1%))。
[0078]
传统缺失值填充方法常根据数据类型及服从的分布形式采用不同的填充方式。例如,对于服从正太分布的连续变量采用均值进行填充;不服从正太分布的连续变量采用中位数进行填充;分类变量采用众数进行填充。尽管这种填充方法简单易行,但该方法将患者的缺失值视为完全随机缺失,对不同患者的缺失值同等看待,无法捕获不同患者缺失值间的联系和差异。因此,简单的缺失值插补法并不能为缺失值提供准确、有效的信息。
[0079]
本实施例选取可以利用原始数据在不同维度上的相关性的knn算法对原始数据中的缺失值进行填充。knn算法填充缺失值的基本原理是在数据空间中识别与待填充的含有缺失值的样本最相近的k个样本,并使用这k个样本的均值对待填充的样本中的缺失值进行估计。为计算含有缺失值的样本与其他样本的距离,首先要选取合适的距离度量方式。对于本文研究的二维表格数据,欧式距离是最常用、最合适的距离计算方法,其计算公式为:
[0080][0081]
其中,d(x,y)表示两点间的距离,xi表示数据x在i维度上的值,yi表示数据y在i维度上的值。
[0082]
在确定距离度量方式后,k值的选取对于缺失值填充的准确性至关重要,当k值选取过小时,容易发生过拟合,样本很容易受到噪声的干扰。而当k值选取过大时,与待填充样本距离较远的样本同样会被选择为邻近点,导致偏差增大,填充准确率降低。因此,本实施例首先依据经验使k值从1到10递增,并用当前k值对应的knn模型对训练集数据进行填充。随后以lr为预测模型, auc为评价指标,使用5折交叉验证法确定lr模型在使用当前k值对应的 knn模型填充后的交叉验证集中的平均auc,并选取平均auc最高的交叉验证结果对应的k值作为knn的参数,不同k值对应的auc如图3所示。
[0083]
从图3中可知,当k值为2时,lr模型在使用knn模型填充后的训练集中通过5折交叉验证得到的平均auc最高。因此,本实施例使用k值为2的 knn模型对训练集和测试集数据进行填充。
[0084]
步骤四,lightgbm模型超参数优化
[0085]
本实施例采取k折交叉验证与贝叶斯优化算法结合的方式进行超参数优化,通过贝叶斯优化更快地寻找潜在的最优超参数组合,并通过k折交叉验证评估选择的超参数组合的泛化能力,在降低计算成本的同时提高了模型的鲁棒性。
[0086]
本实施例最终选取10折交叉验证和贝叶斯调参对模型迭代100次,其中迭代次数由两部分组成,随机搜索的步数和贝叶斯优化的步数,随机搜索用于扩大搜索空间,跳出局部最优,贝叶斯优化用于寻找最大值。本实施例设置随机搜索步数为5,贝叶斯优化步数为95。
[0087]
lightgbm模型超参数优化涉及的关键参数较多。其中learning_rate表示学习率,该值与迭代次数n_estimators相对应,通常learning_rate越小, n_estimators,模型越精确,但同时也带来了过高的计算成本和增加了过拟合的可能性。此外,subsample和colsample_bytree分别用于行采样率和列采样率,在每次迭代过程中随机选择部分数据和特征,可在加快训练速度同时和防止过拟合的发生。reg_alpha和reg_lamba用于分别用于l1正则化和l2正则化,剔除不必要的特征并控制强势特征对预测结果的影响,降低模型的复杂度。 max_depth、num_leaves和min_child_samples分别表示基学习器的最大树深度、
最大叶子节点的数量和叶子节点所包含的最小数据数量,上述三个参数共同用于控制树的生成,并参与调节模型拟合能力和泛化能力之间的平衡。 lightgbm模型超参数优化范围及结果如表4所示,其余未列出的参数设置为默认值。
[0088]
表4lightgbm超参数优化范围及结果
[0089][0090]
本实施例以auc(roc曲线下的面积)、accuracy(模型准确率)、 recall(召回率)、specificity(特异度)、阴性预测值(negative predictivevalue,npv)和阳性预测值(positive predictive value,ppv)作为评价指标综合评估lightgbm的性能。
[0091]
表5模型评价的结果
[0092][0093]
步骤五,模型校准
[0094]
本实施例选取platt scaling算法用于模型校准,该算法是最常用的模型校准算法之一。platt scaling利用了logistic模型输出结果天然具有概率的特性,首先将模型f(x)的输出结果与原始数据集的真实标签组成新的数据集((f(x1),y1),
…
, (f(xn),yn)),随后将其放入logistic模型中进行训练,并将logistic的预测结果作为f(x)校准的结果。
[0095]
使用platt scaling校准模型相当于对模型的再训练,若利用训练模型所用的数据集对模型进行校准,会引入不必要的偏差,容易导致校准后的模型过拟合。因此,本实施例首先将原测试集数据按1:1的比例随机均分为校准集和新的测试集,随后在校准集中对模型进行校准,在新的测试集中对模型校准效果进行评估。由于本实施例样本集相对较小,在最初的数据集划分时,仅将原始数据集划分为训练集和测试集,目的是将尽可能多的样本用于模型训练和预测能力评估。因此,本实施例在选取经原始测试集评估的预测能力最优的模型后,再对测试集进行二次划分,并将划分后的数据集分别用于模型的校准和评估。
[0096]
brier score是最常用的衡量模型校准效果的指标,该分数越低,模型的校准效果越好。brier score的计算公式如下所示:
[0097][0098]
其中yi为样本的真实类别,取值为0或1;pi为校准后的模型预测样本为正的概率,该公式本质是在计算预测概率与真实标签之间的均方误差。
[0099]
校准后的lightgbm模型在新的测试集中的brier score为0.103,为更直观地评估模型的校准效果,本实施例绘制了模型的校准曲线(图5),校准曲线越靠近45
°
参考线,模型校准效果越好。因此,根据brier score和校准曲线可知, lightgbm模型取得了较好的校准效果。
[0100]
图5展示了一个在研究期间内去世的患者的个性化风险因素分析结果。校准后的lightgbm模型预测该患者3年内的死亡风险f(x)为0.623。基线风险 e[f(x)]为0.121,该值等于训练集中死亡人数在研究人群中的占比。分析结果显示,较高的年龄(88years)、bun(36.5mmol/l)、na
+
(164 mmol/l)、cysc(3mg/l)、scr(374umol/l)、effective serumosmolality(343.5mosm/kg)、ctni(0.222μg/l)分别增加了该患者 0.58%、0.15%、0.04%、0.03%、0.03%、0.02%和0.01%的死亡风险。相对较低的bg(15.5mmol/l)和较高的hba1c(11.1%)分别降低了该患者0.32%和 0.05%的死亡风险,模型的预测结果与患者实际的临床结局一致,风险因素分析结果也与临床经验相符。
[0101]
图6的类似的解释可应用于图7,该图展示了测试集中一个在研究期间内存活的患者的模型预测和个性化风险因素分析的结果,该结果同样与患者实际的临床结局和临床经验相符。
[0102]
步骤六,模型超参数调优结果
[0103]
①
lr模型超参数调优
[0104]
lr模型超参数调优的重点在于确定惩罚项使用的范式类型、正则化系数以及损失函数的优化算法。由于l2范数对非稀疏向量的计算效率更高且具备唯一解,本实施例选取l2范数作为惩罚项。c为惩罚系数,用于控制正则化的强度,其值越小,正则化强度越大,模型越不容易过拟合。此外,由于本实施例数据集相对较小,因此损失函数优化算法选择更适用于小规模数据集的 liblinear,该算法使用坐标轴下降法对损失函数进行优化。lr模型超参数优化范围及结果如表6所示,其余未列出的参数设置为默认值。
[0105]
表6lr超参数优化范围及结果
[0106][0107][0108]
②
svm模型超参数调优
[0109]
svm模型超参数调优的重点在于核函数的选择。由于实施例研究的数据集为复杂、高维的医疗数据,因此选取更适用于线性不可分数据的径向基函数核 (radial basis function kernel,rbf)。此外,在确定rbf为核函数后,对模型预测能力有着重要影响的两个超参数分别为用于控制模型泛化能力的惩罚系数 c和用于控制单个样本对整个分类超平面影响的gamma。c值和gamma值越大,样本越容易被选择为支持向量,模型也越容易过拟
合。svm模型超参数优化范围及结果如表7所示,其余未列出的参数设置为默认值。
[0110]
表7svm超参数优化范围及结果
[0111][0112]
③
rf模型超参数调优
[0113]
rf模型超参数调优需重点关注两个方面,一方面是rf的框架,通常为基分类器的数量n_estimators,n_estimators的数量过小容易导致模型欠拟合,而过大则会增加不必要的计算开销;另一方面是控制单棵决策树生成的相关参数,其中关键的参数有树的最大深度max_depth、寻找最佳分割点时需要考虑的特征数量max_features、分裂一个内部节点所需最小样本数min_samples_split和生成叶子节点所需的最小样本数min_samples_leaf。这些参数共同决定单棵决策树的生成并调节决策树的拟合能力和泛化能力之间的平衡。rf模型超参数优化范围及结果如表8所示,其余未列出的参数设置为默认值。
[0114]
表8rf超参数优化范围及结果
[0115][0116]
④
lightgbm模型超参数调优
[0117]
lightgbm模型超参数调优涉及的关键参数较多。其中learning_rate表示学习率,该值与迭代次数n_estimators相对应,通常learning_rate越小, n_estimators,模型越精确,但同时也带来了过高的计算成本和增加了过拟合的可能性。此外,subsample和colsample_bytree分别用于行采样率和列采样率,在每次迭代过程中随机选择部分数据和特征,可在加快训练速度同时和防止过拟合的发生。reg_alpha和reg_lamba用于分别用于l1正则化和l2正则化,剔除不必要的特征并控制强势特征对预测结果的影响,降低模型的复杂度。 max_depth、num_leaves和min_child_samples分别表示基学习器的最大树深度、最大叶子节点的数量和叶子节点所包含的最小数据数量,上述三个参数共同用于控制树的生成,并参与调节模型拟合能力和泛化能力之间的平衡。 lightgbm模型超参数优化范围及结果如表9所示,其余未列出的参数设置为默认值。
[0118]
表9lightgbm超参数优化范围及结果
[0119][0120][0121]
⑤
dnn模型超参数调优
[0122]
dnn模型的超参数可分为两类,一类是与网络结构相关的超参数,另一类是除网络结构以外的与模型训练相关的超参数。本文根据输入数据的大小、特征类型和特征数量预先设定了dnn模型的网络结构,dnn网络结构的示意图如图8所示。
[0123]
本实施例将连续变量和分类变量分别输入批归一化(batch normalization, bn)层和随机失活(dropout)层,其中bn层是一种用于解决dnn训练过程中因参数更新出现的数据分布改变的方法,bn层首先通过归一化将输入转化为均值为0方差为1的标准正态分布,随后对服从标准正太分布的输入进行尺度变化和偏移,从而加快模型收敛速度并缓解梯度弥散问题;随机失活 (dropout)层是训练dnn常用的一种技巧,该层可在网络进行前向传播时,让神经元有一定的概率停止工作,从而减弱对一些局部特征的依赖,增强模型的泛化能力,本实施例将三个dropout层的神经元失活概率均设置为0.5。此外,需要声明的是,由于本实施例所纳入的分类变量均为二分类变量,因此未设置嵌入层对分类变量进行处理linear层也称为全连接层,该层全部神经元均与上一层的神经元相连,实现对输入数据的组合和变换。激活函数选取relu,该函数的解析为式为relu=max(0,x),相比于sigmoid激活函数,relu的训练速度更快并解决了梯度弥散问题。本文dnn网络结构核心参数如表10所示。
[0124]
表10dnn网络结构超参数
[0125]
[0126][0127]
本实施例随后在上述网络结构的基础上对模型进行进一步的超参数调优。本文选取带动量的随机梯度下降(stochastic gradient descent,sgd)算法作为优化器,其中learning_rate表示学习率,learning_rate越大,参数更新步长越大。 momentum表示参数更新时的动量系数,动量是参照物理学中的动能与势能的转换原理提出的,可直观理解为当前时刻的梯度与前一时刻的梯度方向相似时,增加该步的权值更新,反之则减少,该参数可在一定程度上加快模型训练速度并避免陷入局部最优。batch_size决定一次训练的样本数目,因本文数据集相对较小,因此未根据batch_size对数据集进行划分,而是采用全数据集对模型进行训练。全数据集确定的参数更新方向可更好地代表总体样本的规律,从而使参数更准确地朝向极值所在地方向进行更新。
[0128]
dnn模型超参数优化范围及结果如表11所示,其余未列出的参数设置为默认值。
[0129]
表11dnn超参数优化范围及结果
[0130][0131]
注:“/”表示没有相关数据。
[0132]
步骤七,预测结果与分析
[0133]
本实施例以auc、accuracy、recall、specificity、npv和ppv作为评价指标综合评估模型的性能。前文构建的5个预测模型的roc曲线及auc值如图9所示,由图可知,lightgbm在测试集中有着最高的auc(0.887)。
[0134]
5个模型的accuracy、recall、specificity、npv和ppv的值如表12所示。在5个预测模型中,lightgbm模型有着最高的accuracy、recall、npv和 ppv;dnn模型虽然有着最高的specificity,但其recall却过低,导致不能有效识别样本中的正例。此外,dnn模型在除specificity外的5个评价指标中的表现也均不如lightgbm模型。因此,在综合评估后,本实施例选择 lightgbm模型作为最终的hce患者3年内死亡风险预测模型。
[0135]
表12模型评价的结果
[0136][0137]
需要说明的是,本发明中涉及数值范围时,应理解为每个数值范围的两个端点以及两个端点之间任何一个数值均可选用,由于采用的步骤方法与实施例相同,为了防止赘述,本发明描述了优选的实施例。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0138]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1