一种静脉血栓栓塞症危险因素抽取的方法
1.本发明涉及一种静脉血栓栓塞症危险因素抽取的方法,属于自然语言处理领域。
背景技术:
2.静脉血栓栓塞症(venous thromboembolism,vte)包括深静脉血栓形成(deep venous thrombosis,dvt)和肺栓塞(pulmonary embolism,pte),是住院患者常见的并发症,也是医院内非预期死亡的重要原因,已经成为医院管理者和临床医务人员面临的严峻问题。早期的识别和诊断,能够有效降低静脉血栓栓塞症的风险,对于高危患者的精准识别和迅速实施医疗手段显得至关重要。所以尽早对患者进行风险评估以及采取相应的治疗手段,对保障患者安全尤为重要。目前静脉血栓风险评估主要依靠医务人员根据患者电子病历进行填表,最后根据填表的结果对患者采取相应的预防措施,手工填表的方式不仅增加了医护人员的工作负担,而且由于医护人员水平不一,容易出现错误评估,导致患者没法得到正确的预防措施。因此,如何利用自然语言处理和人工智能的方法对电子病历进行信息抽取,如何把抽取出来的信息用于静脉血栓的风险评估是一项有挑战的工作。
3.信息抽取旨在从自然语言文本中抽取出特定的事件或事实信息以形成结构化的文本数据,涵盖命名实体识别(named entity recognition,ner)和关系抽取(relation extraction,re)两个基本任务。根据两个任务的先后完成顺序,可以分为流水线抽取和联合抽取两种类型。
4.流水线方式是指先用一个模型进行命名实体的识别,然后在识别出命名实体的基础上对实体之间的关系类别进行分类,流水线方式存在以下的缺点,(1)误差传递,命名实体模型识别的错误会传递到关系抽取的模型,影响最终抽取效果。(2)缺少交互,命名实体识别模型与关系抽取模型是两个模型,两个模型分开训练又分开预测,导致实体与关系之间缺少信息。(3)关系抽取的冗余,关系抽取模型对多个实体进行两两配对,产生很多冗余的关系对。
5.联合抽取的方式是指在实体和关系抽取在一个模型内进行,在一定程度上克服流水线模式的三个缺点。联合抽取的模型又分为参数共享和联合解码两种。联合模型的难点是如何加强实体模型和关系模型之间的交互,比如实体模型和关系模型的输出之间存在着一定的约束,在建模的时候考虑到此类约束将有助于联合模型的性能。
技术实现要素:
6.鉴于现有技术中的上述缺陷或不足,本发明提供一种静脉血栓栓塞症危险因素抽取的方法。
7.本发明的技术方案是:一种静脉血栓栓塞症危险因素抽取的方法,包括如下:
8.step1、首先根据静脉血栓栓塞症风险评估量表定义新的实体类型和关系类型,从医院获取电子病历文本数据,对数据清洗后进行实体关系的标注;
9.step2、其次获取标注好的数据集,对数据集进行预处理,得到每句话中的实体位
置和实体类型,关系中的头实体和尾实体的位置和关系类型,用于训练深度学习联合抽取模型;
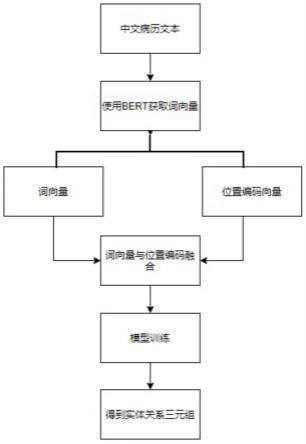
10.step3、对输入模型的text使用中文预训练模型bert对上下文进行编码,提取每个字符的特征,再用旋转位置编码模块对词向量进行位置编码,把词向量与位置向量进行融合,最后进行模型训练;
11.作为本发明的进一步方案,所述step1中,根据静脉血栓栓塞症的风险评估量表定义的新的实体类型和关系类型;
12.定义实体类型,用于标注实体类型;
13.定义关系类型,用于标注关系类型;数据清洗是对异类异常值,格式异常及脏乱进行映射和清洗。
14.作为本发明的进一步方案,所述step2中包括:对标注好的数据进行预处理,包括把文本中的内容进行分句,获取每一句中的实体和关系的类型和位置,从而获得模型训练的数据格式,获取实体关系位置信息的数据再经过bert预处理,得到token span。
15.作为本发明的进一步方案,所述step3的具体步骤如下:
16.step3.1.对输入模型的text使用中文预训练模型bert对上下文进行编码,提取每个字符的特征,得到词向量v={w1,w2,w3......wn};
17.step3.2.词向量通过变换q与k序列向量,位置向量positionembedding=q*k;
18.step3.3.把位置向量转换成与词向量矩阵相同的维度,然后进行拼接融合,把融入后向量输入到全连接层进行实体关系分类;
19.本发明的有益效果是:本发明根据静脉血栓栓塞症风险评估量表定义新的实体类型和关系类型,用于标注临床的电子病历中静脉血栓栓塞症风险因素信息;其次在联合抽取模型上融入旋转式位置编码,在原来词向量的基础上增加了相对位置信息,提高联合抽取模型在中文电子病历的抽取效果;本发明能实现从电子病历中抽取静脉血栓栓塞症危险因素信息。
附图说明
20.图1为本发明手工标注界面;
21.图2为本发明标注后数据预处理过程;
22.图3为本发明模型处理流程。
具体实施方式
23.实施例1:如图1-图3所示,一种静脉血栓栓塞症危险因素抽取的方法,包括如下:
24.step1、首先根据静脉血栓栓塞症风险评估量表定义新的实体类型和关系类型,从医院获取电子病历文本数据,对数据清洗后进行实体关系的标注;定义实体类型,用于标注实体类型;定义关系类型,用于标注关系类型;数据清洗是对异类异常值,格式异常及脏乱进行映射和清洗;实体关系的标注细节:不同类型的实体采用不用的颜色进行展示,再实体都标注好的情况下,对存在关系的实体对进行关系标注。
25.定义的实体类型详细如表1所示:
26.表1为实体类型
[0027][0028][0029]
定义关系类型,详细如表2所示:
[0030]
表2为关系类型
[0031]
关系名称说明body-symptom身体部位和其表现出来的症状method-drug服用药物的方法test-result检查项目及其结果test-value生化检验项目及其数值大小time-disease疾病诊断的时间time-operation手术的实施时间
[0032]
step2、其次获取标注好的数据集,对数据集进行预处理,得到每句话中的实体位置和实体类型,关系中的头实体和尾实体的位置和关系类型。用于训练深度学习联合抽取模型;
[0033]
作为本发明的进一步方案,所述step2中包括:对标注好的数据进行预处理,包括把文本中的内容进行分句,获取每一句中的实体和关系的类型和位置,从而获得模型训练的数据格式。
[0034]
在标注完成后,标注的实体关系信息会在.ann文件中,如图2所示。实体以t开头,关系则以r开头。数据标注好后把.txt文件以句号为分隔符把文本分割多个句子,同时在.ann文件中找到实体关系信息,输出处理好的文件。
[0035]
进一步地,step3中,具体步骤如下:
[0036]
step3.1.对输入模型的text使用中文预训练模型bert对上下文进行编码,提取每
个字符的特征,得到词向量v={w1,w2,w3......wn};
[0037]
step3.2.词向量通过变换q与k序列向量,位置向量positionembedding=q*k;
[0038]
step3.3.把位置向量转换成与词向量矩阵相同的维度,然后进行拼接融合,把融入后向量输入到全连接层进行实体关系分类;
[0039]
step3.4.得到实体关系三元组和计算模型抽取效果,模型评价指标使用准确率(precision、p)、召回率(recall、r)和f1值。
[0040]
精确率(p)、召回率(r)和f1值的表达式如下:
[0041][0042][0043][0044]
tp(true positive)表示将正类预测为正类;
[0045]
fp(false positive)表示将负类预测为正类;
[0046]
fn(false negative)表示将负类预测为负类;
[0047]
精确率(precision):表示正确预测为正的样本占全部预测为正的样本的比例。召回率(recall):表示正确预测为正的样本占实际为正的样本的比例。
[0048]
f1:表示在精确率和召回率之间的一个平衡指标。
[0049]
表3模型效果
[0050] precisionrecallf1实体0.87040.92980.8991关系0.92600.91920.9226
[0051]
由表3可以看出,本发明在实体识别和关系抽取的效果上达到89%和92%。
[0052]
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1